생성 분류기 단순 속임수 피하기
📝 원문 정보
- Title: Generative Classifiers Avoid Shortcut Solutions- ArXiv ID: 2512.25034
- 발행일: 2025-12-31
- 저자: Alexander C. Li, Ananya Kumar, Deepak Pathak
📝 초록
(이 논문은 기존의 판별적 방법 대신 생성적 분류기를 사용하여 분포 이동에 견고한 모델을 만드는 데 초점을 맞춥니다. 생성적 분류기는 전체 입력 데이터를 학습하므로, 단순히 훈련 데이터의 특이적인 패턴을 따라가는 것이 아니라 본질적인 특징을 학습합니다.)💡 논문 해설
1. **실제 분포 이동에서 생성적 분류기의 우수성**: 생성적 분류기는 기존 방법보다 더 강력한 성능을 보여줍니다. 이를 통해 모델은 훈련 데이터 외부에서도 잘 작동합니다. 2. **생성적 분류기가 어떻게 작동하는지 이해하기**: 생성적 분류기의 학습 목표는 입력 데이터 전체를 학습하므로, 단순한 특이 패턴을 따라가는 것이 아니라 본질적인 특징을 파악하게 됩니다. 3. **가우시안 데이터에서의 통찰력**: 간단한 설정에서 생성적 분류기와 판별적 분류기를 비교하여 일반화 단계를 확인하고, 이는 생성적 분류기가 낮은 변동성 특징에 대한 편향을 가짐을 나타냅니다.📄 논문 발췌 (ArXiv Source)
서론
알렉스넷 이후로, 신경망을 사용한 분류는 주로 판별적 방법으로 접근되어 왔습니다. 이 방법은 모델이 $`p_\theta(y \mid x)`$를 학습하도록 훈련됩니다. 이 접근법은 내부 데이터에 대한 성능에서는 잘 작동하지만, 소위 단순해결책(shortcut learning)이라는 현상으로 인해 훨씬 더 취약해집니다. 즉, 훈련 분포에서 잘 작동하는 솔루션을 출력하되, 작은 분포 변화에도 효과가 없게 됩니다. 이러한 모델의 취약성은 이미 잘 문서화되어 있지만, 훈련 데이터 다양성을 늘리는 것 외에는 이 문제를 해결하기 위한 접근법이 아직 크게 발전하지 않았습니다.
본 논문에서는 대안적인 방법인 생성적 분류기를 사용하여 이 문제를 해결할 수 있는지 살펴봅니다. 이 방법은 클래스 조건부 생성 모델을 훈련하여 $`p_\theta(x \mid y)`$를 학습하고, 추론 시 베이즈 정리를 사용하여 $`p_\theta(y \mid x)`$를 계산해 분류합니다. 우리의 가설은 생성적 분류기가 단순한 해결책을 피하는 데 더 효과적일 수 있다는 것입니다. 이는 그들의 목표가 입력 $`x`$ 전체를 모델링하도록 강제하기 때문입니다. 즉, 판별적 모델이 특이 패턴에만 의존하는 것과 달리 생성적 분류기는 핵심적인 특징까지 모델링해야 합니다. 또한 우리는 생성적 분류기가 일관되게 예측 가능한 특징을 사용하도록 하는 인덕티브 편향(inductive bias)을 가질 수 있다는 것을 가정합니다. 이는 분포 변화에 견고하게 작동하기 위해 모델이 학습해야 할 핵심적인 특징입니다.
