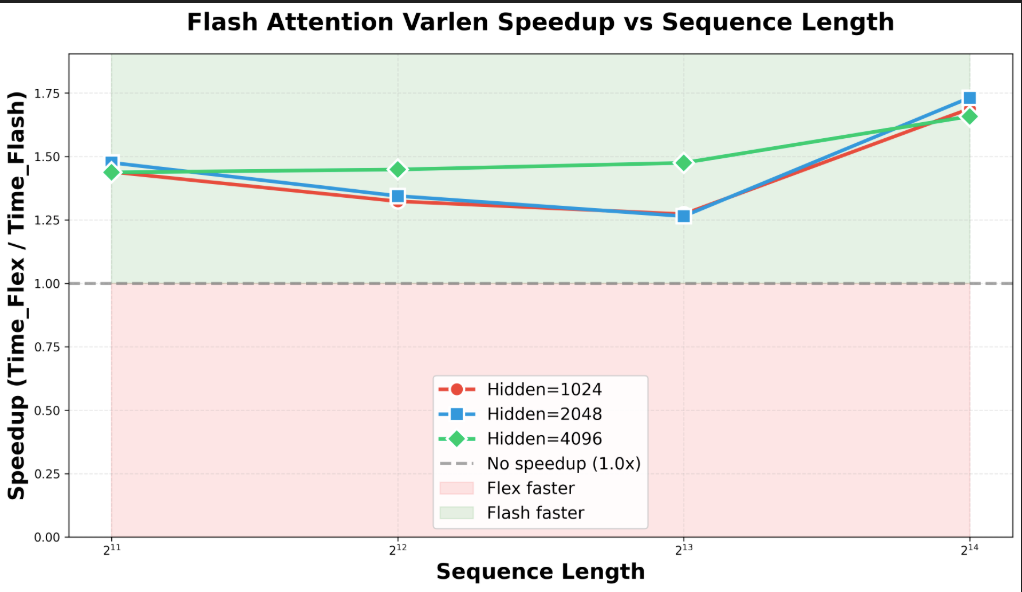
- Title: Dynamic Large Concept Models Latent Reasoning in an Adaptive Semantic Space
- ArXiv ID: 2512.24617
- 발행일: 2025-12-31
- 저자: Xingwei Qu, Shaowen Wang, Zihao Huang, Kai Hua, Fan Yin, Rui-Jie Zhu, Jundong Zhou, Qiyang Min, Zihao Wang, Yizhi Li, Tianyu Zhang, He Xing, Zheng Zhang, Yuxuan Song, Tianyu Zheng, Zhiyuan Zeng, Chenghua Lin, Ge Zhang, Wenhao Huang
📝 초록
대형 언어 모델(Large Language Models, LLMs)은 자연어 처리에서 큰 성공을 거두었지만, 이들 모델은 모든 토큰에 동일한 계산을 적용하는 통상적인 가정을 가지고 있다. 본 논문에서는 이 제약을 벗어나, [[IMG_PROTECT_N]] 동적 대형 개념 모델(Dynamic Large Concept Model, DLCM)을 제안한다. DLCM은 토큰 수준의 예측에 필요한 계산량을 최소화하고, 정보 밀도가 높은 부분에 더 많은 계산 자원을 할당함으로써 효율성을 극대화한다.
💡 논문 해설
1. **개념 수준의 은닉 추론과 학습 경계**: DLCM은 텍스트를 의미 있는 개념 단위로 분할하고, 이 개념들에 대해 깊게 추론하는 모델을 제안합니다. 이를 통해 계산 효율성을 높일 수 있습니다.
