이 논문은 DBF의 성능 한계를 극복하기 위해 Multi-Envelope Double Binary Factorization (MDBF)을 제안한다. MDBF는 기존의 단일 랭크 평가 범위에 제한된 이진 패턴 대신, 여러 개의 평가 범위 모드를 사용하여 정확도를 향상시킨다. 이를 통해 1비트에서 2비트까지의 저정밀도에서도 높은 성능을 유지할 수 있다.
💡 논문 해설
1. **DBF 한계 파악:** DBF는 단일 평가 범위에 제한되어 있으며, 이로 인해 정확도 향상이 제한적이다. 이를 비유하자면, 기존 방식은 하나의 색상만 사용하는 그림 그리기와 같고,MDBF는 여러 색상을 활용하여 더 복잡하고 정교한 그림을 그릴 수 있다.
2. **Multi-Envelope DBF 제안:** MDBF는 동일한 이진 경로를 유지하면서도 여러 평가 범위 모드를 도입해 정확도를 향상시킨다. 이를 비유하자면,MDBF는 여러 색상을 사용하여 그림을 그리되, 기존 방식과 동일한 간단한 도구를 활용하는 것과 같다.
3. **ADB Refinement:** MDBF의 초기화와 ADMM 기반 정제를 통해 효율적인 최적화를 수행한다. 이를 비유하자면,MDBF는 여러 색상을 사용하여 그림을 그리되, 정교하게 수정하여 더 나은 결과를 얻는 것과 같다.
📄 논문 발췌 (ArXiv Source)
# 서론
대형 언어 모델(LLMs)은 많은 NLP 시스템을 지원하지만, 그 크기는 배포를 비싸게 만든다. FP16 또는 FP32 매개변수를 저장하고 메모리 계층을 통해 이동하는 것이 종종 메모리 푸트프린트와 추론 지연 시간을 주도하기 때문이다. 따라서 양자화는 효율적인 배포에 핵심 도구이다. 사후 훈련 양자화(PTQ)는 특히 미리 훈련된 모델에 최소한의 부가비용으로 적용할 수 있어 전체 재훈련을 피하는 것이 매력적이다. 최근 PTQ 방법은 약 4비트 정밀도에서 강력한 정확도를 유지하지만, 정밀도가 2~1비트 범위로 접근하면 성능이 일반적으로 저하된다. 이는 각 층의 정보 예산이 매우 제한되기 때문이다. 2비트 아래로 내려가기 위해 많은 접근 방식은 요소별 양자화를 넘어 구조적 매개변수화로 전환한다. 이진 및 근사 이진 방법은 특히 명확한 하드웨어 빠른 경로를 제공하는 것이 매력적이다: 대부분의 계산은 비트 패킹된 부호 행렬을 사용하여 특수 커널에 의해 수행되며, 가벼운 고정밀도 스케일링만 필요하다.
이진화 방법 중 하나인 각 가중치 행렬을 낮은 등급 성분으로 분해하고 그 성분들을 이진화하는 방법이 있다. OneBit는 적절한 스케일링이 1비트 요소를 안정시킬 수 있음을 보였고, Double Binary Factorization (DBF)은 두 개의 이진 행렬 곱셈과 중간에 대각선 스케일링을 결합하여 명확하게 이진 경로를 만든다. LittleBit는 다중 스케일 스케일링 및 잔차 보정을 통해 극단적인 비트 정밀도에서의 정확성을 향상시키며, 여러 GPU에 걸친 양자화 인식 훈련(QAT)을 활용한다. 이러한 진전에도 불구하고, 기존 형식은 핵심 구조적 제한을 공유하고 있다: 이진화 후, 요소의 크기 값은 단일 랭크-원 캡슐 내에 제한된다. 내부 등급을 증가시키는 것은 주로 부호 다양성을 향상시켜 크기 표현력을 향상시키지 않는다. 따라서 고정된 비트 당 가중치 예산에서 정확도가 포화 상태에 도달할 수 있으며, 성능은 부호보다 크기에 더 많이 의존한다.
