- Title: Dream2Flow Bridging Video Generation and Open-World Manipulation with 3D Object Flow
- ArXiv ID: 2512.24766
- 발행일: 2025-12-31
- 저자: Karthik Dharmarajan, Wenlong Huang, Jiajun Wu, Li Fei-Fei, Ruohan Zhang
📝 초록
이 논문은 로봇의 개방 세계 조작에 대한 새로운 접근 방식을 제안한다. 이를 위해 비전 기반 모델로 합성된 동영상에서 3D 객체 흐름을 추출하고, 이 3D 객체 흐름을 바탕으로 로봇이 수행할 액션을 계획하는 방법을 설명한다.
💡 논문 해설
1. **3D 객체 흐름 인터페이스:**
- **간단하게:** 로봇은 동영상에서 합성된 3D 객체의 움직임을 따라가면서 새로운 작업을 배운다.
- **중급:** 비전 모델이 생성한 동영상을 통해 객체의 움직임을 추적하고, 이를 기반으로 로봇이 액션을 계획한다.
- **고급:** Dream2Flow는 텍스트 조건에 따른 동영상 합성에서 3D 객체 흐름을 추출하여 로봇에게 수행할 작업의 목표를 제공한다.
동작 추론:
간단하게: 로봇은 비전 모델이 예측한 객체 움직임에 따라 행동하도록 설계된다.
중급: 3D 객체 흐름을 바탕으로, 로봇은 태스크를 완료하기 위해 필요한 동작을 계획한다.
고급: 로봇의 상태와 객체의 위치가 주어지면, 로봇은 예측된 3D 객체 흐름에 따라 최적화된 동작을 계획한다.
실제 영역에서의 적용:
간단하게: Dream2Flow는 RGB-D 관찰과 언어 지시를 사용하여 다양한 작업을 수행할 수 있다.
중급: 로봇은 합성된 동영상에서 추출한 3D 객체 흐름에 따라 실제 환경에서 태스크를 완료한다.
고급: Dream2Flow는 시뮬레이션과 실 세계 도메인 모두에서 RGB-D 관찰과 언어 지시만으로 다양한 작업을 제로샷 방식으로 수행할 수 있다.
📄 논문 발췌 (ArXiv Source)
# 소개
로봇 조작은 환경 변화를 예측하는 시각적 세계 모델로부터 큰 혜택을 얻을 수 있다. 최근 생성 동영상 모델링의 발전으로, 주어진 초기 이미지와 오픈 엔드 작업 지시에 기반하여 몇 분간의 고해상도 클립을 합성할 수 있는 시스템이 개발되었다. 이러한 비디오 모델은 물리학과 객체 속성 및 상호 작용에 대한 풍부한 사전 지식을 암시적으로 포착하여, 부분적 관찰을 통해 새로운 작업을 완료해야 하는 오픈 월드 조작 환경에서 로봇에게 매력적인 선택지가 된다.
그러나 이러한 모델이 로봇 조작 시스템에 어떤 역할을 할 수 있는지는 아직 명확하지 않다. 가장 앞선 비디오 생성기는 인간의 몸짓과 관련된 최고의 상호 작용 클립을 만든다. 이는 인간의 상호 작용이 봇보다 훨씬 더 잘 문서화되어 있기 때문이며, 이것이 곧 로봇 조작에서 활용하는 데 장애물로 작용한다.
우리는 이러한 시각적 예측에서 행동 가능한 신호를 추출하고 이를 로봇이 실행하도록 한다. 이는 실제 세계의 상태 변화와 그것들을 실현하는 액튜에터 사이를 분리한다. 제안된 방법 Dream2Flow는 고수준 비디오 시뮬레이션과 저수준 로봇 행동을 연결하는 중간 인터페이스로 3D 객체 흐름을 사용한다. Dream2Flow는 현재 가장 선두의 비디오 생성 모델이 물리적으로 가능성이 있는 객체 움직임을 예측하며, 이 움직임은 오픈 월드 조작 작업에서의 임무 의도와 일치한다.
