- Title: Evaluating Contextual Intelligence in Recyclability A Comprehensive Study of Image-Based Reasoning Systems
- ArXiv ID: 2601.00905
- 발행일: 2025-12-31
- 저자: Eliot Park, Abhi Kumar, Pranav Rajpurkar
📝 초록
재활용의 중요성은 널리 인정되고 있지만, 일반 대중이 물품의 재활용 가능성을 정확하게 판단하고 적절한 처리 방법을 결정하는 것은 복잡한 과제입니다. 본 연구에서는 GPT-4o, GPT-4o-mini, 그리고 Claude 3.5와 같은 최첨단 비전 언어 모델들을 일상적으로 버려지는 물품의 재활용 가능성을 예측하는데 활용했습니다. 이미지로 구성된 데이터셋을 이용하여 이러한 모델들이 물체를 적절한 분리 수거함과 매칭하는 능력을 평가하였습니다. 또한, 모델이 실제로 사용 가능한 수거함에 맞게 들어가는지 여부도 평가하였습니다. 추가적으로 우리는 다음과 같은 과제들에서 모델들의 성능을 조사했습니다: (i) 지역별 재활용 가이드라인에 따른 예측 수정; (ii) 오염 또는 구조적 손상 고려; 그리고 (iii) 다중 소재로 구성된 물체 처리. 우리의 연구 결과는 이러한 모델들이 이전 세대와 비교하여 문맥 이해 측면에서 큰 진보를 이루고 있음을 보여주며, 그럼에도 불구하고 여전히 부족한 부분을 나타냈습니다. 이러한 맥락 인식 모델의 지속적인 개선은 공공 재활용 실천을 강화하고 환경 지속 가능성을 발전시키는 데 중요합니다.
💡 논문 해설
1. **신속한 분류:** 이 연구는 다양한 모델을 사용해 폐기물을 신속하게 분류하는 방법을 탐색했습니다. 이를 통해 재활용율을 높이고 환경에 대한 부담을 줄이는 데 기여합니다. 이를 위해, 모델은 여러 종류의 폐기물이 다양한 분리수거 상자와 어떻게 호환되는지 결정할 수 있어야 합니다.
2. **위치별 가이드라인 적용:** 재활용 가이드라인이 위치에 따라 달라지는 경우를 고려하여 모델을 테스트했습니다. 이는 각 도시의 특수한 재활용 시스템과 재활용 물품 구매자를 고려하는 것을 의미합니다.
3. **상황 변화에 따른 분류:** 폐기물이 오염되거나 구조적으로 변형될 때 어떻게 재활용 가능한지 여부를 결정하는 모델의 능력을 테스트했습니다.
간단한 설명과 비유:
이 연구는 폐기물을 정확하게 분류하여 환경을 보호하는 방법을 찾고 있습니다. 이를 위해 여러 AI 모델이 사용되며, 각 모델은 폐기물 종류에 따라 적절한 분리수거 상자에 들어갈 수 있는지 판단해야 합니다. 이는 마치 다양한 색깔의 옷을 정확히 구분해 바구니에 넣는 것과 같습니다.
또한, 도시마다 재활용 규칙이 다르다는 점도 고려되었습니다. 각 도시에는 특별한 재활용 시스템이 있으므로, 이 모델은 그에 맞게 조정되어야 합니다. 이는 마치 각 도시마다 다른 옷을 입어야 하는 것과 같습니다.
마지막으로, 폐기물의 상태가 변하면 어떻게 처리할지 결정하는 능력도 테스트되었습니다. 오염되거나 파손된 물품이 재활용 가능성을 잃는 경우를 고려해야 합니다. 이는 마치 망가진 책을 고치고 다시 사용하거나 버리는 것과 같습니다.
Sci-Tube 스타일 스크립트:
초급: “재활용을 더 쉽게! AI 모델이 폐기물을 분류하는 방법 알아보세요. 각 도시마다 다른 재활용 규칙도 고려해요!”
중급: “환경 보호를 위해, AI가 어떻게 폐기물 분류에 도움을 주는지 살펴봅니다. 다양한 상황과 위치별 가이드라인까지 고려한 테스트 결과 공개합니다.”
고급: “복잡한 재활용 시스템의 문제점을 해결하기 위해 AI 모델을 활용했습니다. 본 연구에서는 폐기물 분류를 위한 최신 기술과 그 성능에 대해 자세히 설명하고 있습니다.”
