- Title: AutoFed Manual-Free Federated Traffic Prediction via Personalized Prompt
- ArXiv ID: 2512.24625
- 발행일: 2025-12-31
- 저자: Zijian Zhao, Yitong Shang, Sen Li
📝 초록
정확한 교통 예측은 라이드해링, 도시 도로 계획, 차량 페리 관리 등 지능형 교통 시스템에 필수적입니다. 하지만 교통 데이터 주변의 중요한 프라이버시 문제로 인해 대부분의 기존 방법은 로컬 트레이닝에 의존하여 데이터 실로와 제한적인 지식 공유가 발생합니다. 연방 학습(FL)은 개인정보 보호 협업 훈련을 통해 효율적인 해결책을 제공하지만, 표준 FL은 클라이언트 간의 독립적이지 않고 동일하게 분포되지 않은(non-IID) 문제에 어려움을 겪습니다. 이挑战组合中包含了韩文和中文,最后的部分没有完全翻译成韩文。以下是完整的韩文翻译:
정확한 교통 예측은 라이드해링, 도시 도로 계획, 차량 페리 관리 등 지능형 교통 시스템에 필수적입니다. 하지만 교통 데이터 주변의 중요한 프라이버시 문제로 인해 대부분의 기존 방법은 로컬 트레이닝에 의존하여 데이터 실로와 제한적인 지식 공유가 발생합니다. 연방 학습(FL)은 개인정보 보호 협업 훈련을 통해 효율적인 해결책을 제공하지만, 표준 FL은 클라이언트 간의 독립적이지 않고 동일하게 분포되지 않은(non-IID) 문제에 어려움을 겪습니다. 이 어려움은 개인화 연방 학습(PFL)이 유망한 패러다임으로 등장하는 원인이 되었습니다. 그럼에도 불구하고 현재의 PFL 프레임워크는 교통 예측 작업에 대한 전문적인 그래프 특징 공학, 데이터 처리 및 네트워크 아키텍처 설계가 필요합니다. 많은 이전 연구들의 주목할 만한 제한점 중 하나는 실세계 시나리오에서 자주 사용 불가능한 데이터셋 간의 하이퍼파라미터 최적화에 의존하는 것입니다. 이를 해결하기 위해 AutoFed라는 새로운 PFL 프레임워크를 제안합니다. 이는 개인화된 예측자에게 교차 클라이언트 지식을 활용하면서도 로컬 특이성을 유지하도록 하여 자동 조정을 통해 인공적인 하이퍼파라미터 튜닝의 필요성을 제거합니다. 프롬프트 학습에서 영감을 받아, AutoFed는 클라이언트 맞춤형 어댑터를 사용하여 로컬 데이터를 축소된 글로벌 공유 프롬프트 행렬에 응축하는 연방 표현자를 도입하였습니다. 이 프롬프트는 개인화 예측자에게 조건을 제공합니다. 실제 데이터셋에서의 광범위한 실험은 AutoFed가 다양한 시나리오에서 일관되게 우수한 성능을 달성한다는 것을 보여주었습니다. 본 논문의 코드는 https://github.com/RS2002/AutoFed
에서 제공됩니다.
💡 논문 해설
1. **개인화 연방 학습 프레임워크 AutoFed 개발:** 기존의 TP 모델들은 데이터셋에 따라 다양한 설정을 필요로 하는 반면, AutoFed는 자동 조정을 통해 이러한 문제를 해결합니다. 이를 텍스트 분석에 비유하자면, AutoFed는 고정된 질문이 아닌 상황에 맞게 변하는 '스마트 질문'과 같아서 데이터의 특성에 따라 모델을 적응시킵니다.
2. **지역적 데이터 분포에 따른 개인화 예측:** AutoFed의 PP 구성 요소는 지역적인 데이터 패턴을 학습하고 이를 반영하여 개인화된 예측을 수행합니다. 이는 각 지구마다 다른 교통 규칙이 있는 도시에서, 자동차가 해당 지역의 특성에 맞게 주행 경로를 조정하는 것과 유사합니다.
