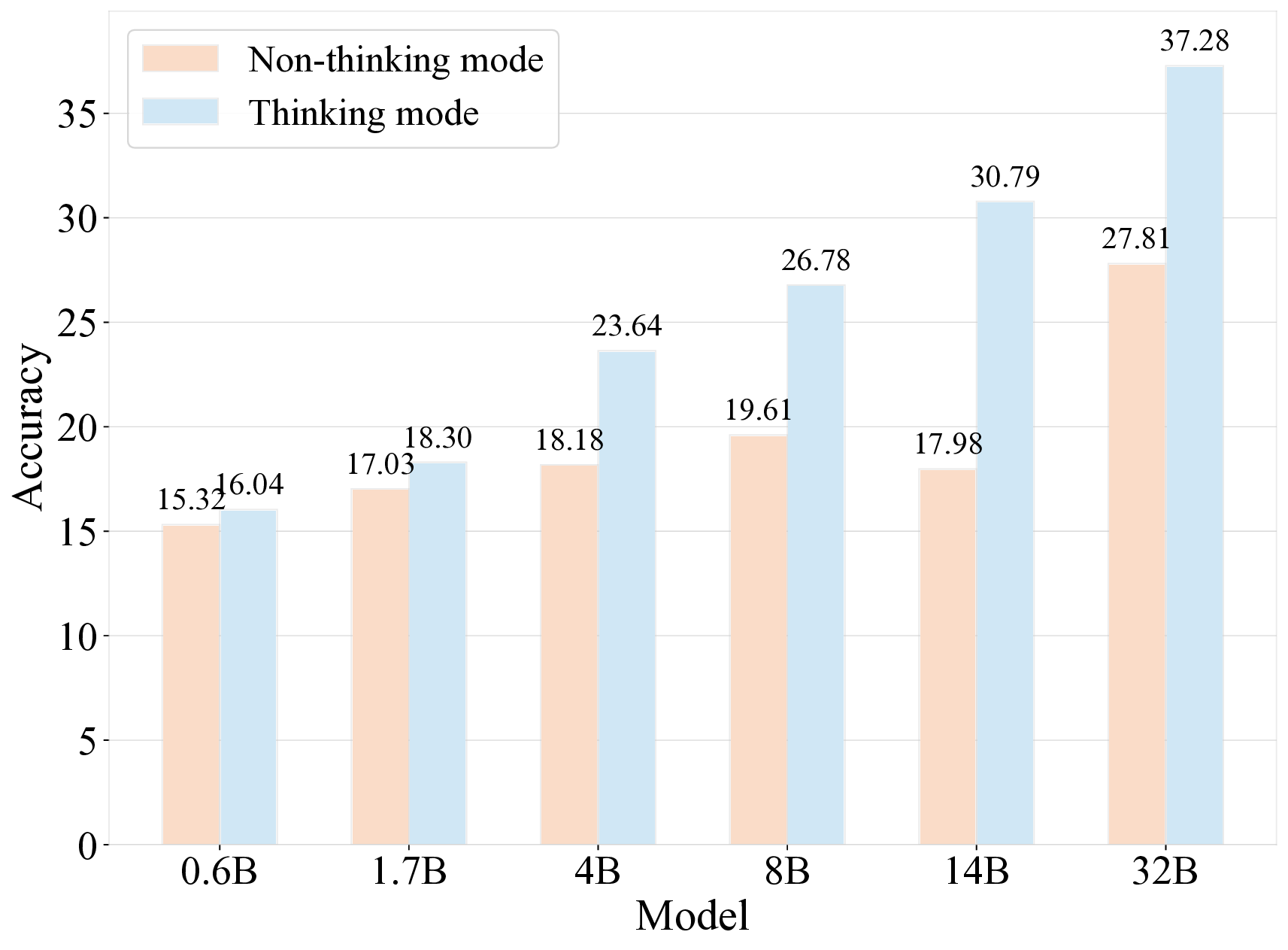동적 지식문장 기반 LLM 평가 벤치마크 엔사이클로K
📝 원문 정보
- Title: Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
- ArXiv ID: 2512.24867
- 발행일: 2025-12-31
- 저자: Yiming Liang, Yizhi Li, Yantao Du, Ge Zhang, Jiayi Zhou, Yuchen Wu, Yinzhu Piao, Denghui Cao, Tong