- Title: Parallel Universes, Parallel Languages A Comprehensive Study on LLM-based Multilingual Counterfactual Example Generation
- ArXiv ID: 2601.00263
- 발행일: 2026-01-01
- 저자: Qianli Wang, Van Bach Nguyen, Yihong Liu, Fedor Splitt, Nils Feldhus, Christin Seifert, Hinrich Schütze, Sebastian Möller, Vera Schmitt
📝 초록
본 논문에서는 다언어 모델의 동작을 이해하기 위해 직접 생성된 다언어 역사례와 번역 기반 역사례를 평가하고, 이들의 효과성을 검증한다. 특히, 영어 외 언어에서 역사례를 생성하는 방법을 연구하며, 이를 통해 모델의 예측을 변경할 수 있는 능력을 분석한다.
💡 논문 해설
1. **다언어 역사례 생성:** 본 논문에서는 다언어 대형 언어 모델(LLM)이 어떻게 다양한 언어에서 역사례를 생성하는지 연구한다. 이는 마치 여러 언어로 이야기를 바꾸면서도 그 핵심을 유지하려는 것과 같다.
역사례 효과 평가: 역사례의 성능은 라벨 플립률, 유사성, 난해도 등 다양한 자동 평가 메트릭을 통해 측정된다. 이는 마치 글쓰기 경연에서 여러 기준에 따라 글을 평가하는 것과 같다.
다언어 역사례의 활용: 다언어 역사례는 모델 성능 향상과 견고성을 위해 데이터 증강에 사용된다. 이는 마치 다양한 언어로 된 레시피를 통해 요리를 더 잘 배우는 것과 같다.
📄 논문 발췌 (ArXiv Source)
# 소개
다중 언어로 설명을 제공하고 다언어 모델의 동작을 밝히는 중요성이 점차 인정받고 있다. 역사례란 원래 예측과 다른 결과를 내는 최소 수정된 입력으로, 모델의 블랙박스적인 행동을 대조적으로 드러낸다. 그러나 역사례 생성 방법론과 LLMs의 인상적인 다언어 기능에도 불구하고, 이러한 접근법은 거의 영어에만 적용되었다. 또한, 언어 간 분석은 영어와 비영어 컨텍스트 사이에서 체계적인 행동 차이를 발견하여 영어로만 생성된 역사례가 모델의 전체 동작을 포착하는 데는 부족함을 보여준다. 그럼에도 불구하고 LLMs가 고품질 다언어 역사례를 생성하는 효과성은 여전히 열린 질문이다.
