양자화가 대형 언어 모델의 자기설명을 방해할까 품질과 신뢰성 종합 평가
📝 원문 정보
- Title: Can Large Language Models Still Explain Themselves? Investigating the Impact of Quantization on Self-Explanations
- ArXiv ID: 2601.00282
- 발행일: 2026-01-01
- 저자: Qianli Wang, Nils Feldhus, Pepa Atanasova, Fedor Splitt, Simon Ostermann, Sebastian Möller, Vera Schmitt
📝 초록 (Abstract)
양자화는 대형 언어 모델(LLM)의 추론 속도를 높이고 배포를 간소화하는 데 널리 사용되지만, 자기설명(self‑explanations, SE) 품질에 미치는 영향은 아직 연구되지 않았다. SE는 모델이 스스로의 출력에 대해 이유를 제시하는 과정으로, 모델 자체의 의사결정 과정을 추론해야 하므로 양자화에 특히 민감할 수 있다. 본 연구는 세 가지 일반적인 양자화 기법을 서로 다른 비트 폭으로 적용한 LLM이 생성하는 두 종류의 SE, 즉 자연어 설명(NLE)과 반사실 예시(counterfactual examples)를 평가한다. 실험 결과, 양자화는 SE 품질을 최대 4.4%, 신뢰성을 최대 2.38% 감소시키는 것으로 나타났다. 사용자 연구에서는 양자화가 SE의 일관성 및 신뢰성을 최대 8.5%까지 저하시킨다는 점이 확인되었다. 규모가 큰 모델은 SE 품질 측면에서는 작은 모델에 비해 회복력이 제한적이지만, 신뢰성 측면에서는 더 잘 유지한다. 