- Title: AMAP Agentic Planning Technical Report
- ArXiv ID: 2512.24957
- 발행일: 2025-12-31
- 저자: AMAP AI Agent Team, Yulan Hu, Xiangwen Zhang, Sheng Ouyang, Hao Yi, Lu Xu, Qinglin Lang, Lide Tan, Xiang Cheng, Tianchen Ye, Zhicong Li, Ge Chen, Wenjin Yang, Zheng Pan, Shaopan Xiong, Siran Yang, Ju Huang, Yan Zhang, Jiamang Wang, Yong Liu, Yinfeng Huang, Ning Wang, Tucheng Lin, Xin Li, Ning Guo
📝 초록
최근 대형 언어 모델(LLMs)은 도구 호출을 통합하여 복잡한 작업 추론 능력을 향상시켰습니다. 이 논문에서는 실시간 공간-시간 상황에서의 추론 작업에 초점을 맞춘 STAgent를 제안합니다. STAgent는 강화학습, 고급 데이터 구성 및 계층적 학습 방법을 통합한 종합적인 파이프라인을 구현하여 복잡한 현실 세계 문제 해결 능력을 향상시킵니다.
💡 논문 해설
1. **새로운 모델의 도입**: STAgent는 기존 모델보다 더 높은 성능을 제공하는 새로운 종류의 언어 모델입니다. 이를 이해하기 쉽게 설명하자면, 이전 모델들은 단순한 계산이나 코드 작성에 강점을 가졌다면, STAgent는 여행 계획이나 날씨 예측과 같은 복잡한 공간-시간 추론 작업에 특화되어 있습니다.
2. **데이터 선택 프레임워크**: STAgent는 대량의 무구조 데이터에서 높은 품질의 학습 데이터를 선택하는 새로운 방법을 도입했습니다. 이는 마치 쓰레기 더미에서 값진 보석을 찾는 것과 비슷합니다.
3. **계층적 학습 방법**: STAgent는 문제의 난이도에 따라 학습을 계단식으로 진행하는 방식을 사용하여 모델의 일반화 능력을 향상시킵니다. 이 방식은 신입사원부터 경력자까지 다양한 수준의 직원에게 맞춤형 교육을 제공하는 것과 유사합니다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사 aketitle
서론
지난 해는 도구 호출을 통합한 대형 언어 모델(LLMs)의 발전이 있었으며, 이는 일반 지능의 경계를 크게 확장시켰습니다. 도구 통합 추론(TIR)은 LLMs에게 도구 환경과 상호작용할 수 있는 능력을 부여하고, 도구로부터 받은 피드백을 바탕으로 다음 단계를 결정할 수 있게 합니다. 중요한 점은 현재 TIR 노력이 주로 수학적 추론이나 코드 테스트와 같은 시나리오에 집중되고 있으며, 실제 세계의 실용적인 설정에 대한 해결책은 여전히 부족하다는 것입니다.
style="width:98.0%" />
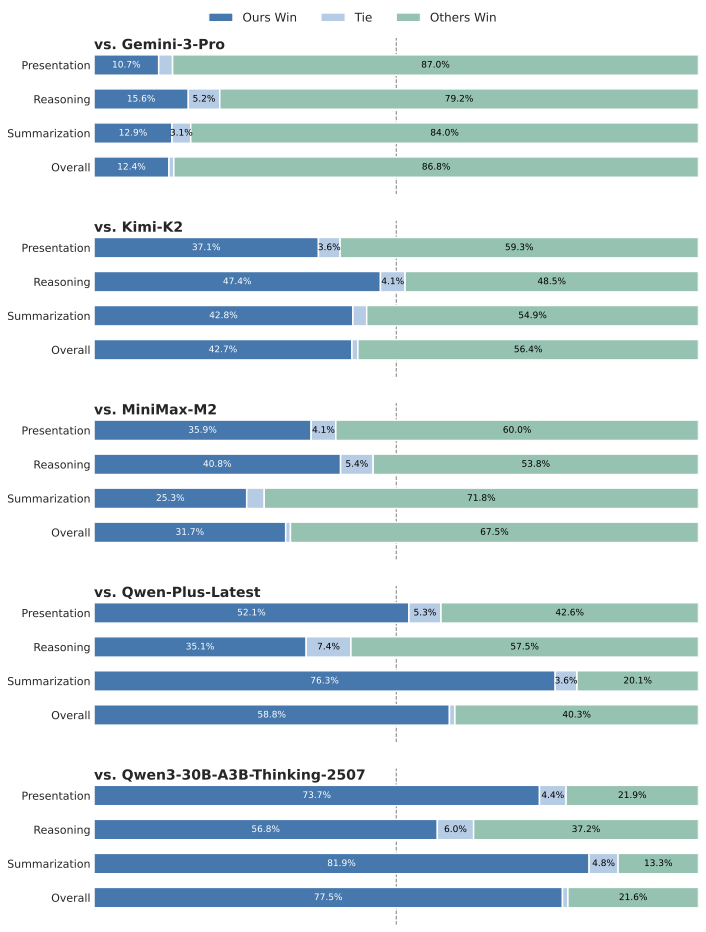
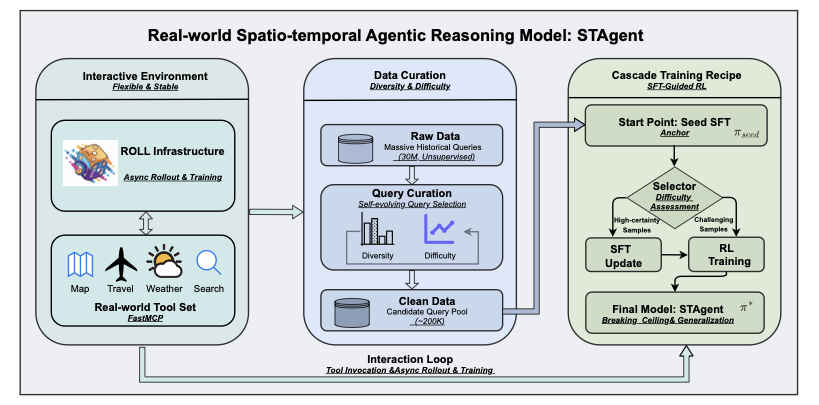
STAgent의 전체 프레임워크를 보여줍니다. 이 프레임워크는 실제 세계의 공간-시간 추론을 위한 포괄적인 파이프라인을 설계합니다. 프레임워크는 세 가지 핵심 단계로 구성됩니다: (1) **강력한 상호작용 환경**, ROLL 인프라와 FastMCP 프로토콜을 통해 효율적이고 비동기적인 도구 통합 추론이 가능합니다. (2) **고품질 데이터 구축**은 다양한 어려운 쿼리를 필터링하기 위한 자가 진화 선택 프레임워크를 활용합니다; (3) **계단식 학습 방법**, SFT-Guided RL 패러다임을 통해 샘플의 난이도에 따라 지시 학습과 강화학습을 조합합니다.
실제 세계 추론 작업은 인지 비용과 처리 속도를 기준으로 System 1 및 System 2 모드로 분류될 수 있습니다: 전자는 신속하며, 후자는 광범위하고 복잡한 심사가 필요합니다. 공간-시간 시나리오에서의 추론 작업은 대표적인 System 2 시나리오입니다. Figure 2에 표시된 것처럼, 이러한 복잡한 작업에는 위치 식별, 운전 경로 설계 또는 다양한 제약 조건을 고려한 여행 일정 계획 등이 포함되며, 이는 다양한 외부 도구의 조율 없이는 해결할 수 없습니다. 따라서 TIR은 사고 생성과 도구 실행을 교차시키고, 모델이 중간 단계를 검증하고 관찰 피드백에 따라 계획 경로를 동적으로 조정하는 능력을 부여하며 이러한 실제 세계 작업에 대응하는 데 본질적인 이점을 제공합니다.
style="width:100.0%" />
공간-시간 시나리오에서의 일반적인 추론 작업.
그러나 수학이나 프로그래밍과 같은 일반 추론 작업과 달리 이러한 실제 세계 작업은 몇 가지 도전 과제를 내포하고 있습니다. 첫째, 유연하고 안정적인 추론 환경을 어떻게 구성할까요? 한편, 가능한 환경은 대규모 동시 도구 호출 요청을 처리할 수 있는 도구 세트가 필요하며, 이는 오프라인 데이터 커URATION과 온라인 강화 학습(RL)에 의해 발생합니다. 다른 한편으로는, 훈련 중 도구 호출과 경로 롤아웃 간의 효과적인 동기화를 유지하고 모델이 정확한 보상 신호를 받을 수 있도록 하는 것이 이러한 복잡한 작업에서 효과적인 TIR의 기반이 됩니다. 둘째, 어떻게 고품질 훈련 데이터를 수집할까요? 실제 세계 공간-시간 시나리오에서는 사용자가 보내고 데이터베이스에 저장하는 대량의 실제 쿼리가 있지만, 이 데이터는 무구조화되어 있으며 각 쿼리의 범주와 난이도 등 필요한 지식을 부족하게 합니다. 따라서 모델은 최적화 방향을 인지하지 못합니다. 따라서 쿼리 분류를 구축하여 모델 최적화를 위한 고품질 데이터 선택을 용이하게 하는 것이 중요합니다. 셋째, 실제 세계 TIR에 대한 효과적인 학습 방법은 어떻게 수행해야 할까요? 현재의 TIR 노력은 주로 알고리즘과 도구 간의 적응에 중점을 둡니다. 예를 들어, 교차 호출된 도구 호출 엔트로피 변화를 모니터링하여 추가 토큰 롤아웃을 안내하거나 롤아웃 배치 크기를 증가시켜 도구 노이즈를 완화합니다. 그러나 실제 세계 시나리오에서는 불확실한 환경과 다양한 작업이 이러한 방법의 적용에 추가적인 도전 과제를 제공합니다. 따라서 더욱 맞춤형 학습 레시피를 도출하는 것이 TIR 성능 상한을 향상시키는 열쇠입니다.
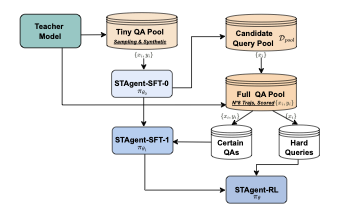
본 연구에서는 실제 세계 공간-시간 추론 작업을 위한 선도적인 에이전트 모델인 STAgent를 제안합니다. 우리는 Figure 1에서 보여주듯이 상호작용 환경, 고품질 데이터 커uration 및 계단식 학습 레시피를 포함하는 포괄적인 파이프라인을 개발했습니다. 구체적으로 STAgent는 세 가지 주요 측면을 특징으로 합니다. 환경과 인프라 측면에서, 우리는 네 가지 범주에 걸쳐 10개의 도메인별 도구를 지원하는 강력한 강화 학습 훈련 환경을 구축했습니다. 이는 지도, 여행, 날씨 및 정보 검색 도구를 포함합니다. 한편으로는 FastMCP[^1]을 사용하여 이러한 도구를 캡슐화하고 매개변수 형식과 호출 프로토콜을 표준화하여 향후 도구 수정이 크게 용이해집니다. 다른 한편으로는 ROLL[^2] 팀과 협력하여 강화 학습 훈련 인프라를 최적화하고 두 가지 핵심 기능인 비동기 롤아웃 및 훈련을 제공합니다. Verl[^3]과 같은 일반적으로 사용되는 오픈 소스 프레임워크에 비해 ROLL은 80%의 훈련 효율성 향상을 제공합니다. 또한 우리는 대량의 역사적 후보에서 고품질 쿼리를 계층적으로 추출하기 위한 세심한 쿼리 선택 프레임워크를 설계했습니다. 쿼리 다양성과 난이도에 초점을 맞추어, 원래 역사 데이터셋 3천만 개에서 약 20만 개의 쿼리를 필터링하는 자가 진화 쿼리 선택 프레임워크를 도출하여 이후 SFT 및 RL 훈련을 위한 후보 쿼리 풀로 활용합니다. 마지막으로, 우리는 계단식 학습 패러다임인 특정 SFT-Guided RL 접근법을 설계하여 모델 능력의 지속적인 개선을 보장했습니다. 종자 SFT 모델을 학습하여 평가기로 사용하고 쿼리 풀의 난이도를 평가하여 이후 SFT 업데이트 및 RL 훈련에 대한 쿼리를 분류합니다. 구체적으로, SFT는 더 확실한 샘플로 세밀화되며, RL은 업데이트된 SFT 모델로부터의 더 어려운 샘플을 대상으로 합니다. 이러한 패러다임은 SFT 모델의 일반화를 크게 향상시키고 RL 모델이 성능 상한을 넘어서는 것을 가능하게 합니다.
최종 모델 STAgent는 Qwen3-30B-A3B-2507 위에 구축되었습니다. 특히, SFT 단계에서 STAgent는 도구 호출 능력을 향상시키기 위해 일반 명령어 팔로잉 데이터를 최소한으로 포함하고 있으며 대부분이 도메인별 데이터로 구성됩니다. 특수화된 모델로서 STAgent는 TravelBench에서 더 큰 파라미터 크기를 가진 모델보다 뚜렷한 우위를 보였습니다. 또한 일반 도메인에 대한 특정 조정 없이도 다양한 일반 도메인 벤치마크에서 개선을 달성하여 강력한 일반화 능력을 입증했습니다.
방법론
개요
본 절에서는 STAgent를 공식적으로 제시하며 세 가지 주요 구성 요소에 초점을 맞춥니다:
도구 환경 구축. 우리는 Section 2.2에서 사용된 도메인 내 도구의 세부 사항을 소개합니다.
고품질 프롬프트 커uration. 우리는 Section 2.3에서 계층적 프롬프트 커uration 파이프라인을 제시하며, 여기에는 프롬프트 분류의 도출, 대규모 프롬프트 주석 및 난이도 측정이 포함됩니다.
계단식 에이전트 후 훈련 레시피. 우리는 Section 2.4, Section 2.5 및 Section 2.6에서 보상 설계, 에이전트 SFT 및 SFT-가이드 RL 훈련에 대한 후 훈련 절차를 제시합니다.
환경 구축
STAgent가 실제 세계 공간-시간 서비스와 통제되고 재현 가능한 방식으로 상호작용할 수 있도록 하기 위해 우리는 FastMCP 위에 고신뢰도 사일드 환경을 개발했습니다. 이 환경은 에이전트의 추론 능력과 기저 공간-시간 API 사이의 다리 역할을 하며, 훈련 및 평가 중 도구 호출을 위한 표준화된 인터페이스를 제공합니다. 대규모 RL 훈련 중 API 지연 시간과 비용을 줄이기 위해 파라미터 정규화와 함께 도구 수준 LRU 캐싱 메커니즘을 구현했습니다.
우리의 도구 라이브러리는 10개의 전문 도구로 구성되어 있으며, 공간-시간 사용자의 전체 범위를 커버하도록 설계된 네 가지 기능 범주에 걸쳐 있습니다. 모든 도구 출력은 구조화된 자연어로 후처리되며 에이전트가 이해할 수 있도록 하고 환영 위험을 줄입니다. 도구 정의 요약은 Table 1에서 확인할 수 있으며, 더 많은 도구 세부 사항은 Appendix [app:tools]를 참조하세요.
Amap 에이전트 사일드 환경의 도구 라이브러리 요약.
카테고리
도구
설명
지도 및 내비게이션
map_search_places
키워드, 위치 또는 지역을 통해 POI 검색
map_compute_routes
여러 교통 수단을 지원하는 경로 계획
map_search_along_route
경로 주변의 POI 찾기
map_search_central_places
여러 출발지에 대한 최적의 회합 장소 탐색
map_search_ranking_list
큐레이션된 순위 목록 검색
여행
travel_search_flights
옵션의 멀티데이 범위를 가진 항공편 검색
travel_search_trains
기차 일정 및 요금 조회
날씨
weather_current_conditions
실시간 날씨와 AQI 확인
weather_forecast_days
멀티데이 예보 조회
정보
web_search
오픈 도메인 웹 검색
프롬프트 커uration
STAgent에게 종합적인 공간-시간 추론 능력을 부여하기 위해 우리는 대규모 실제 사용자 행동에 기반한 고신뢰도 지시 데이터셋을 합성했습니다. 이 데이터셋은 사용자의 전체 필요성을 포괄하며, POI 검색과 같은 원자 쿼리에서 복잡한 일정 계획까지 다양한 제약 조건이 있는 복합 작업을 포함합니다.
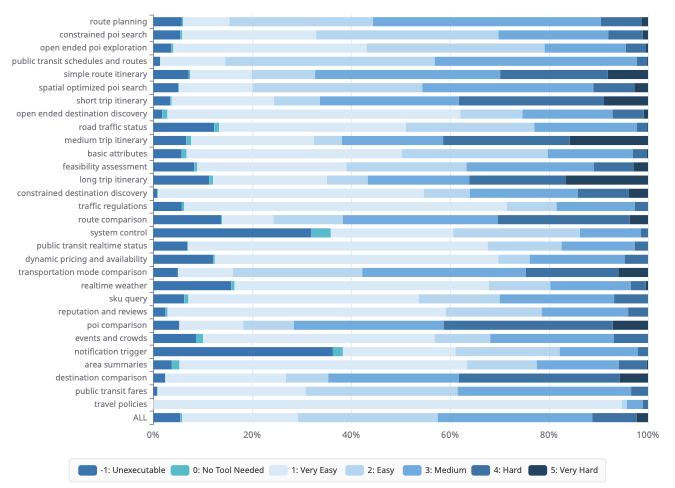
우리는 3개월 기간 동안의 익명화된 온라인 사용자 로그를 주요 데이터 출처로 활용하며, 그 양은 3천만 개입니다. 가장 중요한 과제는 이러한 잡음이 있는 무구조 상호작용을 구조화되고 다양성을 갖춘 지시 데이터셋으로 정리하는 것입니다. 이를 위해 우리는 계층적 의도 분류를 구성했습니다. 이 분류는 정밀한 주석, 수량 분석 및 제어 샘플링 프레임워크로서 역할하여 데이터셋이 작업 유형 다양성(전반적인 의도 커버리지)과 난이도 다양성(기본에서 복잡한 추론까지의 진행)을 최대화합니다.
종자 주도 분류 진화
우리는 완전성 및 직교성을 보장하는 분류를 구성하기 위해 종자 주도 진화 프레임워크를 제안합니다. 정적 분류에 의존하지 않고, 우리의 접근 방식은 고품질의 종자 프롬프트 커널로 시작하여 LLMs의 생성 능력과 엄격한 인간 감독을 협업시키며 도메인 커버리지를 순차적으로 확장합니다. 이 과정은 다음과 같은 단계를 거칩니다:
style="width:100.0%" />
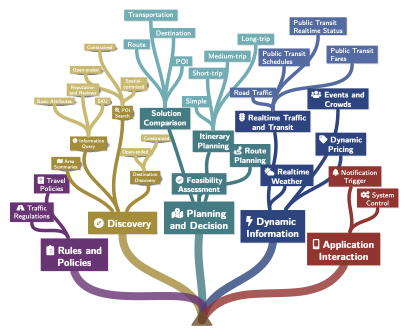
우리 의도 분류 시스템의 가시적 분류입니다. 계층 구조는 규칙 및 정책, 발견, 계획 및 결정, 동적인 정보, 애플리케이션 상호작용이라는 다섯 가지 주요 범주로 구성됩니다. 분류는 16개의 세부 카테고리와 30개의 미세한 잎 노드까지 분기하여 네비게이션과 여행 시나리오에서 실제 사용자 쿼리의 다면적인 복잡성을 포착합니다.
스테이지 1: 종자 초기화. 우리는 도메인의 핵심 다양성을 나타내는 작은, 고분산성 집합 $`n`$ 개의 종자 프롬프트를 수동으로 구축합니다 ($`\mathcal{D}_{seed} \in \mathcal{D}_{pool}`$). 전문가들은 이러한 종자를 오픈 엔드 태그로 주석 처리하여 추상적인 의도 특성을 포착합니다. 각 쿼리는 다음의 튜플로 매핑됩니다:
여기서 $`\mathcal{T}_i`$는 명령문 $`q_i`$에 의해 커버된 $`k`$ 개의 직교 또는 보완적인 의도 노드를 나타냅니다.
스테이지 2: LLM-주도 카테고리 유발. 주석 처리된 종자를 사용하여 LLM은 도메인을 세밀하게 맞춤하기 위한 직교 Level-1 카테고리를 유발합니다.
스테이지 3: 반복적 정제 루프. 환영을 방지하려면 엄격한 확인 업데이트 사이클을 구현합니다. LLM은 생성된 카테고리로 $`\mathcal{D}_{seed}`$를 다시 주석 처리하고; 인간 전문가는 이러한 주석에서 모호성 또는 커버리지 간극을 식별하여 분류 정교화에 대한 피드백을 제공하며, 몇 차례의 반복 “태그-피드백-수정” 사이클을 실행합니다:
이 과정에서 인간 전문가는 LLM 생성 카테고리의 모호성 또는 커버리지 간극을 식별하고 분류 조정에 대한 중요한 통찰력을 제공합니다. $`\mathcal{T}^{(k+1)} \approx \mathcal{T}^{(k)}`$가 되는 시점에 이 과정이 종료되며, 이는 시스템이 수렴한 상태를 나타냅니다.