- Title: From Building Blocks to Planning Multi-Step Spatial Reasoning in LLMs with Reinforcement Learning
- ArXiv ID: 2512.24532
- 발행일: 2025-12-31
- 저자: Amir Tahmasbi, Sadegh Majidi, Kazem Taram, Aniket Bera
📝 초록
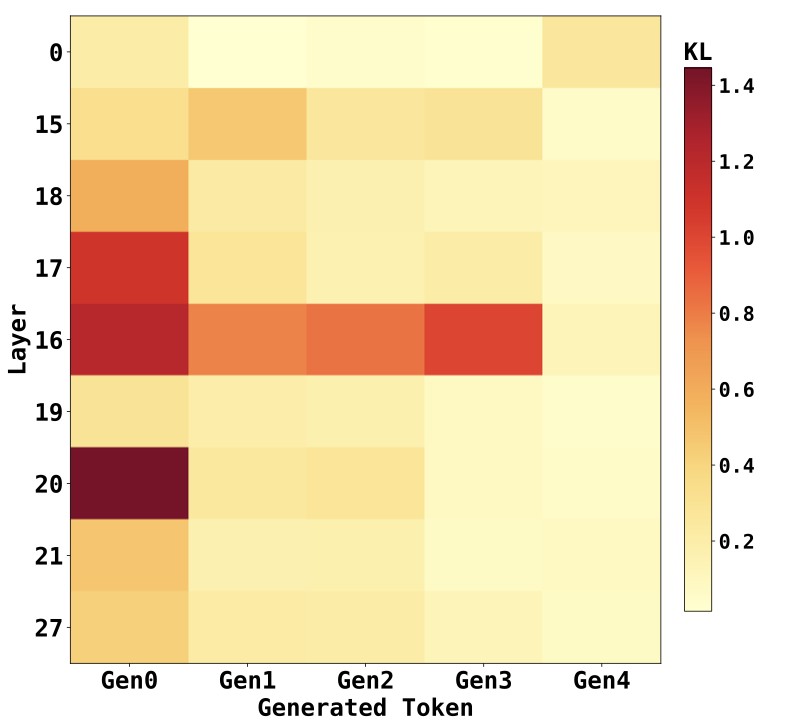
공간 추론은 네비게이션 및 계획 등 다양한 응용 분야에서 주목받고 있는 큰 언어 모델(LLMs)의 특징이다. 그럼에도 불구하고, LLMs는 구조화된 환경에서 공간 변환과 다단계 계획에 여전히 어려움을 겪고 있다. 본 논문에서는 두 단계 접근법을 제안한다. 이 방법은 공간 추론을 원자적 구성 요소와 그것들의 조합으로 분해한다. 첫째, 회전, 평행이동 및 스케일링과 같은 기본적인 공간 변환에 대해 감독 학습을 통해 모델에 기본적인 공간 물리학을 제공하기 위해 훈련을 진행한다. 그런 다음 이 물리학 인식 모델을 동결하고 GRPO 프레임워크 내에서 가벼운 LoRA 어댑터를 훈련시켜, 수수께끼 기반 환경에서 다단계 계획을 위한 이러한 구성 요소들을 조합하는 정책을 학습한다. 이를 위해 아스키아트 데이터셋을 합성하고 해당 아스키 기반 강화 학습 환경을 구축한다. 우리의 방법은 동적인 환경과 정적인 환경 모두에서 일반 베이스라인, 물리학 인식 모델 및 end-to-end RL 모델을 능가하며, 특히 수수께끼 기반 환경에서는 더욱 우수한 성능을 보여준다. 또한 제안된 접근법은 처음부터 강화 학습을 진행하는 것보다 더 빠르게 수렴하고 훈련이 안정적이다. 마지막으로 우리는 주의 패턴을 분석하여 페인트를 통해 공간 이해력에서 의미 있는 개선이 이루어졌는지 평가한다.
💡 논문 해설
1. **기계학습을 활용한 공간 이해력 향상**: 이 연구는 언어 모델이 복잡한 공간적 관계를 이해하고 해결하는 능력을 높이는 방법을 제시합니다. 이를 위해, 모델은 기초적인 물리적 변환을 학습하고 그 결과물을 바탕으로 더 큰 문제를 해결할 수 있도록 합니다. 이는 마치 초보자 운전자가 기본 운전 동작을 익힌 후 복잡한 교통 상황에서 안전하게 주행하는 것과 같습니다.
두 단계 학습 방법론: 연구에서는 먼저 모델이 기초적인 변환을 배우는 단계와, 그 다음으로 강화학습을 통해 이러한 기본 동작들을 조합하여 문제를 해결하도록 하는 두 가지 단계의 학습 방법을 제시합니다. 이는 마치 요리사가 먼저 기본 재료 준비법을 익히고 나서 다양한 레시피를 만들어내는 것과 비슷한 과정입니다.
성능 향상 및 수렴 속도 개선: 연구 결과, 제안된 방법은 다른 기준 모델들보다 더 높은 성능을 보여주며, 강화학습에서 더 빠르게 수렴하는 것으로 나타났습니다. 이는 마치 운동 선수가 자신의 기본적인 스킬을 향상시키고 이를 바탕으로 좀 더 복잡한 기술을 학습하면서 경기 성적을 개선하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 소개
공간 추론과 이해는 환경 내에서 물체들의 상대적 위치, 방향, 거리 및 공간 구성의 변화에 대한 추론 능력을 의미합니다. 대규모 언어 모델(LLM)과 시각-언어 모델(VLM)이 수학 추론 및 시각-언어 이해와 같은 다양한 작업에서 최근 획기적인 발전을 이룬 것처럼, 그들의 공간 추론 능력은 로봇공학이나 언어 기반 탐색 작업 등에 적용되어 주목받고 있습니다. 그러나 이러한 모델의 공간 추론 능력은 아직 충분히 연구되지 않았습니다.
공간 추론 작업은 종종 여러 도메인으로 분류됩니다. 일부는 언어적이고 자연스러운 언어 시나리오를 중심으로 하며, 미로, 루빅스 큐브, 소코반과 같은 퍼즐 기반 설정에서는 모델이 물체들 간의 공간적인 관계를 이해하여 작업을 해결해야 합니다. 퍼즐 기반 설정에서 언어 모델은 여러 기법으로 강화됩니다. 하나는 외부 모듈을 사용하여 LLM이 행동 제안자 또는 추론 후보 생성자를 역할하는 범주입니다. 이 외부 모듈은 BFS나 DFS와 같은 히스토리에 기반하거나, XoT과 같이 사전 학습된 강화학습 및 몬테카를로 트리 검색(MCTS)을 활용하거나 Q-러닝과 같은 학습 기반 접근법을 사용할 수 있습니다. 다른 범주는 모델 자체에 초점을 맞춥니다. 하나의 방향은 프롬프팅을 통해 모델의 행동을 바꾸는 것입니다. 예를 들어, Visualization-of-Thought(VoT)는 LLM에서 공간 추론을 유발하는 데 사용됩니다. VoT는 그들의 추론 경로를 시각화하고 다음 추론 단계를 안내하여 이를 달성합니다. 다른 접근법은 DeepSeek-R1에 영감을 받아 학습된 모델이 솔루션 트레이스에 대해 감독 학습을 통해 세부 조정을 수행한 후 GRPO를 적용하여 같은 작업과 구조에서 추론 단계를 더욱 개선합니다.
