- Title: BERT-JEPA Reorganizing CLS Embeddings for Language-Invariant Semantics
- ArXiv ID: 2601.00366
- 발행일: 2026-01-01
- 저자: Taj Gillin, Adam Lalani, Kenneth Zhang, Marcel Mateos Salles
📝 초록
BERT와 그 후속 모델들은 NLP 작업을 위해 풍부한 임베딩을 생성하는데 사용된다. 하지만 이러한 임베딩은 언어의 진정한 표현을 포착하지 못한다. 이 연구는 BERT를 새로운 학습 아키텍처인 Joint-Embedding Predictive Architectures (JEPA)를 통해 훈련하여, 문장과 정보의 진정한 의미만을 나타내도록 가르치려고 한다. 이를 위해 BERT-JEPA (BEPA)라는 새로운 학습 패러다임을 제시하며, 이는 \[CLS\] 임베딩 공간을 재구조화하고 다언어 작업에서 성능을 향상시키며, PCA 표현을 더 포괄적인 형태로 변화시킨다는 결과를 보여준다.
💡 논문 해설
1. **\[CLS\] 임베딩 공간의 재구조화:** BERT-JEPA (BEPA)는 \[CLS\] 임베딩 공간을 의미 중심 구조로 재구성한다. 이는 마치 책의 목차를 처음부터 다시 작성하는 것과 같다.
2. **PCA 표현의 변화:** BEPA 훈련은 PCA 표현을 낮은 등급에서 더 포괄적인 형태로 바꾼다. 이는 사진의 색상 범위를 넓히는 것과 비슷하다.
3. **영어 성능 유지와 다언어 작업 개선:** BEPA 훈련은 영어 성능에 거의 영향을 미치지 않으면서, 다언어 작업에서 성능을 향상시킨다. 이는 한 언어로 작성된 책을 여러 언어로 번역하면서 원래 의미를 유지하는 것과 같다고 할 수 있다.
📄 논문 발췌 (ArXiv Source)
# 개요
BERT와 그 후속 모델들은 NLP 작업을 위해 풍부한 임베딩을 생성하는데 사용된다. 많은 하류 작업에서 BERT 임베딩은 쉽게 빼내어 경쟁력 있는 성능을 달성하는 데 활용될 수 있다. 그러나 이러한 임베딩은 언어의 진정한 표현을 포착하지 못한다. [CLS] 토큰, 하류 작업에 가장 자주 사용되는 것은 문장 유사도 작업에서 문장을 적절히 이해하는데 부족하다는 것이 발견되었다.
언어는 다양한 구문과 구조를 통해 의미를 유지하는 사고의 구체적인 표현이다. 이것은 스페인어와 영어 간의 기본 번역에 반영된다: “El gato es rojo"와 “The cat is red”. 이들은 각각 독립된 언어 시스템을 통해 동일한 의도와 사고를 전달하고 포함한다. 따라서 우리는 다음과 같은 질문을 제기한다: BERT는 언어 시스템에 독립적이면서 문장과 정보의 진정한 의미만을 나타내도록 가르칠 수 있을까?
우리는 JEPA(Joint-Embedding Predictive Architectures)라는 새로운 논문을 찾아보았다. JEPA는 두 가지 다른 샘플 사이에서 잠재적인 표현을 예측하는 것에 중점을 둔다. 최근 이러한 아키텍처들은 비전과 언어 작업, 특히 코드-텍스트 작업에서 희망적인 결과를 보여주었다.
이는 일반 언어로 자연스럽게 확장되어 모델이 같은 의미를 가진 샘플로부터 다른 샘플의 임베딩을 예측하도록 학습할 수 있다. 이는 공유된 임베딩 공간, 이를 우리는 “사고 공간"이라고 부른다. 이 풍부한 임베딩 공간은 인간이 언어 위에 가지고 있는 추상화와 대응하며 우리의 사고를 나타낸다.
우리는 새로운 학습 패러다임인 BERT-JEPA (BEPA)을 제시한다. BEPA는 JEPA를 활용하여 풍부한 문맥적 이해력을 구축하는 데 초점을 맞춘다. 다음의 결과가 나왔다:
BEPA 재훈련은 [CLS] 임베딩 공간을 의미 중심 구조로 대폭 재구성한다.
BEPA 재훈련은 PCA 표현을 낮은 등급에서 더 포괄적인 형태로 변화시킨다.
