- Title: Iterative Deployment Improves Planning Skills in LLMs
- ArXiv ID: 2512.24940
- 발행일: 2025-12-31
- 저자: Augusto B. Corrêa, Yoav Gelberg, Luckeciano C. Melo, Ilia Shumailov, André G. Pereira, Yarin Gal
📝 초록
이 논문에서는 대형 언어 모델(LLMs)을 반복적으로 배포하고 이를 정제하는 과정에서 그들의 계획 능력이 어떻게 향상되는지 보여줍니다. 이는 사용자 의도를 충족하지 않는 텍스트들을 필터링한 후 남은 텍스트들을 다시 학습 데이터로 활용하는 메커니즘을 포함합니다.
💡 논문 해설
1. **핵심 기여물 1**: 반복 배포 메커니즘이 LLMs의 계획 능력을 향상시킨다는 것을 보여줍니다. 이는 마치 학생이 자신의 과제를 스스로 검토하고 개선하는 것과 유사합니다.
2. **핵심 기여물 2**: 이 메커니즘은 RL 정제와 비슷하지만, 보상 신호가 암묵적으로 정의된다는 점에서 차이가 있습니다. 이를 통해 모델은 사용자와의 상호작용을 통해 스스로 학습합니다.
3. **핵심 기여물 3**: 반복 배포 메커니즘은 RL과 같은 강화학습 방법론에 연결되며, 이는 모델 안전성에 대한 새로운 고려 사항을 제기합니다.
Sci-Tube 스타일 스크립트
초급
메타포: “이 논문은 LLMs가 자신의 과제를 스스로 검토하고 개선하는 것과 같은 방법으로 계획 능력을 향상시킨다는 것을 보여줍니다.”
중급
메타포: “LLMs는 사용자와의 상호작용을 통해 정제되는 과정에서 스스로 학습합니다. 이는 마치 학생이 선생님 없이도 자신의 과제를 검토하고 개선하는 것과 같습니다.”
고급
메타포: “반복 배포 메커니즘은 RL 정제와 비슷하지만, 보상 신호가 암묵적으로 정의된다는 점에서 차이가 있습니다. 이는 LLMs가 사용자와의 상호작용을 통해 스스로 학습하는 과정을 의미합니다.”
📄 논문 발췌 (ArXiv Source)
# 서론
이 논문에서 우리는 대형 언어 모델(LLMs)을 반복적으로 배포하고 이를 정제하는 과정이 그들의 계획 능력을 크게 향상시킨다는 것을 보여줍니다. 이 정제는 단순히 이전 배포로부터 수집한 데이터를 검증하고 선택하여 이루어질 수 있습니다. 이러한 메커니즘은 개념적으로 RL 정제와 유사하지만, 보상 신호가 암묵적으로 정의되어 있다는 점에서 차이가 있습니다. 핵심 아이디어는 간단합니다: 반복 배포는 LLM이 출시 후 사용자들이 텍스트를 생성하는 과정으로 시작됩니다. 이 텍스트들은 검증 과정을 거치며, 사용자의 의도를 충족하지 않는 텍스트들은 거절됩니다. 남은 텍스트들은 웹에 공유되어, 웹에서 수집된 이들 텍스트를 다음 세대 LLM의 학습 데이터로 활용합니다.
반복 배포는 인위적인 설정이 아닙니다: GPT-3.5은 GPT-3 배포 후 웹에서 수집한 데이터로 학습되었으며, 그 때 공유된 웹 내용에는 사용자가 GPT-3을 이용해 생성한 정제된 텍스트가 포함되었습니다. 마찬가지로, GPT-4는 사용자들이 GPT-3.5과 GPT-3으로부터 공유한 데이터로 학습되었습니다. 에이전트 워크플로우가 더 일반화됨에 따라, 미래의 학습 데이터는 이전 모델 세대에서 생성된 액션 추적을 포함할 것이며, 이를 통해 반복적인 학습 과정이 진행될 것입니다.
[[IMG_PROTECT_1]]
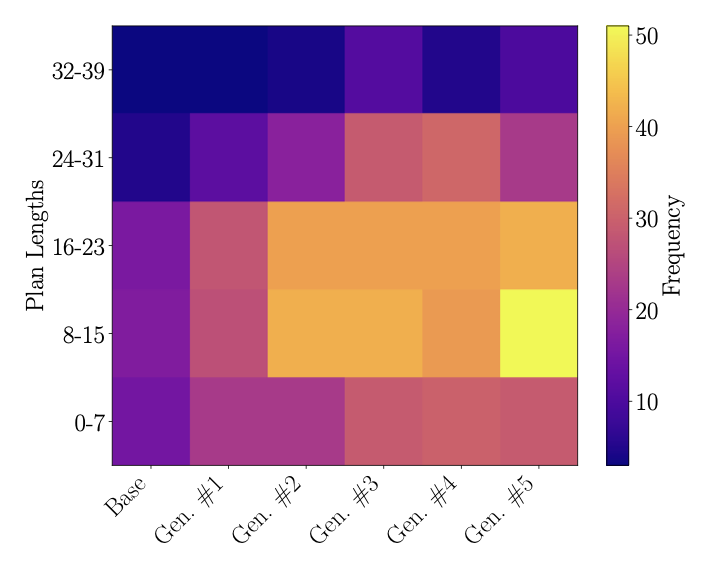
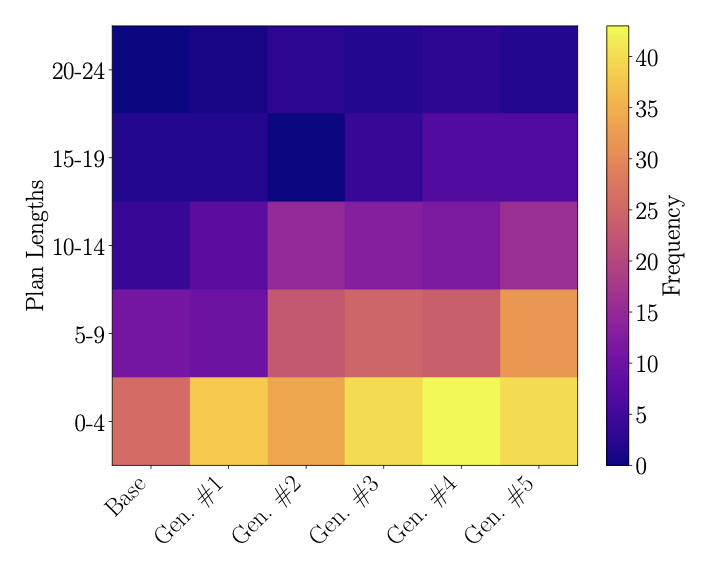
계획에 대한 반복 배포 메커니즘의 단일 반복. 고정된 계획 작업 세트를 사용하여 현재 버전의 LLM – 모델의 n세대라고 지칭되는 것 – 이 이러한 작업을 해결하도록 프롬프팅합니다. 외부 검증자(예: 챗봇을 이용하는 인간 또는 계획의 경우 컴퓨터 프로그램)가 올바르게 해결된 작업을 식별합니다. 그들의 추적 및 계획은, 이전 세대에서 해결된 작업들에 대한 추적과 함께 사용되어 n세대를 미세 조정하여 n+1세대 모델이 생성됩니다.주요 결과 요약. 세 가지 다른 도메인에서 기본 모델과 후속 배포 세대(세대 1, 2 및 5)를 비교한 작업 해결 개수 (각 도메인당 1000개의 작업). 세 개 별도 실행에 대한 평균. 모든 도메인에서 다섯 번째 세대는 기본 모델의 성능을 두 배 이상 향상시킵니다.
이 메커니즘은 고정된 계획 환경에서 평가됩니다. 반복 배포는 계획에 일반적인 패턴을 포착합니다: 사용자들이 LLMs를 이용해 제품 검토, 추론 작업 해결 또는 여행 계획 등에 활용할 때, 결과가 올바르다면 공개적으로 공유하는 경향이 더 크다는 점입니다. 이는 사용자가 올바른 ‘해결책’을 선택하여 공유하기 전에 필터링하는 형태의 정제로 작용합니다. 여기서 우리는 LLMs가 이전에 생성된 정제된 추적만 접근할 수 있는 경우 계획 능력이 향상되는지 연구하고자 합니다. 우리는 이러한 시나리오를 고정된 계획 환경에서 모의실험하고, LLMs의 자체 개선 능력을 집중적으로 연구합니다. 먼저 기본 모델을 다양한 계획 작업에 프롬프팅하여 해결하게 하고, 짧은 시간 범위와 더 어려운 장기 계획 문제를 혼합합니다. 그런 다음 작업을 해결하지 못한 추적들을 제거하고 남은 것을 원래 데이터와 함께 섞어 다음 세대 모델을 미세 조정합니다. 반복적으로 학습된 모델들은 기본적으로 서로의 계획 능력을 부스팅합니다: 각 모델은 외부 프롬프트나 외부 계획자에 의존하지 않고 계획 작업을 해결하려고 시도합니다. 이전 세대에서 해결한 간단한 계획은 후속 세대의 학습 데이터로 사용되며, 이를 통해 모델은 이러한 간단한 “빌딩 블록"을 복잡한 계획 문제를 해결하는 데 활용할 수 있습니다.
Qwen3 4B을 이용한 실험에서, 다섯 번째 배포 세대까지 최신 모델이 모든 테스트된 도메인에서 기본 모델의 성능을 2배 이상 향상시켰습니다.
[[IMG_PROTECT_2]] 주요 실험 결과를 요약합니다. 일부 경우에는 성능이 5배 증가했습니다. 후속 세대는 기본 모델보다 훨씬 긴 계획을 찾을 수 있으며, 이 메커니즘은 분포 외 일반화를 가능하게 합니다. 또한 후속 세대에서 생성된 추론 토큰의 평균 개수에 큰 차이가 없으며, 일부 RL 정제 결과와 대조됩니다.
우리는 반복 배포가 보상 함수가 이진이며 추적들이 중요 샘플링에 따라 가중치를 부여받은 특별한 경우의 REINFORCE와 동등하다는 것을 엄밀하게 증명합니다. 이 연결성은 두 가지 중요한 함의를 지닙니다: 첫째, 반복적으로 학습된 모델 배포에는 큰 안전 위험이 있으며, 사용자 상호작용을 통해 간접적으로 정제하는 경우 다음 세대 모델이 암묵적인 보상 함수로 효과적으로 학습됩니다. 이는 모델의 행동에 중요한 영향을 미칠 수 있습니다(예: 암묵적 보상이 안전 훈련과 충돌할 수 있음). 둘째, 여기서 강조된 메커니즘은 명시적인 RL 대신 정제 메커니즘을 사용하여 일반화를 유지하면서 다른 학습 방법론으로 볼 수 있습니다. 이 정제 메커니즘은 배포 후 환경에서 제공된 프롬프트로부터 생성된 추적(예: LLM과의 사용자 상호작용, 도구 사용 추적)에 대한 후처리 검증을 신호로 활용합니다. 우리의 관찰은 커뮤니티가 이러한 암묵적인 보상 함수의 속성을 최우선으로 연구해야 함을 시사하며, 이미 사회에서 반복 배포된 AI 시스템이 이용되고 있기 때문입니다.
논문 전체에서 초기 모델을 단순히 기본 모델 또는 세대 0이라고 지칭합니다. 마찬가지로, 프로세스의 n번 반복 후에 배포되는 방법은 n번째 세대 모델이라고 부릅니다.
반복 배포는 LLMs의 계획 능력을 향상시킵니다
우리는 반복 배포를 연구합니다. 이는 대형 언어 모델(LLMs)이 외부 전문가의 시연이나 추가적인 교사 모델 없이 스스로 계획 능력에 대한 부스팅을 달성할 수 있는 학습 메커니즘입니다. 핵심 직관은 모델이 이미 성공적으로 해결한 간단한 작업들로부터 학습하여, 그 자체의 유효 출력들을 후속 세대를 위한 학습 데이터로 사용한다는 것입니다(신뢰할 수 있는 정제/검증 메커니즘이 제공되는 경우).
우리는 LLMs가 자신의 정제된 추적을 통해 계획 능력을 향상시킬 수 있다는 가설을 제기합니다. 즉, 먼저 간단한 작업들을 스스로 해결하고 그 추적을 사용하여 미세 조정하는 과정에서 부스팅할 수 있습니다. 후속 세대는 더 큰 작업들부터 시작하여 이를 새로운 추적으로 활용해 더 큰 작업들이 해결될 수 있습니다. 이 과정을 여러 번 반복하면 계획 능력이 점진적으로 향상됩니다. 예를 들어, 현재 모델의 세대가 한 개의 상자를 가진 소코반 문제를 해결할 수 있다면, 그 추적을 통해 두 개 또는 세 개의 상자 문제가 해결될 수 있게 학습합니다. 따라서 자신의 현재 능력을 활용함으로써 모델은 미래 세대에서 더 어려운 작업들을 해결할 수 있습니다.
형식적으로, $`M_n`$을 n세대의 모델로 표기하고 $`\theta_n`$으로 매개변수화된다고 가정합니다. 우리는 솔루션 없이 계획 작업들의 데이터셋 *$\mathcal{D}_{tasks}$*에 접근할 수 있다고 가정하며, 결정론적인 외부 검증자 $V(x, y)$가 추적 $y$가 작업 $x$의 유효한 해결책인지 아닌지를 판단하고 이를 반환하는 함수라고 정의합니다. 이 검증자는 추론 작업을 위한 교정 메커니즘이나 사용자의 선호도를 대신할 수 있는 프록시로 볼 수 있습니다. 우리는 *$\mathcal{D}_{tasks}$*를 테스트 세트로 평가하며, 반복 배포가 모델이 자신의 이전에 정제된 솔루션만을 이용해 더 긴 작업들을 해결하는 능력을 어떻게 향상시키는지 찾고자 합니다. 반복 배포 과정은 다음과 같이 진행됩니다:
배포 및 추적 수집: 각각의 반복 $n$에서, 현재 모델 $M_n$이 *$\mathcal{D}_{tasks}$*에 있는 작업들을 해결하도록 프롬프팅합니다. 각 작업 입력 $x$에 대해 모델은 정책 $\pi_{\theta_n}(y|x)$에 따라 추적 $y$를 생성합니다. 이 추적에는 모델이 생성한 사고 체인과 잠정적인 해결책을 포함합니다. 이것은 모델이 사용자나 환경과 상호작용하는 표준 배포 시나리오를 모방합니다.
검증: 생성된 추적들은 외부 검증자 $V$에게 전달됩니다. 출력을 필터링하여 유효한 추적만 남깁니다, $`\mathcal{D}_{valid}^{(n)} = \{(x, y) | V(x, y) = \text{True}\}`$. 초기 세대에서는 대부분의 출력이 부정확한 계획들로 구성되어 있으며 이들은 제거됩니다.
정제 및 집합: 치명적인 잊음을 방지하고 일반화를 향상시키기 위해 현재 세대와 이전 모든 세대에서 생성된 유효 추적을 합칩니다. 다음 단계의 학습 데이터셋은 $`\mathcal{T}_{n+1} = \bigcup_{i=0}^{n} \mathcal{D}_{valid}^{(i)}`$입니다.
이 집합 과정에서 두 번째 정제 단계를 적용합니다: 선택 메커니즘을 통해 데이터의 품질을 보장합니다. 동일한 작업에 대해 여러 유효 추적(예: 다른 세대들로부터)이 존재할 경우, 가장 높은 품질의 해결책만 유지됩니다. 실험에서 효율성은 계획 길이가 가장 짧고 추론 토큰 수가 적은 추적을 선택하는 것으로 정의되지만 원칙적으로 다른 작업 특정 메트릭들이 사용될 수 있습니다.
감독 학습 미세 조정(SFT): 마지막으로, 우리는 현재 모델 $M_n$을 합쳐진 데이터셋 $`\mathcal{T}_{n+1}`$에 대해 표준 감독 학습 목표(다음 토큰 예측)를 사용하여 다음 세대 $`M_{n+1}`$를 생성합니다.