또한, 어떤 양자화 기법도 정확도, SE 품질, 신뢰성 모두에서 일관적으로 우수한 성능을 보이지 않았다. 양자화의 영향은 상황에 따라 다르므로, 특히 NLE와 같이 민감한 유형에 대해서는 사용 사례별로 SE 품질을 검증할 것을 권고한다. 전반적으로 SE 품질과 신뢰성의 감소가 비교적 미미하므로, 양자화는 모델 압축 기술로서 여전히 효과적이다.💡 논문 핵심 해설 (Deep Analysis)
실험 설계는 세 가지 대표적인 양자화 기법(정적 정밀도 감소, 동적 범위 조정, 혼합 정밀도)과 각각 8‑bit, 4‑bit, 2‑bit의 비트 폭을 조합한 9가지 설정을 포함한다. 이러한 다변량 설계는 양자화 강도와 방법론이 SE에 미치는 차별적 효과를 구분할 수 있게 한다. 모델은 규모가 다른 두 그룹(소형 7B, 대형 70B)으로 나뉘어 평가되었으며, 이는 모델 크기가 양자화에 대한 내성에 어떤 역할을 하는지 탐색하기 위함이다.
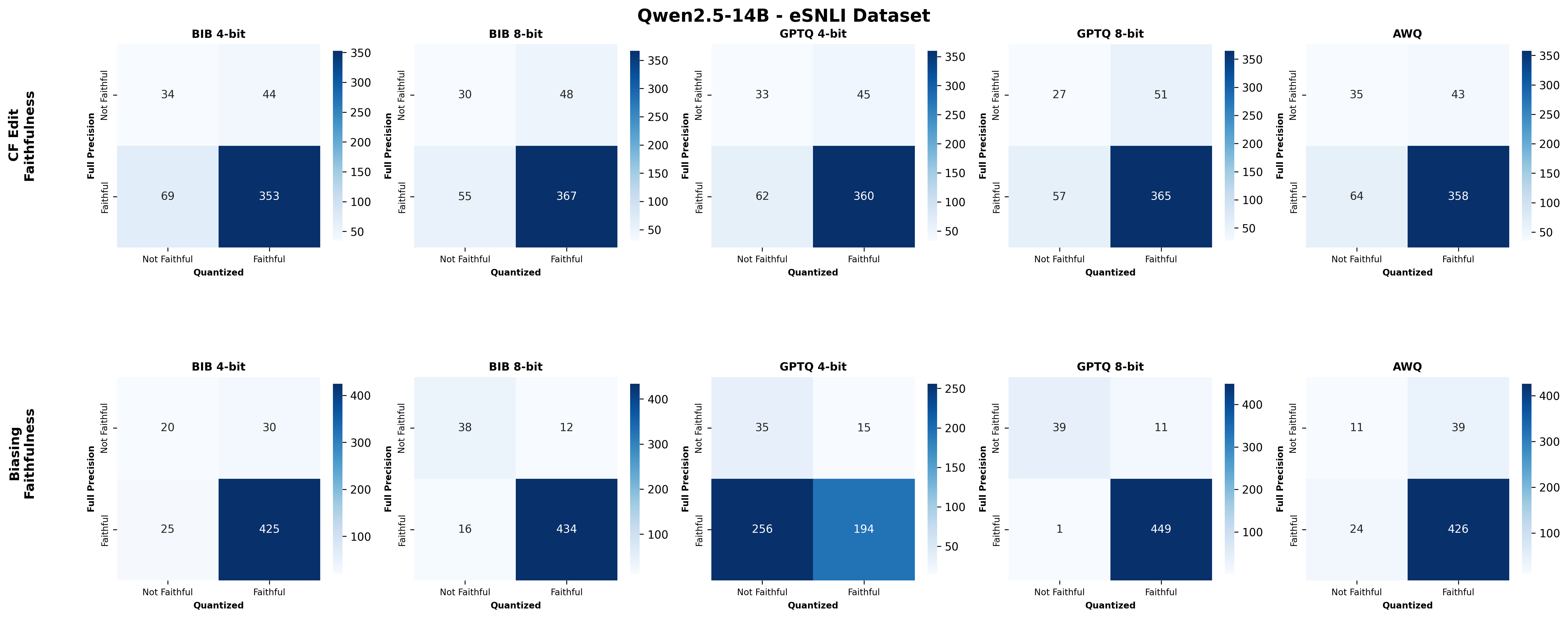
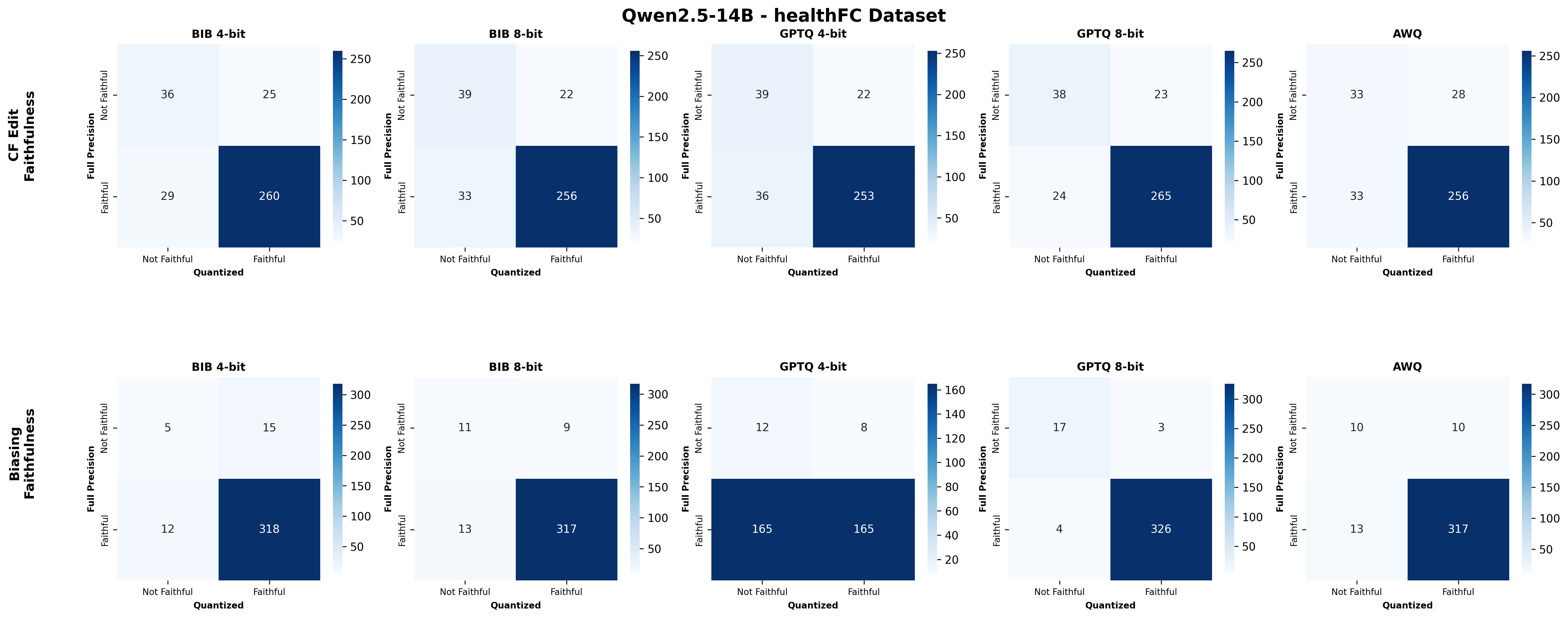
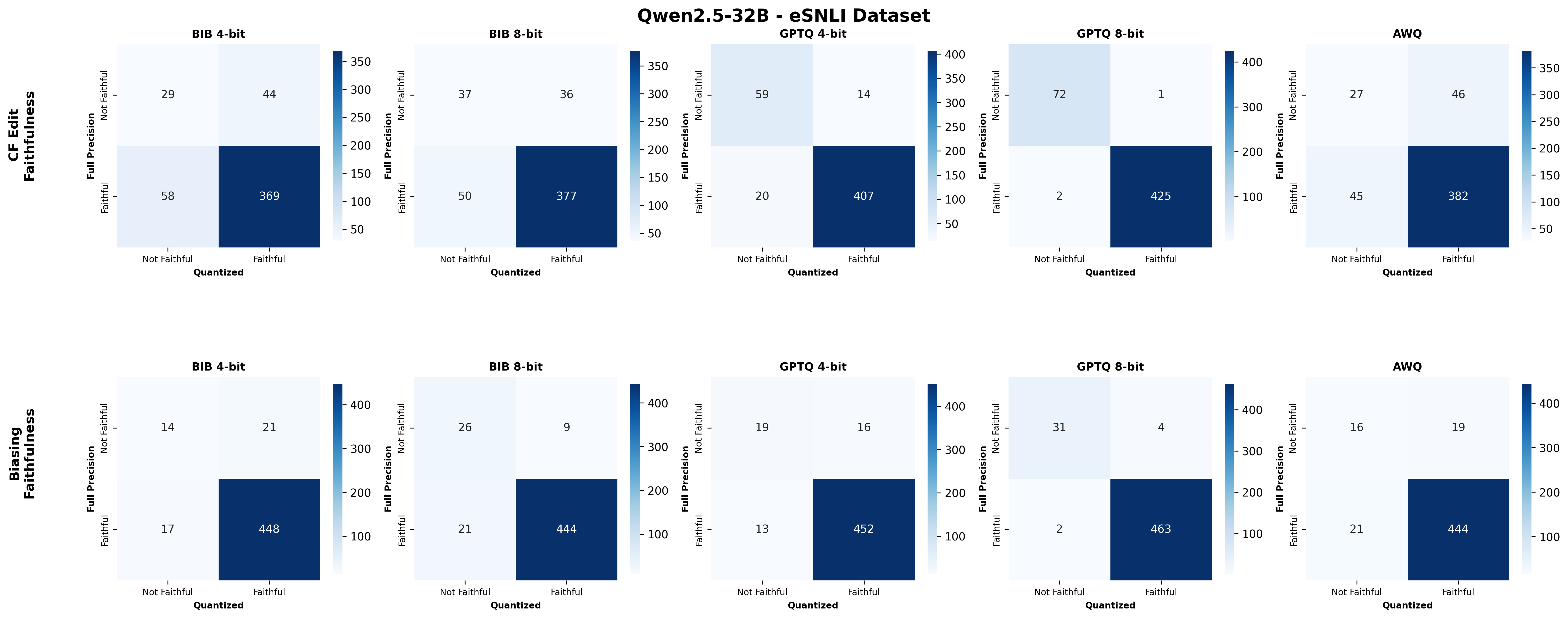
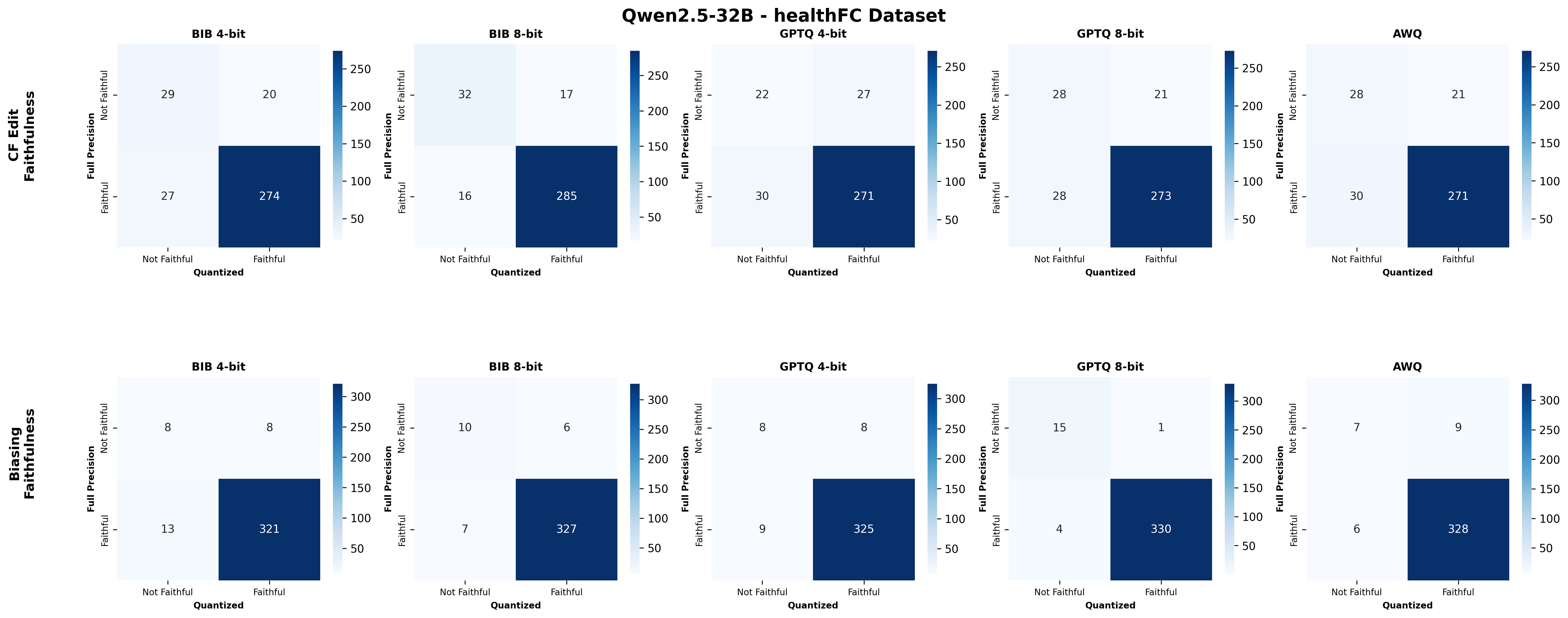
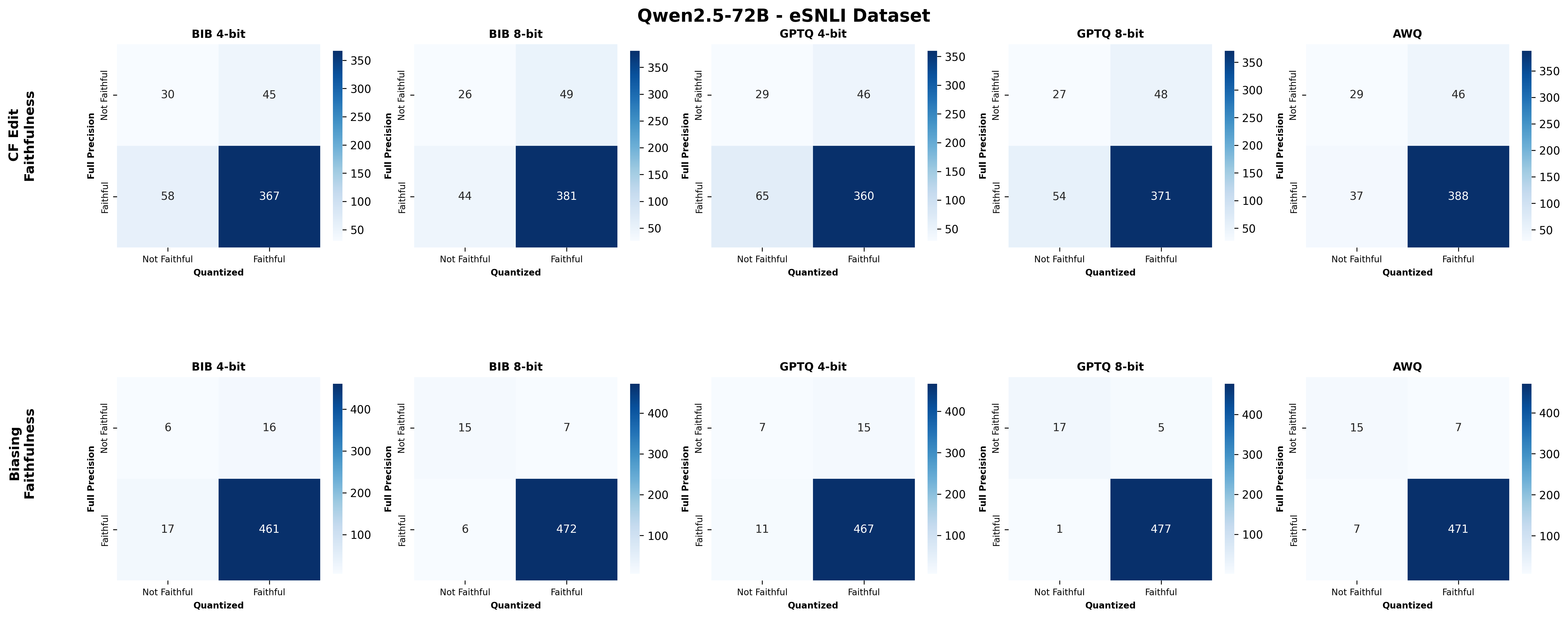
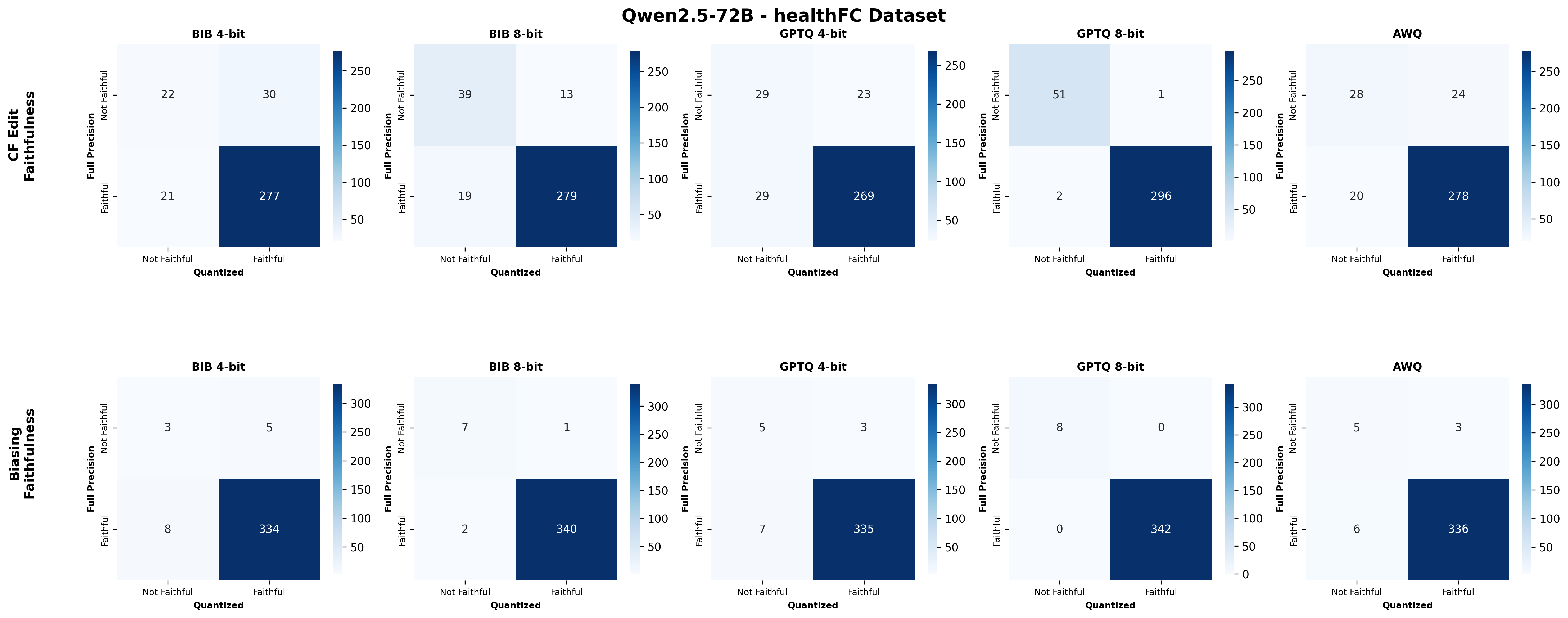
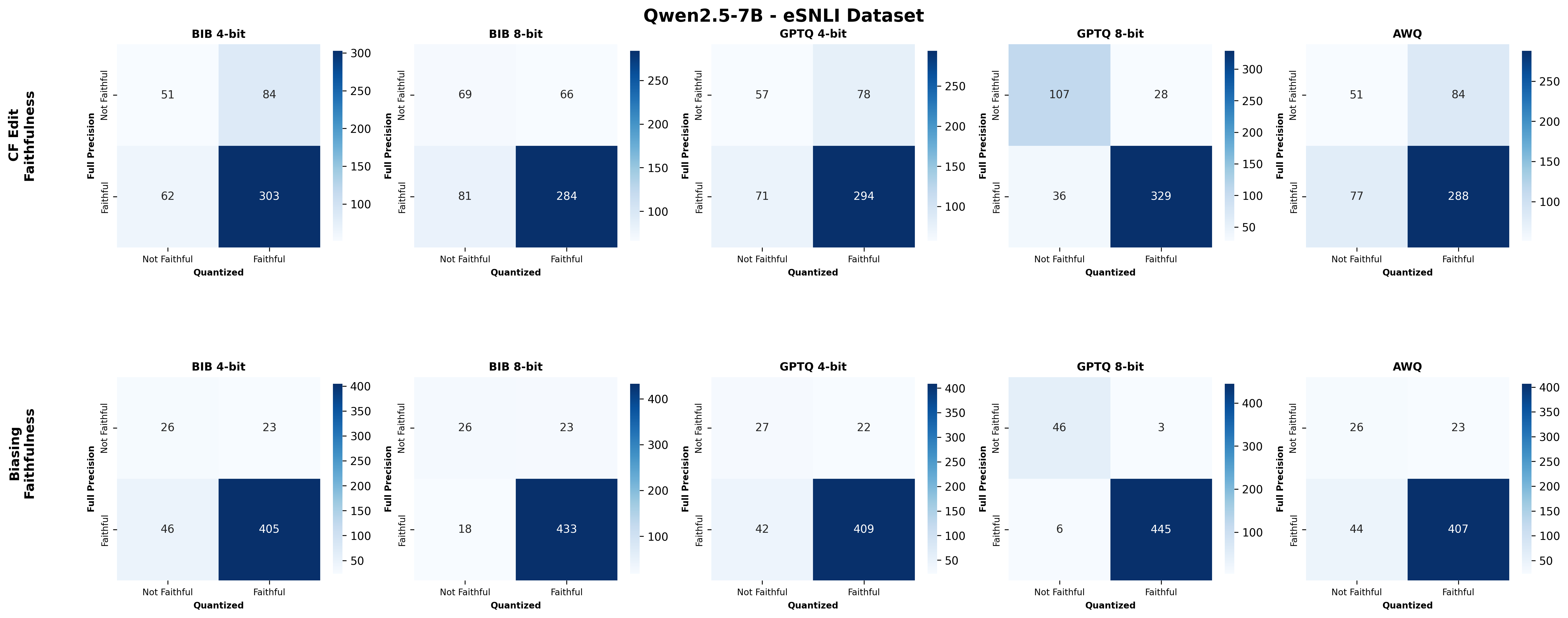
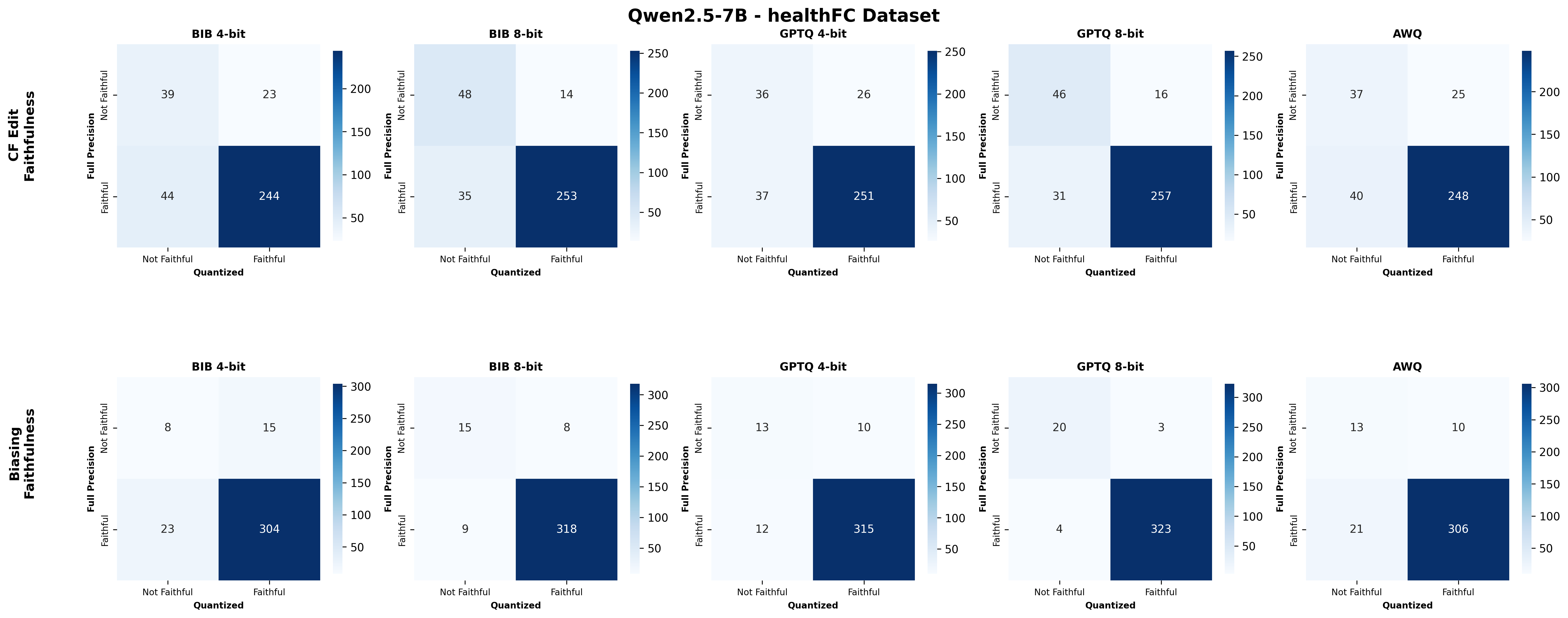
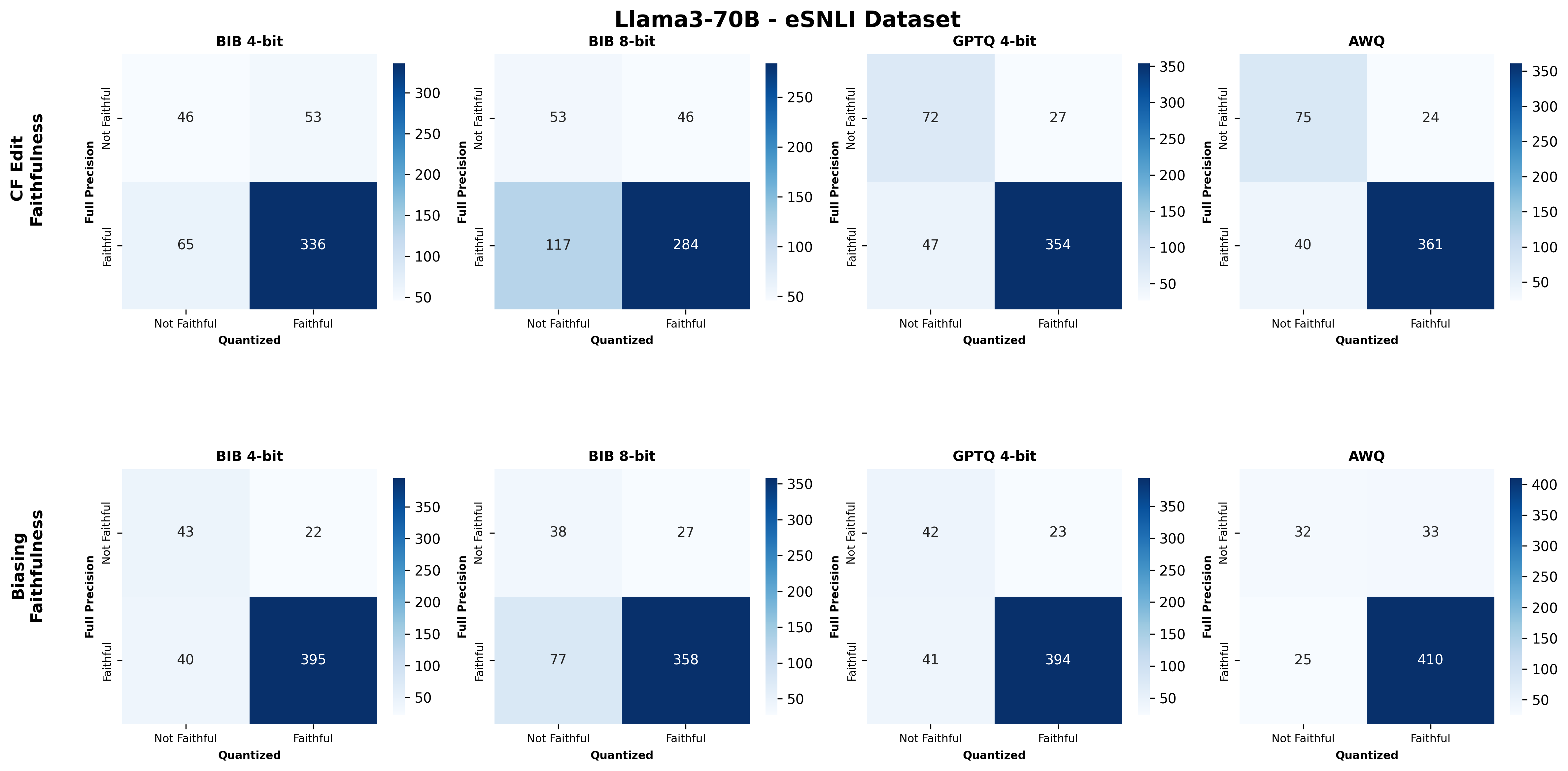
