다중에이전트 강화학습을 활용한 유동성 게임 모델링
📝 원문 정보
- Title: Multiagent Reinforcement Learning for Liquidity Games
- ArXiv ID: 2601.00324
- 발행일: 2026-01-01
- 저자: Alicia Vidler, Gal A. Kaminka
📝 초록 (Abstract)
스와밍 방법을 금융 시장의 유동성 모델링에 적용하고, 스와밍 분석에 금융 분석 기법을 도입하는 것은 두 연구 분야 모두에 새로운 진전을 가져올 가능성이 있다. 스와밍 연구에서는 게임 이론을 활용해 자기 이익을 추구하는 스와밍 참여자들이 집합적 효용을 따르는 현상을 설명할 수 있다. 금융 시장에서는 독립적인 금융 에이전트가 시장의 안정성과 효율성을 위해 자율적으로 조직되는 방식을 이해하는 것이 시장 설계 연구에 큰 도움이 된다. 본 논문은 거래 시 유동성에 따라 트레이더의 보상이 결정되는 ‘Liquidity Games’를, 차별 보상(difference reward)을 이용해 자기 이익과 전역 목표를 정렬시키는 ‘Rational Swarms’와 결합한다. 우리는 트레이더 집단이 시장 유동성 제공이라는 공동 목표를 갖되 개별 에이전트는 독립성을 유지하는 이론적 틀을 제시한다. 마코프 팀 게임 프레임워크 내에서 차별 보상을 적용함으로써, 개별 에이전트가 유동성을 극대화하는 행동이 별도의 협조나 공모 없이 전체 시장 유동성 향상에 기여함을 보인다. 이 금융 스와밍 모델은 양측면—개별 수익성 및 집합적 시장 효율성—을 동시에 달성할 수 있는 합리적이고 독립적인 에이전트의 행동을 모델링하는 기반을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
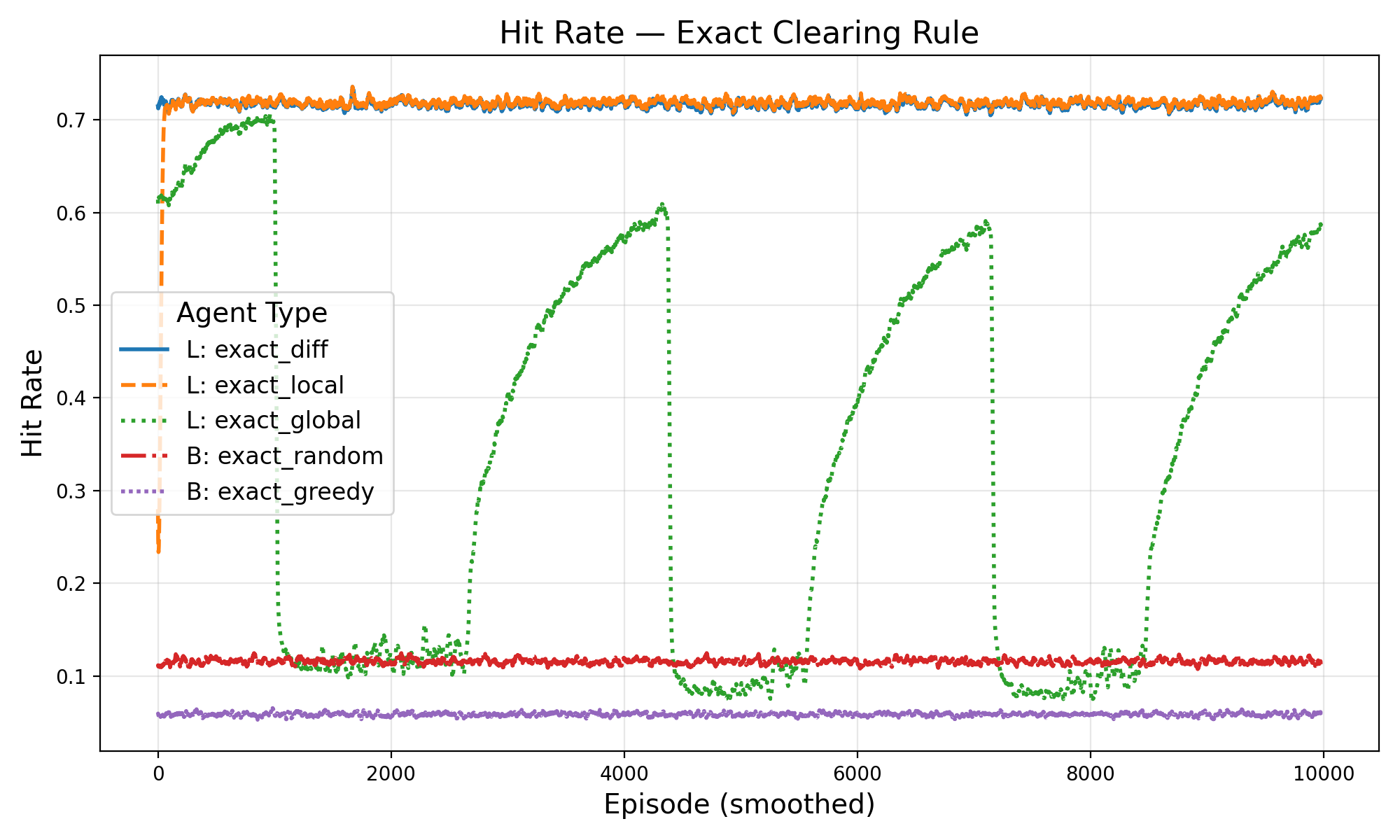
두 번째 흐름인 Rational Swarms는 다중에이전트 강화학습 분야에서 차별 보상(difference reward)이라는 메커니즘을 활용한다. 차별 보상은 개별 에이전트의 행동이 전체 시스템 성과에 미치는 순수한 기여도를 계산함으로써, 자기 이익과 전역 목표 사이의 갈등을 최소화한다. 기존의 공동 보상(shared reward) 방식은 ‘귀속 문제’(credit assignment problem)로 인해 학습 효율이 급격히 저하되는 반면, 차별 보상은 각 에이전트가 자신의 행동이 전체 유동성에 미치는 직접적 영향을 인식하도록 만든다.
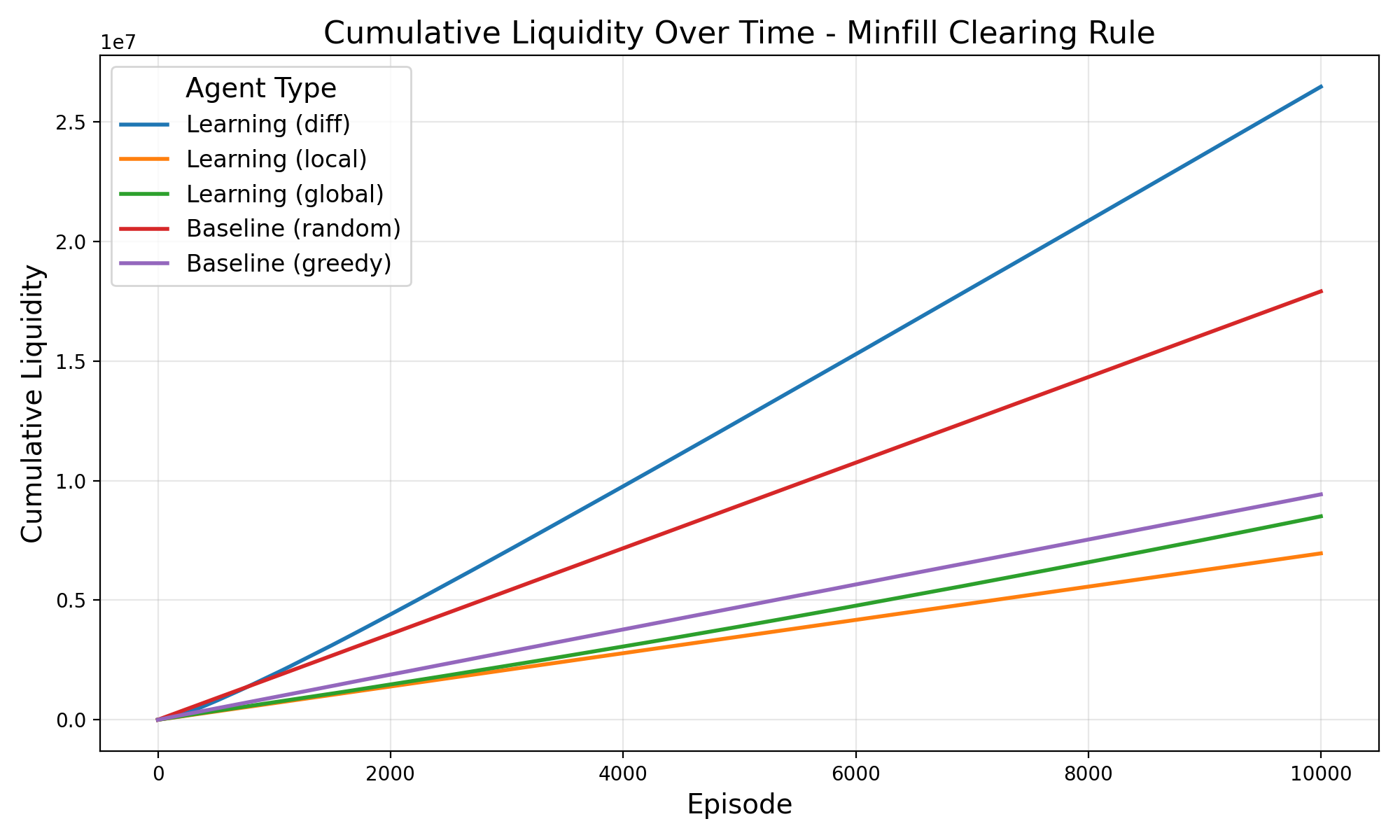
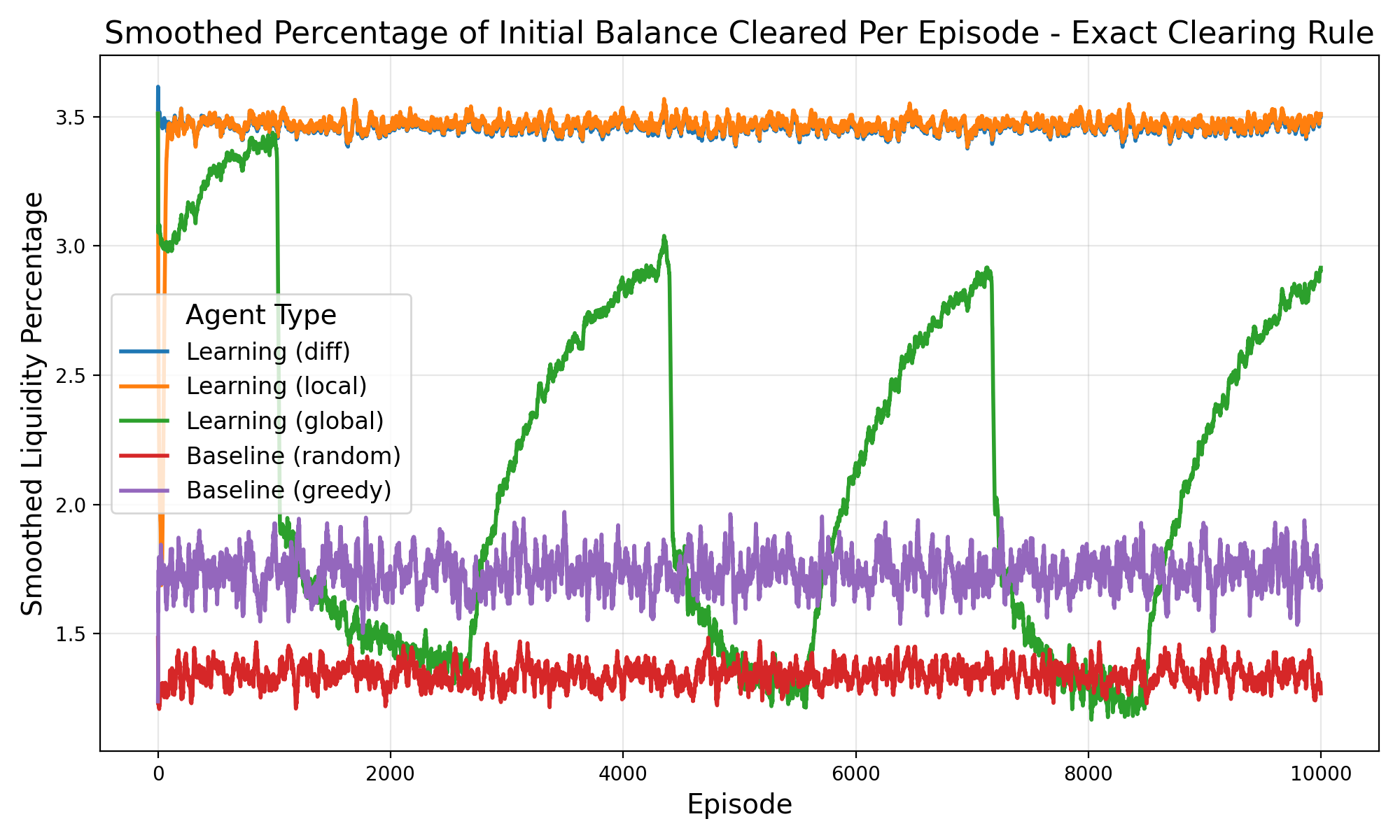