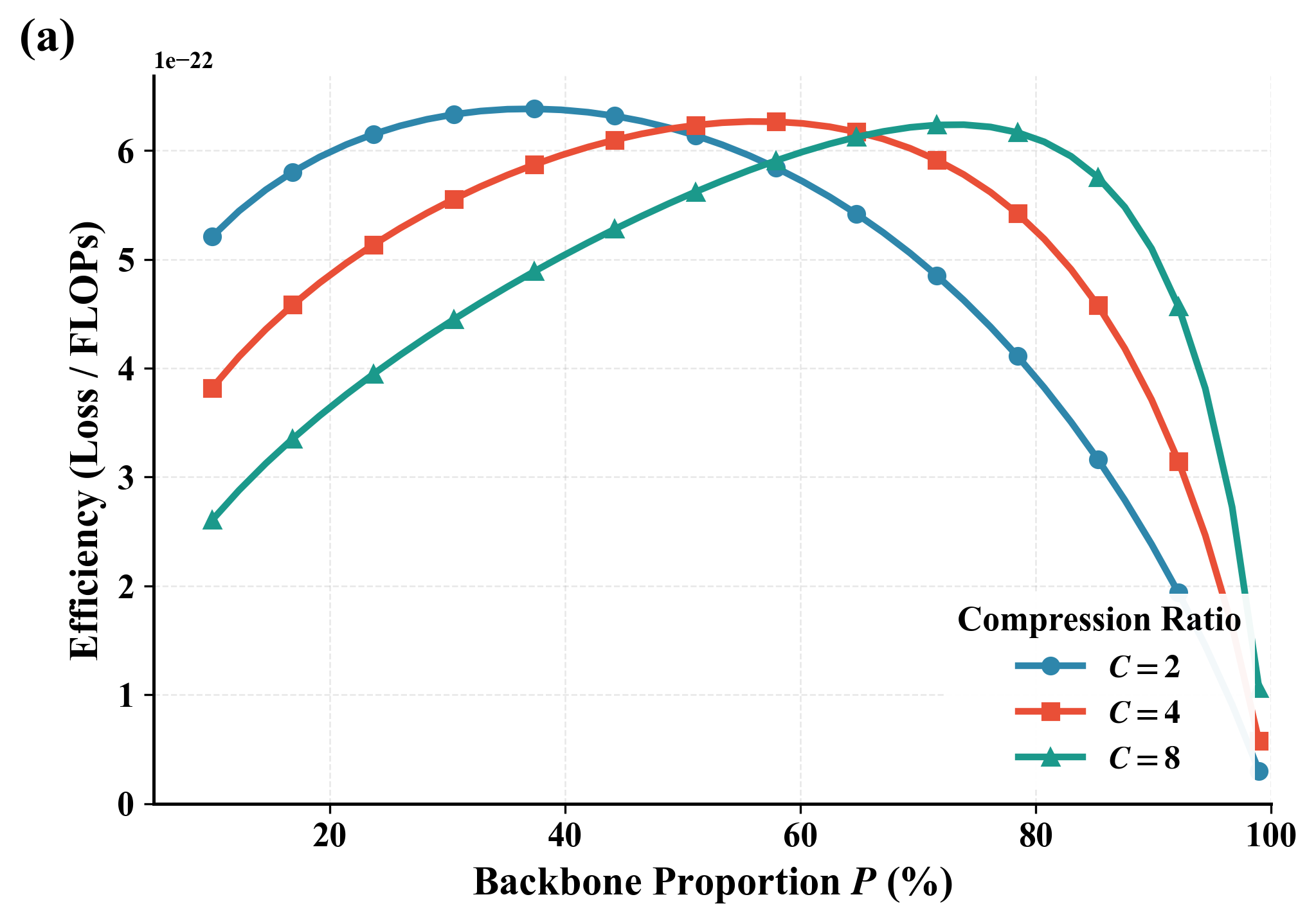
2. **압축 인식 스케일링 법칙**: DLCM은 총 파라미터, 데이터, 압축 비율 및 개념 백본 할당 간의 상호 작용을 모델화하는 공식을 제시합니다. 이를 통해 계산 리소스를 효과적으로 배분할 수 있습니다.
3. **다양한 모듈을 위한 분리된 μP**: DLCM은 다양한 구성 요소에 대해 서로 다른 학습 속도와 초기 가중치 변동을 사용하여 안정적인 훈련을 보장합니다.
📄 논문 발췌 (ArXiv Source)
# 소개
DLCM의 개요 구조.
대형 언어 모델(LLMs)은 자연어 이해, 추론 및 생성 작업에서 놀라운 성공을 거두었습니다. 규모와 학습 데이터에 대한 차이에도 불구하고 거의 모든 최첨단 모델은 공통의 구조적 가정을 가지고 있습니다: 언어는 토큰 수준에서 일관되게 처리되고, 순서열 내의 각 위치에 동일한 깊이와 계산이 적용됩니다.
이 가정은 자연어의 구조와 극명하게 대비됩니다. 정보 밀도는 매우 비균질합니다: 로컬 예측 가능성이 높은 긴 스패닝이 새 개념을 도입하고 추론 난이도가 집중되는 희박하지만 의미적으로 중요한 전환점과 교차합니다. 그럼에도 불구하고 표준 LLM들은 두 가지 제도 모두에 완전한 계산력을 소비하여 상당한 중복과 시스템적인 모델 용량의 잘못된 할당을 초래합니다.
더 근본적으로, 이 효율성 저하는 토큰 수준의 모델링 자체의 한계를 반영합니다. 추론은 본질적으로 계층적입니다: 인간들은 표면 표현에 앞서 아이디어나 개념과 같은 추상 단위에서 추론을 진행합니다. 그러나 토큰 수준 자동회귀 모델은 어떠한 명시적인 추상 메커니즘도 없이 모든 층에서 다음 토큰 예측을 통해 상위 구조를 반복적으로 추론해야 합니다.
이전 연구는 이 제약을 완화하는 방법을 탐구했지만, 중요한 한계점이 있었습니다. 잠재적 추론 접근법은 명시적인 토큰 생성 없이 연속된 숨겨진 공간에서 추론을 수행하며, 문장 수준 개념 모델은 고정된 인간이 정의한 구분을 기반으로 합니다. 이들 중 어느 것도 모델이 의미적 계산이 어디에 집중되어야 하는지 학습할 수 있도록 하지는 않습니다.
