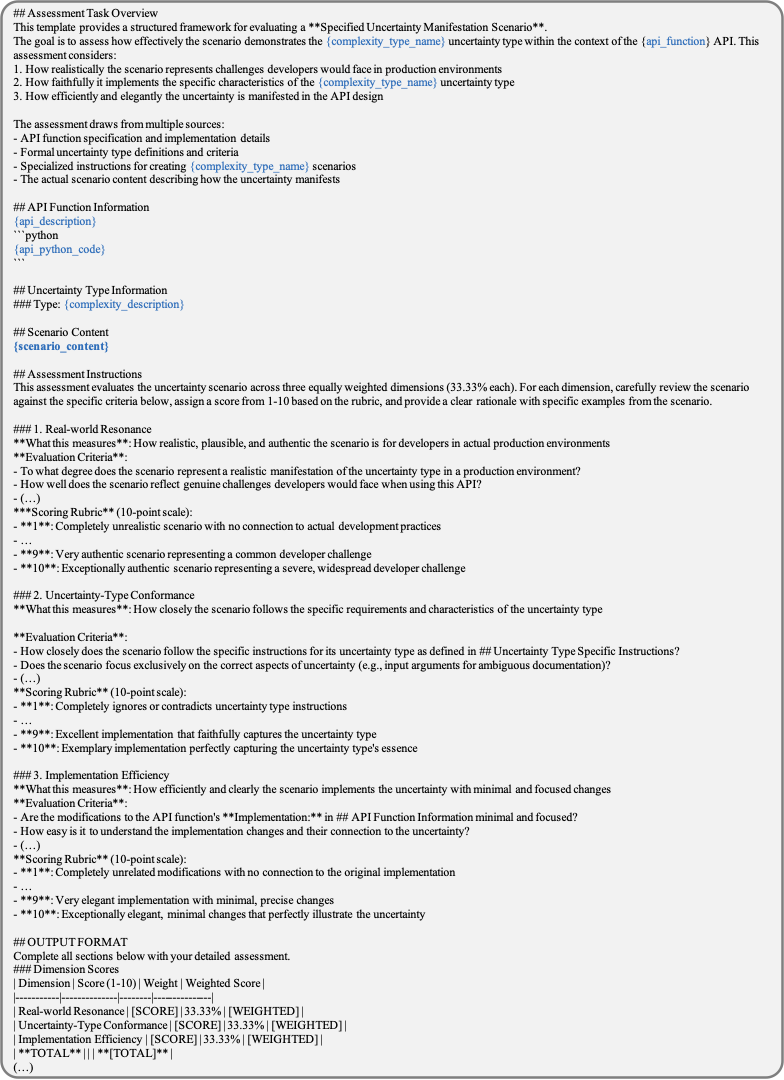
- Title: Beyond Perfect APIs A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
- ArXiv ID: 2601.00268
- 발행일: 2026-01-01
- 저자: Doyoung Kim, Zhiwei Ren, Jie Hao, Zhongkai Sun, Lichao Wang, Xiyao Ma, Zack Ye, Xu Han, Jun Yin, Heng Ji, Wei Shen, Xing Fan, Benjamin Yao, Chenlei Guo
📝 초록
이 논문은 대형 언어 모델(Large Language Model, LLM) 에이전트가 실제 API 복잡성 하에서 외부 함수를 호출하는 능력을 평가하기 위한 새로운 벤치마크인 WildAgtEval을 제안합니다. 이 벤치마크는 8개의 주요 API 복잡성 유형에 기반하며, 각 유형은 실제 월드에서 자주 발생하는 복잡성을 반영합니다. 실험 결과, LLM 에이전트는 특히 무관한 정보와 같은 복잡성 하에서 성능이 크게 저하됨을 보여줍니다.
💡 논문 해설
1. **새로운 벤치마크 WildAgtEval** : 이 논문은 대형 언어 모델(LLM) 에이전트가 실제 API 환경에서 외부 함수를 호출하는 능력을 평가하기 위한 새로운 벤치마크인 WildAgtEval을 제안합니다. 이를 통해 LLM의 실용적인 성능을 더 정확하게 측정할 수 있습니다.
2. **API 복잡성 유형** : WildAgtEval은 8개의 주요 API 복잡성 유형에 기반하며, 각 유형은 실제 월드에서 자주 발생하는 복잡성을 반영합니다. 이를 통해 LLM 에이전트가 다양한 문제 상황을 처리할 수 있는 능력을 평가할 수 있습니다.
3. **복잡성 통합 메커니즘** : 이 논문에서는 각 복잡성이 실제 월드에서 자주 발생하는 API 유형에 자연스럽게 통합되는 방식을 제안합니다.