3. **전역 공통 지식 활용:** FR 구성 요소는 클라이언트 간의 데이터 분포 차이를 고려하면서도 전역적인 패턴을 학습하고 이를 개인화된 예측에 적용합니다. 이는 여러 도시에서 수집된 교통 데이터를 하나의 통합된 기준으로 활용하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 서론
교통 예측(TP)은 현대 지능형 교통 시스템(ITS)의 핵심 요소로, 실시간 호출 배차, 동적 가격 책정, 도시 인프라 계획 및 혼잡 관리와 같은 중요한 응용 분야를 가능하게 합니다. 그러나 강력한 TP 모델을 개발하는 데는 근본적인 도전이 있습니다: 교통 데이터가 풍부하지만 동시에 민감하고 분산되어 있기 때문입니다. 엄격한 개인정보 보호 규제와 상업적 이익으로 인해 이러한 데이터는 종종 다양한 지방 정부 기관(예: 각 관할 구역에 있는 기관)이나 개인 회사(Uber, Lyft 등)가 유지하는 고립된 시스로로 분리됩니다. 결과적으로 중앙 집중식 학습은 일반적으로 불가능하며 대부분의 실제 솔루션은 제한적인 데이터를 사용하여 로컬 학습에 의존해야 합니다. 이러한 시스로 방식은 일반화 능력이 떨어지고 교차 이전 가능한 패턴을 포착하는 데 실패해 효과적인 교통 예측이 어렵게 만듭니다.
연방 학습(FL)은 원시 데이터 공유 없이 모델을 공동으로 학습할 수 있는 유망한 패러다임으로 자리잡고 있습니다. 그러나 FedAvg와 같은 전통적인 FL 알고리즘은 클라이언트 데이터가 독립적이고 동일하게 분포되어 있다고 가정하는데, 교통 예측의 맥락에서 이는 거의 충족되지 않습니다. 실제로 교통 패턴은 도시 구조, 인구 밀도 및 경제 활동에 의해 주요한 차이를 보이는 비동일 분포(non-IID)를 나타냅니다. 이러한 비동일 분포 데이터에서 단일 글로벌 모델을 학습하면 클라이언트 드리프트(client drift)와 참여자 모두에게 부적절한 성능이 발생할 수 있습니다. 개인화 연방 학습(PFL)은 이 도전을 해결하기 위해 각 클라이언트가 맞춤형 모델을 학습하면서 동시에 연맹 내에서 얻은 집단 지식을 활용하도록 합니다. 따라서 PFL은 실제적인, 개인정보를 보호하는 교통 예측을 달성하는 데 특히 유망한 프레임워크입니다.
그러나 기존의 PFL 프레임워크는 TP의 고유한 도전과 직접적으로 부합하지 않습니다. 표준 시간 시리즈 예측 작업에 비해 TP는 복잡한 공간-시간 의존성, 비정상적인 변화, 그리고 다양한 외부 특징 등 큰 도전을 안고 있습니다. 이러한 요구사항은 표준 PFL 프레임워크를 TP 작업의 특정 요구 사항에 맞게 적응시키기 위한 필요성을 낳습니다. 전통적인 방법들은 종종 도메인별 요구사항을 통합하는 데 실패합니다. 불행히도 이러한 적응 과정은 복잡한 수작업, 예를 들어 정교한 그래프 구성이나 하이퍼파라미터 튜닝에 의존할 때가 많습니다. 예를 들어, 필터 방법과 패턴의 양은 파라미터 조정에 따라 성능 변동이 5% 이상 일어날 수 있습니다. 그러나 최적 설정은 데이터셋 간에 크게 달라질 수 있고, 단일 구성은 큰 성능 변동을 초래할 수 있습니다. 이러한 설정 과정은 종종 데이터셋과 클라이언트 구성에 대한 사전 지식이나 전문가의 통찰력에 의존하기 때문에 실제 적용에서는 획득이 어려울 수 있습니다.
