- Title: Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
- ArXiv ID: 2512.24574
- 발행일: 2025-12-31
- 저자: Zhenyu Zhang, Xiaoxia Wu, Zhongzhu Zhou, Qingyang Wu, Yineng Zhang, Pragaash Ponnusamy, Harikaran Subbaraj, Jue Wang, Shuaiwen Leon Song, Ben Athiwaratkun
📝 초록
최근 강화 학습(RL) 기반 훈련을 통해 대형 언어 모델(LLM)의 추론 능력이 크게 향상되었지만, 이들 모델은 여전히 비효율적인 사고 과정을 보일 때가 많다. 본 논문에서는 인지 행동을 추적하고 조절할 수 있는 특정 주의 머리들이 있다는 가설을 제시하고, 이를 통해 'CREST'라는 훈련 없이 추론 중에 사고 패턴을 수정하는 프레임워크를 소개한다. CREST는 모델 내부에서 인지 행동을 조절할 수 있는 주의 머리들을 찾아내고, 테스트 시간에 이들 머리들의 활성화를 조작하여 모델의 사고 경로를 유도한다.
💡 논문 해설
1. **인지 머리 발견**: 본 논문은 특정 주의 머리들이 특정 사고 행동과 상관관계가 있다는 증거를 제공하며, 이를 통해 모델 내부에서 이러한 패턴이 어떻게 나타나는지 이해할 수 있다.
2. **테스트 시간 행동 조절**: 플러그 앤 플레이 활성화 개입 기법을 제안하여 추가 훈련 없이 사고 행동을 유도한다.
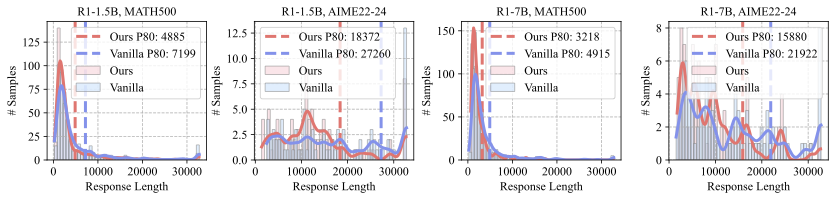
3. **종합적 평가**: 다양한 사고 벤치마크를 통해 CREST의 성능을 검증하고, 이는 추론 정확성을 높이고 토큰 사용량을 크게 줄이는 것을 보여준다.
📄 논문 발췌 (ArXiv Source)
# 서론
최근 강화 학습(RL) 기반 훈련을 통해 대형 언어 모델(LLMs)의 추론 능력이 크게 개선되어 ‘아하!’ 순간을 경험하고 복잡한 작업, 특히 코딩과 계획에 우수하게 대응할 수 있게 되었다. 이러한 능력은 주로 확장된 사고 과정(Chain-of-Thought, CoT) 추론 과정으로 이루어진다. 그러나 효과적이면서도 LLMs가 생성하는 추론 경로는 종종 비최적화 상태에 놓여 있다. 효율성 측면에서 긴 CoT 과정은 표준 응답보다 훨씬 많은 토큰을 소비하며, 특히 장치 내부 애플리케이션에서는 지연 문제가 발생할 수 있다. 성능 측면에서는 최근 연구가 LLMs가 과도한 사고를 하는 경우와 간단한 문제에 대해 불필요하게 긴 설명을 생성하거나 복잡한 솔루션을 완전히 탐색하기 전에 추론을 중단하는 ‘부족한 사고’를 보일 수 있음을 보여주었다. 기묘하게도, 일부 연구는 명시적인 사고 과정 없이도 효과적인 사고가 발생할 수 있다는 것을 제안하고 있다.