메타포 설명
1단계: 건물 설계: WildAgtEval은 LLM 에이전트가 실제로 사용할 수 있는 복잡한 건물을 설계하고 평가하는 것과 같습니다. 이는 건물의 구조와 기능을 잘 이해하는 데 도움이 됩니다.
2단계: 시험 주행: 각 복잡성 유형은 실제 월드에서 발생할 수 있는 다양한 문제 상황을 반영하며, 이를 통해 LLM 에이전트가 이러한 문제를 어떻게 처리하는지 평가할 수 있습니다. 이는 자동차의 성능을 다양한 도로 조건에서 테스트하는 것과 유사합니다.
3단계: 실용성 검증: 실제 월드에서 복잡성이 통합되는 방식은 LLM 에이전트가 실제로 사용될 때 어떤 문제가 발생할 수 있는지 예측하고 해결책을 찾는 데 도움이 됩니다. 이는 제품의 실제 사용자 피드백을 고려하여 개선하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 서론
/>
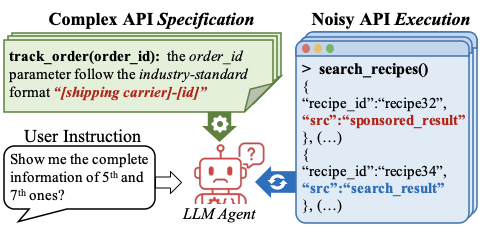
현실 세계 에이전트 배포의 도전 과제.
/>
현재 벤치마크로 인해 평가할 수 없는 에이전트 실패 사례들.WildAgtEval의 주요 동기: (a)는 실제 세계에이전트 배포의 도전 과제를 강조하고, (b)는 LLM 에이전트의 실패 모드를 드러내며 현재 벤치마크가 종종 간과하는 부분을 제공합니다.
대형 언어 모델(LLMs) 에이전트인 아마존 알렉사와 같은 것들은 LLMs의 놀라운 성능(대학 수준 수학에서 인간의 정확도를 초월하고 고위험 도메인에서 탁월한 성과를 내는 것)을 바탕으로 다양한 실제 세계 애플리케이션에 강력한 인터페이스로 빠르게 부상하고 있습니다. 이러한 역할을 평가하기 위해, 기능 호출 또는 도구 호출 벤치마크라는 점진적으로 LLM 에이전트들이 다양한 지시사항을 효과적으로 처리하고 복잡한 다단계 작업을 수행하는 능력을 평가하는 일련의 연구가 진행되고 있습니다.
그럼에도 불구하고, 대부분의 기존 벤치마크는 API 함수가 사용하기 쉽고 항상 신뢰할 수 있는 출력을 생성하는 이상화된 시나리오를 가정합니다. 그러나 Figure 3(a)에서 보듯이, 이러한 가정은 실제 세계 시나리오와 크게 다릅니다. 실용적인 배포 예를 들어 아마존 알렉사에서는 에이전트가 광범위하고 세밀한 API 사양을 철저히 준수해야 합니다(예: “도메인별” 서식 규칙 “[배송업체]-[아이디]")는 물론이고 불완전한 API 실행을 관리해야 하며 이는 종종 잡음 출력(“sponsored_result”) 또는 런타임 오류를 생성합니다.
결과적으로, 현재 벤치마크는 실제 복잡성 하에서 에이전트의 성능을 평가하지 않기 때문에 능력에 대해 지나치게 낙관적인 평가를 내립니다. 예를 들어 Figure 3(b)에서 보듯이 이러한 벤치마크는 복잡한 API 사양으로 인해 발생하는 에이전트 실패를 감지하지 못합니다. 여기서 에이전트는 필요한 형식(“UPS-16”)을 따르기보다 관련성이 있는 정보(“16”)만 사용합니다. 또한, 불완전한 API 실행 결과로 인한 실패도 포착하지 못하며 이 경우 에이전트가 잘못된 스폰서 결과에 혼란하여 적절하지 않은 콘텐츠를 추천할 수 있습니다(예: 20분짜리 요리를 요청했을 때 46분짜리 레시피).