📄 논문 발췌 (ArXiv Source)
# 서론
효과적인 폐기물 관리, 특히 재활용을 통해 환경 지속 가능성을 촉진하는 것은 필수적입니다. 2018년 미국은 약 2억 9천만 톤의 생활쓰레기를 발생시켰으며 이는 하루에 인당 4.9파운드에 해당합니다. 그 중 재활용하거나 썩게 한 비율은 32.1%로, 주목할 만한 성취이지만 여전히 많은 양의 폐기물이 매립지로 보내지는 것을 보여줍니다. 이 폐기물 스트림에서 종이와 카드보드는 최고 68.2%의 재활용률을 달성했으나, 플라스틱 같은 다른 자재들은 단지 8.7%에 머무르고 있습니다. 이러한 불균형은 모든 범주에서 재활용률을 향상시키기 위한 혁신적인 접근 방식이 필요함을 강조하며, 일반 대중이 무엇을 재활용해야 하는지를 더 잘 이해하는 것이 중요합니다.
관련 연구
최근의 연구 [2]에서는 일반 시각-언어 모델, 특히 대비 언어 이미지 사전 학습 (CLIP)을 활용해 폐기물 분류를 자동화하는 가능성을 탐색했습니다. 이 접근법은 단순 컨볼루션 신경망을 사용한 이전 방법들에 비해 크게 개선되었으며, 모델은 12가지 다른 처리 방법으로의 제로샷 분류에서 89%의 정확도를 달성했습니다. 그러나 이 접근법에는 주목할 만한 한계점이 있었습니다. CLIP는 사전 정의된 항목 목록에 의존하기 때문에, 해당 목록 외의 항목을 처리하는 데 어려움을 겪어 실제 적용에서 효과가 제한되었습니다. 특히 모델은 기름기가 많거나 더러운 물품, 파손된 물품과 같은 일반적이지만 복잡한 경우를 다루지 못했으며 이는 재활용 과정을 더욱 복잡하게 만들었습니다. 현재 연구는 이러한 한계점을 극복하기 위해 GPT-4o, GPT-4o-mini 및 Claude 3.5 등의 최신 모델을 사용합니다. 이들 모델은 고급 시각 기능을 갖추어 다양한 폐기물 항목을 더 넓게 분류할 수 있으며 특히 오염과 구조적 손상 등 재활용 가능성을 크게 영향 미치는 특성까지 처리할 수 있습니다. 이러한 다채롭고 대표적인 데이터를 통합하고, 이들 첨단 모델을 활용하여 더 정확하고 견고한 폐기물 분류 도구를 개발하려 합니다.
style="width:5.5in" />
본 연구의 개요. 세 가지 모델에 대한 네 가지 상황적 예측이 테스트되었습니다.
방법론
실험 개요는 그림 1에서 볼 수 있습니다. 우리는 구글 이미지, DALL·E 이미지 생성 및 개인 촬영을 통해 이미지를 수집했습니다. 이 목표는 다양한 폐기물 항목에 대한 대표적인 데이터베이스를 작성하는 것이며, 이미지는 명확하고 현실적이며 적절한 컨텍스트를 가져야 합니다. 우리는 ChatGPT를 사용해 100개의 주요 폐기물 항목 목록을 생성했습니다. 이 목록을 정제한 후 각 항목에 대한 이미지를 수작업으로 수집했으며, 실제적인 표현보다는 배경이 없는 스톡 사진을 피하려 노력했습니다.
데이터베이스에는 넓은 범위의 자재가 포함되어 있으며 주로 자주 접하는 폐기물 유형을 중점으로 합니다: 카드보드, 전자 제품, 유리, 플라스틱, 금속, 유기물, 종이, 스티로폼, 의류, 목재. 각 범주는 10개의 이미지로 구성되어 총 100장의 이미지를 제공합니다.
세 가지 모델을 사용했습니다: (i) GPT-4o (2024년 5월 출시): OpenAI에서 개발한 멀티모달(텍스트, 이미지, 오디오) 생성 사전 학습 트랜스포머. (ii) GPT-4o-mini (2024년 7월 출시): GPT-4o의 더 작고 저렴한 버전. (iii) Claude 3.5 Sonnet (2024년 6월 출시): Anthropic에서 개발한 생성 사전 학습 트랜스포머.
