- Title: Conformal Prediction Under Distribution Shift A COVID-19 Natural Experiment
- ArXiv ID: 2601.00908
- 발행일: 2026-01-01
- 저자: Chorok Lee
📝 초록
공급망 데이터를 이용하여 분포 변경 상황에서 확률 예측의 성능 변화와 그 원인을 분석했습니다. 코로나19 시기의 특이 사례를 통해, 새로운 특징 값이 나타날 때 예측 성능이 어떻게 떨어지는지 살펴보았습니다.
💡 논문 해설
1. **성능 평가**: 공급망 데이터에서 분포 변경이 있을 때 확률 예측의 성능이 얼마나 떨어지는지 측정했습니다. 성능은 0%에서 86.7%까지 다양하게 변동하였습니다.
2. **예측 신호 찾기**: SHAP 분석을 통해, 특정 특징에 의존하는 모델이 더 큰 성능 하락을 보이는 경향이 있음을 발견했습니다. 이는 마치 한 가지 재료만 사용한 레시피가 다른 재료로 바뀌면 맛이 달라지는 것과 같습니다.
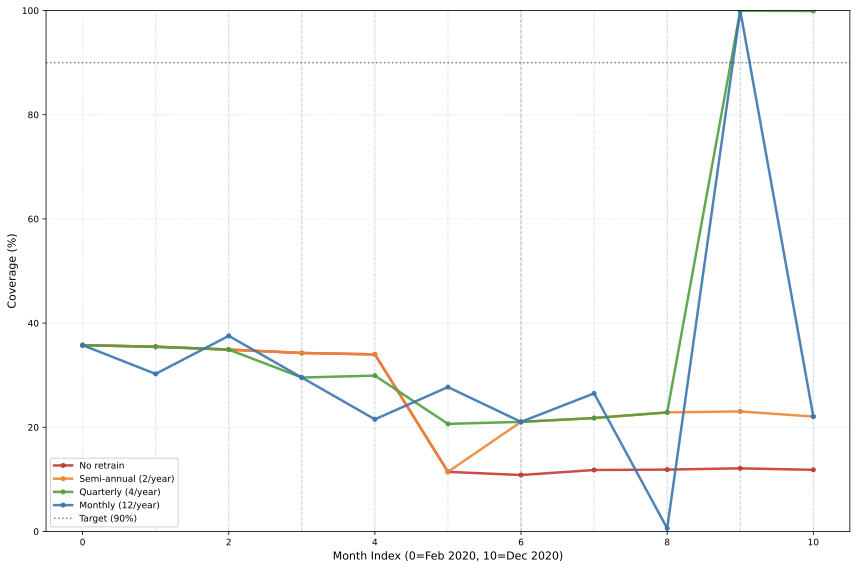
3. **실용적인 해결책**: 분기마다 모델을 다시 학습하면 성능 하락을 크게 개선할 수 있습니다. 하지만 모든 작업에 대해 이런 방법을 사용하는 것은 비효율적일 수 있으므로, 중요한 특징의 변화를 감지하고 그에 따라 재학습 여부를 결정하는 것이 좋습니다.
확률 예측은 교환 가능성을 가정하여 분포에 무관한 커버리지 보장을 제공한다. 그러나 실제 배치에서는 이 가정을 위반하는 분포 변화가 발생한다. 중요한 개방적인 질문은: 분포 변경 상황에서 확률 예측의 보장이 어떻게 악화되는가, 그리고 그 심각성에 어떤 요인이 결정되나?
우리는 rel-salt 데이터셋 – 공급망 벤치마크로 코로나19 발생 시기(2020년 2월)와 정점 시기(2020년 7월)를 시간 분할한 것 – 을 사용하여 분포 변경 상황에서 확률 예측의 제어된 연구를 수행한다. 우리의 주요 기여:
정량화: 우리는 8개의 공급망 작업에 대해 심각한 특징 교체(Jaccard $`\approx`$0)로 인해 커버리지가 얼마나 악화되는지를 측정했으며, 그 변화는 0%에서 86.7%까지 두 배 이상 변동한다.
예측 신호: SHAP 분석을 통해 심각한 분포 변경 시 단일 특징 의존성이 치명적인 실패의 예측 신호가 됨을 확인했다 (Spearman $`\rho = 0.714`$, $`p = 0.047`$, n=8). 추가적으로 4개 작업에 대한 탐색적 분석은 중등도 특징 안정성(Jaccard 0.13–0.86)에서 다른 메커니즘이 적용됨을 보여주며, 이는 특히 시간 안정성이 부족할 때 해당한다.
실용적인 해결책: 재학습 실험은 분기별로 재학습이 치명적 작업의 커버리지를 19% 포인트 복원함을 보여준다 (Wilcoxon $`p=0.04`$ vs 재학습 없음). 분기별이 월별보다 평균 커버리지가 높지만 통계적으로 유의하지 않다 ($`p=0.24`$).
비용-효과 분석: 견고한 작업(99.8% 커버리지)은 재학습으로부터 이점을 얻지 않아 실무자들은 불필요한 계산 비용을 피할 수 있다.
결정 프레임워크: SHAP 중요도 집중에 기반하여 다음과 같은 가이드를 제공: 배포 전 모니터링, 취약하면 분기별로 재학습($`>`$40% 집중), 견고하면 재학습 생략.
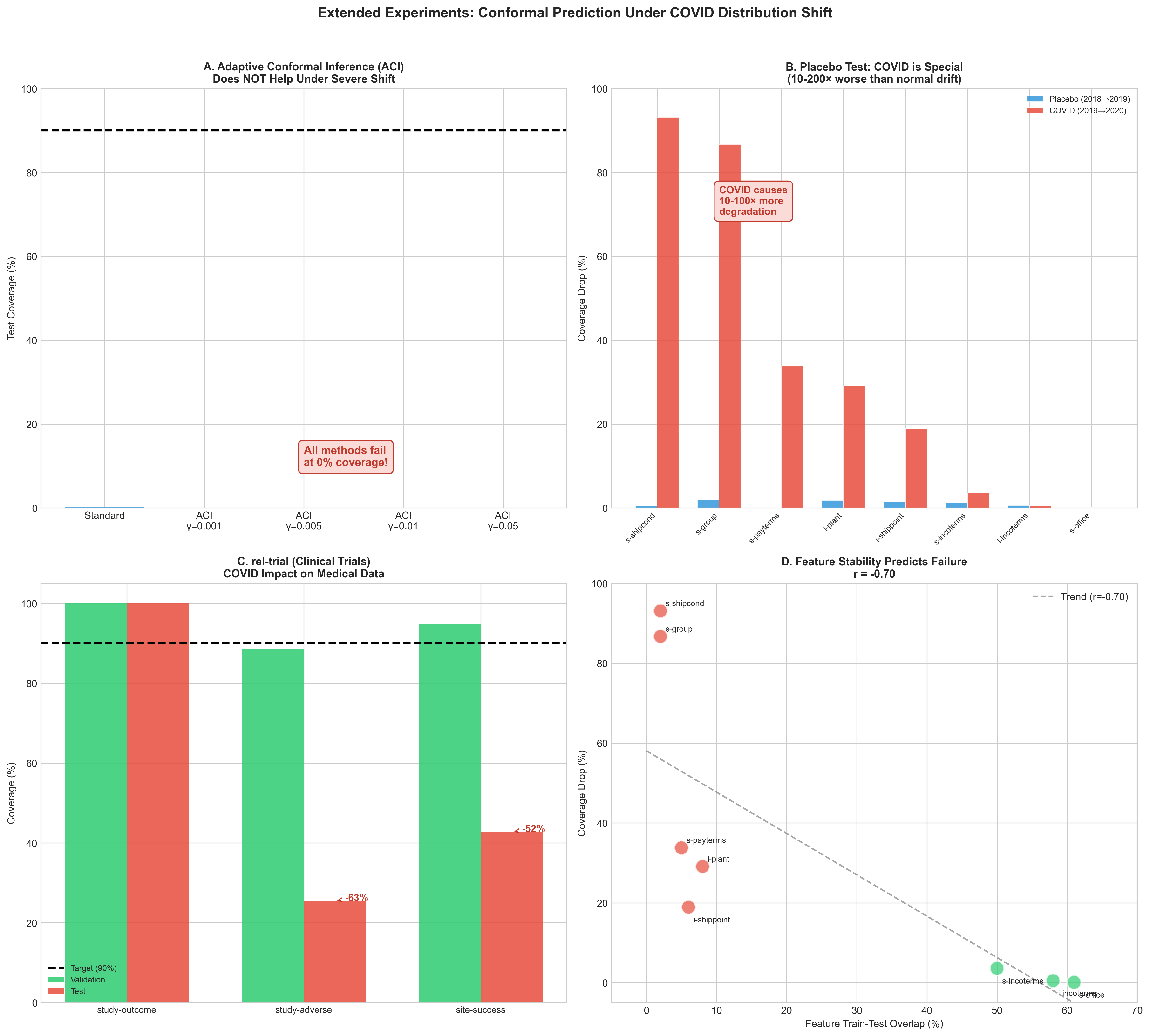
부정적 결과: 우리는 심각한 분포 변경 상황에서 적응형 확률 예측이 도움이 되지 않음을 보여준다.
관련 연구
확률 예측. Vovk 등은 교환 가능성을 보장하는 확률 예측을 소개했다. 최근 연구는 이 방법을 분류와 회귀로 확장시켰다.
분포 변경. Tibshirani 등은 공변량 변화 상황에서의 확률 예측을 연구했다. 우리는 특히 시간적 변화와 특징 변성에 초점을 맞춘다.
적응형 방법론. Gibbs 및 Candès는 비정상적인 환경을 위한 적응형 확률 예측(ACI)을 제안했다. 우리는 심각한 분포 변경 상황에서 ACI가 도움이 되는지 테스트한다.
분포 변경 벤치마크
최근 벤치마크는 다양한 도메인에 걸친 분포 변경을 체계적으로 연구한다. WILDS는 와일드 환경의 변화를 평가하는 표준화된 방법론을 제공하며, Shifts는 안전성이 중요한 응용 프로그램에 초점을 맞춘다. Gulrajani와 Lopez-Paz는 많은 “견고한” 방법이 시간적 변경 상황에서 실패함을 보여주었다. 우리는 특히 시간적 변경과 특징 변성 상황에서 확률 예측 보장의 악화에 초점을 맞추었다.
확률 예측 하의 분포 변경
Tibshirani 등은 공변량 변화와 알려진 경향 점수를 가정한 확률 예측을 연구했다. Podkopaev 및 Ramdas는 레이블 변동 상황에서 분포에 무관한 예측 집합을 개발했으며, Barber 등은 교환 가능성에 대한 확률 예측의 포괄적인 처리방법을 제공한다. 우리는 시간적 변경과 특징 변성 – 학습 및 테스트 사이의 특징 분포가 겹치지 않는 고유한 실패 모드 – 에 초점을 맞추었다.
Gibbs 및 Candès는 비정상 환경을 위한 적응형 확률 예측(ACI)을 제안했으며, Zaffran 등은 이를 시계열로 확장시켰다. 우리는 섹션 5.1에서 이러한 적응 방법이 특징 겹침이 $`\sim`$0%인 경우 실패함을 보여준다 – 이는 교정 문제가 아니라 재학습이 필요한 근본적인 데이터 변경이다.
