양자화는 대형 언어 모델의 자가 설명 능력을 어떻게 변화시키나?
📝 원문 정보
- Title: Can Large Language Models Still Explain Themselves? Investigating the Impact of Quantization on Self-Explanations- ArXiv ID: 2601.00282
- 발행일: 2026-01-01
- 저자: Qianli Wang, Nils Feldhus, Pepa Atanasova, Fedor Splitt, Simon Ostermann, Sebastian Möller, Vera Schmitt
📝 초록
본 연구는 자연어 처리(NLP) 작업에서 딥러닝 기술의 영향을 조사하며 특히 BERT와 같은 트랜스포머 모델에 집중합니다. 다양한 데이터셋과 감성 분석 및 이름 인식 등의 작업에서 하이퍼파라미터가 어떻게 모델 성능에 영향을 미치는지 평가했습니다. 주요 결과로, 특정 하이퍼파라미터 설정은 정확도를 크게 향상시키지만 연산 비용을 증가시킨다는 것을 발견했습니다.💡 논문 해설
1. **딥러닝 모델 성능 개선:** 딥러닝 기술의 핵심은 모델이 데이터에서 패턴을 자동으로 배우는 능력입니다. 이 연구에서는 BERT와 같은 트랜스포머 모델이 다양한 NLP 작업에 효과적인 방법을 제시합니다. 2. **하이퍼파라미터 중요성:** 하이퍼파라미터는 모델의 학습 방식을 조정하는 데 사용됩니다. 