추론 과정을 안내하고 향상시키기 위해 이전 작업은 주로 응답 길이를 직접 조절하는 데 초점을 맞추었다. 그러나 이러한 추론 행동을 구성하고 구동하는 내부 인지 메커니즘에 대한 탐구는 제한적이었다. 인지 심리학에서 계획, 확인, 역추적과 같은 의도적인 과정이 System 2 사고와 연결되어 인간의 문제 해결 능력을 향상시키는 것에서 영감을 받아, 우리는 비슷한 인지 행동을 식별하고 특히 중요하게도 조절할 수 있음을 제안한다. 특히, 일부 모델 구성 요소인 주의 머리들이 이러한 다양한 추론 패턴을 추적하고 조정하는 데 특화되어 있다고 가설을 세운다.
본 논문에서는 사고 과정을 두 가지 유형으로 분류한다: 선형 추론(즉, 단계별 문제 해결)과 비선형 추론(예: 역추적, 확인 및 기타 발산적인 행동). 이러한 행동이 활성화 공간에 어떻게 나타나는지 이해하기 위해 개별 사고 단계를 적절히 라벨링하고 숨겨진 활성화 기반으로 간단한 선형 분류기를 훈련시켜 이를 구분한다. 선형 프로브를 사용하여 특정 주의 머리들을 식별한다. 이들 머리들의 활성화는 사고 유형을 높은 예측력을 가진 것으로 나타난다. 또한, 이러한 머리를 조절하면 추가 훈련 없이 모델의 인지 경로를 효과적으로 변경할 수 있다.
이 발견에 기반하여 우리는 CREST(Cognitive REasoning Steering at Test-time)라는 훈련 없는 프레임워크를 소개한다. 이 프레임워크는 추론 중 동적으로 사고 행동을 조정할 수 있다. CREST는 간단한 오프라인 캘리브레이션을 수행하여 인지 머리를 식별하고 대표적인 사고 예제로부터 조절 벡터를 계산한다. 그런 다음, 테스트 시간에 이러한 벡터 기반 활성화 개입을 사용하여 모델의 추론 경로를 적응적으로 안내하며 비효율적인 인지 모드를 억제하고 효과적인 사고 행동을 장려한다. 특히 CREST는 다양한 사전 훈련된 LLMs과 호환되며, 특정 작업별 재훈련이나 기울기 업데이트가 필요하지 않으므로 실제 세계 응용 프로그램에 매우 확장 가능하고 실용적이다. 그리고 테스트 시간 조정은 무시할 수 있는 오버헤드를 초래하며 처리량을 유지하면서 토큰 소비를 줄여, 전반적인 엔드-투-엔드 효율성을 향상시킨다.
요약하면, 우리의 주요 기여는 다음과 같다: (i) 인지 머리 발견: 특정 사고 행동과 상관관계가 있는 인지 주의 머리가 존재한다는 실증적 증거를 제공하여 모델 내부 상태에서 어떻게 인식 패턴이 나타나는지를 새롭게 해석한다. (ii) 테스트 시간 행동 조절: 추가 훈련 없이 추론 행위를 유도하는 플러그 앤 플레이 활성화 개입 기법을 제안한다. (iii) 종합적 평가: 다양한 사고 벤치마크에서 우리의 방법을 검증하고, CREST는 추론 정확성을 향상시키고(AMC23의 R1-1.5B에서 최대 17.50%), 토큰 사용량도 크게 줄인다(MATH500, AMC23, AIME, LiveCodeBench, GPQA-D 및 캘린더 계획).
추론 모델. 초기 사고 과정(CoT) 프롬프팅 및 자체 일관성 디코딩은 다양한 추론 경로를 샘플링하고 다수의 답변을 선택하여 정확도를 향상시킨다는 것을 보여주었다. 구조화된 탐색 프레임워크는 이러한 아이디어를 확장한다: Tree-of-Thought, Graph-of-Thought 및 Forest-of-Thought. 최근 “생각” 모델 출시인 OpenAI의 o-시리즈, Anthropic의 Claude-3.7-Sonnet-Thinking, Google의 Gemini-2.5-Flash와 함께 경쟁적인 오픈소스 모델인 DeepSeek-R1, Phi-4-Reasoning 및 Qwen3과 같은 것들이다. 이러한 발전은 모델의 추론 능력을 향상시키고 내부 메커니즘에 대한 심층 분석의 새로운 가능성을 창출한다.