본 연구에서는 퍼즐 기반 설정의 공간 추론에 초점을 맞춥니다. 여기서 에이전트는 초기 공간 구성 상태를 순차적인 이산 행동을 통해 목표 구성 상태로 변환해야 합니다. 우리는 이러한 공간 이해를 원자적 변환, 예를 들어 도형을 $`90^\circ`$ 회전하거나 한 그리드 셀 위로 이동시키는 것과 같은 구조물의 집합으로 분해하는 새로운 접근법을 제안합니다. 먼저 감독 학습을 통해 이러한 기본 물리적 변환을 배울 수 있도록 모델을 세부 조정합니다. 이 단계 후에, 물리학을 고려한 모델은 얼어붙은 상태로 유지되고, 가벼운 어댑터 층이 도입되어 이러한 구조물을 원시 요소로 구성하는 정책을 학습하도록 강화 학습이 적용됩니다. 접근법의 개요는 Figure 1에 표시되어 있습니다.
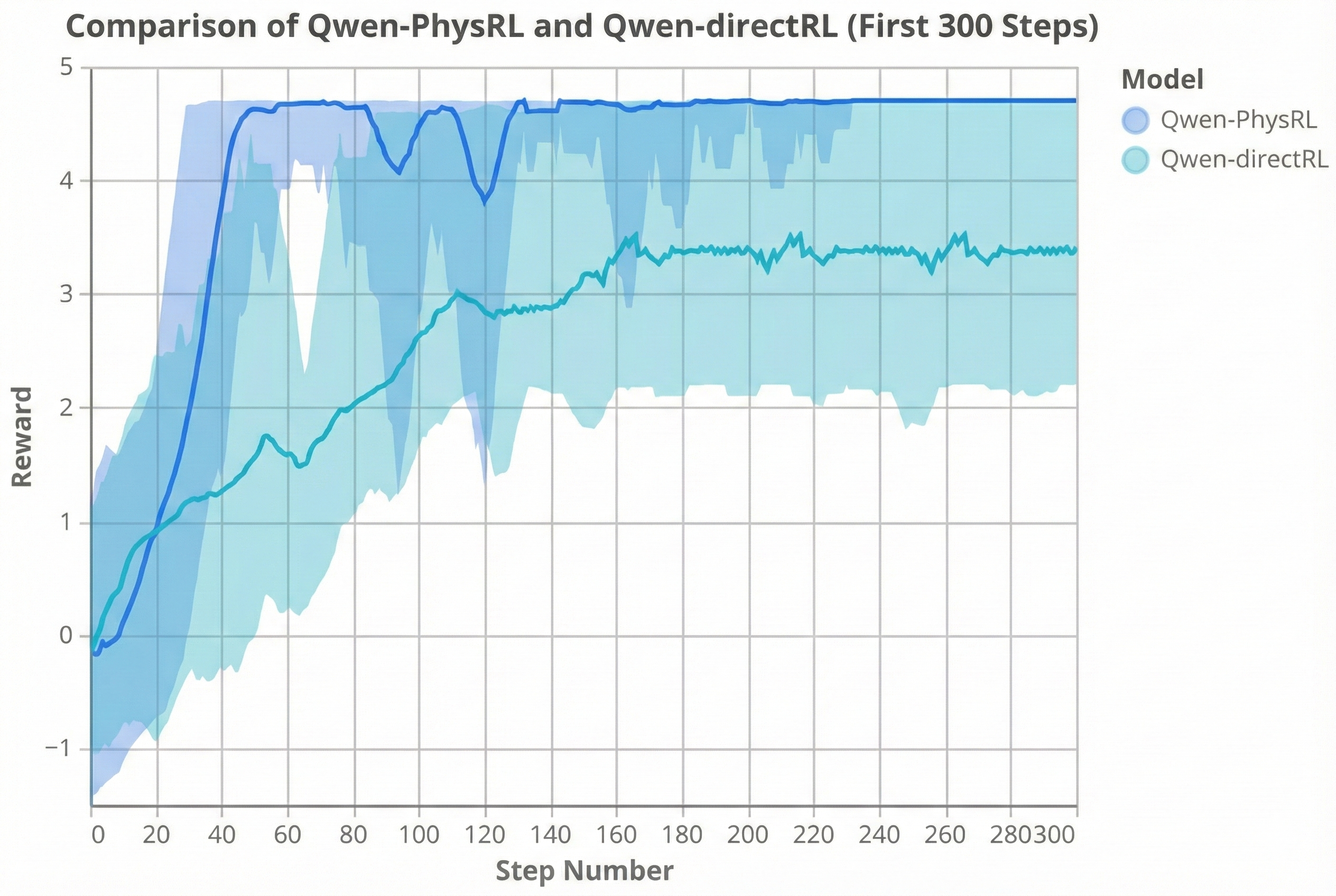
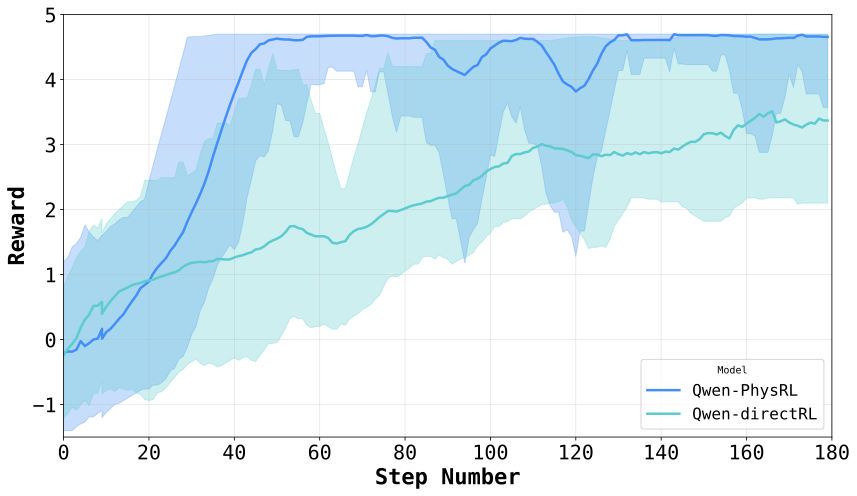
감독 학습 단계에서는 12,000개의 작업을 포함하는 데이터셋을 생성합니다. 이 데이터셋은 변환 범주인 이동, 회전 및 크기 조정을 포괄하며 이를 사용하여 Qwen2.5-1.5B-Instruct 모델을 세부 조정합니다. 후속 강화 학습 단계에서는 물리학을 고려한 모델이 다중 단계의 복합 환경 내에서 직접 강화 학습 루프에 포함됩니다. GRPO를 통해 가벼운 LoRA 어댑터 층을 적용하여 얼어붙은 백본 위에 정책을 최적화하고, 모델이 환경과의 반복적인 상호작용을 통해 원자적 공간 연산 시퀀스에 대한 정책을 학습할 수 있도록 합니다. 우리는 여러 기준 모델들과 우리의 접근법을 비교합니다. 이들에는 일반적인 Qwen2.5-1.5B-Instruct 모델, 감독 학습만으로 훈련된 물리학을 고려한 모델 및 직접 GRPO 강화 학습을 통해 훈련된 Qwen 모델이 포함됩니다. 모든 모델은 두 가지 설정에서 처음 본 적 없는 공간 추론 작업에 대해 테스트됩니다: 하나는 각 행동 후 환경 맵이 업데이트되는 것, 다른 하나는 맵이 고정된 상태입니다. 결과는 제안된 방법이 두 가지 설정 모두에서 모든 기준 모델보다 더 높은 보상을 얻고 강화 학습 중에 더욱 빠르게 수렴함을 보여줍니다.