해석성 및 모델 디버깅
우리의 SHAP 중요도 집중이 확률 예측 실패를 예측한다는 발견은 특징 귀속과 모델 디버깅 작업에 연결된다. SHAP는 일반적으로 사후 설명을 위해 사용되지만, 우리는 이 방법이 배포 전 진단으로서 확률 예측 견고성을 평가하는 데도 활용될 수 있음을 보여준다.
메소드
데이터셋: rel-salt
우리는 코로나19를 분포 변경 사건으로 보는 자연 실험을 제공하는 공급망 데이터셋 rel-salt를 사용한다:
학습: 2020년 2월 이전 (코로나19 전)
검증: 2020년 2월–7월 (코로나19 발생)
테스트: 2020년 7월 이후 (코로나19 정점)
확률 예측 설정
우리는 $`\alpha = 0.1`$($`90\%`$ 목표 커버리지, $(1-\alpha) \times 100\%$로 계산됨)를 사용한 적응형 예측 집합(APS) 알고리즘을 통해 확률 예측을 수행한다:
학습 데이터에 대해 LightGBM 앙상블 (50개 시드)을 학습
검증 세트의 50%에서 확률 예측기 교정
보유 검증 및 테스트 세트에서 커버리지 평가
변동량 측정을 위한 앙상블
우리는 모델 초기화로 인한 불확실성을 측정하기 위해 50개의 독립적인 모델을 학습한다 (시드 42–91):
각 시드 $`s`$에 대해 별도의 LightGBM 분류기 $`M_s`$를 학습
검증 세트를 50/50로 분할하여 교정($`\mathcal{D}_{\text{cal}}^s`$) 및 평가($`\mathcal{D}_{\text{eval}}^s`$) 세트로 나눔
$`\mathcal{D}_{\text{cal}}^s`$에서 개인별 확률 예측기 $`\text{CP}_s`$를 교정
$`\mathcal{D}_{\text{eval}}^s`$(검증 커버리지) 및 테스트 세트(테스트 커버리지)에서 커버리지 평가
50개의 실험에 대해 평균 $`\pm`$ 표준 편차를 보고한다. 이는 앙상블 예측이 아닌 각 시드가 모델 변동을 측정하는 독립적인 실험적 시도를 나타낸다.
여기서 $`A_{\text{train}}`$ 및 $`A_{\text{test}}`$는 각각 학습 및 테스트 데이터에서 특징 $`f`$의 고유 값 집합이다.
결과
작업별 커버리지 악화
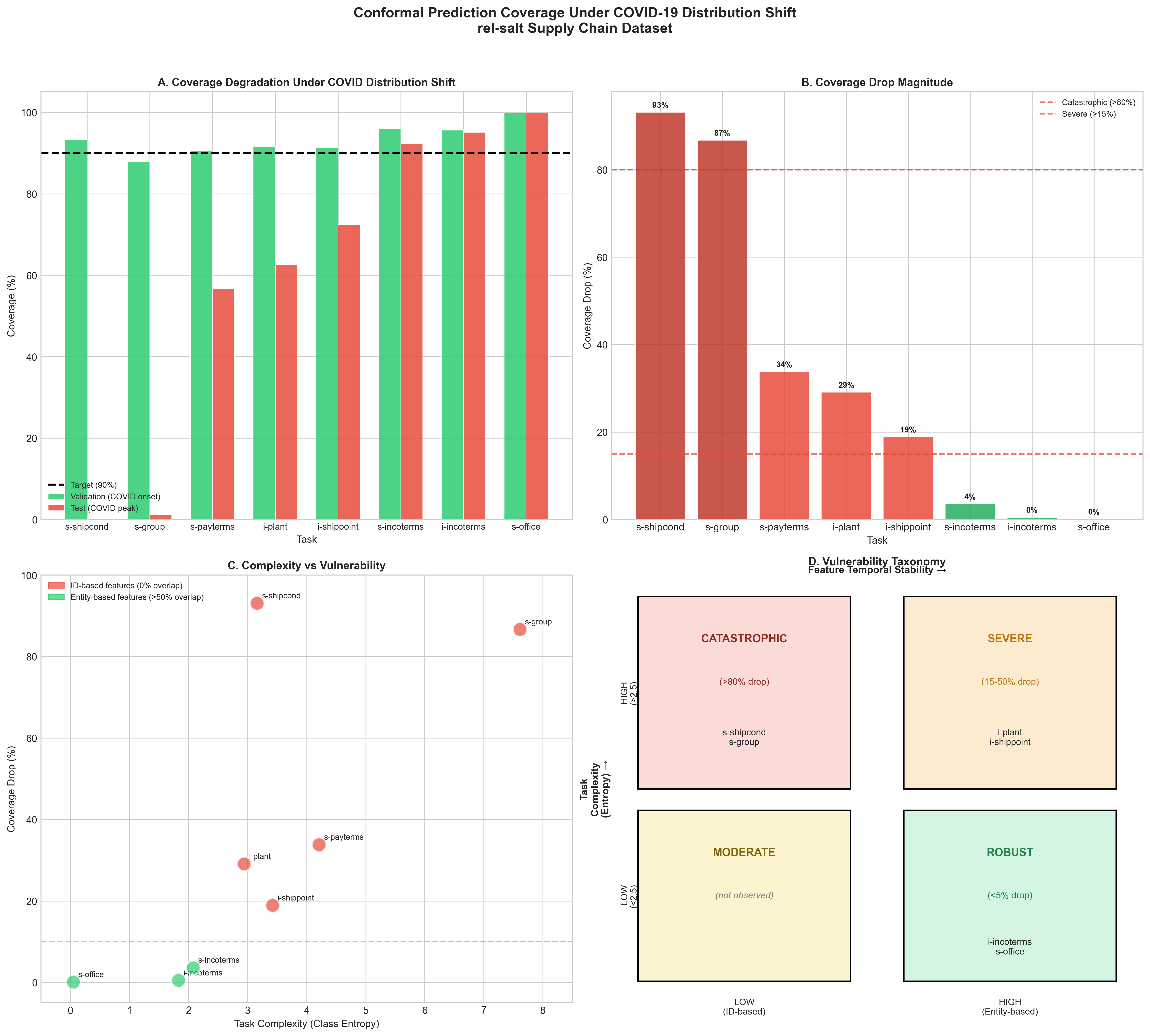
표 [tab:main_results]는 심각한 특징 교체(Jaccard $`\approx`$0)를 경험하는 8개 공급망 회귀 작업에서의 커버리지 악화를 보여준다. 악화 범위는 0%에서 86.7%까지 두 배 이상 변동한다. 우리는 또한 임상 및 모터스포츠 분야의 추가 4개 분류 작업(섹션 4.6)에 대한 탐색적 교차 도메인 검증을 수행했다.
작업
클래스
검증 커버리지 (%)
테스트 커버리지 (%)
분류
3-4 (lr)5-6
평균±표준 편차
중앙값(사분위)
평균±표준 편차
중앙값(사분위)
s-shipcond
45
93.5±1.0
93.5(1.4)
21.8±27.0
13.5(39.7)
SEV
s-group
459
83.6±6.7
86.8(6.8)
12.4±32.3
0.5(0.7)
SEV*
s-payterms
137
90.8±0.6
90.6(0.7)
13.7±27.0
0.1(0.3)
SEV
i-plant
35
92.0±0.9
91.7(1.3)
81.4±8.4
81.8(12.7)
ROB
i-shippoint
69
91.2±0.8
91.1(0.9)
72.7±36.1
89.9(7.0)
SEV*
s-incoterms
13
95.5±0.6
95.6(0.9)
87.0±8.0
92.3(17.3)
ROB
i-incoterms
13
95.0±0.4
95.0(0.6)
83.7±9.9
82.1(19.8)
ROB
s-office
25
99.9±0.0
99.9(0.0)
99.9±0.0
99.9(0.0)
ROB
SEV = 심각($`>`$70% 악화), ROB = 견고($`<`$15% 악화). $`^*`$높은 모델 변동성(표준 편차 $`>`$ 30%, 변동계수 $`>`$ 50%)은 초기값의 작은 변화가 학습된 표현을 크게 바꾼다는 것을 나타낸다.
진단 분석
우리는 커버리지 악화의 변동성을 설명하는 두 가지 요인을 확인했습니다:
요인 1: 작업 복잡도 (엔트로피). 낮은 엔트로피 작업(하나의 클래스가 우세한 경우)은 자명하게 견고함 – 모델이 “항상 클래스 0을 예측"하는 것을 배우면 완벽히 전달된다.
요인 2: 특징 시간적 안정성 (Jaccard). 거래 ID를 사용하는 작업에서는 새로운 거래가 보지 못한 ID를 가짐으로써 치명적인 실패를 겪는다. 반면에 제품이나 비즈니스 파트너와 같은 안정된 엔티티를 사용하는 작업은 커버리지를 유지한다.
작업
주요 특징
Jaccard
악화
s-shipcond
SALESDOCUMENT (ID)
0.02
93.1%
s-group
SALESDOCUMENT (ID)
0.02
86.7%
i-incoterms
PRODUCT, PARTY
0.58
0.5%
s-office
SALESORGANIZATION
0.61
0.1%
주요 특징에 대한 특징 겹침. Jaccard 유사성은 각 작업의 가장 중요한 특징(Shap 분석을 통해 식별)에서 측정된다. 전체 모델 견고성은 주요 특징뿐만 아니라 상위 5개 특징 모두에 따라 결정된다 – 섹션 4.4 참조.
주요 결과: (A) 작업별 커버리지 악화, (B) 악화 정도에 따른 임계값, (C) 복잡도와 취약성 산점도, (D) 2×2 취약성 분류.
특징 중요도 분석
치명적인 실패의 메커니즘을 이해하기 위해 sales-shipcond (치명적, 71.6% 커버리지 악화)와 sales-office (견고, 0.1% 악화)에 대한 SHAP 특징 중요도 분석을 수행했습니다. 우리는 치명적인 작업이 시간적 안정성이 낮은 특징에 의존하는 경향이 있을 것으로 가정했으며, 이를 Jaccard 유사성으로 측정하였습니다.
놀라운 발견: 두 작업 모두 가장 중요한 상위 5개 특징에서 거의 완전한 분포 변경을 경험하며 $`\sim`$0%의 Jaccard 유사성을 보였음에도 불구하고, 커버리지 악화는 700$`\times`$ 차이가 났습니다. 이는 특징 값 겹침이 주요 메커니즘이 아니라는 것을 규명하고 더 정교한 현상을 지적합니다: 분포 변경 상황에서의 특징 중요도 동태.
sales-office는 안정적인 특징(SALESORGANIZATION, Jaccard = 0.61)을 가지고 있지만 이 특징은 총 SHAP 중요도의 20%만 차지하며 (57 중 11.46), 모델이 분포 변경 후 여러 특징에 중요도를 재분배할 수 있습니다. 반면, sales-shipcond의 주요 특징(SALESDOCUMENT, Jaccard = 0.02)은 중요도의 45%를 차지하며 (20 중 9.00), 단일 특징 의존성을 형성하여 치명적인 실패를 초래합니다.
그림 2은 극단 사이의 주요 차이점을 드러냅니다. 치명적 작업(패널 A)에서 주요 특징 SALESDOCUMENT는 중요도가 1.98에서 9.00까지 (4.5배 증가) 폭발적으로 증가하면서 # Limit to 15k chars for stability