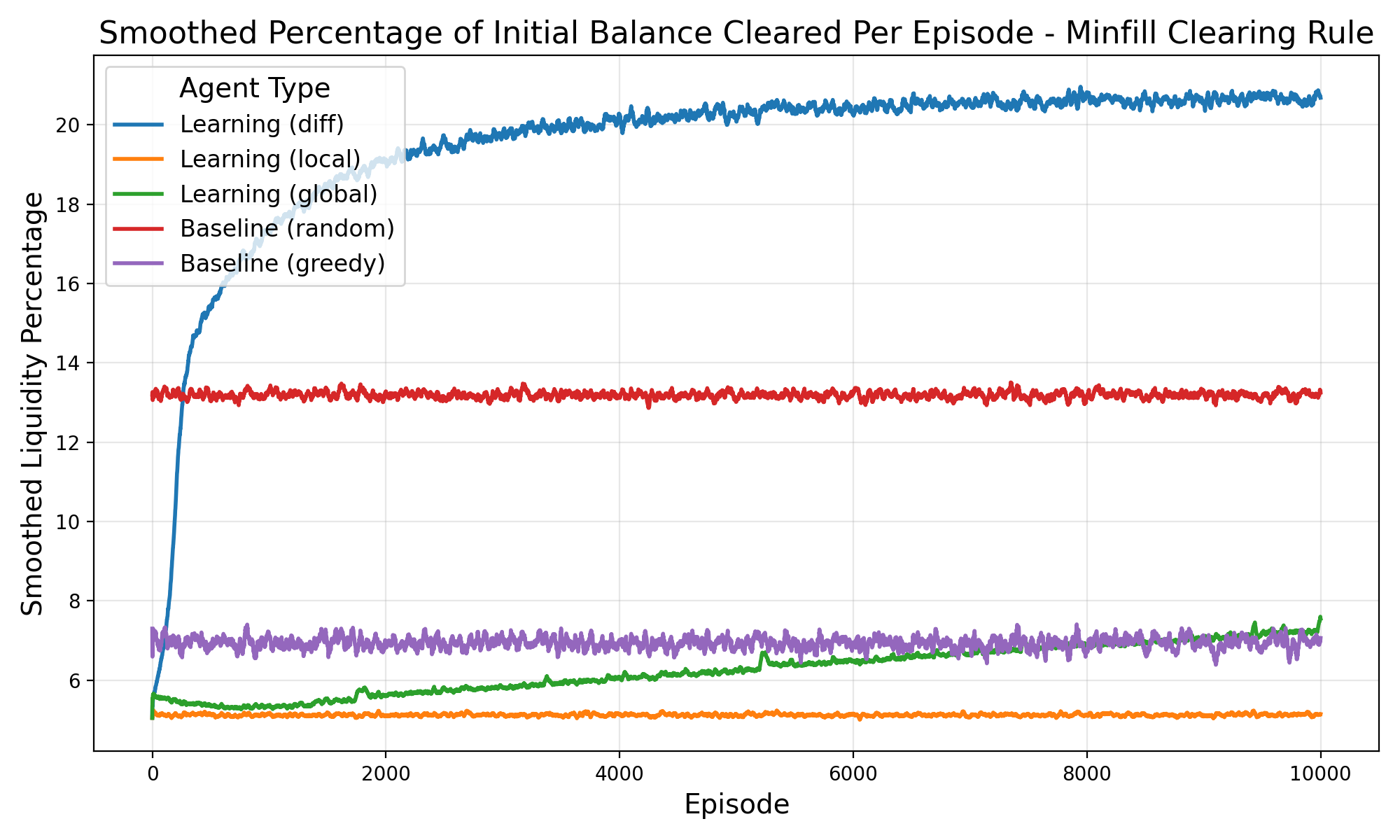
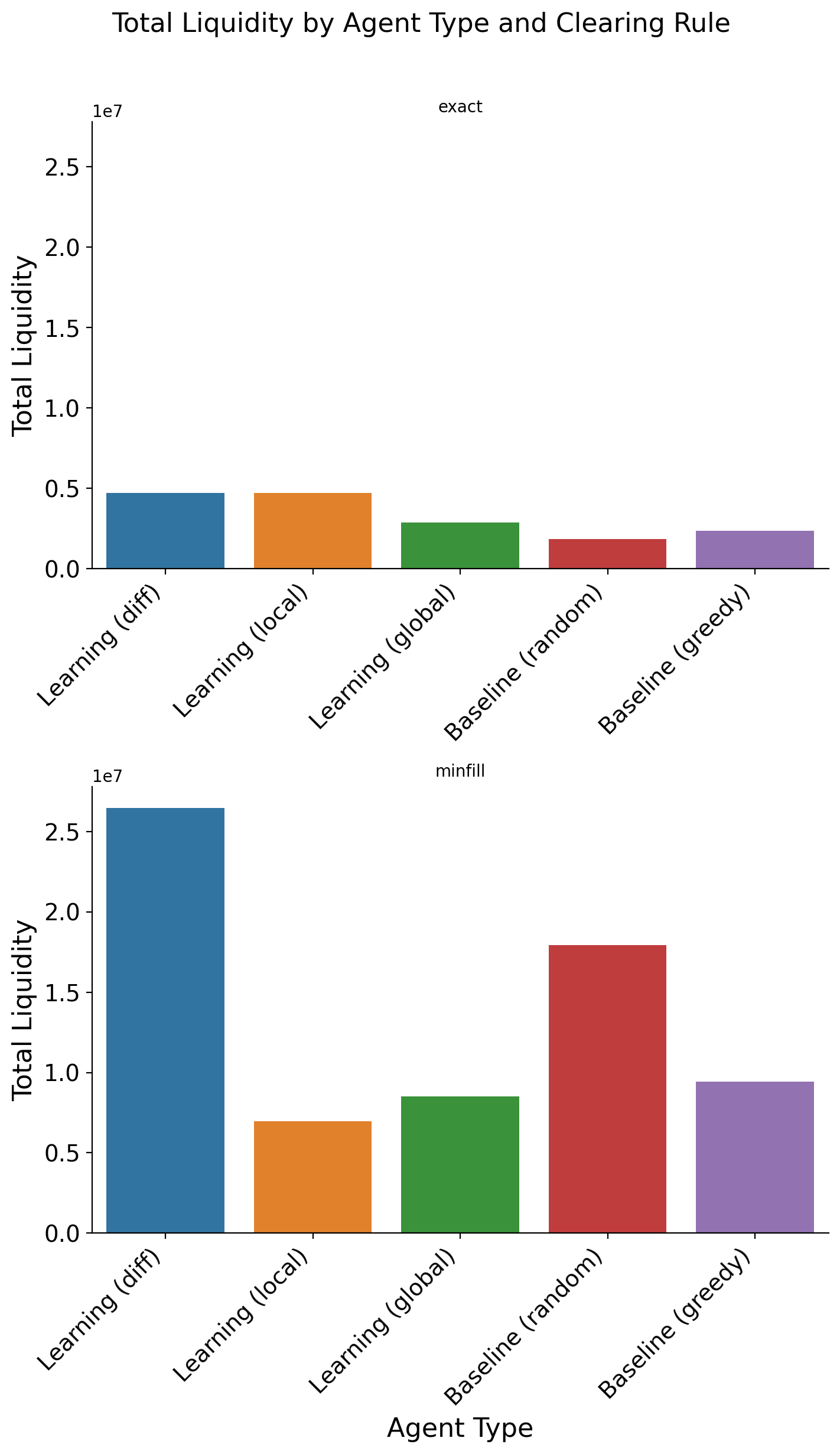
논문은 이 두 메커니즘을 마코프 팀 게임(Markov Team Games) 형태로 공식화한다. 여기서 상태는 시장의 현재 주문장 깊이와 가격 수준, 행동은 트레이더가 제시하는 매수·매도 가격 및 수량, 보상은 차별 보상 형태의 유동성 기여도로 정의된다. 중요한 점은 에이전트 간에 어떠한 직접적인 통신이나 협조 프로토콜이 존재하지 않음에도 불구하고, 차별 보상이 각 에이전트에게 ‘내가 이 거래를 더 유동성 있게 만들면 전체 보상이 얼마나 증가하는가’를 학습하게 만든다. 실험 결과는 이러한 설정이 개별 수익성을 유지하면서도 전체 시장 유동성을 크게 향상시킨다는 것을 보여준다.
이론적 기여 외에도 실증적 기여가 눈에 띈다. 저자는 합성 시장 시뮬레이션을 통해 전통적인 시장 메이커 전략과 비교했을 때, 차별 보상을 적용한 에이전트 집단이 스프레드 감소, 주문 실행 지연 감소, 그리고 가격 충격 흡수 능력에서 우수함을 입증한다. 특히, 에이전트가 독립적으로 학습함에도 불구하고 ‘자발적 협조’(emergent cooperation) 현상이 나타나는 점은 복잡계 이론과 금융 시장 설계 모두에 중요한 시사점을 제공한다.
하지만 몇 가지 한계도 존재한다. 첫째, 차별 보상의 계산은 전체 시스템의 보상을 필요로 하므로, 실제 고빈도 거래 환경에서는 실시간으로 보상을 추정하는 데 계산 비용이 크게 늘어날 수 있다. 둘째, 모델은 이진 거래(양방향 매수·매도)와 단일 자산에 국한되어 있어, 다자산 포트폴리오나 파생상품 시장으로의 확장은 추가적인 연구가 필요하다. 셋째, 에이전트가 동일한 학습 알고리즘을 공유한다는 가정은 실제 시장에서 다양한 전략과 시간 지연을 가진 참가자들을 충분히 반영하지 못한다.
향후 연구 방향으로는 (1) 차별 보상의 근사화 기법을 도입해 실시간 적용성을 높이는 방안, (2) 다중 자산 및 다중 시장 환경에서의 확장 모델링, (3) 이질적인 학습 알고리즘을 가진 에이전트 간의 상호작용을 고려한 이론적 분석이 제시될 수 있다. 또한, 정책 입안자 입장에서는 이러한 ‘자율적 유동성 제공’ 메커니즘을 규제 설계에 활용해, 인위적 시장 메이커 의존도를 낮추고 자연스러운 유동성 공급을 촉진할 수 있는 방안을 모색할 수 있다. 전반적으로 본 논문은 강화학습, 게임 이론, 그리고 금융 시장 미시구조를 연결하는 다리 역할을 수행하며, 향후 학제간 연구의 토대를 마련한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리