LLMs의 인지 행동. 최근 연구는 사고 추적에서 반복되는 패턴을 인지 행동으로 정의하며, 이는 정확도와 상관관계가 있는 검증, 역추적 또는 하위 목표 계획 등의 행동이다. 이러한 것은 인간 문제 해결 휴리스틱과 닮아 있으며 LLMs에 유사한 행동을 명시적으로 부여하는 방법론을 동기부여한다. 우리의 연구는 이 선을 확장하여 이러한 행동과 관련된 내부 주의 머리를 식별한다.
테스트 시간 추론 개선. 추론 시 사고를 향상시키는 방법에는 재훈련 없이 이루어진다. 주목할 만한 접근법은 (i) 동적 토큰 할당을 수행하는 적응형 계산 제어, (ii) 사고 과정 체인의 수정 또는 압축을 수행하는 직접 추적 조작 등이다. 최근 활성화 편집 방법은 숨겨진 표현을 직접 유도한다. 우리의 접근 방식 CREST는 인지 주의 머리를 식별하고 효율성을 개선하면서 새로운 해석 가능성을 제공하기 위해 표적 머리 수준 조작을 시연한다.
추론에서 인지 패턴 분석 및 조절
이 섹션에서는 사고 모델이 어떻게 인지 행동을 나타내고 내부화하는지 살펴본다. 특히 역추적, 하위 목표 형성 및 역추적과 같은 비선형 사고 패턴에 초점을 맞춘다. 우리는 먼저
Section 3.1에서 이러한 행동을 개별 추론 단계 수준에서 식별하고 분류한다.
Section [sec:prob]에서는 그러한 행동이 주의 머리들의 내부 활성화에 어떻게 반영되는지 조사하며, 여기서 일부 부분인 인지 머리가 비선형 추론을 일관되게 인코딩하는 것을 발견한다. 마지막으로
Section 3.3에서는 이러한 머리를 테스트 시간에 직접 조작하여 모델의 추론 경로를 유도하는 방법을 시연하며, 재훈련 없이 복잡한 사고에 대한 세밀한 제어 메커니즘을 제공한다.
추론 모델의 인지 행동
O1과 같은 LLMs은 확장된 사고 과정 사고를 통해 문제를 해결하고 종종 전통적인 단계별 사고에서 벗어난 비선형 패턴을 보여준다. 이러한 비선형 경로(예: 역추적, 검증, 하위 목표 설정 및 역 추론)는 인간 인지 행동과 유사하며 모델이 복잡한 문제 해결 작업에 대응할 수 있는 능력을 향상시킨다.
인지 행동을 분석하기 위해 사고 과정은 일반적으로 <think>와 </think> 마커 토큰으로 구분되며, 각 단계는 “``\n \n```” 토큰 시퀀스로 구분된다. 그런 다음 각 추론 단계를 키워드 일치를 통해 두 가지 유형 중 하나로 분류한다: 비선형 사고 단계는 정의된 세트에서 어떤 키워드($`\{\mathrm{Wait}, \mathrm{Alternatively}\}`$; 전체 목록은
Appendix 8.1)를 포함하는 경우 비선형으로 표시되며, 그렇지 않으면 선형 사고 단계로 분류된다. 우리는 여러 토큰으로 구성된 단일 추론 단계를 $`\mathrm{S}`$라고 표기하고 각각을 $`\mathrm{S}^l`$과 $`\mathrm{S}^n`$으로 나타낸다.
인지 행동의 주의 머리 식별
추론 중에 인지 행동을 분석하는 것은 본질적으로 어렵다. 같은 행동, 예를 들어 검증은 샘플의 맥락 및 기본 사고 패턴에 따라 토큰 공간에서 다르게 나타날 수 있다. 직관적으로 이러한 행동은 종종 장거리 토큰 상호작용을 포함하며 모델이 이전 추론 단계를 검색하고 재평가한다. 최근 연구는 주의 머리가 사실 확인, 위치 정렬 등의 다양한 해석 가능한 기능을 수행한다는 것을 보여주었다. 이러한 통찰에 동기부여되어 우리는 사고 중 인지 행동과 강하게 상관관계가 있는 주의 머리를 식별하기 위해 초보적인 연구를 진행한다.
