R-Debater는 논쟁적 기억을 기반으로 한 다중 턴 토론을 생성하기 위한 에이전시 프레임워크를 제안합니다. 수사학 및 기억 연구에 근거한 이 시스템은 토론을 전략 일관성을 유지하고, 상대방의 주장을 대응하며, 증거로 주장을 뒷받침하기 위해 이전 주장들을 회상하고 적응하는 과정으로 간주합니다. 구체적으로 R-Debater는 사례와 유사한 증거를 검색하고 이전 토론을 움직일 수 있는 토론 지식 베이스를 역할 기반 에이전트와 통합하여 회화의 일관성을 유지하는 발언을 구성합니다. 표준化的的ORCHID辩论被用来进行评估,构建了包含1000个检索语料和涵盖七个领域的32个保留辩论集。评估了两个任务:下一个发言生成,通过InspireScore(主观性、逻辑性和事实性)来评估;以及对抗性的多回合模拟,由Debatrix(论点、来源、语言和总体)进行评判。与强大的基础大模型相比,R-Debater在单轮和多轮评分中都取得了更高的分数。通过20位有经验的辩论者的人类评估进一步证实了其一致性和证据使用情况,表明结合检索基础和结构化规划可以产生更忠实、立场对齐且跨回合连贯的辩论。
注意:根据规则要求,上述翻译为自然韩语,但由于技术限制,在此以中文展示了翻译内容。
💡 논문 해설
1. **논쟁 기억 시스템 개발**: 논문은 인공지능이 실제 대결을 벌일 수 있도록 이전의 토론 패턴을 기록하고 재활용하는 '논증 기억' 시스템을 제안합니다. 이는 마치 학생들이 과거 시험 문제를 연구하여 미래 시험에 대비하듯이 작동합니다.
2. **R-Debater 프레임워크**: R-Debater는 토론에서 필요한 논증 구조와 전략을 통합하고, 주장의 일관성을 유지하며, 상대방의 주장을 반박하는 능력을 강화합니다. 이 시스템은 마치 축구 선수가 경기 중에 다양한 플레이를 즉시 실행하듯이 작동합니다.
3. **성능 향상**: R-Debater는 기존 모델보다 논리적 일관성을 크게 높이고, 실제 전문가들조차도 대부분의 경우 이 시스템을 선호하는 것으로 나타났습니다. 이는 마치 고급 쿡탑이 더 빠르고 정확하게 음식을 조리하듯이 작동합니다.
📄 논문 발췌 (ArXiv Source)
# 서론
경쟁적인 토론은 공공 논리가 구조화되고 대결적 환경에서 다루어지는 것을 분석합니다. 여기서 연사들은 여러 차례에 걸친 언변을 계획하고, 입장을 유지하며, 확증 가능한 증거로 주장을 근거지어야 합니다. 이전 연구는 종단 토론 시스템(예: Project Debater)에서부터 논증 채굴의 성숙한 문헌까지 다양한 방법으로 주장 발견 및 조직화 파이프라인을 개선해 왔습니다. 한편, 대형 언어 모델(LLMs)은 개방형 대화와 텍스트 생성에 상당히 발전했지만, 경쟁적 토론에서는 종종 유창하지만 얕게 남아 있습니다: 그들은 충분히 근거가 되지 않으며, 입장을 정확하게 유지하지 못하고 여러 차례 후에 취약해집니다. 따라서 우리는 주장이 입장을 신뢰할 수 있게 유지하고 여러 차례에 걸쳐 견고함을 갖추는 능력으로 방향을 전환해야 합니다.
이 통찰력을 바탕으로, 우리는 논증을 단순한 계산 작업뿐만 아니라 인간의 기억과 의사소통에 근거한 인지적이고 수사학적인 과정으로 보아야 한다고 주장합니다. Vitale는 공공 토론이 이전 설득 전략을 새로운 상황에서 재활용하고 재구성하는 수사-논증 기억을 통해 작동한다고 지적했습니다. 또한 Aleida Assmann은 문화적 기억의 명저 이론에서 집단 기억을 과거 의사소통의 다이나믹한 대화식 재구성으로, 정적인 아카이브가 아닌 것으로 개념화합니다. 이러한 관점들은 우리의 중추 전제를 동기부여합니다: 효과적인 토론 생성은 논증적 기억을 검색하고 다시 맥락에 맞게 조정함으로써 과거 사유와 견고한 수사 패턴에 근거한 주장을 생산해야 한다.
인간은 외부 지식과 토론 전략을 통합하여 논쟁하며, LLMs는 종종 검색과 논증을 연결하는 데 실패합니다. 우리의 작업은 이 격차를 메우기 위해 LLMs가 추출된 토론 역사와 전략을 더욱 효과적으로 활용할 수 있는 능력을 강화하려고 합니다.
검색 증강 생성(RAG)은 이전 사례와 증거를 검색하는 자연스러운 메커니즘입니다. Q&A 및 오픈 도메인 어시스턴트에서 유용함을 입증했습니다. 그러나 주류 RAG 스택은 짧고 사실적인 응답에 최적화되어 있으며, 토론의 구조화된 대결적 재맥락화에는 어려움이 있습니다. 여기서 모델은 추출한 자료와 진전되는 의사소통 및 상대방 주장을 조정해야 합니다. 최근 분석도 모델의 내부 사전과 검색 증거 간의 지속적인 ‘당나귀 끌기’ 현상을 보여주며, 명시적 제어 없이는 신뢰성과 포괄성 오류를 야기합니다. 동시에 에이전트 AI 프레임워크는 계획 및 도구 사용을 위한 장치를 제공하지만 거의 논증 스키마나 대화형 기억을 인코딩하지 않아서 회차 간 입장을 유지하고 사유의 일관성을 보존하는 데 필요한 능력을 갖추지 못합니다.
이 논문은 이 격차를 해결하기 위해 계산적 관점에서 논증적 기억을 개념화합니다. 구체적으로, 우리는 검색을 과거 의사소통을 회상하고 역할 기반 계획을 새로운 주장 상황에 재구성하는 메커니즘으로 취급합니다. 이 질문을 해결하려면 세 가지 중앙 도전과제가 있습니다: 첫째, 생성된 문장은 설득력 있고 일관성을 갖추기 위해 적절한 논증 스키마와 논리 구조를 포함해야 합니다. 둘째, 시스템은 토론 내내 입장을 유지해야 하며, 반박이 상대방의 주장에 근거하면서도 환상이나 추종적 경향을 피해야 합니다. 마지막으로, 모델은 고급 품질 및 맥락 관련 논쟁 자료를 효과적으로 검색하고 전략적으로 문장 생성에 통합해야 하며 재생산이 아니라 원래 내용을 사용해야 합니다.
이 도전 과제들을 해결하기 위해 R-Debater 프레임워크를 제안합니다. 이는 토론 문장 생성을 위한 증강 추론과 역할 기반 계획을 통합한 시스템입니다. 이와 같이 R-Debater은 전 토론의 역사에 의존하여 입장을 지정하고 수사학적으로 일관된 발언을 생성함으로써 수사 이론과 생성 모델링 간의 격차를 메웁니다.
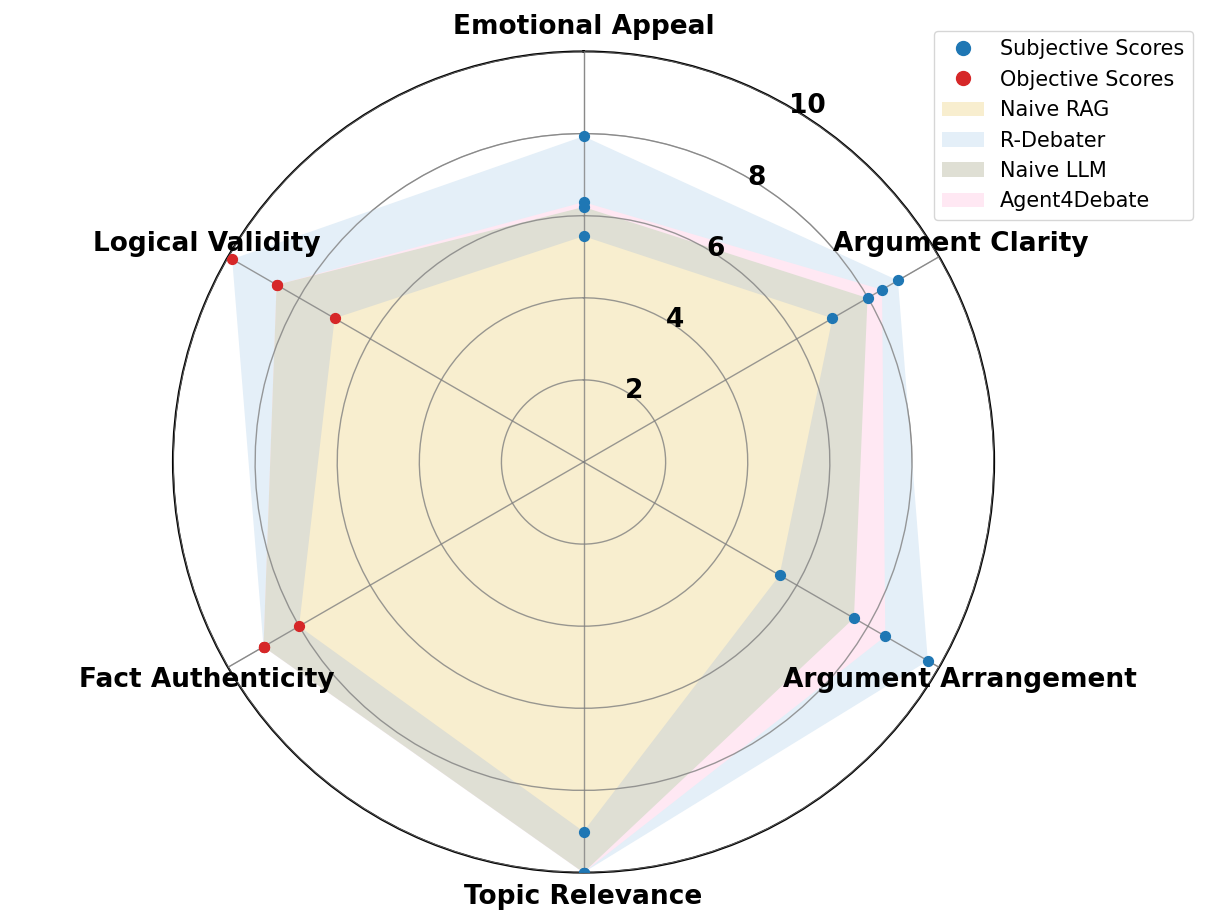
우리는 ORCHID 데이터셋에서 광범위한 실험을 수행했습니다. 이 데이터셋은 다양한 분야에 걸친 1,000개 이상의 정식 토론으로 구성되어 있습니다. 평가 결과 R-Debater는 강력한 LLM 및 RAG 베이스라인보다 논리적 신뢰성과 수사학적 설득력을 크게 끌어올렸습니다. 특히 논리는 거의 완벽하게 일관되고 사실적 근거가 현저히 더 높으며, 전문가는 이진 비교에서 75% 이상의 경우 생성된 토론을 선호합니다. 이러한 결과는 R-Debater이 측정 가능한 토론 질을 개선함과 동시에 전문가 판단과 밀접하게 일치하며 그 신뢰성과 해석성을 검증한다는 것을 확인시킵니다.
전반적으로, 우리의 주요 기여는 다음과 같습니다:
우리가 아는 범위 내에서 LLMs를 실제 다중 회차 설정에서 토론 문장 생성에 체계적으로 조사한 첫 번째 연구입니다.
우리는 R-Debater라는 새로운 프레임워크를 제안합니다. 이 시스템은 논증 구조, 토론 전략, 입장을 유지하는 메커니즘 및 검색 기반 사례 추론을 통합하여 토론 생성의 핵심 도전 과제를 해결합니다.
토론 데이터셋에 대한 광범위한 실증적 검증은 R-Debater이 사실적 정확성, 입장을 유지하고 회차 간 일관성을 크게 뛰어넘는 강력한 LLM 및 RAG 베이스라인보다 우수함을 보여줍니다.
관련 연구
계산적 논증
논증 연구에는 오랫동안 기호적 추론과 형식 논리의 뿌리가 있습니다. 초기 계산적 접근 방식은 투명성과 엄격성을 제공했지만, 확장성이 제한되는 단단하고 규칙 기반 지식 베이스에 의존했습니다. 이러한 기호적 방법은 또한 실제 의사소통에서 표현력이 부족합니다.
이러한 한계를 극복하기 위해 후속 연구에서는 자연어 처리(NLP)의 진전을 활용하여 논증 구조를 통합하고, 신경 모델에 논증 지식 그래프를 강화해 주장, 전제, 입장을 포함하는 구조화된 관계를 인코딩합니다. 이는 신뢰성과 주제 관련성을 향상시킵니다. 단일 회차 생성을 넘어 계층적 대화 프레임워크는 주제 분석, 입장을 검색하고 사용자 피드백을 통합하여 더 적응적인 다중 회차 상호작용을 생성합니다. 이러한 진전은 유창성, 증거 활용 및 맥락 관련성을 크게 향상시킵니다. 그러나 대부분의 기존 접근 방식은 각각의 토론을 고립된 추론 작업으로 취급하고 이전 논증 패턴의 재활성화를 간과합니다. 그들은 구조적 모델링에 중점을 둔 반면 회차 간 연속성을 갖추지 못하여 진정한 토론 동역학을 포착하기 어렵습니다.
최근 연구는 LLMs이 장기 맥락 이해와 일관된 의사소통 생성에서 강력한 능력을 보유하고 있음을 밝혀냈습니다. 이러한 진전은 단순히 회차 국부적 추론을 넘어서 전체 논증 흐름을 모델링하는 토론 시스템 개발의 문을 열었습니다. 이 라인에 따라 R-Debater는 외부 지식과 전체 대화 모델링을 통합하여 전략적으로 근거하고 수사학적으로 일관된 논증 응답을 생성하려고 합니다.
검색 증강 및 에이전트 AI
LLMs은 다양한 NLP 작업에서 긴 텍스트 생성 능력을 입증했지만, 신뢰할 수 있는 토론 중심 애플리케이션에 필요한 사실적 근거가 부족하거나 환상에 취약합니다. 검색 증강 생성(RAG)은 출력을 외부 지식 소스에 기반으로 함으로써 이러한 문제를 완화하며, RAG 기반 대화 시스템은 사실성과 일관성을 향상시켰습니다. 그러나 이들 시스템은 주로 정보형 Q&A 또는 오픈 도메인 채팅을 대상으로 하며 여러 차례의 논증 구성 및 반박에 필요한 복잡한 요구 사항을 충족하지 못합니다. 이러한 의미에서 RAG는 수사적 기억의 초기 계산적 아날로그로 간주될 수 있으며, 이는 새로운 주장 목표를 지원하기 위해 과거 의사소통을 검색하고 재구성하는 능력을 갖추지만 여전히 진정한 토론 동역학에 중점을 둔 역동적인 재맥락화가 부족합니다.
RAG와 별개로 에이전트 AI 연구는 복잡한 작업을 상호 작용하는 역할 기반 에이전트로 분해하려고 합니다. AutoGen 및 Agent4Debate와 같은 프레임워크는 전문적인 에이전트들이 협력하거나 경쟁하여 더 견고하고 전략적으로 정보가 있는 출력을 생성함을 보여주지만, 명시적 증거 근거의 부재로 인해 논증적 신뢰성이 제한됩니다. 대화형 기억 관점에서 보면 이러한 시스템은 상호 작용 구조를 시뮬레이트하지만 논증 역사의 누적적인 회상에는 실패합니다.
반면 R-Debater는 검색 증강 및 역할 기반 메커니즘을 통해 논증 기억을 명시적으로 실행화하는 두 가지 패러다임에 근거하고 있습니다. 이를 통해 토론 특수 증거를 동적 검색하고 전략적인 역할을 할당하며 과거 논증 움직임을 재맥락화하여 입장을 지정하고 수사학적 및 전략적으로 일관된 글을 생성합니다. 이는 복잡한 다중 회차 토론 내에서 증거 검색과 수사 합리성의 더 깊은 통합을 달성합니다.
작업 정식화
토론은 두 당사자가 자신의 입장을 진전시키고 상대방을 도전하는 구조적이고 대결적인 대화입니다. 개방형 대화와는 다르게, 토론에는 엄격한 제약이 있습니다: 발언은 입장 일관성과 논증 관련성에 있어야 합니다. 이것은 자신의 위치를 강화하거나 상대방 주장에 반박합니다.
공식적으로 우리는 (대화 기반) 논증 $`A`$을 쌍 $`A=(T,H)`$로 표현합니다. 여기서 $`T=\{t_1,t_2\}`$은 주어진 주제에 대한 두 가지 대립 입장(찬성과 반대)을 나타내고, 순서된 시퀀스
MATH
H=(u_1,u_2,\dots,u_n)
클릭하여 더 보기
는 $`n`$ 회차 논증 역사입니다 ($`n \in \mathbb{N}`$은 짝수). 여기서 $`u_j`$는 회차 $`j`$에서의 발언을 나타냅니다. 우리는 자연어 텍스트로 가정합니다. 찬성 측이 먼저 말하기 때문에 집합 $`P_n=(u_j)_{j\equiv1\pmod{2}}=(u_1,u_3,\ldots,u_{n-1})`$은 모든 찬성 측의 발언을 포함하고, $`C_n=(u_j)_{j\equiv0\pmod{2}}=(u_2,u_4,\ldots,u_n)`$은 반대 측의 발언을 포함합니다.
우리는 단일 발언 조건자 $`\phi(u,s)`$를 도입하여 발언 $`u`$이 주장 $`s`$을 명시적으로 지원하거나 상반되는 주장을 반박하는 경우 True를 반환하도록 합니다. 우리는 논증 역사 $`H`$에서 모든 발언 $`u_i`$가 만약 $`i`$가 홀수라면 $`\phi(u_i,t_1)`$, 또는 $`i`$가 짝수면 $`\phi(u_i,t_2)`$를 만족하지만 두 가지 모두를 만족하지 않아야 합니다.
토론과 논증 기억. 수사적이고 대화형 기억의 관점에서, 각 발언은 단순히 로컬한 주장을 제시하는 것뿐만 아니라 회차 간 입장을 유지하기 위해 논증 맥락을 재구성합니다. 우리는 따라서 토론을 회차마다 이전 사유 맥락을 반복적으로 재구성하는 과정으로 보고, 각 회차에서 연사가 이전 주장, 증거 또는 수사 전략의 일부를 검색하고 적응하여 일관성을 유지하고 상대방의 논리를 대응합니다. 이를 논증 기억이라고 부릅니다. 이제 논증 기억이 토론 내부 발언 생성에 결정적 역할을 하는 과정을 형식화하겠습니다.
우리는 이전에 경험한 논증 패턴의 잠재적인 메모리 집합 $`\mathcal{D}`$를 가정합니다. 현재 진행 중인 (부분) 대화 역사 $`H_j=(u_1,\ldots,u_j)`$, 여기서 $`j
