복잡도 기반 코드 임베딩
📝 원문 정보
- Title: Complexity-based code embeddings
- ArXiv ID: 2601.00924
- 발행일: 2026-01-01
- 저자: Rares Folea, Radu Iacob, Emil Slusanschi, Traian Rebedea
📝 초록 (Abstract)
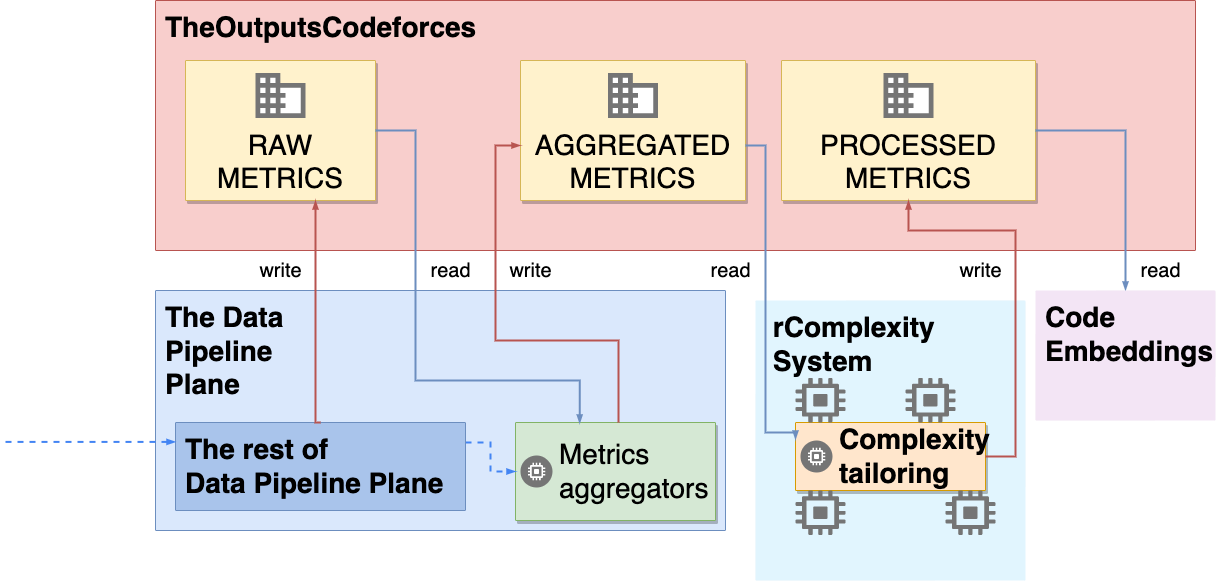
