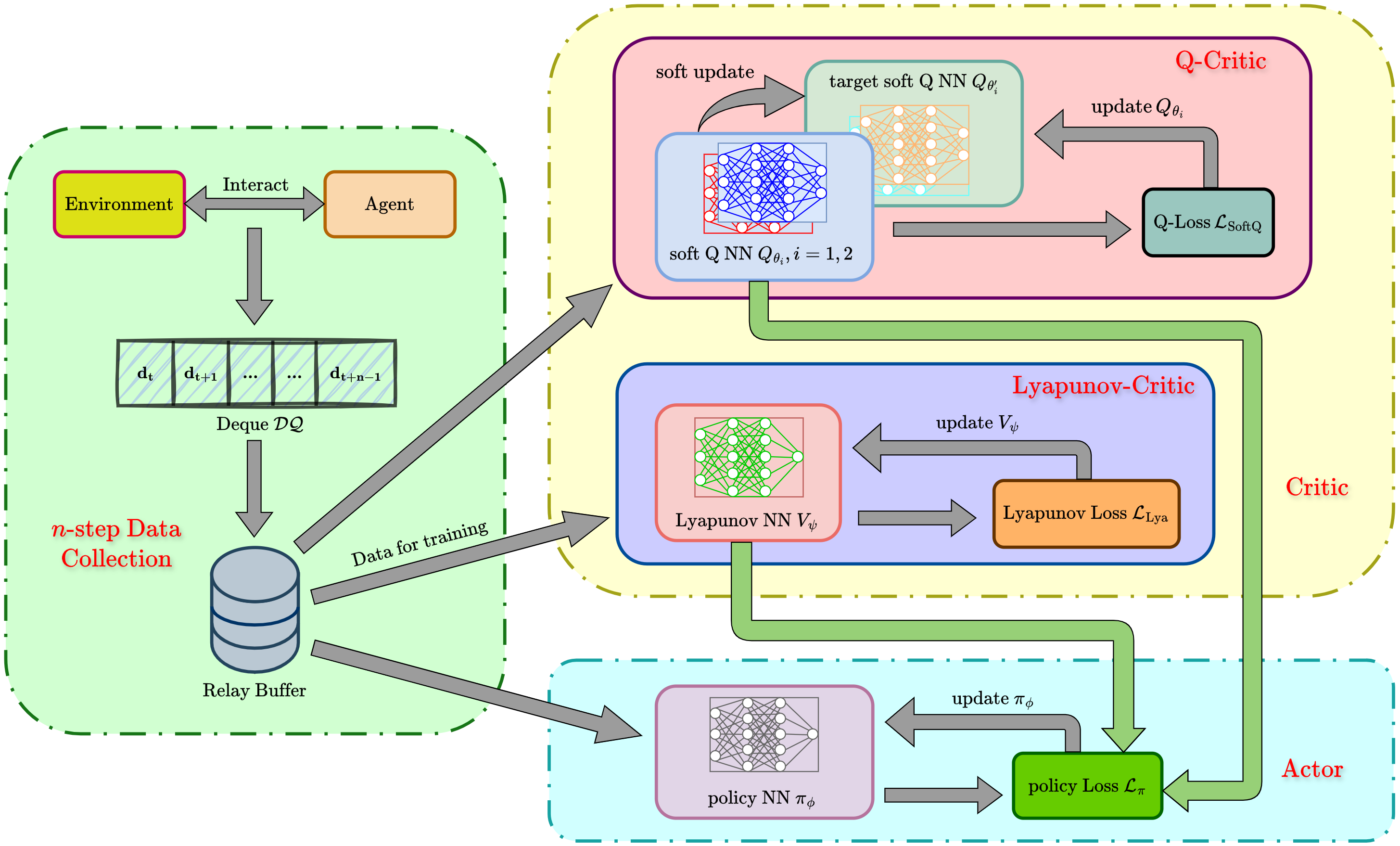
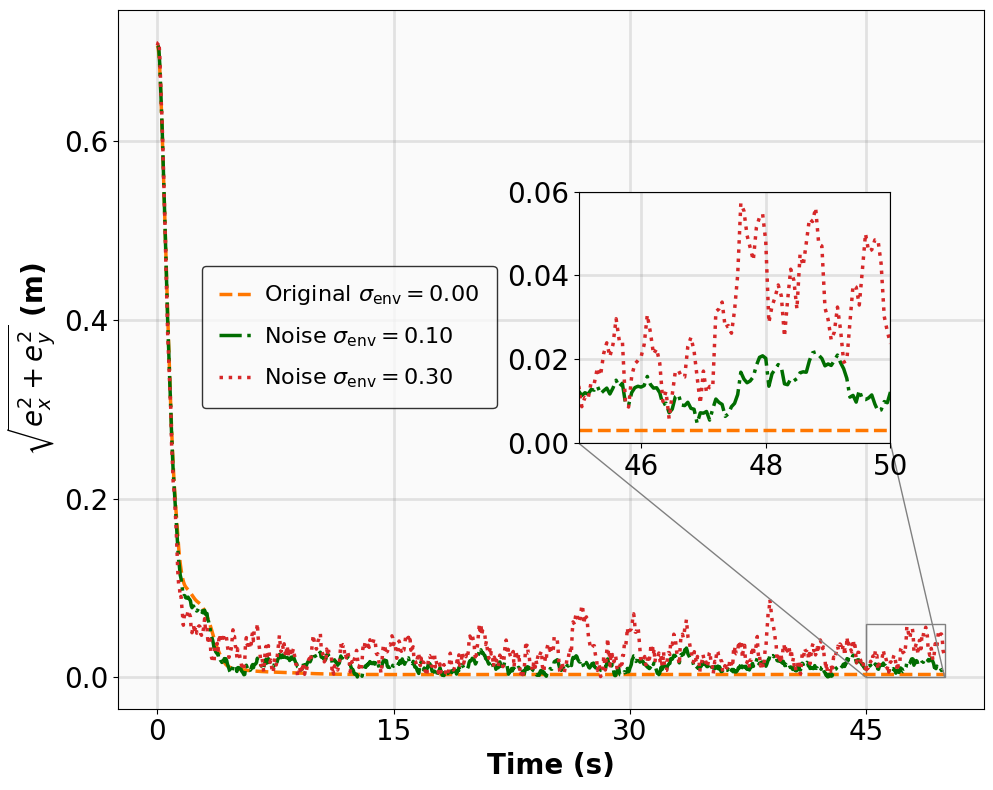
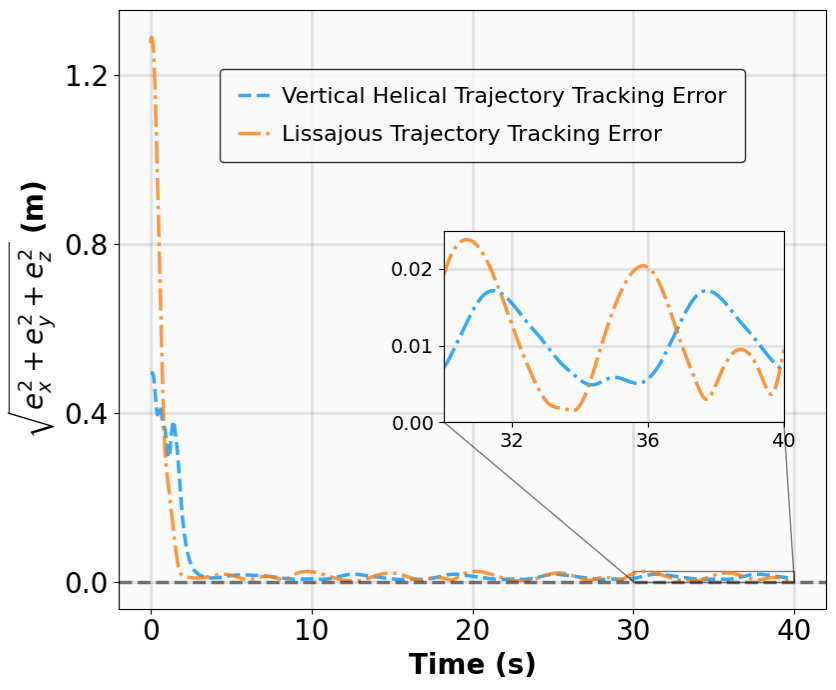
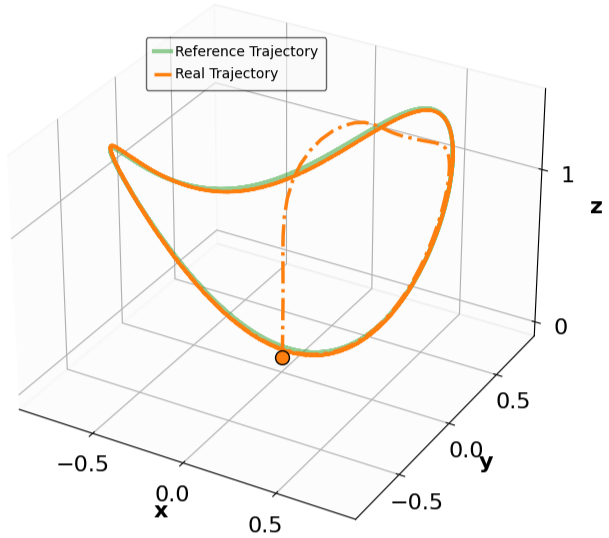
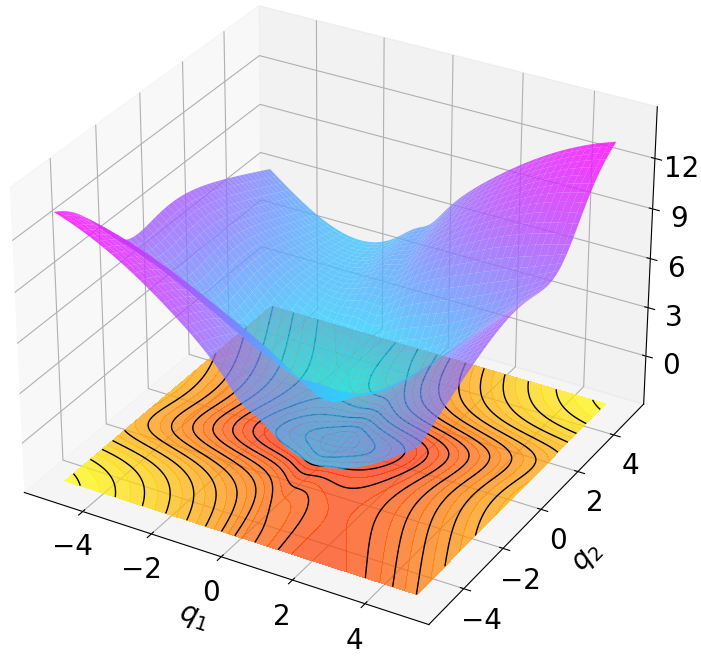
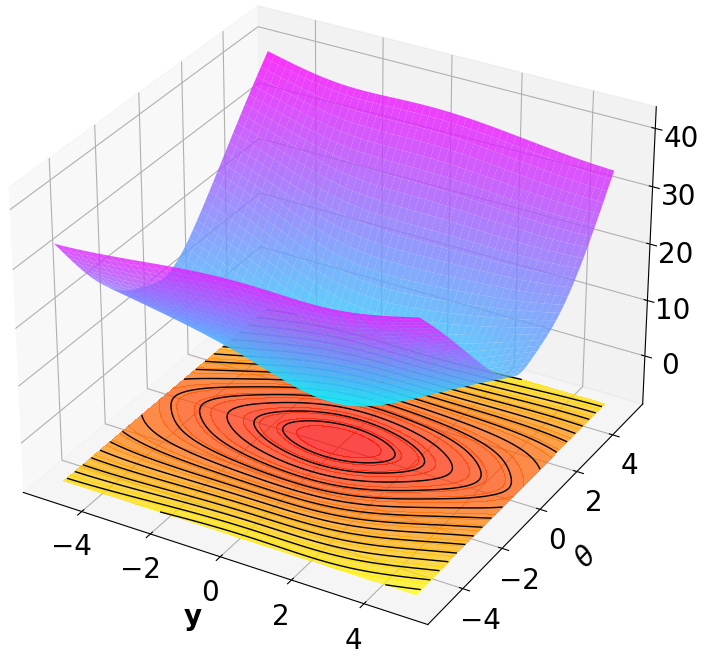
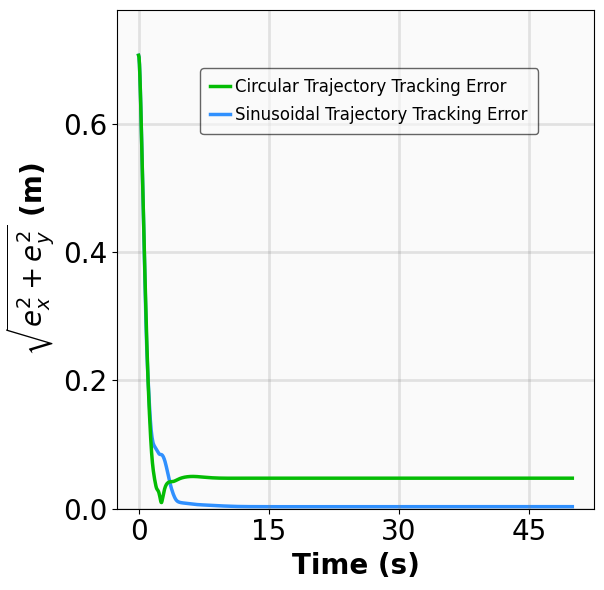
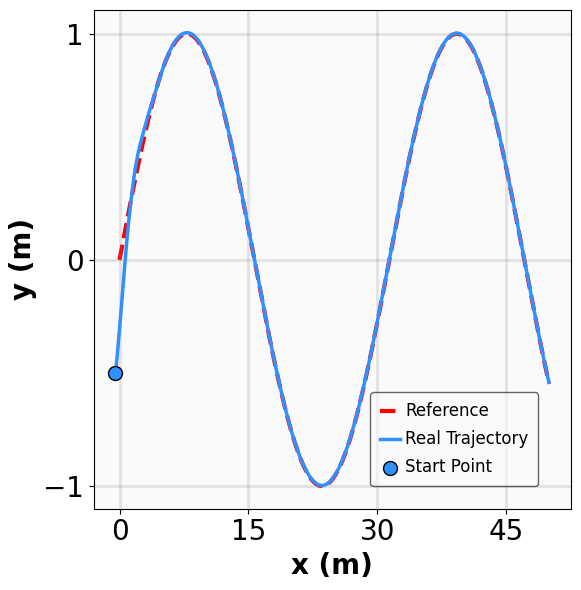
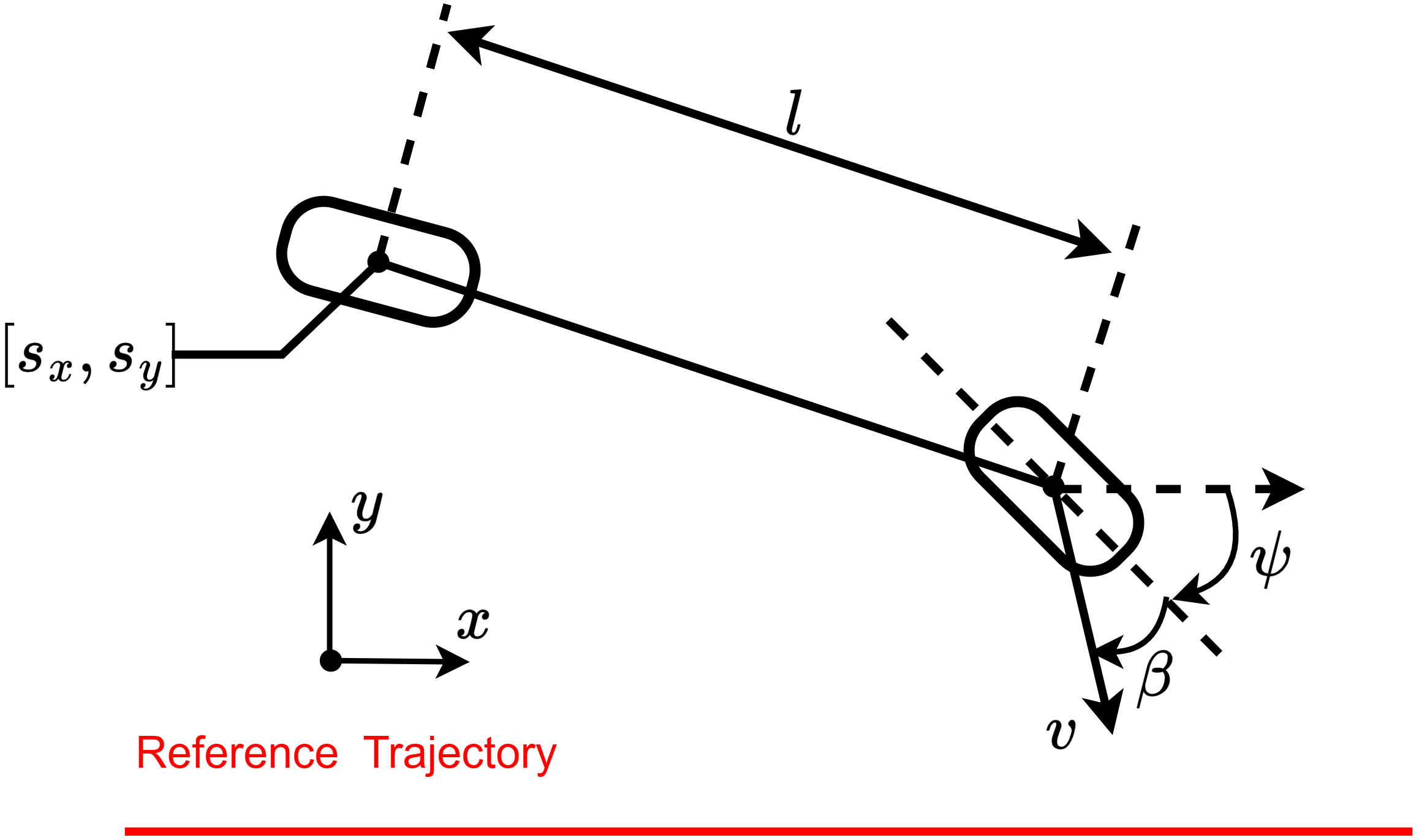
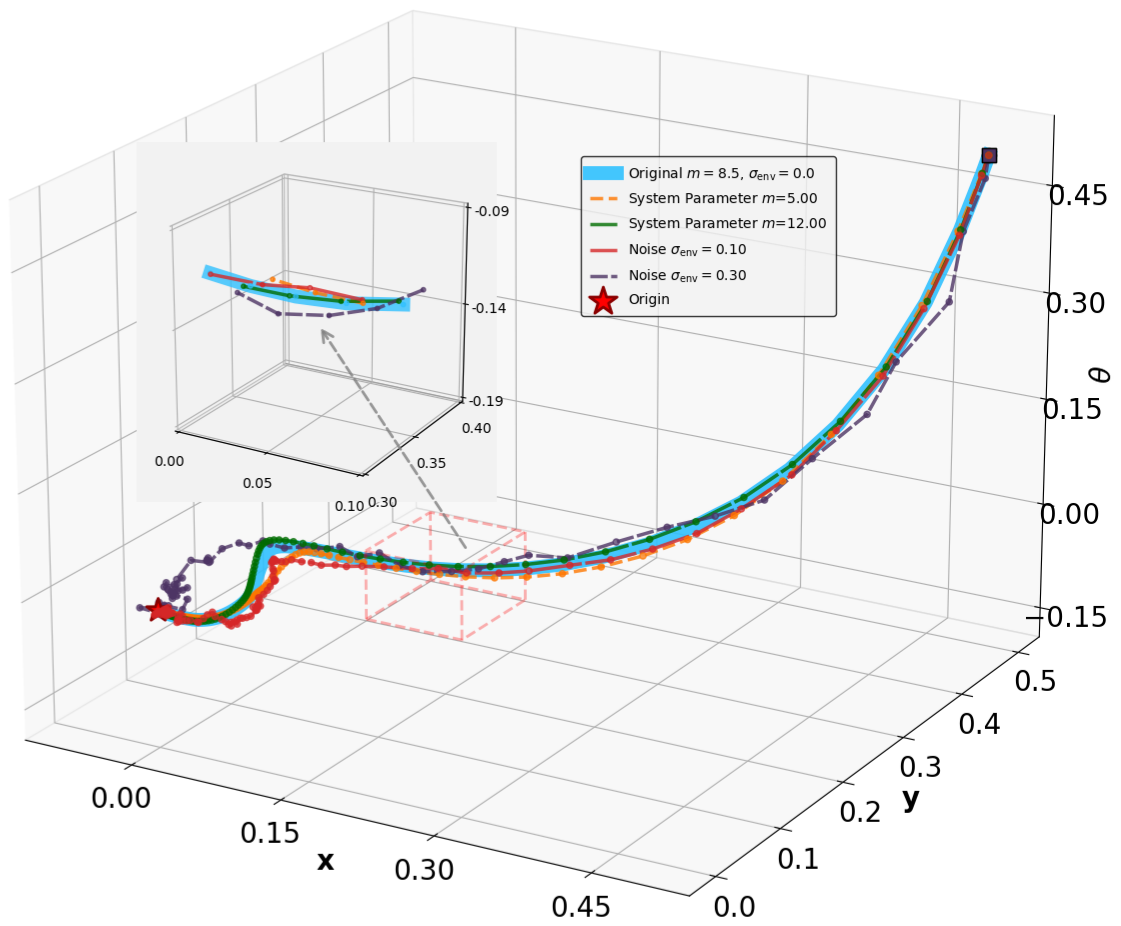
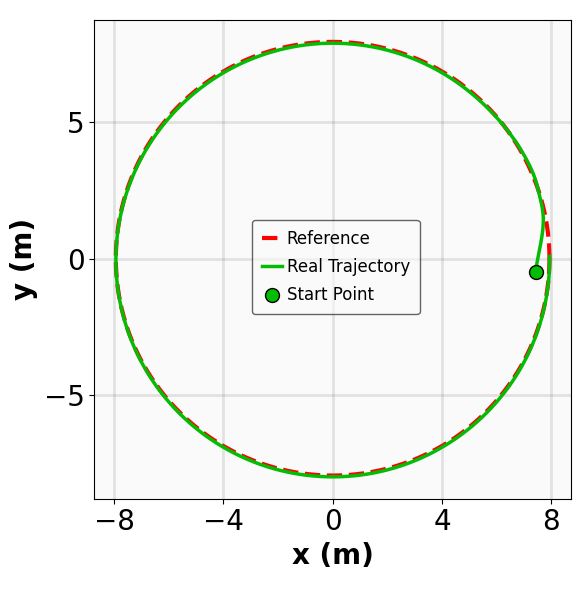
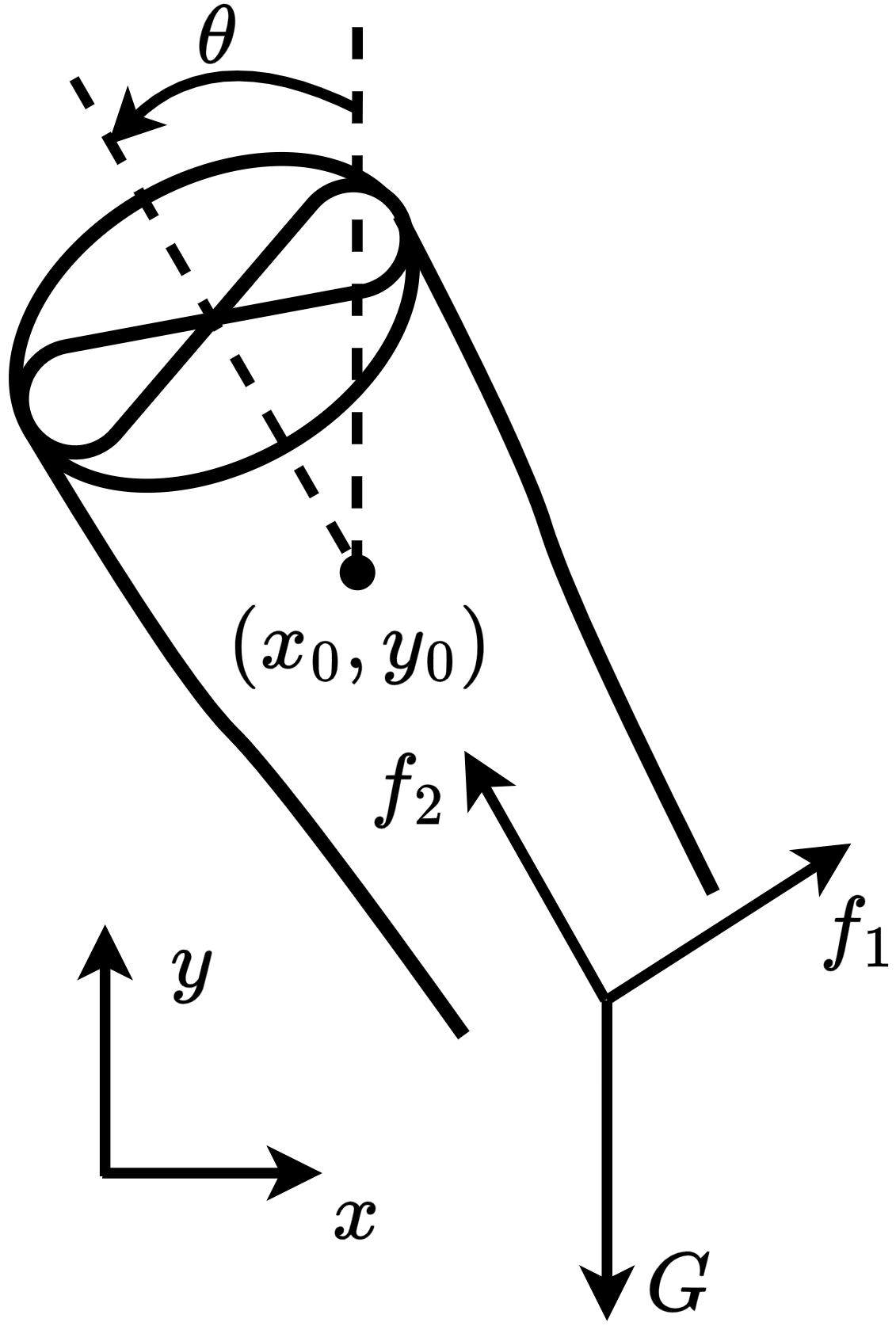
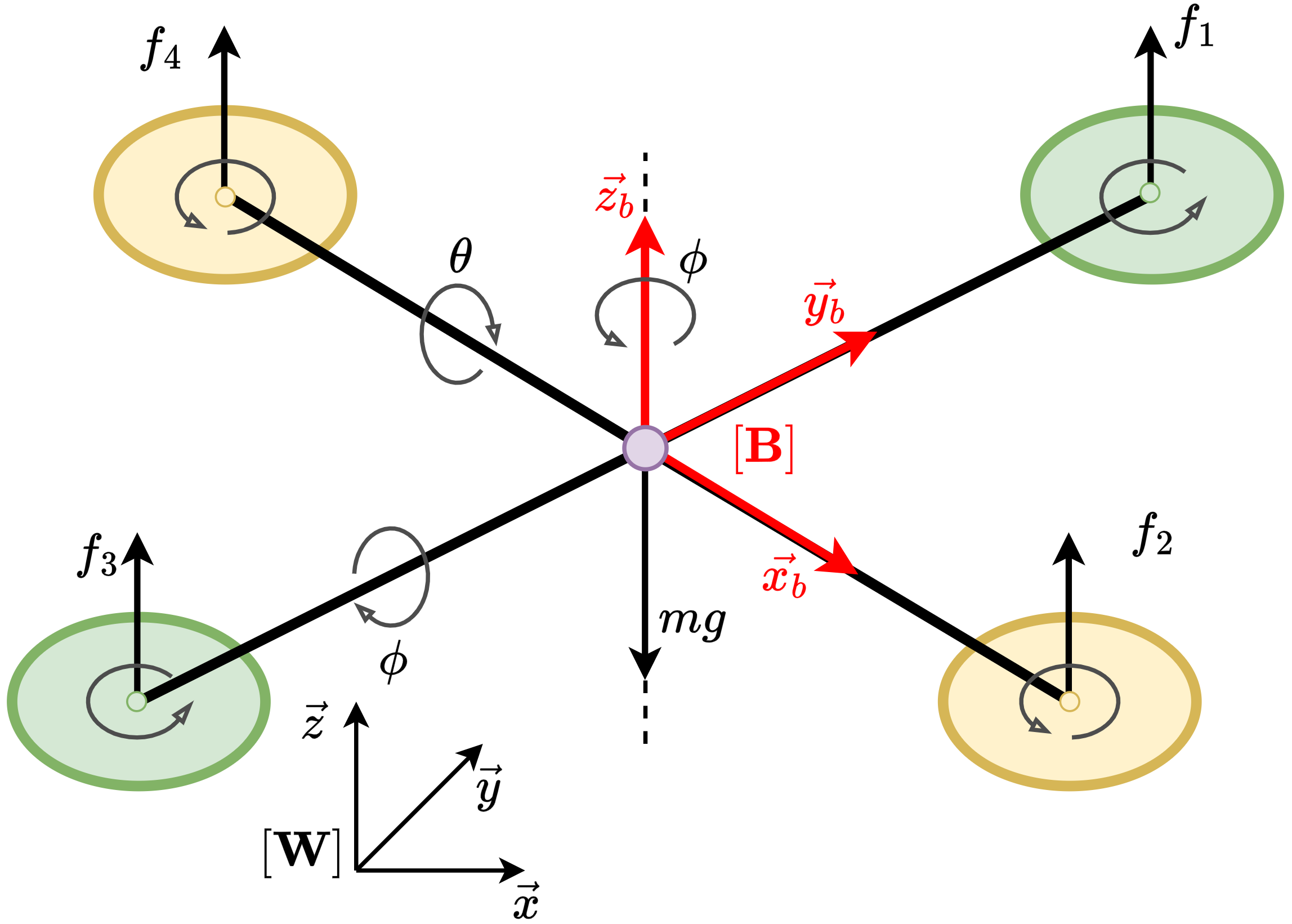
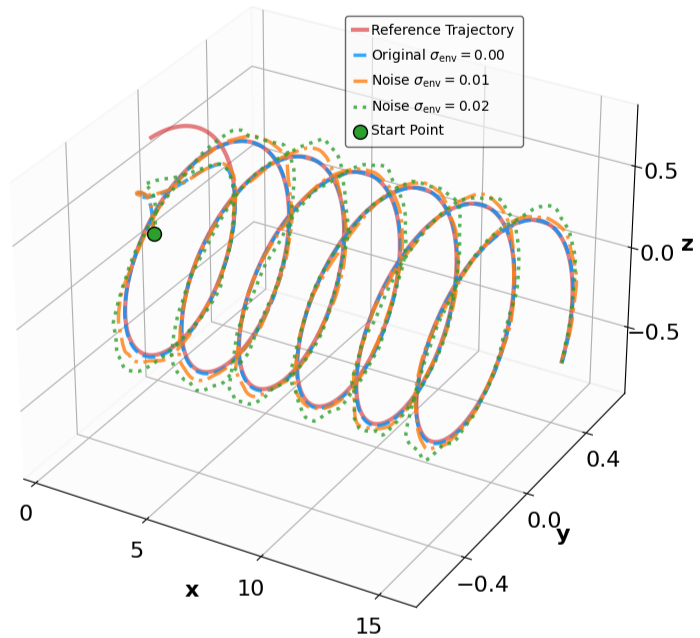
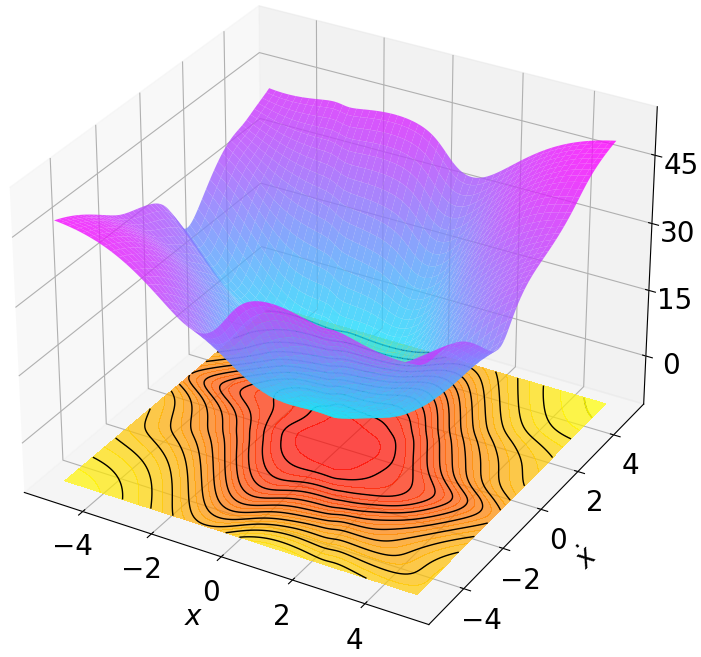
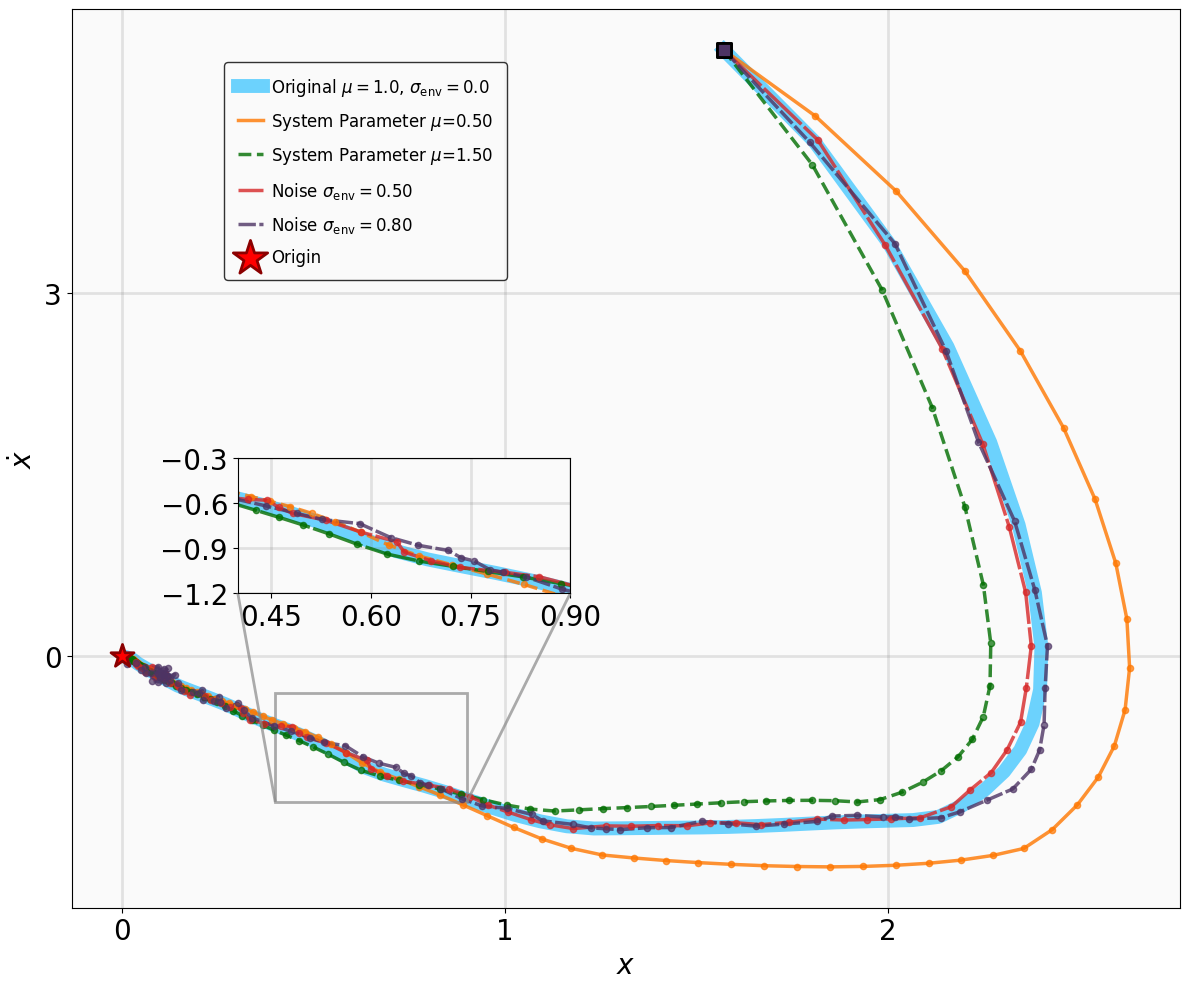
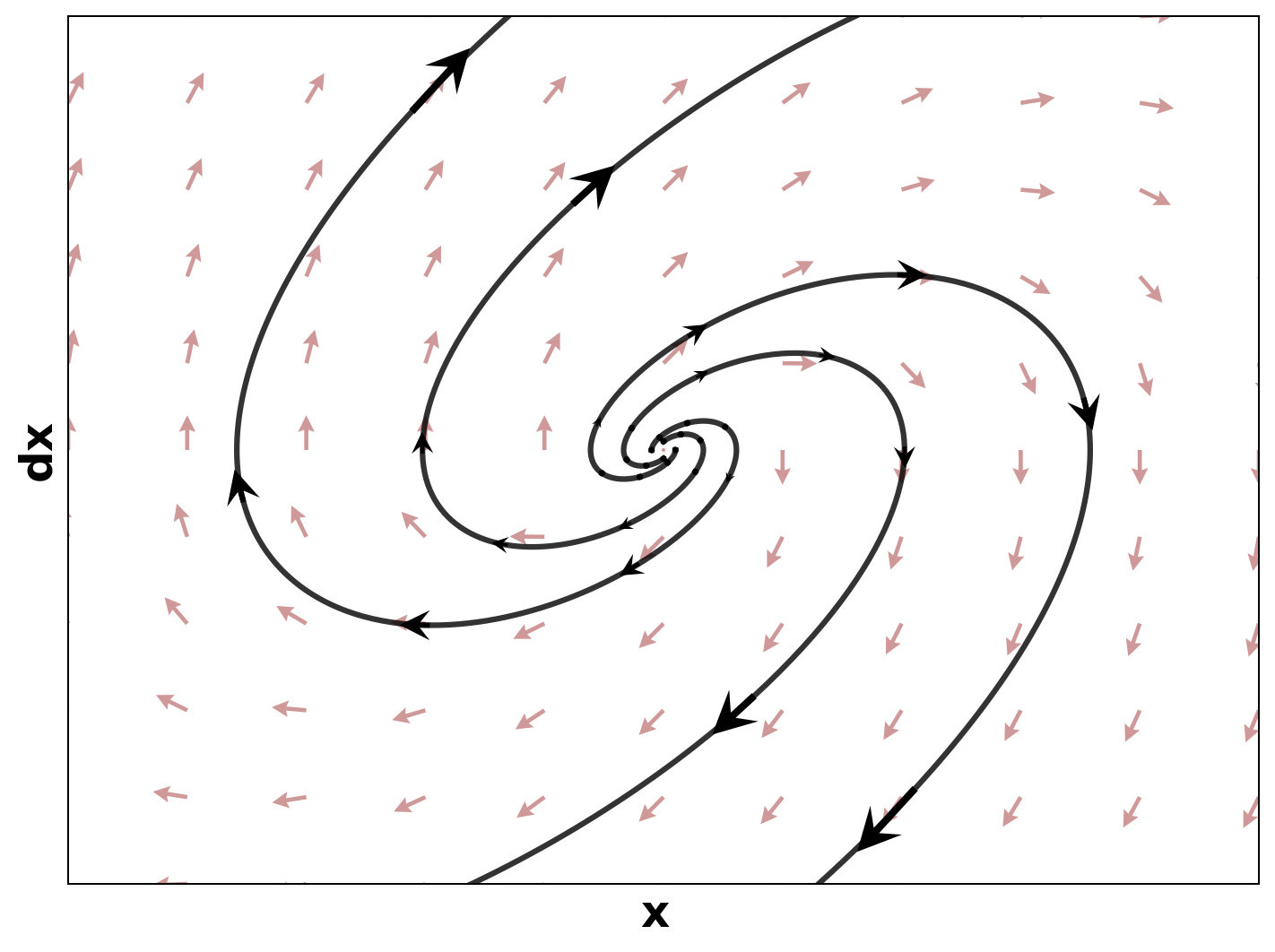
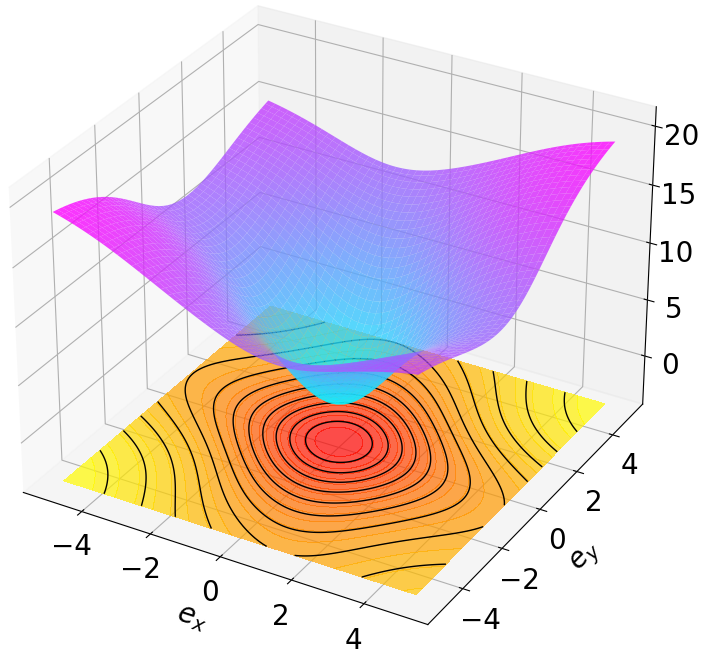
- Title: MSACL Multi-Step Actor-Critic Learning with Lyapunov Certificates for Exponentially Stabilizing Control
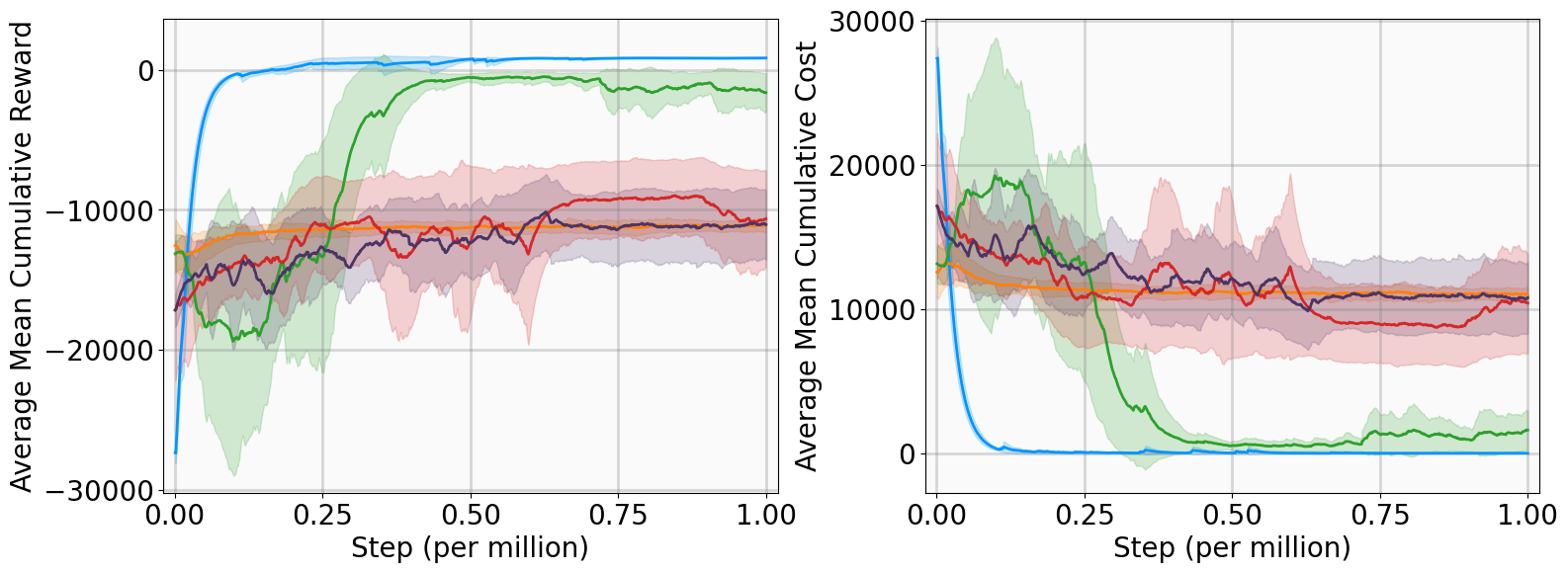
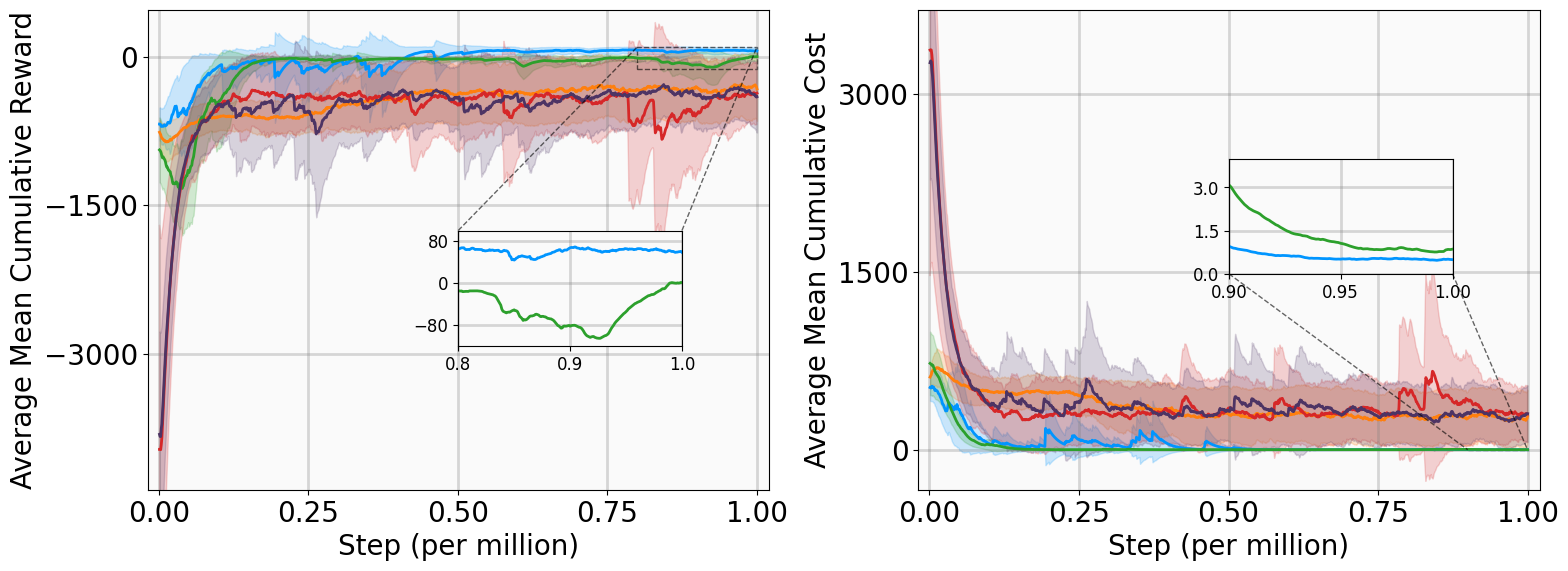
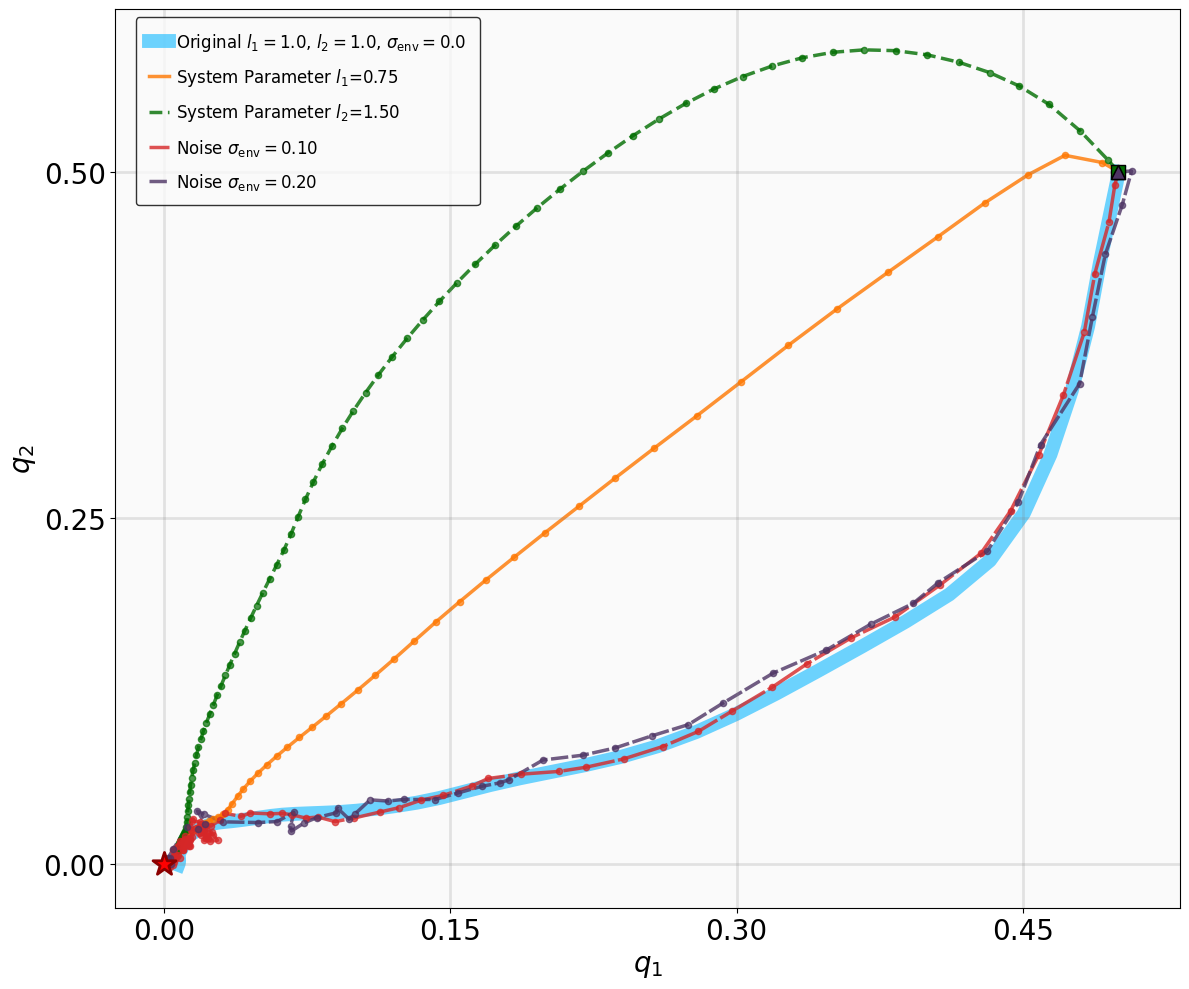
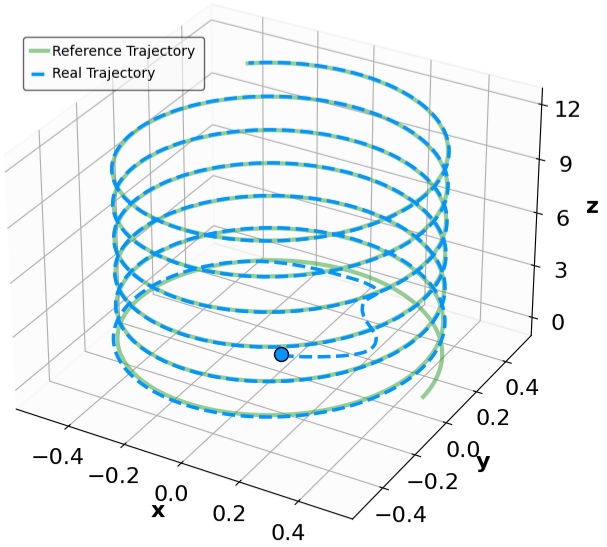
모델이 없는 강화학습(RL)에서 증명 가능한 안정성을 달성하는 것은 여전히 도전적인 과제이며, 특히 탐험과 엄격한 안전 사이의 균형을 맞추는 것이 어렵습니다. 본 논문은 지수안정성 이론과 최대엔트로피 RL을 다단계 라이아푸노프 증명서 학습을 통해 통합하는 MSACL 프레임워크를 소개합니다. 복잡한 보상 공학에 의존하는 방법들과는 달리, MSACL은 오프-폴시 다단계 데이터를 활용하여 이론적 안정성 조건을 만족시키는 라이아푸노프 증명서를 학습합니다. 지수안정성 레이블(ESL)과 $λ$ 가중치 집합 메커니즘을 도입함으로써, 프레임워크는 다단계 학습에서 편차와 분산의 균형을 효과적으로 조절합니다. 안정성을 고려한 이점 함수를 통해 정책 최적화가 유도되며, 이를 통해 학습된 정책이 빠른 라이아푸노프 감소를 촉진하도록 합니다. MSACL은 안정화 및 비선형 추적 작업을 포함한 여섯 가지 벤치마크에서 평가되었으며, 최신의 라이아푸노프 기반 RL 알고리즘보다 우수함을 입증하였습니다. MSACL은 간단한 보상하에서도 지수안정성과 빠른 수렴성을 달성하며, 불확실성에 대한 강건성과 미지의 궤도에서의 일반화를 나타냅니다. 민감도 분석을 통해 다양한 시스템에서 다단계 휴리존 $n=20$이 견고한 기본값으로 설정되었습니다. 라이아푸노프 이론과 오프-폴시 액터-크리틱 프레임워크를 연결함으로써, MSACL은 검증 가능한 안전 학습 기반 제어의 기반이 됩니다. 소스 코드와 벤치마크 환경은 공개될 예정입니다.
1. **지수 안정성 보장 via 다단계 학습:** MSACL 프레임워크를 도입하여, 지수 안정성을 가진 리아폰트 증명학습을 수행합니다. 이를 통해 시스템 상태가 균형점으로 지수적으로 수렴하도록 강제하여, 기존의 점근적 수렴 방법보다 더 강력한 성능 보장을 제공합니다.
2. **효율적인 오프-폴리시 프레임워크:** 최대 엔트로피 RL 패러다임 내에서 개발된 우리의 프레임워크는 효율적인 오프-폴리시 학습을 가능하게 합니다. 트래젝토리별 중요도 샘플링을 통해 데이터 분포 변화를 보정하여, 기존의 온-폴리시 리아폰트 기반 RL 알고리즘보다 표본 복잡성을 크게 줄입니다.
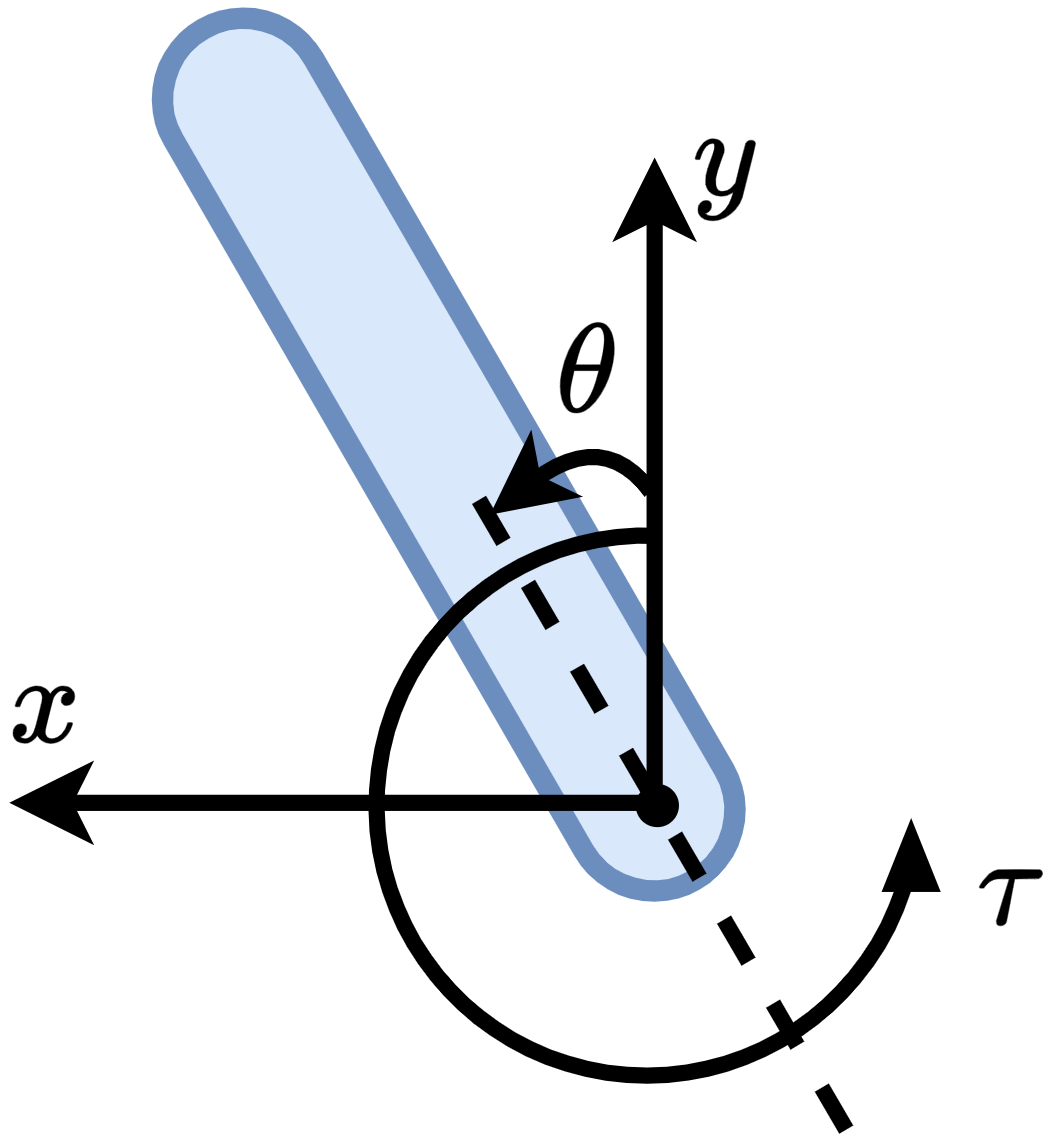
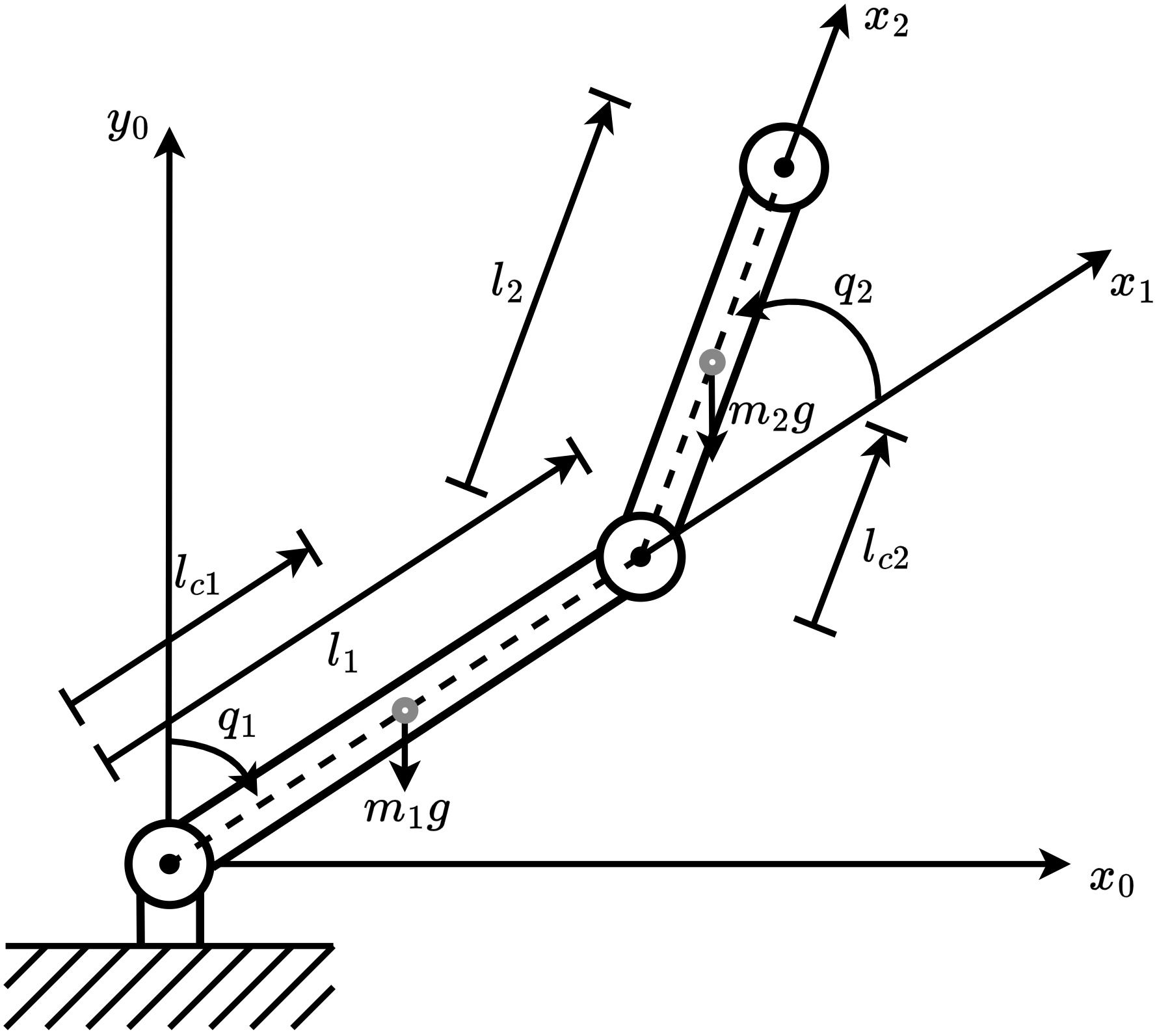
3. **강력한 벤치마크 시스템:** 다양한 6개의 비선형 동적 환경을 개발해 안정성 증명기반 RL 알고리즘을 철저히 평가하고 표준화합니다.
모델-프리 제어, 지수 안정성, 리아폰트 증명,
다단계 데이터 수집 및 활용, 오프-폴리시 RL, 최대 엔트로피 RL.
서론
심층학습(Deep Learning)은 복잡하고 비선형적인 동적 시스템을 통제하는 데 강력한 패러다임으로 부상하였으며, 분석 모델이 필요하지 않습니다. 그럼에도 불구하고 고차원 작업에서의 경험적 성공에도 불구하고 안전성이 중요한 응용 분야에 대한 강화학습(Reinforcement Learning)의 광범위한 배포는 공식적인 신뢰성 보장의 부재로 제약을 받고 있습니다. 이러한 영역에서는 안정성이 단순히 바람직한 지표가 아니라 필수 조건입니다; 시스템이 안전한 운영 범위 내에 유지되지 않으면 재앙적 결과를 초래할 수 있습니다. 제약된 마코프 의사결정 과정(constrained Markov Decision Processes, cMDPs) 및 해밀턴-야코비 도달성 분석(Hamilton-Jacobi reachability analysis)과 같은 접근법은 부분적인 해결책을 제공하지만 증명 기반 방법은 학습 에이전트를 검증하기 위한 골드 표준으로 자리잡았습니다. 이들은 엄격한 제어 이론 도구, 특히 점근적 안정성을 위해 리아폰트 함수(Lyapunov functions)와 집합 불변성을 위해 제어 장벽 함수(control barrier functions, CBFs)를 활용하여, 시스템이 균형점으로 수렴하거나 엄격하게 안전한 경계 내에 머무는 것을 보장하는 데이터 기반 증명을 제공합니다.
안정성 및 안전성 증명의 합성은 분석적 방법에서 신경망 기반 접근법으로 패러다임이 전환되었습니다. 2018년 경, 신경증명(neural certificates)에 대한 초기 연구는 검증 가능한 제어와 블랙박스 학습 간의 연결을 이루는 전환점을 형성하였습니다. Berkenkamp 등은 가우시안 프로세스를 사용하여 안전한 탐색을 위한 리아폰트 함수를 학습하였으며, Richards 등과 Chow 등은 수렴 영역을 추정하기 위한 이론적 틀을 개발하였습니다. 이러한 연구들은 비선형 시스템의 안정성 및 안전성을 분석하는 엄격한 수학적 기초를 제공합니다.
최대 엔트로피 강화학습(Maximum Entropy Reinforcement Learning, MERL) 프레임워크 위에 우리의 접근법을 구축하였습니다. Soft Actor-Critic (SAC) 및 DSAC와 같은 알고리즘은 예상 수익뿐만 아니라 정책의 엔트로피를 최대화합니다. 이러한 엔트로피 정규화는 강건한 탐색을 장려하고, 미리 결정된 부적절한 행동으로 빠르게 수렴하는 것을 방지합니다. 표본 효율성과 강인함 측면에서 최대 엔트로피 프레임워크는 고급 안정성을 고려한 제어 알고리즘 개발에 이상적인 기반이 됩니다.
그러나 DDPG, TRPO, PPO, TD3, D4PG, SAC, DSAC와 같은 표준 모델-프리 RL 알고리즘은 안정화 또는 추적 작업에 적용될 때 중요한 제한 사항이 있습니다. 첫째, 이들은 내재적인 안정성 보장이 없습니다; 이러한 방법을 통해 학습된 정책은 단순히 스칼라 보상 최대화를 최적화하므로, 안정성은 본질적으로 우발적인 부산물입니다. 둘째, 이 알고리즘의 효율성은 완전한 보상 공학에 크게 의존하며, 사용자는 상태 편차, 제어 노력 및 보조 항목에 대한 계수를 조정하여 안정적인 행동을 유발해야 합니다. 우리의 프레임워크 MSACL은 이러한 한계점을 해결합니다.
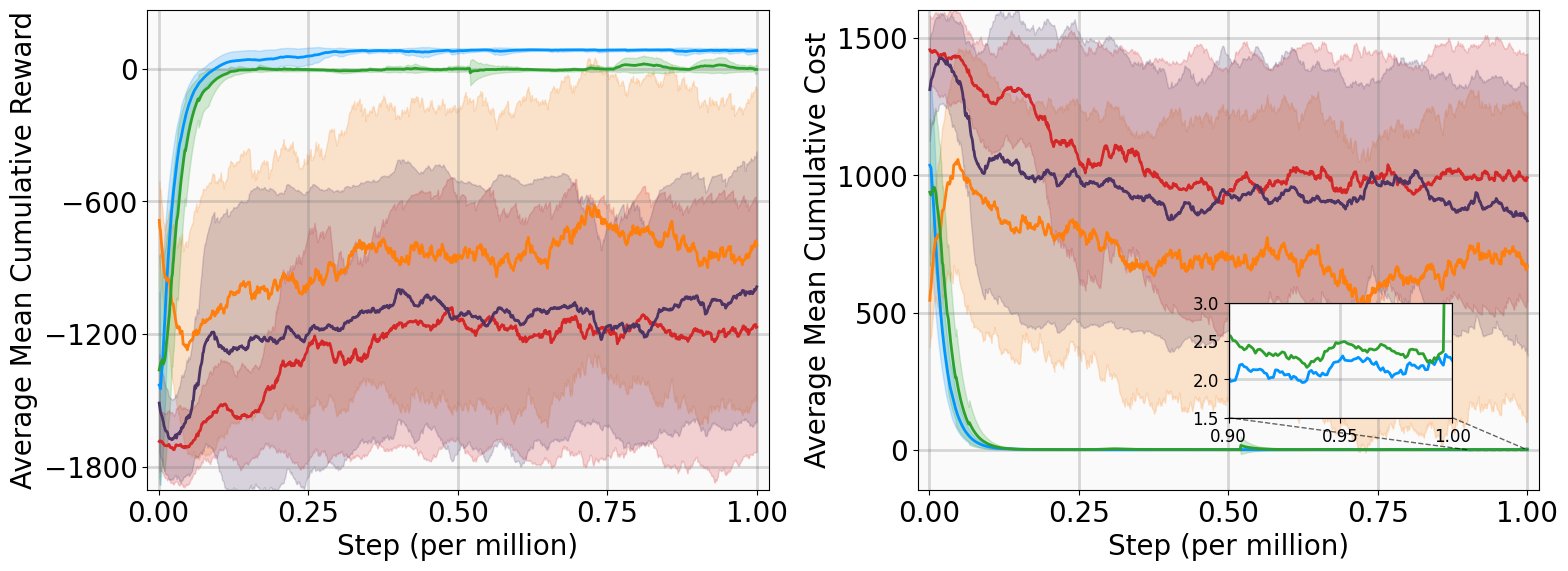
리아폰트 기반 RL 알고리즘은 위의 두 가지 문제를 완화하기 위해 제안되었습니다. 그러나 존재하는 방법은 각각 고유한 단점이 있습니다. POLYC 알고리즘은 이론적 보장을 제공하지만 온-폴리시 학습에 의존하여 물리 시스템에서 표본 복잡성을 크게 증가시킵니다. 반면, LAC 알고리는 오프-폴리시 접근법을 도입하지만 기본적으로 목표를 왜곡합니다; 이는 안정성 위험을 최소화하려고 하므로, 종종 제어 노력이 과도하게 증가하는 공격적인 컨트롤러를 생성합니다. 또한 POLYC와 LAC는 일반적으로 점근적 안정성만 보장하여 수렴률에 대한 강한 보장을 제공하지 않습니다.
MSACL은 오프-폴리시 프레임워크 위에 구축되어 과거 에이전트-환경 상호작용 데이터를 활용해 데이터 효율성을 크게 향상시킵니다. LAC와 달리 MSACL는 상태 규제 및 제어 노력과 함께 지수 안정성 조건을 강제하는 포괄적인 목표를 최적화합니다.
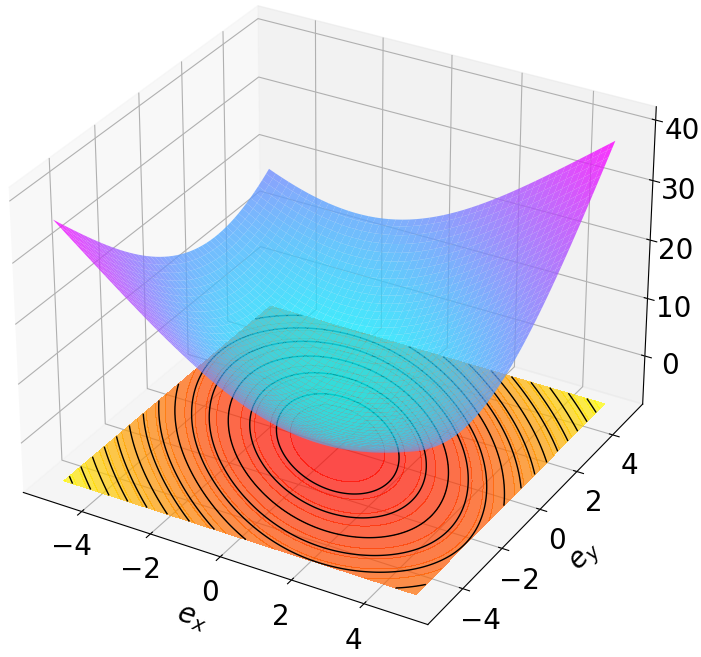
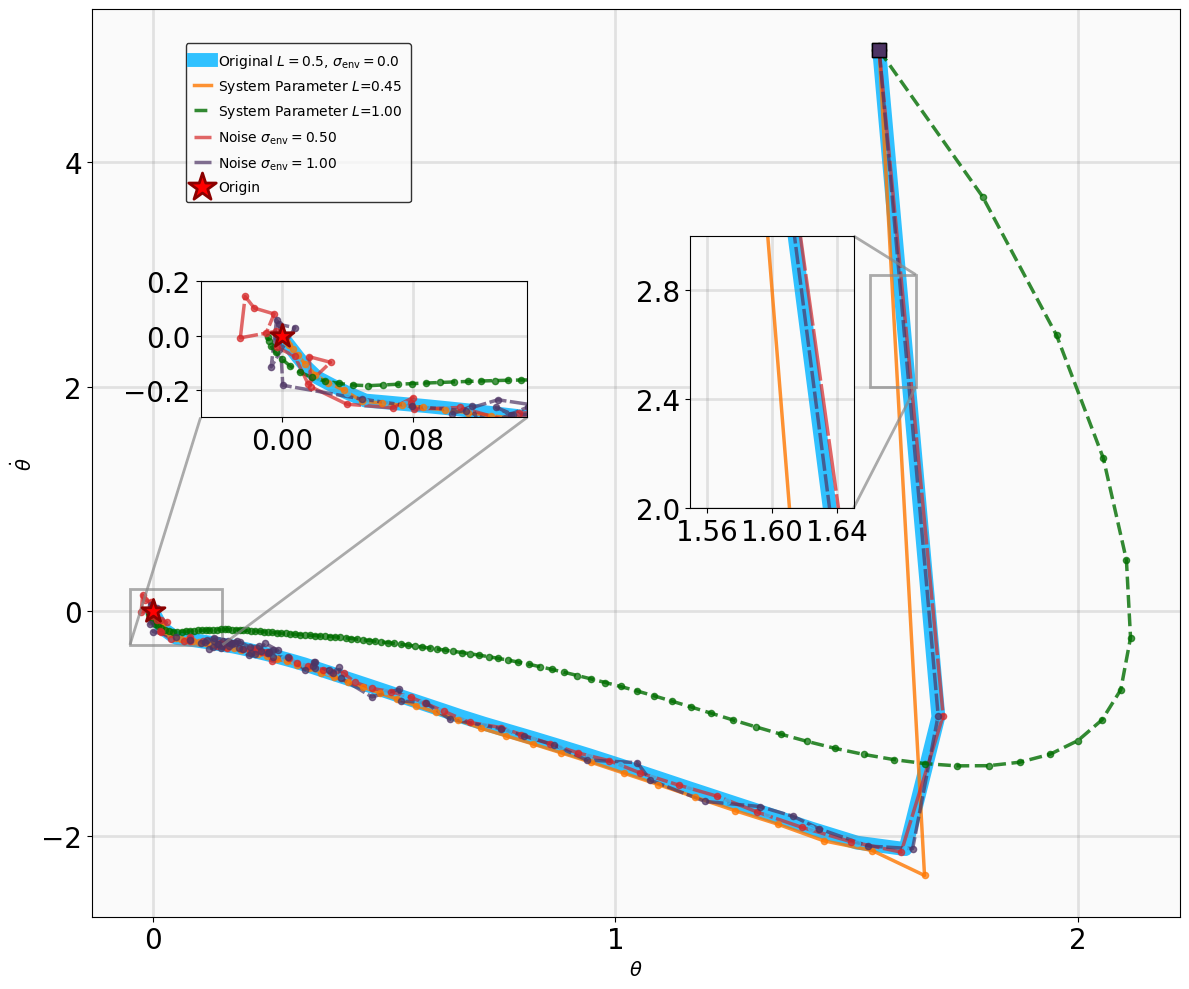
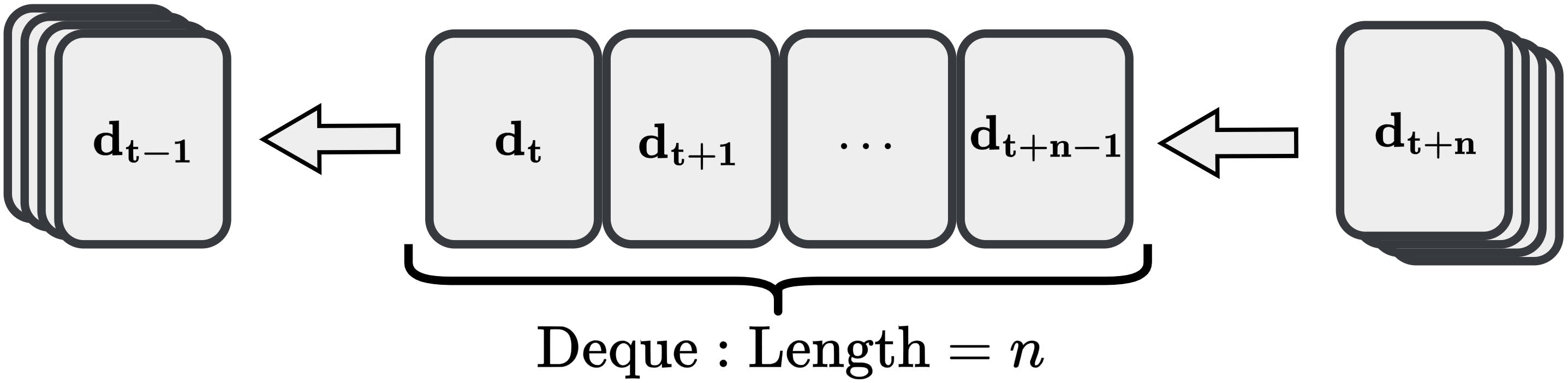
다른 중요한 혁신은 다단계 데이터 활용입니다. 기존 RL 및 리아폰트 기반 방법은 일반적으로 학습 제약 조건을 단일 단계 전이에 의존하므로, 특히 현지 노이즈가 있는 경우 연속 시간 리야푸노프 함수의 Lie 미분근사에서 크게 오류를 발생시킵니다. 이를 완화하고 장기 동적 사항을 포착하기 위해 다단계 학습 메커니즘을 도입합니다.
결론적으로, 이 논문은 모델-프리 지수 안정 제어를 위한 종합적인 강화학습 프레임워크를 제시합니다. 주요 기여는 다음과 같습니다:
- 지수 안정성 보장 via 다단계 학습: MSACL 프레임워크를 도입하여, 리아폰트 증명학습에 지수 안정성을 통합합니다.
- 효율적인 오프-폴리시 프레임워크: 최대 엔트로피 RL 패러다임 내에서 개발된 우리의 프레임워크는 효율적인 오프-폴리시 학습을 가능하게 합니다.
- 강력한 벤치마크 시스템: 다양한 6개의 비선형 동적 환경을 개발해 안정성 증명기반 RL 알고리즘을 철저히 평가하고 표준화합니다.