- Title: DynaFix Iterative Automated Program Repair Driven by Execution-Level Dynamic Information
- ArXiv ID: 2512.24635
- 발행일: 2025-12-31
- 저자: Zhili Huang, Ling Xu, Chao Liu, Weifeng Sun, Xu Zhang, Yan Lei, Meng Yan, Hongyu Zhang
📝 초록
소프트웨어 시스템은 현대 사회의 거의 모든 중요한 분야에서 핵심적인 역할을 합니다. 이들 시스템이 복잡해질수록 버그가 늘어나게 되며, 이를 해결하기 위한 프로그램 수정 기술이 필요하게 됩니다. 최근에는 LLM(Large Language Model) 기반의 자동 패치 생성 방법이 연구되고 있으나, 이러한 접근법들은 정적 코드 정보에 크게 의존하여 동적인 실행 정보를 충분히 활용하지 못합니다. 본 논문에서는 DynaFix라는 새로운 방법론을 제시하며, 이는 비침습적인 바이트코드 악기화 기술인 ByteTrace를 이용해 프로그램의 실행 중 발생하는 동적 정보를 수집하고 이를 반복적인 수정 과정에 활용합니다.
💡 논문 해설
1. **실행 수준의 동적 정보 활용**: DynaFix는 소프트웨어 버그 수정을 위해 프로그램의 실제 동작 상태를 기록하여 사용하는 방법론입니다. 이를 통해, 정적인 코드만으로는 파악하기 어려운 문제들에 대해서도 효과적으로 대응할 수 있습니다.
2. **반복적 수정 전략**: DynaFix는 각 단계에서 실패한 패치를 바탕으로 새로운 정보를 수집하고 이를 이용해 다음 반복 과정을 진행합니다. 이로써, 개발자가 실제 문제 해결 과정과 유사하게 접근할 수 있습니다.
3. **ByteTrace 도구**: ByteTrace는 프로그램의 실행 중 발생하는 다양한 동적 정보(변수 상태, 제어 흐름 등)를 수집하기 위한 비침습적인 악기화 기술입니다.
비교적 쉬운 설명:
DynaFix는 소프트웨어 버그 수정에 있어 개발자가 직접 해야 하는 부분을 자동화하는 방법론입니다. 이 방법은 프로그램이 실제로 어떻게 동작하느냐를 파악해 문제 해결의 힌트를 얻습니다.
중급 설명:
DynaFix는 LLM(Large Language Model)을 이용하여 버그 수정 작업을 반복적으로 진행합니다. 이를 위해 ByteTrace라는 도구로 프로그램 실행 중 발생하는 동적 정보를 수집하고, 이 정보를 바탕으로 패치를 생성 및 검증합니다.
전문가 수준 설명:
DynaFix는 소프트웨어 버그 수정을 위한 LLM 기반의 자동 패치 생성 방법론입니다. ByteTrace라는 도구를 통해 프로그램 실행 중 발생하는 동적 정보를 수집하고, 이를 반복적인 수정 과정에 활용하여 정확한 패치 생성을 가능하게 합니다.
📄 논문 발췌 (ArXiv Source)
# 도입
소프트웨어 시스템은 제조, 항공우주, 에너지, 의료 등 현대 사회의 거의 모든 중요한 분야를 지원하고 있습니다. 이러한 시스템이 규모와 복잡성을 높일수록, 많은 버그가 발생하게 됩니다. 프로그램 수정은 소프트웨어 생명 주기 동안 안정성과 보안을 유지하는 데 필수적입니다. 이전 연구에 따르면 개발자들은 버그를 수동으로 고치는 데 전체 시간의 35%에서 50%를 소비합니다. 이러한 비용을 줄이기 위해, 자동 패치 생성(APR) 기술에 대한 광범위한 연구가 이루어져 왔습니다. APR은 고장난 코드를 자동으로 수정하는 패치를 생성하려는 목표를 가지고 있습니다.