 style="width:90.0%" />
style="width:90.0%" />
생성적 분류기는 최소한 피셔 판별 분석까지 거슬러 올라갑니다. 나이브 베이즈와 같은 생성적 분류기는 학습 상의 장점이 있었지만, 당시에는 좋은 생성 모델링 기법이 부족하여 제약을 받았습니다. 그러나 지금은 매우 강력한 생성 모델이 있으며 일부 연구는 이러한 새로운 모델로 생성적 분류기를 재검토하고 있습니다. 특히 ImageNet에서 훈련된 확산 모델이 추가 데이터 없이 “효과적인 견고성”을 보여주어, 생성적 분류기가 근본적으로 다른 (그리고 아마도 더 나은) 인덕티브 편향을 가질 수 있음을 시사합니다. 그러나 그들의 분석은 ImageNet의 분포 이동에 한정되어 있으며, 이해를 제공하지 않습니다. 우리 논문에서는 깊은 생성적 분류기와 오늘날의 판별적 방법을 포괄적인 분포 이동 벤치마크에서 세심하게 비교합니다. 또한 그들이 작동하는 이유와 상황에 대한 철저한 분석도 수행합니다. 우리의 기여는 다음과 같습니다:
-
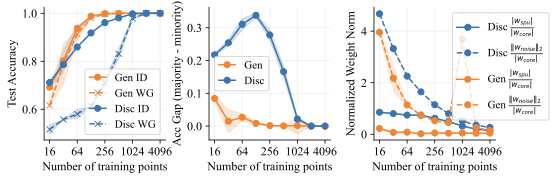
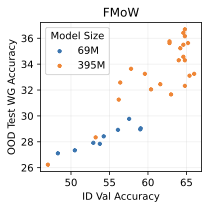
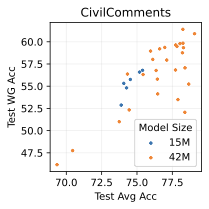
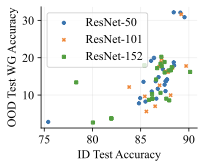
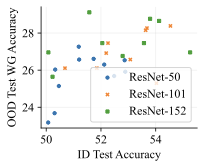
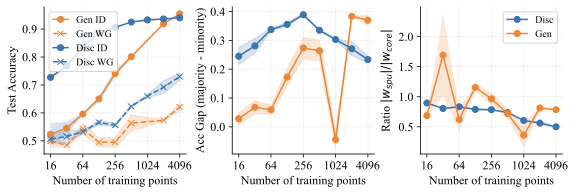
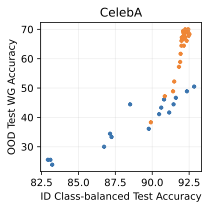
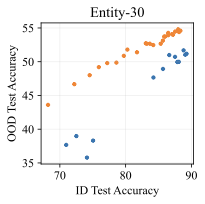
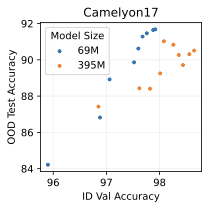
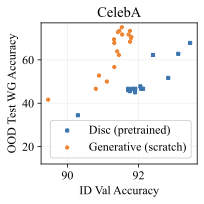
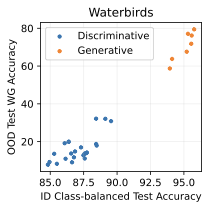
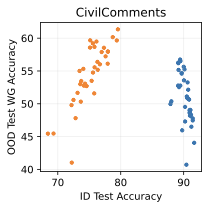
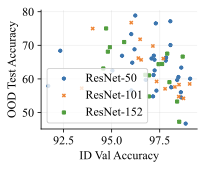
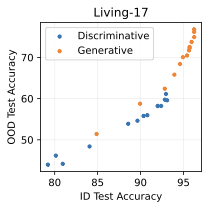
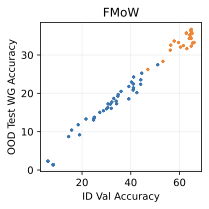
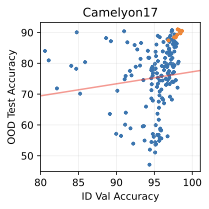
실제 분포 이동에서 생성적 분류기의 큰 우위: 생성적 분류기는 이전의 분포 이동 완화 방법보다 간단하고 효과적입니다. 그들은 현재의 생성 모델링 파이프라인을 활용하며 추가 하이퍼파라미터나 훈련 단계 없이, 특이 패턴을 피하기 위한 지식도 필요하지 않습니다. 우리는 표준 분포 이동 벤치마크에서 이미지와 텍스트 도메인에 대한 실험을 수행하고 생성적 분류기가 판별적 접근법보다 분포 이동에서 더 잘 작동한다는 것을 발견했습니다. 가장 주목할 만한 점은 그들이 “효과적인 견고성”을 보여내는 첫 번째 알고리즘적 접근법이라는 것입니다. 즉, 그들은 훈련 분포 성능보다 분포 이동에서 더 나은 성능을 보입니다 (그림 1 참조). 우리는 또한 대부분의 데이터셋에서 더 높은 내부 분포 정확도를 발견하여 생성적 분류기가 과적합에 덜 취약하다는 것을 나타냅니다.