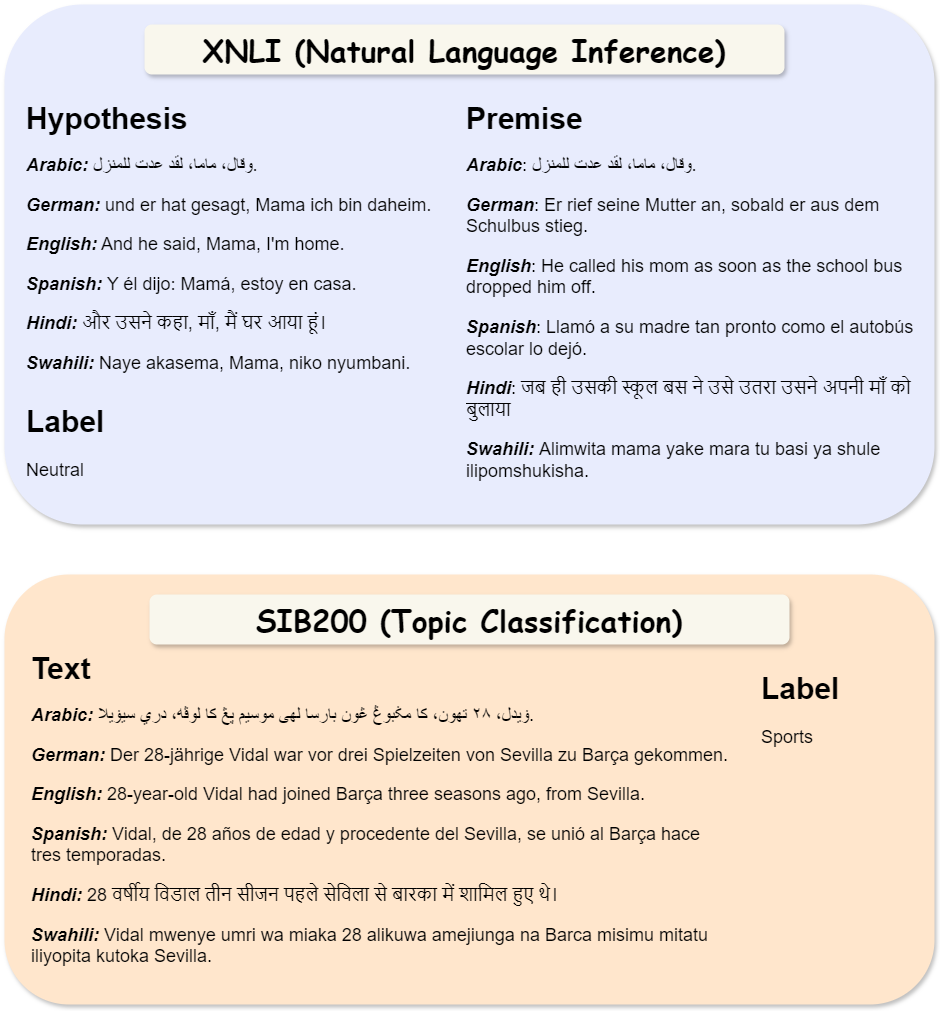
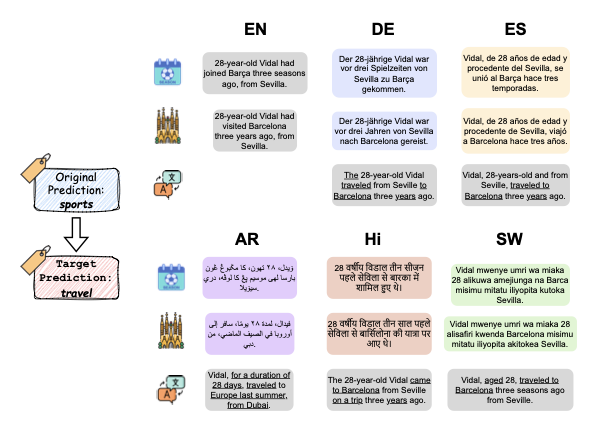
SIB200 데이터셋에서 영어, 독일어,
스와힐리어로 분류된 "정치" 원문 입력의 평행 표시, 라벨을 “과학/기술”(Sci/Tech)으로 바꾸려는 역사례, 자동 평가 결과 및 생성된 역사례의 영어 번역. 다언어 역사례는 세 가지 자동 메트릭(라벨 플립↑, 퍼플렉서티↓,
유사성↑)을 사용하여 평가된다. 다언어 역사례와 그들의 영어 번역에서 LLM에 의해 수정된 단어는 보라색으로 강조 표시되어 있다.
이 간극을 메우기 위해, 우리는 세 가지 크기의 다양한 LLMs을 사용하여 두 개의 다언어 데이터셋에서 여섯 가지 언어(영어, 아랍어, 독일어, 스페인어, 힌디어, 스와힐리어)에 대한 역사례 생성에 대한 포괄적인 연구를 수행한다(Figure 1). 첫째, 우리는 (1) 대상 언어에서 직접 생성된 역사례(DG-CFs), 그리고 (2) 영어 역사례를 번역하여 얻은 역사례(TB-CFs)의 효과성을 평가한다. 고자원 유럽 언어에서는 DG-CFs가 높은 라벨 플립률(LFR)로 모델 예측을 자주 변경하는 것으로 관찰된다. 특히, 영어 역사례는 다른 언어들보다 LFR이 높게 나타난다. 반면에 TB-CFs는 DG-CFs보다 LFR에서 우수하지만, 그만큼 많은 수정이 필요하다. 또한, TB-CFs는 번역된 원래 영어 역사계열보다 낮은 LFR을 보여준다. 둘째, 우리는 서로 다른 언어의 역사례에서 같은 수정이 얼마나 적용되는지에 대해 조사한다. 우리의 분석은 영어, 독일어, 스페인어에서 입력 수정이 높은 유사성을 보이는 것을 보여주며, 특히 비슷한 단어가 여러 언어에서 편집된다 (cf.
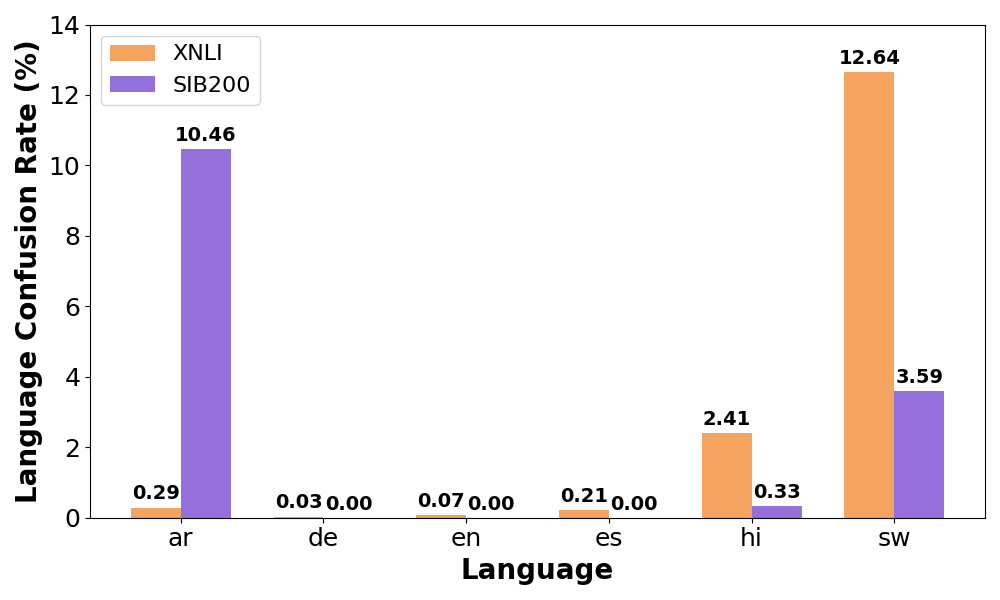
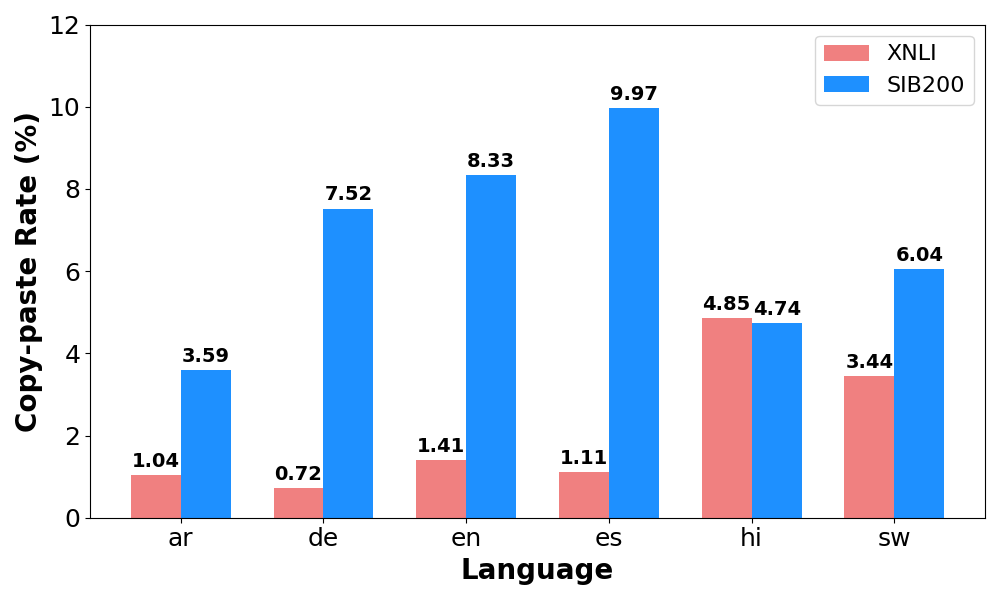
Figure 24). 셋째, 생성된 역사례에서 네 가지 일반적인 오류 패턴을 보고한다: 복붙, 부정, 일관성 없는, 그리고 언어 혼동. 마지막으로, 우리는 언어 간 및 다언어 역사계열 데이터 증강(CDA)이 모델 성능과 견고성에 미치는 영향을 조사한다. 성능과 견고성 향상에 대한 신호가 혼합되어 있지만, 특히 저자원 언어에서는 다언어 CDA가 더 나은 모델 성능을 달성하는 것으로 나타났다.
관련 연구
역사례 생성.
모델의 출력을 특정 예측으로 전환하기 위한 대비적 수정을 생성한다. Polyjuice는 미세 조정된 GPT2를 사용하여 역사계열 인스턴스 생성에 필요한 변형 유형을 결정한다. 중요한 입력 토큰을 확인하는 방법을 제안하며, 이는 생성된 역사계열 예에서 중요하다. 계산적 합리화와 스팬 수준 마스크 언어 모델링을 결합하여 역사계열 예를 생성한다. 입력의 잠재 표현을 찾아 이를 관찰 가능한 특징으로 되돌려 역사계열을 만든다. 동일한 LLM이 생성한 중요한 단어에 의해 안내되는 제로샷 설정에서 Pseudo-Oracle로서 LLMs을 사용하여 역사계열 예를 생성한다. 기능 중요성 방법을 사용하여 역사계열 예의 생성을 이끄는 중요한 단어를 식별한다. 그러나 이러한 모든 방법은 영어 데이터셋에만 평가되었으며, LLM이 다언어 역사계열을 생성하는 능력은 여전히 탐색되지 않은 상태이다.
역사계열 설명 평가.
역사계열의 품질은 다양한 자동 평가 메트릭을 사용하여 평가할 수 있다. **라벨 플립률(LFR)**은 생성된 역사계열의 유효성과 효과성을 평가하는 주요 평가 메트릭이다. LFR은 총 생성된 역사계열 중 라벨이 성공적으로 변경된 인스턴스 비율을 나타낸다. 유사성은 역사계열 생성에 필요한 텍스트 수정의 범위를 측정하며, 일반적으로 편집 거리로 정량화된다. 다양성은 주어진 입력에 대한 여러 개의 역사계열 예들 간의 평균 쌍별 거리를 측정한다. 유창성은 역사계열이 인간 작성 텍스트와 얼마나 유사한지를 평가한다.
다언어 역사계열.
다른 언어에서 민족적 편향을 평가하기 위해 역사계열을 제안하며, 이는 번역 모델의 추가 훈련 데이터로 사용되는 역사계열 데이터 증강(CDA) 접근법이다. CDA에 사용된 역사계열은 실제 라벨을 바꾸는 것이 아니라 모델 예측을 바꾸기 때문에 본 논문에서 탐구하는 역사계열 설명과 다름이 있다. 이진 검색 보조 생성 시스템에서 답변 귀인을 측정하기 위해 역사계열을 사용한다. 그럼에도 불구하고, LLMs이 고품질 다언어 역사계열 설명을 얼마나 잘 생성할 수 있는지에 대한 연구는 여전히 이루어지지 않았다.
실험 설정
역사계열 생성
입력 $`x`$에서 원래 모델 예측 $`y`$를 대상 라벨 $`\tilde{y}`$로 변경하는 역사계열 $`\tilde{x}`$을 생성하는 것이 우리의 목표이다. 우리는 고급 생성 방법보다는 다언어 역사계열 설명에 대한 포괄적인 개요를 제공하고자 한다. 따라서, 잘 알려진 역사계열 생성 접근법을 채택한다. 이 접근법은 원샷 체인-오브-사고 프롬프팅을 기반으로 하며 다음과 같은 속성을 만족한다:
생성된 역사계열은 평가되는 LLM에만 의존하여 외부 중요한 특징 신호와 같은 혼란 요인을 피한다.
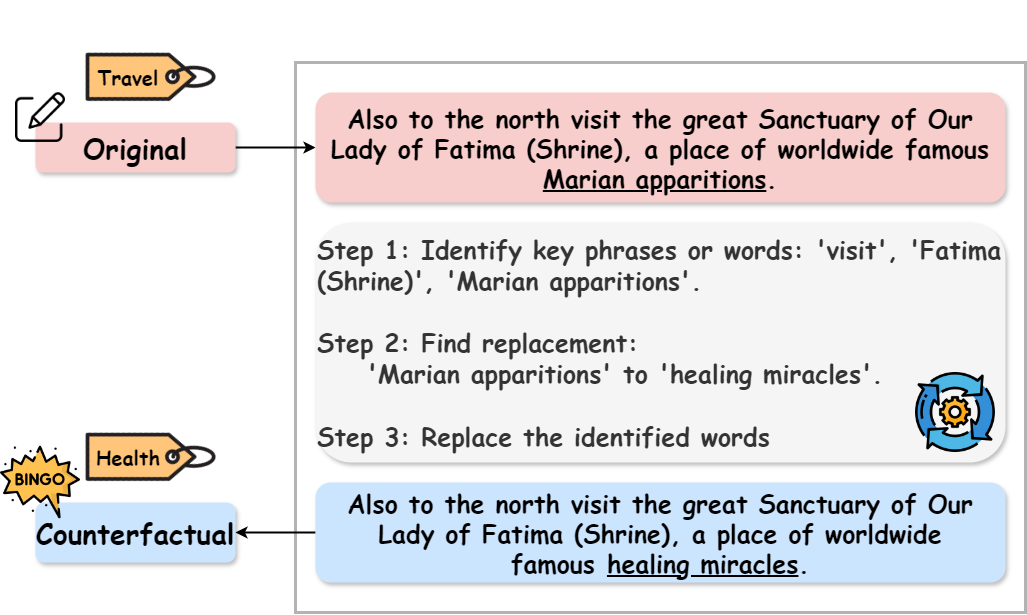
역사계열 생성 과정 개요. SIB200에서 "여행"으로 분류된 원래 인스턴스 x, 해당 역사계열 x̃은 "건강"으로 분류된다. x에 대한 수정은 밑줄로 표시되어 있다.
우리는 대상 언어에서 역사계열 $`\tilde{x}`$ (DG-CFs, Table [subtab:direct])를 직접 생성한다. 이는 Figure 2에서 보여진 세 단계 과정을 통해 이루어진다:
원래 입력에서 모델 예측에 가장 큰 영향을 미치는 중요한 단어를 식별한다.
이러한 식별된 단어의 적합한 대체어를 찾아서 목표 라벨로 이끌 수 있도록 한다.
원래 단어를 선택한 대체어로 바꾸어 역사계열을 구성한다.
또한, 우리는 번역 기반 역사계열 $`\tilde{x}_{\textsf{en}\text{-}\ell}`$ (TB-CFs, Table [subtab:translation])의 효과성을 조사한다. 여기서 $`\ell \in \{\textsf{ar,de,es,hi,sw}\}`$. 구체적으로, LLMs은 Figure 2에서 보여진 세 단계 과정을 따라 영어로 역사계열을 생성한다. 그런 다음 생성된 역사계열을 대상 언어로 번역하기 위해 동일한 LLM을 사용한다 (Figure 12). 번역 품질은 자동 평가 메트릭(§10.1)과 인간 주석자(§10.2)를 통해 평가된다.
데이터셋
우리는 역사계열 생성 문헌에서 널리 연구된 두 가지 분류 작업에 초점을 맞춘다: 자연어 추론과 주제 분류. 따라서 우리는 두 개의 작업에 맞는 다언어 데이터셋을 선택하고 결과를 평가한다.
XNLI
은 언어 간 자연어 추론(NLI) 작업을 위한 것이며, 영어 MultiNLI 코퍼스를 14개 추가 언어로 번역하여 확장한다. XNLI는 전제와 가설 사이의 관계를 포함, 반대, 또는 중립으로 분류한다.