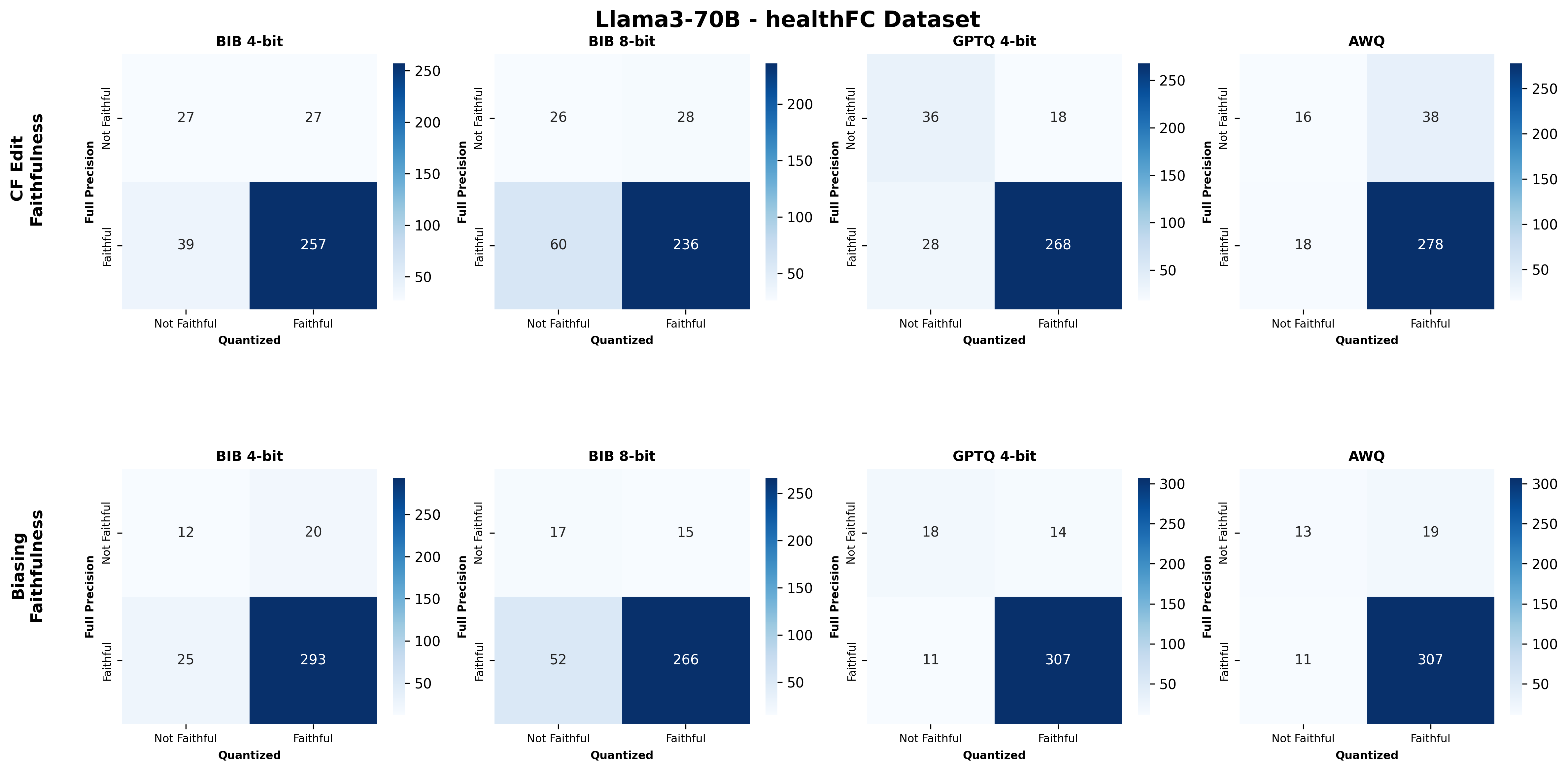
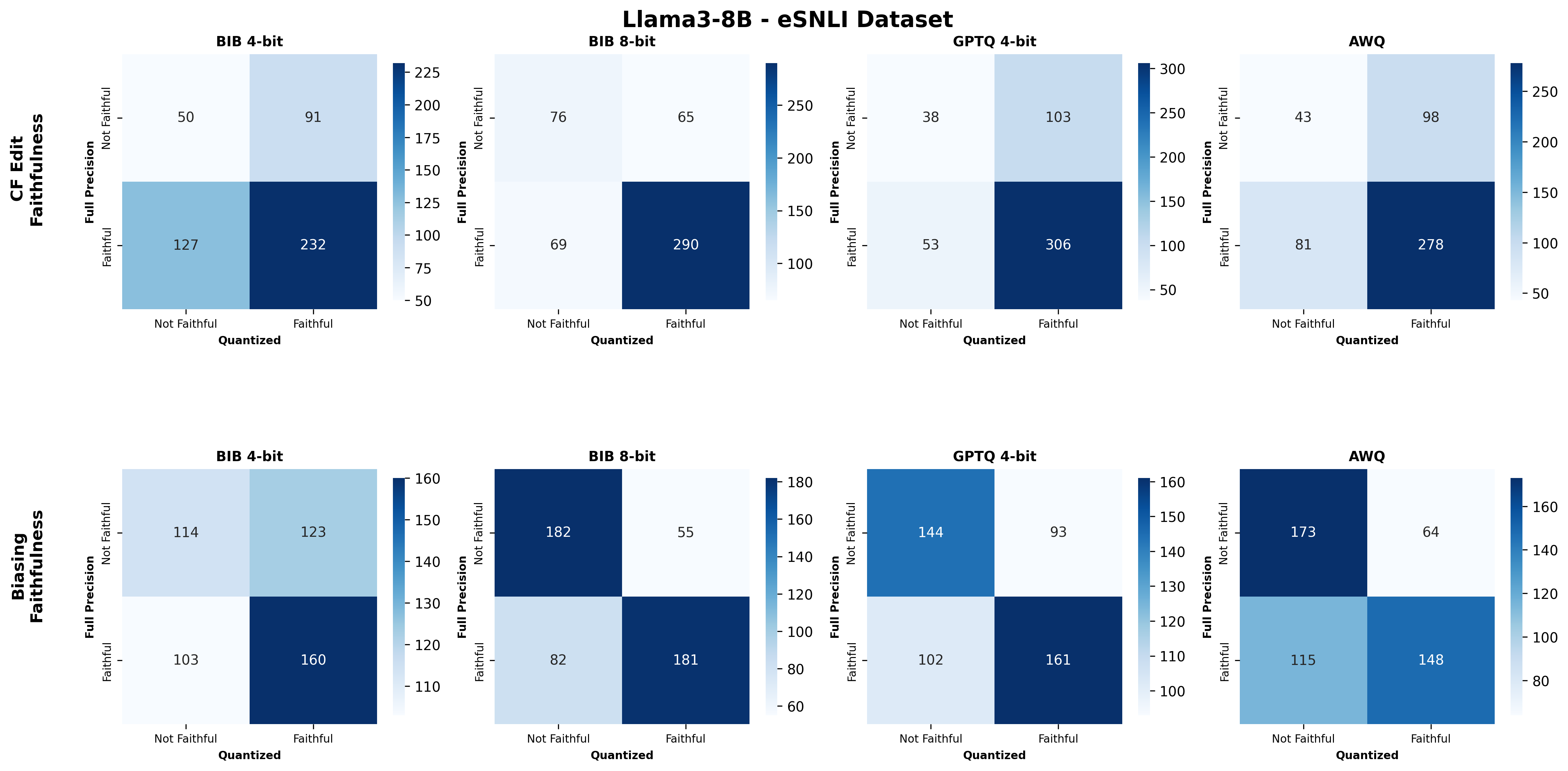
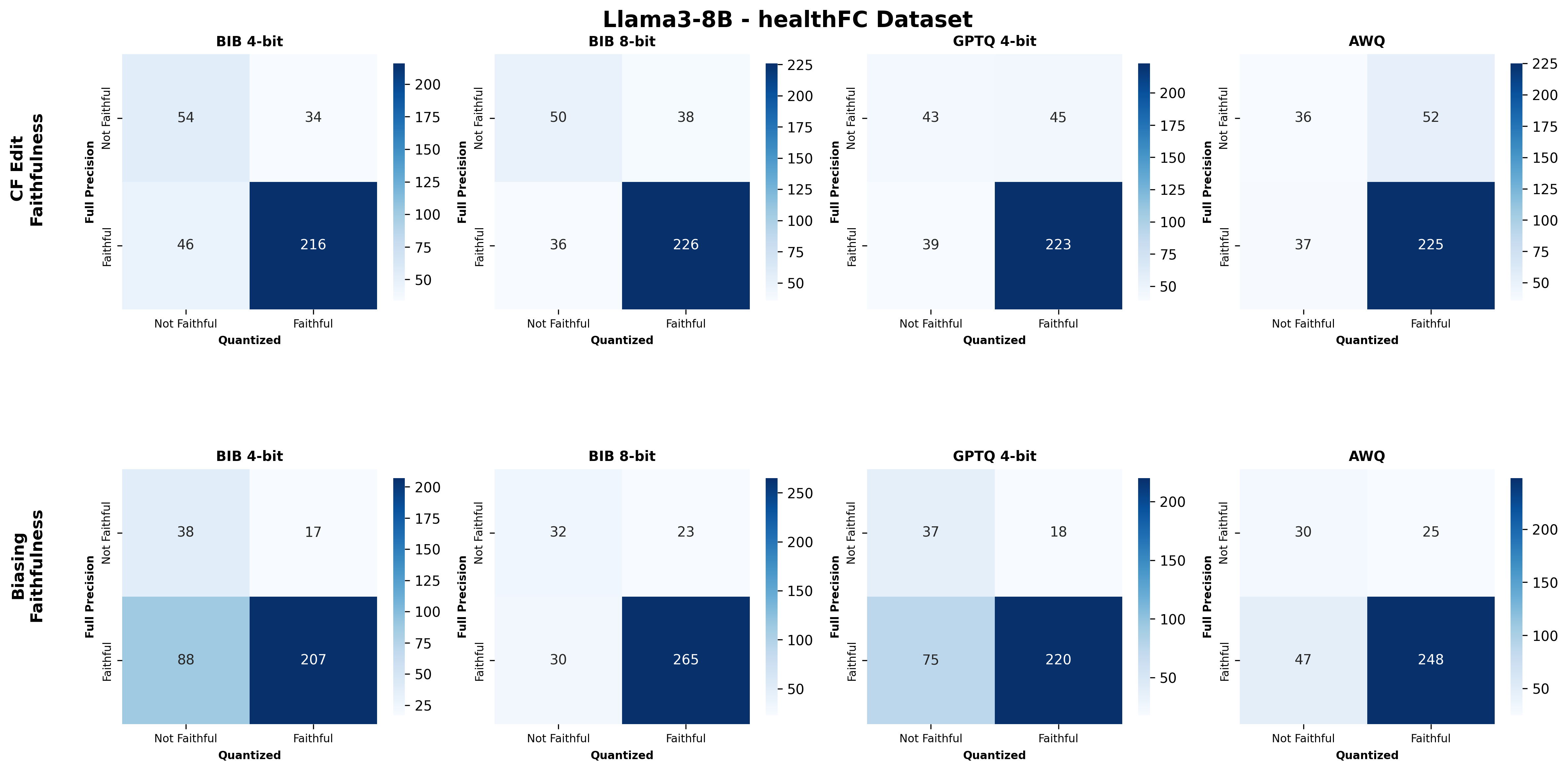
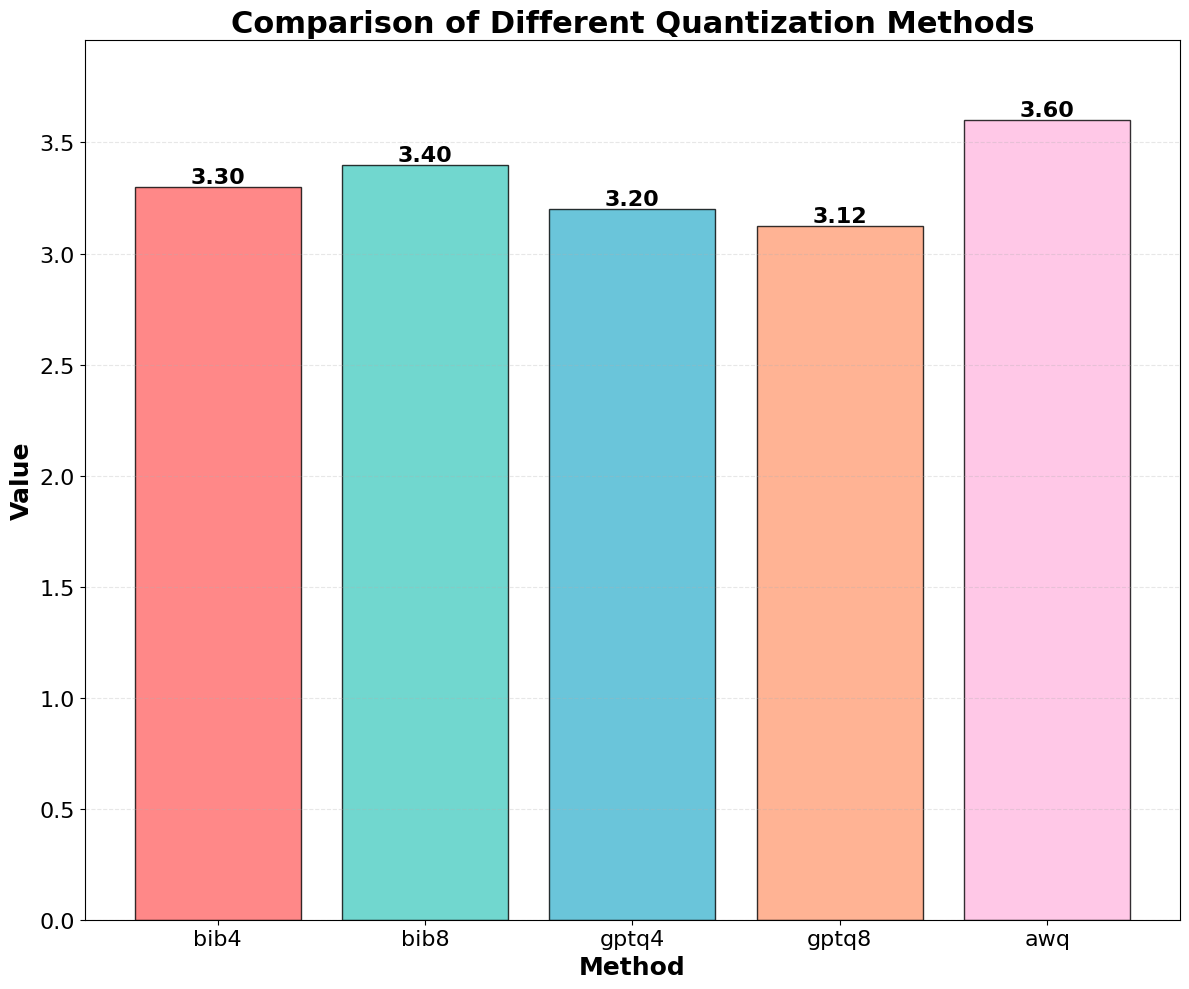
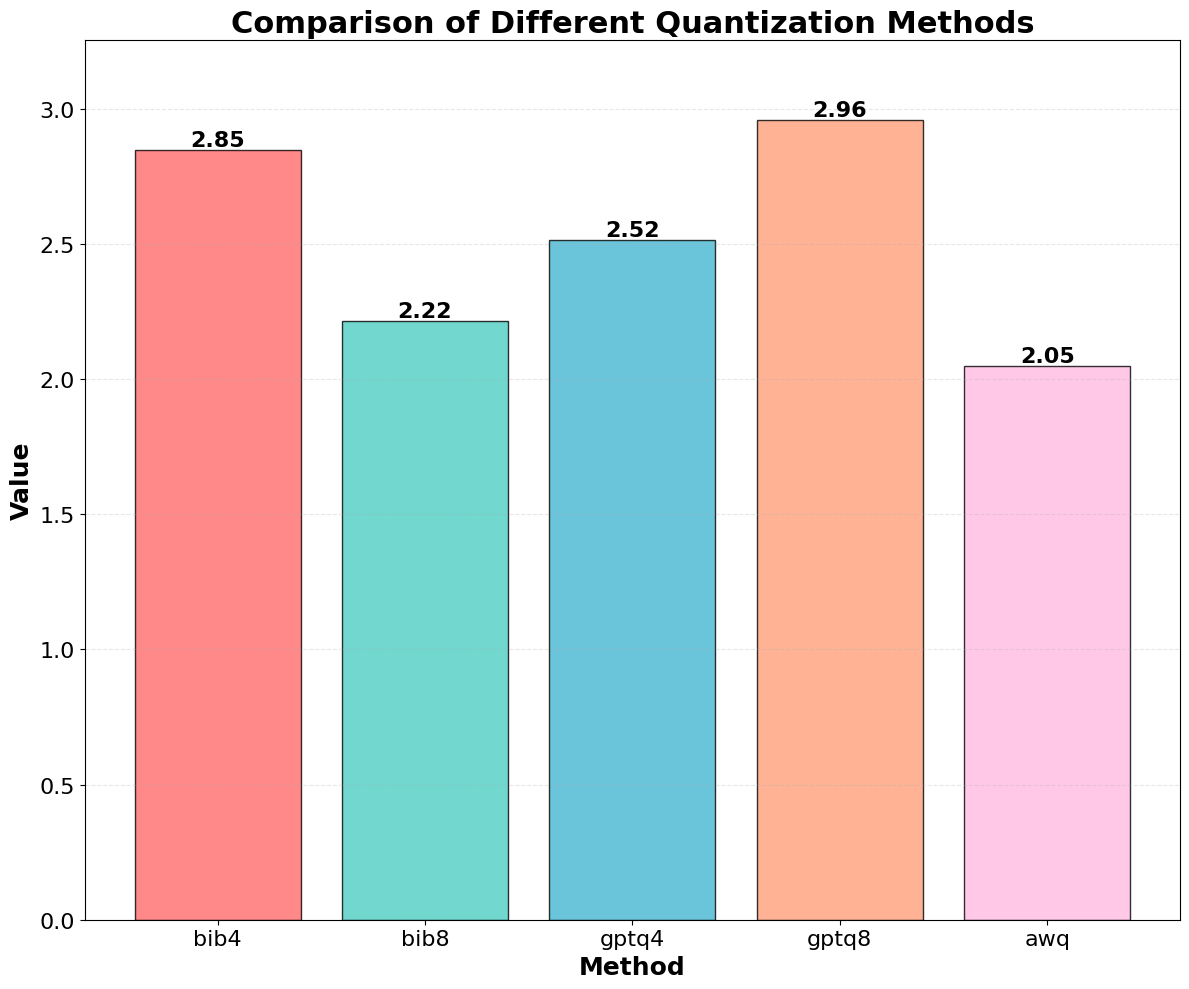
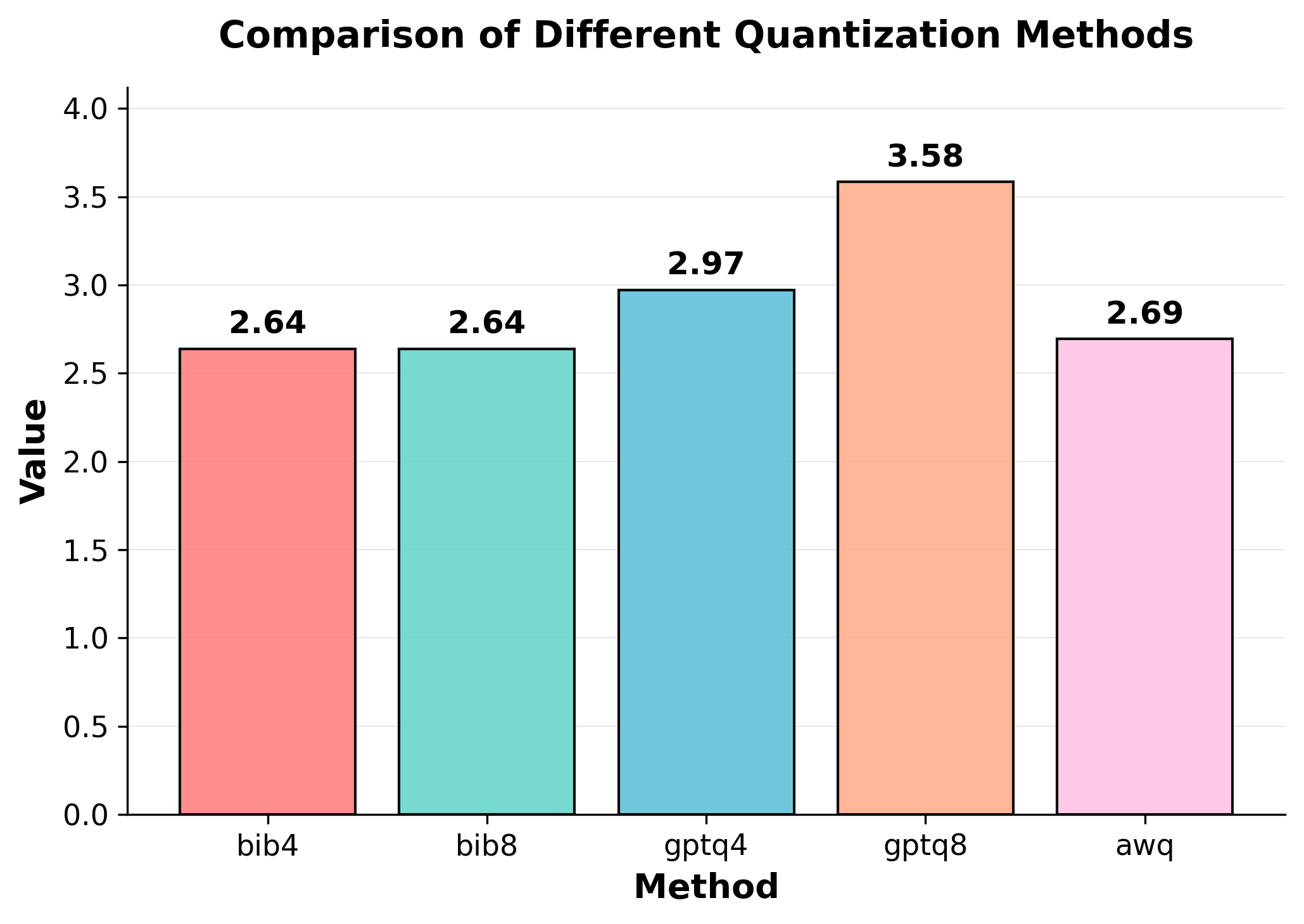
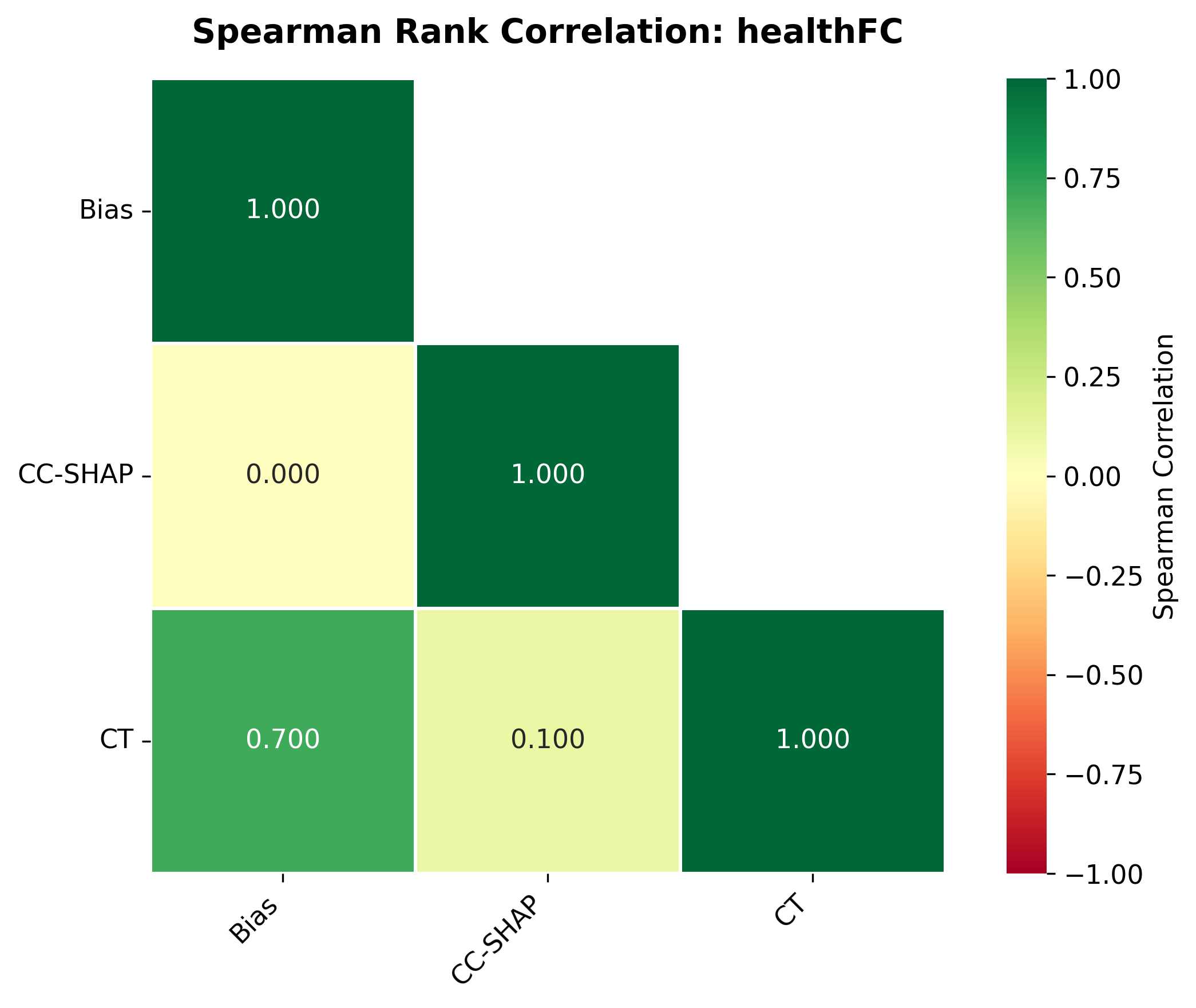
주요 결과는 다음과 같다. 첫째, 양자화는 전반적으로 SE 품질을 최대 4.4% 감소시켰으며, 이는 특히 NLE에서 두드러졌다. NLE는 언어적 유창성과 논리적 일관성을 동시에 요구하기 때문에, 비트 폭이 낮아질수록 미세한 가중치 손실이 문맥 파악에 영향을 미쳐 설명이 흐트러지는 경향이 있었다. 