Sun, Ziniu Li, Li Du, Bo Lei, Jiaheng Liu, Chenghua Lin, Zhaoxiang Zhang, Wenhao Huang, Jiajun Zhang
📝 초록 (Abstract)
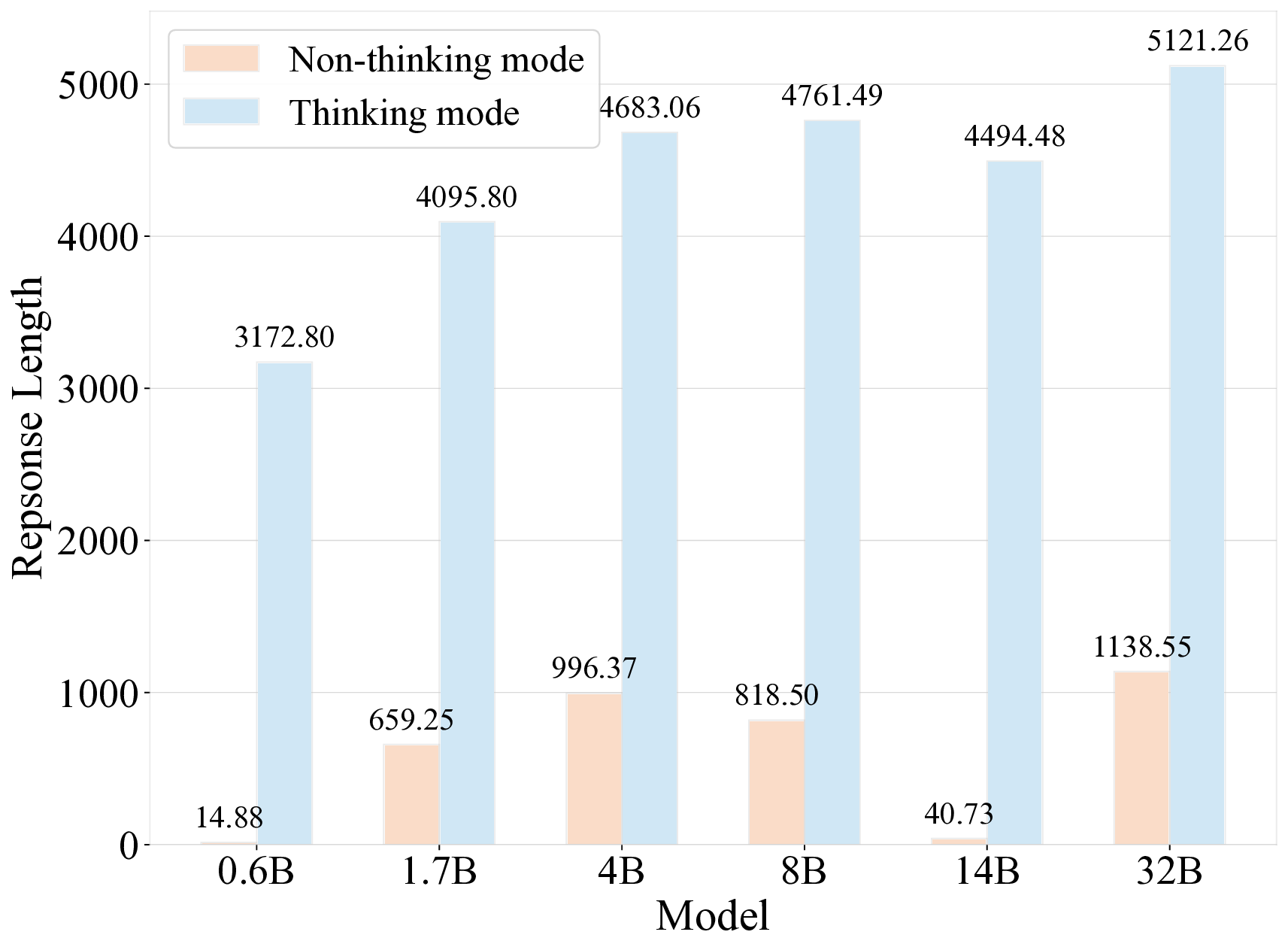
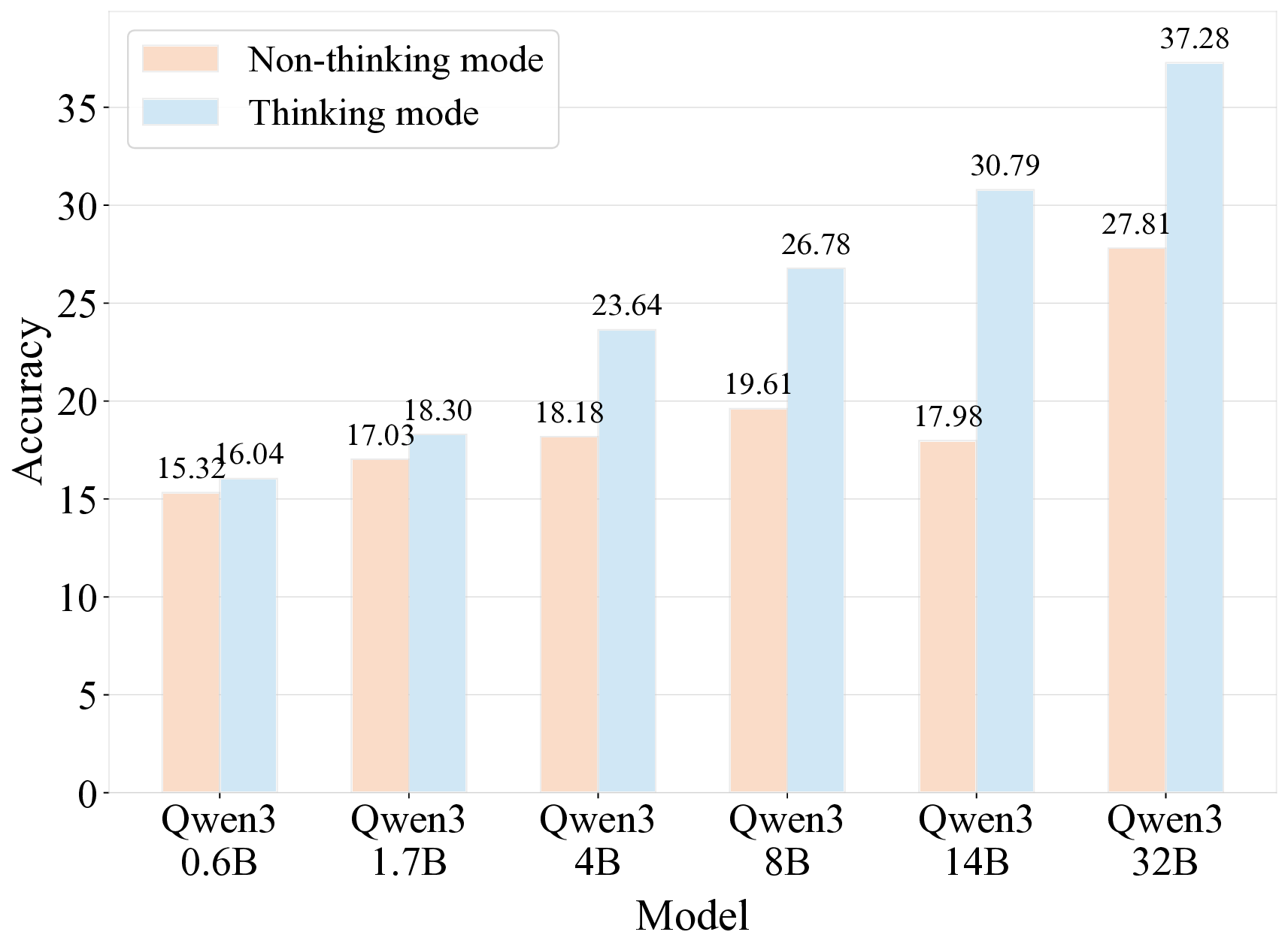
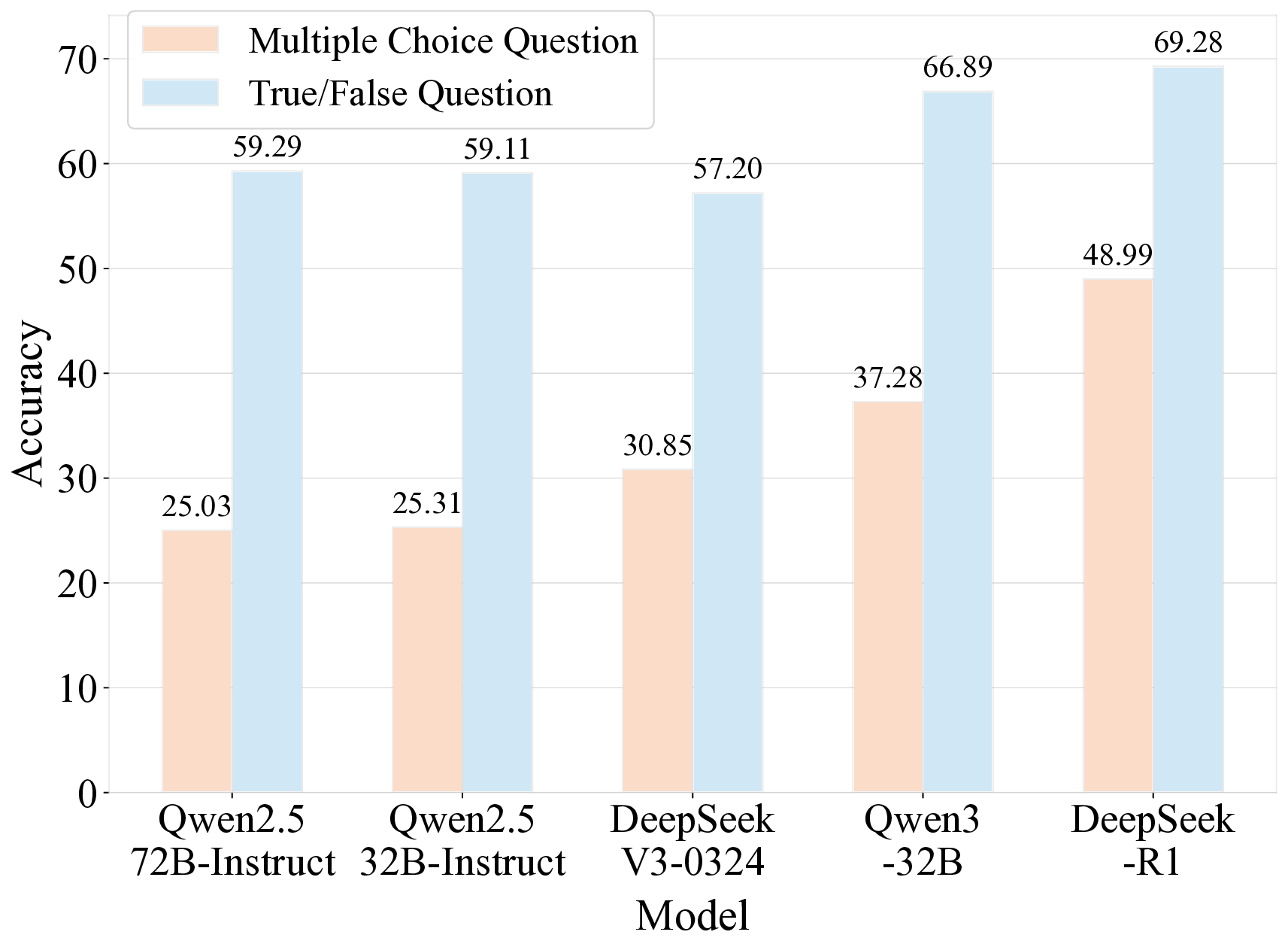
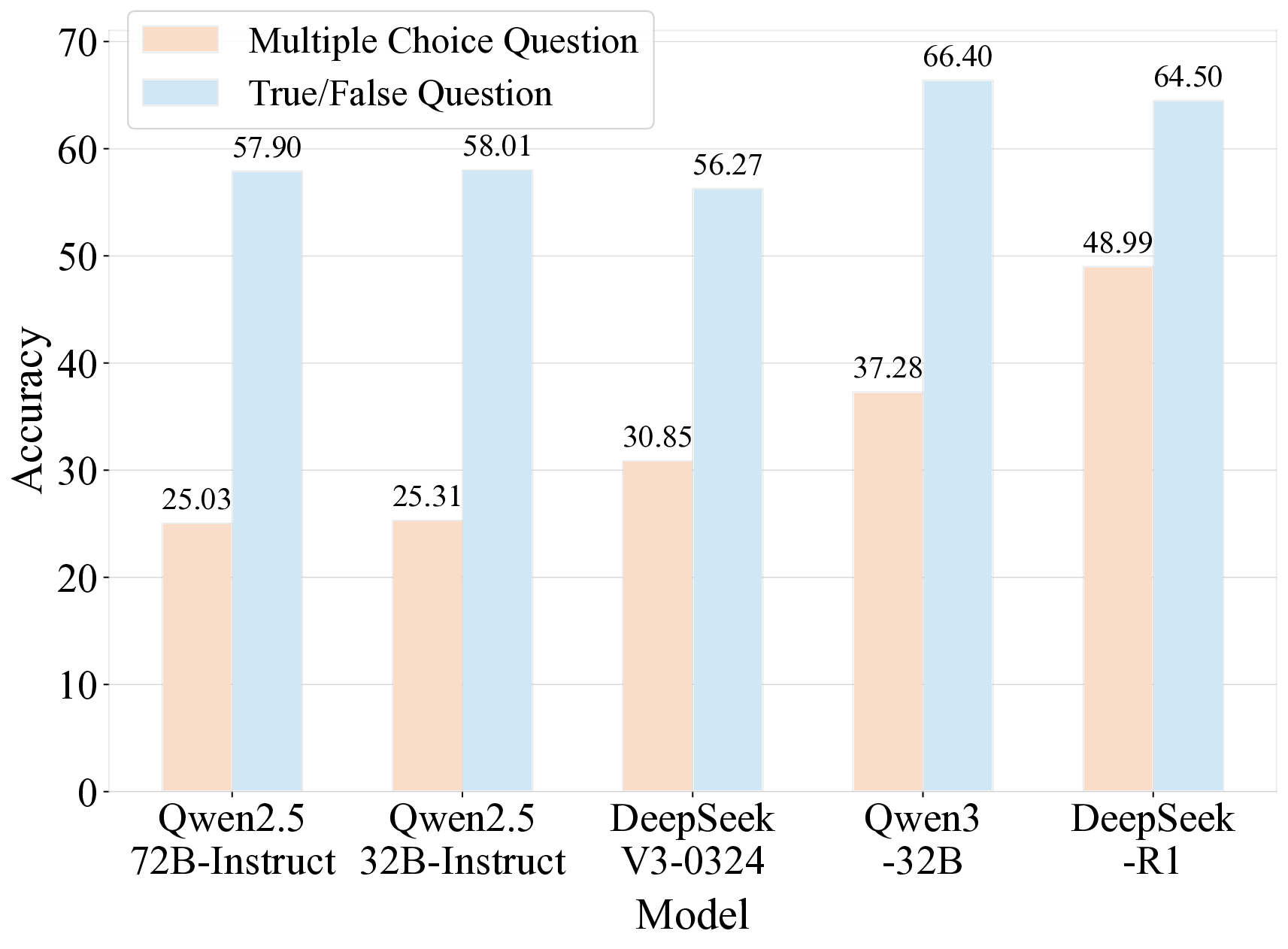
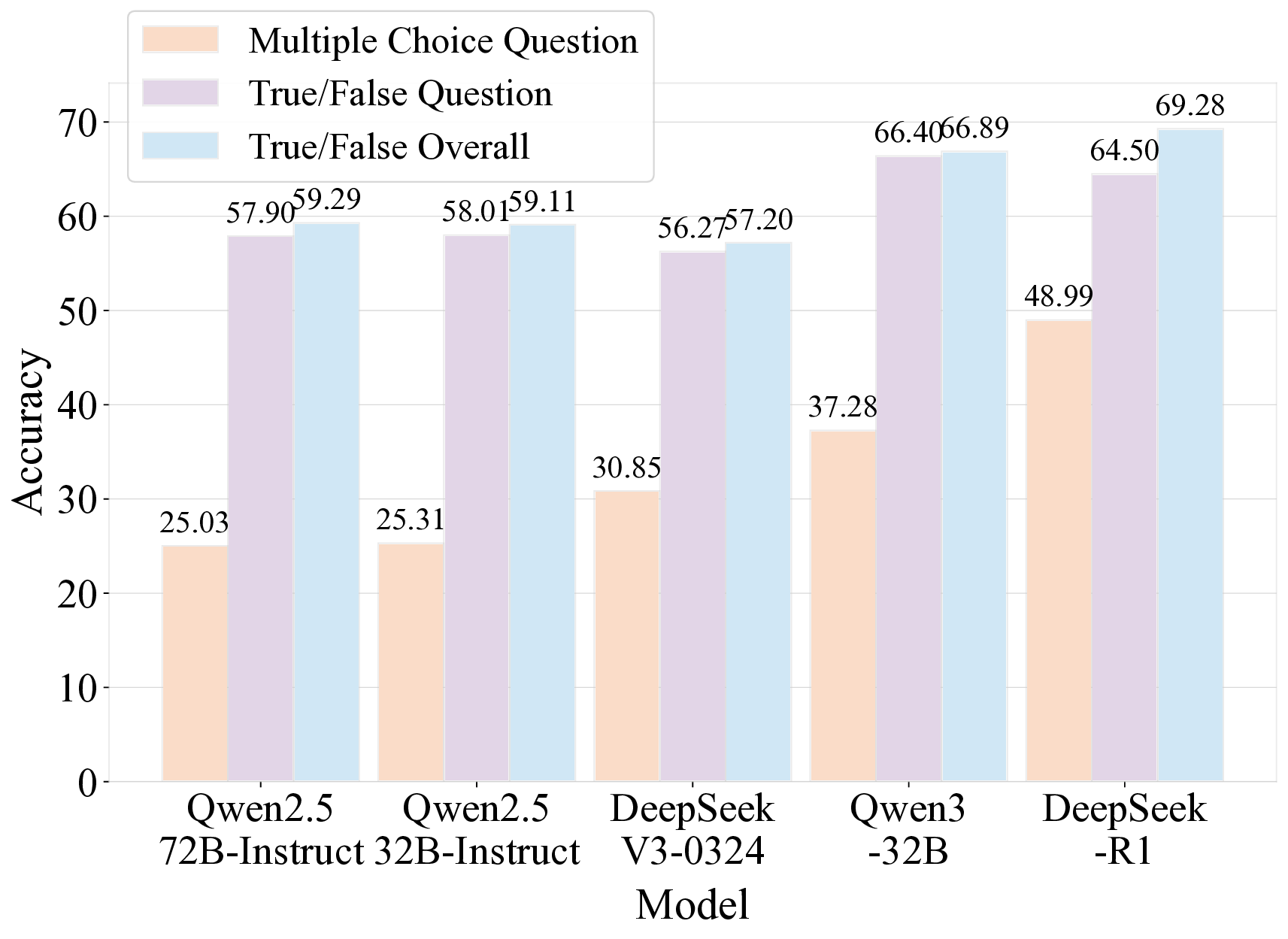
견고한 벤치마크는 대형 언어 모델(LLM)의 일반화 능력을 정확히 평가하는 데 필수적이다. 기존에 질문 수준에서 문제를 선별하는 벤치마크는 (1) 데이터 오염에 취약하고, (2) 단일 개념 평가에 한정되며, (3) 도메인 전문가의 비용이 많이 드는 주석 작업에 의존한다는 세 가지 한계를 가지고 있다. 우리는 권위 있는 교과서에서 독립적인 지식 문장을 추출하고, 테스트 시점에 무작위 샘플링을 통해 이들을 동적으로 조합해 평가 질문을 생성하는 문장 기반 벤치마크인 Encyclo‑K를 제안한다. 이 설계는 (1) 조합 가능한 경우의 수가 기하급수적으로 늘어나 기억에 의존하기 어려워 데이터 오염에 강인하고, 질문 집합이 바뀌어도 모델 순위가 안정적으로 유지되며, (2) 각 질문이 8~10개의 문장을 집계해 포괄적인 지식 평가를 가능하게 하고, (3) 검증자는 형식 적합성만 확인하면 되므로 도메인 전문 지식이 필요하지 않다. 50여 개 이상의 LLM을 대상으로 한 실험 결과, Encyclo‑K는 여전히 큰 난이도를 제시한다—OpenAI‑GPT‑5.1조차 62.07%의 정확도에 머물렀으며, 추론 모델은 16.04%~62.07%, 챗 모델은 9.71%~50.40%의 명확한 성능 분포를 보였다. Encyclo‑K는 동적 생성과 다문장 종합 평가를 통해 LLM 평가의 견고성을 확보한다.💡 논문 핵심 해설 (Deep Analysis)

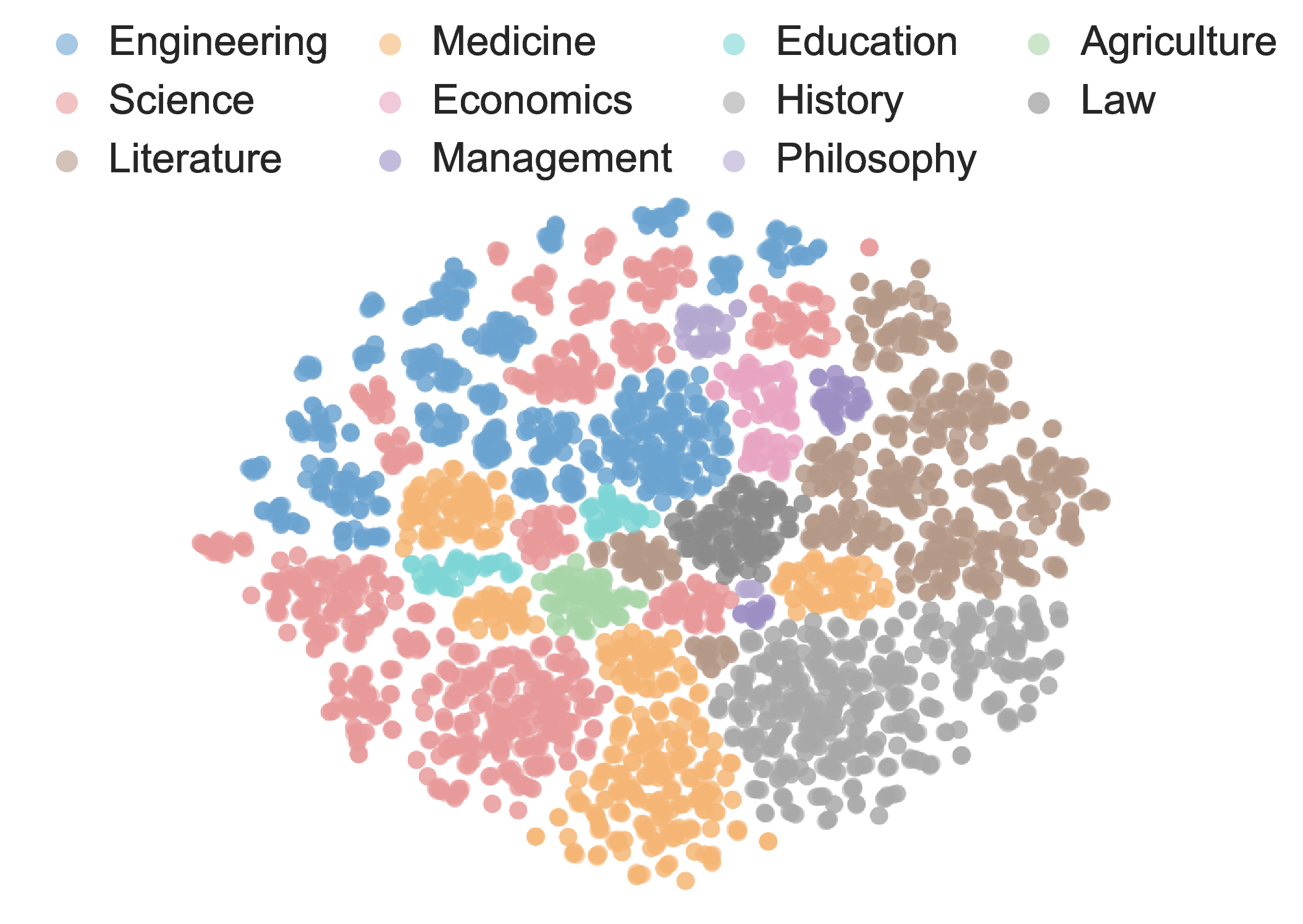
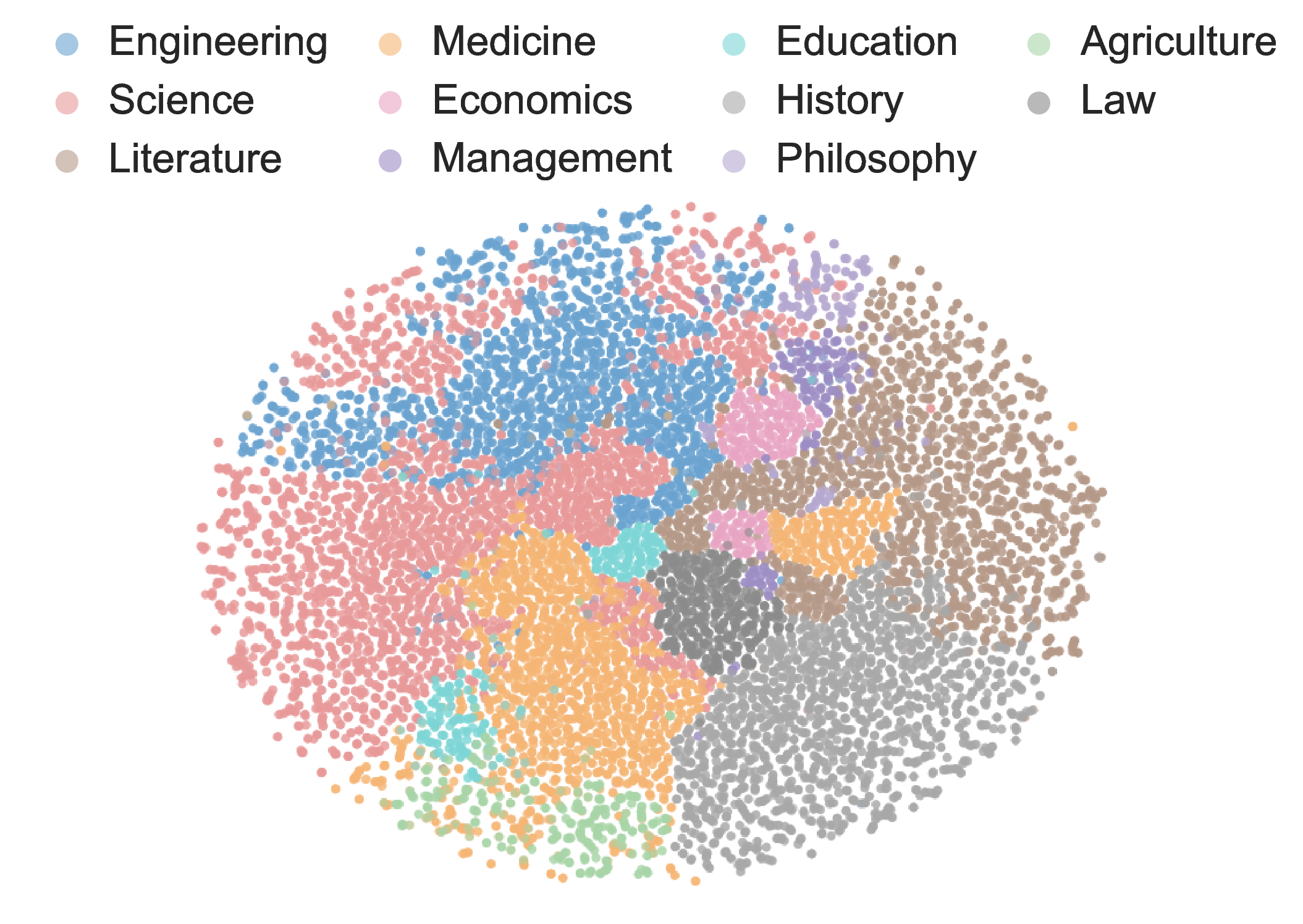
두 번째 장점은 평가의 “다중 개념” 접근이다. 하나의 질문에 여러 문장이 포함되면, 모델은 단일 개념을 넘어 복합적인 관계망을 파악해야 한다. 이는 실제 인간이 학습하고 활용하는 지식 구조와 더 가깝다. 예를 들어, 물리학 교과서에서 “뉴턴의 제1법칙”, “관성”, “힘과 가속도 관계”와 같은 문장을 동시에 제시하면, 모델은 이들 사이의 연관성을 종합해 정답을 도출해야 한다. 이런 방식은 단일 개념 질문만으로는 드러나지 않는 모델의 약점을 드러내며, 보다 정밀한 성능 프로파일링을 가능하게 한다.
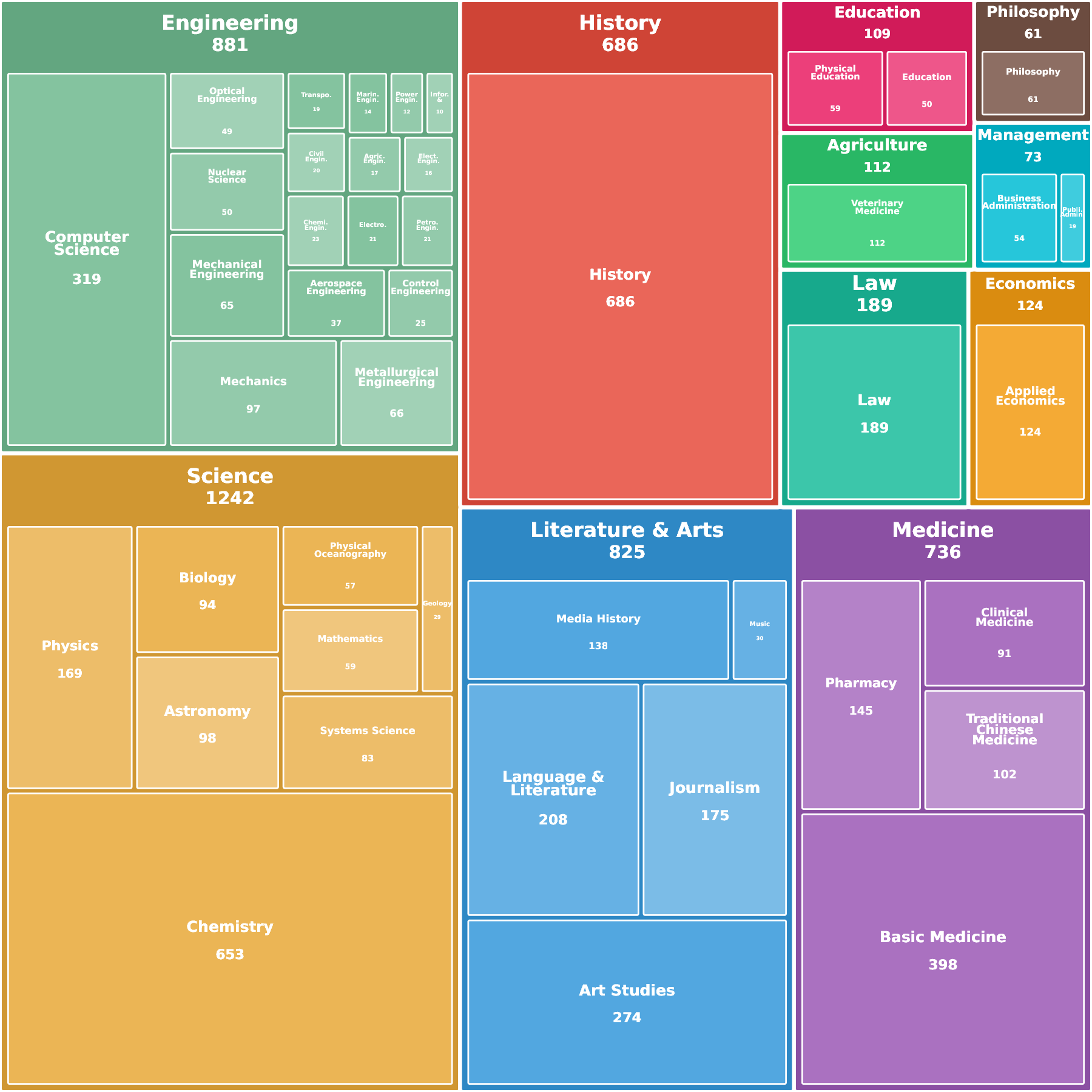
세 번째로, 주석 비용 절감이다. 기존 고품질 벤치마크는 도메인 전문가가 정답을 검증하고, 질문·답변을 설계하는 데 수십 시간에서 수백 시간의 인력이 투입된다. Encyclo‑K는 문장 추출 단계에서 이미 권위 있는 교과서를 사용하므로, 내용의 정확성은 교과서 자체가 보증한다. 검증자는 문장이 올바른 형식(예: “주어‑술어‑목적어” 구조)으로 정리됐는지, 조합된 질문이 논리적으로 일관되는지만 확인하면 된다. 이는 전문가가 아닌 일반 검수 인력으로도 충분히 수행 가능하므로, 대규모 벤치마크 구축 비용을 크게 낮춘다.