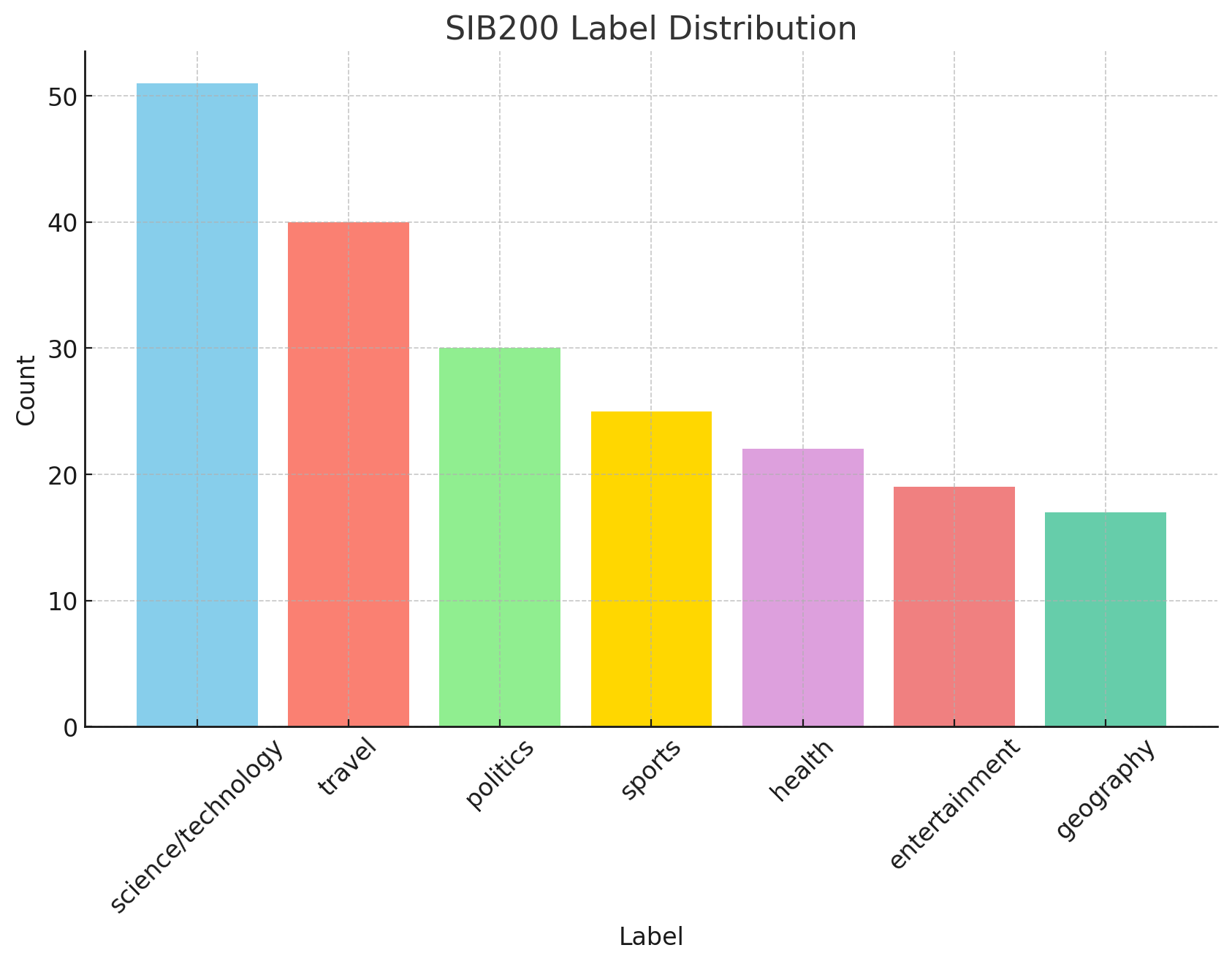
SIB200
은 205개 언어에서 주제 분류를 위한 대규모 데이터셋이다. SIB200는 문장을 과학/기술, 여행, 정치, 스포츠, 건강, 연예, 그리고 지리의 일곱 가지 주제로 분류한다.
언어 선택
XNLI와 SIB200 데이터셋 간에 겹치는 여섯 개 언어를 식별했다: 영어, 아랍어, 독일어, 스페인어, 힌디어, 그리고 스와힐리어. 이러한 언어들은 그들의 고유한 다양성을 대표하며, 널리 사용되는 언어에서 저자원 언어까지의 스펙트럼을 포괄하고 다양한 문자 체계를 포함한다.
모델
우리는 세 가지 최신 오픈 소스 지시 미세 조정 LLMs 중 하나를 선택하여 실험에 활용한다: Qwen2.5-7B , Gemma3-27B , Llama3.3-70B. 이러한 모델들은 여러 언어 지원을 제공하고, 선택된 언어가 포함된 데이터로 훈련되었다(§3.2, Appendix 9.1.1). 또한, 우리의 실험에서는 역사계열을 사용하여 다언어 BERT를 설명하려고 한다(§3.2).
평가 설정
자동 평가
우리는 세 가지 문헌에서 널리 채택된 자동 메트릭을 사용하여 생성된 다언어 역사계열을 평가한다.
라벨 플립률 (LFR)
역사계열이 원래 모델 예측을 얼마나 자주 변경하는지를 측정한다. $`N`$ 개의 인스턴스를 포함한 데이터셋에 대해 LFR은 다음과 같이 계산된다:
시퀀스에 대해 계산된 평균 음의 로그 우도의 지수이다. 이것은 텍스트 분포의 자연성을 측정하고 모델이 앞선 단어를 바탕으로 다음 단어를 얼마나 유창하게 예측할 수 있는지를 나타낸다. 주어진 시퀀스 $`\mathcal{S} = (t_1, t_2, \cdots, t_n)`$에 대해 PPL은 다음과 같이 계산된다:
GPT2은 종종 역사계열 문헌에서 PPL을 계산하는 데 사용되지만, 이는 영어 데이터만으로 학습되었기 때문에 다언어 역사계열 평가에는 적합하지 않다. 따라서 우리는 mGPT-1.3B를 사용하여 실험에서 PPL을 계산한다.
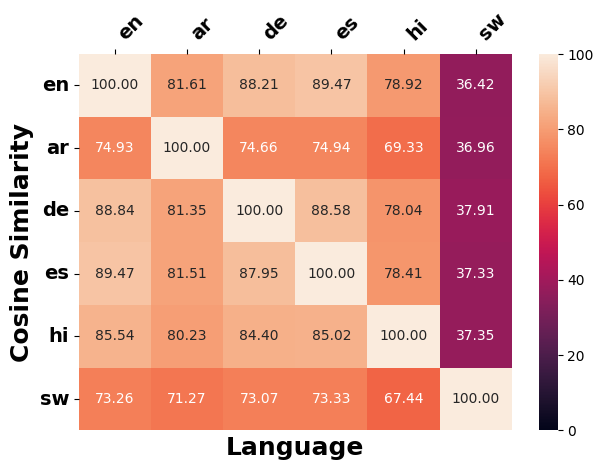
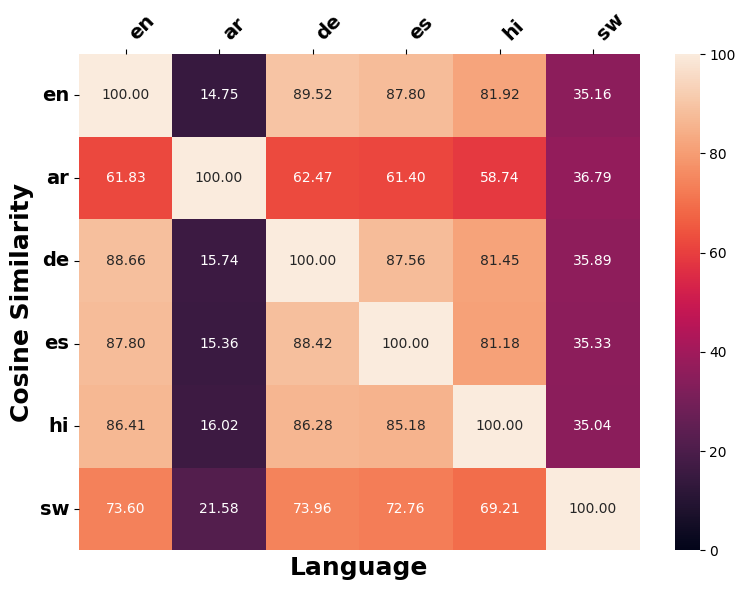