반면, 반사실 예시는 비교적 구조화된 형식(입력‑출력 쌍)으로 제시되므로 품질 저하가 상대적으로 적었다.
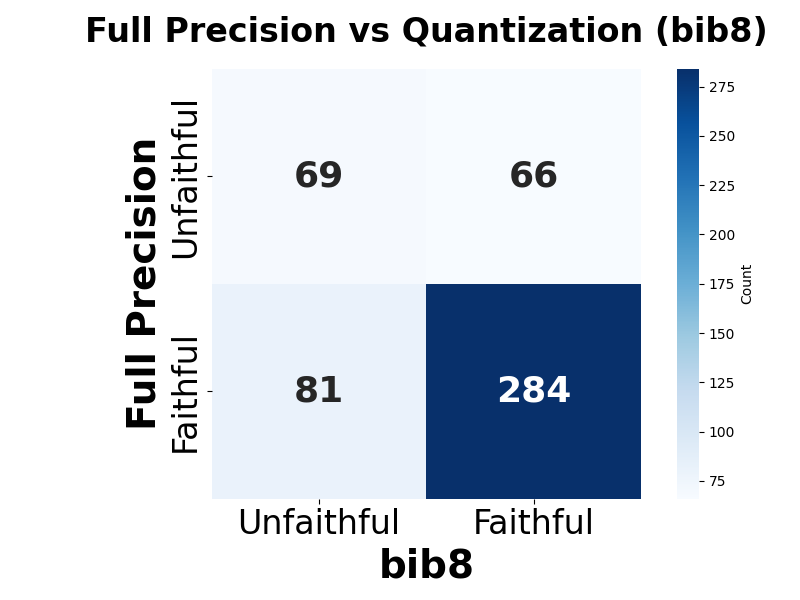
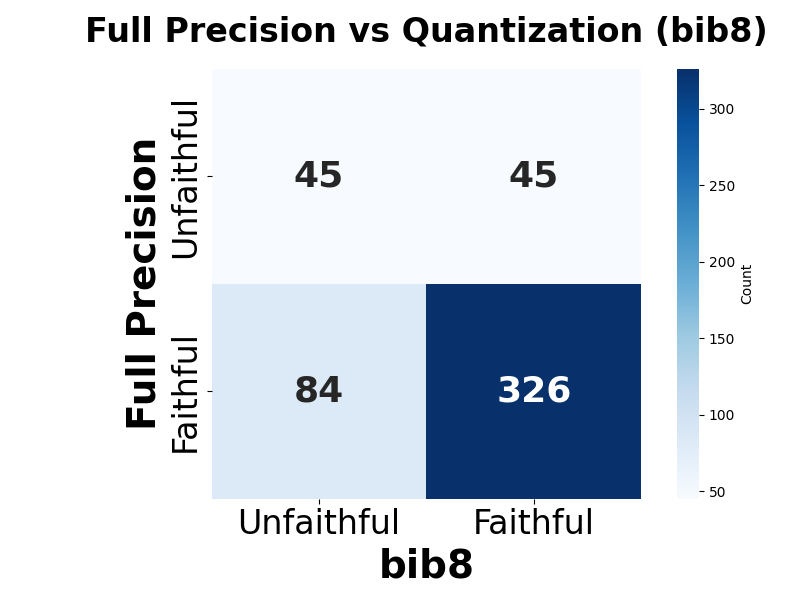
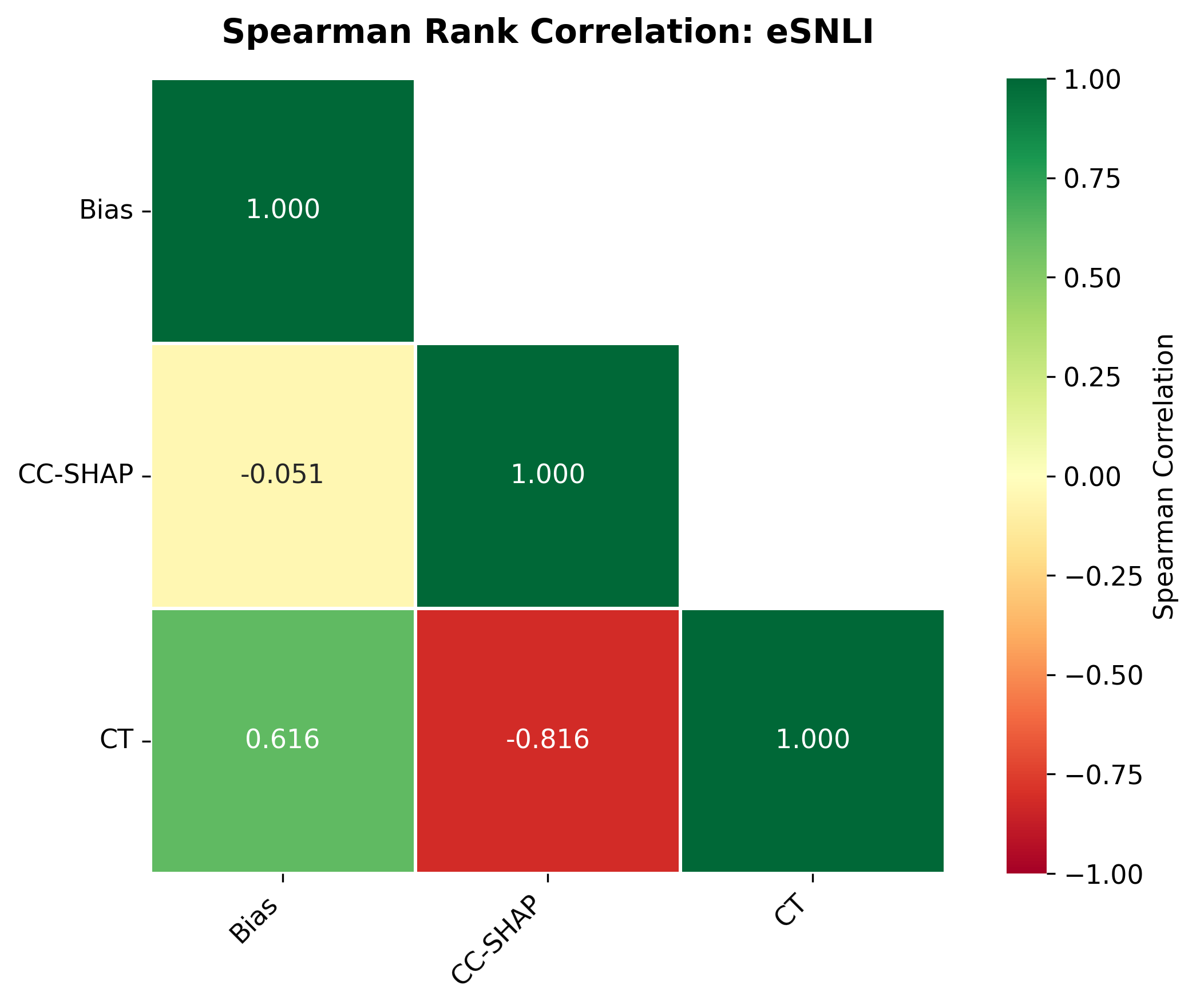
둘째, 신뢰성(faithfulness) 측면에서는 최대 2.38% 감소가 관찰되었다. 신뢰성 평가는 모델이 제시한 설명이 실제 내부 추론 경로와 일치하는지를 측정하는데, 양자화가 가중치와 활성값을 근사함에 따라 내부 토큰 흐름이 변형될 수 있다. 특히 2‑bit 양자화에서는 일부 레이어에서 정보 손실이 급격히 발생해, 설명이 실제 예측 근거와 불일치하는 경우가 늘어났다.