/>
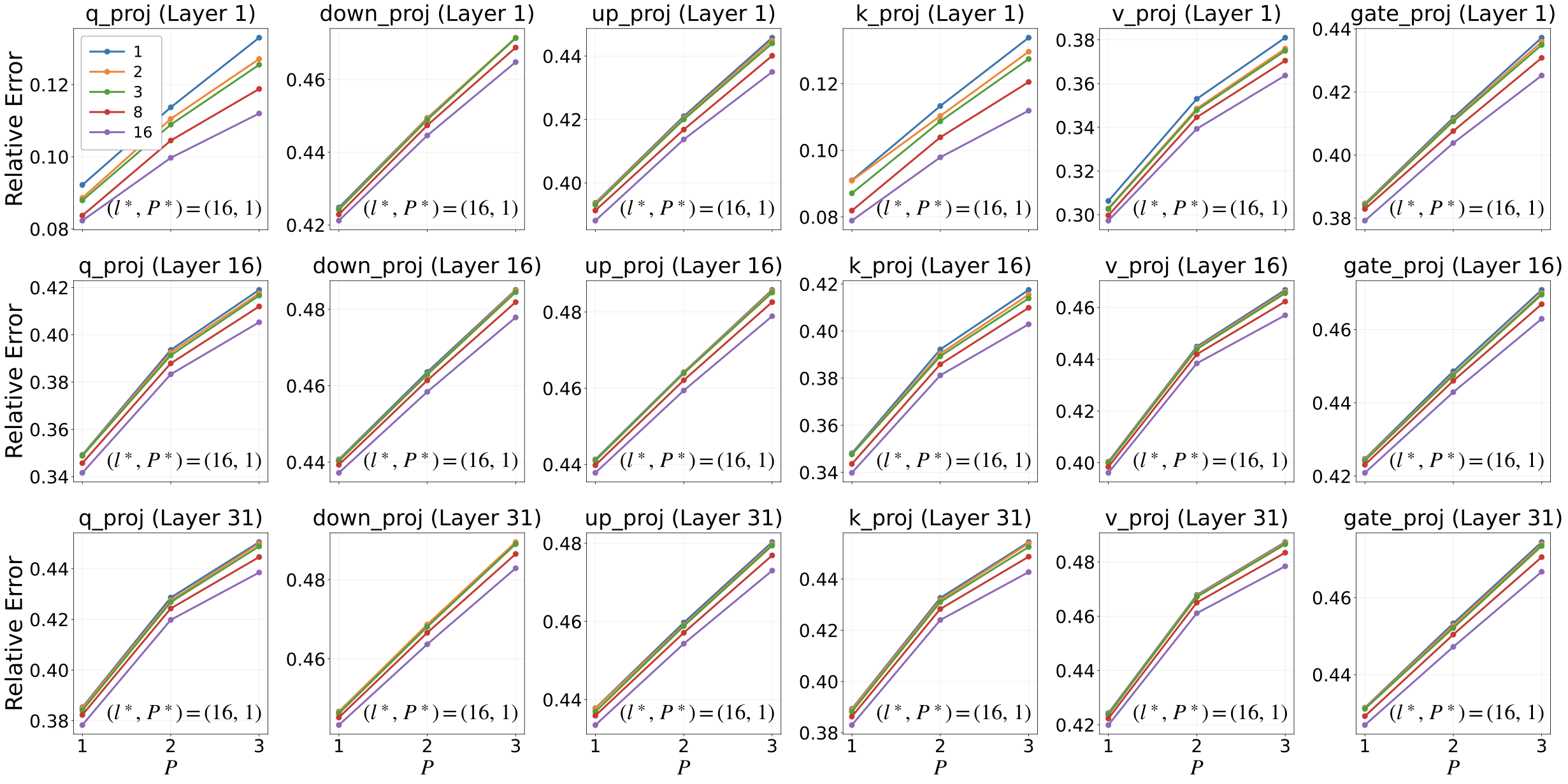
레이어별 재구성 오차 vs. 캡슐 랭크 및 분해 깊이 (LLaMA2 7B). 우리는 1.5비트 양자화 설정에서 실험을 수행하고MDBF의 상대 Frobenius 오차 $\nicefrac{\|W-\widehat{W}\|_{F}}{\|W\|_{F}}$
를 층 0, 15 및 30과 중앙 주의/MLP 투영에 대한 캡슐 랭크 l와 분해 깊이 P의 함수로 보고한다. 모든 레이어 및 모듈에서, 크기를 표현하는 능력을 향상시키는 더 큰 l, 즉 공유 부호 기반을 유지하면서 일관되게 재구성 오차를 줄인다. 반면에, 분해 깊이를 추가하고 부호 기반을 늘리는 더 큰 P는 가중치 당 비트가 동일한 경우 재구성을 악화시키는 경향이 있다. 이 스윕에서 가장 좋은 구성은 (l*, P*) = (16, 1).