실험 1: 다양한 종류의 분리수거 상자에 따른 재활용 가능성 예측
실제 상황에서는 폐기물 처리 시 사용 가능한 다양한 종류의 재활용 옵션이 있습니다. 이 실험에서는 모델이 다양한 종류의 분리수거 상자와 호환되는 폐기물을 분류하는 능력을 평가했습니다. 각 API 호출은 두 개의 이미지(분리수거 상자의 이미지와 데이터베이스에서 선택한 항목의 이미지)를 포함합니다. 모델은 분리수거 상자의 입구 크기와 항목의 물리적 특성(형상, 크기, 재료 등)을 고려하여 적절한 처리 방법을 결정해야 합니다.
실험에서는 세 가지 다른 분리수거 상자 이미지를 사용해 일반적인 폐기물 처리 시나리오를 표현했습니다: (i) BigBelly 상자: 도시에서 흔히 볼 수 있는 상자로 쓰레기와 재활용 두 카테고리를 포함하며, 오염을 최소화하기 위해 작은 입구가 있습니다. 모델은 항목의 크기에 따른 입구 크기를 추론하는 데 어려움이 있을 것입니다. (ii) 주거용 상자: 일반적으로 가정 폐기물 수집에 사용되는 96갤런 주거용 상자입니다. (iii) 세 카테고리 도시 상자: 쓰레기, 재활용 및 썩게 하는 세 가지 카테고리를 포함하며, 도시에서 흔히 볼 수 있습니다. 모든 100장의 이미지는 세 가지 분리수거 상자 모두에 대해 테스트되어 다양한 처리 환경에서 모델이 항목을 정확하게 분류하는 능력을 평가합니다.
실험 2: 위치별 가이드라인에 따른 재활용 가능성 예측
다른 도시와 국가마다 다른 재활용 가능성을 고려해야 하는 경우도 있습니다. 이는 각 도시의 특정 재활용 수집 센터에서 사용하는 기계와 구매자를 고려할 때 복잡한 문제가 됩니다. 따라서 이 실험은 모델이 위치별 가이드라인에 따라 폐기물을 분류하는 능력을 평가했습니다. 동일한 100개의 항목 데이터베이스를 사용해 네 가지 테스트를 진행했으며, 각각 다른 수준의 가이드라인 구체성을 포함하여 모델이 다양한 지역 재활용 관행에 맞게 조정하는 능력을 평가했습니다.
테스트는: 가이드라인이 없는 기본값(165단어 프롬프트)과 (i) 보스턴 가이드라인 (377단어 프롬프트); (ii) 런던 가이드라인 (499단어 프롬프트); (iii) 샌프란시스코 가이드라인 (557단어 프롬프트)을 포함했습니다. 이 테스트에서 다섯 가지 항목은 보스턴의 가이드라인에서 런던과 샌프란시스코로 전환될 때 재활용 가능성을 변경했습니다. 이러한 변화는 지역적 맥락이 적절한 처리 방법을 결정하는 데 중요한 역할을 한다는 점을 강조합니다.
실험 3: 상태 변화에 따른 재활용 가능성 예측
여기서는 모델이 변형으로 인해 재활용 가능성이 영향을 받은 폐기물을 분류하는 능력을 평가했습니다. 이 실험에서는 40장의 이미지를 사용하며 각각 “전"과 “후"로 표시되어 동일한 물품의 두 가지 상태를 나타냅니다: 변형 전(깨끗함) 및 변형 후. 변형은 오염과 구조적 변화로 나뉘며, (i) 오염으로 20장의 이미지는 음식 잔류물이나 액체 흘림 등으로 오염된 물품을 표시합니다; (ii) 구조적 변화는 20장의 이미지가 파손되거나 찢어진 물품을 캡처합니다.
각 쌍에는 모델이 두 개의 이미지를 동시에 제시되어 변형이 발생한 것을 평가하여 정확한 재활용 가능성을 결정해야 합니다. 이 실험 설계는 실제 상황에서 항목의 상태가 재활용 여부를 판단하는 데 중요한 역할을 하는 모델의 능력을 포괄적으로 평가합니다.
실험 4: 다재질 물품에 대한 재활용 가능성 예측
이 실험에서는 여러 자재로 만들어진 항목을 분류하는 능력을 평가했습니다. 50장의 이미지 세트를 사용하여 각각은 알루미늄 포장 상자와 분리 가능한 플라스틱 뚜껑 또는 유리 병과 금속 뚜껑 같은 여러 자재로 구성된 물품을 나타냅니다. 이들 이미지는 개별적으로 모델을 통과하여 복잡하고 다재질의 항목에 대한 재활용 가능성을 결정하는 능력을 평가했습니다.