로봇의 역할은 주어진 작업을 완료하기 위해 인간 동작을 직접 모방하는 대신 생성된 비디오로부터 재구성하고 재생산되는 3D 객체 흐름에 가까이 접근하는 것이다. 이 접근법은 무엇이 일어나야 하는지(즉, 환경의 상태 변화)와 특정 몸체가 그에 따라 행동하는 방법(즉, 액션) 사이를 깔끔하게 분리한다. 중요한 것은 이를 트래젝터리 최적화 또는 강화 학습 정책과 자연스럽게 연결할 수 있다는 것이다.
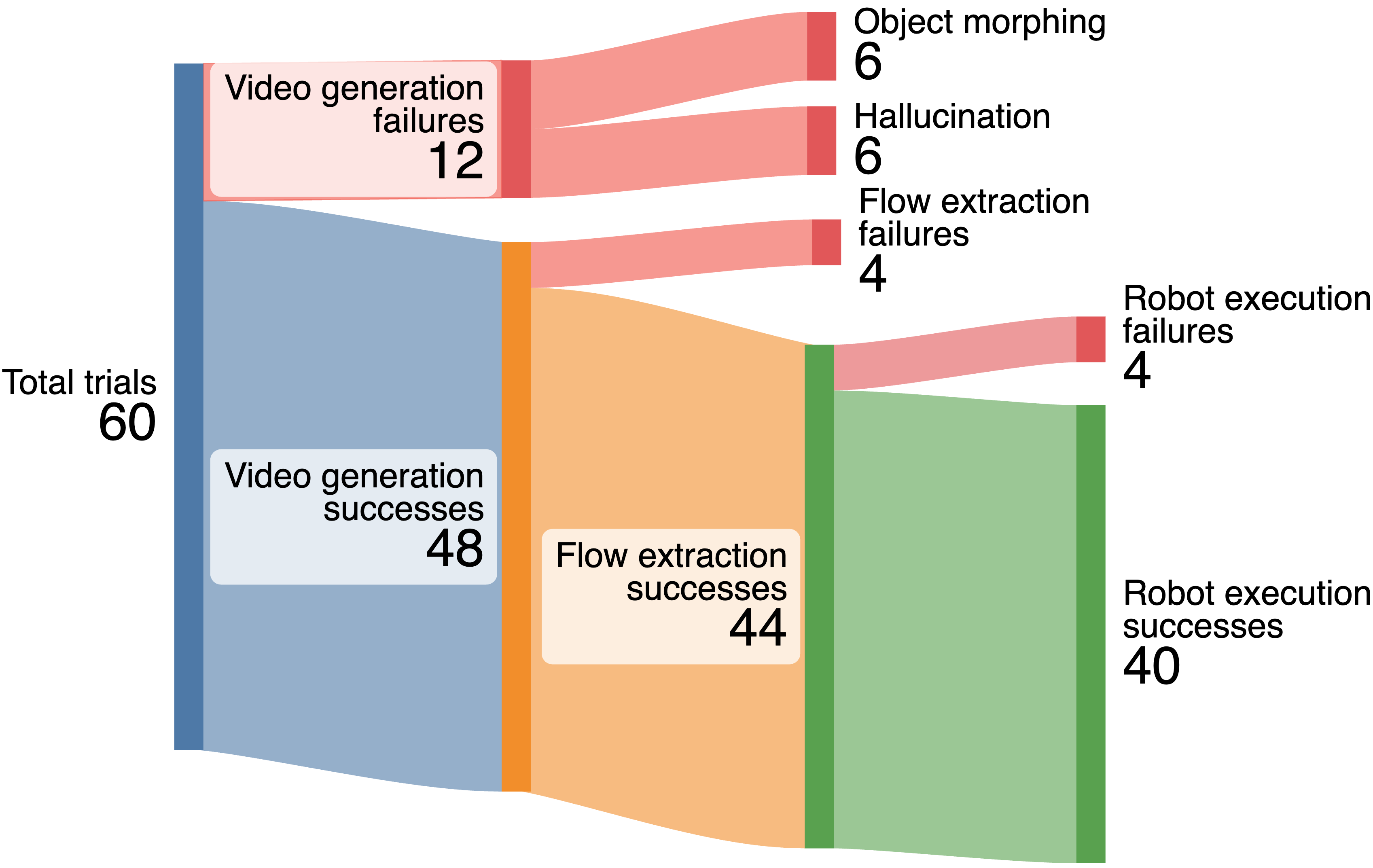
기존 모델과 도구를 활용하여 자동화된 파이프라인을 구현하는데, 이는 1) 텍스트 조건에 따른 가능한 상호 작용의 동영상 생성, 2) 심도 추정과 포인트 추적을 통해 3D 객체 흐름 획득, 그리고 3) 트래젝터리 최적화와 강화 학습을 활용한 로봇 액션 시뮬레이션이 포함된다. 이 설계는 조작 작업에 여러 가지 장점을 제공한다.
요약하자면, 우리의 주요 기여점은 다음과 같다:
우리는 비디오 생성 모델을 오픈 월드 조작에 적응시키기 위해 객체 트래젝터리 추적 문제로 3D 객체 흐름 인터페이스를 제안한다.
시뮬레이션 및 실제 도메인에서 이 접근법의 효과성을 구현함으로써, RGB-D 관찰과 언어 지시만을 사용하여 다양한 작업을 수행한다.
우리는 다른 중간 표현들과 비교하고 핵심 설계 선택사항 및 일반화 특성에 대해 연구를 통해 3D 객체 흐름의 속성을 검토한다.
관련 연구
조작 태스크 명세
조작 문제 범위 내에서 태스크를 명시하는 방법은 기호적, 학습 기반, 결과 중심, 및 객체 중심 인터페이스로 나눌 수 있다. 고전적인 접근 방식은 PDDL과 같은 기호 형식으로 목표와 제약을 인코딩하거나 비용 증강형 공식을 최적화한다. 학습 기반 시스템은 언어 및 지각을 통해 작업을 명시하고, 언어 조건에 따른 시각-모터 정책과 비전-언어-액션 모델을 사용하여 지시문을 동작으로 매핑한다.
2D/3D 흐름의 로봇 활용
밀집된 움직임 필드—광학적 유동, 포인트 추적, 및 3D 장면/객체 흐름은 조작에 대한 몸체 무관한 중간 인터페이스를 제공한다. 장면 중심 접근 방식에서는 정책이 2D 또는 3D에서 움직임을 매개변수화하거나 조건화하여 동작을 결정하고, 포인트/키포인트 인터페이스는 관찰과 행동을 통합하며, 액션-유동은 정확성을 높이는 데 기여한다. 객체 중심 접근 방식에서는 원하는 객체 움직임이 몸체에 독립적으로 지정되고 정책 추론, 계획, 및 최적화를 통해 동작으로 변환된다.
로봇을 위한 비디오 모델
최근 연구는 다양한 방법으로 비디오 모델을 로봇 작업에 통합하고 있다. 이들은 부가적인 훈련 목표, 보상 모델, 정책, 또는 환경 시뮬레이터로 사용될 수 있다. 특히 예측적 모델링에서 비디오 프레임 예측은 세계 모델의 한 형태로서 활용되며, 미래 시각 관찰을 시뮬레이션하여 이러한 모델들은 시각 계획 및 조작이 가능하게 한다.
방법
style="width:99.0%" />
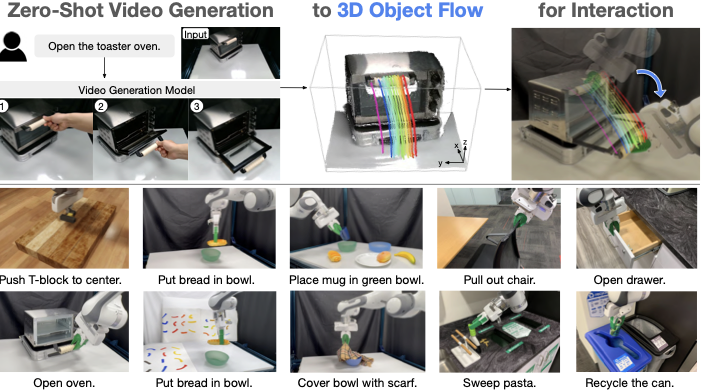
Dream2Flow 개요. 작업 지시와 초기 RGB-D 관찰을 주어진 상태에서 이미지-비디오 모델이 조건에 따라 비디오 프레임을 합성한다. 우리는 또한 비전 기반 모델로부터 객체 마스크, 비디오 심도, 및 포인트 추적을 획득하여 이를 통해 3D 객체 흐름을 재구성한다. 마지막으로, 로봇 정책은 트래젝터리 최적화 또는 강화 학습을 사용하여 3D 객체 흐름을 추적하는 실행 가능한 액션을 생성한다.
다음 섹션에서는 Dream2Flow의 문제 정식화를 소개하고, 비디오 생성에서 3D 객체 흐름을 추출하며, 조작을 위해 3D 객체 흐름으로 동작 계획을 수행하는 방법에 대해 설명한다.
문제 정식화
주어진 작업 지시 $`\ell`$, 초기 RGB-D 관찰 $`(I_0 \in \mathbb{R}^{H\!\times\!W\!\times\!3},\, D_0 \in \mathbb{R}^{H\!\times\!W})`$, 그리고 알려진 카메라 프로젝션 $`\Pi`$ (로봇 프레임까지의 내외부 파라미터)에 대해 우리의 목표는 생성된 비디오에서 추론된 객체 움직임을 따르는 액션 시퀀스를 출력하는 것이다. 우리는 특정 동작 매개변수화에 대한 가정을 하지 않는다: $`\mathcal{U}`$는 모션 프리미티브, 엔드-이펙터 자세, 또는 저수준 제어를 나타낼 수 있다.
3D 객체 흐름 추출: $(I_0,\ell)$로부터 이미지-비디오 모델은 프레임 $`\{V_t\}_{t=1}^T`$를 생성하고 비디오 심도 추정기는 각 프레임의 심도 시퀀스 $`\{Z_t\}_{t=1}^T`$을 제공한다. 작업 관련 객체의 이진 마스크 $`M`$과 투영 $`\Pi`$를 사용하여, $`Z_{1:T}`$로 마스킹된 이미지 포인트를 로봇 프레임에서 객체 중심 3D 트래젝터리 $`P_{1:T} \in \mathbb{R}^{T\times n\times 3}`$으로 추출한다. 이를 3D 객체 흐름이라 부른다.
3D 객체 흐름을 사용한 동작 추론: 상태는 작업 관련 객체와 로봇을 나타낸다: $`x_t = (x_t^{\text{obj}}, r_t)`$, 여기서 $`x_t^{\text{obj}} \in \mathbb{R}^{n\times 3}`$은 객체 포인트이고, $`r_t`$는 로봇 상태를 나타낸다. $`f`$가 동역학 모델이라 하면 $`\hat{x}_{t+1} = f(\hat{x}_t, u_t)`$이며 $`\hat{x}_0 = x_0`$. 각 계획 단계에서 시간 조정된 타겟 $`\tilde{P}_t \in \mathbb{R}^{n\times 3}`$을 비디오 객체 흐름으로부터 파생한다. 동작 추론은 최적화 문제로 정식화된다:
Section 3.3에서 $`\mathcal{U}`$와 $`f`$를 다른 도메인에 맞게 구현한다.
비디오로부터 3D 객체 흐름 추출
비디오 생성: 작업 언어 지시문 $`\ell`$과 로봇이 보이지 않는 작업 공간의 RGB 이미지 $`I_0\!\in\!\mathbb{R}^{H \times W \times 3}`$을 주어진 상태에서 Dream2Flow는 오프더셰프 이미지-비디오 생성 모델을 사용하여 작업 수행을 보여주는 RGB 비디오 $`\{V_t\}_{t=1}^T`$, $`V_t\!\in\!\mathbb{R}^{H \times W \times 3}`$를 생성한다. 초기 프레임에 로봇을 포함하거나 텍스트 프롬프트에서 언급하지 않는 것이 좋다.
비디오 심도 추정: 생성된 비디오로부터 Dream2Flow는 SpaceTrackerV2를 사용하여 각 프레임의 심도 $`\{\tilde{Z}_t\}_{t=1}^T`$, $`\tilde{Z}_t\!\in\!\mathbb{R}^{H \times W}`$을 추정한다. 단일 카메라 비디오의 스케일-변위 모호성을 해결하기 위해 첫 번째 프레임을 로봇에서 받은 초기 심도 $`D_0`$와 대응하여 전역 $(s^\star,b^\star)$를 계산하고, 보정된 심도 $`Z_t = s^\star\tilde{Z}_t + b^\star`$을 얻는다.
3D 객체 흐름 추출: 3D 객체 흐름은 작업 관련 객체에 대한 3D 트래젝터리 $`P_{1:T}\!\in\!\mathbb{R}^{T \times n \times 3}`$과 가시성 $`V\!\in\!\{0,1\}^{T\times n}`$를 생성한다. 먼저 Grounding DINO를 사용하여 $(I_0,\ell)$로부터 바운딩 박스를 생성하고 이를 통해 SAM 2에 이진 마스크를 요청한다. 시간 $`t=1`$의 마스킹 영역에서 $`n`$ 개의 픽셀을 샘플링하고 CoTracker3을 사용하여 비디오 전체에서 추적해 2D 트래젝터리 $`c_i^t`$와 가시성 $`v_i^t`$를 얻는다. 가시 포인트는 보정된 심도와 카메라 내외부 파라미터로 3D로 변환되어 $`P_{1:T}`$가 생성된다.
3D 객체 흐름을 사용한 동작 추론
Simulated Push-T 도메인: 비집게 조작 작업을 포함하는 태스크에서는, Dream2Flow는 평평한 테이블 위의 시작 밀 위치 $(c_x, c_y)$, 단위 밀 방향 $`(\Delta c_x, \Delta c_y)`$, 그리고 밀 거리 $`d`$로 매개변수화된 밀 기술 프리미티브를 사용한다. 이 설정에서는 전체 장면의 특성-증강된 입자 $`\Tilde{x}_t \in \mathbb{R}^{N \times 14}`$을 입력으로 받아 각 점의 다음 타임스텝 위치 변화 $\Delta \hat{x}_{t+1}$를 출력하는 앞으로의 동역학 모델을 학습한다.
3D 객체 흐름 추종 비용 최적화는 랜덤 샷팅을 사용하며, $`r`$ 개의 밀 기술 매개변수를 무작위로 샘플링하여 모든 밀이 관심 대상 객체와 다른 위치 및 방향에서 접촉하게 한다. 그런 다음 예측된 점 위치에 따라 비용이 가장 낮은 매개변수를 선택한다. 비디오의 어느 타임스텝을 비용 함수에 사용할지 결정하는 데는 추가적인 세부 사항이 있다.
실제 영역 도메인: 우리는 absolut
[Title_Easy_KO]: “3D 객체 흐름으로 로봇 조작”
[Title_Easy_EN]: “Robot Manipulation with 3D Object Flow”