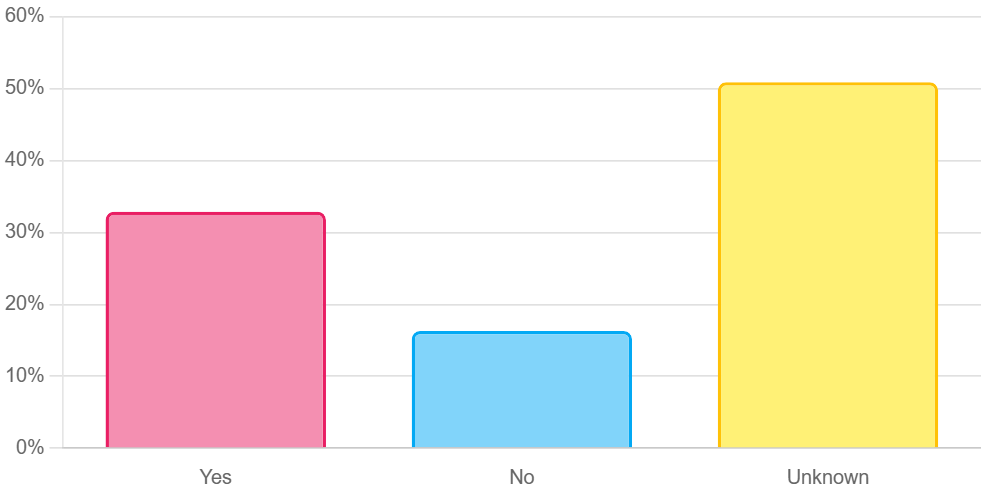
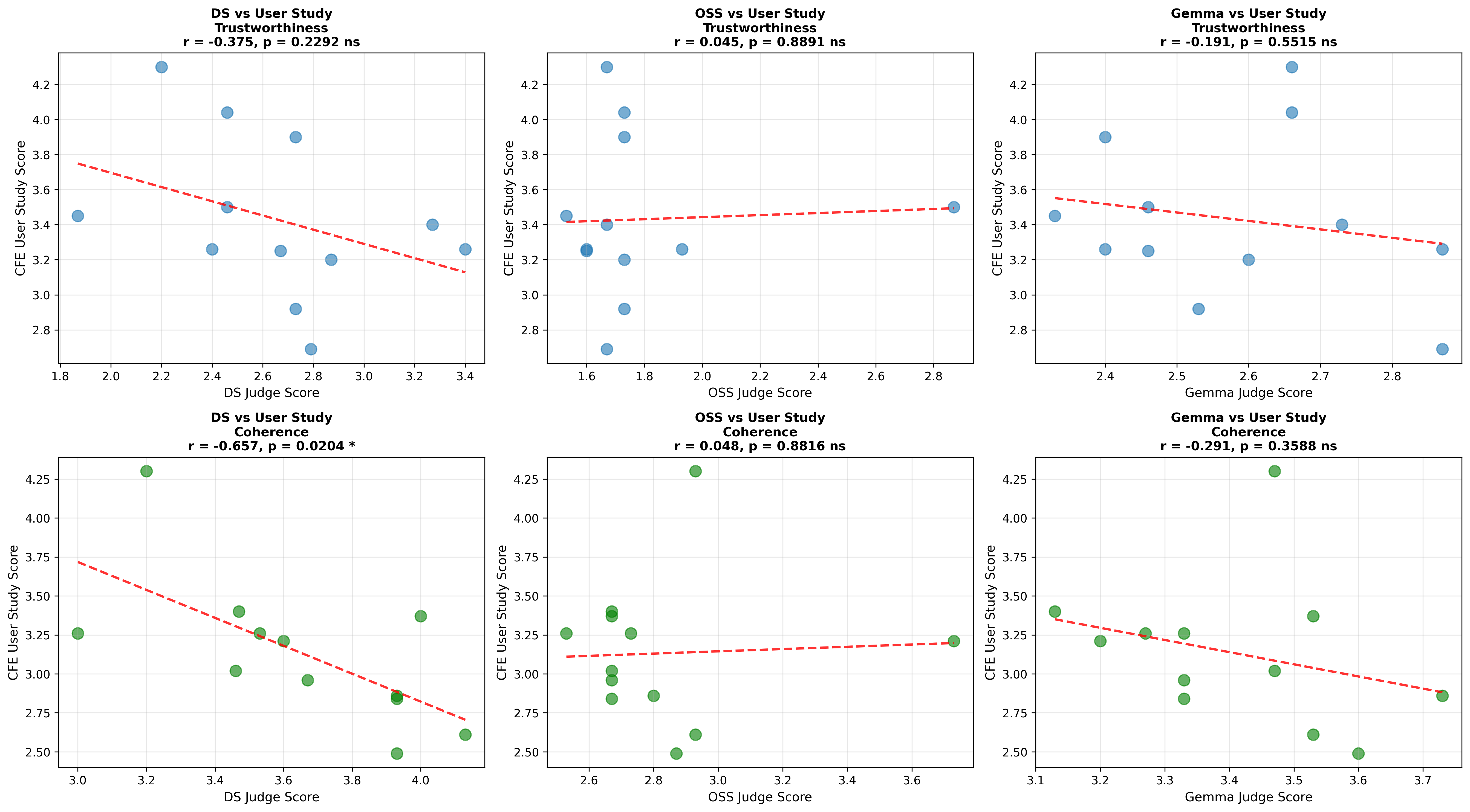
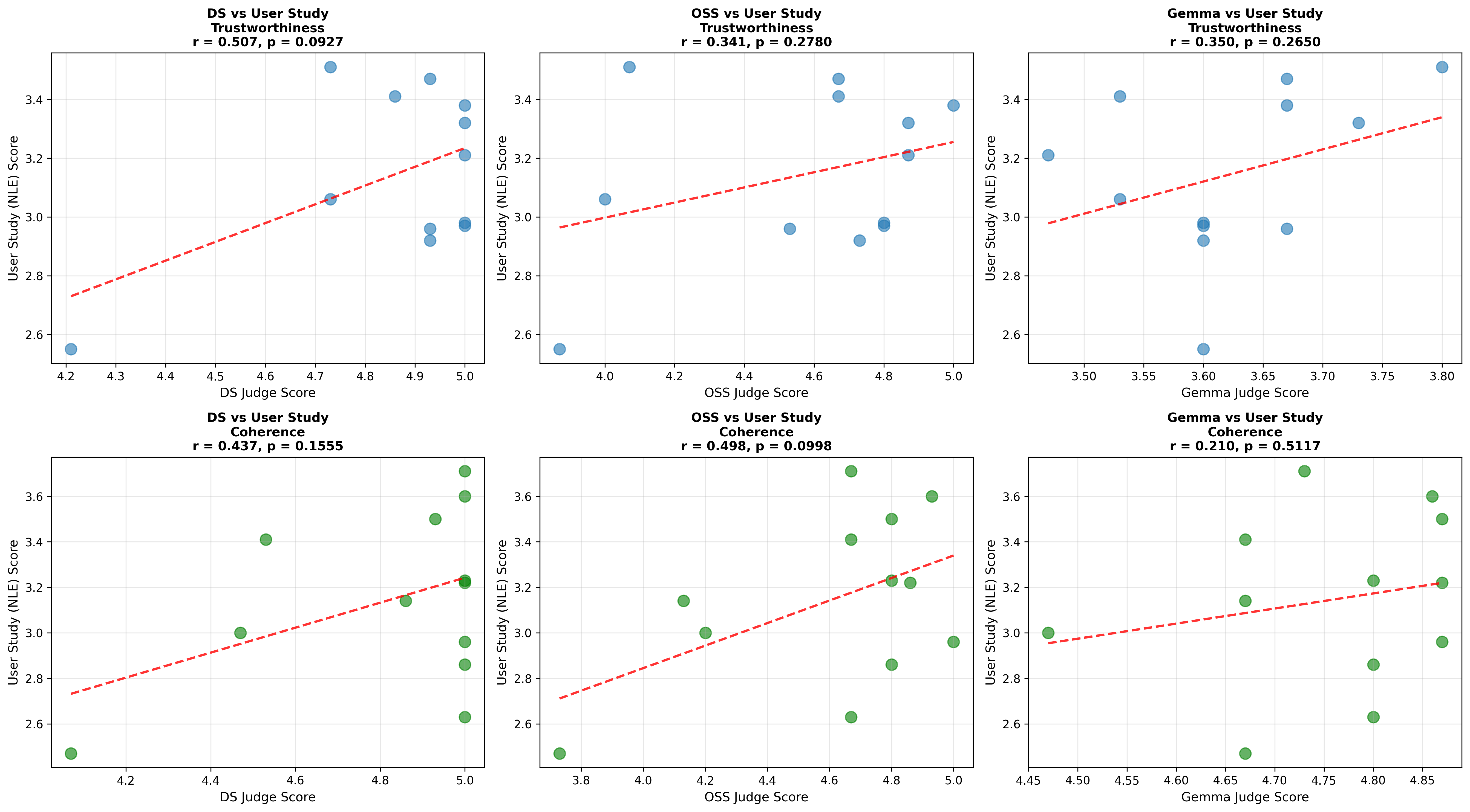
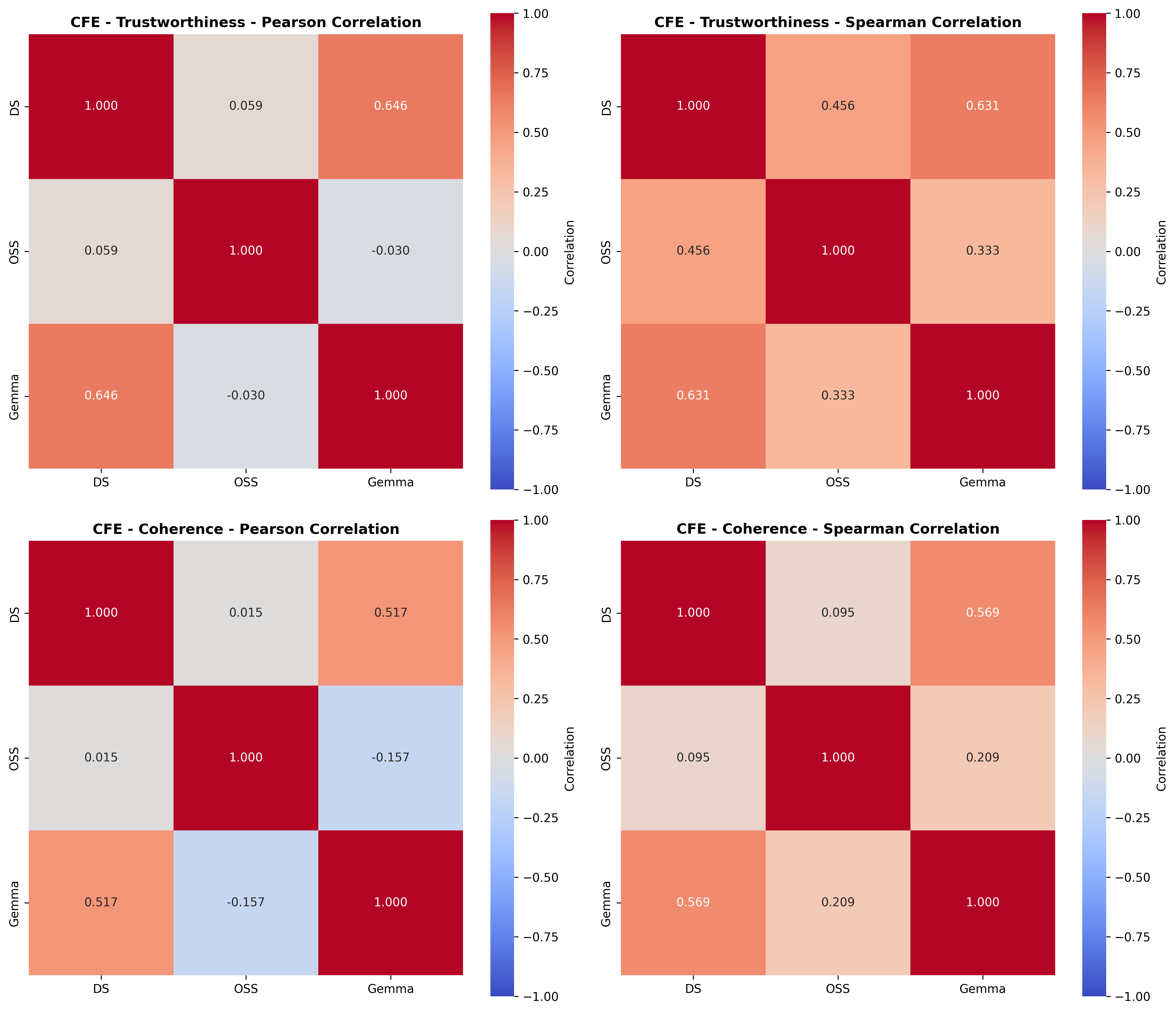
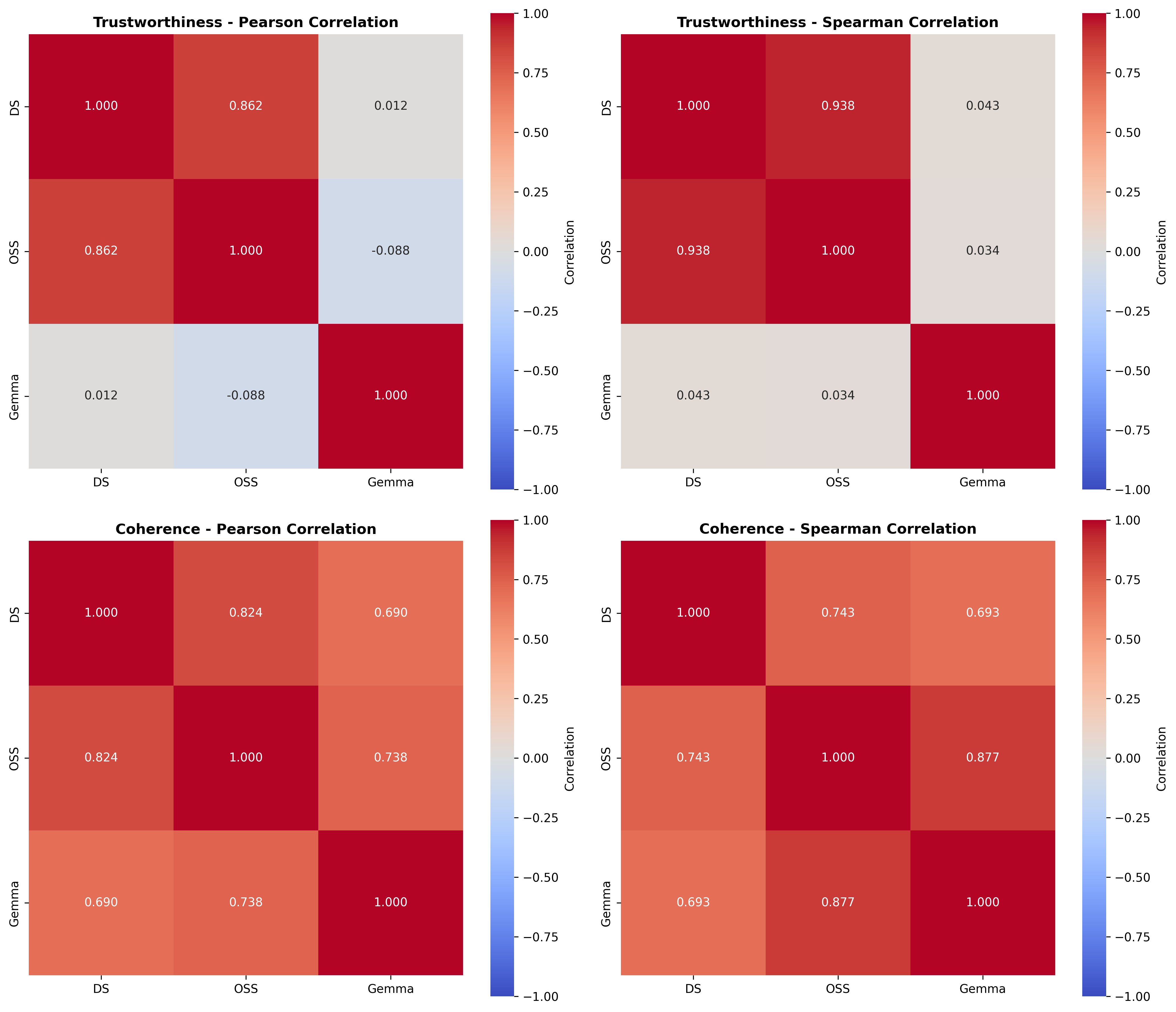
셋째, 사용자 연구(실제 인간 평가)에서는 양자화된 모델이 생성한 SE가 일관성·신뢰성 모두에서 최대 8.5% 낮은 점수를 받았다. 이는 객관적 메트릭과 주관적 인식 사이에 차이가 존재함을 시사한다. 사용자는 설명이 ‘논리적 흐름이 끊긴다’거나 ‘예시가 비현실적이다’는 느낌을 받았으며, 이는 실제 배포 환경에서 사용자 신뢰를 저해할 위험이 있다.
넷째, 모델 규모와 양자화 내성 사이에는 흥미로운 상반된 패턴이 나타났다. 대형 모델은 전반적인 SE 품질에서는 소형 모델에 비해 큰 회복력을 보이지 않았지만, 신뢰성에서는 오히려 더 높은 유지율을 보였다. 이는 대형 모델이 풍부한 파라미터 공간을 가지고 있어, 양자화 후에도 핵심 추론 경로를 보존할 가능성이 높기 때문이다.
마지막으로, 어느 양자화 기법도 정확도·SE 품질·신뢰성 세 축을 동시에 최적화하지 못했다. 이는 실무에서 ‘한 번에 모든 것을 만족시키는’ 양자화 전략이 존재하지 않으며, 사용 목적에 따라 트레이드오프를 명시적으로 설정해야 함을 의미한다.
종합하면, 양자화는 모델 압축 측면에서 큰 이점을 제공하지만, 특히 고신뢰성이 요구되는 설명형 AI 시스템에서는 SE 품질과 신뢰성 저하를 사전에 검증해야 한다. 특히 NLE는 비트 폭 감소에 민감하므로, 8‑bit 이상을 유지하거나 후처리(예: 설명 재정제) 기법을 병행하는 것이 바람직하다. 향후 연구는 양자화와 함께 설명 전용 파인튜닝을 진행하거나, 양자화 친화적인 설명 생성 아키텍처를 설계하는 방향으로 나아가야 할 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리