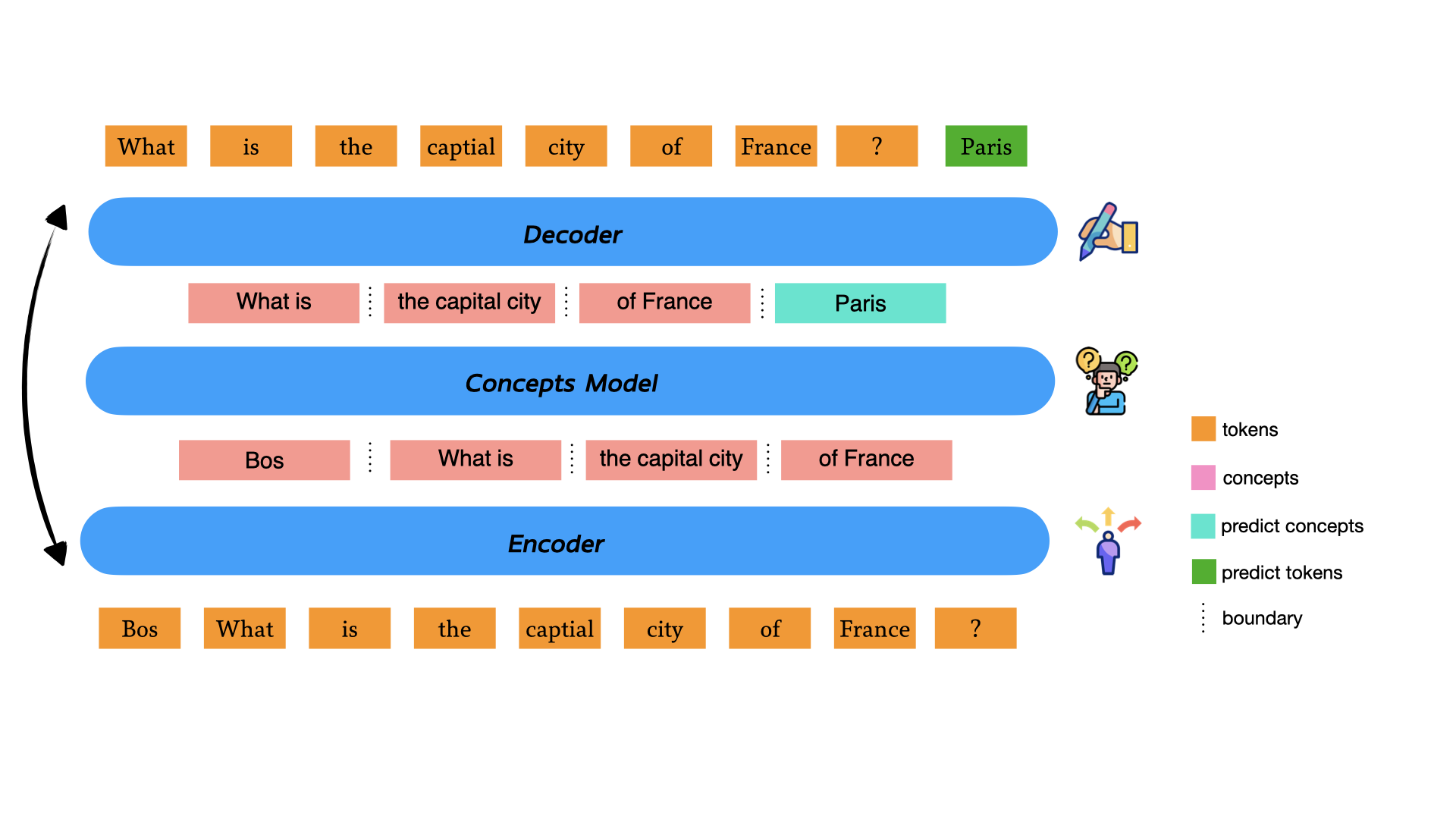
우리는 효과적인 추론이 학습된 중간 단위를 요구한다는 주장을 제기합니다: 원시 토큰이나 사전 정의된 문장이 아닌, 표현 공간에서 직접 발견되는 가변 길이 의미적 개념입니다. 이 통찰을 바탕으로 [[IMG_PROTECT_N]] 동적 대형 개념 모델(DLCM) 을 제안합니다. DLCM은 계층적 다음 토큰 예측 프레임워크로, 토큰 시퀀스를 개념으로 동적으로 분할하고 압축된 개념 공간에서 깊게 추론을 수행하며 인과적인 크로스 어텐션을 통해 토큰 수준의 예측을 재구성합니다.
이 설계는 무엇에 대해 추론해야 하는지와 어떻게 추론해야 하는지를 분리합니다. 의미 경계를 end-to-end 학습하고 중복된 토큰 처리에서 계산력을 개념 수준 추론으로 이동함으로써 DLCM은 정보 밀도에 맞게 적응적인 계산 자원 할당을 가능하게 합니다.