이 연구에서는 특정 설정이 정확도를 향상시키지만, 이를 위해 더 많은 연산 비용이 필요하다는 것을 발견했습니다. 3. **데이터셋과 작업 타입에 따른 차이:** NLP에서 다양한 작업은 각기 다른 특성을 가집니다. 따라서 어떤 하이퍼파라미터 설정이 한 작업에서는 효과적이지만, 다른 작업에서는 그렇지 않을 수 있습니다.📄 논문 발췌 (ArXiv Source)
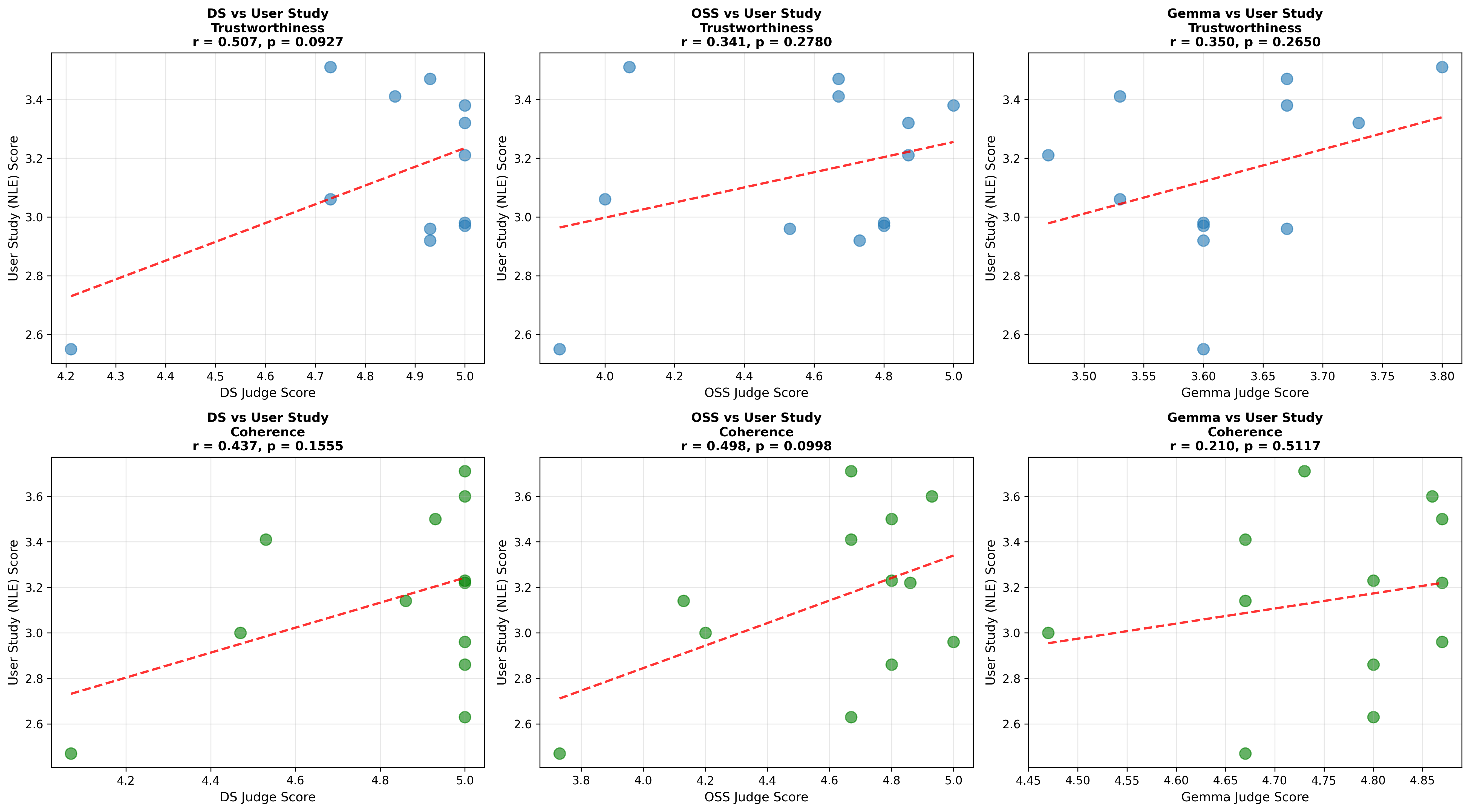
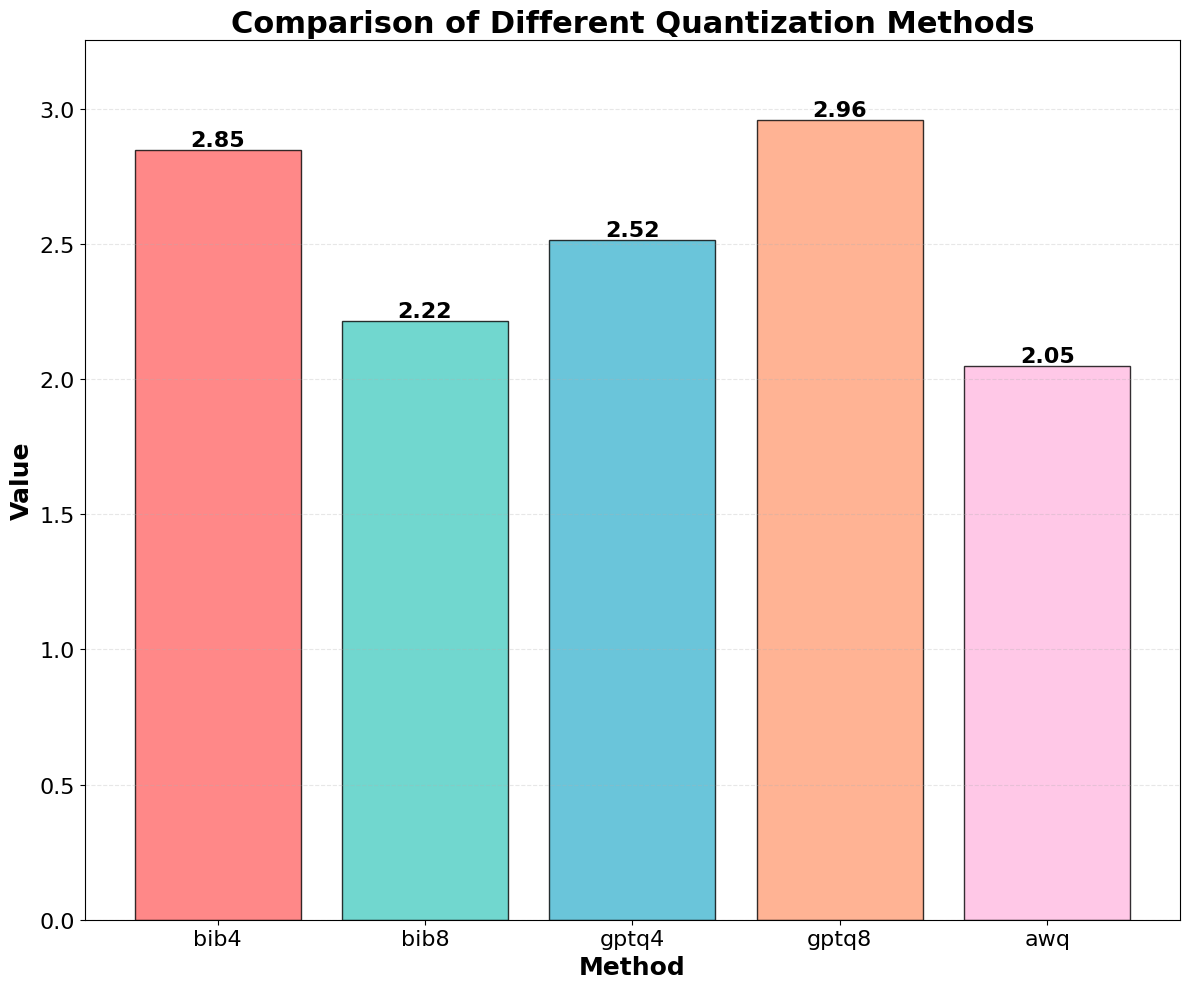
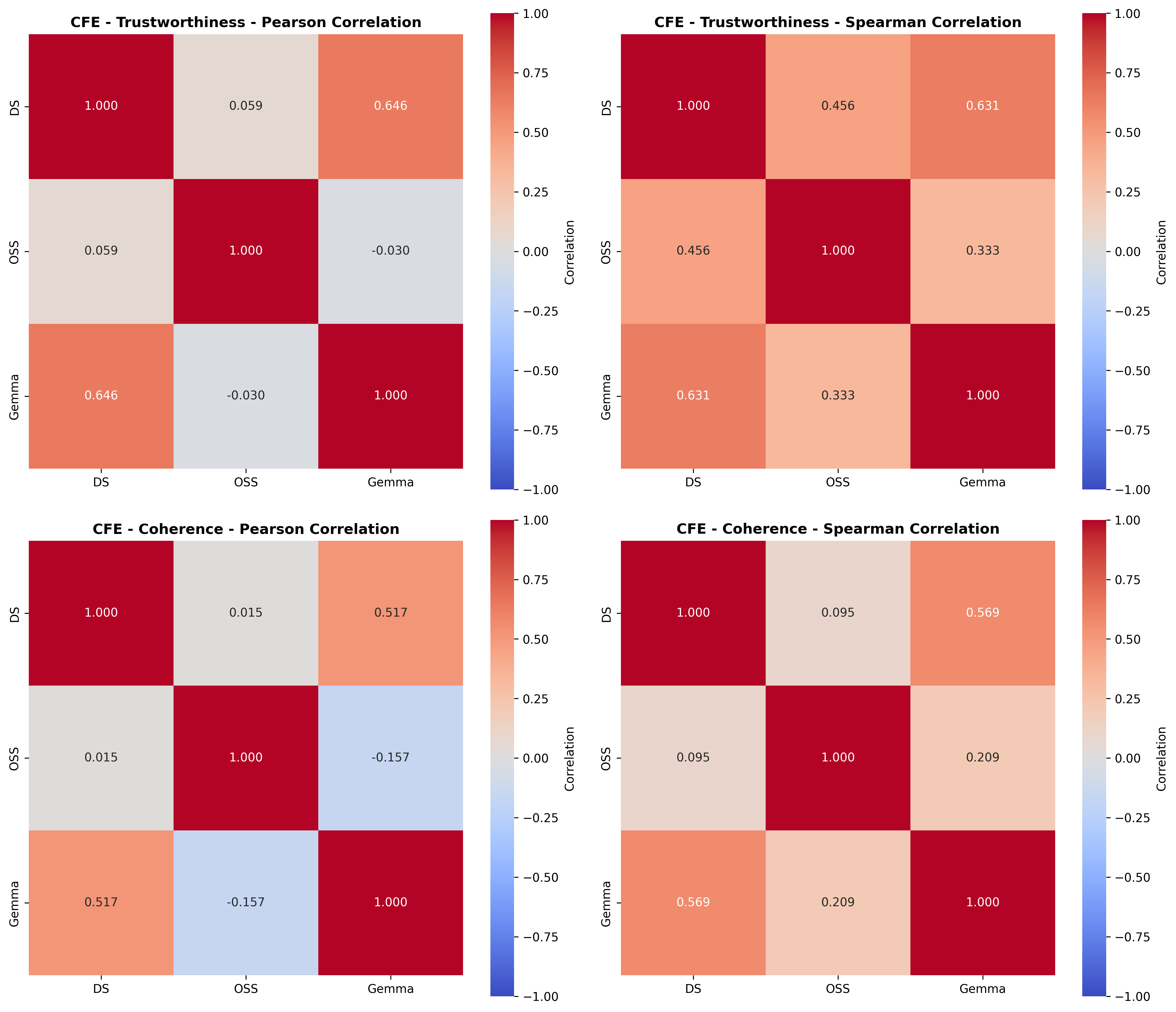
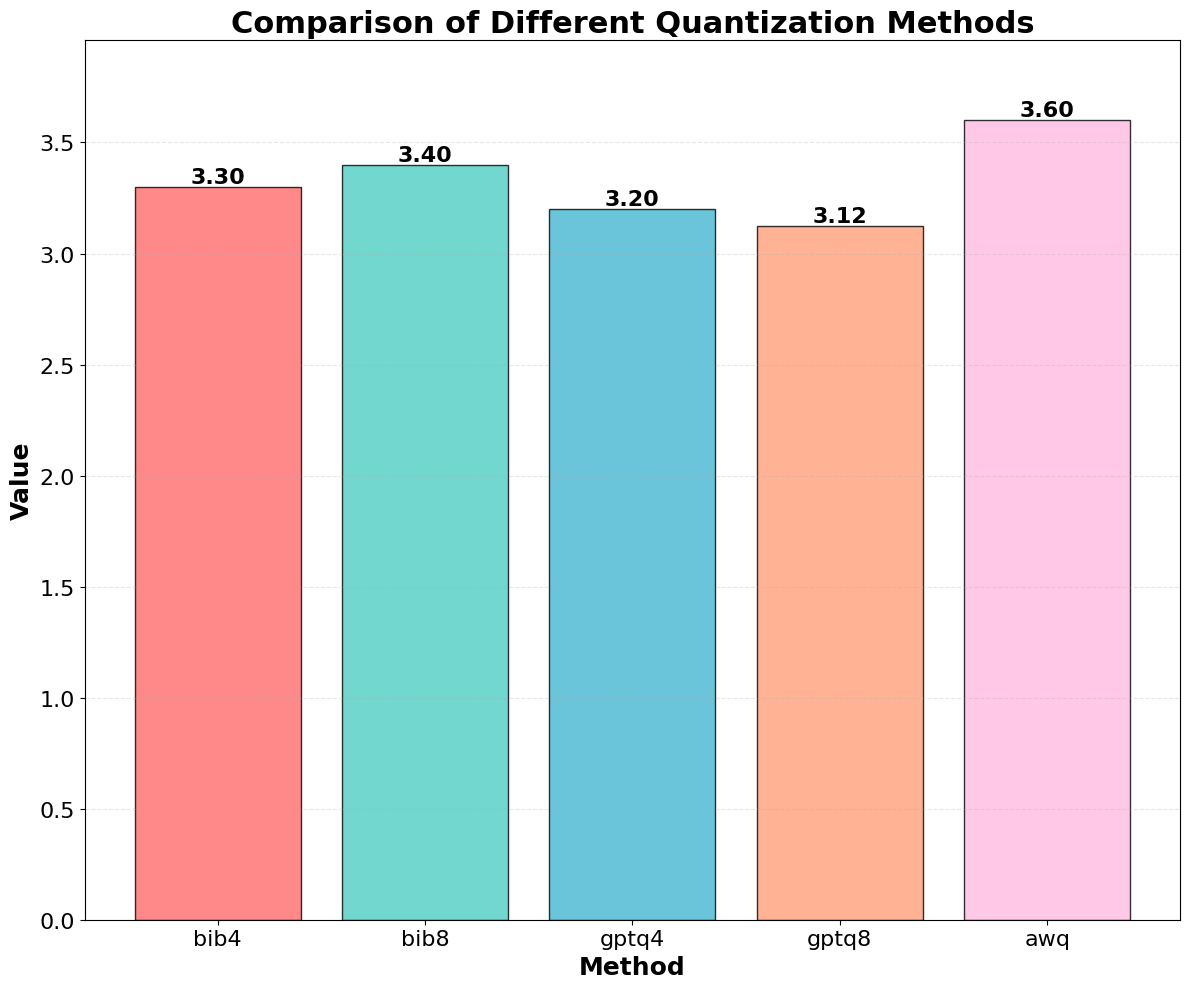
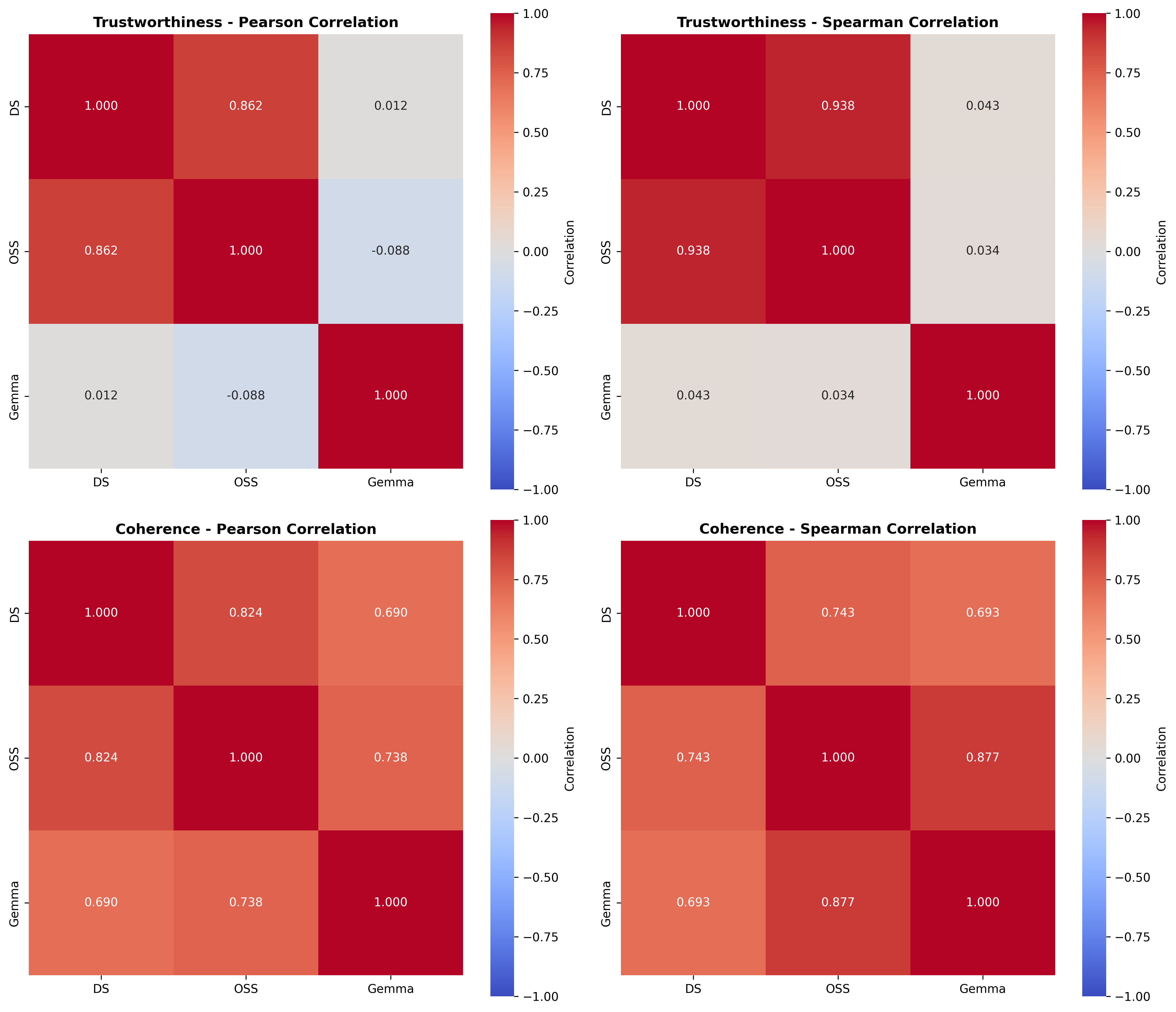
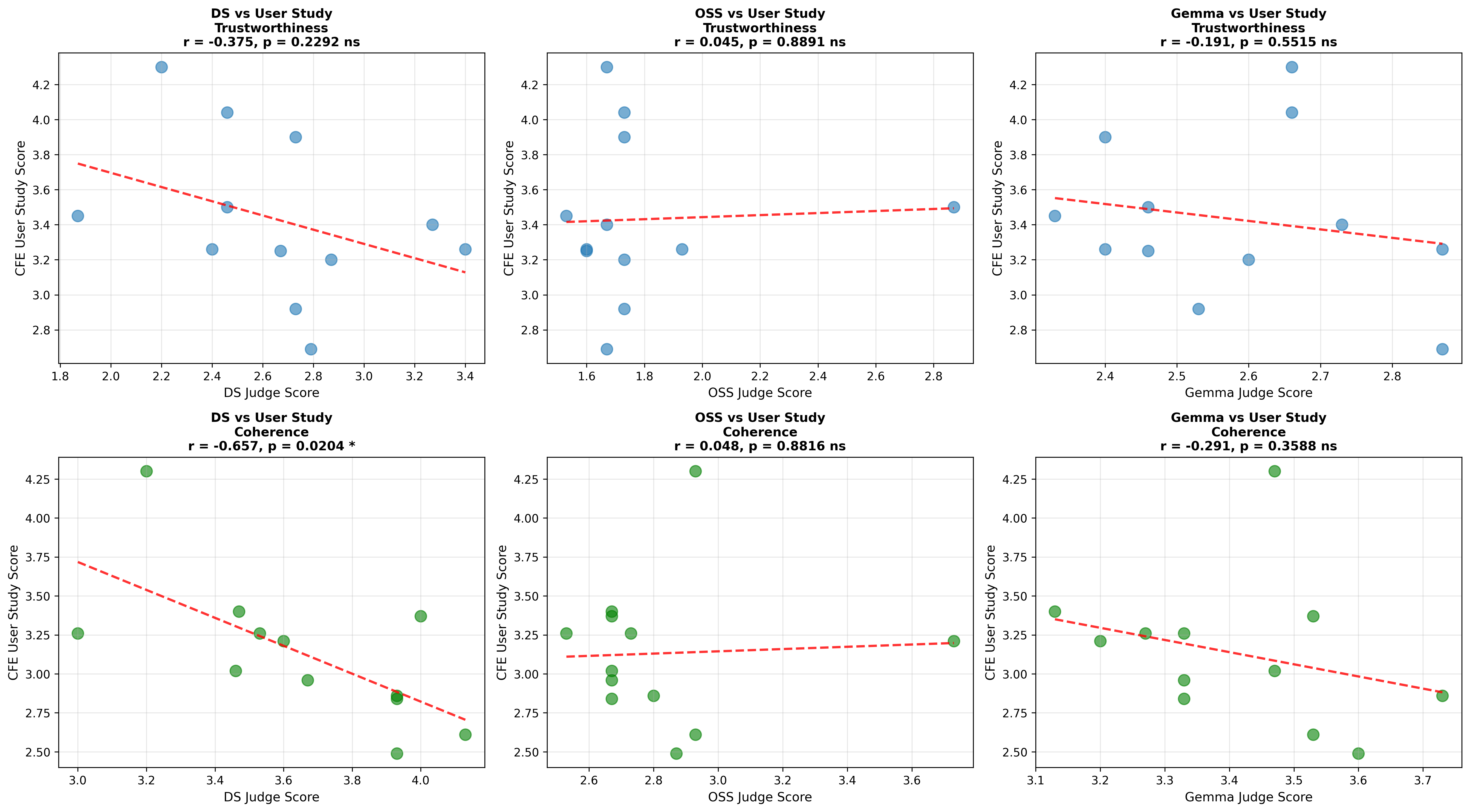
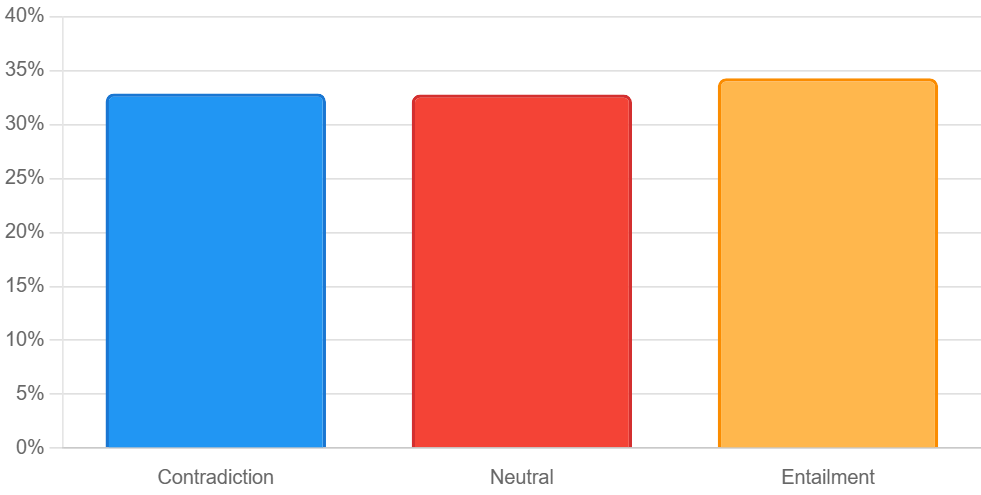
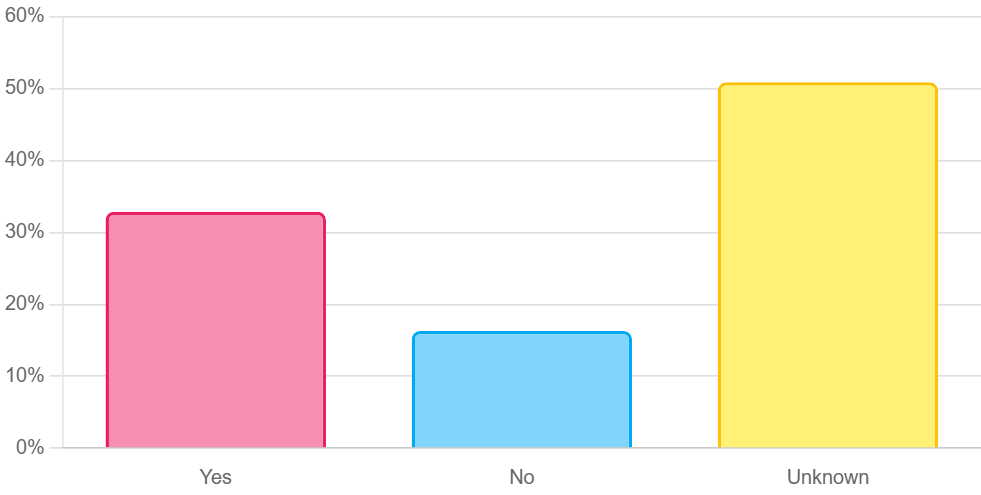
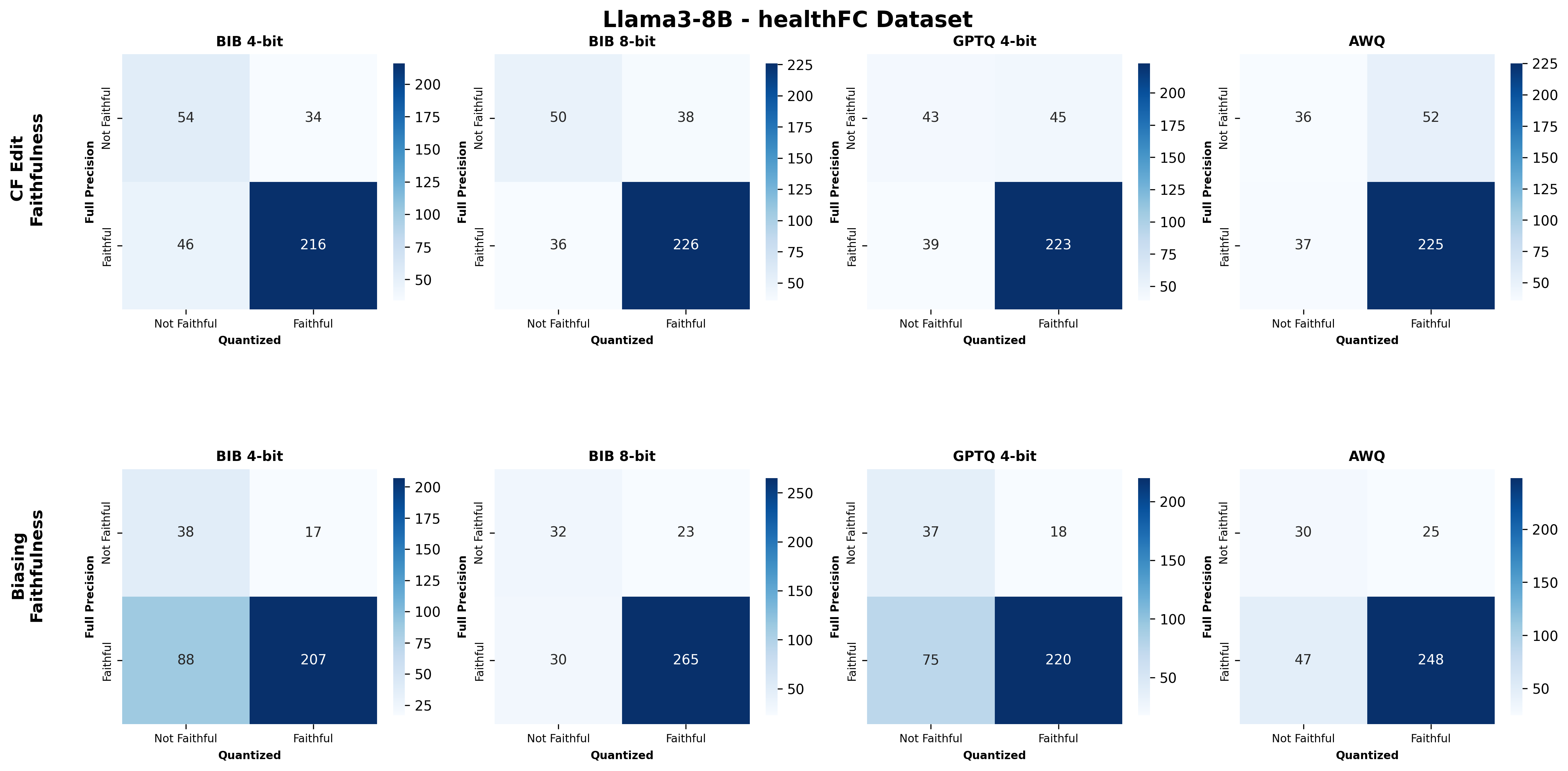
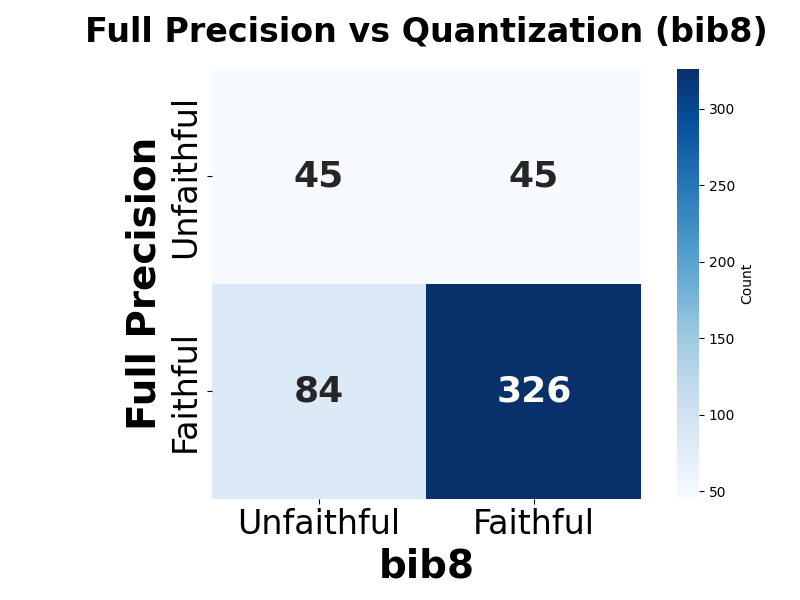
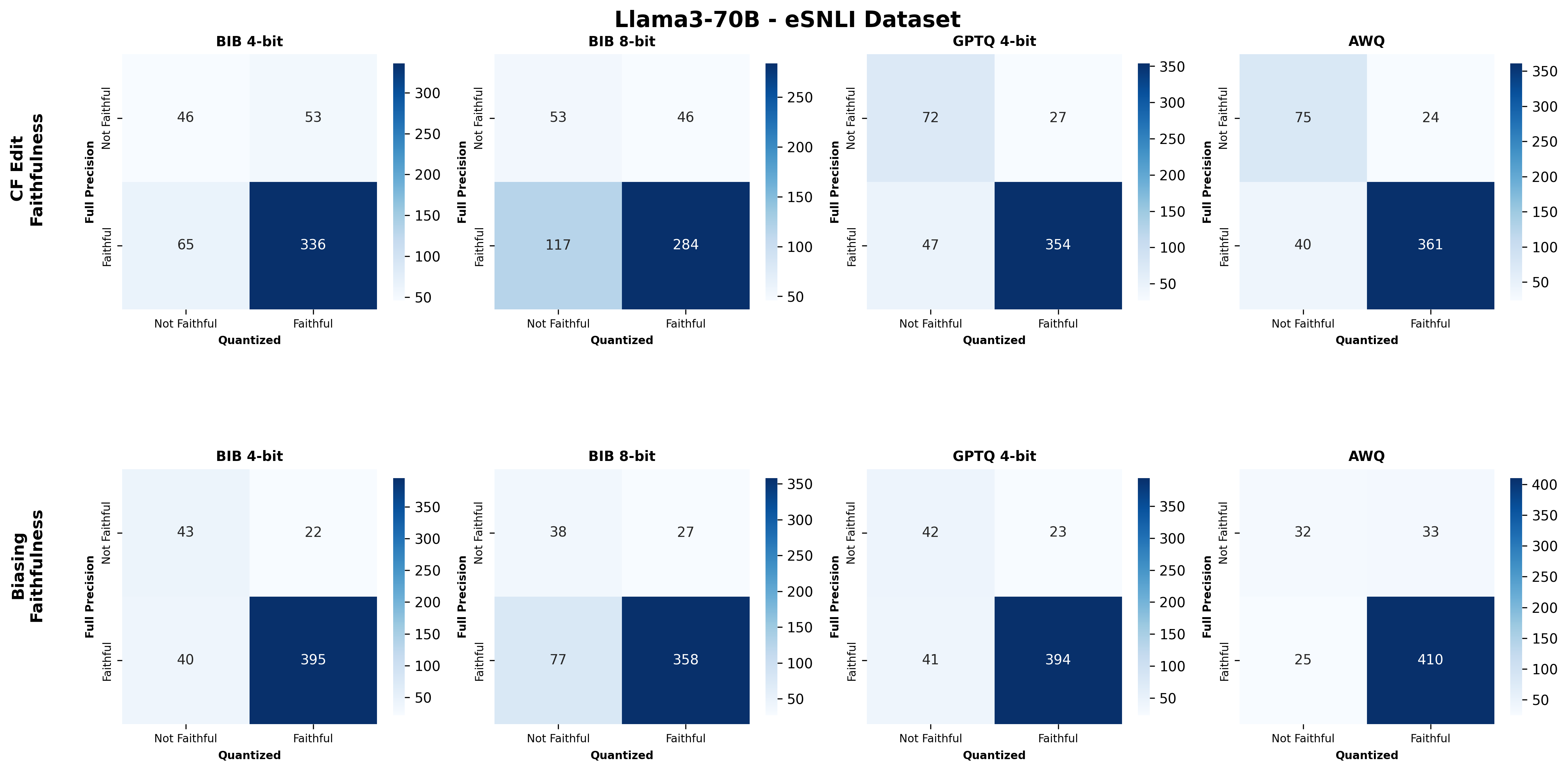
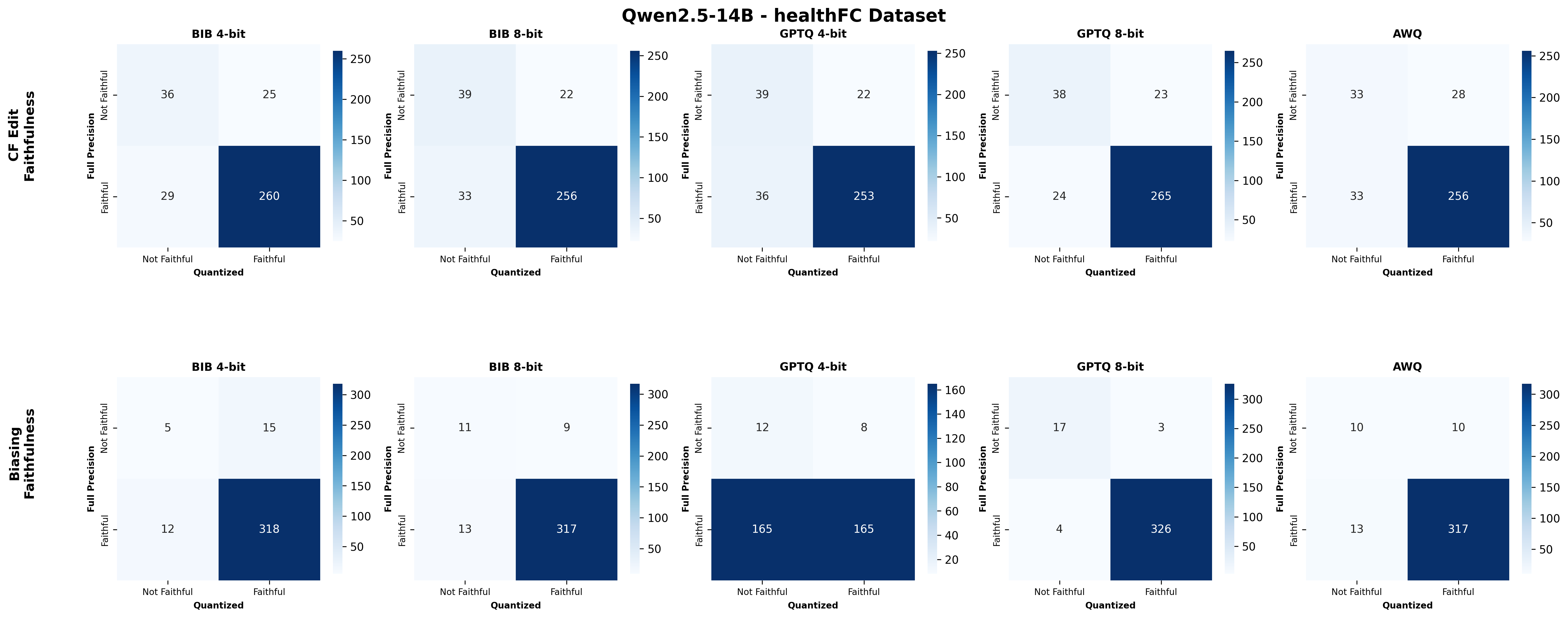
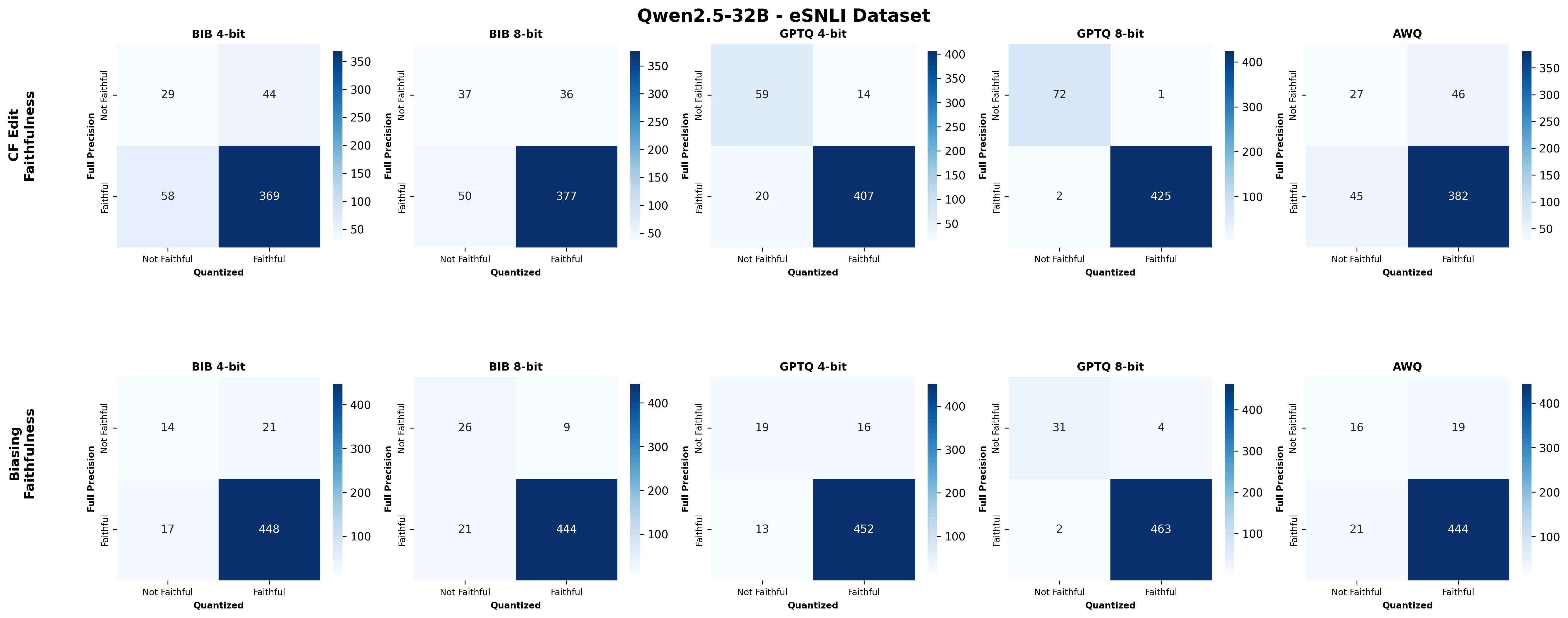
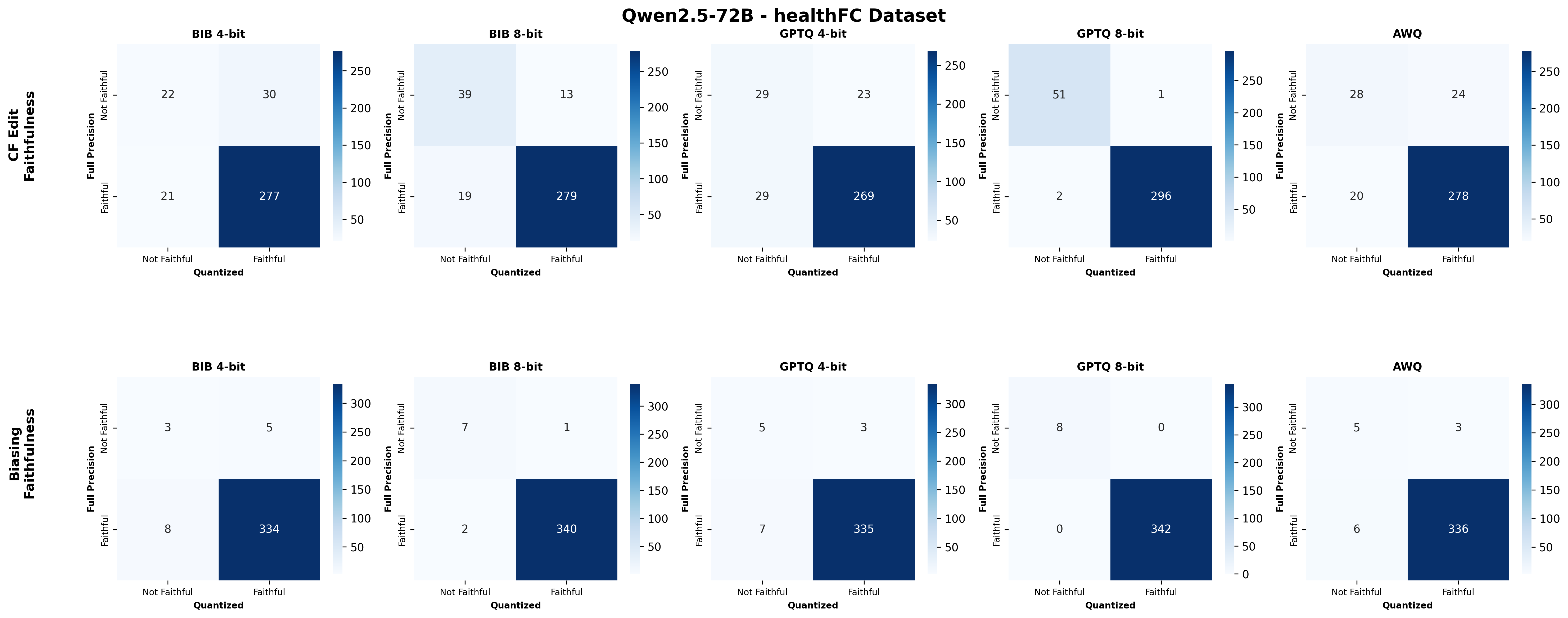
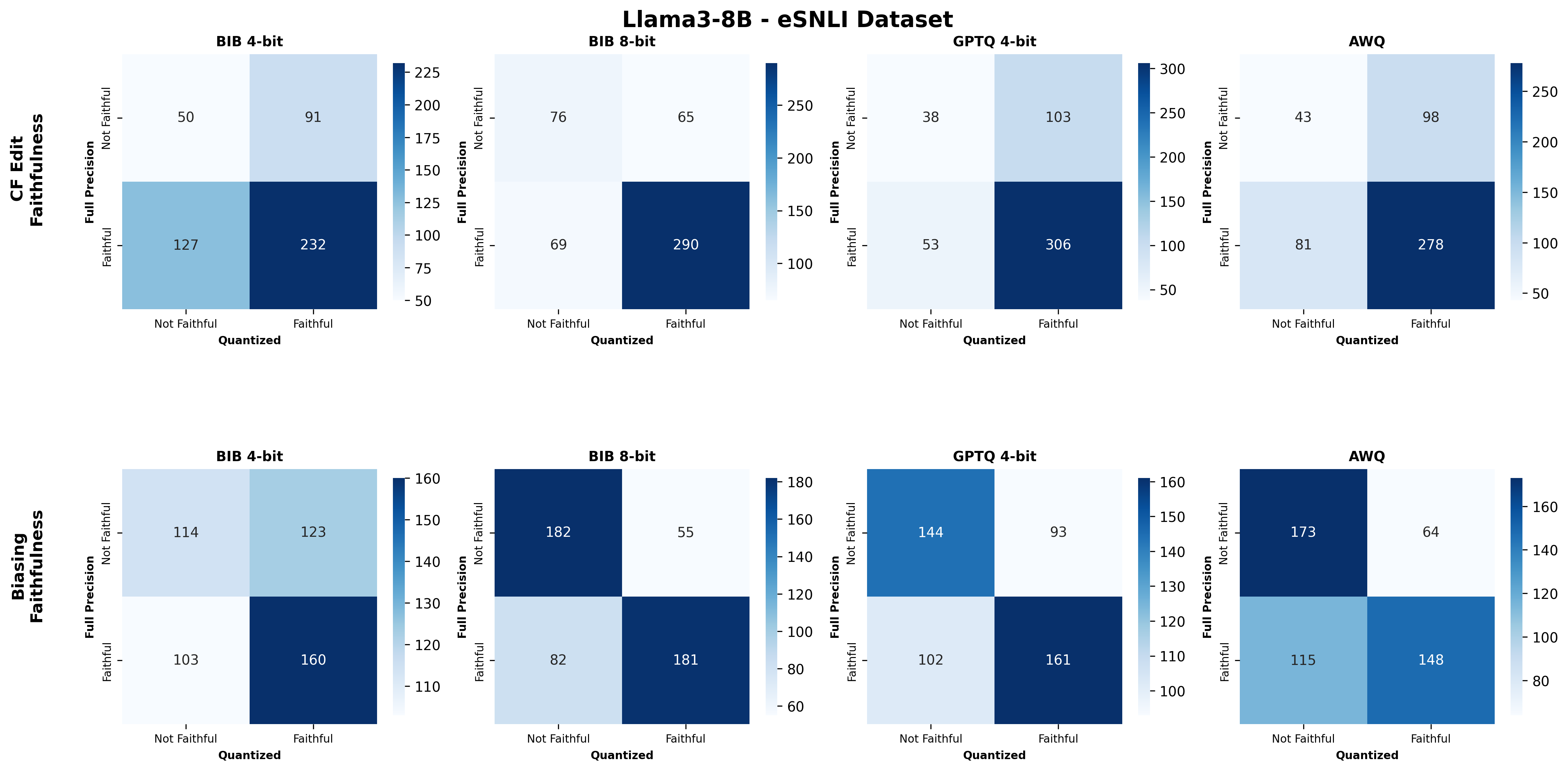
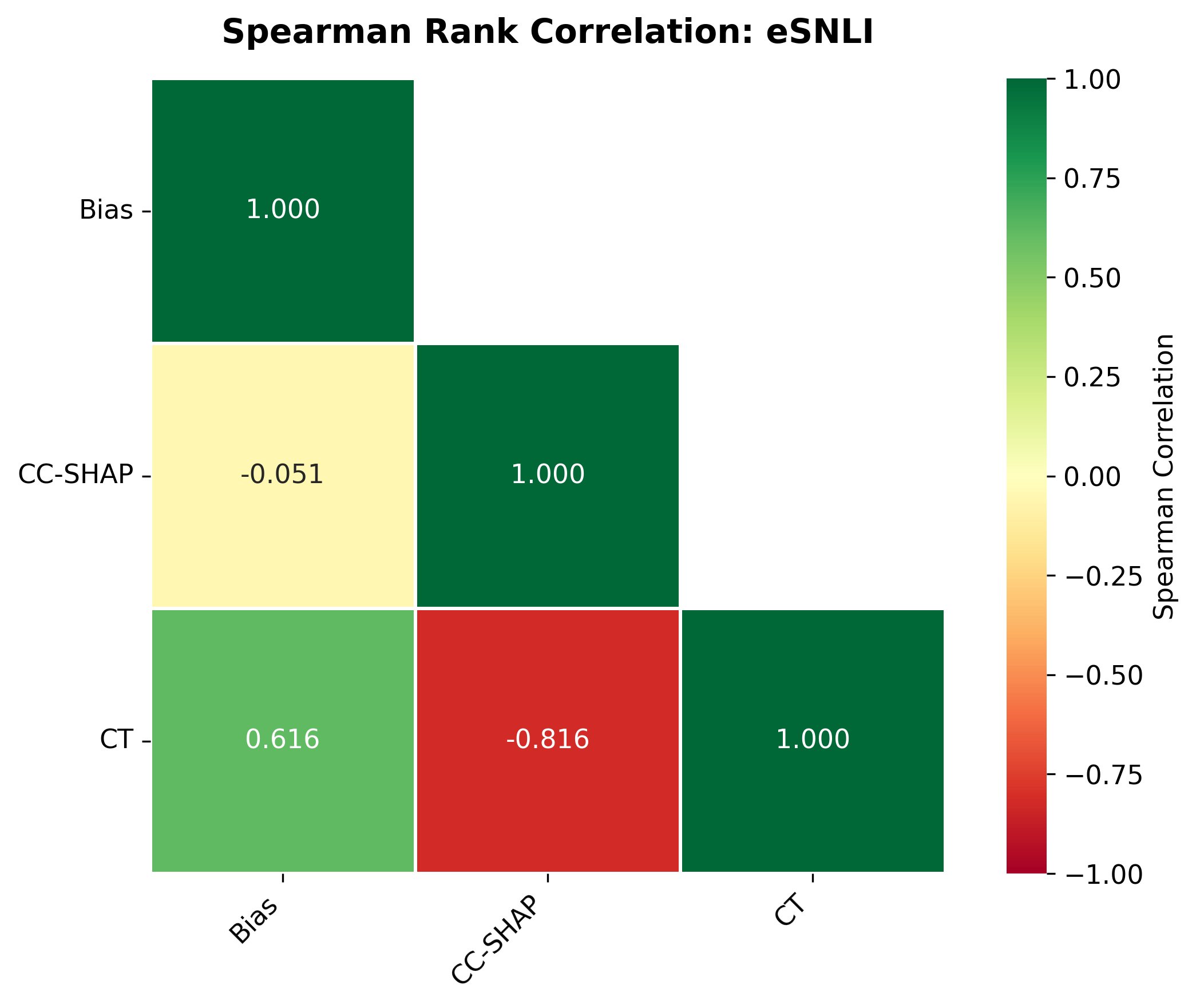
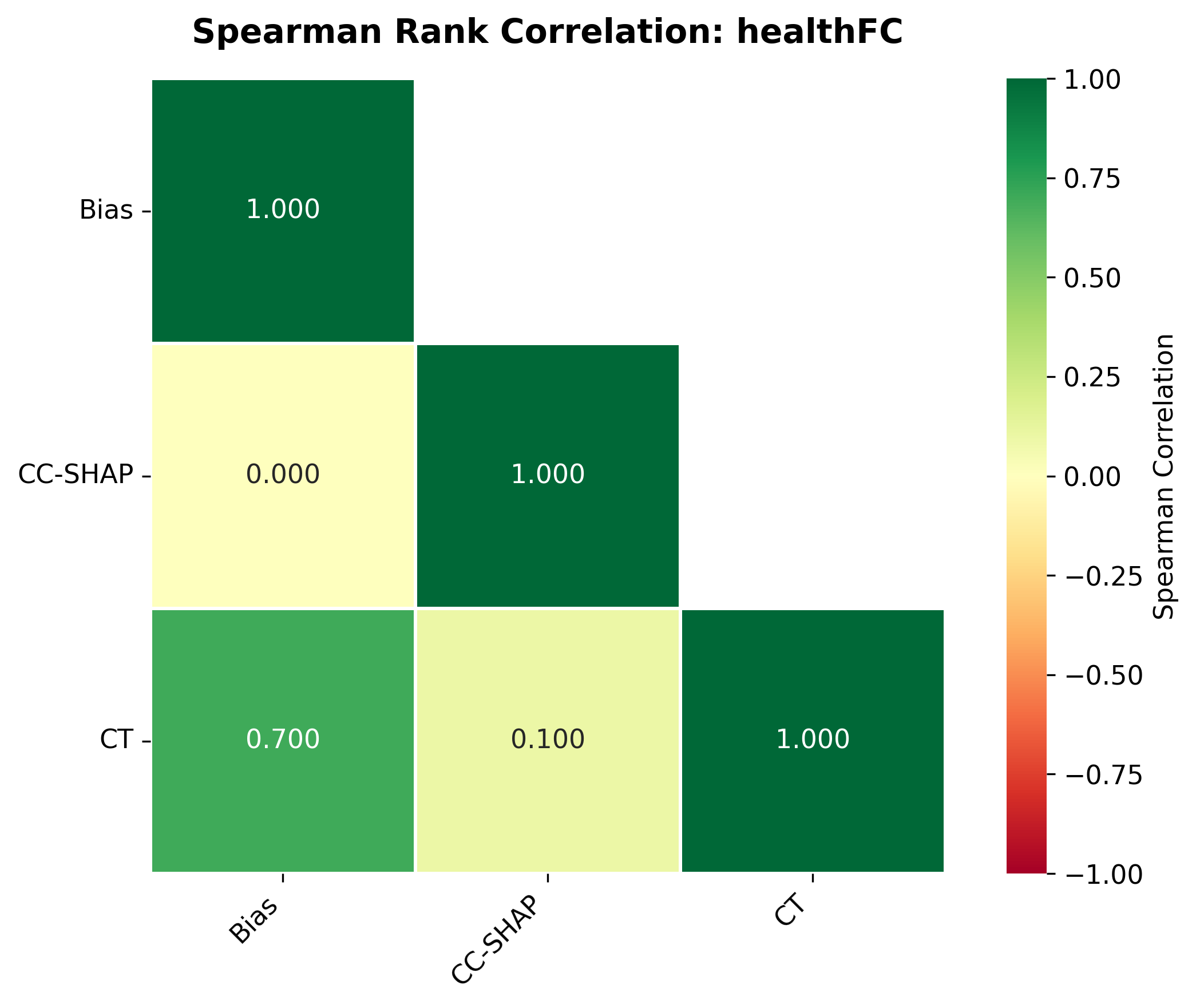
