코드 언어 모델의 정확한 오류 예측법 감독 모델이 답이다
📝 원문 정보
- Title: Localized Calibrated Uncertainty in Code Language Models- ArXiv ID: 2512.24560
- 발행일: 2025-12-31
- 저자: David Gros, Prem Devanbu
📝 초록
이 논문에서는 대형 언어 모델(Large Language Model, LLM)이 생성한 코드에서 신뢰할 수 있는 불확실성을 측정하는 방법을 연구합니다. 특히, 코드의 각 부분에 대한 잘 교정된 확률을 제공하여 개발자가 수정해야 할 부분을 식별하도록 돕는 방법을 탐구했습니다.💡 논문 해설
1. **교정된 불확실성 측정**: 이 연구는 LLM이 생성한 코드의 각 부분에 대한 신뢰할 수 있는 확률을 제공하는 방법을 제시합니다. 이를 통해 개발자는 더 효율적으로 코드를 검토하고 수정할 수 있습니다. 2. **다중 샘플링 기법**: 여러 번의 코드 생성을 통해 불확실성을 측정하며, 일관성 높은 부분과 그렇지 않은 부분을 구별합니다. 이는 마치 여러 사람에게 같은 문제를 물어보고 가장 많이 나오는 대답을 신뢰하는 것과 비슷합니다. 3. **잠재 상태 탐지**: 모델의 내부 상태를 분석하여 코드의 특정 부분이 얼마나 정확한지를 추정합니다. 이를 통해 개발자는 코드의 어떤 부분이 수정 필요성이 높은지 쉽게 파악할 수 있습니다.📄 논문 발췌 (ArXiv Source)
대형 언어 모델은 놀라운 양의 복잡한 텍스트를 생성할 수 있습니다. 예를 들어, 능숙한 인간 타이피스트가 최고 속도로 분당 약 500자, 약 10-20줄의 Python 코드를 작성할 수 있다고 가정하면, GPT와 같은 모델은 분당 수천 줄의 (대부분) 문법적으로 올바른 코드를 생성할 수 있습니다. 생성된 코드는 버그가 있을 수 있지만, 작업 시간과 노력을 절약할 가능성이 있습니다. 예를 들어 2022년에 구글 연구원들은 회사 내에서 AI로 생성된 코드 비율이 약 3%였다고 보고했지만, 2025년에는 이 비율이 30%까지 증가했습니다.
LLM이 생성한 코드가 더 복잡해지고 널리 사용될수록, 생성된 출력 시퀀스의 각 부분이 올바를 가능성이 얼마나 되는지 정확하게 추정하는 것이 개발자에게 유익할 것입니다. 이는 품질 관리를 위한 자원 배분을 최적화하고, 모델의 안전 리스크를 줄이는 데 도움이 될 수 있습니다. 예측 모델에서 불확실성을 평가하는 전통적인 방법은 교정된 확률입니다. 이는 출력의 특정 부분이 40% 또는 90% 신뢰할 수 있는지 예측하고, 그 확률이 실제 정확성과 일치하도록 합니다. 이런 교정된 확률은 불확실성을 포함한 합리적인 의사결정을 돕고, 기대되는 결과를 향상시킵니다. 코드 검토의 비용과 어려움을 고려할 때, 생성된 코드에서 가장 주의가 필요한 부분을 명확히 표시하는 교정된 확률은 가치가 있습니다.
이 논문에서는 코드 생성의 맥락에서 잘 교정되고 국소화된 불확실성을 생산하는 문제를 연구하기 위해 몇 가지 실험을 제시합니다. 다음 연구 질문들을 탐구합니다:
- 모델의 잠재 상태는 어떻게 잘 교정되고 국소화된 불확실성을 나타내나요?
- 모델의 확률적 성격은 여러 샘플 간 일관성으로부터 교정된 국소화된 불확실성 추정치를 생성하는 데 사용될 수 있나요?
- 모델은 자신의 출력에 대해 국소화된 불확실성을 어떻게 반영하나요?
- 이러한 기술들은 소프트웨어 엔지니어링 이외의 새로운 도메인에 얼마나 잘 일반화되나요?
각 실험 세트는 공통 평가 방법론을 공유합니다 (제 4 참조). 우리는 자체 포함된 함수 생성 데이터와 고성능 GitHub 프로젝트에서 생성된 함수에 대한 평가를 수행합니다.
동기 및 접근 방식
이 논문의 주요 목표는 개발자가 LLM이 생성한 코드를 더 효과적으로 활용하여 더 나은 품질의 코드를 저렴하게 생산할 수 있도록 돕는 것입니다. 접근 방법은 개발자에게 수정이 필요한 부분을 집중적으로 검토하고 수정하도록 안내하는 것입니다. 우리는 이를 위해 신뢰할 수 있는 국소화된 불확실성 값을 탐색합니다. 단위로 줄과 토큰 레벨에서 이 값을 추정합니다.
 style="width:95.0%" />
style="width:95.0%" />
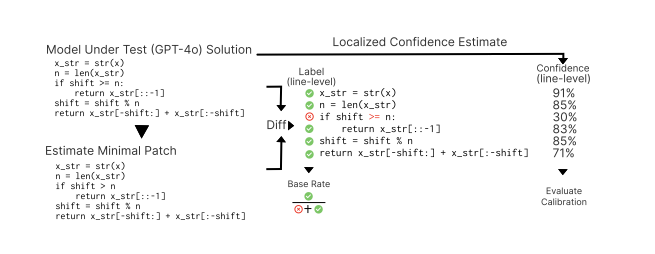
그림 1은 우리의 일반적인 접근 방식을 보여줍니다. 맨 왼쪽 위에는 GPT-4o에서 생성된 원래 코드가 있습니다. 이 코드는 올바르지 않습니다. 행운히도, 이번 경우에는 세 번째 줄의 “>=” 토큰만 수정이 필요합니다. 현재 실무에서는 개발자에게 제공되는 것은 오직 코드뿐입니다. 따라서 이러한 예제에서 우리가 배후에 테스트 케이스를 가지고 있다고 해도, LLM이 생성한 코드의 많은 사용 사례에서는 자연어 프롬프트만을 기준으로 판단해야 합니다. 그러므로 코드가 의도와 일치하지 않는 부분을 감지, 진단하고 국소화하는 것이 어렵습니다.
그림 오른쪽은 같은 코드를 보여주지만 신뢰도 어노테이션이 포함되어 있어 정확성에 대한 가능성을 나타냅니다. 이전 연구는 개발자가 실제로 수정이 필요한 코드 부분을 식별하는 데 정확하고 국소화된 표시가 유익하다는 것을 제안했습니다. LLM에서 생성되는 코드 양 (구글에서 큰 비율)을 고려하면, 신뢰할 수 있는 신뢰도 측정을 통해 검토/수정 작업에 집중하는 것은 장기적으로 가치가 있을 것입니다.
이제 논문의 나머지를 간략히 정리하겠습니다. 먼저 3에서는 관련 작업을 조사하고 “교정"이라는 주요 측정 방법에 대해 설명합니다. 그런 다음 우리의 연구 방법을 설명하며, 그 뒤의 섹션에서 이를 확장합니다. 우리가 첫 번째로 다루는 과제([sec:gathering])는 잘못된 생성 코드와 최소한의 적절한 수정을 포함하는 적합한 데이터셋을 구성하는 것입니다. 이어 각 줄과 토큰에 대한 세밀하게 교정된 신뢰도를 계산하기 위한 다양한 접근 방식을 설명합니다. 우리는 모델에서 얻은 기본 원시 확률 (5)부터 시작하고, 탐사 방법 ([sec:probing])을 제시합니다. 그 다음 다중 샘플링 접근 방식 (7), 그리고 반사적 접근 방법 (8)을 설명합니다. 마지막으로, 자연어 출력에 대한 일반화 가능성, 우리의 연구의 함의를 탐구합니다.
관련 작업 및 배경
여기서 몇 가지 관련 개념과 이전 작업에 대해 논의하겠습니다.
확률적으로 불확실한 예측 (예: “내일 비올 확률이 30%입니다”)은 여전히 합리적인 의사결정을 위해 사용될 수 있습니다. 그러나 그러한 의사결정을 지원하려면 신뢰도 (즉, 확률) 값이 잘 교정되어야 합니다. 확률 숫자는 경험적 빈도를 반영해야 하며, 그에 따른 결정은 실제로 성공할 가능성이 높아야 합니다. 따라서 평균적으로 전체 예측에서 내일 비올 확률을 $`X\%`$로 예측한 경우, 실제로 거의 정확하게 $`X\%`$의 시간 동안 비가 오게 됩니다. 예측된 신뢰도와 경험적 빈도 사이에 일치하는 정도가 더 높을수록 예측된 신뢰도는 “더 잘 교정"됩니다. 신경망에서의 예측에 대한 교정은 오랫동안 관심사였습니다.
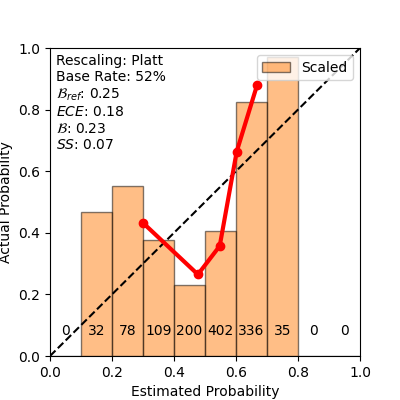
교정을 측정하기 위해 우리는 두 가지 일반적인 교정 측정 방법인 Brier score와 ECE를 사용합니다. Glenn Brier는 1950년에 널리 사용되는 Brier score를 제안했습니다. 이는 신뢰도와 실제 결과 사이의 평균 제곱 오차를 샘플 예측 집합 위에서 측정하며, 예측된 신뢰도가 실제 결과로부터 얼마나 벗어나는지를 추정합니다. 모델의 Brier score를 계산하는 방법은 [def:brier]에서 볼 수 있습니다: $`p_i`$는 샘플 $`T`$의 크기 $`N`$에 대한 $`i^{th}`$ 예측의 신뢰도를 나타내며, 여기서 $`o_i`$는 결과입니다.
\begin{equation}
B_{model} = \frac{1}{N} \sum_{i=1}^{N} (\hat{p_i} - \hat{o_i})^2
\label{def:brier}
\end{equation}\begin{equation}
B_{ref} = p *(1-p)
\label{def:briarref}
\end{equation}\begin{equation}
BSS = \frac{(B_{ref} - B_{model})}{B_{ref}}
\label{define:SS}
\end{equation}Brier score를 얻기 쉽다는 점에 주목해야 합니다. 특히 기반 빈도 (즉, 비가 오는 전체 경험적 빈도)가 매우 높거나 낮을 때입니다. 예를 들어, 비가 거의 매일 내리는 열대 우림에서는 지속적으로 매일 95%의 비 예측 확률이 주로 맞게 되어 낮은 Brier score를 얻습니다. 따라서 기반 빈도 $`p`$에 대해 항상 확률 $`=p`$를 예측하는 간단한 모델을 고려할 수 있습니다; 그런 모델의 참조 Brier score는 [def:briarref]에서 계산됩니다. 실제로, 이 “AZY” 접근 방식을 개선하는 것이 중요합니다. 따라서 일반적으로 스킬 점수 $`SS`$를 보고하며, 이는 참조 Brier 값에 대한 개선을 나타내며, [define:SS]에서 계산됩니다. 스킬 점수 값은 모델이 신뢰도가 거의 완전히 틀릴 때 $`-\infty`$에서, 모델의 신뢰도 값이 샘플 내 각 이벤트에 대한 실제 발생과 거의 완벽하게 일치할 때 $`1`$까지 범위를 가집니다.
\begin{equation}
acc(B_i) = \frac{1}{|B_i|} \sum_{\hat{o_i}\in B_i} {\hat{o_i}}
\label{def:accuracy}
\end{equation}\begin{equation}
conf(B_i) = \frac{1}{|B_i|} \sum_{\hat{p_i}\in B_i} {\hat{p_i}}
\label{def:confidence}
\end{equation}\begin{equation}
ECE = \displaystyle\sum_{i=1}^m \frac{\mid B_i \mid}{N} \lvert \text{acc}(B_i) - \text{conf}(B_i) \rvert
\label{def:ECE}
\end{equation}교정을 측정하는 또 다른 방법은 $`ECE`$입니다. 이 측정 방식은 샘플 $`T`$의 $`N`$ 예측 확률을 범위로 나눠 (예: $`\{0\text{--}0.1, 0.1\text{--}0.2, \ldots, 0.9\text{--}1\}`$), 각 빗물 예측 결과의 경험적 빈도를 측정합니다. 따라서 이 사례에서 잘 교정된 신뢰도가 있는 경우 가장 낮은 범위에서는 경험적 빈도가 $`10\%`$, 가장 높은 범위에서는 $`90\%`$ 정도가 됩니다. $`ECE`$는 각 빗물 예측의 평균 신뢰도와 평균 결과 빈도 사이의 차이를 측정합니다. 다시, 샘플 집합 $`T`$의 예측을 $`m`$ 개의 버킷으로 나눈 것으로 가정하며, $`B_i,~i=1 \ldots m`$. [def:accuracy]는 버킷 $`B_i`$의 평균 빈도를 계산하는 방법을 보여주며, [def:confidence]은 $`B_i`$에 대한 평균 신뢰도이며, [def:ECE]는 전체 샘플의 크기 $`N = \mid T \mid`$에서 모든 $`m`$ 개 버킷에 대한 ECE 계산을 보여줍니다. 명백히, 잘 교정된 모델은 정확도와 신뢰도를 더 잘 일치시키고 낮은 ECE 값을 가집니다. 그러나 ECE는 모델이 “버킷 콜라스"를 앓아서 잘못될 수 있습니다, 즉, 모든 예측에 대해 기반 빈도 신뢰도만 생성하는 경우; 이런 경우에는 값들이 하나의 확률 버킷으로 모두 붕괴되어 ECE가 0일 수 있지만 모델의 신뢰도는 거의 가치가 없습니다.
완전성을 위해 AUC-ROC도 보고합니다. 이것은 무작위로 선택한 유지 토큰/줄이 삭제된 토큰/줄보다 더 높은 신뢰도를 가질 확률을 나타냅니다. 따라서 이는 신뢰도 기법의 신호를 측정하지만 직접적인 교정 측정은 아닙니다.
몇 가지 이전 작업에서는 LLM에 제시된 생성 문제 수준에서 교정을 평가했습니다. 목표는 모델로부터 생성된 전체 (возможно, длинный и многострочный) ответа의 хорошо калиброванную уверенность получить. Хотя это полезно, пользователи, сталкивающиеся с долгим и многострочным выводом, могут задаться вопросом: не являются ли некоторые части более надежными, чем другие? Таким образом, иметь хорошо калиброванные уверенности на уровне строки и токена для фокусировки проверочных усилий было бы желательно. Наша цель здесь - продемонстрировать техники, которые могут обеспечить хорошо калиброванные уверенности на уровнях завершения, строк и токенов.
Далее мы обсудим несколько различных способов получения мер уверенности.
Уверенность от моделей: врожденная и вербализованная рефлексия
Языковые модели, будучи стохастическими генераторами (через выборку), интuitивно связывают уверенности с генерируемым выводом. Таким образом, если сгенерировано $`n`$ токенов, каждый из них связан с значением уверенности напрямую моделью[^2]. Эти значения по токенам могут быть накоплены на уровне строки или всего проблемы для получения уверенностей различных уровней детализации. Кроме того, модели также можно снова запросить после первоначальной генерации, чтобы “размышлять” о сгенерированном содержимом и вербализовать рейтинг того, что сгенерированный вывод действительно правильный. Предыдущие работы исследовали некоторые из этих подходов на самом грубом (полное генерирование) уровне детализации и сообщили положительные показатели навыков на этом грубом уровне. В этой работе мы используем вербализованную оценку уровня строки путем рефлексивного запроса.
Уверенность от выборки и различий
Локальная, хорошо калиброванная оценка уверенности стремится предсказать точно какие части сгенерированного текста являются низкой уверенностью, а значит наиболее вероятными для изменения. Один из способов сделать это - сравнить сгенерированный код с другими возможными версиями того же кода. Например, если бы мы могли (гипотетически) получить различные возможные будущие версии кода, затем, путем простого различия, мы смогли бы локализовать части кода, которые остаются неизменными во всех возможных будущих состояниях и какие нет. Затем мы могли бы сообщить о большей уверенности в тех частях, которые остаются неизменными во многих из возможных будущих состояний. Это похоже на подход “самосогласованности” . Различные работы применили согласованность для оценки уверенности в естественном языке . используют несколько образцов от модели кода, чтобы пометить токены как “неуверенные” или “уверенные”. Вместо фокуса на калибровку они формулируют цели через функцию полезности и используют умное оптимизационный алгоритм для сравнения образцов, что сложнее того, что мы исследуем. использует повторную выборку для оценки надежности модели-сгенерированных команд shell. В этой работе мы генерируем для получения детализированных уверенностей на уровне строки и токена, используя несколько образцов генерации, как мы описываем ниже в 7.
Уверенность от скрытого пробирования
Генеративные языковые модели имеют очень высокоразмерное, богатое внутреннее представление текущего состояния текста, который они генерируют. Предыдущие работы показали, что концепты такие как честность, правильность и т. д. могут быть довольно точно отображены из внутренних представлений. Это относится к исследованиям пробников
📊 논문 시각자료 (Figures)