반대 극단에서는 H-NET이 학습된 경계 감지와 적응적 계산 자원 할당의 가능성과 함께 바이트 수준에서 작동하며, 현대 LLM 파이프라인 내에서 표준 다음 토큰 예측(NTP) 베이스라인에 대한 검증은 이루어지지 않았습니다.
우리의 연구는 이러한 격차를 메꾸기 위해 [[IMG_PROTECT_N]] 개념 수준의 잠재적 추론을 도입합니다. 본 논문 전체에서 개념이라는 용어는 표현 공간에서 발견된 가변 길이 잠재 세그먼트를 의미하며, 언어적으로 사전 정의된 의미 단위가 아닙니다. 핵심 통찰은 효과적인 추론이 토큰 수준의 세분화(너무 미세하고 계산적으로 낭비됨)나 문장 수준의 세분화(너무 광범위하고 유연성이 부족함)가 아닌 의미상 일관된 개념을 요구하며, 이 경계는 데이터를 통해 end-to-end 학습됩니다. 우리는 [[IMG_PROTECT_N]] DLCM 을 제안합니다. 이 계층적 아키텍처는 네 단계 파이프라인을 통해 이 통찰을 구현합니다(Figure 1):
인코딩: 가벼운 인코더가 원시 토큰을 처리하여 미세한 표현을 추출합니다.
