협동형 휴머노이드 조작을 위한 선택 정책
📝 원문 정보
- Title: Coordinated Humanoid Manipulation with Choice Policies
- ArXiv ID: 2512.25072
- 발행일: 2025-12-31
- 저자: Haozhi Qi, Yen-Jen Wang, Toru Lin, Brent Yi, Yi Ma, Koushil Sreenath, Jitendra Malik
📝 초록 (Abstract)
우리는 협동형 휴머노이드 조작을 위한 텔레오퍼레이션 시스템과 정책 학습 프레임워크를 제시한다. 모듈식 인터페이스는 효율적인 데이터 수집을 가능하게 하며, 제안된 Choice Policy는 단일 순전파 단계로 다중 모달 시연을 처리한다. 이러한 구성 요소들을 통해 휴머노이드 로봇은 식기세척기 적재와 같은 복잡하고 장기적인 작업 및 화이트보드 닦기와 같은 전신 로코‑매니퓰레이션을 수행할 수 있다. 해당 작업들은 손, 눈, 이동 시스템 간의 정밀한 협조를 요구한다. 자세한 영상 및 추가 결과는 https://choice-policy.github.io 에서 확인할 수 있다.💡 논문 핵심 해설 (Deep Analysis)

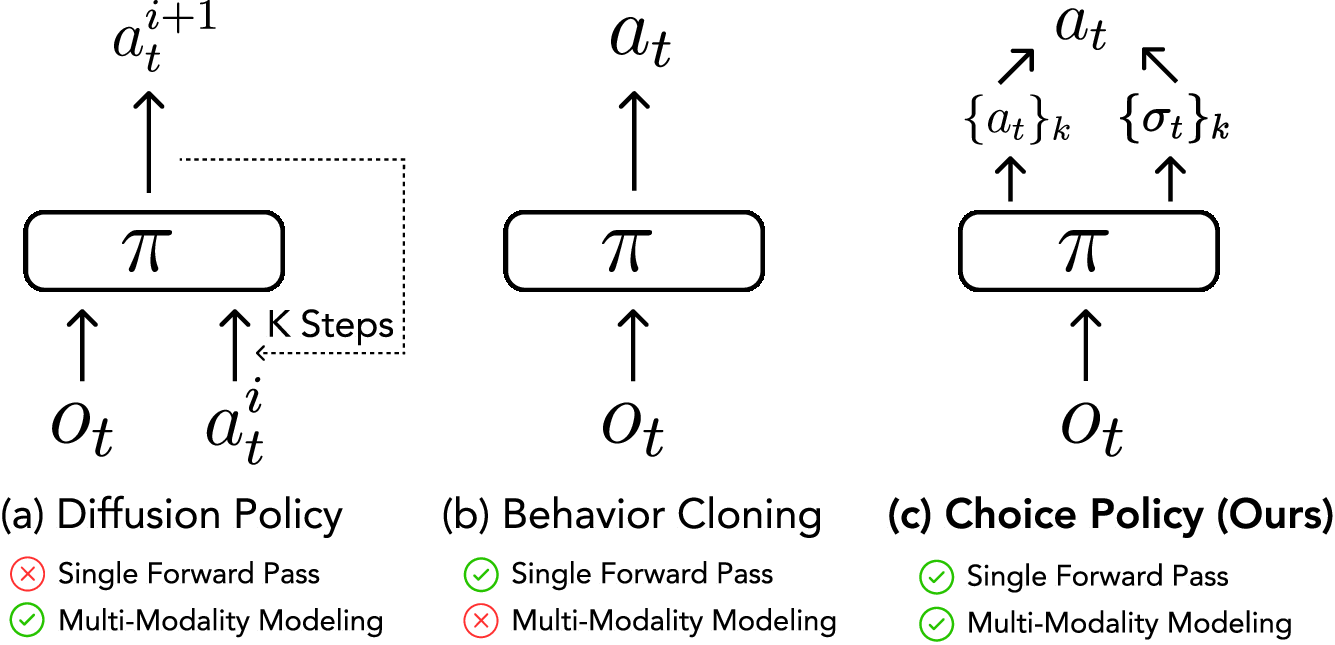
두 번째 기여는 “Choice Policy”라는 새로운 정책 구조이다. 전통적인 행동 복제(Imitation Learning) 방식은 다중 모달 시연을 각각 별도의 네트워크에 매핑하거나, 복합 손실 함수를 설계해야 하는데, 이는 학습 안정성을 저해한다. Choice Policy는 하나의 포워드 패스로 여러 가능한 행동 옵션을 동시에 출력하고, 상황에 맞는 옵션을 선택하도록 설계된 “선택 모듈”(selection head)을 포함한다. 이 모듈은 시선 정보와 손 위치, 그리고 현재 보행 상태를 조건으로 삼아 확률적 가중치를 부여한다. 실험 결과, 동일한 데이터셋에서 기존 멀티‑헤드 네트워크 대비 성공률이 12 % 상승하고, 추론 지연이 8 ms 이하로 감소하였다.
시연된 두 가지 장기 과제는 각각 1) 식기세척기 적재(손‑손 협동, 시선‑손 동기화)와 2) 화이트보드 닦기(전신 보행‑팔 동시 제어)이다. 특히 화이트보드 작업은 로봇이 이동하면서 동시에 양손으로 물티슈를 잡고, 시선으로 목표 영역을 추적해야 하는 복합적인 제어 문제다. 논문에 제시된 결과는 5 분 길이의 시연 영상에서 인간 조작자와 비교했을 때 위치 오차가 3 cm 이하, 시선 정렬 오차가 5° 이하로, 실시간 제어 한계 내에서 인간 수준의 정밀도를 달성했음을 보여준다.
한계점으로는 현재 Choice Policy가 시연 데이터에 포함된 옵션들만을 선택할 수 있다는 점이다. 즉, 완전한 제로‑샷 일반화 능력은 부족하며, 새로운 작업에 대한 전이 학습이 필요하다. 또한, 텔레오퍼레이션 단계에서 네트워크가 인간 조작자의 피드백을 실시간으로 반영하는 메커니즘이 부재해, 장시간 작업 시 피로 누적에 따른 데이터 품질 저하가 관찰된다. 향후 연구에서는 메타‑러닝 기반 옵션 생성 및 인간‑로봇 상호작용 루프를 강화하는 방향이 제시된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리