/>
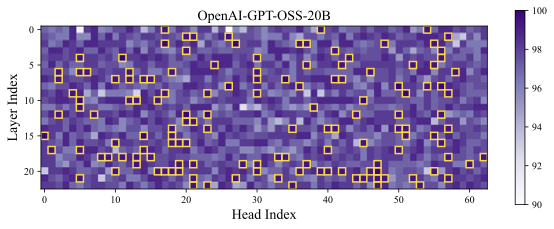
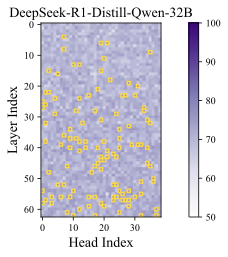
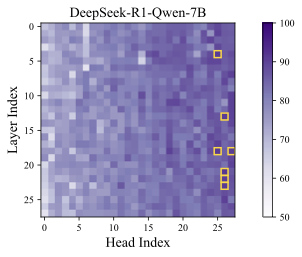
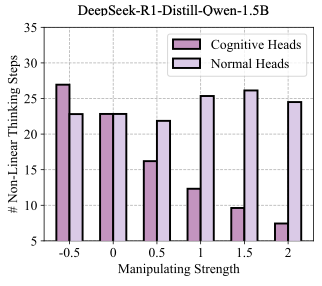
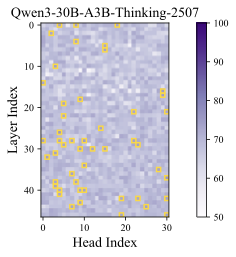
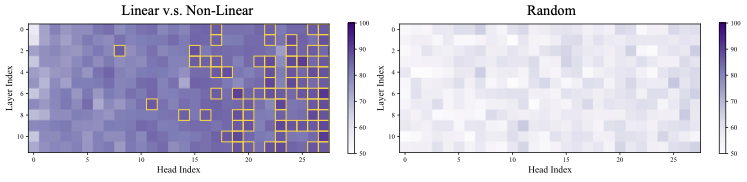
DeepSeek-R1-Distill-Qwen-1.5B에 대한 탐침 정확도 시각화 (좌) 선형 및 비선형 추론 단계의 정확성, 85% 이상인 고정확도 영역이 황금색 상자로 강조 표시됨. (우) 무작위 샘플링 토큰에 대한 정확성 측정. 설정은 Section [sec:prob].
설정. 우리는 MATH-500 벤치마크에서 무작위로 500개의 훈련 샘플을 추출하고 DeepSeek-R1-Distill-Qwen-1.5B 모델을 사용하여 end-to-end 추론을 실행한다. 여기서 “단계"는 특수 구분자 토큰 \n\n 사이의 연속적인 사고 텍스트 조각으로 정의된다.
구성 요소. 각 프롬프트에 대해 사고 과정을 구분자 \n\n에서 나누어 $`\{s_1, s_2,\ldots,s_k\}`$로 구성되는 k 개의 세그먼트를 생성한다. 구분자는 유지되므로 \n\n은 각 세그먼트의 최종 토큰이므로 모든 $`s_\ell`$ (with $`\ell=1,\dots,k`$)는 하나의 이산 사고 단계를 나타낸다.
각 단계 임베딩. 사고 과정 $`\{s_1, s_2, ..., s_k\}`$을 단일 프리필로 실행하고 구분자 토큰 \n\n에서 숨겨진 상태를 캡처한다. 이를 이전 토큰의 간결한 요약으로 취급하고 포스트 주의 활성화
를 추출한다. 여기서 $`i`$는 머리들을 인덱싱하고 $`j`$는 층을 인덱싱한다. 따라서 $`a^{i,j}_{s_k}`$는 세그먼트 $`s_k`$의 마지막 구분자 토큰(\n\n)의 컨텍스트 임베딩을 나타낸다.