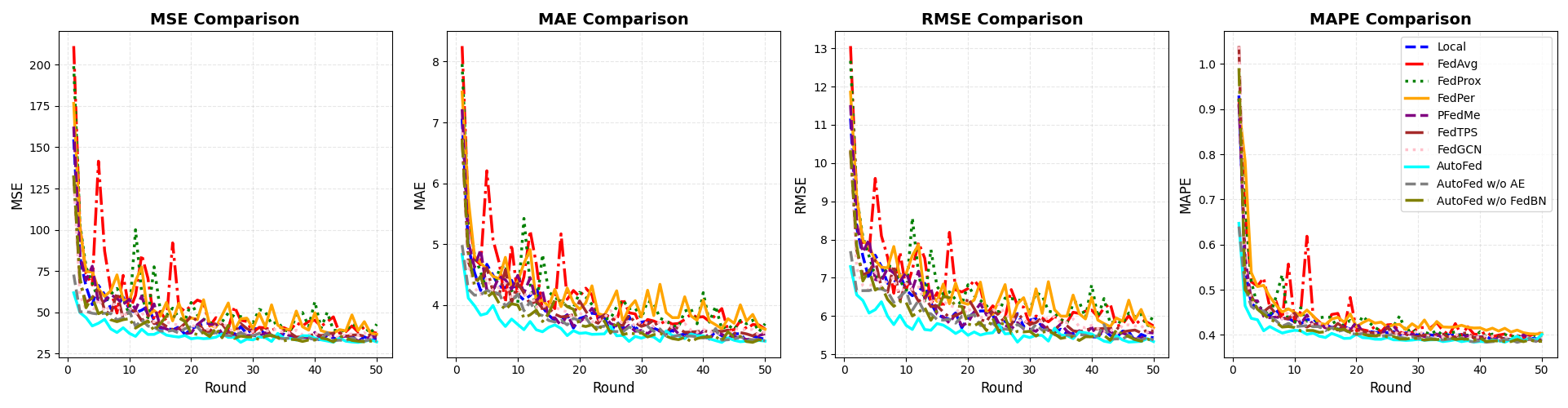
이러한 도전에 대응하기 위해, 우리는 새로운 TP를 위한 PFL 프레임워크인 AutoFed를 제안합니다. 이는 수작업 적응 노력의 필요성을 없앤다고 합니다. AutoFed에는 개인화 예측기(PP)와 연방 표현자(FR)라는 두 가지 핵심 구성 요소가 포함되어 있습니다. PP는 적응적인 그래프 컨볼루셔널 순환 신경망(AGCRN)을 활용하여 인접 행렬을 자동으로 학습합니다. 따라서 클라이언트별로 수작업 설계를 필요로 하지 않습니다. 기존 FL 접근 방식과 달리 모델 파라미터 집약에 의존하지 않고, FR은 프롬프트 학습에서 영감을 받았습니다. 구체적으로는 먼저 오토인코더(AE)와 AGCRN 인코더를 통해 로컬 입력 데이터를 압축하여 정제된 로컬 특징을 캡처합니다. 그런 다음 FedBN의 원칙에 따라 FR은 다층 퍼셉트론(MLP)의 공유 선형 레이어를 활용하여 이러한 로컬 특징을 클라이언트 전체에서 통합된 글로벌 표현으로 맞춥니다. 각 클라이언트 별로 독립적인 배치 정규화 레이어를 유지함으로써 개인화된 통계적 특성을 보존합니다. 이는 비동일 분포 데이터에 적응하면서 PP에게 개인화된 프롬프트를 생성하는 것을 가능하게 합니다. 이러한 설계 덕분에 AutoFed는 자동 조정을 필요로 하지 않고 틀림없이 프레임워크의 견고성과 일반화 능력을 강화합니다. 이 접근법은 다양한 실제 TP 데이터셋에서 기존 방법보다 우수한 성능을 보여줍니다.
관련 연구
교통 예측
ITS의 핵심 구성 요소로서, TP는 여행 수요 예측, 교통 유동성 예측 및 여행 시간 예측과 같은 다양한 작업을 포괄합니다. 초기 연구에서는 각 교통 노드를 독립적인 엔터티로 다루며 TP를 일반적인 시간 시리즈 예측 작업으로 정의했습니다. 많은 방법이 통계적 방법, 클러스터 기반 패턴 매칭 및 신경망과 같은 전통적인 단일 차원 시간 시리즈 접근법을 기반으로 개발되었습니다. 그러나 이러한 접근 방식은 교통 노드 간의 공간적 관계를 무시하는 경향이 있습니다. 예를 들어, 한 지역에서 교통 체증이 발생하면 인근 지역에서도 교통 유동성이 증가할 가능성이 높습니다. 이후 대부분의 접근 방법들은 각 시간 프레임 내에서 먼저 공간 특징을 추출한 후 시리즈 네트워크로 예측하는 패러다임을 채택했습니다. 예를 들어, CNN-LSTM 네트워크를 교통 유동성 예측에 사용하였습니다. 그러나 CNN 기반의 공간적 추출은 교통 네트워크의 비유클리디안 성질을 충분히 표현하지 못하여 강력한 공간 특징 학습에 어려움이 있습니다. 최근에는 그래프 신경망(GNNs)이 효과적으로 노드 간 관계를 포착하는 유망한 해결책으로 등장했습니다. 예를 들어, AGCRN은 GCN-LSTM 구조를 사용하고 적응적 인접 행렬을 활용하여 공간적 의존성을 캡처하며 엔드 투 엔드 학습이 가능합니다. 또한 STWave는 교통 데이터를 정상성과 비정상성 구성 요소로 분리하는 새로운 해체 접근 방식을 도입하였습니다.
그러나 이러한 진전에도 불구하고 대부분의 방법은 중앙 집중형 학습에 의존하며, 교통 데이터 내에서 개인정보 보호 고려 사항이 점점 더 인정되고 있는 GDPR 및 CCPA와 같은 개인정보 보호 규정을 간과합니다. 최근에는 일부 연구가 프라이버시 문제를 해결하기 위해 연방 학습 기반 패러다임에 초점을 맞추기 시작했습니다. 예를 들어, Shang et al은 FedAvg를 기반으로 수평적 및 수직적 방법을 제안하였으며, 교통 노드 간의 관계를 효과적으로 포착하기 위해 신중하게 설계된 교통 그래프를 사용하였습니다. 또한 Hu et al은 새로운 MendGCN 모듈을 통해 그래프 노드와 외부 요인 사이의 관계를 고려하는 FedGCN을 도입하였습니다. 개인화 연방 학습 방법 분야에서는 Zhou et al이 클라이언트 간 지식 공유에 교통 패턴 저장소를 활용한 FedTPS를 개발하였습니다.
연방 학습
최근 몇 년 동안 FL은 고수준의 프라이버시와 리소스 제약 상황에서 널리 적용되었습니다. 의료 인식, 교통 예측 및 자율 주행과 같은 분야에서 그렇습니다. 그러나 FedAvg와 같은 표준 FL 방법들은 클라이언트 간 데이터가 독립적이고 동일하게 분포되어 있다고 가정하는데, 실제에서는 항상 가능한 것은 아닙니다. 비동일 분포(non-IID) 데이터에 대한 해결책은 데이터 기반, 프레임워크 기반 및 모델 기반 방법으로 구분될 수 있습니다. 그 중 개인화 연방 학습(PFL)은 모델 기반 접근 방식으로 유망한 성능을 보여줍니다. PFL에서 클라이언트는 공통 지식을 활용하기 위해 모델의 일부만 공유하지만, 지역적 데이터 분포에 적응하기 위해 개인화된 파라미터나 구조를 유지합니다.
FedPer부터 시작하여 각 클라이언트가 강력한 특징 추출을 위한 상류 레이어를 공유하며 마지막 출력을 위한 맞춤형 하류 레이어를 보관하는 것이 전달 학습 이론에서 잘 알려진 패러다임입니다. 그 이후로 클러스터링, 메타 학습 및 하이퍼 네트워크와 같은 혁신적인 기술을 도입한 다양한 방법들이 나왔습니다. 특히 PFL은 서로 다른 모델 구조를 가진 클라이언트가 공통 서브네트워크의 집약화를 가능하게 함으로써 유연성을 크게 발휘합니다. 이는 클라이언트가 서로 다른 계산 리소스를 보유하고 있는 경우에 특히 유리합니다.
프롬프트 학습
최근 대형 언어 모델(LLMs)의 성공은 마스크된 언어 모델(MLM) 사전 훈련, 검색 강화 생성(RAG), LLMs 자체 등 시간 시리즈 분석에 다양한 관련 기술을 효과적으로 적용하고 확장하는데 이끌었습니다. 이러한 기술들 중 프롬프트 학습은 효율성과 구현의 용이성을 인정받고 있습니다. LLMs의 맥락에서 프롬프트는 후속 디코딩에 직접적인 영향을 미치는 중요한 역할을 합니다.
시간 시리즈 분석 분야에서는 대부분의 연구가 프롬프트를 설계하여 특정 작업에 맞게 사전 훈련된 LLMs 또는 그 아키텍처를 적응시키는데 집중하고 있습니다. 예를 들어, 학습 가능한 원형을 디코딩 과정에서 가이드 프롬프트로 사용합니다. 그러나 원형의 수는 모델 성능에 크게 영향을 미치며 최적 수량은 데이터셋마다 다릅니다.
방법론
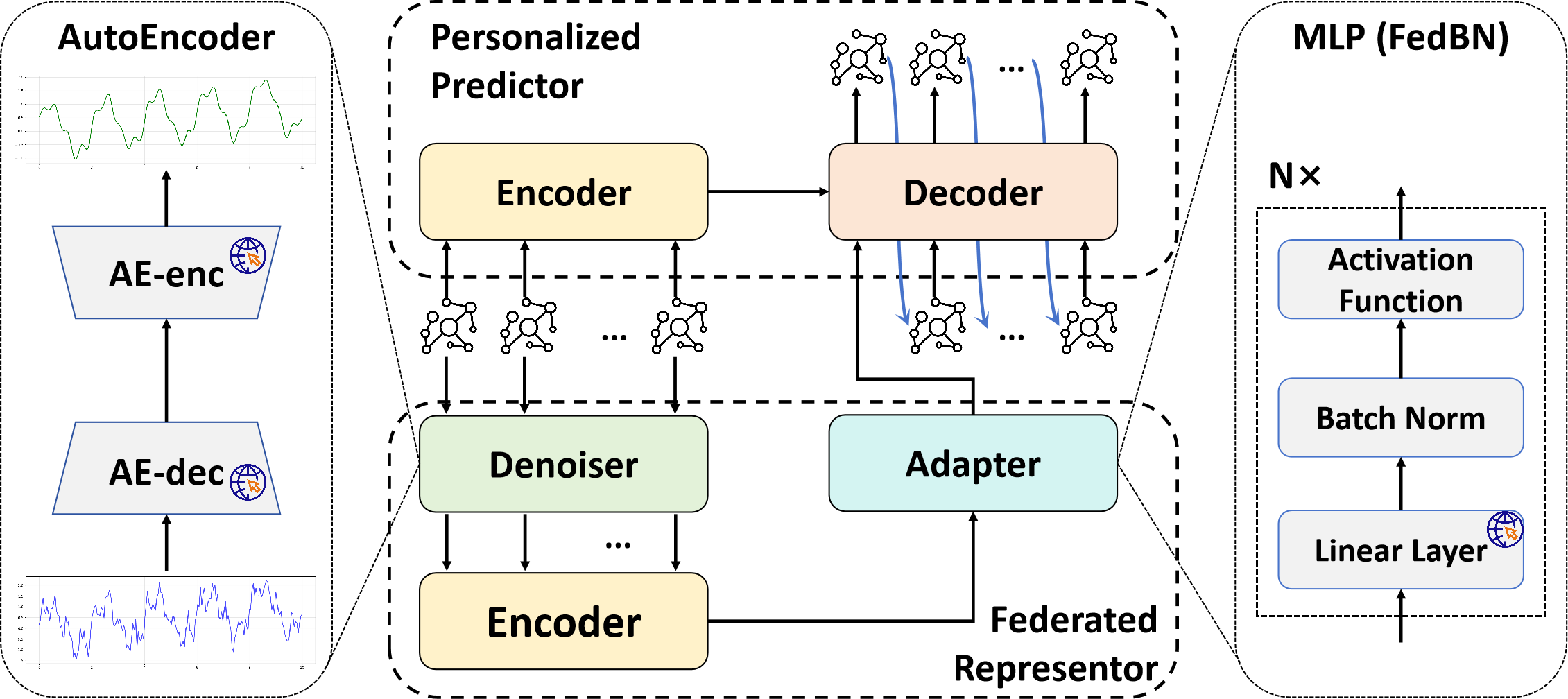
네트워크 구조: 네트워크는 PP와 FR으로 구성됩니다. PP는 인코더-디코더 구조를 사용하는 그래프 시간 시리즈 네트워크입니다. FR은 강력한 특징 추출을 위한 AE 기반 디노이저, 특징 압축을 위한 그래프 시간 시리즈 인코더 및 로컬 표현을 글로벌 표현으로 전환하기 위한 클라이언트 맞춤형 어댑터를 사용하여 디코더에 안내 프롬프트 행렬을 제공합니다. 그림에서 "earth" 아이콘을 가진 모듈만 클라이언트 간에 공유됩니다.