이 논문은 DBF의 한계를 극복하기 위해 극도로 낮은 정밀도에서 중요 요소에 표현력을 명시적으로 할당한다. 우리는 Multi-Envelope Double Binary Factorization (MDBF)을 제안하며, MDBF는 공유된 1비트 부호 기반 및 배포 친화적 이진 경로를 유지하면서 랭크 하나의 크기 캡슐을 여러 개의 해부된 캡슐 모드로 대체한다. 그림 1은 캡슐 랭크 $`l`$을 증가시키면 재구성 오차가 체계적으로 줄어들지만, 가중치 당 비트 예산이 고정된 상태에서 LittleBit와 같이 잔차 경로 $`P`$를 늘리는 것은 종종 덜 효과적임을 보여준다. MDBF는 크기를 모델링하는 데 실제 값의 자유도 몇 개를 추가하여 트랜스포머 가중치가 거의 항상 랭크 하나가 아닌 경험적으로 관찰된 저랭크 구조와 더 잘 일치한다.MDBF를 층별 PTQ에 적용할 수 있도록, 우리는 폐형 초기화 후 ADMM 정제를 포함하는 층별 최적화 파이프라인을 도입한다. LLaMA 및 Qwen 가족 전체에서, MDBF는 고정된 비트 당 가중치 내에서 이전의 이진 형식보다 난해한 2~1비트 범위에서도 perplexity와 제로샷 정확도를 향상시키며, 동일한 배포 친화적 이진 추론 원시 요소를 유지한다.
기여.
DBF 한계 파악: 우리는 단일 캡슐 제약을 한계로 식별한다. 고정된 비트 당 가중치 예산에서 크기 변동을 모델링하는 것이 부호 다양성을 증가시키는 것보다 정확도 향상에 더 큰 영향을 미친다.
DBF의 Multi-Envelope 일반화: 우리는 단일 캡슐 제약을 유지하면서 공유된 1비트 부호 기반 및 동일한 배포 친화적 이진 경로를 유지하면서 랭크 하나의 크기 캡슐을 랭크-$`l`$ 캡슐로 대체하는 Multi-Envelope DBF (MDBF)를 제안한다.
MDBF 초기화 및 ADMM 정제: 우리는 LittleBit의 초기화와 DBF의 ADMM 기반 정제를 다중 캡슐 설정으로 일반화한다. 이는 폐형 초기자와 효율적인 교차 ADMM 정제 절차를 결과로 낳는다.
실증적 검증: LLaMA 및 Qwen 모델 가족에 걸쳐,MDBF는 고정된 BPW 내에서 이전의 이진 형식보다 재구성 오차를 줄이고 perplexity와 제로샷 정확도를 향상시킨다.