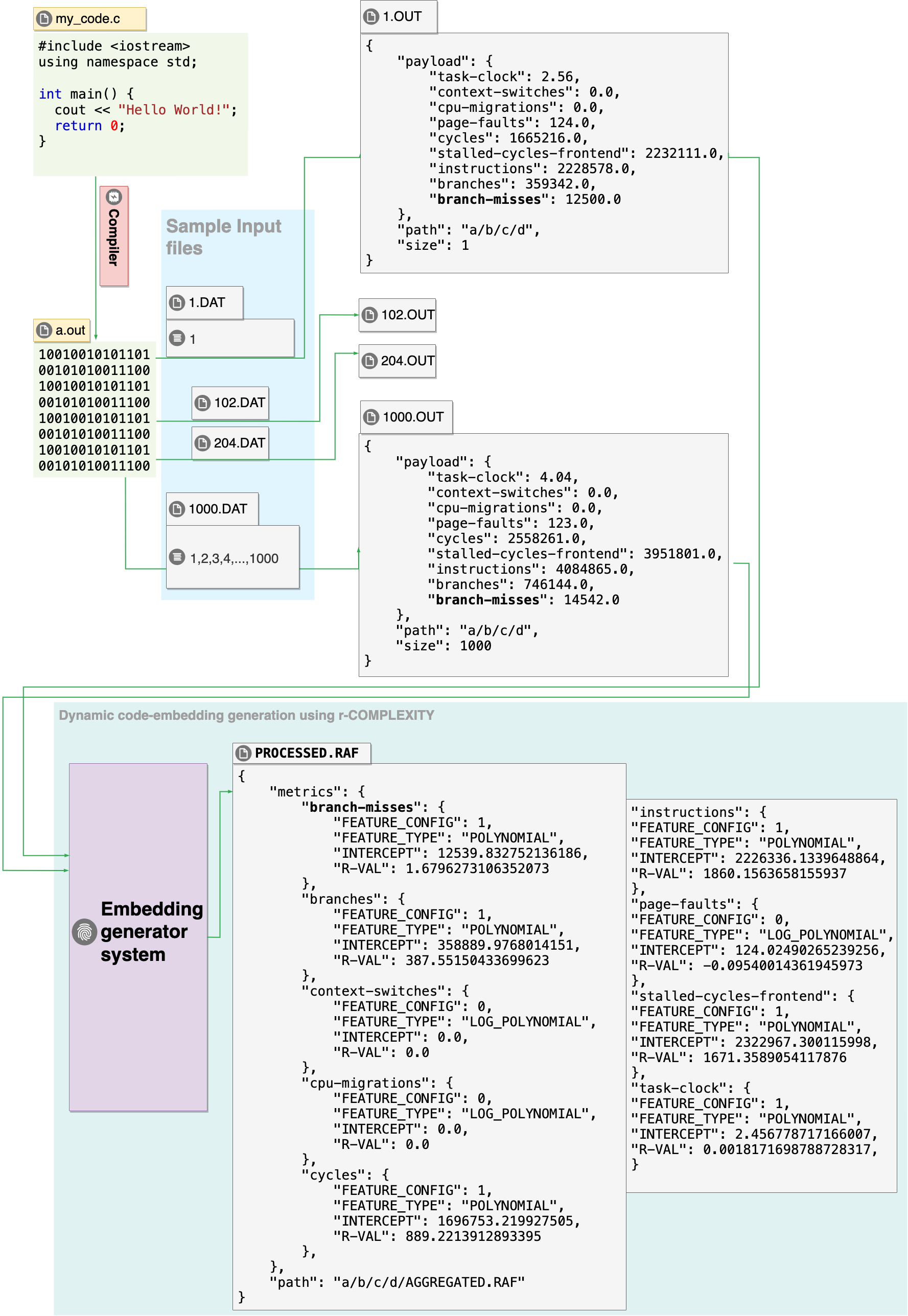
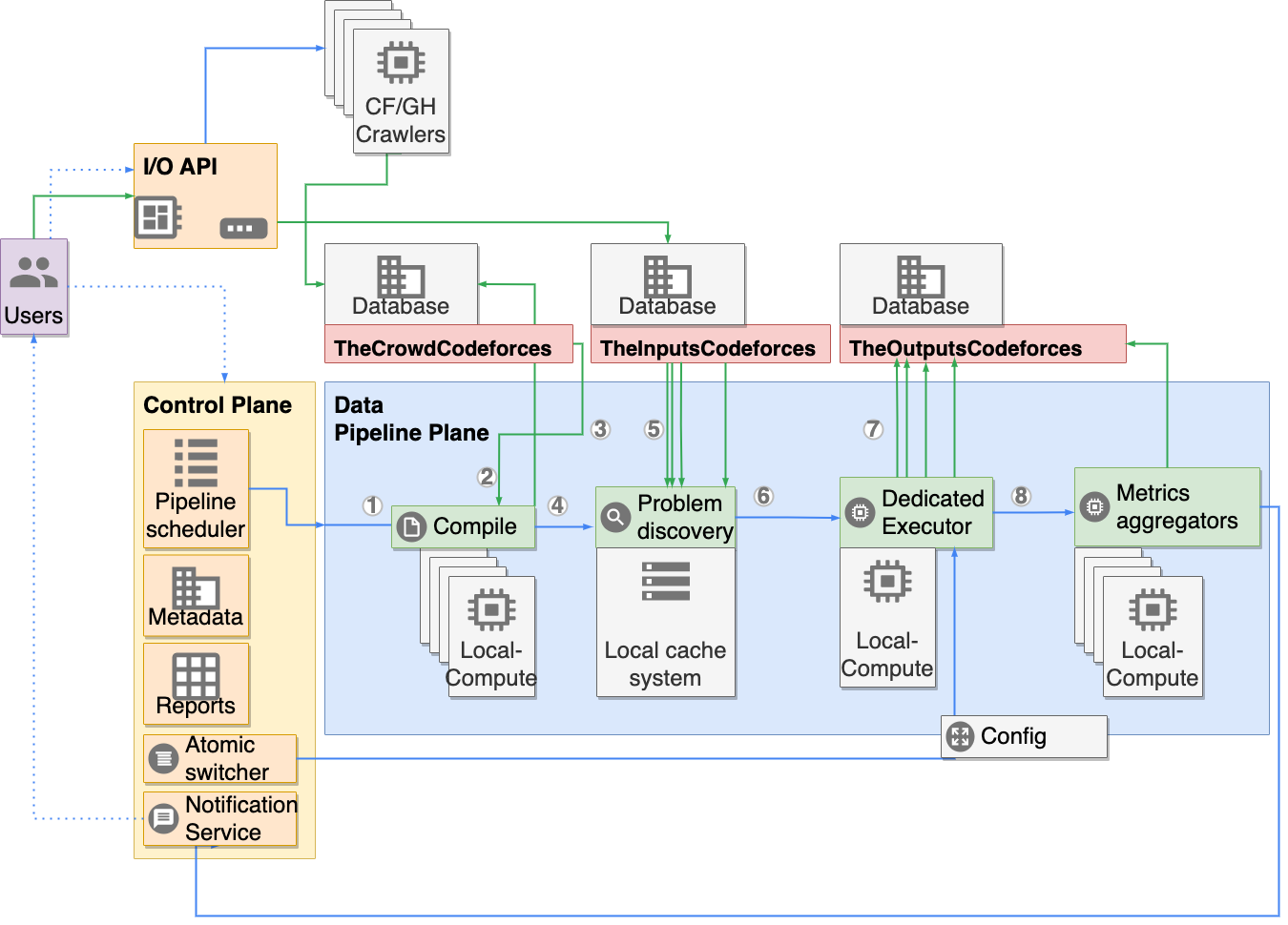
본 논문은 다양한 알고리즘의 소스 코드를 수치 임베딩으로 변환하는 일반화된 방법을 제시한다. 프로그램을 여러 입력에 대해 동적으로 실행하고, 분석된 메트릭에 대해 여러 일반 복잡도 함수를 맞춤 적용함으로써 코드의 행동을 정량화한다. 제안된 임베딩은 r-Complexity💡 논문 핵심 해설 (Deep Analysis)
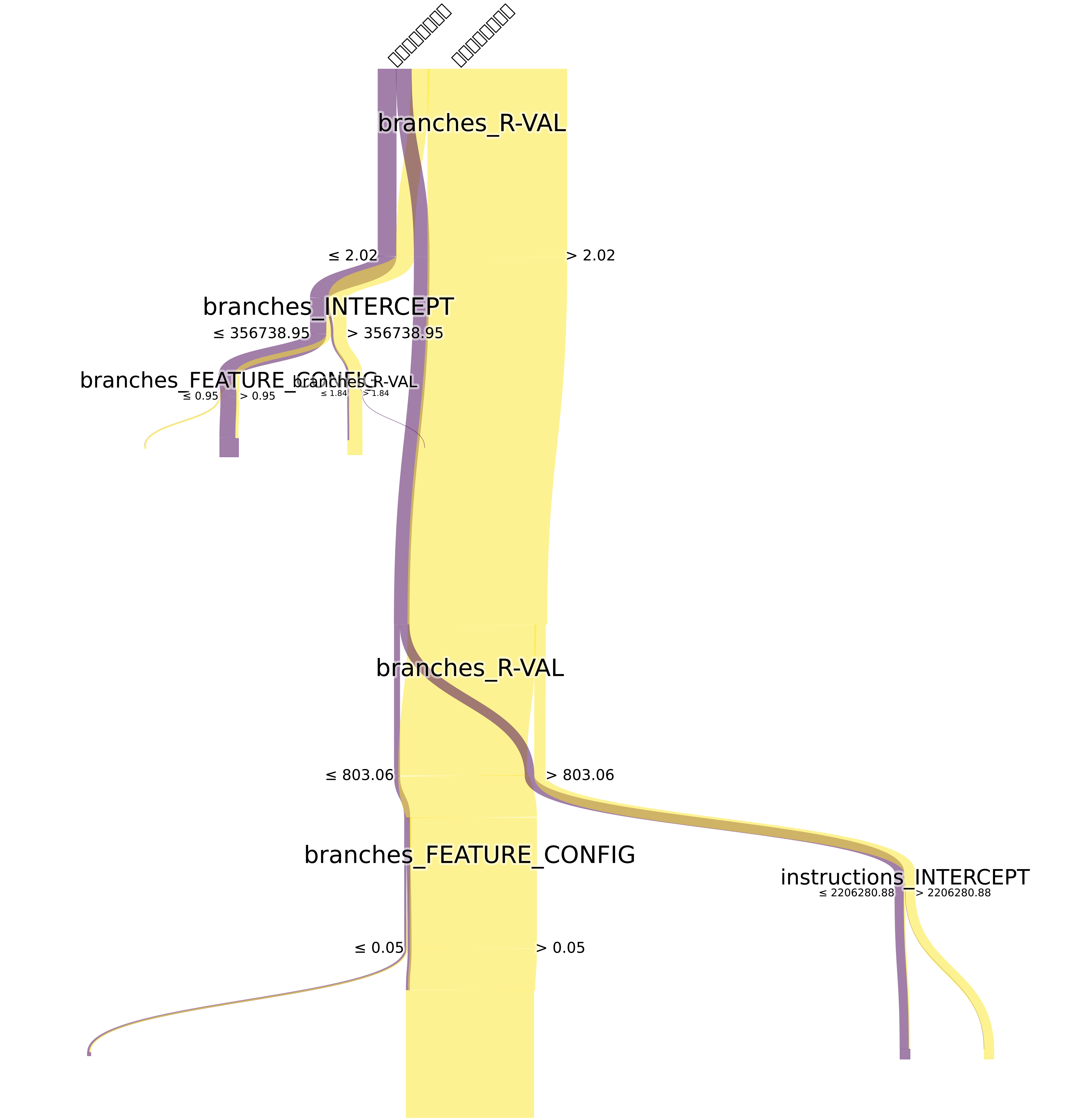
제안된 임베딩을 활용한 실험에서는 Codeforces에서 수집한 11개의 라벨을 가진 다중 라벨 데이터셋에 XGBoost를 적용하였다. XGBoost는 트리 기반 부스팅 모델로, 고차원 임베딩 공간에서도 과적합을 방지하면서 강력한 분류 성능을 발휘한다. 실험 결과 평균 F1‑score가 90 %에 달했으며, 이는 동일 데이터셋에 기존의 토큰‑기반 임베딩이나 AST‑기반 임베딩을 적용했을 때 얻은 성능(대략 75 %~80 %)보다 현저히 높은 수치이다. 이는 동적 복잡도 정보를 포함한 임베딩이 코드의 기능적·알고리즘적 차이를 더 잘 구분한다는 것을 시사한다.
또한, 논문은 r‑Complexity
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리