[CLS] 임베딩의 재구성이 영어 성능에 거의 손실을 초래하지 않는다.
BEPA 재훈련은 다언어 작업에서 성능을 향상시킨다.
배경
NLP 분야는 지난 6년 동안 크게 변화했다. BERT의 출현은 트랜스포머 아키텍처를 활용하여 하류 작업에 대한 풍부한 임베딩을 생성할 수 있는 깊은 네트워크를 구축함으로써 언어 이해 분야를 혁명화했다. BERT는 마스킹된 언어 모델링 (MLM)과 같은 새로운 사전 학습 작업을 소개했으며, 이는 BERT의 양방향 주의 기능이 제대로 작동할 수 있도록 한다.
BERT에 이은 모델들인 RoBERTa와 XLM-RoBERTa는 더 긴 훈련과 필요하지 않은 학습 작업인 다음 문장 예측 (NSP) 및 번역 언어 모델링 (TLM)을 제거함으로써 BERT를 개선했다. 이러한 모델들은 강력한 잠재 표현에 집중함으로써 다양한 벤치마크에서 기초적인 BERT보다 성능을 크게 향상시켰다. 실험에서는 RoBERTa와 XLM-RoBERTa를 기본값 및 비교 대상으로 사용한다.
불행히도, 이러한 언어 모델들은 여전히 언어에 특정된 특성을 인코딩하는 경향이 있어, 예제에 작은 의미 보존적인 변경만으로도 모델의 동작과 예측이 바뀔 수 있다. 이는 언어 모델들이 아직 언어에 대한 불변성이 되지 못했다는 것을 의미한다.
JEPA(Joint-Embedding Predictive Architectures)는 모델을 훈련하는 방식을 변화시켰다. JEPA는 입력 공간에서 모델을 정렬하는 대신 임베딩 공간에서 모델을 정렬함으로써 더 강력한 표현과 이해력을 생성한다. 실제로 이러한 아키텍처들은 확장 가능하며 비전 작업에서 기존 방법들과 경쟁하거나 우수한 성능을 보여주었다. 이들 모델에서 생성된 임베딩은 풍부한 문맥을 가지고 있으며 가장 중요한 특징으로 구성되어 있다.
최근에는 언어 작업에 대한 JEPA 변형이 소개되었으며, NL-Regex와 NL-SQL 사례에서는 인상적인 성능을 보여주었다. 우리는 이 논문에서 영감을 받아 BERT 및 그 변종 모델들로 더 풍부한 임베딩 공간을 구축하기 위해 JEPA를 적용하려고 한다.
우리의 새로운 임베딩의 질을 평가하기 위해 다양한 벤치마크와 기술을 사용할 계획이다. 일반적으로 BERT 및 그 변종 모델들은 SST-2에서 벤치마킹된다. STS 크로스링구얼 데이터셋은 언어 간 의미 표현이 일치하는지, BEPA가 언어를 추상화하는 데 성공했는지를 이해하는데 사용될 수 있다. 하류 평가 외에도 t-SNE 시각화 및 이성질과 같은 진단 방법을 이용해 우리의 임베딩의 특성을 연구할 수 있다.
방법: 새로운 JEPA 스타일 BERT 재훈련 프레임워크
이 섹션에서는 BEPA(BERT-JEPA)를 사용하여 BERT 유형 모델을 훈련하는 데 사용되는 트레이닝 리그멘드에 대해 설명한다. 완전한 프레임워크 세부 사항은 7.5를 참조하라. 학습 세부 사항 및 하이퍼파라미터는 7.3에서 확인할 수 있으며, 해당 저장소 및 세부 사항은 7.4를 참조하라.
BEPA 프레임워크
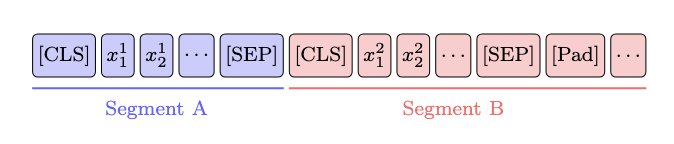
우리의 새로운 BERT 학습 방법은 현재 BERT 모델의 임베딩 공간을 언어 시스템에 독립적이도록 변환하고 알려진 CLS-토큰 붕괴를 수정한다. 우리는 기본 사전 훈련된 RoBERTa 모델 (xlm-roberta-base)을 사용하지만, BERT 유형의 모든 모델이 가능하다. 두 문장을 옆에 배치하고 이를 단일 트랜스포머 입력으로 구성한다.