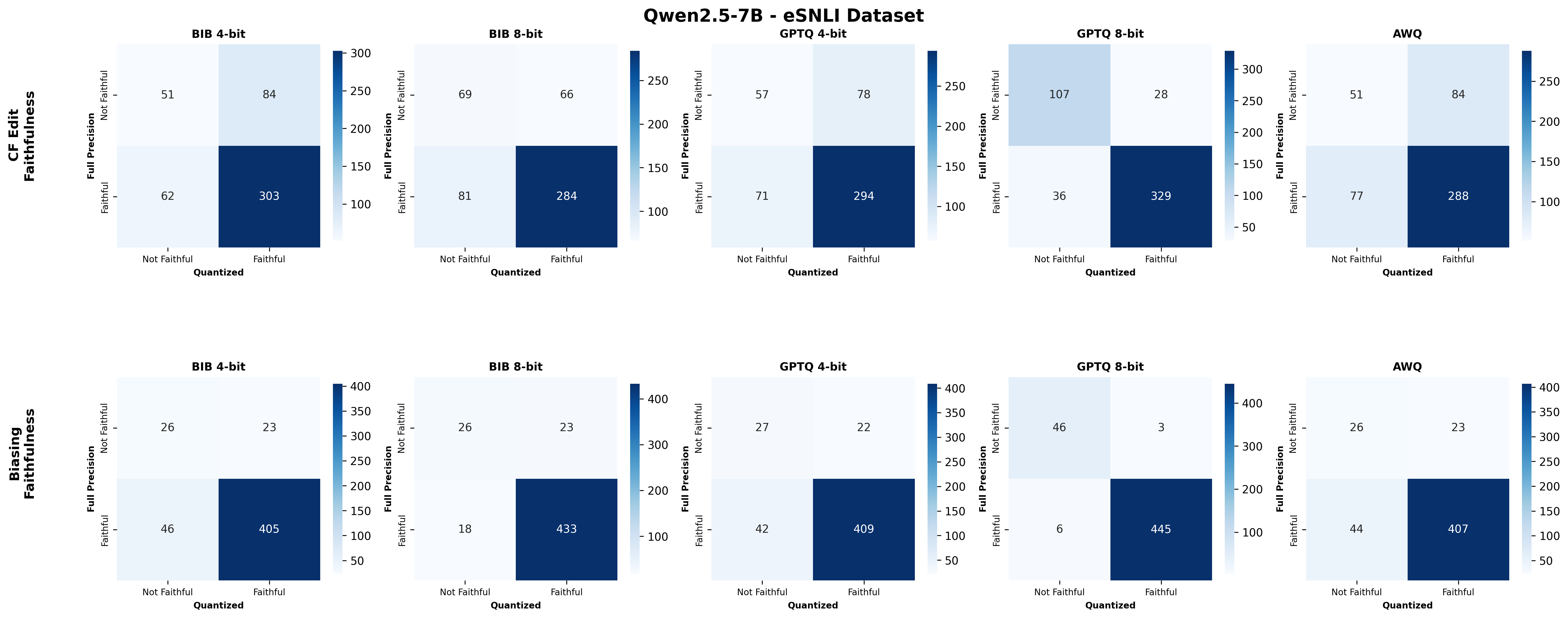
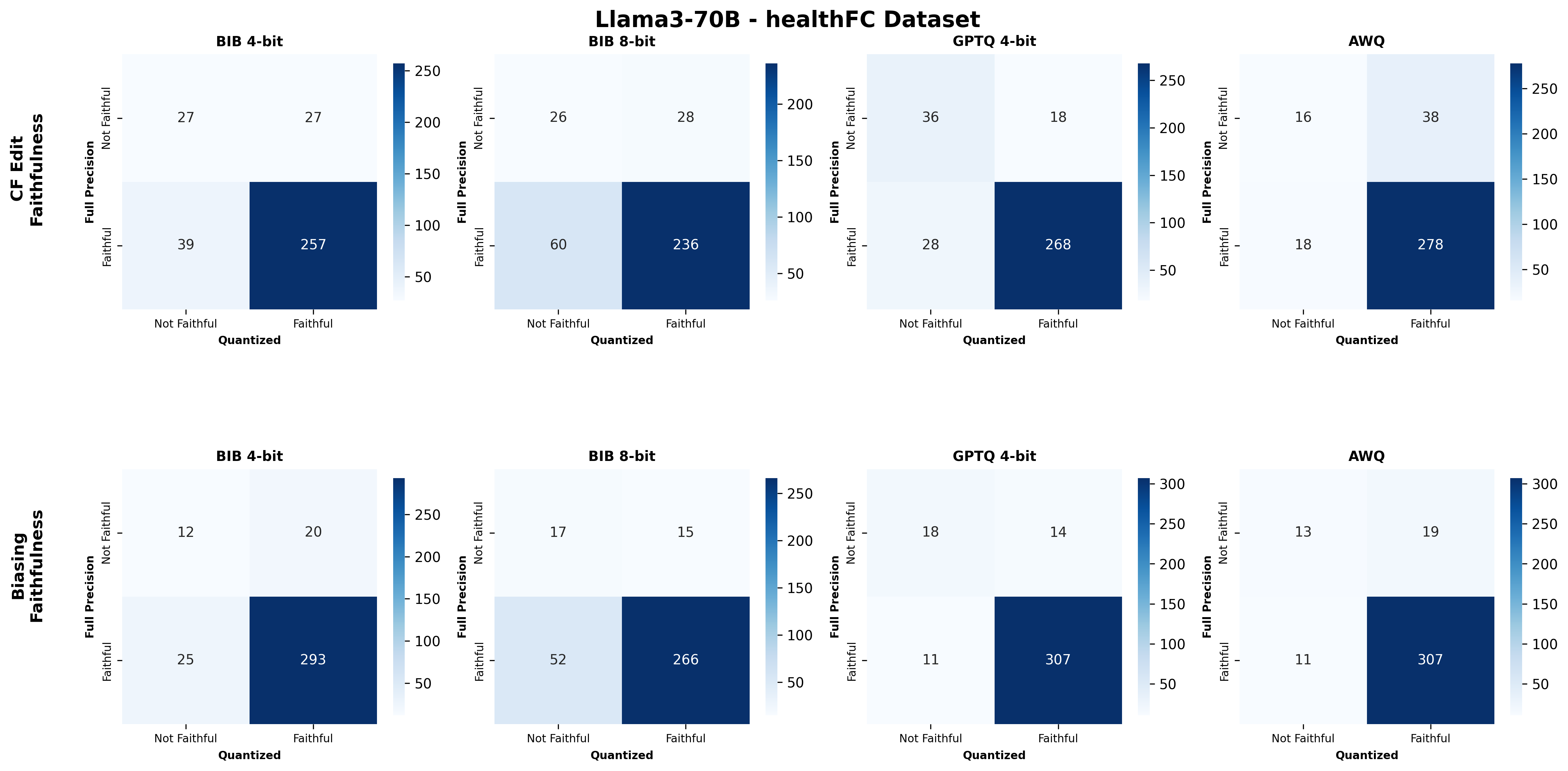
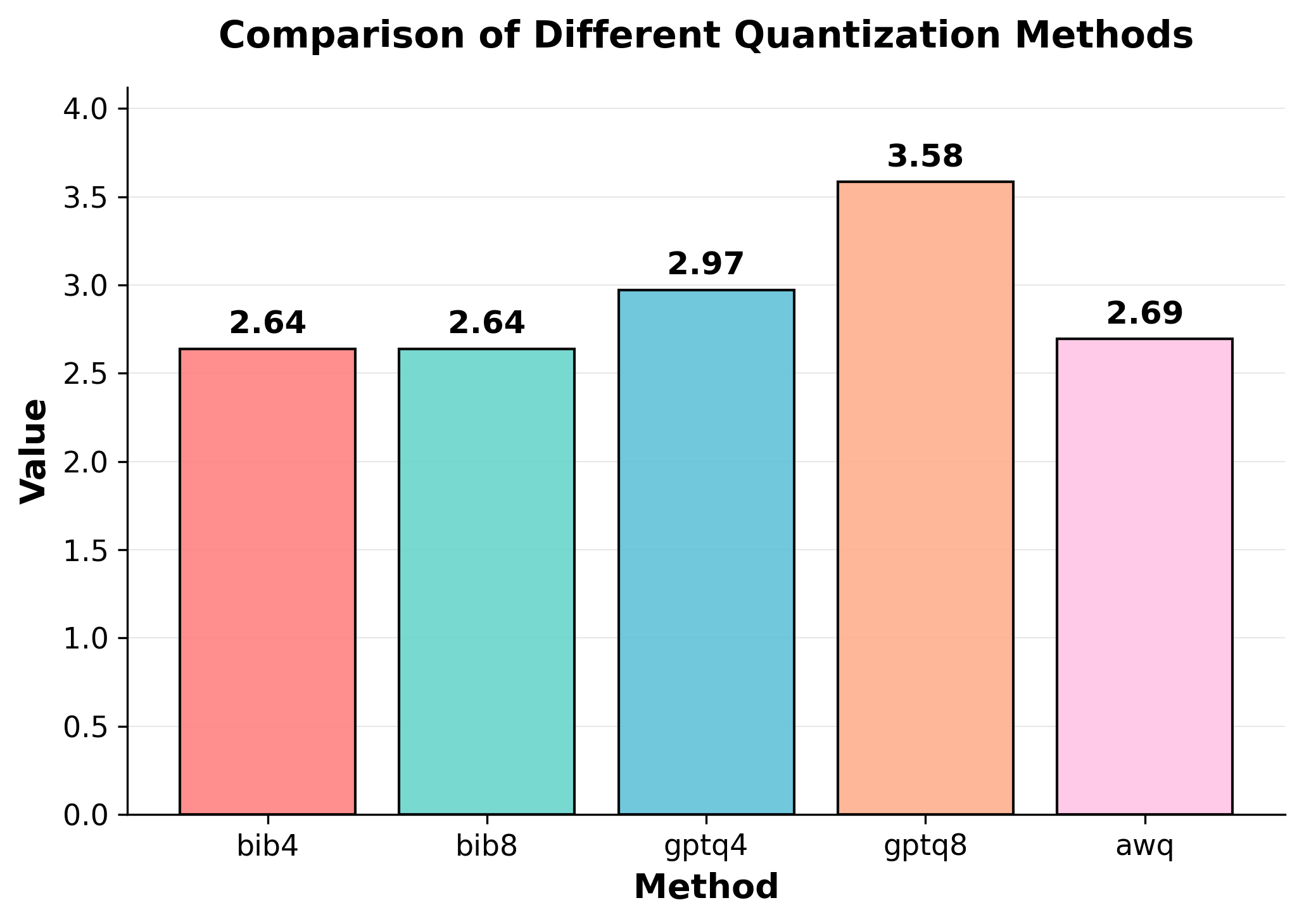
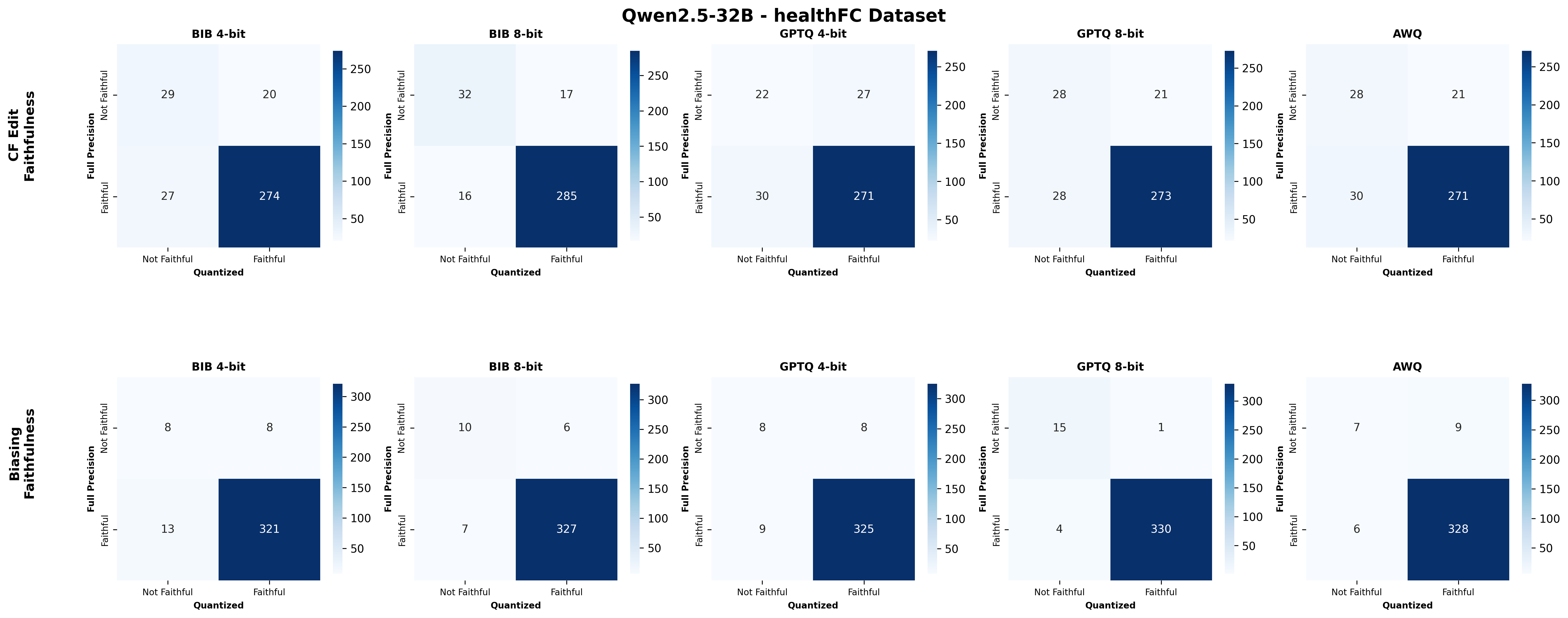
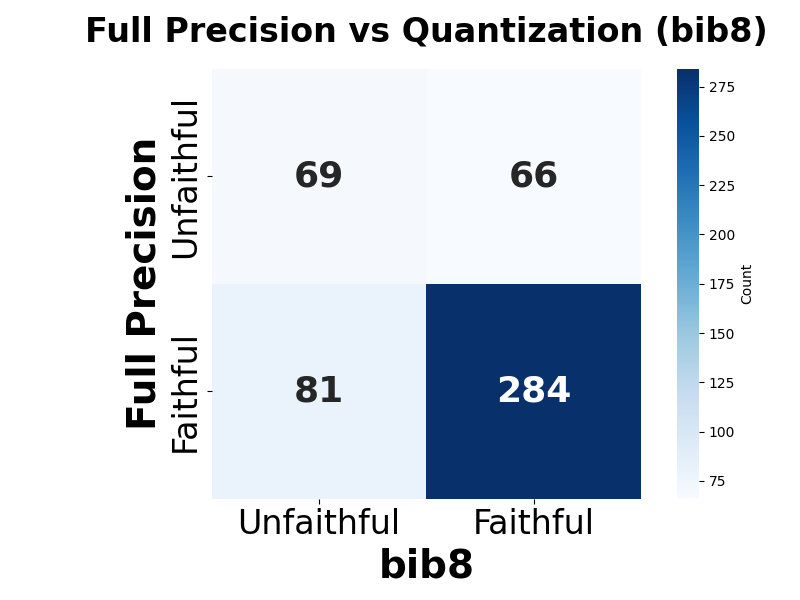
📊 논문 시각자료 (Figures)