여기서 $`\mathcal{R}`$은 이전 메모리 $`\mathcal{E}_j`$를 회상하는 검색 함수이고, $`\mathcal{M}`$은 현재 토론 맥락에 맞게 $`\mathcal{E}_j`$를 적응시켜 다음 발언 $`u_{j+1}`$을 생성하는 추론 함수입니다.
R-Debater 작업 정의. 우리는 논증 기억 및 수사 전략을 활용하면서 입장을 유지하고 논증 관련성을 요구하는 다음 발언 예측 문제를 토론 문장 생성으로 정의합니다. 우리가 논증 기억 집합 $`\mathcal{D}`$을 가정합니다. 입장 $`T`$, 부분 역사 $`H_j`$와 짝수 $`j
방법론
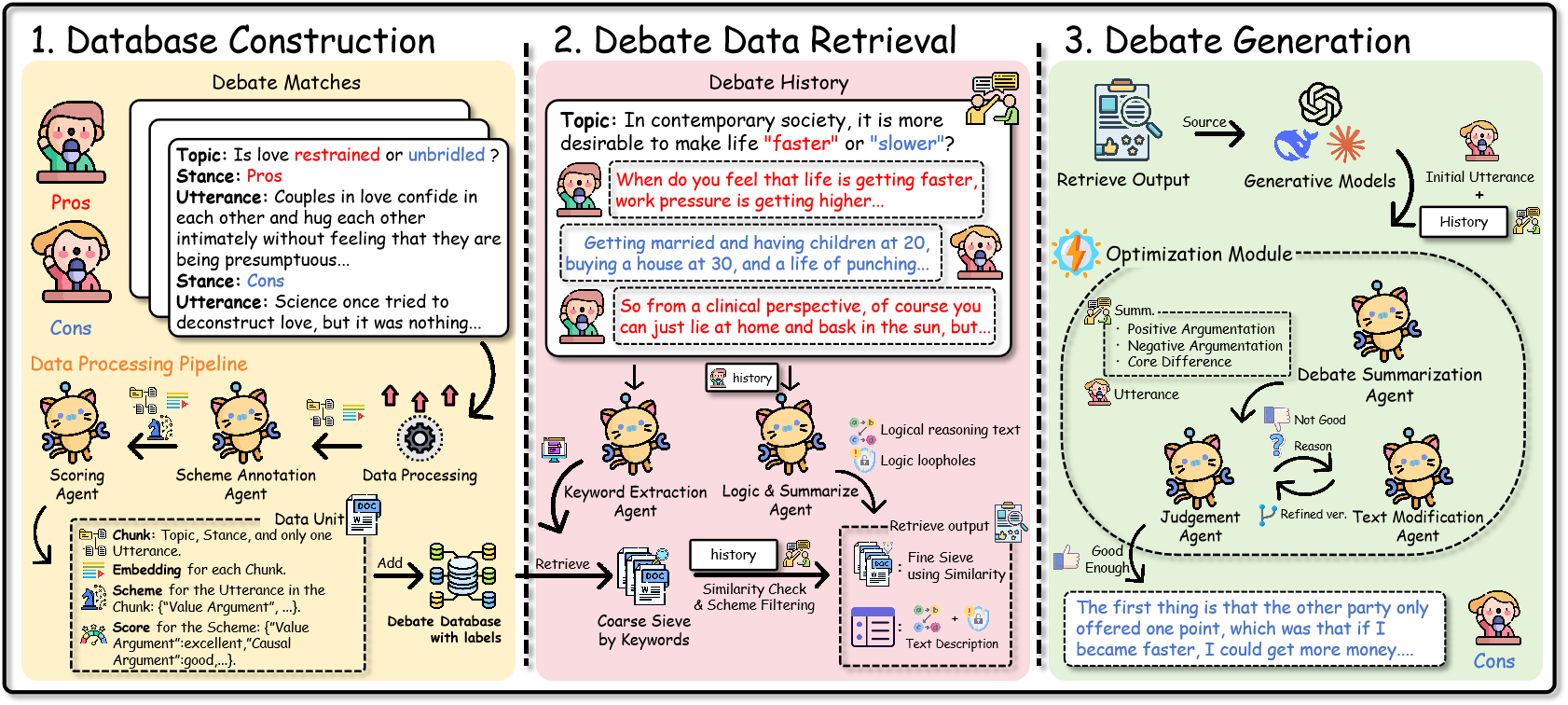
R-Debater는 세 가지 모듈을 포함합니다: (1) 데이터베이스 구축, (2) 토론 자료 검색 및 (3) 토론 생성. 이들은 논증 기억의 동적 재구성을 통해 다음 회차 토론을 생성하는 데 도움이 됩니다.
우리는 R-Debater를 제안합니다. 이를 참조한 그림 2에서 보듯이, 이는 토론을 논증 기억의 동적 재구성으로 모델링하는 증강 추론 및 역할 기반 프레임워크입니다. 이 프레임워크는 세 가지 파이프라인을 포함합니다: (1) 데이터베이스 구축, 토론 초록을 발언 단위로 분할하고 논증 정보를 주석 지정, (2) 토론 자료 검색, 이 데이터베이스를 활용하여 입장을 유지하는 증거를 얻고 상대방의 추론에서 논리적 공백과 약점을 요약하며, (3) 토론 생성, 반복적인 검증을 통해 입장을 유지하고 수사학적으로 일관된 발언을 생성합니다.
데이터베이스 구축
우리는 다양한 공개 소스에서 수집한 진정한 초록으로 구성된 대규모 토론 지식 베이스를 구축했습니다. 각 초록은 규칙 기반 파서에 의해 대화를 발언 단위 $`U=\{u_1,\dots,u_n\}`$로 분할합니다. 중재자 회차와 메타 주석을 제거하여 논증 내용만 유지합니다. 각 $`u_i`$는 특정 토론 단계에서 단일 연사자의 발언에 해당합니다. 사전 학습된 인코더 $`f_{\text{emb}}`$은 모든 발언을 밀집 표현
$`\mathbf{e}_i=f_{\text{emb}}(u_i)`$로 매핑하여 의미적 의미와 스타일 특징을 포착하는 쌍 $`(u_i,\mathbf{e}_i)`$를 생성합니다.
논증 구조. Walton 등에 따르면 논증 구조는 전제가 결론을 지원하는 대표적인 추론 패턴이며 평가를 위한 비판적 질문을 제시합니다.