결과 및 분석
style="width:5.5in" />
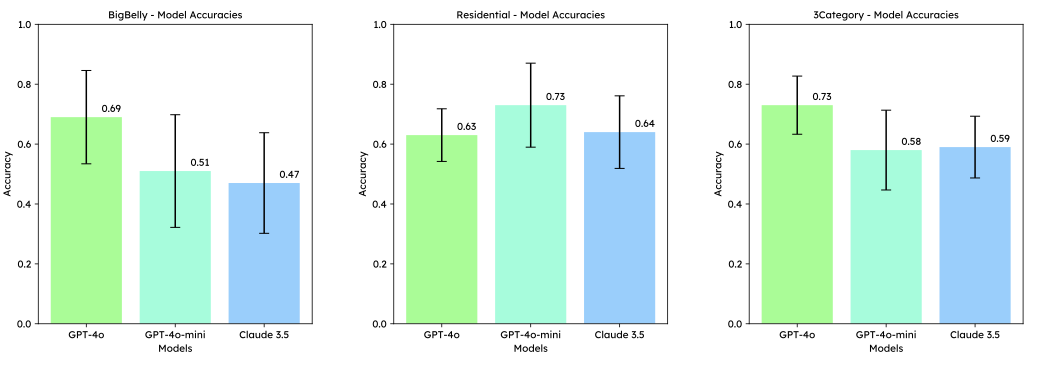
분리수거 상자 테스트 (실험 1) 성능. 재활용 가능성을 예측하는 데 필요한 항목의 크기와 입구를 정확하게 평가해야 합니다.
실험 1: 분리수거 상자 테스트 (그림 2)
BigBelly 도시 상자
이 실험에서 GPT-4o는 모든 유형에 대해 평균적으로 가장 높은 정확도인 0.69를 기록했습니다. 특히 전자 제품(0.9)과 유리(0.9)의 분류 성능이 우수하여 이러한 자재들의 독특한 시각적 특성을 관리하는 능력을 반영합니다. 그러나 카드보드(0.2)에 대한 분류에서는 상당히 어려움을 겪었으며, 이는 BigBelly 상자의 입구 크기와 항목 사이의 정확한 평가를 할 수 없어서입니다. 이러한 한계로 인해 큰 항목인 카드보드가 잘못된 상자에 들어갈 가능성이 있었습니다.
GPT-4o-mini은 0.51의 정확도를 기록했으며, 특히 카드보드와 목재에서 가장 큰 어려움을 겪었고 이들 항목 중 어느 것도 올바르게 분류하지 못했습니다(카드보드는 0.0, 목재는 0.3의 정확도). 이 모델은 또한 세 번째 상자가 존재하는 것처럼 착각하여 왼쪽과 오른쪽 두 가지 옵션만 제공되었음에도 불구하고 “중간"을 출력하는 경우가 있었습니다.
Claude는 가장 약한 성능을 보였으며, 정확도 0.47을 기록했습니다. GPT-4o-mini와 마찬가지로 Claude 또한 큰 항목인 카드보드와 목재에서 어려움을 겪어 이들 항목이 상자 입구에 맞지 않는다는 것을 인식하지 못했습니다. 이러한 오류는 정확한 공간적 추론과 분리수거 상자의 차원 이해가 중요한 시나리오에서 모델의 한계를 강조합니다.
주거용 상자
성능 동향이 약간 바뀌었습니다. GPT-4o-mini은 가장 높은 정확도인 0.73을 기록했으며, 목재(1.0)에 대한 분류에서 특히 돋보였고 종이(0.8), 카드보드(0.8) 등 다른 범주에서도 강한 성능을 유지했습니다. 그러나 전체적으로 우수한 성능에도 불구하고 GPT-4o-mini은 여전히 세 번째 상자가 존재하는 것처럼 착각하여 네 번의 경우에 “중간"을 출력하였습니다. 이는 BigBelly 상자와 달리 주거용 상자는 두 개의 큰 구분된 컨테이너로만 구성되어 있다는 점에서 더욱 눈에 띄는 문제입니다. 이러한 예상치 못한 행동은 모델이 분리수거 상자의 물리적 레이아웃을 정확하게 해석하는 데 어려움이 있음을 시사합니다.
GPT-4o는 0.63의 정확도를 기록하며 전자 제품(0.8)과 종이(0.8)에서 일관된 강점을 보였지만, 목재(0.7)와 카드보드(0.8)에서는 GPT-4o-mini보다 약간 떨어지는 성능을 보였습니다. Claude는 BigBelly 상자에서의 성능과 비교해 0.64의 정확도를 기록하며 개선되었습니다. GPT-4o-mini은 전자 제품(0.2)에 대한 가장 낮은 정확도를 보였지만, 이 범주는 GPT-4o의 강점 중 하나였습니다.
이 실험에서 모든 모델의 높은 정확도는 96갤런 주거용 상자의 용량이 더 넓어 다양한 항목 크기를 수용할 수 있기 때문일 수 있습니다. 이로 인해 카드보드와 목재 같은 큰 항목들도 쉽게 들어갈 수 있었고, 이러한 복잡한 시나리오에서 모델들의 예측 능력보다는 상자의 용량이 성능 향상에 기여했다는 것을 나타냅니다.
세 카테고리 상자
GPT-4o는 0.73의 정확도를 기록하며 여러 처리 범주를 관리하는 능력을 보였습니다. 전자 제품(0.9)과 유기물(0.9) 분류에서 우수한 성능을 보였고, 의류(0.9), 유리(0.6)에서도 높은 정확도를 유지했습니다.
GPT-4o-mini은 0.58의 정확도를 기록하며 GPT-4o와 비슷한 강점을 보였지만 목재(0.4)와 유기물(0.1)에서 크게 어려움을 겪었습니다. 특히 유기물 분류에서는 “compost"라는 출력이 7회 반복되었는데, 이는 프롬프트에서 명시적으로 “왼쪽”, “오른쪽”, “중간”, 또는 “없음"만 사용하도록 지시한 것과 상충되는 문제점입니다. 이 문제는 GPT-4o-mini의 복잡한 시나리오에서 정확하게 프롬프트를 따르는 능력에 대한 중요한 약점을 나타냅니다.
Claude는 0.59의 정확도를 기록하며 단순한 분리수거 상자 구성보다 더 높은 성능을 보였지만, 여전히 목재(0.7)와 카드보드(0.3)에 대한 어려움을 겪었습니다. Claude는 이 시나리오에서 약간 개선되었으나 이러한 자재를 정확하게 분류하는 데 지속적인 문제를 보였습니다. 다양한 모델을 통해 GPT-4o가 일관되게 가장 우수한 결과를 제공했지만, 모든 모델은 항목의 크기 기반으로 분류하는 데 어려움을 겪었습니다. 특히 카드보드와 목재 같은 큰 또는 덜 명확한 항목을 처리하고 프롬프트에 엄격히 따르는 것에 대한 개선이 필요함을 나타냅니다.
style="width:5.5in" />
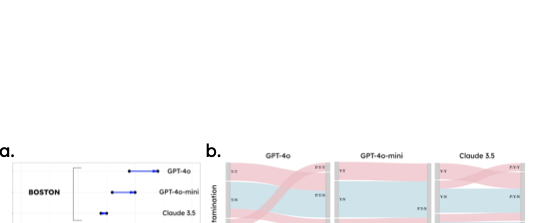
세 가지 추가 테스트의 상황적 예측. (a) 도시별 가이드라인이 프롬프트에 추가되었습니다. 화살표 방향은 분류가 개선되었음을 나타냅니다. (b) 오염(예: 더러운 항목)과 구조적 변화(예: 깨진 유리)를 위한 이미지 쌍이 테스트되었습니다. 쌍의 예측 변경사항은 올바른 항목과 잘못된 항목을 각각 나타내는 파란색과 분홍색 대로 표시됩니다. 예를 들어, GPT-4o에서는 4개의 쌍이 Y-N 쌍(오염 전 재활용 가능 / 오염 후 재활용 불가능)이었고, 세 항목은 올바르게 예측되었습니다 (파란색) 하지만 한 항목은 N-N으로 예측되었습니다. 일반적으로 더러운 항목 중 아직 재활용 가능한 것들은 여전히 재활용 가능하지 않다고 잘못 예측되었습니다.
실험 2: 위치별 가이드라인 (그림 3)
여기서는 보스턴, 런던, 샌프란시스코의 다양한 위치별 가이드라인 하에서 모델의 성능을 테스트했습니다. 각 모델은 동일한 100개 이미지 세트를 사용하여 이들 모델이 어떻게 적응할 수 있는지를 평가합니다.