문제 설정
이 논문에서는 비동일 분포 데이터를 가진 m개의 클라이언트 C = {C1, C2, …, Cm}과 중앙 서버 S가 포함된 연방 TP 작업을 연구합니다. 각 지역 i에 대해 교통 네트워크는 G_i = (V_i, E_i)로 표현되며 여기서 V_i와 E_i는 노드 및 에지를 나타냅니다. 또한 A_i ∈ R^{|V_i|, |V_i|}는 가중 인접 행렬로 교통 노드 간의 관계(예: 공간적, 유사성, 의존성)를 나타내며, |⋅|은 집합 크기를 나타냅니다.
각 클라이언트 i는 사적인 데이터셋 D_i = {X_i, Y_i}를 보유하며 여기서 X_i ∈ R^{N_i, T, |V_i|, H}는 과거 교통 특징을 나타내며, Y_i ∈ R^{N_i, 𝒯, |V_i|}은 미래 수요의 정답입니다. 특히 N_i는 클라이언트 i의 샘플 크기를 나타냅니다. T와 𝒯은 과거 정보 시퀀스 길이와 예측할 미래 시간 범위를 각각 나타내며, H는 특징 차원입니다.
특히 개인화 연방 학습(PFL) 시나리오에서는 각 클라이언트 i의 라운드 m에서 네트워크가 f(⋅; θ_i^m, Θ^m)로 표현되며 여기서 θ_i^m은 클라이언트 i의 네트워크 파라미터의 개인 부분을 나타내며 자신의 데이터 분포에 대한 맞춤형 측면을 학습하고, Θ^m는 공유된 네트워크 파라미터의 부분을 나타냅니다. 모든 클라이언트를 위한 글로벌 일반 표현을 학습합니다. 따라서 PFL의 목표는 다음과 같이 정의됩니다:
네트워크 구조는 그림 1에서 보여주며 두 가지 주요 구성 요소로 구성됩니다. 개인화 예측기(PP)와 연방 표현자(FR). PP는 인코더-디코더 기반 그래프 시간 시리즈 네트워크를 사용하며 로컬 학습을 통해 지역 데이터 분포에 적응하도록 훈련됩니다. 추론 중, 인코더는 과거 데이터 x ∈ R^T, n, H를 입력으로 받으며 디코더는 미래 교통 데이터 ŷ ∈ R^{𝒯, n}을 자동 회귀(AR) 방식으로 예측합니다. 클라이언트 i의 경우 입력 x는 그들의 데이터셋 X_i에서 파생되며 n은 노드 수(|V_i|)를 나타냅니다.
FR은 입력 x에 기반하여 프롬프트 행렬 p_g ∈ R^{n,h}을 생성하며 여기서 h는 은닉 차원입니다. 이는 디코더의 접두사 토큰으로 사용됩니다. 이를 통해 각 클라이언트가 유사한 교통 패턴을 공유할 수 있다는 직관에 기반하여 입력 x에서 관련 패턴 정보를 전달하고 디코딩 과정을 안내합니다.
개인화 예측기
우리의 프레임워크는 궁극적으로 그래프 시간 시리즈 모델에 의존하지만, AGCRN과 같이 적응형 그래프 구조를 사용하는 방법을 권장합니다. 이 권장 사항은 실험에서 역시 활용되었습니다.