3. 라벨링 및 프로브. 각 단계를 선형 ($`y_{s_k}=0`$) 또는 비선형 ($`y_{s_k}=1`$)으로 표시한다. 모든 머리 $`(i,j)`$에 대해 선형 프로브
를 피팅한다. 여기서 $`\sigma`$는 시그모이드 함수이고, $`f`$는 평균 제곱 오차 손실 함수다.
결과 프로브는 선형 및 비선형 사고를 가장 잘 구분하는 머리를 지정하며, 이는 캘리브레이션 및 조절 단계의 기초가 된다.
여러 프롬프트에 걸쳐. 각 프롬프트 $`\ell`$에 대해 세그먼트화는 $`k_\ell`$ 단계
$`S^{(\ell)}=\{s^{(\ell)}_1,\dots,s^{(\ell)}_{k_\ell}\}`$. 전체적으로 이러한 것은 글로벌 집합
$`\mathcal{S}=\bigcup_{\ell=1}^{n} S^{(\ell)}`$, 그 크기는 $`|\mathcal{S}|=\sum_{\ell=1}^{n} k_\ell`$. 각각의 $`S^{(\ell)}\in\mathcal{S}`$는 앞서 설명한대로 임베딩, 라벨링 및 프로브를 수행하므로 모든 다운스트림 분석은 전체 $`\sum_{ \ell=1}^{n}k_ \ell`$ 사고 단계에 대해 작동한다. 우리는 prompt $`\ell`$을 정의하는 $`a^{i,j}_{s_k^{(\ell)}}`$를 정의한다.
결과. 분류 정확도는
Figure 1에 보여지며, 다른 모델 및 데이터셋에 대한 추가 결과는
Appendix 9.1에서 제공된다. 정상 점검으로 무작위로 샘플링된 토큰에 대해 프로브 절차를 반복하고, 오른쪽 부분의 Figure1에서 분류 정확도는 기회 수준 근처로 유지되어 구별 가능한 신호가 없다. 반면에 왼쪽 하위 그림은 특정 주의 머리들이 훨씬 더 높은 정확도를 달성한다는 것을 보여준다. 이러한 머리들을 인지 머리라고 지칭하며 나머지는 표준 머리로 처리한다. 특히 깊은 층에서 인지 머리가 더 많이 발견되며, 이것은 깊은 층이 고수준 의미적 특징을 포착하고 얕은 층이 토큰 수준의 특징을 인코딩하는 기대와 일치한다. 일부 인지 머리는 중간 층에서 나타나며 이는 모델 내부에 분산된 인지 기능의 출현을 시사한다.
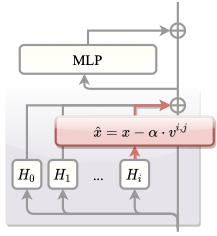
활성화 개입을 통한 인지 행동 조절
r0.26 style=“width:100.0%” />
우리는 비선형 사고 과정이 가장 “인지적"인 주의 머리들의 활성화를 직접 편집하여 테스트 시간에 조절할 수 있는지 조사한다.
프로토타입 생성. 설정에서 정의한 것처럼 각 프롬프트에 대해
$`N_\ell = \sum_{k=1}^{|S^{(\ell)}|}\mathbb{I}[y_{s_k^{(\ell)}}=1]`$
비선형 사고가 있다. $`v_\ell^{i,j}
= \frac{1}{N_\ell}
\sum_{k=1}^{|S^{(\ell)}|}a^{i,j}_{s_k^{(\ell)}}\,
\mathbb{I}[y_{s_k^{(\ell)}}=1]`$를 정의하면 $`\ell`$번째 프롬프트에 대한 비선형 평균 활성화이며, 머리별 벡터로 비선형 사고의 평균 패턴을 포착한다: