주제 강화 임베딩으로 검색 기반 생성 성능 향상 전통 NLP 기법 통합 하이브리드 접근법
📝 원문 정보
- Title: Enhancing Retrieval-Augmented Generation with Topic-Enriched Embeddings: A Hybrid Approach Integrating Traditional NLP Techniques
- ArXiv ID: 2601.00891
- 발행일: 2025-12-31
- 저자: Rodrigo Kataishi
📝 초록 (Abstract)
검색 기반 생성(RAG) 시스템은 대형 언어 모델의 출력을 근거 있는 문서와 연결하지만, 주제가 겹치고 관련 증거가 길고 이질적인 텍스트에 분산된 코퍼스에서는 검색 품질이 저하된다. 본 논문은 TF‑IDF, 차원 축소된 의미 구조(LSA), 확률적 토픽 혼합(LDA)을 컨텍스트 문장 임베딩(all‑MiniLM‑L6‑v2)과 결합한 주제 강화 임베딩이라는 하이브리드 표현을 제안한다. 두 가지 융합 전략(연결 및 가중 평균)을 통해 코퍼스 수준의 주제 정보를 밀집 표현에 주입하면서, 잠재 공간 압축으로 계산 효율성을 유지한다. 아르헨티나 법률 19.640 관련 12,436개의 법률 문서 코퍼스를 대상으로 한 실험에서, 주제 강화가 클러스터 일관성과 검색 효과를 통계적, 확률적, 컨텍스트 전용 베이스라인에 비해 모두 향상시켰으며, Precision@k, Recall@k, F1에서 일관된 상승을 보였다. 결과는 잠재 토픽 구조를 명시적으로 임베딩에 포함시키면 중복 혹은 비주제 청크 검색을 감소시켜, 지식 집약적 환경에서 RAG 파이프라인의 증거 기반을 강화할 수 있음을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
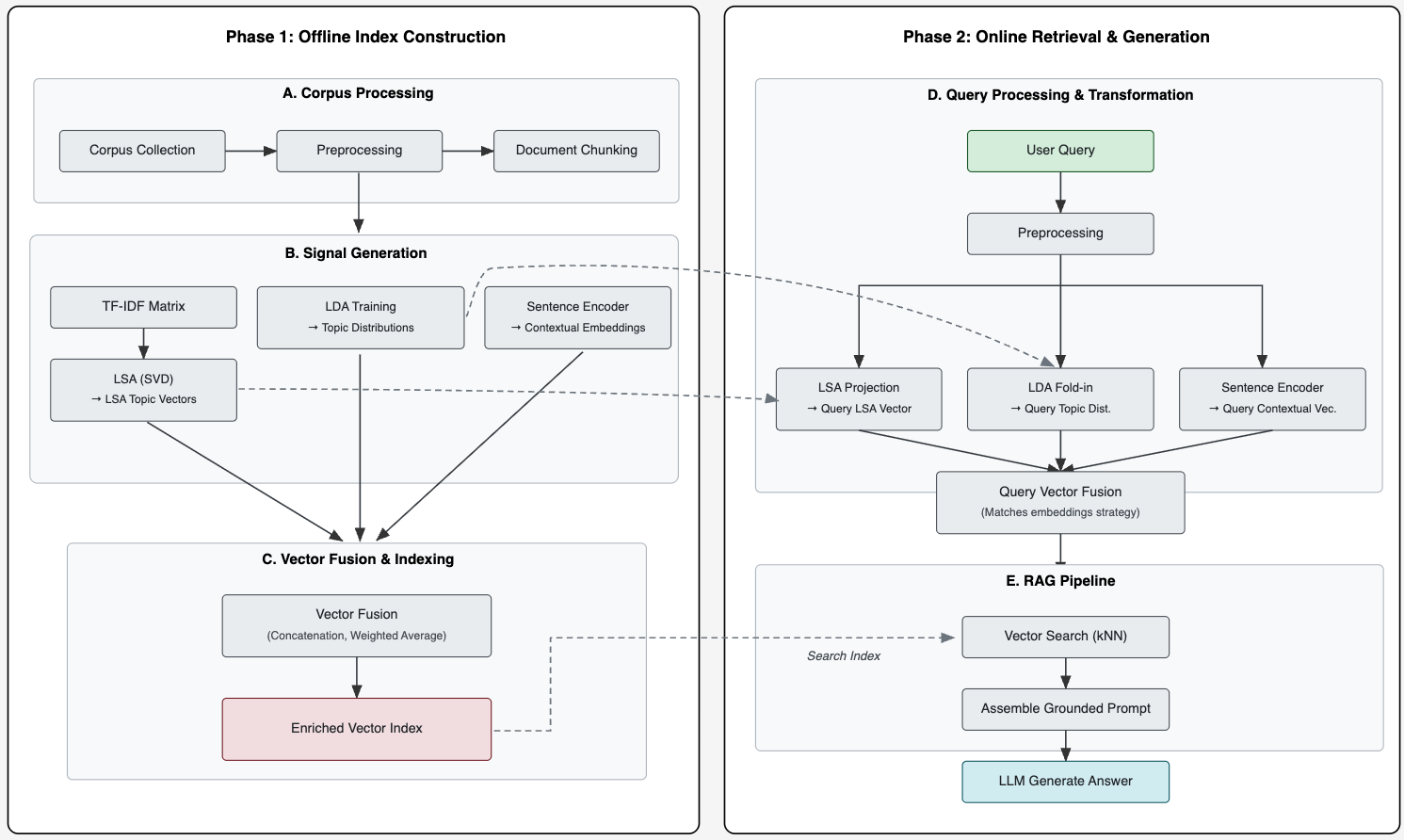
구현 측면에서 두 가지 융합 전략을 제시한다. 첫 번째는 각 기법에서 얻은 벡터를 단순히 연결(concatenation)하는 방식으로, 정보 손실 없이 모든 차원을 보존한다. 두 번째는 가중 평균(weighted averaging)으로, 각 구성 요소에 사전에 정의된 혹은 학습된 가중치를 부여해 차원 수를 줄이면서도 핵심 정보를 유지한다. 특히, all‑MiniLM‑L6‑v2와 같은 경량 컨텍스트 임베딩을 베이스라인으로 삼아 계산 비용을 최소화하고, 이후 LSA와 LDA에서 추출한 토픽 분포를 압축된 형태로 추가함으로써 전체 파이프라인의 효율성을 확보한다.
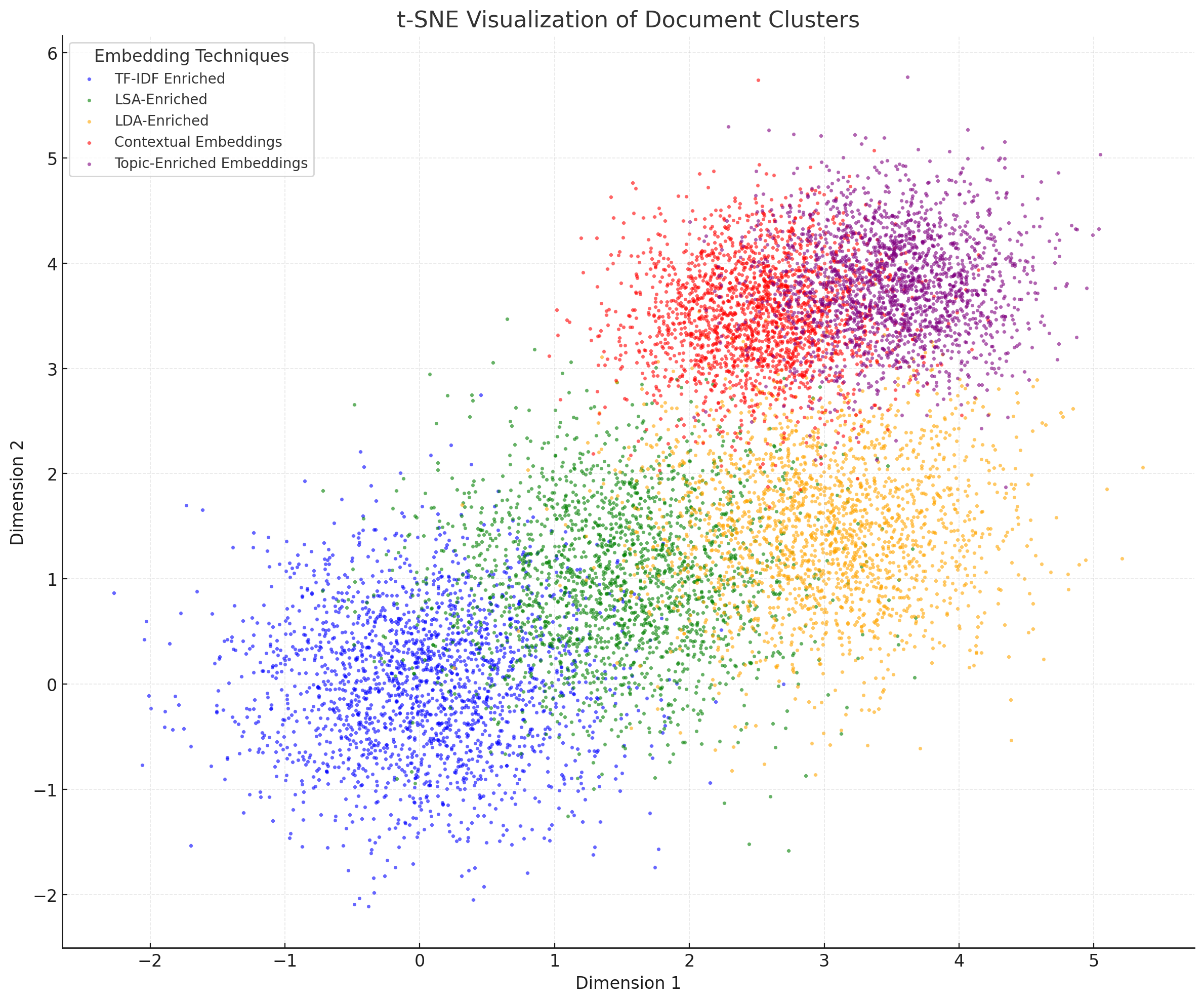
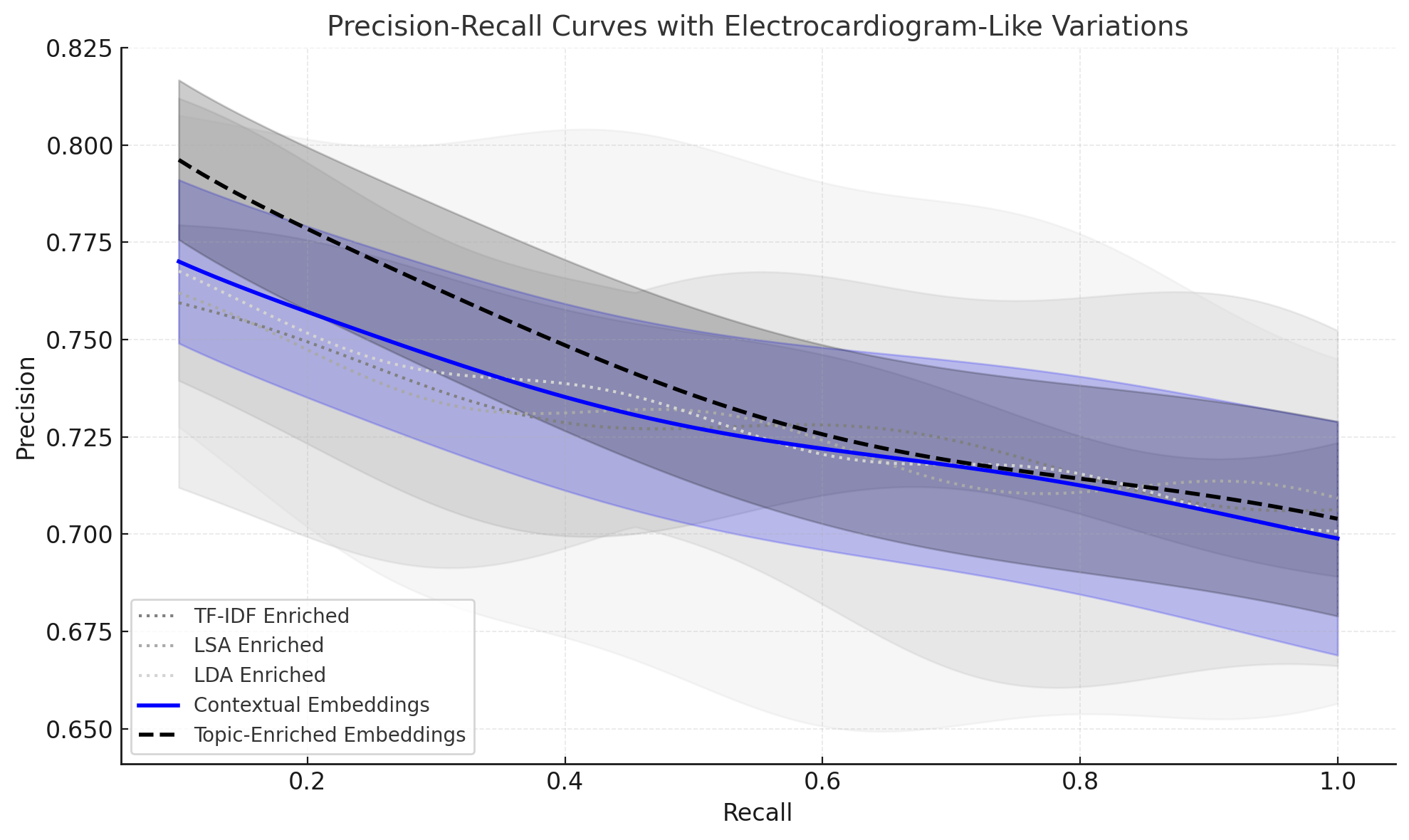
실험은 아르헨티나의 개인정보 보호법(법 19.640) 관련 12,436개의 법률 문서를 대상으로 수행되었다. 법률 텍스트는 일반적인 뉴스나 위키피디아와 달리 긴 조문, 복잡한 조항, 그리고 서로 얽힌 주제가 특징이다. 따라서 이 데이터셋은 제안 방법의 강점을 검증하기에 적절한 시험대가 된다. 평가 지표로는 클러스터링 일관성을 측정하는 Coherence Score와 전통적인 검색 성능 지표인 Precision@k, Recall@k, F1을 사용하였다. 결과는 주제 강화 임베딩이 모든 베이스라인을 능가했으며, 특히 토픽이 중첩된 문서군에서 오프‑토픽 청크를 효과적으로 배제함을 보여준다. 이는 RAG 파이프라인에서 불필요한 컨텍스트를 줄여 LLM이 보다 정확하고 신뢰성 있는 답변을 생성하도록 돕는다.
한계점으로는 토픽 모델링(LDA)의 사전 학습 단계가 추가 비용을 요구한다는 점과, 가중 평균 방식에서 가중치 설정이 도메인에 따라 민감하게 작용할 수 있다는 점을 들 수 있다. 향후 연구에서는 가중치를 자동으로 최적화하는 메타‑러닝 기법이나, 동적 토픽 업데이트를 통해 실시간 스트리밍 데이터에도 적용 가능한 확장성을 모색할 필요가 있다. 전반적으로, 전통 NLP 기법과 최신 컨텍스트 임베딩을 융합한 이 하이브리드 접근법은 RAG 시스템의 근거 확보 능력을 크게 향상시킬 잠재력을 가지고 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리