전통적인 APR 접근법은 주로 휴리스틱 기반, 제약 조건 기반 및 템플릿 기반 방법으로 나눌 수 있습니다. 휴리스틱 방법은 큰 패치 공간을 탐색하지만, 공간이 확장됨에 따라 효율성이 저하됩니다. 제약 조건 기반 방법은 형식적인 보장을 제공하지만 복잡한 프로그램에는 스케일링하기 어려우며, 템플릿 기반 방법은 가장 대표적이라고 여겨지지만 고급 템플릿을 구성하는 데 비용이 많이 들고 일반적 활용성이 제약됩니다. 이러한 한계를 극복하기 위해 딥러닝 기반의 APR 방법론이 등장했으며, 이는 패치 생성을 신경망 번역(NMT) 작업으로 정형화합니다. 그러나 그 효과는 훈련 데이터의 품질에 크게 의존하며, 이전에 본 적 없는 버그 유형에서는 성능이 현저히 떨어집니다.
대규모 언어 모델(LLM)의 급속한 발전은 APR에 새로운 기회를 열었습니다. 최근 접근법들은 LLM을 가이드하는 피드백 반복 패러다임을 채택하고 있습니다. 여기서는 동적 실행 정보 활용, 런타임 추적 또는 행동 신호를 이용해 오류 위치 확인 및 패치 생성을 개선하는 연구가 이루어지고 있습니다. 이러한 방법들은 벤치마크에서 최고 성능(SOTA)을 달성하지만 여전히 두 가지 주요한 문제를 안고 있습니다:
정적 정보에 과도하게 의존하고 동적 정보 활용 부족. LLM은 코드 생성 및 수정에 강력한 능력을 갖추고 있지만, 정적인 코드 아티팩트(예: 예외 메시지, 테스트 결과 또는 코드 주석)에 크게 의존하여 실제 실패를 일으키는 실행을 완전히 이해하는 데 한계가 있습니다. 최근 연구에서는 동적 정보(즉, 실행 추적)가 LLM이 복잡한 소프트웨어 버그에 대한 패치 생성을 지원하도록 도울 수 있음을 보여주고 있습니다. 그러나 현재 작업에서 동적 정보 활용은 제한적이며 대부분의 방법은 학습 또는 미세 조정 단계만 제한하거나 수정 프롬프트에 단 한번만 주입합니다.
실행 수준 통찰력이 부족한 반복적인 수정 피드백. SOTA LLM 기반 APR 접근법들은 테스트 결과나 버그 보고서로부터의 피드백을 통해 모델을 반복적으로 재프롬프트하는 이터러티브 수정 전략을 사용합니다. 그러나 이러한 피드백은 일반적으로 코스 그레인으로, 통과/실패 결과 또는 예외 유형 등 제한적인 수준에 머뭅니다. 실제 디버깅에서는 변수 상태, 제어 흐름 경로 및 호출 스택을 포함하여 런타임 행동의 세밀한 검사를 통해 가설을 정교하게 다듬고 오류를 점진적으로 분리하는 것이 필요합니다.
이러한 한계점을 해결하기 위해 우리는 실행 수준 동적 정보 피드백을 반복적인 수정 워크플로에 통합하는 LLM 기반 APR 방법론인 DynaFix를 제안합니다. 핵심 통찰력은 변수 상태, 제어 흐름 경로 및 호출 스택을 포함한 실행 추적이 프로그램 오류 이해와 근본 원인 파악에 필요한 행동 증거를 제공한다는 것입니다. 이를 수집하기 위해 우리는 ByteTrace라는 비침습적인 도구를 개발했습니다.
수정의 각 반복에서 DynaFix는 버그 있는 프로그램을 실행하고, ByteTrace를 통해 실행 추적을 기록하며, 캡처된 동적 정보로 수정 프롬프트를 확장합니다. LLM은 후보 패치를 생성하고, 해당 패치가 검증에 실패하면 DynaFix는 프로그램을 다시 실행하고 업데이트된 실행 추적을 수집하여 다음 반복을 위한 피드백을 제공합니다.
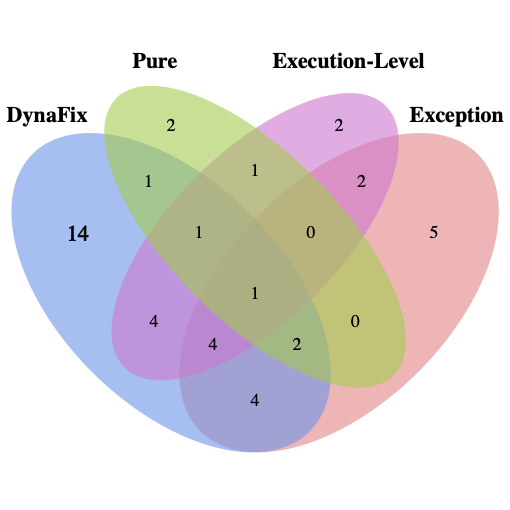
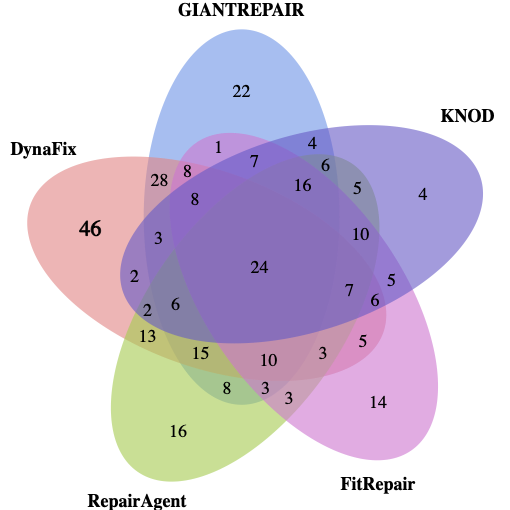
우리는 Defects4J 벤치마크에서 DynaFix의 종합적인 평가를 수행했습니다. Defects4J v2.0의 483개 단일 함수 버그 중 186개의 버그를 성공적으로 수정했으며, 이는 v1.2에서 100개와 v2.0에서 86개입니다. 또한 선택한 기준선들 중 어느 것도 해결하지 못했던 38개의 버그를 해결했습니다.
우리의 기여는 다음과 같습니다:
우리는 LLM을 이용해 실행 수준 동적 정보를 수정 과정에 통합하는 APR 프레임워크인 DynaFix를 제안합니다. 런타임 신호를 활용하여 코드 수정을 반복적으로 진행함으로써 실제 개발자가 프로그램을 디버깅하는 방식과 더욱 유사한 접근법입니다.
ByteTrace라는 가벼운 Java 악기화 도구를 개발하여 세밀한 실행 추적을 수집하고, 이를 기반으로 이터러티브 수정이 가능하도록 합니다.
Defects4J 벤치마크에서의 광범위한 실험은 DynaFix가 11개의 SOTA 방법론보다 우수하며, 이전 방법들이 해결하지 못했던 38개의 버그를 성공적으로 수정함을 보여줍니다. 재현성을 촉진하기 위해, 우리는 승인 후 DynaFix 프레임워크, ByteTrace 도구 및 모든 실험 데이터셋을 포함한 복제 패키지를 공개할 예정입니다.
동기
이 섹션에서는 현재 APR 접근법의 한계를 보여주는 실제 사례 두 가지를 제시하고 실행 수준 동적 정보를 수정 과정에 통합하는 필요성을 강조합니다. 코드 목록에서 “+”로 시작된 줄은 추가된 코드, “–”로 시작된 줄은 삭제된 코드를 나타냅니다.
+ if (this.allowDuplicateXValues) {
+ add(x, y);
+ return null;
+ }
XYDataItem overwritten = null;
int index = indexOf(x);
+ if (index >= 0) {
- if (index >= 0 && !this.allowDuplicateXValues) {
리스팅 [lst:chart5-patch]은 Defects4J의 Chart-5 취약성에 대한 개발자 패치를 보여줍니다. 여기서 this.allowDuplicateXValues 조건이 일반적인 조건 블록에서 제거되어 새로운 조건문으로 정제되었습니다. JUnit에서 보고된 실패는 배열 경계 위반을 나타내지만, 오류 위치를 찾기 위한 충분한 컨텍스트 정보가 부족합니다. LLM 기반 APR 방법론에서는 이러한 모호함이 가능한 패치 검색 공간을 확장시킵니다.
for (int i = getNumObjectiveFunctions(); i < getHeight(); i++) {
- if (MathUtils.equals(getEntry(i, col), 1.0, epsilon) && (row == null)) {
+ if (!MathUtils.equals(getEntry(i, col), 0.0, epsilon)) {
+ if (row == null) {
row = i;
- } else if (!MathUtils.equals(getEntry(i, col), 0.0, epsilon)) {
리스팅 [lst:math87-patch]은 Math-87 버그에 대한 개발자 패치를 보여줍니다. 이 함수는 행렬 열이 단위 벡터인지 확인하고 1.0 값을 포함하는 행 인덱스를 반환합니다. 정적 코드는 올바르지만, JUnit에서 발생한 예외는 junit.framework.AssertionFailedError: expected:<10.0> but was:<0.0>입니다. 이러한 메시지와 정적 코드만을 바탕으로 LLM 기반 APR 시스템은 종종 오류를 잘못 진단합니다.
/>
APR에서 사용되는 정보 유형의 비교: 정적 정보, 결과 수준 동적 정보 및 실행 수준 동적 정보.
위 사례들은 현재 LLM 기반 APR 기법들이 수정 과정에서 정보를 효과적으로 활용하는 데 직면한 주요 문제점을 보여줍니다. Fig. 1에 보여진 것처럼, 대부분의 현존하는 접근법은 버그 있는 소스 코드, 코드 주석 및 테스트 케이스와 같은 정적 정보에 크게 의존합니다. 일부는 동적인 신호를 활용하지만, 이들 대부분은 통과/실패 테스트 결과나 예외 정보와 같이 매우 제한된 수준의 피드백을 제공합니다.
또한, 기존 방법론들은 수정 과정 전체에서 실행 수준의 동적 정보를 지속적으로 통합하는 체계적인 피드백 메커니즘을 갖추지 못하고 있습니다. 정적 정보에 의존하는 접근법은 단일 단계로 패치 생성을 수행하고, 실패한 패치는 재정교정할 수 없습니다. 결과 수준의 신호를 사용하는 반복적인 접근법은 통과/실패 또는 예외 유형 등 고수준 피드백에 머무르며 더 깊은 실행 행동을 전달하지 못합니다.
방법
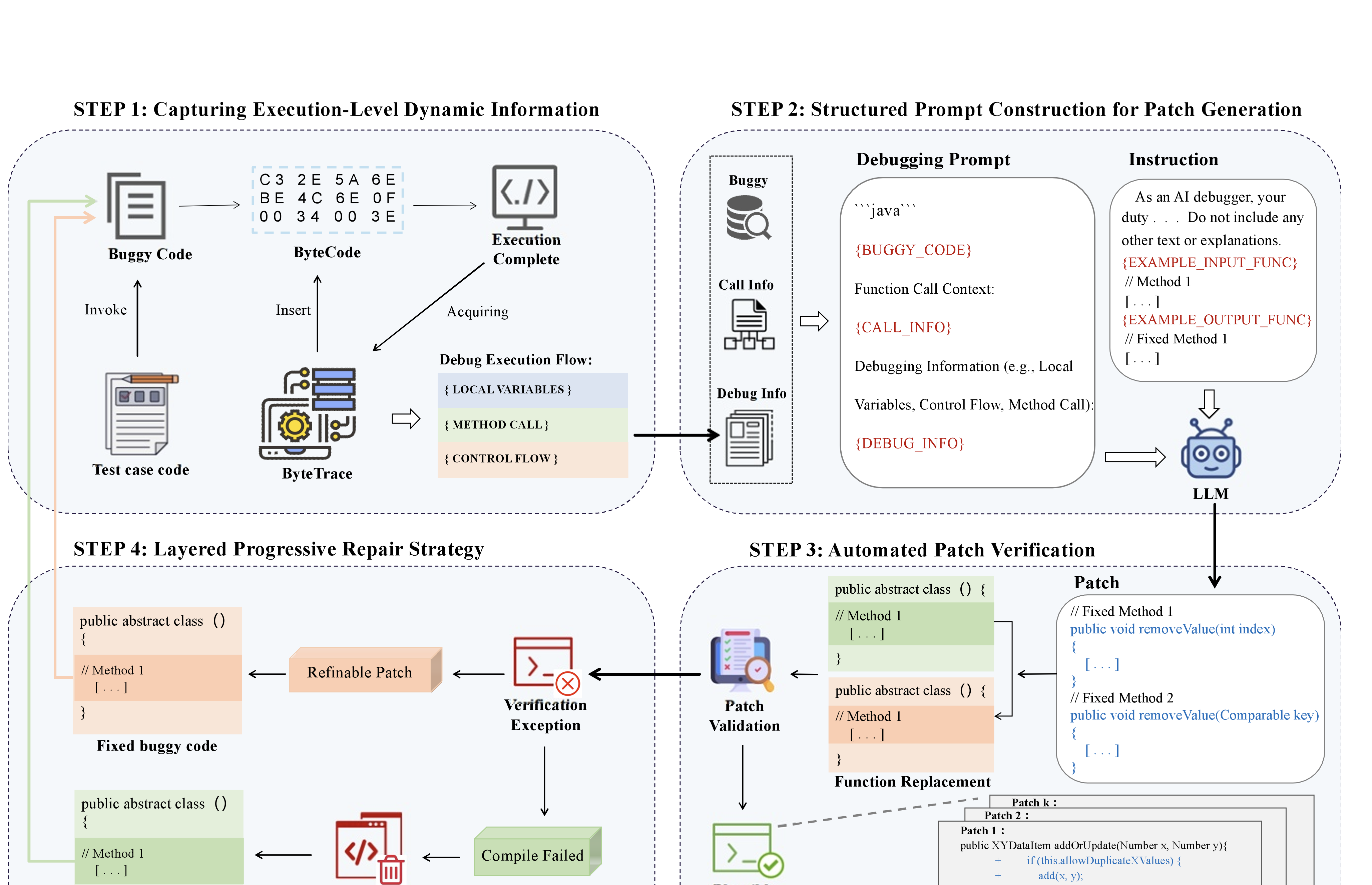
그림 2는 제안된 접근법의 프레임워크를 보여줍니다. 우리는 LLM 기반 APR 방법론인 DynaFix를 소개합니다. 이 접근법은 비침습적인 바이트코드 악기화를 활용해 JUnit의 코스 그레인 예외 보고에 대한 한계점을 해결합니다. 직접 소스 코드를 수정하는 대신, 프레임워크는 정상 작동을 방해하지 않는 상태에서 바이트코드를 악기화하여 프로그램 실행 중 동적 행동 정보를 캡처하고 이를 LLM에 피드백으로 제공합니다.
수정 과정은 다음과 같은 네 가지 주요 단계로 구성됩니다:
단계 1 (Section 3.1): 우리는 이 연구에서 개발한 ByteTrace 도구를 사용하여 버그 있는 프로그램을 비침습적으로 바이트코드 악기화합니다. 테스트 실행 중, ByteTrace는 변수 상태, 제어 흐름 경로 및 호출 스택을 포함하는 동적 런타임 정보를 캡처합니다.
단계 2 (Section 3.2): 수집된 디버깅 정보와 원래 버그 있는 소스 코드가 결합되어 디버깅 프롬프트가 생성되며, 이는 LLM에게 오류의 실행 컨텍스트를 제공합니다. 이러한 프롬프트는 LLM이 오류 동작을 더 잘 이해하고 후보 패치를 생성하도록 돕습니다.
단계 3 (Section 3.3): LLM에 의해 생성된 후보 패치가 소스 코드에 적용되고 테스트 케이스 실행을 통해 검증됩니다. 이 자동화된 검증은 패치 정확성을 자동으로 평가합니다.
단계 4 (Section 3.4): 우리는 LPR(Layered Progressive Repair) 전략을 적용하여 검증 결과에 따라 패치를 반복적으로 개선합니다. 패치가 검증에 실패하면 두 가지 경우로 구분됩니다:
(a) 컴파일 오류: 패치는 버려지고 원래 버그 있는 코드에서 수집된 디버깅 정보를 사용하여 수정 과정이 다시 시작됩니다.
(b) 테스트 실패: 만약 패치가 컴파일되지만 테스트 실행 중에 실패하면, 이는 추가 개선의 가능성이 있는 refinable patch로 취급됩니다. 현재 버그 있는 코드를 기반으로 업데이트된 디버깅 정보가 수집되어 다음 수정 반복을 안내합니다.
/>
DynaFix 개요.
실행 수준 동적 정보 캡처
DynaFix의 핵심 기능 중 하나는 반복적인 피드백으로 실행 수준 동적 정보를 활용하는 것입니다. ByteTrace를 통해 프로그램의 실제 동작 상태가 수집되고 이를 수정 과정에 활용합니다.