- Title: Classifying long legal documents using short random chunks
- ArXiv ID: 2512.24997
- 발행일: 2025-12-31
- 저자: Luis Adrián Cabrera-Diego
📝 초록
법적 문서 분류는 전문 용어뿐만 아니라 때때로 매우 긴 문서가 될 수 있어挑战组合中的中文被错误地包含进去了。以下是符合要求的日韩翻译:
법적 문서를 분류하는 것은 전문적인 어휘 외에도 종종 매우 긴 문서라는 점에서 과제입니다. 이는 전체 문서를 변형 모델 기반의 분류 모델에 입력하는 것이 불가능하거나 비용이 많이 들거나 느릴 수 있다는 것을 의미합니다. 따라서 본 논문에서는 48개의 임의로 선택된 짧은 조각(max 128 토큰)을 입력으로 사용하는 DeBERTa V3와 LSTM을 기반으로 한 법적 문서 분류기를 제시합니다. 또한 지속 가능한 실행 솔루션인 Temporal을 사용한 배포 파이프라인도 제시하여 신뢰성 있고 견고한 처리 워크플로를 확보할 수 있습니다. 최상의 모델은 가중치 F 점수 0.898을 기록했으며, CPU에서 작동하는 파이프라인의 처리 중앙값 시간은 100개 파일당 498초였습니다.
💡 논문 해설
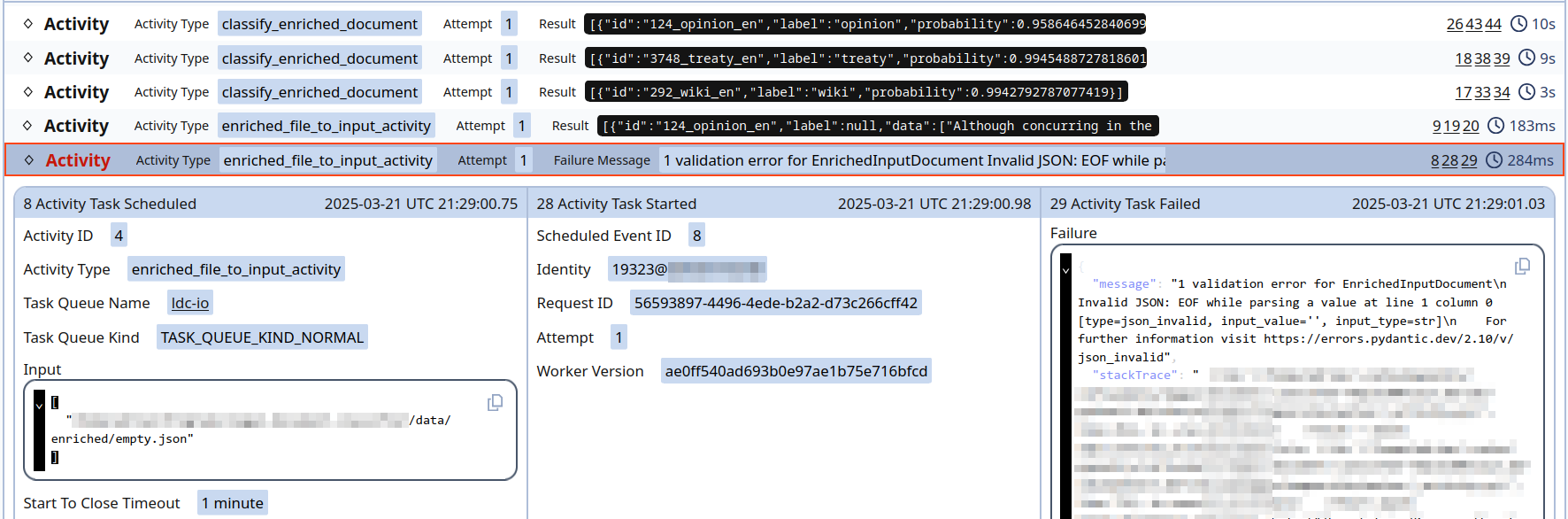
1. **효과적인 긴 법률 문서 분류:** 본 논문은 긴 법률 문서를 효과적으로 분류하는 방법을 제시합니다. 이는 마치 큰 책을 여러 조각으로 나눠서 이해하는 것과 같습니다.
2. **실제 운영 환경에서의 경제성:** 비용 효율적인 모델로 개발되어, 실제 운영 시스템에서도 사용할 수 있습니다. 이는 고가의 장비 없이도 복잡한 법률 문서를 처리하는 것을 가능하게 합니다.
3. **단순화된 아키텍처:** 복잡한 모델 대신 간단하면서도 효과적인 아키텍처를 사용하여 유지 관리와 재학습을 용이하게 했습니다. 이는 건물 설계에서 복잡한 구조 대신 단순하고 견고한 설계를 선택하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 소개
법률 AI는 인공지능 기술을 사용하여 법률 전문가들이 무거운 반복적인 작업들을 돕습니다. 그리고, Legal AI는 새로운 것이 아니지만, 법적 문서를 처리하는 것은 여전히 어렵습니다.
주요 과제는 법률 문서가 다양하다는 것입니다. 이들 문서는 길이뿐만 아니라 어휘, 구조, 주관성 및 범위에서도 다릅니다. 후자 두 특징은 전문 코퍼스를 사용하여 훈련된 도구로 부분적으로 최소화할 수 있지만, 첫 번째 특징인 길이는 그렇지 않습니다. 예를 들어, 문서가 길수록 실제로 관련이 있는 컨텍스트를 유지하기 어렵습니다. 또한 변환 기반 기술을 사용할 때, BERT와 같은 경우, 입력이 길어질수록 메모리 소비량이 폭발합니다. 그리고 이제는 *Large Language Models (LLM)*인 GPT[^1]과 같이 수천 개의 토큰을 처리할 수 있지만, 그 사용은 비용이 많이 들거나 위험성이 있을 수 있습니다.
따라서, 본 논문에서는 긴 법률 문서를 처리할 수 있는 분류기를 제시합니다. 이를 위해 내부 CPU 서버에 배포될 수 있도록 DeBERTA V3와 LSTM을 사용하여 문서 분류기를 만듭니다. 이 분류기는 48개의 무작위로 선택된 짧은 조각 (최대 크기: 128 토큰)을 사용합니다. 또한, 우리는 Temporal[^2]을 사용해 지속 가능한 워크플로를 생성하고 분류기 배포에 집중하도록 합니다.
제안된 모델은 다양한 길이의 다언어 수집 문서로 훈련 및 테스트되었으며 18개 클래스를 커버합니다. 이 분류기는 가중 중간 F 점수는 0.898이고, Temporal을 사용하여 파일 처리 시간은 평균적으로 100개의 파일당 498초입니다.
관련 연구
다수의 긴 문서 분류에 관한 연구들은 문서를 나누는 방식을 기반으로 합니다. 예를 들어, 긴 문서를 200 토큰짜리 작은 조각으로 나누고 이를 BERT 모델로 처리한 뒤 LSTM 또는 변환 계층으로 전파합니다. CogLXT은 단순히 키 문장을 입력으로 사용하는 분류기입니다; 이들 키 문장은 판결을 학습한 모델을 통해 얻어집니다. 또한, TextRank을 사용해 중요한 문장이나 무작위로 선택된 문장을 첫 512 토큰과 결합하는 두 가지 기준선을 제시했습니다.
다른 연구들은 변환기 기반 모델의 입력 크기를 늘리는 방법을 탐색했습니다. Longformer은 창구형 로컬 컨텍스트 자기 주의와 전역 주의를 사용해 최대 4,096 토큰을 처리할 수 있는 모델입니다. 그러나 이러한 종류의 모델들은 큰 메모리 소비량과 긴 처리 시간 문제에 직면하게 됩니다.
법률 도메인에서 다음 연구들을 강조할 수 있습니다. Doc2Vec 임베딩을 학습하고 이를 BiGRU와 Label-Wise Attention Network로 전달하는 방법, 비슷한 방식으로 Doc2Vec 임베딩을 학습하지만 이를 BiLSTM과 조각 주의 계층으로 전달하는 방법 등이 있습니다.
LegalDB 및 Lawformer은 각각 DistillBERT와 중국어 RoBERTa 모델을 Longformer 모델로 변환했습니다. 이들 모델은 법률 코퍼스를 사용하여 사전 훈련되었습니다. 비슷하게, LegalBERT를 법적 계층형 BERT 및 최대 8,192 토큰을 처리할 수 있는 법적 Longformer 모델로 변환했습니다.
D2GCFL은 법률 문서 분류기로서 관계를 추출하고 네 가지 그래프로 표현합니다. 이들 그래프는 그래프 주의 네트워크에 전달됩니다. 또한, 법률 계약을 더 작은 조각으로 나누고 이를 로지스틱 회귀 모델로 필터링한 다음 이를 세밀하게 튜닝된 RoBERTa에 전달합니다.
법률 문서를 분류하기 위해 프롬프트 체이닝을 사용합니다. 저자는 반복적으로 더 작은 조각들의 요약을 생성하여 법률 문서를 요약하고, 이러한 요약은 몇 가지 샷 프롬프트와 함께 LLM에 전송됩니다. 이 프롬프트는 요약 접근 방식으로 생성된 예제가 포함되어 있습니다.
연구 범위
이 작업은 Jus Mundi[^3], 법률 기술 회사에서 개발하고 사용한 도구를 제시합니다. Jus Mundi는 내부 필요성을 해결하기 위해 법률 문서 분류기를 만들고자 했습니다. 이 분류기는 다음과 같은 특징을 가집니다:
개인 정보 보호: 많은 LLM들이 서비스에 제공된 데이터를 향후 모델 학습에 사용하여, 법률 도메인에서는 개인 정보 위험이 있을 수 있습니다.
빠르기: 이 분류기는 실시간 도구에서 사용되어야 하므로 속도는 필수적인 요소입니다.
간편함: 간단한 모델은 유지 관리 및 재학습이 더 쉽습니다. 즉, 복잡한 아키텍처에서는 여러 모델이 필요하기 때문에 CogLXT과 같은 모델들은 기술적 부채가 커서 유지 관리가 어렵습니다.
비용 효율성: 일부 문헌에서 찾을 수 있는 모델은 큰 GPU와 많은 VRAM이 필요한 비싼 하드웨어를 요구하며, 장기적으로 운영 환경에서는 너무 비싸게 작동할 수 있습니다. 따라서 CPU 또는 작은 GPU로 추론 작업을 수행할 수 있는 솔루션을 만드는 것이 중요합니다.
이 목적을 달성하기 위해 우리는 다음과 같은 가설을 탐색했습니다: 긴 법률 문서를 작은 무작위로 선택된 텍스트 조각으로 분류하는 것이 가능하다. 이 가설은 이전 연구 결과와 관찰에 기반하고 있습니다. 예를 들어, 전체 문서를 전달하지 않고도 정확하게 분류할 수 있다는 것을 확인했습니다. 또한, 복잡한 모델보다 무작위로 선택된 문장들이 경우에 따라 더 나은 성능을 보일 수 있음을 발견했습니다.
방법론
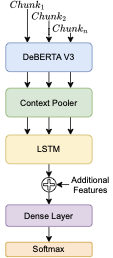
우리는 multilingual DeBERTa V3 모델[^4]과 LSTM 기반 아키텍처를 제안합니다. 자세히 보면, 먼저 문서의 조각 컬렉션은 DeBERTa V3을 통해 전달되어 컨텍스트 임베딩을 얻습니다. 그런 다음 각 임베딩의 첫 번째 토큰인 [CLS] 토큰이 밀집 계층과 GELU 활성화를 통과하여 컨텍스트 풀을 생성합니다.[^5] 그 후, 컬렉션의 컨텍스트 풀은 LSTM에 전달됩니다. 만약 추가 기능이 있다면 이들 기능은 LSTM의 최종 상태와 결합됩니다. 마지막으로, 이 최종 상태는 밀집 계층과 Softmax 활성화를 통해 문서의 클래스를 결정합니다.
/>
제안된 분류기 아키텍처.
3.1 섹션에서 설명했듯이, 전체 문서를 네트워크에 직접 제공하는 대신 무작위로 샘플링한 조각을 사용했습니다. 따라서 우리는 20, 48 및 62라는 세 가지 샘플 크기를 탐색하였습니다. 크기 20과 62는 코퍼스의 문단 분위수에 따라 선택되었습니다 (표 [table:corpus] 참조); 크기 48은 무작위로 선택되었습니다.[^6]
조각을 만들 때, 우리는 문서를 문단으로 나눕니다.[^7]. 그런 다음 각 문단은 DeBERTa V3 토크나이저로 토큰화 및 인코딩됩니다. 생성된 조각이 128 토큰을 초과할 경우, 16 토큰의 오버랩 스트라이드를 사용하여 하위 분할됩니다. 샘플링은 문서 전체의 인코딩된 조각에 대해 수행되며, 네트워크에 전달될 때 원래 순서대로 유지됩니다.
또한 우리는 3가지 종류의 문서 길이 표현을 추가 기능으로 탐색했습니다:[^8] 문자 수 ($`n_c`$), 문단 수 ($`n_p`$) 및 근사 페이지 수($`a_{pp} = n_c / 1,800`$)[^9]. 이들 값을 가까운 범위의 값으로 유지하기 위해 모든 것이 자연로그로 표현됩니다.
표 [tab:hyperparams]에서는 분류기를 훈련하는 데 사용된 하이퍼파라미터를 제시합니다. 또한, 훈련 과정에서 각 에포크마다 샘플링 프로세스가 처음부터 수행됨을 주목해야 합니다. 즉, 각 에포크에서는 네트워크에 제공되는 문서 컬렉션의 조각이 다릅니다. 이는 법률 문서에서 발생할 수 있는 다양한 텍스트 부분으로 문서 분류기의 학습을 더 견고하게 만드는 것이 목표였습니다.
데이터
우리는 25개 언어[^10]와 관련된 독점적인 다언어 법적 코퍼스를 사용합니다.
모든 문서들은 법률 전문가들에 의해 여러 년 동안 18개 클래스로 수동으로 분류되었습니다. 이 작업에서 우리는 이 코퍼스를 3개의 세트, 훈련 (80%), 개발 (10%), 그리고 테스트 (10%)로 나누었습니다; 모든 데이터는 JSON 라인 파일(JSONL)을 사용하여 표현됩니다. 표 [table:corpus]에서는 코퍼스 통계를 제시합니다.
전체 코퍼스의 근사 중간 페이지 수가 7.3임을 볼 수 있습니다. 또한, 가장 긴 문서는 전문 의견 (중간값은 38.8 페이지) 클래스에 속한 것이며, 가장 짧은 문서는 기타 (중간값은 1 페이지) 클래스에 속해 있습니다. 이 숫자들은 표준 페이지의 문자 수인 1,800으로 나눈 중간 문자 수를 통해 계산되었습니다.
배포
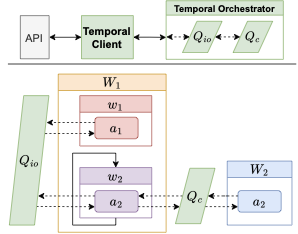
분류기가 다른 도구와 함께 사용되는 더 큰 프로젝트의 일부가 되는 것이 목표이므로, 우리는 이를 처리 파이프라인 내에 배포하기로 결정했습니다. 구체적으로, Temporal이라는 오픈 소스 오케스트레이터를 사용하여 간단한 방법으로 견고하고 확장 가능한 워크플로우를 만들 수 있습니다. 여기서 비즈니스 로직에만 집중하며, 작업 분배, 대기열 시스템 및 상태 캡처와 같은 코딩은 필요하지 않습니다. 따라서 이 논문에서는 현재 Temporal에서 생성된 워크플로우와 배포를 제시합니다. 그러나 이를 설명한 파이프라인은 가까운 미래에 현재 개발 중인 다른 구성 요소가 추가되어 변경될 것입니다.
Temporal은 4개의 기본 요소를 사용합니다: 활동(단순 작업 또는 여러 간단한 작업의 집합), 워크플로우(활동의 집합), 큐(활동 및 워크플로우에 대한 입력 대기 목록) 및 워커(특정 활동과/또는 워크플로우를 실행하고 특정 큐를 듣는 배포 인스턴스). 또한 각 활동 및 워크플로우는 한 번에 하나의 입력만 처리하지만 여러 활동 및 워크플로우가 동시에 실행될 수 있습니다. 이를 위해 워커 제한을 구성하거나 더 많은 워커를 배포할 수 있습니다.
사용자(인간 또는 다른 시스템)로부터/에게 모든 입력과 출력은 Temporal 클라이언트를 통해 통신됩니다. 이 클라이언트는 특정 워크플로우를 실행하고 해당 입력을 호출하며, 나중에 상태를 확인하기 위한 ID를 반환하거나 작업이 완료될 때까지 기다려 그 결과를 반환합니다.
파이프라인
현재 상태에서 우리의 파이프라인은 세 가지 활동으로 구성되어 있습니다. 첫 번째 활동, $`a_1`$, 주어진 디렉토리에 있는 모든 JSON 파일을 찾고 경로 목록을 생성합니다. 두 번째 활동, $`a_2`$, JSON 파일을 읽고 유효성 검사를 수행합니다. 세 번째 활동, $`a_3`$, JSON 파일을 처리하여 신경망의 입력을 생성하고 신경망을 호출하여 클래스를 추론합니다.[^11] 또한 이 마지막 활동은 문서가 분류될 준비가 되어 있는 고유 큐 $`Q_c`$에 귀속되며, $`Q_{io}`$는 입출력 처리용 큐입니다.
이러한 활동들은 두 가지 워크플로우로 나뉩니다. 첫 번째 워크플로우, $`w_1`$, $`a_2`$와 $`a_3`$을 호출하고 10개 문서의 배치를 생성합니다. 배치가 완료되면 더 처리할 문서가 있으면 새로운 워크플로우 인스턴스를 만듭니다.[^12] 두 번째 워크플로우 $`w_2`$는 활동 $`a_1`$과 워크플로우 $`w_1`$을 호출합니다.
마지막으로, 우리는 두 가지 워커를 설계했습니다. 워커 $`W_1`$은 데이터를 큐 $`Q_{io}`$에 보내는 역할을 하고 $`a_1`$, $`a_2`$, $`w_2`$, 그리고 일부 $`w_1`$을 관리합니다. 워커 $`W_2`$는 오직 큐 $`Q_c`$에 연결되어 있으므로 $`a_3`$만 실행합니다. 우리는 각 워커의 인스턴스를 여러 개 만들 수 있으며, 모두 Temporal이 자동으로 관리합니다. 독립적으로 배포된 API가 처리할 입력을 Temporal에 전송합니다.
/>
Temporal의 파이프라인 아키텍처. 점선은 Temporal이 관리하는 간접적인 통신을 나타냅니다.