동적 분할: 학습된 경계 감지기가 인접 토큰 표현 사이의 로컬 비슷성을 측정함으로써 의미적인 브레이크포인트를 식별합니다. LCM의 고정 문장 경계와 달리 이러한 경계는 모델 자체의 잠재 공간을 통해 end-to-end 최적화를 통해 발생합니다.
개념 수준 추론: 각 세그먼트 내의 토큰은 통합된 개념 표현으로 그룹화됩니다. 고용량 변환기는 이 압축된 개념 시퀀스에 대해 깊게 추론을 수행하며, 대부분의 계산이 여기서 발생합니다.
토큰 수준 디코딩: 디코더는 인과적 크로스 어텐션 메커니즘을 통해 추론된 개념에 주목하여 토큰 수준 예측을 재구성합니다.
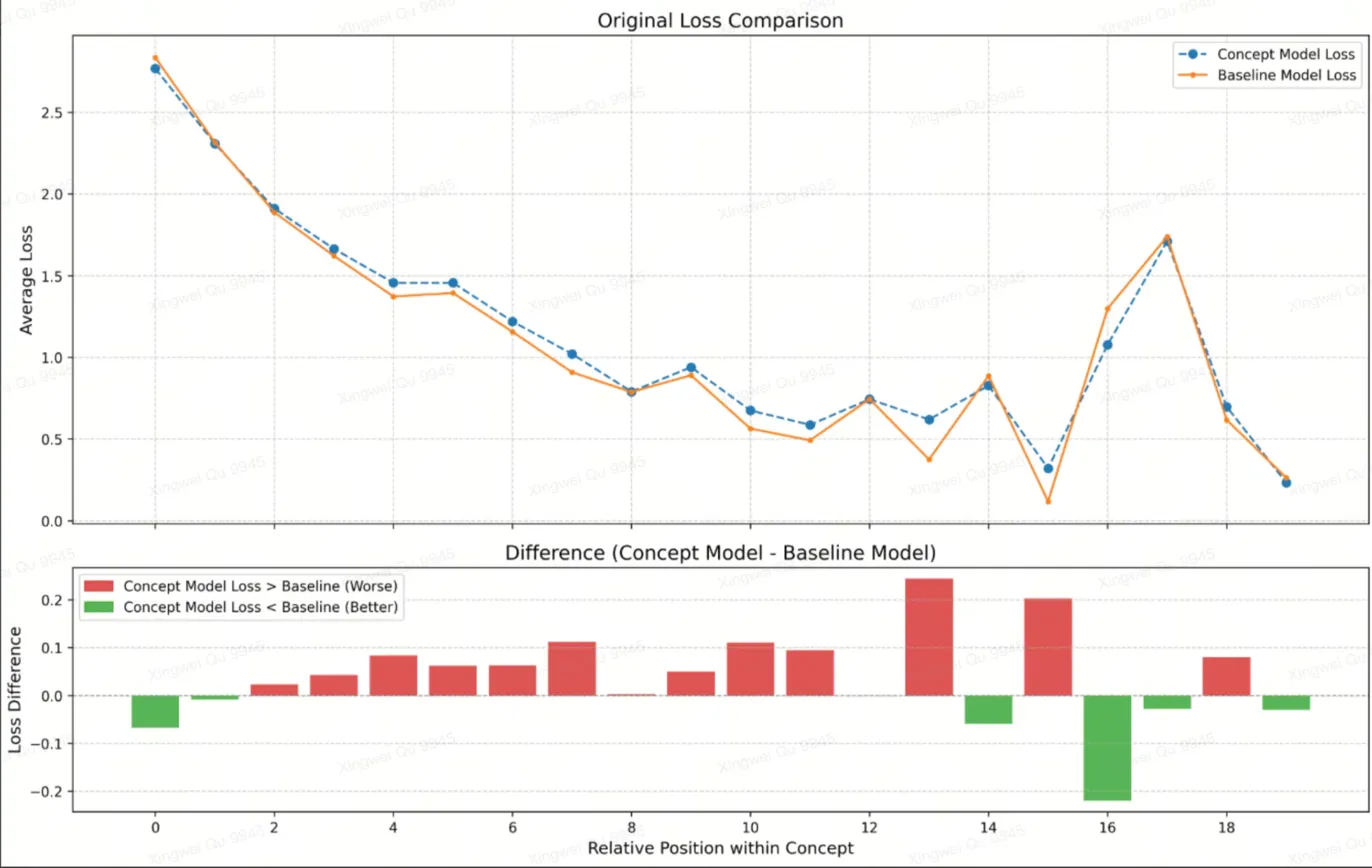
이 설계는 어떤 것을 생각해야 하는지(학습된 경계를 통한 개념 형성)와 어떻게 생각할 것인가(압축 잠재 공간에서의 추론)를 명시적으로 분리함으로써 모델은 의미 구조에 따라 표면 토큰 수보다 계산 자원을 적응적으로 할당할 수 있습니다. 우리의 결과는 이 구조적 편향이 새로운 개념을 나타내는 고정보성, 낮은 예측 가능성을 가진 토큰 처리에서 모델의 성능을 크게 향상시킨다는 것을 보여줍니다.
우리의 주요 기여는 다음과 같습니다:
개념 수준의 잠재적 추론과 학습 경계. DLCM은 잠재 표현에서 가변 길이 의미적 개념을 발견하고 압축된 개념 공간에서 깊게 계산하는 계층적인 다음 토큰 예측 아키텍처를 제안합니다.
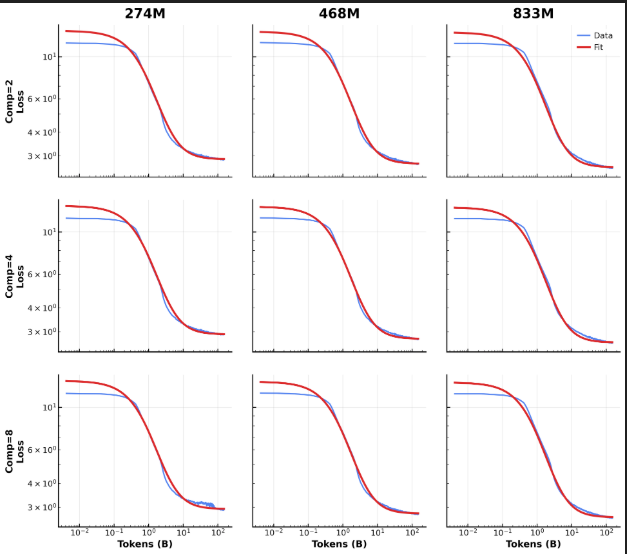
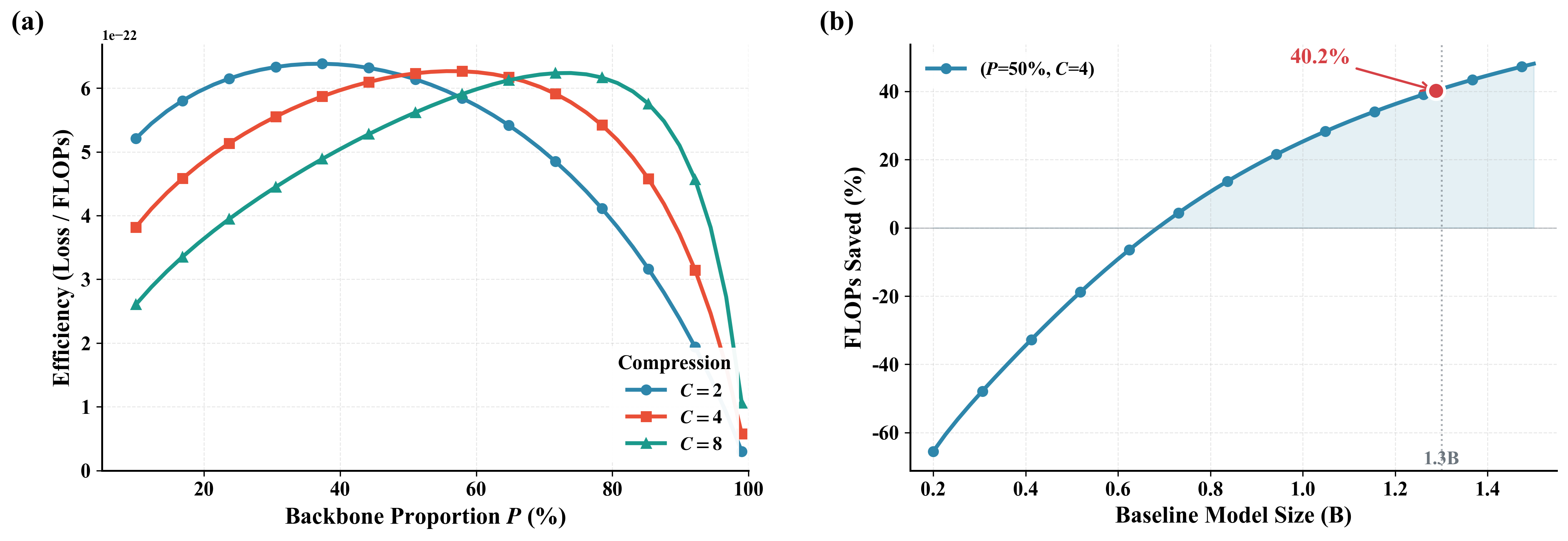
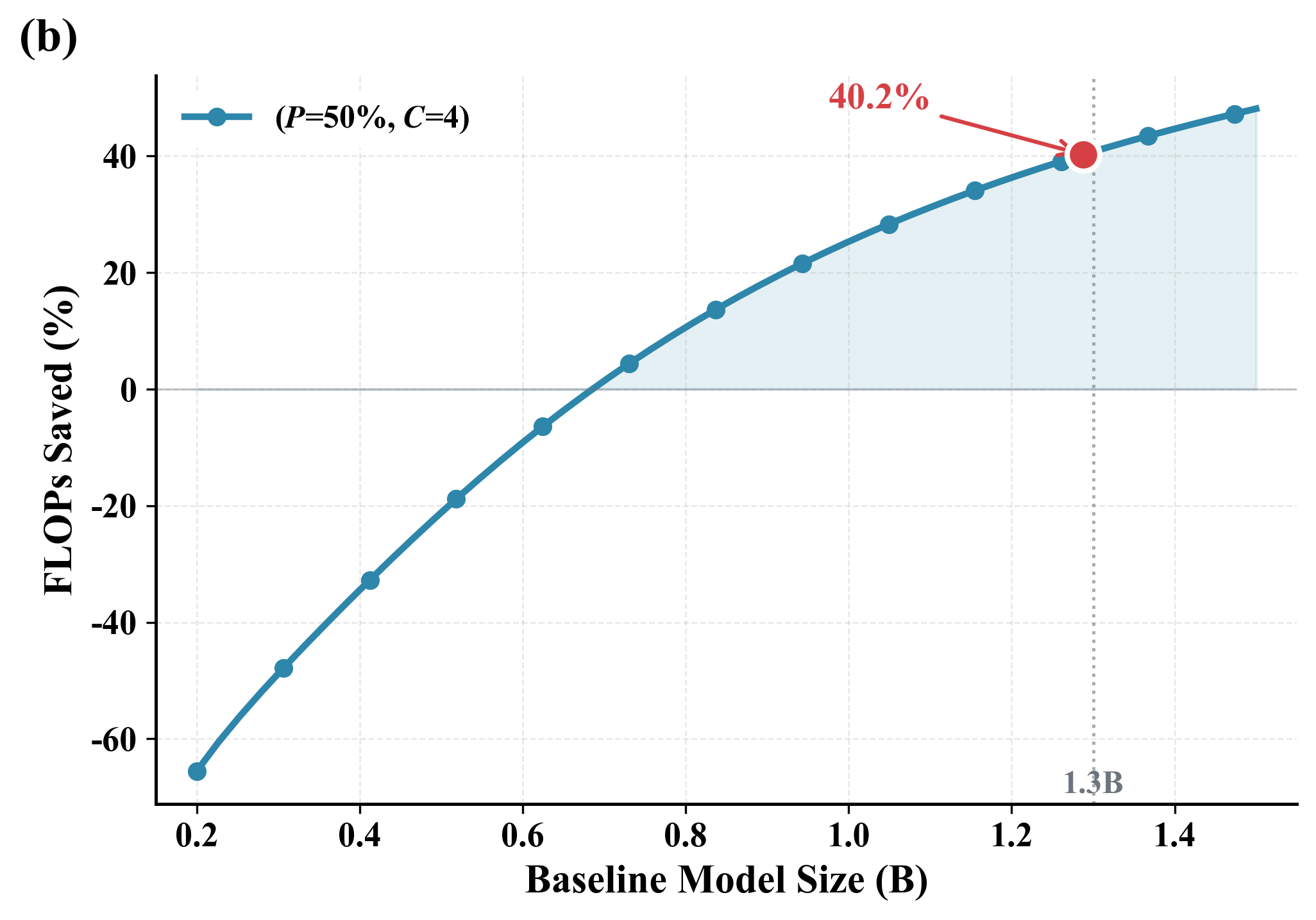
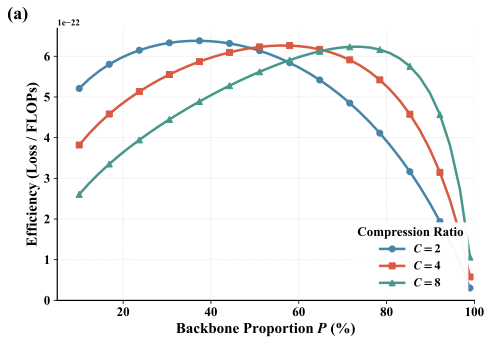
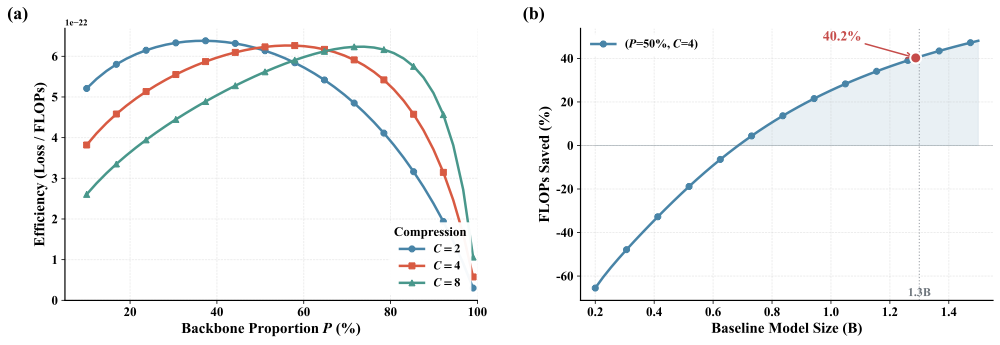
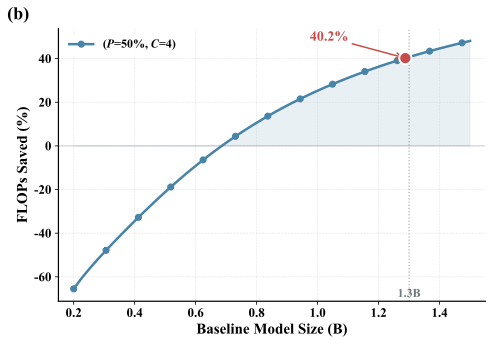
계층적 LMs의 압축 인식 스케일링 법칙. 총 파라미터, 데이터, 압축 비율 및 개념 백본 할당 간의 상호 작용을 명시적으로 모델화하는 스케일링 법칙 $`L(N,D,R,P)`$를 도출하여 동등한 FLOPs 제약 조건 하에서 원칙적인 아키텍처 선택이 가능하도록 합니다.
다양한 모듈을 위한 분리된 μP(why different LR / init variance). Maximal Update Parametrization($`\mu`$P)이 우리에게 고유한 아키텍처에 효과적으로 적용될 수 있음을 보여줍니다. 특히, 우리의 모델의 서로 다른 너비로 인해 토큰 수준 구성 요소, 개념 백본 및 임베딩의 학습 속도를 독립적으로 조정해야 합니다.
계산 리소스 재분배는 FLOPs가 적을 때 추론 성능 향상. $`R=4`$에서 DLCM은 최대 34%의 FLOPs를 줄이며, 큰 추론 백본 용량으로 늘려 평균적으로 12개의 제로샷 벤치마크에서 2.69%의 정확도 향상을 얻습니다.
관련 연구
잠재적 추론에서 개념 수준 언어 모델링까지
최근 연구는 개별 토큰보다 더 높은 수준의 추상화에서 추론을 수행하는 방법을 탐구하여 계산 효율성과 새로운 모델링 능력을 제공합니다. 잠재적 추론 프레임워크는 명시적인 토큰 생성 없이 연속된 숨겨진 상태 공간 내에서 완전히 추론을 수행합니다. COCONUT 프레임워크에서는 모델의 숨겨진 상태가 하나의 추론 단계에서 다음 단계로 직접 전달됩니다. 이 접근법은 체인 오브 씽크트 프롬프팅과 같은 방법보다 계산적인 장점을 제공하며, 연속된 표현 공간을 통해 여러 가능한 추론 경로를 동시에 탐색할 수 있습니다.