-
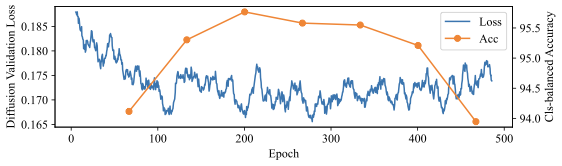
생성적 분류기 작동 원리 이해: 우리는 생성적 분류기가 어떻게 더 잘 작동하는지에 대한 몇 가지 가설을 세심하게 검증합니다. 우리는 $`p(x \mid y)`$ 학습 목표가 모델이 $`x`$의 모든 특징을 학습하도록 강제하기 때문에 일관된 학습 신호를 제공한다는 결론을 내립니다.
-
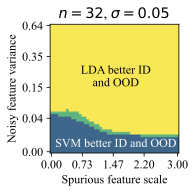
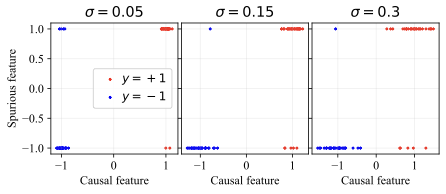
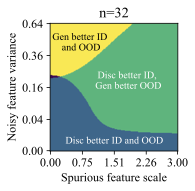
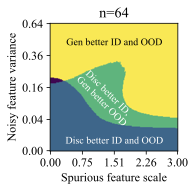
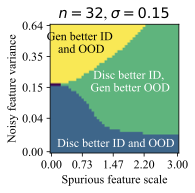
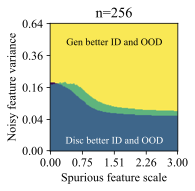
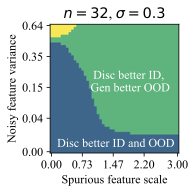
가우시안 데이터에서의 통찰력: 간단한 설정에서 생성적 (선형 판별 분석)과 판별적 (로지스틱) 분류 방법을 비교합니다. 우리는 특이 패턴과 잡음 특징의 강도에 따라 어떤 접근법이 더 잘 작동하는지를 보여주는 “일반화 단계"가 존재한다는 것을 발견했습니다. 이러한 단계는 생성적 분류기가 낮은 변동성 특징에 대한 편향을 가짐을 나타냅니다.