이 격차를 해결하기 위해, 우리는 WildAgtEval이라는 새로운 벤치마크를 제안합니다. 이는 이상화된 API를 넘어서 실제 세계의 API 복잡성 하에서 LLM 에이전트가 외부 함수를 호출하는 능력을 평가합니다. 구체적으로 WildAgtEval은 이러한 실제 세계 복잡성을 고정된 기능 모음인 API 시스템에 시뮬레이션하여 사용자-에이전트 대화 중 발생하는 도전 과제를 드러냅니다(Figure 3(b)). 따라서 WildAgtEval은 (i) API 시스템과 (ii) 그에 바탕을 둔 사용자-에이전트 상호작용을 제공하며, Table [tab:contribution]에서 보듯 복잡성 유형의 광범위를 포함합니다. API 사양은 정교한 문서화와 사용 규칙을 다루며 API 실행은 런타임 도전 과제를 포착합니다. 이러한 차원을 통해 API 시스템은 60개의 특정 복잡성 시나리오를 포함하여 약 32,000개의 고유 테스트 구성이 생성됩니다. 이러한 시나리오에 대한 사용자-에이전트 상호작용은 최근 대화 생성 방법을 사용하여 생성됩니다.
중요한 고려 사항 중 하나는 API 시스템 내 복잡성 시나리오가 실제 세계의 API 환경을 정확히 반영해야 한다는 것입니다. 이를 위해 우리는 각 복잡성 유형이 기능에 따라 자연스럽게 발생한다는 통찰력을 활용하여 새로운 할당 및 주입 메커니즘을 사용합니다. 예를 들어, 무관한 정보는 정보 검색 함수에서 자주 발생합니다(예: search_recipes() in Figure 3(b)). 따라서 우리는 먼저 각 복잡성 유형을 실제 세계에서 이와 같은 복잡성을 가장 많이 겪게 될 기능에 할당하고 해당 API 구현을 수정하여 이러한 복잡성을 주입합니다.
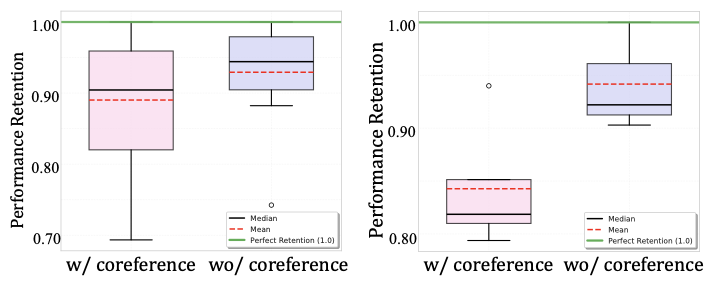
WildAgtEval에 대한 평가 결과, 대부분의 복잡성 시나리오는 강력한 LLM 에이전트(Claude-4-Sonnet)의 성능을 일관되게 저하시킵니다. 특히 무관한 정보 복잡성이 가장 큰 도전으로 작용하여 평균 성능 하락률 27.3%를 보입니다. 또한, 여러 복잡성들이 쌓이면 최대 63.2%의 성능 저하가 발생합니다. 양적 분석은 LLMs가 해결할 수 없는 작업에 대해 계속해서 시도함으로써 사용자 의도를 왜곡하고 오해의 소지가 있는 성공 응답을 생성한다는 것을 보여줍니다.
관련 연구
API 기반 벤치마크 for LLM 에이전트
기존 API 기반 벤치마크는 함수 종속성을 통해 다단계 추론에 초점을 맞추어 에이전트 평가를 발전시켰습니다. BFCLv3과 $`\tau`$-bench는 연속적인 의존성 시나리오(예: search_media() → play() 재생)를 도입합니다. 또한, ComplexFuncBench는 다단계 작업에 사용자 제약 조건을 통합하고 NESTful은 수학적 영역으로 확장합니다. 그 외에도 Incomplete-APIBank와 ToolSandbox는 각각 에이전트에게 누락된 API 및 서비스 상태 변동에 대한 탄력성을 평가합니다. 그럼에도 불구하고, 이전 벤치마크는 여전히 실제 세계의 API 복잡성(표 [tab:contribution])을 충분히 반영하지 못해 지나치게 낙관적인 평가를 내립니다. 본 연구는 이러한 격차를 메꾸기 위해 그러한 복잡성을 에이전트 평가에 통합합니다.
사용자 기반 벤치마크 for LLM 에이전트
사용자 기반 벤치마크는 다양한 복잡도의 실제 세계 사용자 지시사항을 충족하는지 여부를 평가합니다. MT-Eval, Multi-Turn-Instruct, Lost-In-Conv은 다중 라운드 상호작용에서 에이전트가 다양한 사용자 지시사항을 얼마나 잘 처리하는지를 평가하며 의도 해석, 다중 의도 계획 및 선호도 추출과 같은 도전 과제를 강조합니다. IHEval와 UserBench는 각각 사용자의 의도가 충돌하거나 변화하는 시나리오를 추가로 포함하여 이러한 평가를 확장합니다. 그럼에도 불구하고, 그들은 일반적으로 도구 호출에 관련된 복잡성, 예를 들어 복잡한 API 사양이나 잡음 있는 API 실행을 간과합니다.