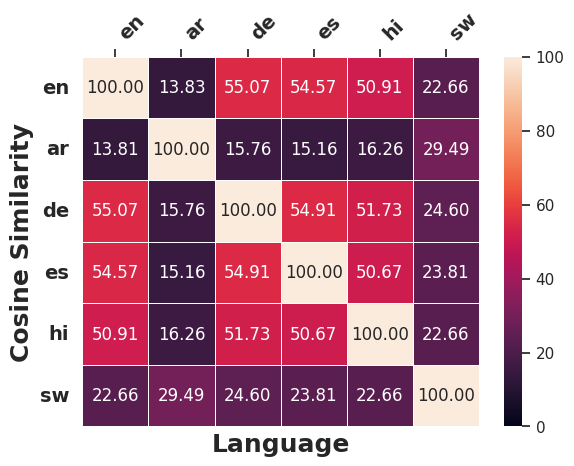
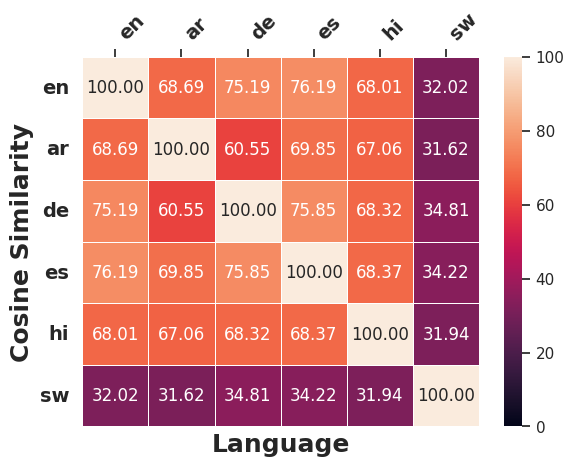
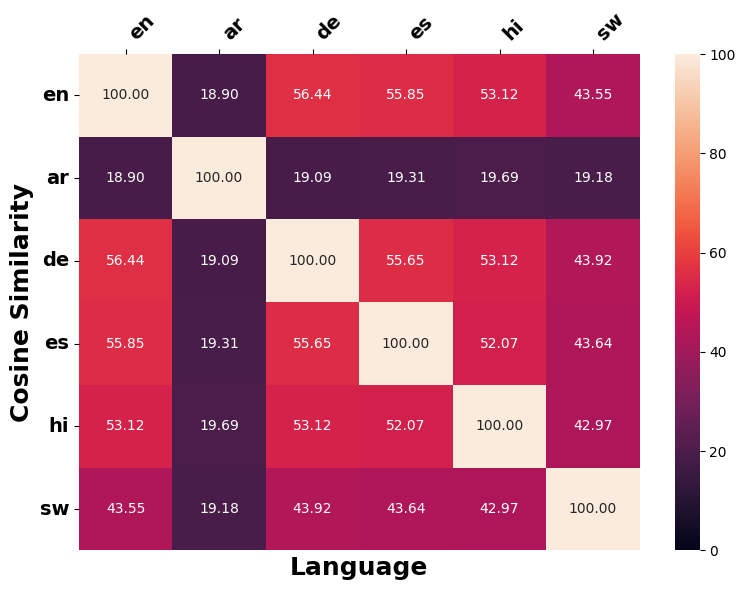
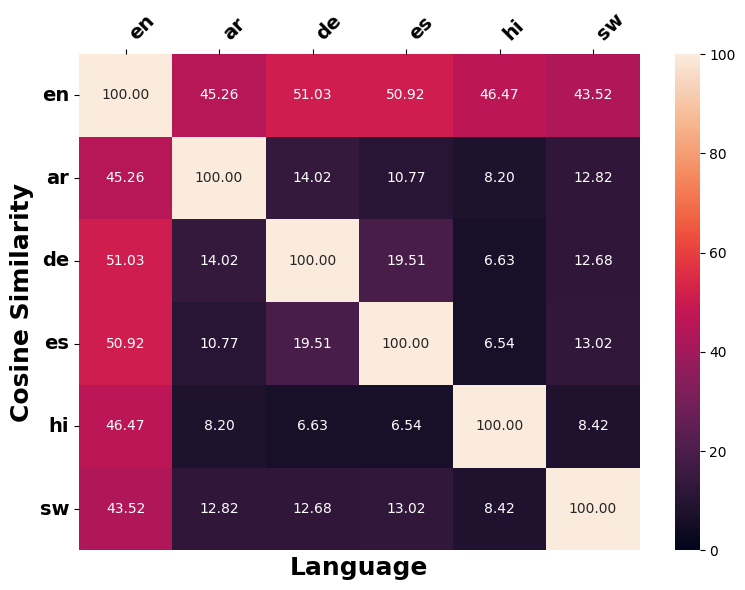
언어 간 수정 유사성
언어 간 일관성을 따르는 개념에 따라, 서로 다른 언어의 역사계열에서 원래 입력의 의미를 변경하기 위해 얼마나 일관되게 적용되는지 조사한다. 이를 위해 우리는 §5.1에서 사용된 다언어 SBERT를 채택하여 문장 임베딩 유사성을 측정한다. 이를 위해 (1) 서로 다른 대상 언어 $`\ell`$에 대한 직접 생성된 역사계열 $`\tilde{x}_{\ell}`$ 간의 쌍별 코사인 유사성 계산, (2) 직접 생성된 역사계열 $`\tilde{x}_{\ell}`$을 대상 언어 $`\ell`$에서 영어로 역 번역하여 얻은 영어 역사계열 간의 쌍별 코사인 유사성을 계량한다.