잠재적 추론 원칙을 기반으로 하는 Large Concept Model(LCM) 프레임워크는 토큰 대신 문장 수준의 “개념"에서 추론합니다. LCM은 세 단계 파이프라인을 사용합니다: (1) 동결된 인코더가 문장을 의미 공간으로 매핑하고, (2) 트랜스포머는 확산 또는 양자화 기법을 통해 개념 공간에서 자동회귀 예측을 수행하며, (3) 동결된 디코더가 토큰 수준의 출력을 재구성합니다. 이 접근법은 연속 공간에서 작동하여 큰 효율성을 제공하는 동시에 각 개념이 해독 가능한 문장으로 남아 있습니다. LCM은 영어로만 훈련된 모델이 200여 개 언어를 생성할 수 있음을 보여줍니다. 그러나 LCM 프레임워크는 중요한 한계점을 가지고 있습니다. 첫째, 대규모 다국어 데이터에 대한 별도의 인코더 및 디코더 모델을 사전 훈련해야 하기 때문에 확장성 측면에서 병목 현상이 발생합니다. 둘째, 문장 수준의 세분화는 고정된 인간의 선입견입니다. 모델은 미리 정해진 문장 경계를 받아들여야 하며, 임무 최적화 세그먼트를 학습하는 것은 불가능합니다. 이러한 엄격성은 모델이 다른 도메인이나 작업에 대한 개념적 세분화를 조정할 수 없게 합니다. 우리의 DCLM 아키텍처는 end-to-end 훈련을 통해 동적인, 학습 가능한 경계 감지로 이 두 가지 제한점을 해결합니다.
언어 모델의 동적 계산 리소스 할당
표준 LLM은 모든 토큰에 일관된 계산력을 할당하며, 일부 토큰(예: 예측 가능성이 높은 기능 단어)은 최소한의 처리를 필요로 하며 다른 토큰(예: 개념 경계)에는 더 많은 노력이 요구된다는 사실을 무시합니다. 최근 연구는 적응적 할당 메커니즘을 탐구했습니다. Universal Transformer는 깊이에서 재귀성을 도입하여 동일한 변환 블록을 반복적으로 적용하고, 각 위치가 충분히 정제되었는지를 결정하는 학습된 중단 메커니즘이 있습니다. Mixture of Experts(MoE) 모델은 각 토큰이 서브넷의 일부로 경로를 구성하여 조건부 계산을 수행합니다.
H-NET은 적응적 할당을 통해 학습된 경계 감지를 직접적으로 다룹니다. H-NET은 로컬 패턴(예: 연속적인 숨겨진 상태 간의 유사성)을 분석하여 의미 경계를 예측하고, 시퀀스를 가변 길이 청크로 분할하며, 압축된 청크 표현에서 계층적으로 처리합니다. 핵심은 경계 감지가 미분 가능하고 end-to-end 학습되며, 작업에 적합한 청크 전략을 발생시킵니다. 이 접근법은 학습 지도 없이 언어 구조와 일치하는 학습된 경계를 생성하며, 압축(4-8× 감소)은 주의력 절약에 기여합니다. 이를 통해 새로운 개념이 시작되는 고정보성 경계에서 예측이 가장 어렵기 때문에 더 많은 계산력을 할당할 수 있습니다.
방법론
DLCM의 기술적 세부 사항을 설명하겠습니다. 전체 아키텍처는 Figure 1에 표시되어 있습니다.
개요
DLCM은 네 단계를 통해 토큰 시퀀스를 처리합니다. (1) 인코딩에서 미세한 토큰 표현을 추출하고, (2) 동적 분할에서는 의미 경계를 식별하고 토큰을 개념으로 그룹화하며, (3) 개념 수준 추론에서는 압축된 시퀀스에 대해 깊게 계산을 수행하고, 마지막으로 (4) 토큰 수준 디코딩에서 인과적 크로스 어텐션을 통해 추론된 개념에 주목하여 예측을 재구성합니다. 이를 다음과 같이 정식화할 수 있습니다:
여기서 $`\mathcal{E}`$는 인코더, $`\Phi`$는 분할-풀링 연산, $`\mathcal{M}`$은 개념 수준의 트랜스포머, $`\mathcal{D}`$는 디코더이며, $`\Psi`$는 Eq. [eq:cross_attn]에서 정의된 크로스 어텐션 확장을 나타냅니다.
인코딩
인코더 $`\mathcal{E}`$는 원시 토큰 $`\mathbf{x} = [x_1, \dots, x_L]`$를 처리하여 미세한 표현 $`\mathbf{H} = [\mathbf{h}_1, \dots, \mathbf{h}_L] \in \mathbb{R}^{L \times d_{\text{token}}}`$을 생성하는 표준 인과적 트랜스포머입니다. 이러한 표현은 로컬 맥락 정보를 포착하고 경계 감지 및 최종 토큰 수준 디코딩의 기초가 됩니다.
동적 분할
경계 점수는 잠재 표현에서 end-to-end 학습됩니다만, 우리는 언어 모델링 손실로부터 이산적인 분할 결정을 명시적으로 분리함으로써 최적화 간섭을 피합니다. 이를 통해 대규모에서 필수적인 훈련 안정성과 제어 가능한 압축을 얻는다.
경계 감지
우리의 핵심 가설은 서로 다른 개념 사이의 전환이 잠재 특징 공간에 커다란 변화를 나타낸다는 것입니다. 우리는 이러한 “개념 브레이크"를 인접 토큰 간의 로컬 비슷성을 측정함으로써 감지합니다.
인코더 출력 $`\mathbf{H}`$가 주어졌을 때, 각 토큰은 차원 $`d_{\text{scan}}`$의 질의-키 공간에 투영됩니다: