- Title: HaineiFRDM Explore Diffusion to Restore Defects in Fast-Movement Films
- ArXiv ID: 2512.24946
- 발행일: 2025-12-31
- 저자: Rongji Xun, Junjie Yuan, Zhongjie Wang
📝 초록
이 논문에서는 딥러닝 기반의 확산 모델을 사용하여 고해상도 필름 복원 작업에서 발생하는 문제점을 해결하고자 한다. 특히, 제안된 HaineiFRDM 모델은 낮은 VRAM 장치에서도 작동할 수 있도록 설계되었으며, 패치 기반 학습 및 추론 프레임워크를 사용하여 고해상도 복원 작업의 계산 비용을 줄이고자 한다. 또한 실제 손상된 필름과 합성 데이터로 구성된 새로운 데이터셋을 제안하여 모델 성능 평가 기준을 제공한다.
💡 논문 해설
1. **고해상도 복원 문제 해결**: 이 논문에서는 낮은 VRAM 장치에서도 작동할 수 있는 딥러닝 기반 확산모델을 제안합니다. 이는 마치 카메라 앱이 빠르게 움직이는 동작을 포착하듯, 모델이 복잡한 필름 손상도 정확히 인식하고 복원할 수 있게 합니다.
2. **패치 기반 학습 및 추론 프레임워크**: 이 논문은 고해상도 영상을 처리하는 데 필요한 계산 비용을 줄이기 위해 패치 기반 학습 방법을 제안합니다. 이를 통해 모델은 전체 이미지 대신 작은 부분을 복원하고, 이를 다시 조합하여 완성된 이미지를 생성할 수 있습니다.
3. **실제 손상 필름 데이터셋**: 이 논문에서는 실제 손상된 필름과 합성 데이터로 구성된 새로운 데이터셋을 제안합니다. 이는 모델의 성능을 평가하고 개선하는 데 중요한 기준이 됩니다.
📄 논문 발췌 (ArXiv Source)
# 도입부
각 필름은 필름 복원 전문가들이 수작업으로 각 프레임을 복원해야 합니다. 예를 들어, 2시간짜리 영화는 대략 $`170,000`$개의 프레임이 있어서 전문가들에게 막대한 시간과 노동력이 필요합니다. 이런 상황에서 많은 양의 복원을 기다리는 필름들이 있기 때문에 필름 복원 부담을 줄일 수 있는 모델을 설계할 필요성이 절실합니다.
또한, 일반적인 필름 복원 협업에서는 각 전문가가 24GB VRAM RTX 4090 GPU와 같은 소비자 기기를 갖추고 있습니다. 이 경우, 비디오 확산 모델을 설계할 때 추론 시간과 VRAM 제한을 고려해야 합니다.
다양한 복원 방법, 오픈소스 방법 및 상업적 소프트웨어를 비교한 결과, 현재의 오픈소스 연구 방법이 MTI와 DIAMANT 같은 상업적인 소프트웨어보다 크게 뒤처져 있다는 것을 발견했습니다. 여기서 대부분의 오픈소스 복원 문제를 요약하면 다음과 같습니다: 1) 현재 오픈소스 방법의 학습 목표는 인간 전문가와 다릅니다. 먼지 제거 단계에서, 인간 전문가는 때때로 먼지와 흠집만 제거하고 나머지는 그대로 두어 필름에 오래된 분위기를 유지하려 합니다. 그러나 오픈소스 방법은 일반적으로 RTN에서 사용되는 합성 방법을 통해 저품질 데이터를 생성하여 모든 것을 복원하려고 시도합니다. 이로 인해 실제 손상된 필름 샘플과 크게 다른 LQ-GT 데이터 쌍이 만들어져 모델이 모든 흐린 영역을 명확한 영역으로 바꾸는 경향이 있어 영화의 촬영 깊이와 감독의 미적 아이디어를 변경할 수 있습니다. 