본 논문은 계층적 생성 슬레이트 추천 프레임워크인 HiGR을 제안한다. HiGR은 대규모 온라인 서비스에서 사용자 경험의 핵심 요소로 작용하는 슬레이트 추천 문제를 해결하기 위해 설계되었다. 기존 방법론이 효율적이지만 항목 수준 목표만 최적화하고 전체 리스트 품질을 무시하는 반면, HiGR은 생성 모델과 대조 학습을 통한 계층적 구조화된 아이디를 통해 슬레이트의 글로벌 구조와 세부 항목 선택 사이에서 효율적인 추론을 가능하게 한다.
💡 논문 해설
1. **계층적 생성 프레임워크 (HiGR)**: 기존 추천 시스템은 각 항목을 독립적으로 평가하고, 이를 합쳐 슬레이트를 만드는 방식이었다. 그러나 HiGR은 전체 슬레이트의 구조와 세부 항목 선택 사이에 계층적 접근법을 도입하여 효율적인 추론과 글로벌 품질 최적화를 동시에 달성한다.
대조 학습을 통한 아이디 구조화 (CRQ-VAE): HiGR은 항목의 의미적 정보를 보존하면서도 복잡성을 줄이는 대조 학습 기반의 아이디 구조화 방법론을 사용한다. 이를 통해 모델이 슬레이트 생성 과정에서 더 정확하게 제어할 수 있다.
리스트 단위 선호도 일치 (ORPO): HiGR은 사용자 피드백을 기반으로 한 리스트 단위의 선호도 최적화 방법론을 도입하여, 슬레이트의 전반적인 품질을 높이는 동시에 모델 학습과 실제 평가 지표 사이의 격차를 줄인다.
📄 논문 발췌 (ArXiv Source)
<ccs2012> <concept>
<concept_id>00000000.0000000.0000000</concept_id> <concept_desc>이 코드를 사용하지 않고, 논문에 맞는 올바른 용어를 생성하십시오.</concept_desc>
<concept_significance>500</concept_significance> </concept>
</ccs2012>
서론
개인화 추천 시스템은 이제 뉴스 피드, 짧은 동영상 플랫폼 및 전자 상거래 애플리케이션 등 대규모 온라인 서비스의 핵심 역할을 수행하고 있습니다. 기존 항목 수준 추천과 달리 슬레이트 추천에서는 항목들이 순위별로 동시에 사용자에게 표시됩니다. 이 슬레이트는 사용자 경험의 기본 단위로서, 어떤 콘텐츠를 소비하는지뿐만 아니라 플랫폼의 관련성 및 다양성을 어떻게 인식하는지 결정합니다.
기존 슬레이트 추천 접근법은 두 단계 패러다임을 따릅니다: 첫째로 각 항목에 대해 독립적으로 점수를 매기는 포인트나 쌍별 순위 모델을 사용하고, 둘째로 그리디 선택 또는 재순위화 휴리스틱을 통해 최종 슬레이트를 구성합니다. 이러한 방법은 계산 효율성이 있지만, 항목 수준 목표만 최적화하고 리스트 수준의 품질을 고려하지 않는다는 한계가 있습니다. 예를 들어 짧은 동영상 추천에서 사용자는 종합적인 선호도로 다양한 콘텐츠를 선호하므로 단일 항목 점수로는 포착할 수 없습니다.
최근 생성 모델의 발전, 특히 대형 언어 모델과 자동회귀 아키텍처는 슬레이트 추천에 새로운 가능성을 열었습니다. 이러한 접근법은 순서 생성 작업으로 추천을 정의하여 항목 간 복잡한 종속성을 모델링하고 전체적인 추천 목록을 일관되게 생성할 수 있습니다. 최근 연구들은 일반적으로 잔차 양자화 VAE (RQ-VAE) 기반의 의미 ID (SID)를 사용해 항목을 이산 코드로 토큰화합니다. 그럼에도 불구하고 이러한 방법론은 실제 대규모 시스템에서 배포되는 데 있어 세 가지 근본적인 도전과제를 안고 있습니다: 첫째, 기존 의미 양자화는 ID 공간이 “다른 접두사가 유사한 의미를 공유"하거나 “동일한 접두사가 다른 의미를 함축"하는 경우에 구조적으로 복잡해져 모델이 정확하게 제어할 수 없게 됩니다. 둘째, SID는 어휘 크기를 줄이지만 각 항목을 여러 토큰 (예: 3개의 토큰)으로 표현하여 자동회귀 모델은 순차적으로 토큰을 생성해야 하므로 일반적인 슬레이트를 생성하는 데에 많은 시간이 걸립니다. 셋째, 자동회귀 생성에는 전체적인 목록 계획이 부족합니다.
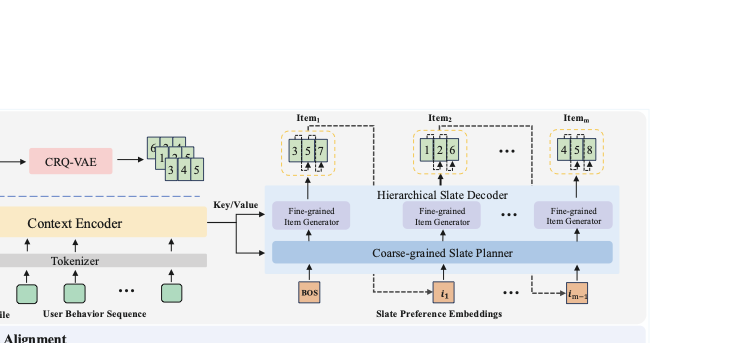
이러한 한계를 극복하기 위해 우리는 계층적 생성 슬레이트 추천 프레임워크인 HiGR을 제안한다. HiGR은 슬레이트 추천을 계층적이고 세밀하게 생성하는 과정으로 재구성하고, 리스트 수준 선호도 일치를 통해 해결합니다. 본질적으로 의미적인 얽힘 문제를 해결하기 위해 우리는 잔차 양자화 및 대조 학습 (CRQ-VAE)을 사용한 오토인코더를 제안한다. 일반적인 양자화와 달리 CRQ-VAE는 접두사 수준의 대조 제약 조건을 주입하여 고수준 ID 접두사가 의미 유사성과 구분성을 명시적으로 인코딩하도록 합니다. 이를 통해 “접두사"가 신뢰할 수 있는 의미적 앵커로 작용하는 구조화된 어휘를 만듭니다.
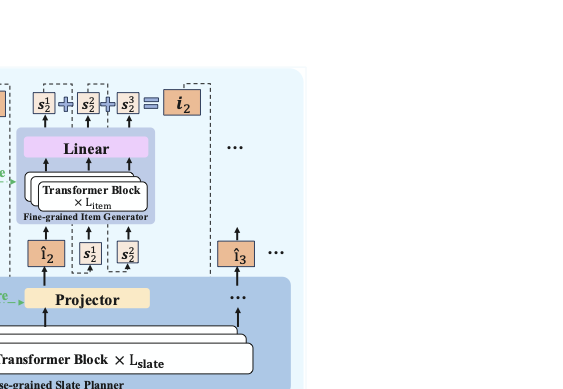
HiGR은 슬레이트 생성을 두 단계로 분리합니다: 전체 슬레이트의 글로벌 구조와 의도를 포착하는 리스트 수준 선호도 계획 단계, 그리고 특정 항목 선택으로 선호도 계획을 구현하는 항목 수준 디코딩 단계. 이 계층적 설계는 효율적인 추론과 동시에 일관된 글로벌 계획을 유지하여 효율성과 품질 문제를 동시에 해결합니다.
우리의 주요 기여는 다음과 같습니다:
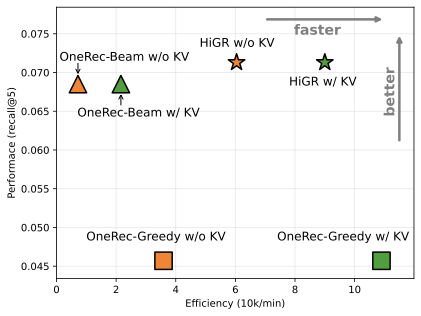
HiGR은 최초의 end-to-end 생성 슬레이트 추천 프레임워크로, 추론 효율성과 성능을 크게 개선하여 산업적 시나리오에서 배포 가능성을 제공합니다.
CRQ-VAE와 HSD를 도입해 접두사 수준의 정렬 및 리스트 수준 계획과 항목 수준 선택을 분리하여 효율적인 추론과 일관된 글로벌 구조를 가능하게 합니다.
사용자의 암묵적 피드백을 활용한 리스트 단위 선호도 일치 목표를 제안해 모델 학습과 실제 평가 지표 사이의 격차를 줄입니다.