WildAgtEval: API 복잡성 하에서 LLM 에이전트 평가
우리는 WildAgtEval을 제안하여 외부 함수를 호출하는 LLM 에이전트의 견고성을 실제 세계 API 복잡성 하에서 평가할 수 있는 벤치마크로 활용합니다. 이전 연구에 따르면, 에이전트는 (i) 실행 가능한 API 시스템과 (ii) 사용자-에이전트 상호작용의 일련(이하 대화라고 함)을 받은 다음 적절한 API 호출을 통해 응답을 생성합니다.
WildAgtEval은 기존 벤치마크를 발전시켜 실제 세계 에이전트 도전 과제를 더 잘 반영합니다. 실무에서 자주 관찰되는 8개의 API 복잡성 유형을 소개하고 이를 실제 사용 패턴에 따라 API 시스템에 통합합니다. 결과적으로 WildAgtEval은 60가지 다른 복잡성 시나리오를 포함하며 약 32,000가지 고유 테스트 구성의 가능성을 제공합니다.
API 복잡성 분류
표 [tab:api_complexity_taxonomy]는 API 사양과 실행 단계에 걸친 8개 유형의 API 복잡성을 설명하며 Figure 4는 이러한 복잡성이 각 API 함수에서 어떻게 나타나는지 에이전트에게 보여주는 프롬프트를 시각화합니다. 사양 복잡성은 에이전트가 읽는 데 영향을 줍니다. 애전트의 프롬프트 내에서 이러한 복잡성은 “API 함수” 및 “지시사항” 섹션에 나타나며 프롬프트 생성 동안 일관되게 포함됩니다(그림 4 참조). 반면, 실행 복잡성은 에이전트가 API 호출을 수행한 후 관찰하는 데 영향을 줍니다. 이들은 에이전트에 의해 호출된 API 호출에 따라 후속 프롬프트에 도입됩니다. [C6]에서 보듯이, 에이전트가 stock_price()를 호출하면 다음 프롬프트에는 무관한 정보(“AAPL (스폰서)")가 포함되어 잡음 출력을 필터링하거나 조정해야 합니다.
실제 세계 복잡성 통합
각 복잡성 유형은 특정 기능 카테고리에서 자연스럽게 발생하며 그 핵심 기능(예: 정보 검색)에 반영됩니다. 이 관찰 결과를 바탕으로, 우리는 각 복잡성 유형을 먼저 실제 세계에서 해당 복잡성을 가장 많이 겪게 될 것으로 예상되는 기능에 할당하고 이후 주입하는 할당 및 주입 복잡성 통합 메커니즘을 사용합니다. 예를 들어 무관한 정보 복잡성이 정보 검색 함수인 stock_price()로 할당 및 주입됩니다. 또한 모든 복잡성 유형이 관련 기능에 자연스럽게 할당되도록 우리의 API 시스템은 충분히 다양한 기능을 포함하도록 구성합니다.
복잡성 통합을 통한 벤치마크 구축
/>
WildAgtEval에서 LLM 에이전트의 프롬프트, 사양 수준 복잡성—기본 매개변수 규칙, 유사하지만 기능적으로 다른 함수, 도메인 특정 종속성 및 문서화되지 않은 세부사항 ([C1–C4])와 함께 실행 수준 복잡성—동반 함수 알림, 무관한 스폰서 콘텐츠, 암시적 대체를 통한 부분 실패 및 암호화된 오류 코드를 사용한 완전 실패 ([C5–C8]). style="width:100.0%" />
WildAgtEval 구축 개요.
개요
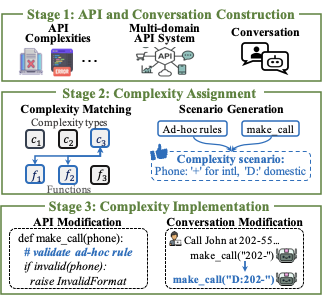
그림 5는 WildAgtEval을 구성하는 할당 및 주입 프로세스를 설명하며 다음과 같이 구성됩니다:
단계 1: 다중 도메인 API 시스템과 그 시스템에 근거한 대화를 구축합니다.
단계 2: 복잡성을 관련 기능에 할당하고 구체적인 복잡성 시나리오를 생성합니다.
단계 3: 이러한 시나리오를 API 함수에 주입하며 필요에 따라 대화에도 주입합니다.