관련 작업
특이한 특징이 있는 상황에서 학습하기
심층 네트워크가 경험 위험 최소화(ERM)로 훈련될 때 레이블을 예측하는 데 특이 패턴에 의존한다는 것은 잘 알려져 있습니다. 특히 이미지의 배경이나 특정 단어와 같은 것들입니다. 특히 이러한 단순해결책에 과적합되면 분포 이동에서 성능이 저하됩니다. 이런 특이 패턴은 더 이상 예측적이지 않을 수 있기 때문입니다. 특정 “소수” 그룹의 성능이 특히 저하되며, 이 불균형은 고도로 과매개변수화된 모델에서 더욱 악화됩니다. 이론적 작업들은 이를 판별 분류기의 교차 엔트로피 손실 편향에 귀인합니다. 이러한 분류기는 최대 마진 해를 찾는 것을 선호하므로 특이 패턴을 학습하게 됩니다, 심지어 그것들이 핵심적인 특징보다 예측력이 약할 때조차도. 판별적 모델의 이러한 실패를 해결하기 위해 각 그룹 간 학습을 균형 있게 하는 목표 또는 데이터 증강을 사용하여 잡음 특징을 부드럽게 하려는 시도가 있었습니다. 그러나 이러한 방법은 여전히 핵심적인 특징을 포착하지 못하고 종종 내부 분포 성능에서 저하를 초래합니다. 일부 접근법은 특정 특이 패턴을 식별하고, 이를 포함하는 예제에 표시하여 데이터를 다시 균형 있게 만드는 방법을 사용했습니다. 그러나 이러한 접근법은 상당한 수동 노력을 필요로 하며 스케일링이 어렵고 인간이 학습된 특징을 이해하지 못하는 문제에서는 작동하지 않을 수 있습니다. 아이디얼하게는 분포 이동에 잘 일반화되면서 추가적인 감독 없이도 올바른 인덕티브 편향을 가진 접근법을 찾고자 합니다.
생성 모델을 사용한 분류
심층 학습 접근방식 중 대부분은 클래스 조건부 생성 모델을 훈련시키거나 직접 분류에 사용하지 않았습니다. 특히 약한 생성 모델로 $`p(x \mid y)`$를 모델링하는 것이 어려운 작업이기 때문일 수 있습니다. 그러나 최근의 생성 모델은 크게 개선되었으며, 확산 확률 모델에서 더 나은 기법을 사용하여 깊은 생성 분류 방법이 최근 제안되었습니다. 이미지넷에서 훈련된 클래스 조건부 확산 모델이 판별적 분류기와 경쟁하며 추가 데이터 없이 “효과적인 견고성"을 달성한다는 것을 보여주었습니다. 또한 테스트 시 적응을 사용하여 여러 합성 오염에 대한 성능을 개선하는 하이브리드 생성-판별 분류기를 제안했습니다. 다른 작업은 큰 사전 훈련된 생성 모델이 형태 특징에 더 편향되며 합성 오염에 대해 견고하다는 것을 보여주었지만, 이는 사전 훈련에서 추가 데이터의 효과 또는 확산이 입력 변동에 대한 내구성을 부여하기 때문일 수 있습니다. 다른 작업은 생성 분류기가 적대적 견고성을 개선한다는 것을 발견했습니다. 그러나 적대적 견고성이 분포 이동에 대한 견고성으로 전달되지 않는다는 것이 입증되었습니다. 전반적으로 아직도 생성적 분류기가 실제적인 분포 이동에서 특이 패턴에 대해 더 견고한지, 왜 그렇게 될 수 있는지에 대한 명확성이 부족합니다.
예비 지식
분포 이동의 유형
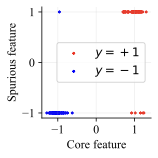
우리는 두 가지 유형의 분포 이동 하에서 분류를 고려합니다. 부분집합 변화에서는 레이블과 상관관계가 있는 고수준 특이 패턴이 있습니다. 예를 들어, CelebA에서 사람의 머리색이 금발인지 아닌지를 예측하는 작업에서 특이하게 상관된 특징은 성별입니다. 이는 데이터셋에 금발 남성이 매우 적기 때문이며, 모델은 보통 “남자"라는 특징을 사용합니다. 특이 패턴은 그룹을 결정합니다: 주요 그룹에는 특이 패턴이 올바른 예제가 있고, 소수 그룹에는 특이 패턴이 틀린 예제가 있습니다. 또한 도메인 변화도 고려합니다. 여기서 테스트 도메인의 데이터 분포는 학습 도메인의 데이터 분포와 유사합니다. 예를 들어 Camelyon17-WILDS에서 학습 이미지는 3개 병원에서 오지만, 테스트 이미지들은 이에 겹치지 않는 다른 4번째 병원에서 옵니다. 학습 분포에서 작동하던 특이 패턴, 예를 들어 슬라이드 염색이나 샘플 수집 방법의 잡음 등은 분포 변화로 인해 정확도가 떨어질 수 있습니다. 우리는 총 5개의 일반적인 분포 이동 벤치마크를 검토합니다: CelebA와 Camelyon 외에도 Waterbirds (부분집합 변화), FMoW (부분집합과 도메인 변화 모두), CivilComments (부분집합 변화).
판별적 분류기의 단점
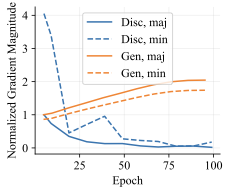
판별적 분류기는 $`p_\theta(y \mid x)`$를 최대화하려고 하며, 특이 패턴에 지나치게 의존하여 단순해결책에 빠질 수 있습니다. 이는 그들이 주요 그룹 예제를 정확하고 확신 있게 맞추기 위해 특이하게 상관된 특징을 사용할 수 있기 때문입니다. 이렇게 되면 이러한 예제의 손실은 평평해지고, 핵심적인 특징을 사용하도록 모델을 격려하는 경사 신호가 적어집니다. 모델은 따라서 남아 있는 소수 그룹 예제에서 과적합하게 됩니다. 이러한 단순해결책은 내부 분포에서는 잘 작동하지만, 심지어는 작은 분포 변화에서도 실패할 수 있습니다. 이 문제를 방지하기 위한 많은 노력이 이루어졌지만, 주로 데이터를 재균형시키는 방법으로 특이 패턴이 더 이상 유지되지 않도록 합니다. 그러나 이러한 방법은 훈련 과정에 추가 하이퍼파라미터와 복잡성을 추가하며 종종 정확한 분포 변화를 반작용하기 위한 지식을 필요로 하는데, 실제 문제에서는 다양한 특이 패턴이 있을 수 있어 이는 실용적이지 않습니다.
생성적 분류기
생성적 분류기를 소개합니다. 이것은 클래스 조건부 생성 모델을 사용한 간단한 분류 방법입니다. 입력 $`x`$를 분류하기 위해, 생성적 분류기는 먼저 클래스 조건부 생성 모델로 $`p_\theta(x | y)`$를 계산하고 베이즈 정리를 이용하여 $`p_\theta(y | x)`$를 얻습니다. 이 접근법은 선형 판별 분석이나 나이브 베이즈와 같은 방법으로 인기 있는 머신 러닝에서 사용되었지만, 심층 학습 시대에서는 주목받지 못했습니다. 우리는 이 접근법을 다시 살펴보고 깊은 학습 아키텍처를 사용하여 분포 변화에 대한 견고성의 장점을 보여줍니다 (섹션 5 참조). 알고리즘 15는 생성적 분류 프로세스 개요를 제공합니다.
직관
왜 생성적 분류기가 이러한 분포 이동에서 더 잘 작동할 수 있을까요? 판별적 분류기와 달리, 그들은 몇 가지 특이 패턴만 사용하여 학습 목표를 최소화할 수 있습니다. 반면에 생성적 분류기는 전체 입력 $`x`$를 모델링해야 합니다. 즉, 그들은 단순히 특이 패턴에 머물러 있지 않아야 하며, 학습 목표는 핵심적인 특징과 특이 패턴을 모두 학습하도록 강제합니다. 이는 훈련 과정에서 더 나은 학습 신호를 제공해야 합니다 (섹션 5.3 참조). 두 가지 유형의 특징을 학습하는 것은 입력 분류 시 동일하게 사용하지 않음을 의미하지 않습니다. 생성적 분류기는 레이블과 가장 일관되게 상관되는 특징을 배우고 그에 따라 가중치를 부여해야 합니다. 섹션 6.3 및 6.4에서는 간단한 가우시안 데이터 설정에서 이러한 인덕티브 편향을 보여줍니다.