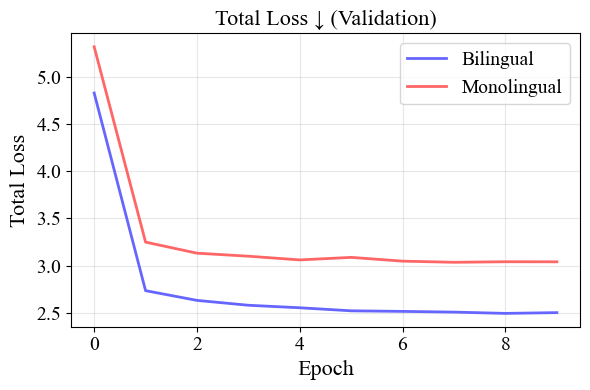
독립적으로 우리는 이 설정을 위한 두 가지 다른 방법을 테스트했다: monolingual 및 bilingual. monolingual은 같은 언어의 샘플만 옆에 배치하고 bilingual은 서로 다른 언어의 샘플도 함께 패키징할 수 있다. 본 논문은 주로 bilingual 패키징 전략의 결과를 중점으로 다루며, monolingual과 기타 변형 결과는 7.9 참조하라.
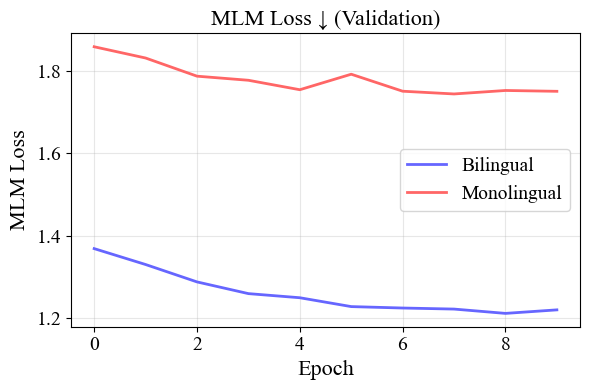
이 설정은 BERT의 고전적인 MLM 학습을 거친다. 이를 통해 BERT 유형 트랜스포머의 강력한 언어적 능력을 유지한다.
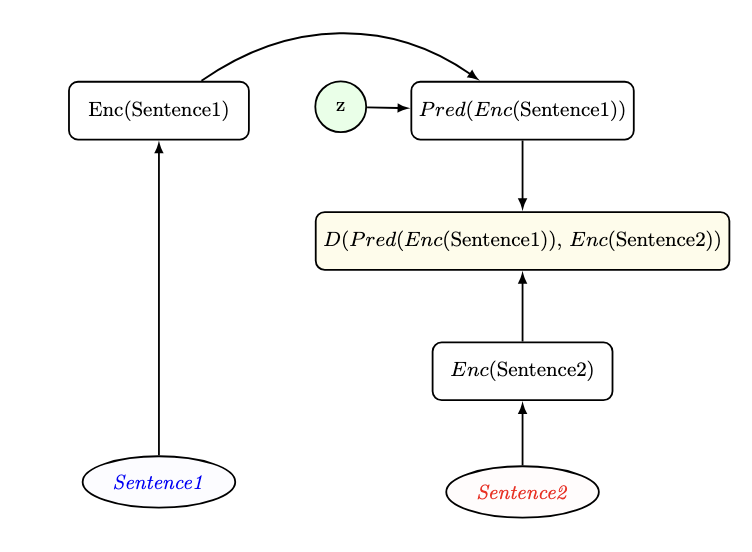
그런 다음 BEPA 프레임워크의 새로운 부분으로 넘어간다. BERT 유형 모델들은 마지막 층 [CLS] 토큰을 시퀀스의 잠재 표현으로 취급하므로, 우리는 [CLS] 토큰을 가져와 언어 간 불변성을 장려하는 정렬 손실을 계산한다. 각 개별 문장을 마스킹한 두 가지 다른 순방향 패스를 수행했다는 점에서 7 참조하라.
각 문장의 [CLS] 토큰의 잠재 표현을 가져와 $`L_{Alignment}`$를 통해 정렬한다. 더 자세한 내용은 3.2 참조하라. 우리는 [CLS] 토큰을 정렬하기 전에 동일성 예측기를 활용했지만, 미래의 연구에서는 다른 유형과 스타일의 예측기를 시험해야 한다.
BEPA 손실
우리가 선택한 손실은 기본 손실이 될 수 없으며, BEPA를 위한 두 가지 학습 목표를 고려해야 한다. BERT 유형 MLM 및 CLS-토큰 JEPA 정렬 결과 새로운 학습 목표는 다음과 같다:
MATH
L_{BEPA} = L_{MLM} + \lambda L_{Alignment}
클릭하여 더 보기
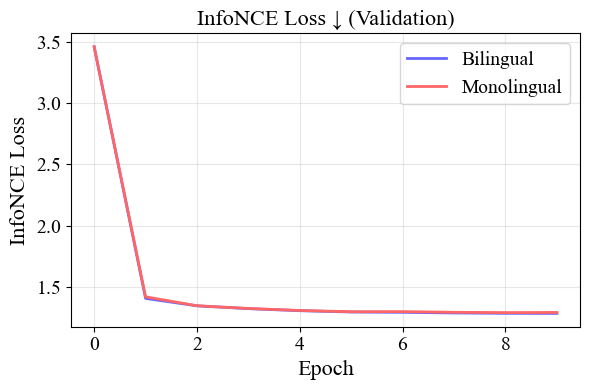
여기서 $`\lambda`$는 $`L_{Alignment}`$에 얼마나 큰 중요성을 부여할지 결정하는 하이퍼파라미터다. 우리는 Cross Entropy와 유사하게 $`L_{MLM}`$을 사용했으며, $`L_{Alignment}`$로 InfoNCE가 가장 효과적이었다. 미래의 연구에서는 SigREG과 같은 다른 목적에 대한 영향을 시험해야 한다.
프레임워크는 완전히 확장 가능하며 현재 손실은 사용자가 필요로 하는 어떤 손실로도 교체될 수 있다. 우리는 정렬 작업에서 MSE와 Cosine Similarity가 [CLS] 붕괴를 극복하지 못하므로 효과적이지 않음을 발견했다.
BEPA 훈련이 의미적으로 CLS 임베딩 공간을 재구성한다
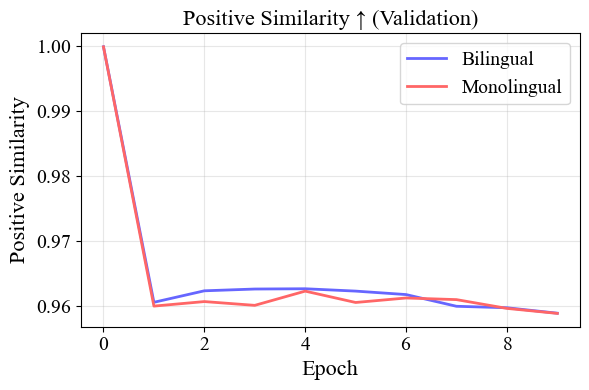
이 섹션에서는 BEPA 재훈련 후의 결과 [CLS] 공간을 연구한다. 재훈련 전, BERT 유형 모델들은 붕괴된 임베딩 공간을 보여주었다. 이를 7.6에서 볼 수 있으며, 특히 [collapsed-cls-full-roberta,collapsed-cls-full-xlm]에서, 의미적으로 유사하거나 아닌 어떤 쌍도 높은 코사인 유사성을 보였다. 이 경향은 RoBERTa와 XLM-RoBERTa 모두에 걸쳐 보였으며.
그러나 BEPA 재훈련 후, 다른 이야기가 나타난다. 우리의 모델들은 의미적으로 유사한 쌍 (언어 내부 및 간)에서 높은 정렬을 보여주고, 의미적으로 다르거나 같은 쌍에서는 더 낮은 수준의 정렬을 보였다. 이를 확인하려면 17과 7.8 참조하라.
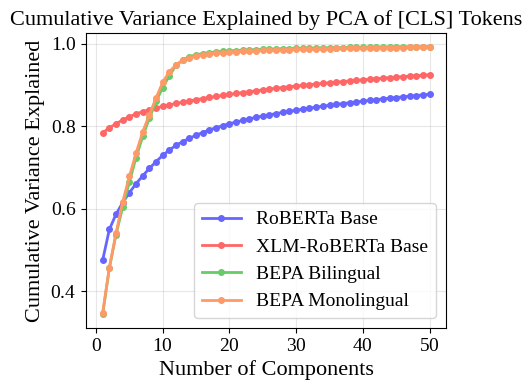
재구성된 [CLS] 임베딩을 더 연구하기 위해 PCA를 수행하여 공간의 각 구성 요소에 대한 분산을 설명했다. 우리는 monolingual 및 bilingual 모델이 분산을 더 많은 주요 구성 요소에 걸쳐 배포함을 발견했으며, 이는 더 많은 임베딩 차원이 정보가 있으며 따라서 그들의 [CLS] 표현이 덜 중복된다는 것을 의미한다. 이를 1에서 볼 수 있다.
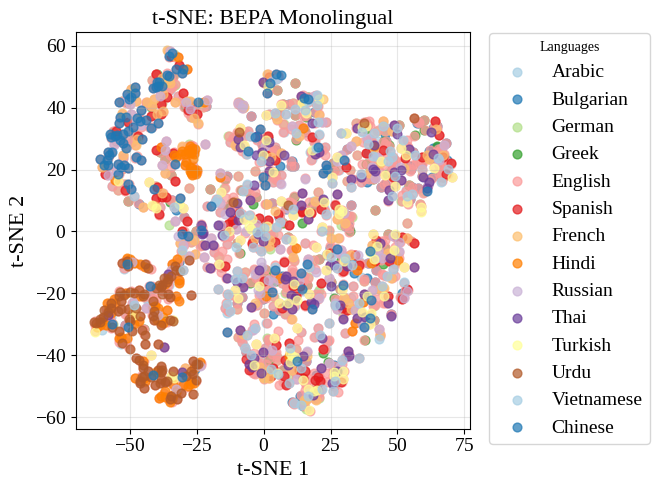
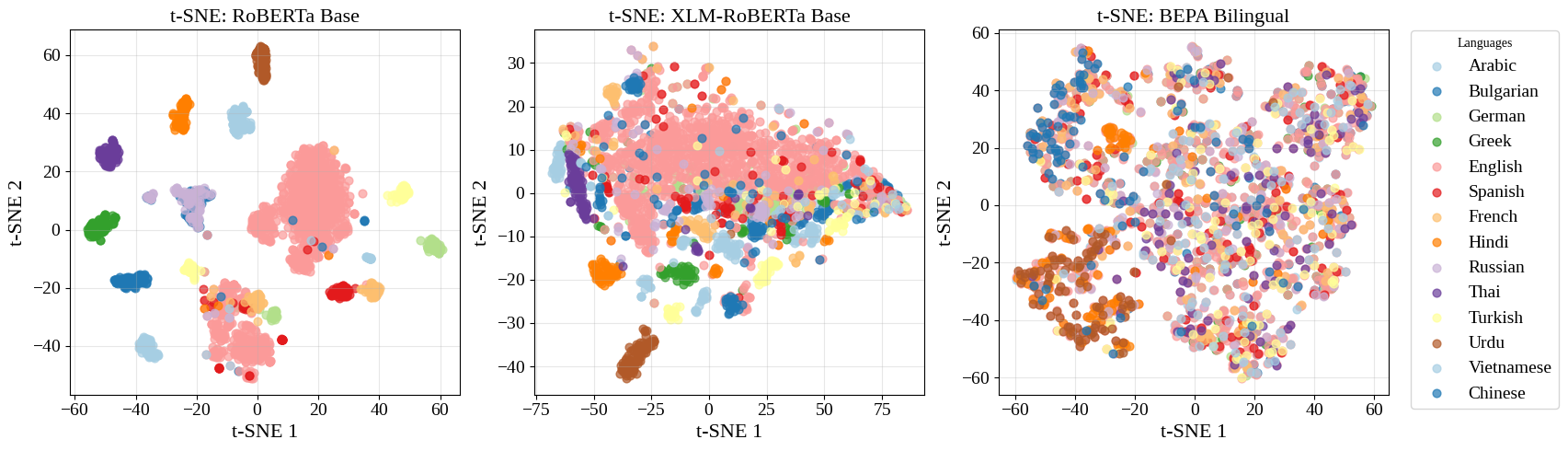
또한, RoBERTa와 XLM-RoBERTa의 [CLS] 임베딩에 대한 t-SNE 시각화는 언어별 클러스터를 보여주지만, 우리의 monolingual 및 bilingual 모델은 언어 간 더 많은 겹침을 나타내며, 이는 더욱 언어 불변적인 임베딩 공간을 의미한다. 이러한 클러스터는 2에서 찾을 수 있다.
PCA 플롯은 \[CLS\] 임베딩 공간의 각 구성 요소에 대한 분산을 보여준다. BEPA 재훈련은 (↑) 높은 분산 구성 요소의 수를 증가시킨다. 반면, 표준 RoBERTa와 XLM-RoBERTa는 각각 47%와 78%의 대부분의 분산을 단일 구성 요소에서 보여주는 반면, BEPA 모델은 첫 번째 구성 요소에서 34%를 보인다.
(왼쪽): RoBERTa의 t-SNE 플롯, 샘플은 언어별로 밀접하게 분포하며 영어는 큰 범위를 가진 독특하다. (중간): XLM-RoBERTa의 t-SNE 플롯, 일부 언어들은 RoBERTa와 유사하게 고립되어 있지만 덜 밀집되게 배치되었다. 많은 언어들, 특히 영어는 더 큰 공간을 차지하며 여러 언어와 공유한다. (오른쪽): BEPA Bilingual의 t-SNE 플롯, 언어들은 균형 있게 겹쳐 분포한다. BEPA는 언어 간에 공유되고 정렬된 공간을 만든다.. 우리의 재훈련된 BEPA Monolingual 모델 결과는 14 참조하라.
의미적으로 구조화된 토큰 공간이 다언어 전환을 개선한다
이 섹션에서는 우리의 BEPA 재훈련 모델의 벤치마크 성능에 대해 설명한다. 우리는 GLUE, XNLI 및 MLQA를 사용하여 테스트한다. 이러한 벤치마크의 완전한 결과는 7.9 참조하라.
우리는 XNLI 벤치마크를 실행하여 BEPA 재훈련이 BERT 유형 모델이 문장 수준의 의미를 이해하고 이를 언어 간에 적용할 수 있는지 테스트했다. 이 BEPA 재훈련 모델들이 “사고 공간"을 통해 사고한다면, 그들은 언어 간 더 정확하게 수행해야 한다.
XNLI 벤치마크를 실행하기 위해 우리는 영어에서 두 에폭 동안 재훈련하고 나머지 모든 언어에 대한 제로샷 평가를 진행했다. 우리의 모델 결과는 [tab:xnli_results,tab:xnli_results_app] 참조하라. 우리는 BEPA 재훈련 (특히 Bilingual 패키지 설정)이 모든 언어에서 일관된 성능 향상을 보여주며 더 나은 언어 불변성 및 의미적으로 정렬된 [CLS] 임베딩 공간을 강조한다.
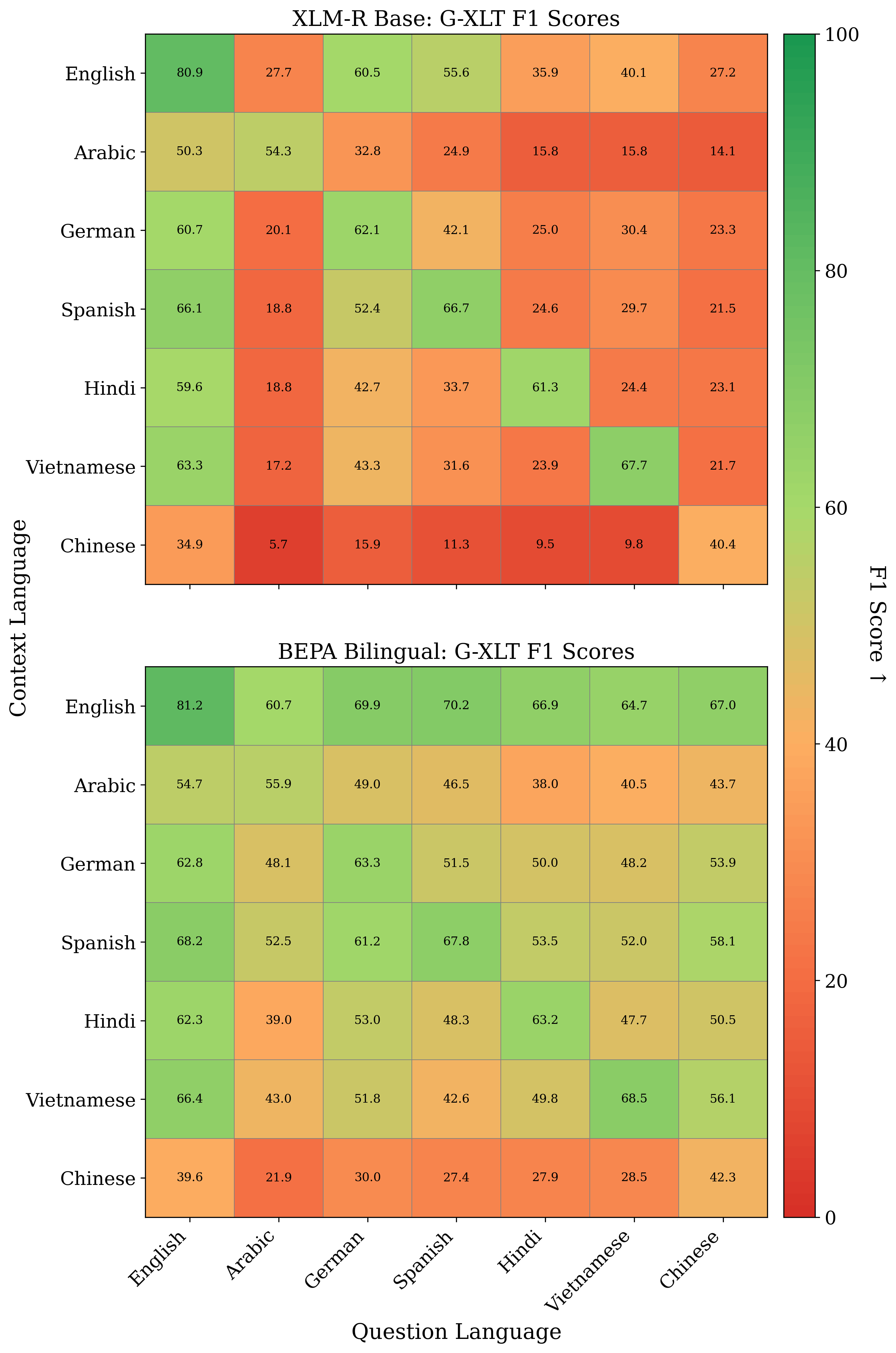
MLQA 벤치마크의 성능 G-XLT 매트릭스. 49개 언어 쌍에 대한 F1 점수 (7개 컨텍스트 언어 × 7개 질문 언어). 대각성분은 단일 언어 성능을 나타내며, 비대각성분은 다언어 전환을 보여준다. (위): XLM-RoBERTa Base는 단일 언어 작업에서 강력한 성능을 보이지만 특히 영어가 아닌 경우에 크게 어려움을 겪는다. (아래): BEPA Bilingual은 다언어 전환에서 향상된 성능을 보이며, 언어 쌍 간 일관성 있는 성능을 유지하면서 강력한 단일 언어 성능을 유지한다. 이는 BEPA가 표현 공간에서 토큰 수준의 의미 정렬을 배운다는 것을 나타낸다.
우리는 MLQA (Multilingual Question Answering) 벤치마크를 실행하여 우리의 BEPA 재훈련이 BERT 유형 모델이 언어 간 토큰 수준에서 정보를 이해하고 추출하는 데 도움이 되는지 테스트한다. XNLI와 달리 문장 수준 분류를 평가하는 대신 MLQA는 추출적 질문 답변 작업을 요구하며 모델은 컨텍스트 단락 내의 특정 답변 구간을 식별해야 한다.
BEPA 재훈련 모델이 표현 공간에서 더 나은 의미 정렬을 달성하면, 언어 간 토큰 수준 추론 능력을 더욱 효과적으로 전환할 수 있다. MLQA 벤치마크를 실행하기 위해 우리는 영어 SQuAD v1.1에서 두 에폭 동안 재훈련하고 모든 49개 언어 쌍에 대한 제로샷 평가 (7 × 7 G-XLT 매트릭스)를 진행했다.
우리는 단일 언어(동일한 컨텍스트 및 질문 언어)와 다언어(다른 컨텍스트 및 질문 언어) 구성에서 F1 점수를 보고한다. 결과는 3 참조하라. 단일 언어 설정에 대한 성능은 두 모델 모두 유사하고 우수하지만 다언어 전환에서 BEPA Bilingual이 향상된 성능을 보인다.