또한 이전 방법은 세부 사항 오류 및 큰 색상 왜곡을 야기하여 인간 전문가에게 추가 부담을 주고 복원된 프레임을 거의 사용하지 못하게 합니다. 2) 제한적인 필름 복원 데이터로 인해 이전 방법은 보통 흑백 필름만 복원하고 컬러 필름을 뒤로 미루어 이를 적용 범위를 제한했습니다. DeepRemaster는 RGB 공간을 LAB 공간으로 바꾸고 L 채널만 수정하려고 시도하여 영상 재생 시 눈에 띄는 아트팩이 발생합니다; 3) 이전 방법은 REDS와 DAVIS 같은_vlog 스타일 비디오를 학습 데이터로 사용하고 실제 영화는 고려하지 않았습니다. 이로 인해 콘텐츠 유형, 촬영 방식 및 손상 유형을 고려하지 않은 제한된 일반화 능력을 가집니다; 4) 이전 방법은 빠른 움직임 샷에서 어려움이 있습니다. 상업적인 방법인 MTI와 DIAMANT는 프레임 보간법을 사용합니다. 오픈소스 방법은 일반적으로 BasicVSR 같은 프레임워크를 사용하고 학습된 광학 흐름을 복원을 돕기 위해 사용합니다. 이 방법은 느린 움직임 프레임에는 적합하지만 인접 프레임이 큰 차이가 있는 경우 광학 흐름이 실패하여 영화 콘텐츠를 변경할 수 있어 인간 전문가에게 추가 부담을 줍니다; 5) 이전 방법은 잘라낸 $`512 \times 512`$ 또는 리스케일된 해상도 프레임에서 평가하며 실제 필름 스캔해상도 데이터, 예를 들어 1080p, 2K, 4K 해상도에서는 평가하지 않습니다. 이들의 방법은 2K 해상도의 영화 데이터에서 테스트할 때 세부 사항 아트팩이 크게 나타날 수 있습니다. RVRT와 같은 3D 윈도우 추론 방법을 사용하면 결과 프레임에 패치 효과가 나타나 인간 전문가에게 받아들일 수 없는 것입니다. 이전 방법은 공통 벤치마크를 가지고 있지 않고 자체적인 비공개 합성 데이터셋으로 평가해 왔습니다. 또한 아직 분류되지 않은 실제 손상된 필름들이 많아 모델의 실제 성능을 밝히는 데 도움이 됩니다.
확산 모델을 필름 복원에 활용할 때 마주하는 도전 과제: 1) 낮은 VRAM(예: 24GB VRAM) 소비자 그래픽 카드에서 모델을 학습 및 테스트합니다. 2) 로컬 패치를 복원할 때 전역적인 관점을 어떻게 가이드하고 동일한 객체에 대한 다른 패치 사이의 색상 또는 세부 사항 차이가 없도록 협업하는 방법.
우리는 더 일반화된 성능을 갖춘 오래된 필름 복원 시나리오에서 비디오 확산의 생성 사전을 탐색합니다. 또한 이전 연구에서는 노이즈가 있는 광학 흐름을 사용하여 인근 프레임을 왜곡시켜 스크래치 맵을 감지하는 것과 달리, 우리는 스크래치 감지 모듈을 설계하지 않고 확산 모델의 본질적인 실제 세계에 대한 이해를 통해 스크래치 손상에 대해 이해할 수 있는 잠재력을 탐색합니다. 또한 메모리를 효율적으로 사용하는 파이프라인을 설계하여 소비자 기기에서 확산 모델을 활용할 수 있도록 했습니다.
주요 기여 사항은 다음과 같이 요약할 수 있습니다:
우리는 확산 모델의 콘텐츠 이해 능력을 활용하여 빠른 움직임 프레임을 복원합니다.
메모리 효율적인 파이프라인을 제안하여 24GB VRAM 소비자 그래픽 카드에서 학습 및 평가할 수 있습니다. 우리는 조건 특성 추출 손실을 보완하기 위해 효과적인 주파수 인식 어텐션 모듈을 제안합니다. 또한 패치별 학습 및 추론 파이프라인을 배포하여 소비자 기기(24GB GPU)에서 학습 가능하게 합니다. 그리고 패치별 일관성 문제를 완화하기 위해 글로벌 크로스 어텐션 모듈과 VAE 융합 전략을 제안합니다.
우리는 실제 손상된 필름과 제안한 합성 모델로 생성한 합성 손상 데이터를 포함하는 필름 손상 데이터셋을 제안합니다. 또한 필름 수준 해상도에서 복원 결과를 완전히 평가할 수 있는 합성 손상 벤치마크와 실제 손상된 필름 벤치마크를 제안합니다.
관련 연구
style="width:100.0%" />
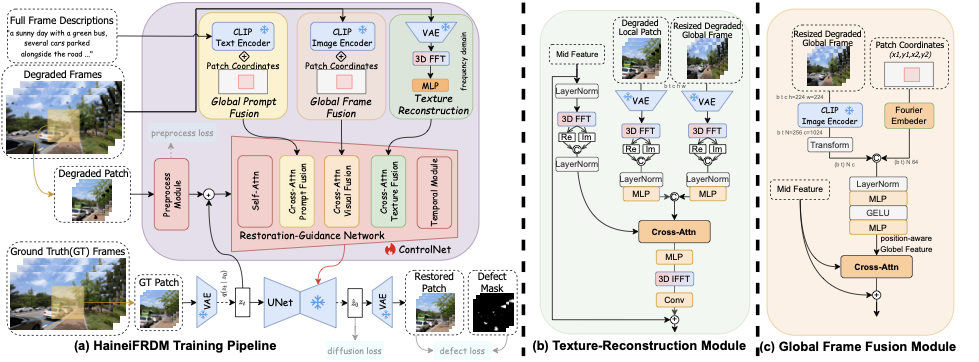
HaineiFRDM의 학습 파이프라인. 모델은 손상된 패치 프레임을 입력하고 Preprocess Module을 통해 각 프레임 특징을 추출합니다. 그런 다음 프레임 특징은 ControlNet으로 전달되며, 여기서 우리는 Global-Prompt-Fusion 모듈과 Global-Frame-Fusion 모듈을 사용하여 모델이 전체 프레임 인식을 할 수 있도록 도와주고 주파수 모듈을 통해 원래 프레임의 텍스처를 유지합니다. 마지막으로 학습된 ControlNet 잔차는 Unet에 입력되어 복원된 프레임 특징 $\hat{z_0}$을 생성하고, 이를 RGB 공간에 매핑하여 복원된 프레임의 결함 영역을 강조하는 결함 손실을 사용합니다.
필름 복원
필름 손상은 구조화된 결함과 비구조화된 손상으로 분류될 수 있습니다. 구조화된 결함은 먼지, 마찰 흔적 등 필름의 물리적 손상입니다. 반면에 비구조화된 손상에는 블러, 가우시안 노이즈, 색상 감소가 포함됩니다. 전통적인 방법은 구조화된 결함 복원을 중점으로 하며 결함 감지 및 복원 단계로 구성되어 있습니다. 이를 통해 깨끗한 영역의 콘텐츠를 보존하면서 프레임 내에서 결함을 복원합니다. 그러나 이러한 방법은 불완전한 가정, 수작업 특징 및 수동 임계값에 기반하므로 콘텐츠 이해 능력이 부족하여 실제 필름에서 결함 감지 및 복원 성능이 제한됩니다. 특히 세밀한 텍스처가 있는 프레임이나 큰 크기의 결함 또는 빠른 움직임을 가진 프레임에서는 이러한 전통적인 방법들이 대부분의 프레임 결함을 탐지하지 못하고 결함 영역에서 텍스처 일관성이 손상될 수 있습니다.
최근에는 딥러닝 기반 방법이 구조화된 결함과 비구조화된 손상을 동시에 해결하려고 합니다. 이러한 방법은 시간 모델링 방식에 따라 광학 흐름 기반 방법과 암묵적 움직임 모델링 방법으로 분류됩니다. 1) 암묵적 움직임 모델링 방법은 명시적인 움직임 정보 없이 신경망을 사용하여 공간-시간 특징을 학습합니다. 예를 들어, DeepRemaster는 완전 3D 컨볼루션을 제안했습니다. 그러나 3D 컨볼루션이 제약된 수용 영역으로 인해 대부분의 결함 복원이 어렵고 복원 프레임에 시간 일관성이 부족한 문제를 안고 있습니다. TAPE는 이동 창 메커니즘을 사용하여 다른 프레임 내에서 특징을 전파합니다. 주목 기제를 통해 이러한 방법은 눈에 띄는 성능을 보여줍니다. 그러나 복잡한 텍스처가 있는 프레임의 결함을 구분하는 데 여전히 어려움이 있습니다; 2) 광학 흐름 기반 방법은 BasicVSR 프레임워크를 따르며, 잡음이 많은 광학 흐름을 수정하고 이 광학 흐름을 사용하여 프레임 특징을 전파하여 결함을 감지하고 결과의 시간 일관성을 개선하려고 시도합니다. 또한 이러한 방법은 윈도우 어텐션, 포커스 어텐션 또는 Mamba를 사용하여 프레임 특징의 공간-시간 일관성을 향상시키면서 모델의 메모리 소비량을 줄이려고 합니다. 그러나 학습된 광학 흐름은 여전히 정확하지 않아 모델이 깨끗한 영역 콘텐츠를 결함으로 잘못 수정할 수 있습니다. 따라서 복원된 프레임에서 인간의 팔과 같은 내용 구조가 지워질 수 있어 전문가에게 받아들일 수 없는 것입니다. 또한 대부분의 방법은 실제 영화와 크게 다른 제한적인 합성 데이터를 사용합니다.; 3) 프레임 보간법
결론적으로, 모든 위의 방법은 콘텐츠 이해 능력이 제한되어 있어 콘텐츠 구조 삭제 및 시간 튀김 문제를 야기할 수 있습니다. 또한 이러한 방법들은 다양한 유형의 결함을 고려하지 않고 720p와 같은 저해상도 프레임만 테스트되었으며, 2K나 4K의 고해상도 필름 데이터에서는 복원 성능이 저하됩니다.
패치 기반 이미지 생성
확산 모델은 복원 작업에서 유망한 잠재력을 보여줍니다. 그러나 스캔된 필름은 일반적으로 2K나 4K의 고해상도이며, 고해상도 비디오에 확산 모델을 학습하려면 막대한 계산 비용이 필요합니다. 따라서 복원 연구실의 소비자 등급 기기에서 직접 고해상도 프레임을 복원하기는 어렵습니다. 휘트치된 필름 결함을 복원하는 확산 모델의 콘텐츠 이해 능력을 탐색하기 위해 패치 기반 생성 방법을 참조하여 계산 비용을 줄이려고 합니다.
패치 기반 고해상도 이미지 생성 방법 중 MultiDiffusion은 슬라이딩 윈도우 방식으로 패치를 생성하고 이 패치를 결합하여 파노라마 이미지를 형성합니다. 그러나 이러한 방법은 객체 반복 문제에 직면했습니다. 또한 학습이 없는 일반적인 접근법으로는 낮은 해상도 이미지를 생성한 다음 슈퍼 리졸루션 기술을 사용하여 이미지를 확장하는 것입니다. ScaleCrafter와 FouriScale은 확산 노이즈 제거 과정에서 희석된 컨볼루션을 사용하여 이미지 특징을 확장합니다. 그러나 이러한 방법은 고해상도 결과에서 패치의 텍스처 일관성을 유지하는 데 어려움이 있습니다. 이에 더해 DemoFusion는 먼저 낮은 해상도 이미지를 생성하고, 특징 공간에서 이미지를 업스케일링한 다음 이를 참조로 사용하여 확산 노이즈 제거 과정을 가이드하여 패치 일관성을 유지하는 고해상도 이미지를 생성하기 위한 글로벌 잔차 프레임워크를 제안하였습니다. 학습이 없는 방법 외에도 Inf-DiT와 HPDM과 같은 접근법은 네트워크 구조를 재설계하고 명시적인 패치 위치 정보를 모델에 통합하여 고해상도 생성을 가능하게 합니다.
필름 복원 데이터셋
고품질 복원 데이터가 부족한 문제를 해결하기 위해, 우리는 복원 연구실에서 실제 필름을 관찰하고 실제 손상된 필름과 합성 데이터로 구성된 데이터셋을 구축했습니다. 우리의 데이터셋은 손상된 프레임, 복원된 프레임, 결함 마스크 및 비디오 설명으로 구성되어 있습니다.
실제로 복원된 필름을 구성하기 위해 먼저 복원 연구실과 MTI, DIAMANT와 같은 회사에서 발행한 ‘복원 전-후’ 비디오를 수집했습니다. 그 다음 비교 비디오에서 손상된 프레임과 복원된 프레임을 추출하고 쌍의 프레임으로 이진 결함 마스크를 계산했습니다. 그러나 일부 복원된 비디오는 픽셀 불일치 문제로 인해 프레임이 결함 복원 외에도 동영상 디플리킹, 색조 조정 절차를 거쳤을 수 있습니다. 또한 일부 복원된 프레임은 불완전한 복원으로 인해 여전히 결함이 남아 있을 수 있습니다. 픽셀 일치하고 잘 복원된 고해상도 프레임을 수집하기 위해 우리는 프레임별로 비디오를 수동으로 필터링했습니다. 마지막으로, 우리는 CogVLM2를 사용하여 비디오 캡션을 생성하고 텍스트를 수동으로 확인한 다음 카메라 각도와 샷 크기 기술자를 사용해 비디오를 라벨링했습니다. 결과적으로 5분(24fps)의 지속시간을 가진 복원된 실제 필름과 테스트를 위한 10분 동안의 2K 해상도 실제 필름을 수집했습니다.
데이터셋 부피를 늘리기 위해 Fig.6에 따라 현실적인 손상된 프레임을 합성하였습니다. 구체적으로, 우리는 다양한 카메라 각도와 샷 크기에 따른 흠집이 없는 필름 클립을 수집했습니다. 또한 다양한 유형의 필름 결함 템플릿을 수집하였고, 여기에는 드문 먼지와 밀도 높은 먼지, 담배 화상 구멍, 깜빡임과 지속적인 스크래치 등이 포함됩니다. 또한 샘플 프레임에 품질 손상(리스케일링, JPEG 압축) 및 필름 텍스처 시뮬레이션(가입자 추가)을 무작위로 적용하여 다양성을 증가시킵니다. 그런 다음 템플릿에서 결함에 색상을 부여하고 프레임과 결함을 결합하여 손상된 프레임을 얻습니다.
방법
빠른 움직임 프레임 복원 시 콘텐츠 왜곡 및 불완전한 복원 문제를 피하기 위해, 우리는 확산 모델의 콘텐츠 이해 능력을 활용하여 HaineiFRDM(Film Restoration Diffusion Model)을 제안합니다. 이는 결함을 인식하고 복원하면서 무결한 콘텐츠를 손상시키지 않습니다. 우리는 패치 기반 학습 프레임워크(4.1절 참조)와 글로벌 잔차 기반 추론 프레임워크(4.2절 참조)를 설계하여 고해상도 복원 작업의 계산 비용을 줄이고 패치 일관성 문제를 해결합니다.
패치 기반 학습 프레임워크
Fig.1에서 보듯이, 우리의 모델의 학습 프레임워크는 VAE, UNet, 복원 가이드 네트워크, 글로벌 프레임 융합 모듈 및 텍스처 재구성 모듈로 주로 구성됩니다. 산업에서 낮은 VRAM 장치에서도 고해상도 프레임을 복원하는 요구 사항을 고려하여 우리의 모델은 잠재 공간에서 프레임을 복원하고 패치 기반 학습 전략을 사용합니다. 구체적으로, 전체 비디오 프레임을 이동 창 메커니즘에 따라 겹치는 3D-패치로 분할하고 패치 위치를 무작위로 샘플링한 다음 훈련에 필요한 손상된 패치, GT 패치 및 결함 마스크를 준비합니다. 또한 결함과 관련 없는 특징을 추출하기 위해 Preprocess Module을 사용하여 손상된 패치를 인코딩하고 VAE 모델을 사용하여 무결한 패치를 잠재 공간으로 인코딩하여 계산 과부하를 줄입니다. 그리고 랜덤