확산 기반 생성적 분류기
이미지 분류에 있어서 우리는 현재 이미지 모델링의 최고 접근법인 확산 모델을 사용합니다. 확산 모델은 이미지를 점진적으로 노이즈를 제거하면서 훈련되며 단일 순방향 패스로 정확한 가능성을 계산할 수 없습니다. 그들은 일반적으로 $`\log p_\theta(x|y)`$의 재가중 변분 하한으로 훈련됩니다. 생성적 분류 프레임워크에 사용하기 위해, 우리는 그 값을 $`\log p_\theta(x \mid y)`$로 근사합니다:
\begin{align}
\log p_\theta (x \mid y) \approx \mathbb E_{\epsilon, t}[\|\epsilon_\theta(x_t, y) - \epsilon \|^2]
\label{eq:diffusion_elbo}
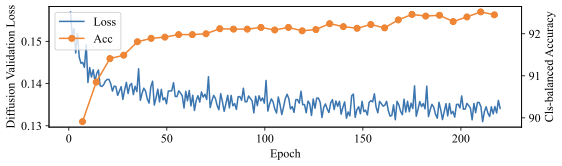
\end{align}클래스 조건부 확산 모델을 훈련하는 것은 일반적으로 수행됩니다 – 우리는 기본 학습 파이프라인을 사용하여 어떤 하이퍼파라미터도 수정하지 않고 확산 모델을 처음부터 훈련합니다. 추론 시에는 Diffusion Classifier 알고리즘에서 제시한 대로 여러 노이즈 $`\epsilon`$를 샘플링하고 이를 이미지에 추가하여 노이즈된 $`x_t = \sqrt{\Bar{\alpha}_t} x + \sqrt{1 - \Bar{\alpha}_t} \epsilon`$을 얻고, 네트워크를 여러 차례 순방향 패스하여 Eq. [eq:diffusion_elbo]의 몬테카를로 추정치를 얻습니다. 이는 각 클래스에 대해 수행되며, 가장 높은 조건부 가능도 $`\log p_\theta(x \mid y)`$, 즉 가장 낮은 노이즈 제거 오차가 있는 클래스가 선택됩니다.
자동회귀 생성적 분류기
텍스트 분류를 위해 우리는 자동회귀 트랜스포머 모델 위에 생성적 분류기를 소개합니다. 이는 텍스트 모델링의 주요 아키텍처입니다. $`p_\theta(x \mid y)`$를 학습해야 하므로 $`x`$는 텍스트 토큰 시퀀스이고 $`y`$는 레이블입니다. 우리는 학습 절차에 작은 수정을 가합니다. 텍스트 토큰 시퀀스의 시작에 “시작 토큰” (BOS)을 사용하는 대신, 사전에서 각 클래스당 하나씩 $`C`$ 개의 특별한 클래스 토큰을 할당하고 BOS를 원하는 클래스 토큰으로 바꿉니다. $`\log p_\theta(x \mid y)`$는 단일 순방향 패스로 얻을 수 있습니다:
\begin{align}
\log p_\theta(x \mid y) = \log \left(\prod_{i=1}^n p_\thet
</div>
<div style="margin-top: 20px;"><a href="https://arxiv.org/pdf/2512.25034.pdf" target="_blank">ArXiv 원문 PDF 보기</a></div>
<div class="mobile-ad w-full my-6 text-center" style="border: 2px dashed red; background: #ffe6e6;"><ins class="adsbygoogle" style="display:block" data-ad-client="ca-pub-1873718820012422" data-ad-slot="auto"></ins><script>(adsbygoogle = window.adsbygoogle || []).push({});</script></div>
<br>
<h4>📊 논문 시각자료 (Figures)</h4>

<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>

<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>

<br>
<br>
<br>
<br>
<br>
<br>

<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<h4 style="margin-top: 3rem; margin-bottom: 1rem; border-bottom: 1px solid #e5e7eb; padding-bottom: 0.5rem;">감사의 말씀</h4>
이 글의 저작권은 연구하신 과학자분들께 있으며, 인류 문명 발전에 공헌해주신 노고에 감사를 드립니다.