- Title: DarkEQA Benchmarking Vision-Language Models for Embodied Question Answering in Low-Light Indoor Environments
- ArXiv ID: 2512.24985
- 발행일: 2025-12-31
- 저자: Yohan Park, Hyunwoo Ha, Wonjun Jo, Tae-Hyun Oh
📝 초록
본 논문에서는 실내 어두운 환경에서의 대답 능력을 평가하기 위한 새로운 벤치마크인 DarkEQA를 제시한다. 이는 저조도 조건 하에서 시각-언어 모델(VLM)의 성능을 정확하게 측정하도록 설계되었다.
💡 논문 해설
1. **새로운 벤치마크 소개**: 본 논문은 실내 어두운 환경에서 작동하는 로봇들의 대답 능력을 평가하기 위한 새로운 벤치마크인 DarkEQA를 제시한다. 이는 저조도 조건 하에서의 시각-언어 모델(VLM) 성능을 정확하게 측정하도록 설계되었다.
- **비유**: 어두운 방에서 물체를 찾는 것이 어렵듯이, 로봇에게도 어두운 환경에서는 정보 인식이 어렵다. DarkEQA는 이러한 어려움을 평가하기 위한 도구이다.
데이터 생성 방법: 저조도 이미지를 합성하여 데이터셋을 만드는 방법을 제시한다. 이는 실제 저조도 이미지 수집의 어려움을 해결하는 데 도움이 된다.
비유: 실제로 어두운 방에서 사진을 찍는 대신, 컴퓨터가 이를 가상으로 만들어내는 것과 같다.
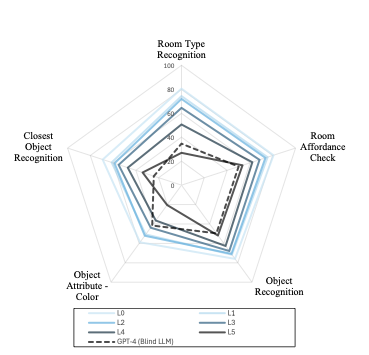
평가 결과 분석: 저조도 조건에서의 VLM 성능을 평가한 결과를 제시하며, 이는 현재 모델들이 저조도 환경에서 얼마나 견고하게 작동하는지 보여준다.
비유: 어두운 방에서 로봇이 물체를 인식하고 대답하는 능력을 측정하여, 그 성능을 개선할 수 있는 방법을 찾는 것이다.
📄 논문 발췌 (ArXiv Source)
# 서론
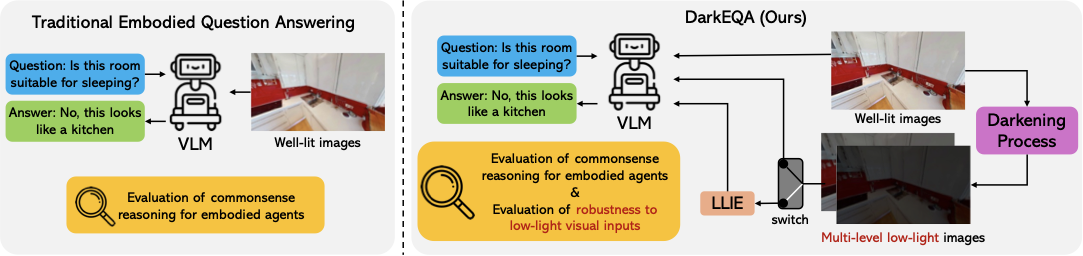
시각-언어 모델(VLMs)의 발전은 로봇 능력을 크게 향상시켰으며, 의미적 장면 이해, 공간 추론 및 시각-언어-행동(VLA) 정책을 개선했습니다. 여러 몸체 기반 질문 대답(EQA) 벤치마크가 이러한 상황 판단 능력을 평가하기 위해 제안되었지만, 대부분 잘 비춰진 이상적인 시각 조건을 가정하고 있습니다. 그러나 가정용 로봇은 24/7 운영이 목표이며, 따라서 밤에나 어두운 방이나 정전 등 저조도 상황을 자주 맞닥뜨릴 것입니다. 다양한 환경에서의 로봇 배치가 증가함에 따라 이러한 조건 하에서의 견고한 인식은 더 이상 간과할 수 없는 핵심적인 필요성입니다. 따라서, 저조도 조건 하에서 몸체 기반 VLM 추론을 스트레스 테스트하는 벤치마크는 실제 세계의 견고성을 측정하기 위해 필수적입니다. 그러나 대규모의 실제 세계 저조도 이미지와 깨끗한 짝 지어진 주석을 획득하는 것은 어렵고 비싸며, 이러한 벤치마크를 구성하는 것을 방해했습니다. 결과적으로, 기존 벤치마크는 침체된 조명 하에서의 VLM 기반 추론과 인식에 대한 체계적인 평가를 크게 간과하여 실제 세계 견고성을 예측할 능력을 제한하고 있습니다.
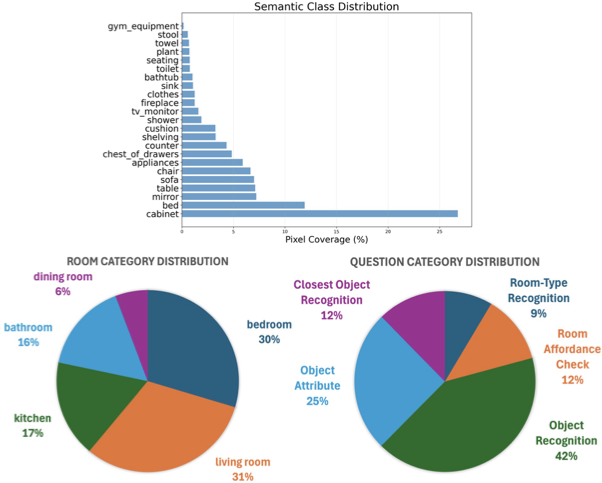
이 평가 공백을 채우기 위해 우리는 DarkEQA라는 오픈 소스 벤치마크를 제시합니다. 이는 저조도 조건 하에서 몸체 작업의 인식 원칙을 체계적으로 측정하기 위한 것입니다. DarkEQA의 설계는 주로 물리적 기반 형식에 기초하고 있으며, 모든 시각 침해는 레이(RAW) 센서 데이터 수준(또는 선형 RGB 공간)에서 모델링됩니다. 이는 조명과 센서 노이즈의 물리학을 따르며 실제 세계의 이미지 신호 처리(ISP) 상황을 현실적으로 시뮬레이션합니다. 또한 벤치마크의 정확성을 보장하고 잠재적인 데이터 오염을 방지하기 위해 모든 질문-답변(QA) 쌍은 규칙 기반 절차를 통해 결정론적으로 생성됩니다. QA 생성은 간단한 물체 인식(“이미지에 쿠션은 있나요?")에서부터 행동 가능성 추론(“자는 것이 원하는데, 이 방은 적합하겠습니까?")까지 인식 원칙을 목표로 하는 질의 패밀리를 생성합니다.
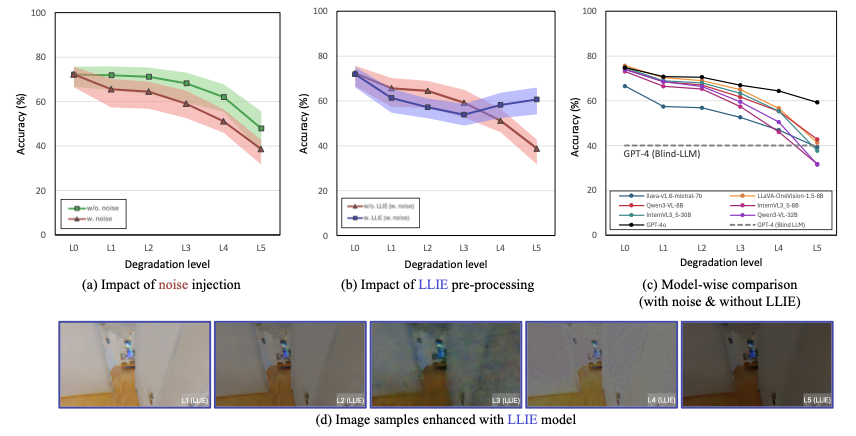
DarkEQA는 9.4k 질문-이미지 쌍을 제공하며, 표준 평가 프로토콜과 저조도 침해 파이프라인을 재현하기 위한 공개 코드베이스를 제공합니다. 우리의 DarkEQA는 다양한 시각-언어 모델(VLMs)을 벤치마킹하며, 오픈 및 클로즈 소스 시스템 모두 포함합니다. 또한 최신 저조도 이미지 향상(LLIE) 모델을 사전 처리 기준선으로 평가합니다. 우리의 평가는 두 가지 관찰을 제공합니다. 첫째, 인간은 입력 이미지의 구조적 장면 정보를 명암 대비에서 인식할 수 있지만 모든 시험 VLM들은 이미지가 침해될수록 성능이 분명히 하락합니다. 둘째, LLIE 사전 처리는 특정 침해 수준에서는 성능을 향상시키지만 그 효과는 항상 긍정적이지는 않으며 때로는 제한적인 이익만 제공하거나 오히려 성능 저하를 초래할 수도 있어 실제 한계를 강조합니다. 함께 이러한 결과는 현재 VLM 기반 EQA 파이프라인이 저조도 오염 하에서 여전히 취약함을 보여주며, 인식 향상만으로는 일반적인 해결책으로 부족하다는 것을 보여주어 견고성 중심 평가 및 방법 개발을 촉구합니다.
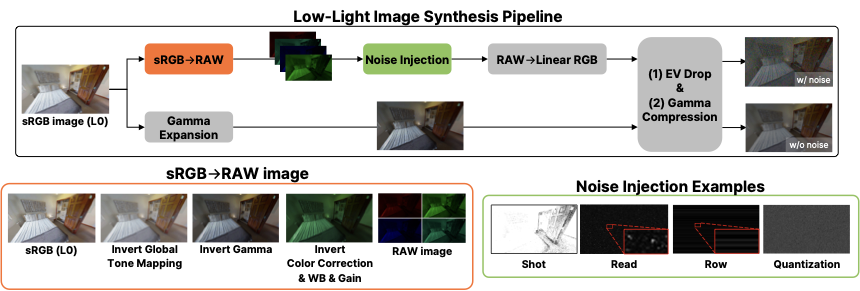
조명과 노이즈 요인을 분리한 저조도 합성 파이프라인.
우리의 벤치마크를 위한 제어된 저조도 입력을 생성하기 위해, 이전 연구에서 사용한 ISP에 영감받은 언프로세싱 및 노이즈 형식을 채택합니다.
중요하게, 각 원본 이미지에 대해 paired 변형체를 생성하여 VLM 기반 EQA의 실패 원인을 분리합니다: (a) sRGB에서 Bayer RAW로 언프로세싱하는 물리학적 브랜치(상단), 그리고 RAW에서 네 가지 노이즈 요소를 주입하고 EV 드롭 및 감마 압축을 적용하며, (b)噪光