정제 및 집합 단계는 중요하며, LLM과의 상호작용을 공개로 만드는 가능성은 균일하지 않고 상호 작용의 성격과 사용자의 의도에 따라 달라집니다. 예를 들어, 사용자가 LLM을 이용해 코딩 작업을 해결할 때, 그들은 특히 우아하거나 간단한 솔루션을 코드베이스로 통합할 가능성이 더 큽니다. 이는 사용자의 선호도가 나타난 선택 메커니즘과 유사하게 작용합니다(이는 반드시 명시적인 선호도가 아닐 수 있습니다). 이는 모델 붕괴 연구에서 사용된 가정들과의 중요한 차이점입니다. LLMs은 재귀적으로 생성된 데이터로 학습할수록 성능이 저하되고 모델들이 결국 붕괴될 가능성이 높습니다. 그러나 정제는 이를 지연하거나 예방할 수 있습니다. 본 연구에서는 이러한 추가 가정에 대한 효과를 연구하며, 미래 세대 모델들에 미치는 영향을 이해하는 것이 중요함을 주장합니다.
[[IMG_PROTECT_3]] 이 과정의 한 반복이 어떻게 작동하는지 설명합니다. LLM의 n세대가 배포되면 사용자들이 프롬프팅합니다. 생성된 추적들은 외부 검증자에 의해 필터링되고, 유효한 추적들은 모델의 n+1세대를 미세 조정하기 위해 사용됩니다. 우리는 학습 커리큘럼을 직접 구성하는 것이 아니라 LLM과 검증자가 함께 이를 구성한다는 점에서 주목해야 합니다: 테스트 세트 *$\mathcal{D}_{tasks}$*로부터 모든 작업에 대해 모델을 프롬프팅하여, 유효하지 않은 추적들을 제거하고 유효한 것들을 학습 데이터에 추가한 후 다음 세대를 미세 조정합니다.
강화학습과의 연결성 공식화
반복 배포는 보상 신호가 암묵적으로 정의된 RL 정제와 해석할 수 있습니다. 우리는 SFT에서 유효 추적만 사용하는 것이 이진 보상 함수를 갖는 REINFORCE의 특별한 경우임을 증명합니다.
이를 보여주기 위해 다음 결과부터 시작합니다:
Proposition 1. SFT에서 유효 추적만 사용하고, 이진 보상을 가진 REINFORCE와의 기울기 업데이트 방향은 동일하다.
증명은
[[IMG_PROTECT_4]]에 포함되어 있습니다.
현재 정책 $`\pi_\theta`$로 생성된 추적들을 on-policy 추적으로 지칭하며, 이전 세대나 외부 출처에서 생성된 behavior policy $`\pi_\beta`$로 생성된 추적들은 off-policy 추적으로 지칭합니다.
Proposition 2. on- 및 off-policy 유효 추적의 혼합에 대한 SFT는 이진 보상을 가진 REINFORCE와 동일하며, behavior policy로부터 중요도 가중 기여를 추가로 갖습니다.
Proposition [[IMG_PROTECT_5]]의 증명은 또한
[[IMG_PROTECT_4]]에 포함되어 있습니다.
이것으로 원래 주장인 SFT에서 유효 추적만 사용하는 것이 REINFORCE의 특별한 경우임을 증명합니다.
Proposition 3. 반복 배포 메커니즘(Section [[IMG_PROTECT_6]])에 따른 유효 추적을 사용한 SFT는 암묵적으로 정의된 이진 보상을 가진 REINFORCE의 특별한 경우입니다.
증명. Proposition [[IMG_PROTECT_5]]로부터 직접 도출됩니다. ◻
AI 안전성에 대한 함의
반복 배포는 RL 정제와 링크를 공유하지만, AI 안전성에 대한 새로운 우려 사항도 제기합니다. 표준 RL 학습과 달리, 반복 배포는 배포 후 사용자 상호작용을 통해 암묵적인 신호에 의존합니다. 사용자가 이전에 배포된 모델들과의 상호작용을 통한 간접적 정제는 이해하고 제어하기 어려운 불투명한 보상 함수를 만듭니다. RL에서 인간 선호도와 안전 제약 조건을 명시적으로 인코딩하는 데 사용되는 보상 함수와 달리, 반복 배포는 이러한 암묵적인 신호에 의존합니다.