표기법
벡터는 진하게 쓰여진 소문자로, 예를 들어 $`{\bm x}`$, 행렬은 대문자로, 예를 들어 $`W`$로 표기된다. 전체적으로 $`W\in{\mathbb R}^{N\times M}`$는 실수 가중치 행렬을 나타낸다. 우리는 $`\odot`$를 Hadamard 요소별 곱셈으로 사용하고, 벡터 $`{\bm a}`$에 대해 $`D_{{\bm a}}`$를 대각행렬로 표현하며 $`(D_{{\bm a}})_{ii}=a_i`$이다. 우리는 $`\|\cdot\|_F`$를 Frobenius 노름으로 사용하고, $`\langle A,B\rangle_{F}\coloneqq \mathrm{Tr}(A^\top B)`$는 해당 Frobenius 내적을 나타낸다. 모든 행렬 $`A`$에 대해 그 특이값은
$`\sigma_1(A)\ge \cdots \ge \sigma_{\min(N,M)}(A)\ge 0`$로 표기된다. 목표 랭크가 $`R\le \min(N,M)`$인 경우, 우리는 $`W`$의 랭크-$`R`$ 단순화된 SVD를 $`W_R = U_R\Sigma_R V_R^\top`$로 표기한다. 여기서
$`U_R\in{\mathbb R}^{N\times R}`$와 $`V_R\in{\mathbb R}^{M\times R}`$는 직교 열을 가지고 있으며,
$`\Sigma_R=\mathrm{diag}(\sigma_1,\dots,\sigma_R)\in{\mathbb R}^{R\times R}`$. 마지막으로, 각 항에 대한 부호 함수 $`\mathrm{sign}(\cdot)`$는
$`\{\pm 1\}`$로 매핑하며 $`\mathrm{sign}(0)=+1`$이다.
예비
저랭크 근사
모델 압축의 일반적인 접근 방식은 가중치 행렬에 대한 경험적으로 관찰된 대략적 저랭크 구조를 활용하는 것이다. 가중치 행렬 $`W \in {\mathbb R}^{N\times M}`$을 주어졌을 때, 우리는 이를 랭크-$`R`$
인 요소화로 근사한다:
MATH
\begin{equation}
\label{eq:low-rank-basis}
W \approx U V^{\top},~~
U \in {\mathbb R}^{N \times R},~V \in {\mathbb R}^{M \times R}.
\end{equation}
클릭하여 더 보기
이것은 $`UV^{\top}`$가 $`W`$를 $`R`$ 개의 랭크 하나 구성 요소로 표현한다는 것을 나타낸다, 즉 $`UV^{\top}=\sum_{j=1}^{R}{\bm u}_{j}{\bm v}_{j}^{\top}`$, 여기서 $`{\bm u}_{j}`$와 $`{\bm v}_{j}`$는 $`U`$ 및 $`V`$의 $`j`$번째 열이다.
그러나 저랭크만으로 의미 있는 메모리 절약을 보장하지 않는다. 만약 $`U`$와 $`V`$가 표준 고정밀도 형식, 예를 들어 FP16 또는 FP32로 저장된다면, 매개변수 수는 $`(N+M)R`$, 이는 원래의 $`NM`$ 매개변수와 유사할 수 있으며, $`R \ll \min(N, M)`$이 아닌 경우 절약 효과가 제한적일 수 있다. 더 나아가 정확도를 유지하려면 보통 중간 크기의 $`R`$이 필요하여 압축 이점이 더욱 제한된다. 따라서 매우 낮은 비트 폭에서 의미 있는 저장 공간을 절약하면서 충분히 큰 효과적인 랭크를 유지하기 위해서는 요소화 또는 추가 구조를 도입하여 효율적인 계산과 함께 소형 저장을 촉진해야 한다.
Double Binary Factorization
Double Binary Factorization (DBF)은 가중치 행렬 $`W\in{\mathbb R}^{N\times M}`$을 두 개의 이진 부호 기반 및 대각선 리스케일링을 사용하여 표현한다:
공유된 부호 기반을 사용하여 해체하면 각 요소 캡슐은 랭크 하나의 외적을 구성한다. 즉, $\widehat{U}$의 각 열은 스칼라 곱 $`m_j^{1/2}`$을 제외하고 동일한 행 방향 캡슐 프로필 $`{\bm a}`$를 공유하며, 마찬가지로 $`\widehat{V}`$에 대해 $`{\bm b}`$가 적용된다. 우리는 이 랭크 하나의 해체된 캡슐 제약을 단일 캡슐 제약이라고 부른다.
추론.
입력 활성화를 $`X\in{\mathbb R}^{T\times N}`$로 표기하고, 출력을 $`Y=X\widehat{W}_{\mathrm{DBF}}\in{\mathbb R}^{T\times M}`$로 표기한다. DBF는 대각선 스케일링이 두 개의 이진 행렬 곱셈과 함께 중첩되는 효율적인 평가 순서를 허용한다:
대각행렬과의 곱셈은 요소별 스케일링에 해당하며, 일반적으로 행렬 곱셈보다 대역폭이 적다. 따라서 DBF는 하나의 고정밀도 GEMM을 두 개의 이진 GEMMs 및 저렴한 대각선 연산으로 대체한다. 가중치 당 효과적인 비트 수는 원래 행렬의 $`NM`$ 항목에 대한 압축된 $`\{S_a,S_b\}`$와 실수 벡터 $`\{{\bm a},{\bm b},{\bm m}\}`$의 저장에 의해 결정된다.
잔차 보정.
LittleBit은 단일 DBF 근사에 추가적인 DBF 항을 더함으로써 정확도를 향상시킨다. LittleBit은 구체적으로 다음과 같은 두 가지 항 분해를 사용한다:
두 번째 DBF 항을 $`\widehat{R}`$에 근사하도록 맞춘다. 이 잔차 보정 방법은 단일 DBF 구성 요소로 표현하기 어려운 구조를 포착한다.
방법
/>
LLaMA2 13B의 트랜스포머 레이어를 통한 엔트로피 기반 효과적인 랭크. 우리는 전체 가중치 행렬 W, 이진화된 부호 sign(W), 해체된 캡슐 |U| 및
|V|의 평균 효과적인 랭크를 보고한다. 이 캡슐은 일관되게 랭크 하나보다 위에 있으며, 단일 캡슐 제약을 완화하기 위한 여러 크기 모드를 동반한다.
한계: 단일 캡슐 제약
실제로 DBF는 성능 천장이 있다; 내부 차원 $`R`$을 증가시키면 수익감소 현상이 발생하고, 정확도는 실제 값의 저랭크 근사와 동등한 매개변수 수에서 포화 상태에 도달한다. 이 간극은 경험적인 것이 아니라 구조적이다. 섹션 3에서 설명했듯이, 해체는 각 DBF 요소가 모든 $`R`$ 열에 걸쳐 공유된 랭크 하나의 진폭 캡슐로 제한됨을 나타낸다. $`R`$을 크게 하면 부호 패턴 다양성을 주로 증가시키지만 진폭 표현력을 향상시키지 않아 정확도를 근본적으로 한계 지운다.
LLM 가중치의 경험적 구조와 일관되지 않은 단일 랭크 캡슐 가정을 양화한다. 이를 측정하기 위해 LLaMA2 13B에서 해체된 캡슐 $`|U|`$ 및 $`|V|`$의 엔트로피 기반 효과적인 랭크를 분석한다; 자세한 정의는 부록 10.1 참조. 그림 2은 트랜스포머 블록과 그 선형 층을 통한 평균 효과적인 랭크를 보고한다. 이러한 캡슐은 저랭크이지만 일관되게 랭크 하나가 아니다; 그들의 효과적인 랭크는 1보다 약간 높아, 단일 캡슐 제약 하에서 DBF가 표현할 수 없는 여러 크기 모드를 나타낸다.
이 관찰은 단순히 부호 다양성을 증가시키는 것, 예를 들어 LittleBit과 같은 잔차 스타일의 다중 항 설계가 가장 직접적인 해결책이 아니라는 것을 명확하게 한다. 목표는 배포 친화적 추론 경로를 유지하는 것이다. 공유된 이진 전달자는 효율적인 1비트 계산을 가능하게 하며, 단일 캡슐 제약의 병목 현상을 해소한다. 이러한 동기는 Multi-Envelope DBF에 이끌려,MDBF는 동일한 공유된 이진 부호 기반 하에서 더 높은 랭크 진폭 캡슐을 사용하여 표현력을 향상시킨다.