단계 1: 다중 도메인 API 시스템 및 대화 구축
API 시스템 구성. 모든 복잡성 유형에 자연스럽게 통합되도록, 우리는 7개의 일반적으로 사용되는 도메인(예: 장치 제어, 정보 검색)을 포괄하는 86개의 API 함수를 포함한 포괄적인 다중 도메인 API 시스템을 개발합니다. 각 기능은 완전히 실행 가능하며 관련 데이터베이스와 정책과 함께 제공됩니다. 광범위한 도메인 커버리지와 정책 제약 조건으로 인해 LLM 에이전트를 위한 API 사용 설명 프롬프트는 약 34,000 토큰에 이릅니다.
대화 구성. 우리는 대화 생성 프레임워크를 채택하여 정확한 API 호출 주석을 포함하는 다중 라운드 대화를 생성합니다. 그림 11에서 보듯이, 과정은 검증된 의도 원시 단위를 수집하여 특정 사용자 목표(“영화 보기”)와 해당 API 호출(“search_media()”, “power_on()”, “play()")을 포함한 작업입니다. 이어서 LLM은 이러한 원시 단위를 더 긴 상호작용 시나리오로 구성하여 실제 대화를 보장합니다. 모든 합성된 대화는 대화 맥락의 일관성과 관련 API 호출 주석의 정확성을 확인하기 위해 사후 생성 검증을 거칩니다. 결과 데이터셋은 300개의 다중 라운드 대화로 구성되며 총 3,525개의 에이전트 API 호출이 필요하며 각 대화는 평균적으로 약 4.7개의 사용자-에이전트 회차와 2.5개의 회차당 API 호출을 포함합니다.
API 시스템 및 대화 구성에 대한 추가 정보는 부록 7.1 참조.
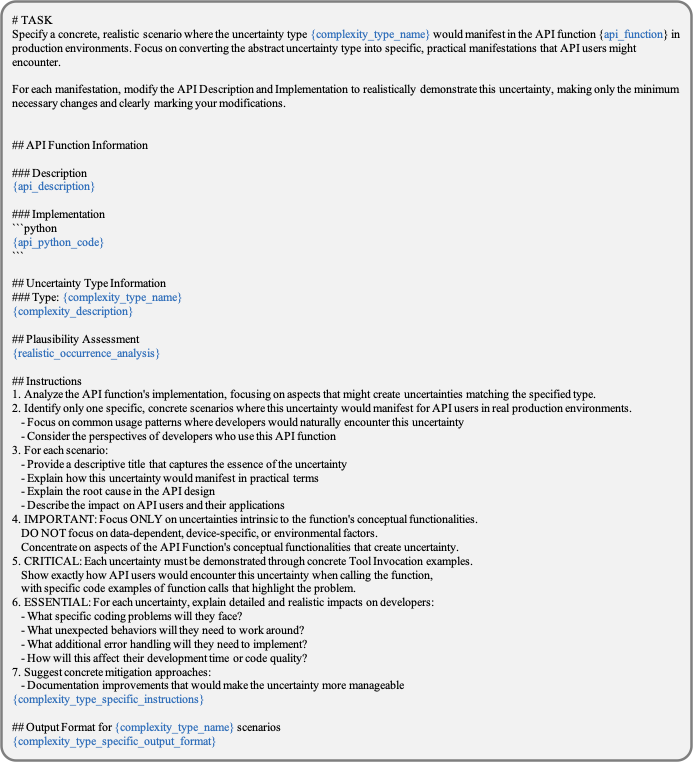
단계 2: 복잡성 할당
우리는 각 복잡성이 실제 세계에서 발생할 가능성을 평가하여 관련 복잡성-기능 쌍을 식별하고 이를 고도로 관련된 쌍에 대한 구체적인 시나리오를 생성합니다.
관련성 기반 복잡성 매칭. 다중 도메인 API 시스템과 복잡성 유형 집합 $`\mathcal{C}`$가 주어졌다고 가정하겠습니다. 각 복잡성 유형 $`c \in \mathcal{C}`$에 대해, 우리는 가장 관련성이 높은 함수의 하위집합 $`\mathcal{F}^*_c \subset \mathcal{F}`$를 찾고자 합니다(예: $`\mathcal{F}^*_{c_3}=\{f_1,f_2\}`$ in Figure 5). 구체적으로, 각 쌍 $`(c, f)`$에 대해 우리는 실제 세계에서 발생할 가능성을 양화하기 위해 관련성 점수 $`{\rm r}_{c,f}`$를 정의합니다. 이 점수는 지시사항을 따르는 언어 모델과 관련성 평가 템플릿 $`\mathcal{I}_{\text{rel}}`$를 사용하여 다음과 같이 얻습니다: