- Title: Modeling Language as a Sequence of Thoughts
- ArXiv ID: 2512.25026
- 발행일: 2025-12-31
- 저자: Nasim Borazjanizadeh, James McClelland
📝 초록
Transformer 언어 모델은 언어를 토큰의 시퀀스로 모델링하여 뛰어난 자연스러운 텍스트를 생성할 수 있지만, 주로 표면적 동시 발생 통계에 의존하기 때문에 전체적으로 일관된 잠재 표현을 형성하지 못하며, 이는 관계적 일반화 능력의 부족(역전呚的詛咒), 上下文化錯誤和數據低效等問題。相比之下,認知科學表明,人類理解將語言輸入轉換為緊湊的事件類似表示,這些表示在記憶中持久存在,而逐字形式則是短暫的。受這些發現的啟發,我們提出了思想完形(TG)模型,這是一種遞歸變壓器,它在兩個抽象層次上對語言進行建模:令牌和句子級“思維”狀態。TG 一次生成一个句子,并通过交叉注意力关注先前句子表示的工作记忆。使用共享堆栈的变压器块生成标记和句子表示,并通過單一目標(下一個標記預測損失)進行訓練。通過保留寫入工作內存的句子表示的計算圖,來自未來令牌損失的梯度通過交叉注意流回以優化生成早期句子向量的參數。在擴展實驗中,TG 在數據和參數效率方面始終比匹配的 GPT-2 運行和其他基線有所提高,擴展適配表明 GPT-2 需要約 5-8% 更多的數據和約 33-42% 更多的參數以匹配 TG 的測試損失。TG 也在父親兒子逆轉詛咒探針上的關係方向泛化錯誤中有所減少。
💡 논문 해설
1. **핵심 기여 1**: TG 모델은 인간의 사고 방식을 모방하여 텍스트를 단위 사건으로 구분하고, 이를 통해 더 효과적인 언어 처리를 가능하게 합니다. 이는 마치 영화에서 장면이 전환될 때마다 관객이 새로운 정보를 이해하는 것과 같습니다.
2. **핵심 기여 2**: TG 모델은 문장 수준의 표현을 학습하면서, 토큰 수준의 예측 오류를 줄이고 더 나아가 일반화 성능을 높입니다. 이는 마치 낚시꾼이 물고기를 잡기 위해 큰 그물망 대신 작은 구멍이 있는 그물을 사용하는 것과 같습니다.
3. **핵심 기여 3**: TG 모델은 문장 간의 관계를 학습하면서, 역방향 일반화 문제를 해결하고 더 나은 상황 모델을 생성합니다. 이는 마치 우리가 일상생활에서 사건을 이해하고 기억하는 방식처럼 작동합니다.
Sci-Tube 스타일 스크립트
초급: TG 모델은 텍스트를 작은 조각으로 나누고, 각 조각을 학습하여 더 쉽게 이해하고 기억하도록 설계되었습니다. 이는 마치 책을 읽을 때 페이지마다 새로운 정보를 받아들이는 것과 같습니다.
중급: TG 모델은 문장 간의 관계를 학습하면서, 더 나은 상황 모델을 생성합니다. 이를 통해 텍스트에서 중요한 개념을 추출하고 이해하는 능력이 향상됩니다.
고급: TG 모델은 문장을 처리할 때 과거 문장 표현을 기억에 유지하며, 이는 문장 간의 관계를 더 잘 이해하고 일반화 성능을 높이는 데 도움이 됩니다.
📄 논문 발췌 (ArXiv Source)
# 소개
인지과학의 이전 연구는 언어가 인간에게서 기본적인 사고를 전달하기 위한 일련 코드로 기능하며, 사고 자체의 구성 매체는 아니라는 것을 제안한다. 이러한 견해에 따르면 이해는 언어적 스트림을 디코딩하여 상황 모델을 구축하는 과정이다—시간 순서, 인과 관계 및 설명된 사건의 개체를 코딩하는 정신적 표현. 상황 모델은 기억과 후속 추론을 지원하며, 표면 형태의 텍스트가 아닌 더 높은 수준의 개념적 표현으로 특징지어진다.
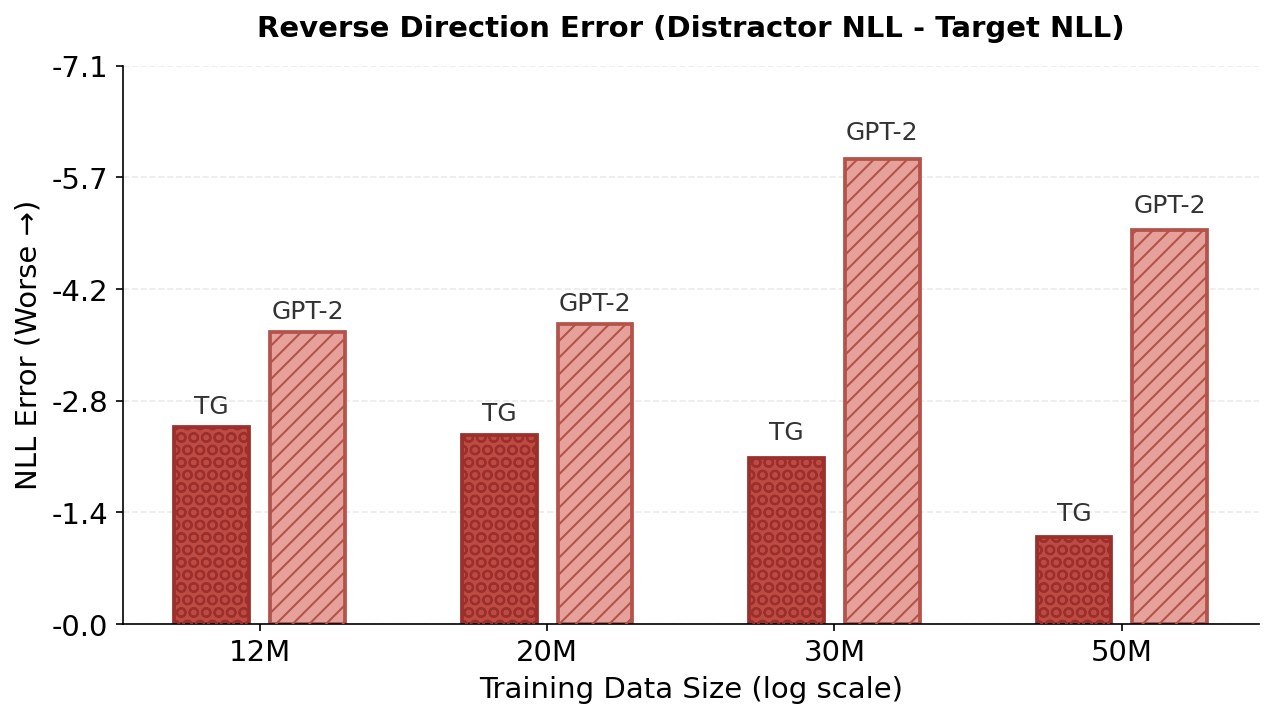
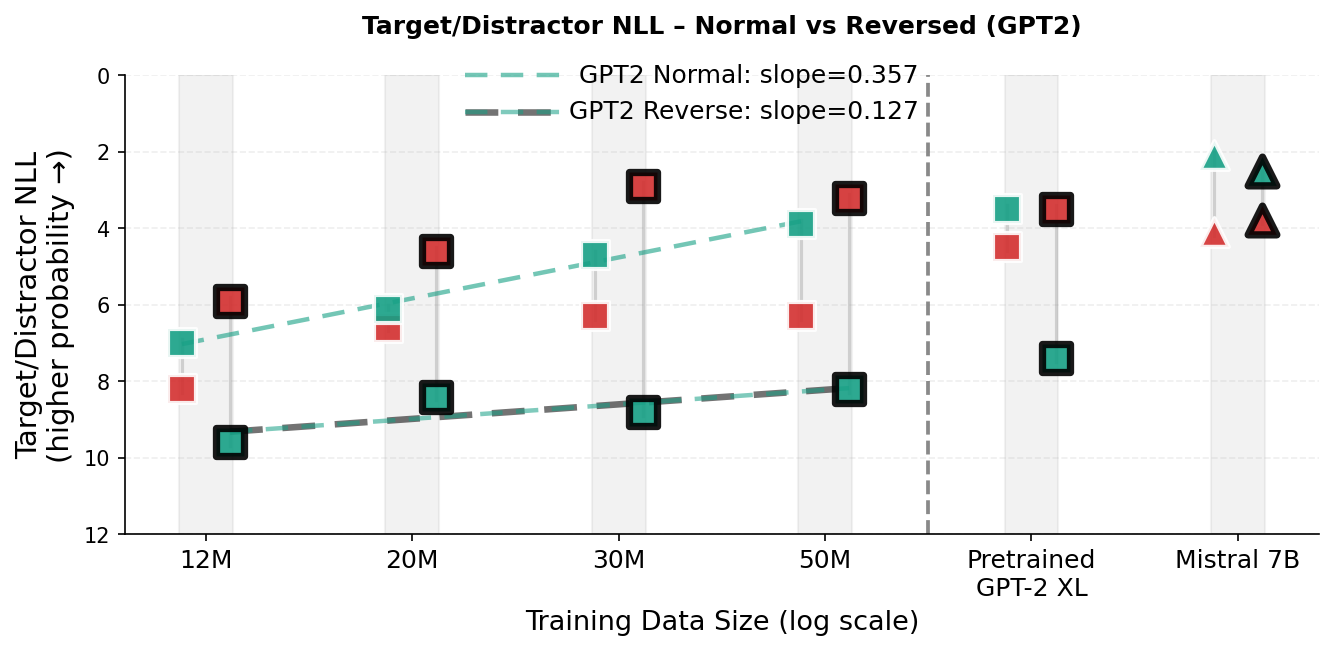
반면에 현대 대형 언어 모델(LLMs)은 언어를 토큰의 일련으로 학습하고 다음 토큰 예측을 최적화한다. 이는 뛰어난 유창성을 갖춘 모델을 생성하지만, 토큰 중심의 학습 신호는 표면 수준 통계 패턴을 포착하기 위해 견고한 경험법칙을 장려할 수 있다. 이러한 접근은 일반화와 구성 작업에서 실패를 초래한다. ‘역방향 저주’는 구체적인 예로, 모델이 한 관계 방향(예: “A는 B”)에 대해 훈련되었지만 반대 방향(“B는 A”)으로 일반화하는 데 실패한다. 그러나 GPT-4와 같은 최신 모델에서는 ‘역방향 저주’가 나타나지 않으나, §3.4에서 보여주듯이 GPT-2 규모의 작은 모델에서는 프롬프트 반대 방향으로 관계를 조회할 때 상당한 방향적 비대칭성이 존재한다.
표준 트랜스포머 모델의 또 다른 단점은 식별된 컨텍스트화 오류로, 하위 트랜스포머 레이어에서는 후방 토큰이 앞쪽 토큰 표현에 대해 주의를 기울여 애매한 부분을 해결하기 전까지 완전히 컨텍스트화되지 않은 상태에서 참조한다. 마지막으로, 많은 현대 모델은 수 조 개의 토큰에 대한 학습을 수행하며, 이는 아동의 언어 노출 추정치보다 세 수준 이상 더 많다(약 수천만 단어). 이러한 격차는 토큰보다 높은 수준의 추상화에서 잠재 표현을 학습하고 재사용하는 아키텍처를 동기부여한다. 즉, 정보를 일관된 GESTALT—부분들의 합으로 설명할 수 없는 통합적 표현들로 조직화하여 텍스트가 전달하는 기본 개념과 관계를 포착하는 모델을 만드는 것이다.
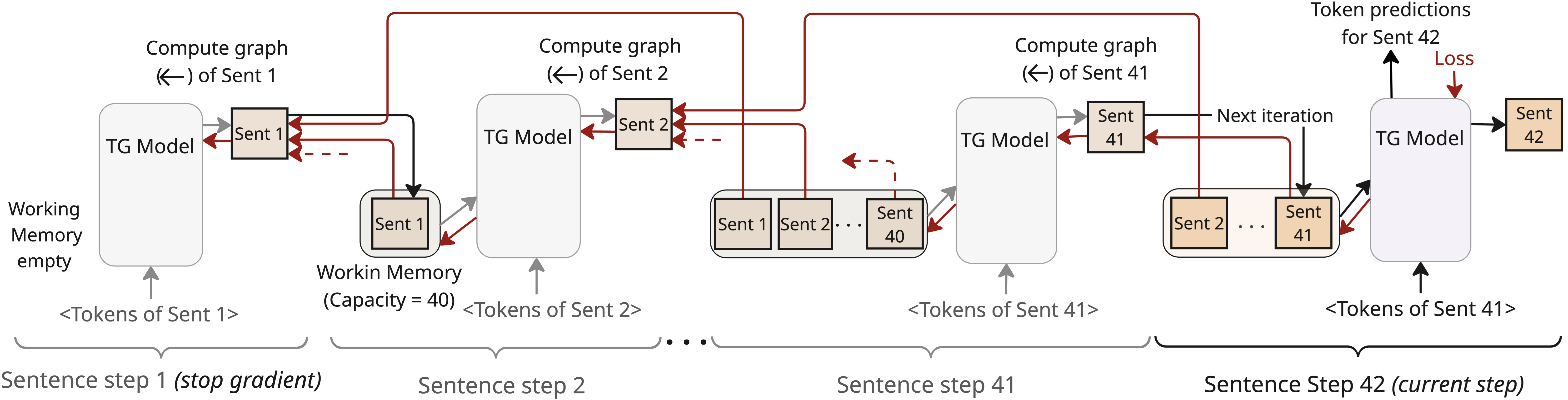
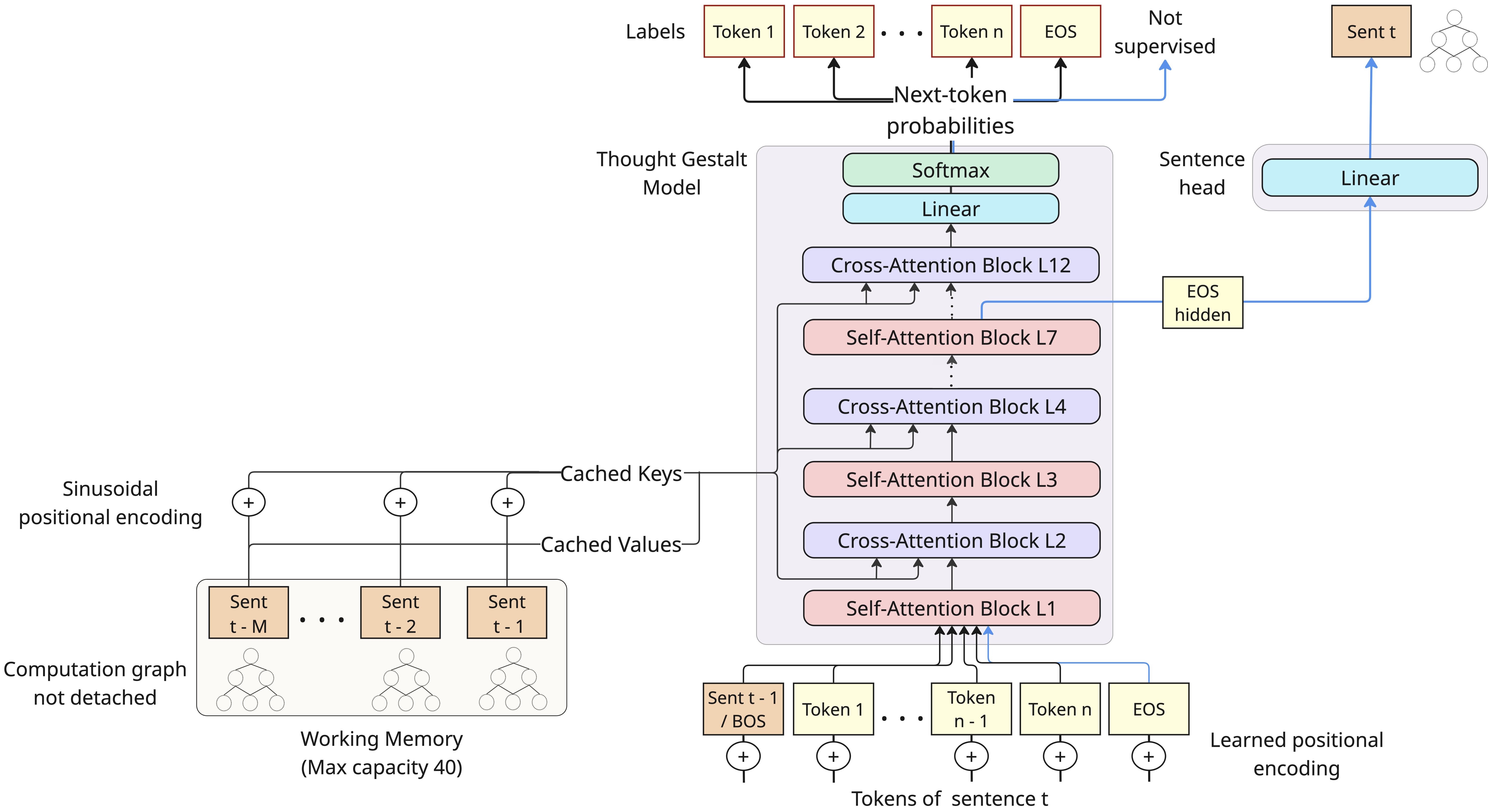
TG의 순방향/역방향 통과. 각 문장 단계는 다음 토큰 예측 및 문장 벡터를 생성하고, 이는 계산 그래프를 떼어놓지 않고 고정 용량 메모리에 추가된다(메모리가 가득 차면 가장 오래된 항목을 제거). 다음 토큰 손실 기울기는 메모리를 통해 이전 문장 표현을 생성한 매개변수를 최적화한다.
본 연구에서는 Thought Gestalt (TG) 모델을 소개한다. TG는 토큰과 문장 수준 사고 두 가지 추상화 레벨에서 언어를 모델링하는 재귀 트랜스포머 아키텍처다. TG는 한 번에 하나의 문장을 처리(문장 단계)하고 현재 문장의 토큰 수준 정보만 유지한다. 그러나 맥락은 이전 문장 표현으로 구성된 작업 메모리에서 유지된다: 전체 문장을 벡터로 압축한 통합적 표현, 즉 “GESTALT"들(Figure 1 참조). 이러한 설계는 인간이 텍스트의 연속적인 스트림을 이산 사건으로 분할하여 기억을 조직하는 인지 증거에 기반한다. 언어의 구두 형태는 짧은 시간 동안만 존재하고 좁은 범위에 제한되지만, 이전 내용은 사건과 관계를 표현하는 안정적이고 고수준의 표현으로 유지된다. TG는 또한 단어 시퀀스를 단일 사건 표현으로 점진적으로 매핑하는 Sentence Gestalt 모델에서 영감을 받았다. TG도 문장 경계를 사고 경계의 구조적 대리인으로 사용한다. 문장 경계는 일대일 매핑은 아니지만, 배경 정보가 통합되고 개념이 업데이트되는 자연스러운 인지 지점을 제공한다. 따라서 문장 표현을 학습하는 것은 상황 모델과 잠재적 사고 표현을 학습할 수 있는 생성 시스템을 구축하기 위한 첫걸음이다.
아키텍처적으로, TG는 현재 문장의 토큰에 대한 자기 주의와 고정 용량 작업 메모리 내 이전 문장 표현에 대한 교차 주의를 번갈아가며 적용한다. 토큰은 현재 문장 내에서 인과적으로 주의하고, 이전 문장을 참조하려면 문장 GESTALT 벡터를 통해 접근해야 한다(gist와 유사). 각 문장 표현은 문장 끝(<EOS>) 토큰 위치의 컨텍스트화된 은닉 상태로부터 구성된다(Figure 3 참조). 문장 단계 후에는 새로운 문장 표현이 메모리에 추가되고, 메모리가 가득 차면 가장 오래된 항목이 제거된다. 중요한 점은 TG가 작업 메모리에 작성할 때 문장 표현의 계산 그래프를 유지함으로써 나중 문장에서의 다음 토큰 예측 손실이 교차 주의를 통해 이전 문장 GESTALT 생성 매개변수로 역전파되게 한다(Figure 1 참조). 문장 GESTALT는 의미적으로 일관된 내용 덩어리의 컨텍스트화된 요약이므로, 추론 시 캐싱 및 검색을 통해 지속적인 학습을 가능하게 하는 자연스러운 후보가 된다(기억 변환자와 유사). 여기서 우리는 주로 그들이 사전 훈련에 대한 미분 가능한 맥락으로 활용되는 역할에 초점을 맞춘다.
우리의 문장 표현 학습 설계는 표준 다음 토큰 목표 하에서 end-to-end로 구현되며, 이는 추가적인 목적을 통해 문장 임베딩을 학습하는 최근 아키텍처와 구분된다. 예를 들어, 다음 문장 예측, 토큰 재구성, 문장 순서 정렬 또는 대조적 정렬과 같은 언어 모델링 손실 위에 추가적인 목적을 사용한다. 경험이 드러내는 바와 같이 이러한 보조 목적은 견고성이 떨어질 수 있으며 때로는 하류 일반화를 저하시키기도 한다. 반면에 TG는 별도의 인코더나 문장 수준의 추가 손실을 사용하지 않고, 토큰과 문장 표현이 동일한 모델 매개변수 세트를 사용하여 생성되며 다음 토큰 예측 목표를 통해 감독받는다. 또한 표준 트랜스포머와 달리 TG는 초기 레이어가 완전히 컨텍스트화된 문장 GESTALT의 메모리를 참조할 수 있도록 하여 식별된 컨텍스트화 오류를 직접적으로 대상으로 삼는다.
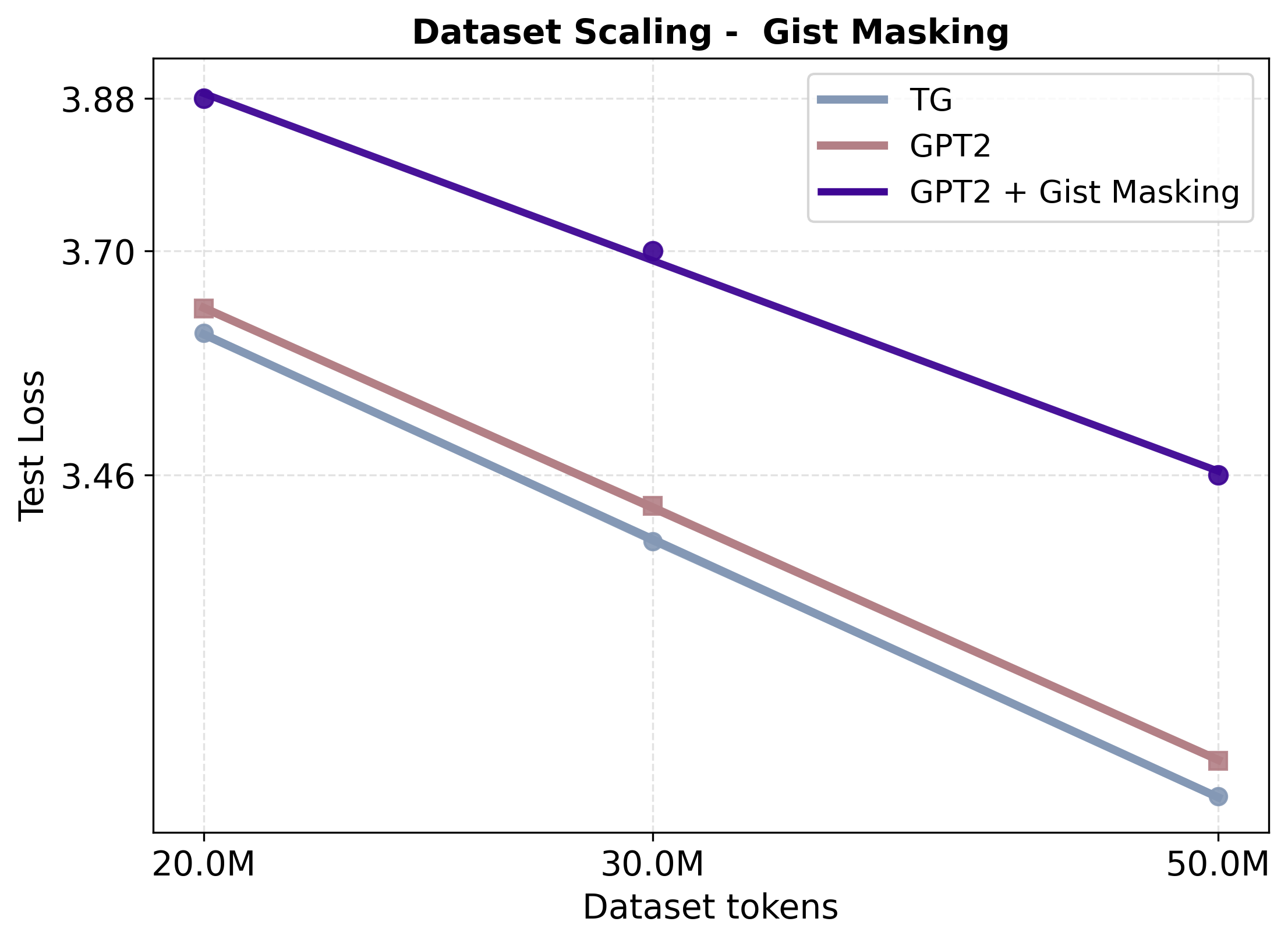
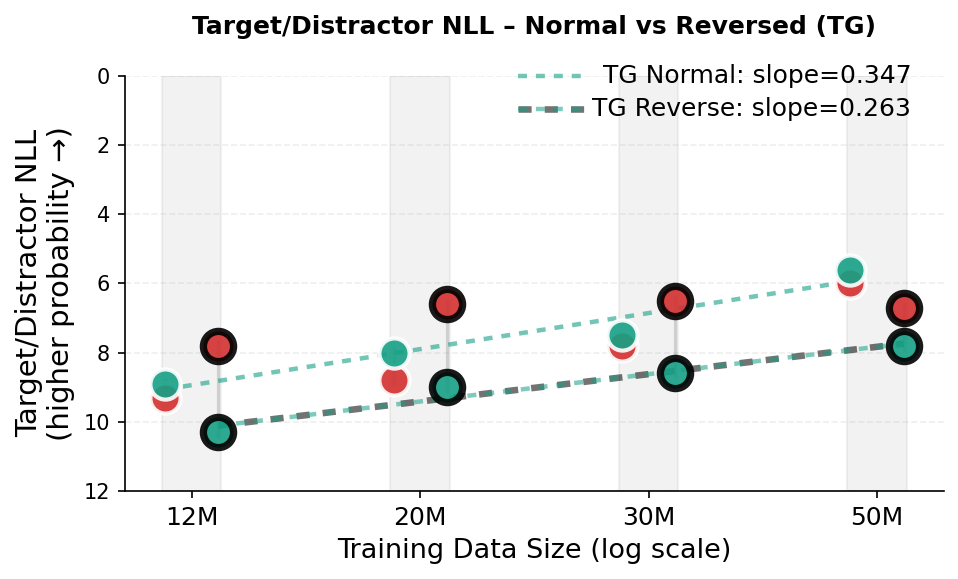
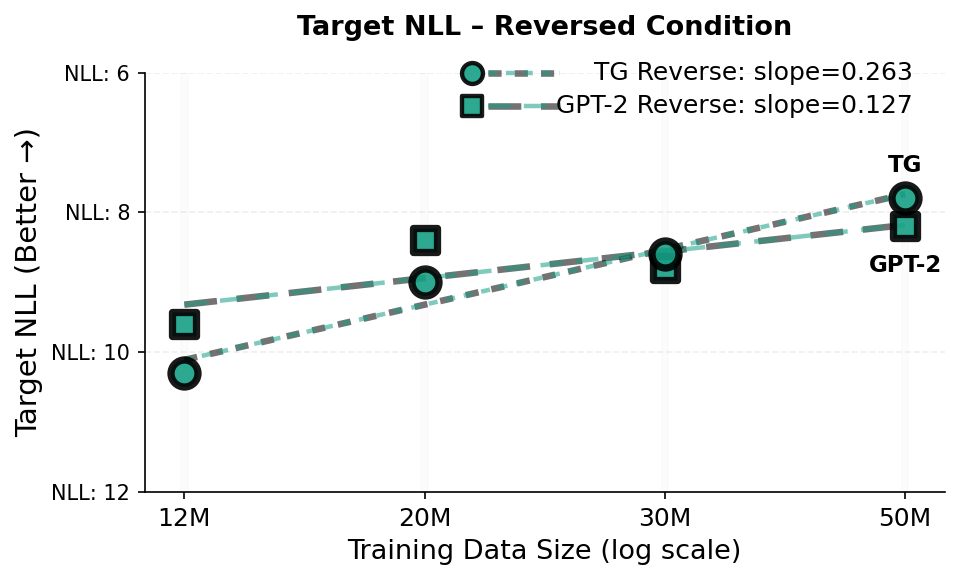
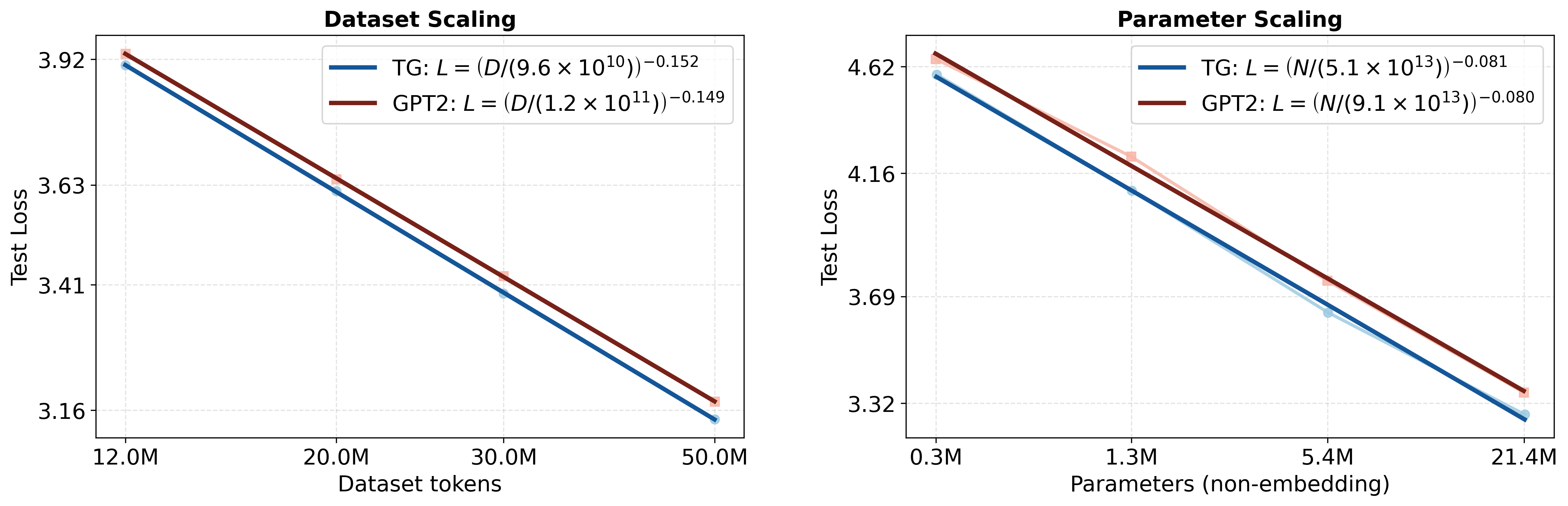
경험적으로, TG는 학습 효율성과 표현력 강건성을 동시에 향상시킨다. TG는 WikiText-103에서 사전 훈련된 동일한 GPT-2 베이스라인보다 데이터 및 매개변수 효율성이 일관되게 더 높다(Figure 2 참조). 데이터 크기 확장 실험($`12`$–$`50`$M 학습 토큰; $`N \approx 85`$M 비 임베딩 매개변수)에서, TG는 모든 규모에서 $`2`$–$`4\%`$ 더 낮은 테스트 perplexity를 달성하고(예: $`23.2`$ 대비 GPT-2의 $`24.0`$), 같은 손실을 달성하는 데 필요한 학습 토큰 수가 실제 $`5`$–$`8\%`$ 줄어든다. 고정된 $`D=50`$M 토큰에서 매개변수 크기 확장 실험에서는 TG는 $`0.3`$M–$`21.3`$M 모델 크기 범위에서 일관되게 우세를 유지하고, GPT-2가 동일한 성능을 내려면 $`1.33`$–$`1.42\times`$ 더 많은 매개변수를 필요로 한다. 다양한 대안적 베이스라인과의 비교(예: 특별 토큰을 사용하여 GPT-2에 문장 경계 편향 추가, TG의 문장 기반 재귀를 고정 토큰 스패닝으로 교체 및 문장 수준 gist-style 주의 마스킹)는 TG의 성능 증가가 의미적으로 일관된 완전히 컨텍스트화된 단위에 대한 토큰 생성 조건에 의존함을 보여준다. 문장을 임의의 토큰 블록으로 대체하거나 재귀 없이 압축 토큰을 통한 이전 토큰 접근 제한 시 성능이 저하된다(Figure 4 참조). 또한, in-context father–son 프로브에서 TG는 GPT-2보다 상대 방향 일반화를 더 빠르게 개선한다. 완료 쿼리가 프롬프트의 방향을 반전할 때 대상 토큰의 가능성으로 측정된다(Figure 5 참조). 마지막으로, 청크는 문장 GESTALT 작업 메모리와 메모리를 통해 기울기 흐름 유지가 TG의 성능에 필수적임을 확인하고 추가적인 레이어별 자기 및 교차 주의 용량은 성능 개선에 더욱 도움이 된다(Table 1 참조).
Kaplan 스타일 확장 행동. 패널 (a)는 고정된 모델 크기의 85M 비 임베딩 매개변수에 대해 TG와 GPT-2의 학습 데이터 크기 D를 변화시키며, 패널 (b)는 고정된 학습 데이터셋 크기인 50M 토큰에서 모델 크기 N을 변화시킨다.
주요 설계 원칙
Thought Gestalt (TG) 모델은 단일 트랜스포머 스택을 사용하여 문장 수준 사고의 일련으로 언어를 학습한다. 이 스택은 토큰 디코더이자 문장 인코더 역할을 수행한다(Figure 3 참조). 구체적으로, TG는 문서를 문장 단계의 시퀀스로 처리한다. 문장 단계 $`t\in\{1,\dots,T\}`$에서 $`T`$가 문장 스트림 내 문장 수인 경우, TG는 (i) 토큰에 대한 인과적 자기 주의와 이전 컨텍스트화된 문장 벡터에 대한 작업 메모리 교차 주의를 번갈아가며 문장 $`t`$의 토큰을 예측하고, (ii) 문장 $`t`$를 단일 벡터로 압축하여 $\mathbf{s}_t$, 이는 그래디언트를 떼어놓지 않고 메모리에 기록된다. 본 절에서는 TG 아키텍처, 작업 메모리의 읽기/쓰기 인터페이스 및 안정적이고 확장 가능한 학습을 가능하게 하는 훈련 및 데이터 준비 파이프라인을 설명한다. 배치 구성과 임의 정규화에 대한 세부 정보는 부록 7을 참조하고, 주요 TG 구성 요소의 청크는 §3.5를 참조하며, 학습 시간 메모리 사용 및 기울기 흐름 분석은 부록 8과 부록 9을 참조하십시오.
TG 아키텍처. 교차 주의 및 자기 주의 블록이 번갈아가며 주 모델 스택을 구성한다. 토큰 뷰는 문서 내 최종 문장이 아닌 사례(마지막 단어 없음)를 설명하고, 명확성을 위해 패딩 토큰은 생략되었다. 7단계에서 컨텍스트화된 은닉 상태가 작은 선형 문장 헤드에 의해 투영되어 문장 표현을 생성한다.
데이터 준비
데이터 파이프라인은 원시 코퍼스를 TG의 계산 모델과 일치하는 문장 수준 학습 샘플로 변환한다. 구체적으로, 우리는: (i) 소스에서 제공되는 경계(즉, 단일 위키백과 기사)에 따라 데이터셋을 문서 수준 텍스트 유닛으로 분할하고; (ii) 문서를 문장으로 나누고; (iii) 각 문장을 특별한 경계 토큰으로 감싸고; (iv) 고정 최대 길이의 연속적인 문장 스트림으로 문서를 슬라이스하여 제한된 그래디언트 그래프 깊이를 가진 학습 예제를 생성하며; (v) 배치는 문장 스트림에서 균일하게 샘플링하고, 배치당 단어 토큰의 목표 수에 제약을 두어 GPU 메모리 사용량과 최적화를 안정적으로 유지한다(자세한 내용은 부록 7.1 참조).
문장 나누기.
우리는 먼저 문서(독립적인 위키백과 기사)를 제목 서식에 따라 분리하고, 그 다음 “SaT Capped” 방법을 사용하여 텍스트를 문장으로 나눈다. SaT Capped는 구두점 오류에도 강한 토큰 수준에서 문장 경계를 예측하며, 주어진 최대 토큰 길이($`L\!=\!64`$ 토큰)보다 긴 문장을 더 짧고 의미적으로 일관된 구역으로 나누는 구두점 인식 대체 규칙을 적용하여 최대 문장 길이를 강제한다. 이 방법은 Large Concept Model 연구에서 문장 수준 재구성을 위한 가장 높은 AutoBLEU 점수를 달성했기 때문에 선택되었다.
문장 텐서화 및 경계 마커.
문장 나누기를 통해 각 문장을 토큰화하고(모든 베이스라인에 공유된 토크나이저/어휘), 설정한 최대 문장 길이 $`L_{\max} = 64`$ 토큰으로 패딩한다. 그런 다음 명시적인 경계 마커를 추가하여 문장 텐서를 형성: 문장 시작 토큰 <BOS>와 문장 끝 토큰 <EOS>. <BOS> 토큰은 TG 모델이 새 문장의 첫 번째 단어 토큰을 예측할 수 있도록 하고, 교차 주의를 위해 작업 메모리에 대한 비공백 상태로 맥락을 설정한다. <EOS> 토큰은 문장 생성의 끝을 표시하고, 문장 표현 $\mathbf{s}_t$을 형성하는 데 사용되는 은닉 상태를 추출할 위치를 지정한다(§2.2 참조). 또한 문서 끝 마커 <EOD>를 위한 전용 슬롯을 <EOS> 바로 앞에 예약한다. 이 슬롯은 문서의 마지막 문장에서만 텍스트 생성의 종료를 표시하기 위해 추가되며, 모든 중간 문장에서는 <PAD>로 설정된다. 따라서 각 문장 텐서는 고정된 총 길이 $`L \;=\; 1 + L_{\max} + 2 \;=\; 67.`$를 갖는다.
문장 스트림을 학습 예제 및 배치 구성으로 사용.
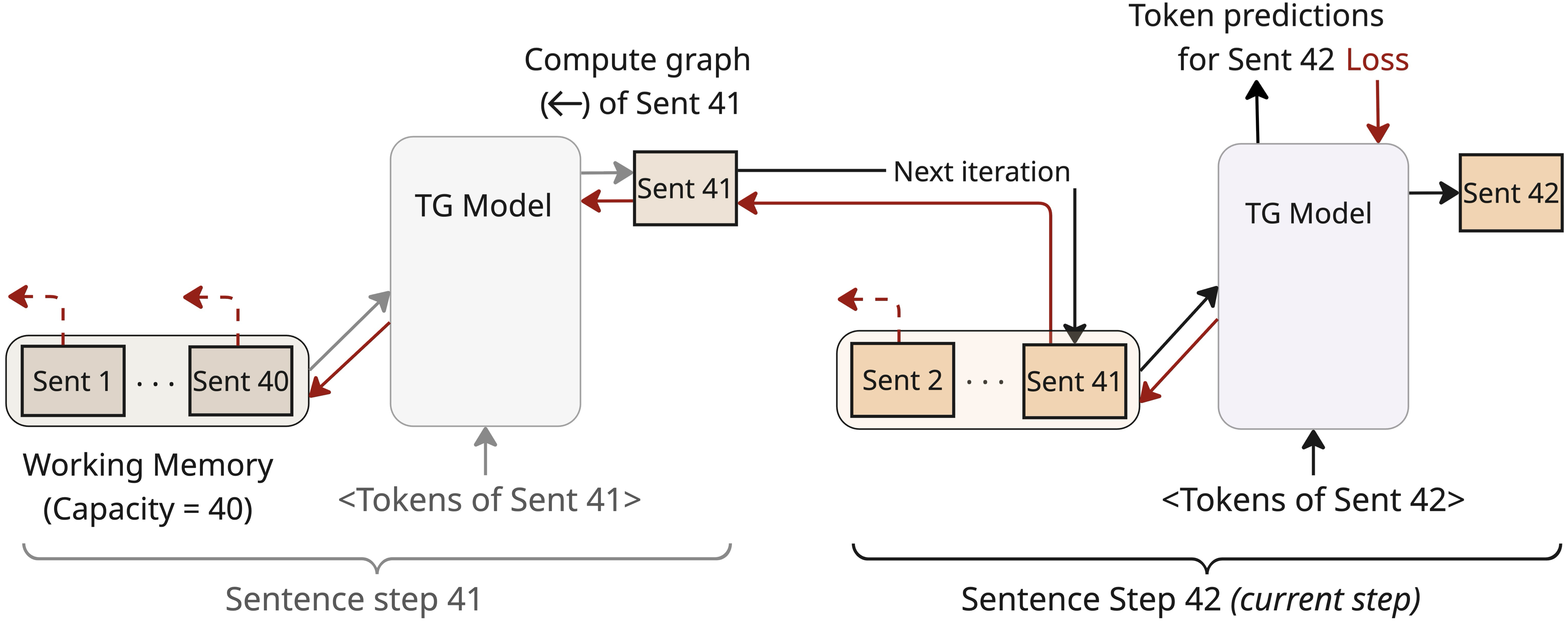
TG는 메모리에 기록된 문장 표현의 계산 그래프를 유지하여 다음 토큰 예측 손실을 통해 문장 인코딩을 학습한다. 문장 단계 $`t`$에서 모델은 전방 통과 중 가장 최근 $`M`$ 문장 벡터에만 교차 주의를 적용한다. 그러나 메모리 항목의 계산 그래프가 유지되므로 저장된 문장 벡터는 형성될 때 참조한 이전 문장의 그래프와 연결을 유지한다. 결과적으로 단계 $`t`$에서의 기울기는 더 이상 작업 메모리에 없더라도 더 오래된 문장 표현의 계산 그래프로 재귀적 역방향 전파가 가능하다(부록 Fig.).