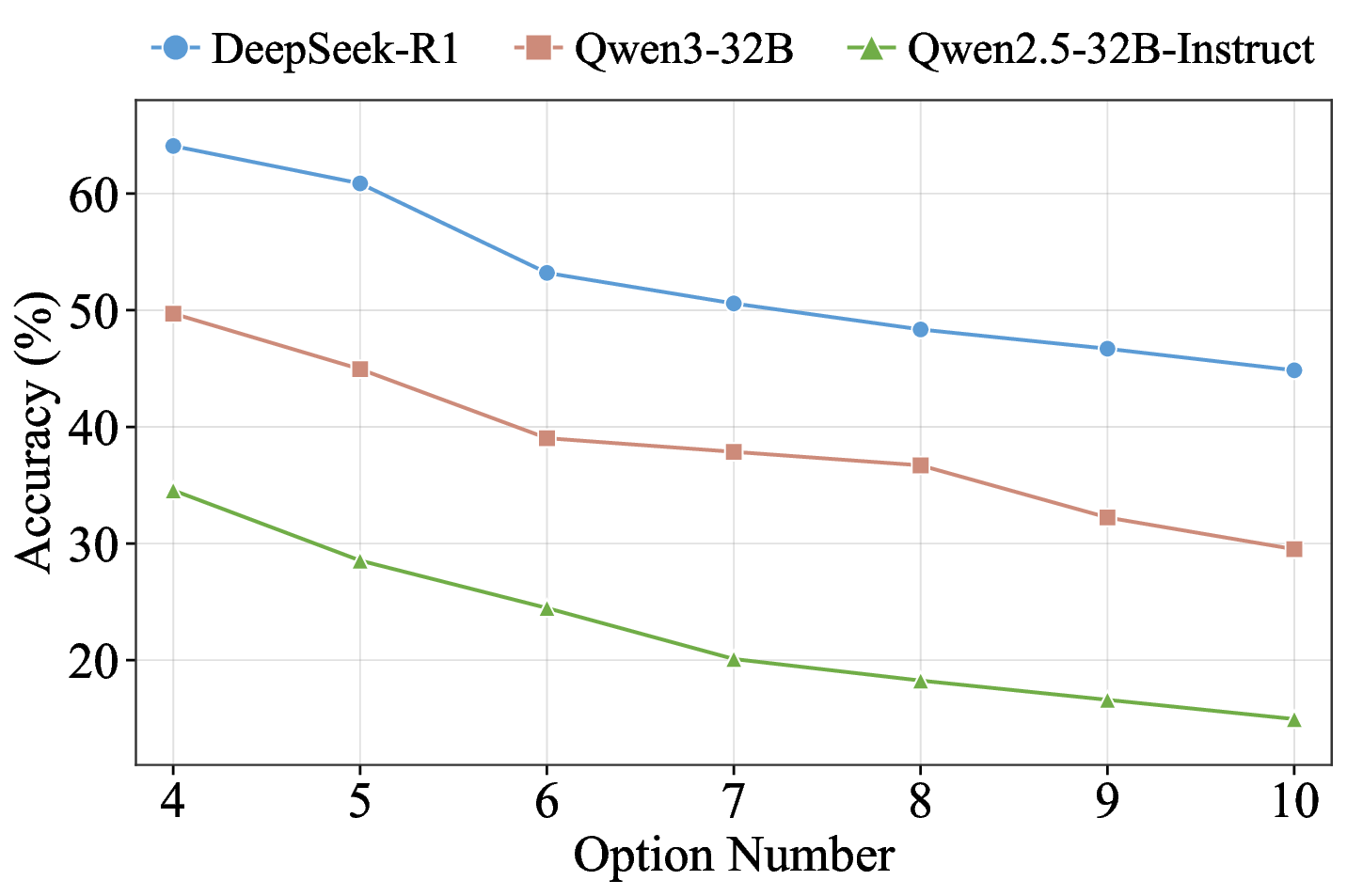
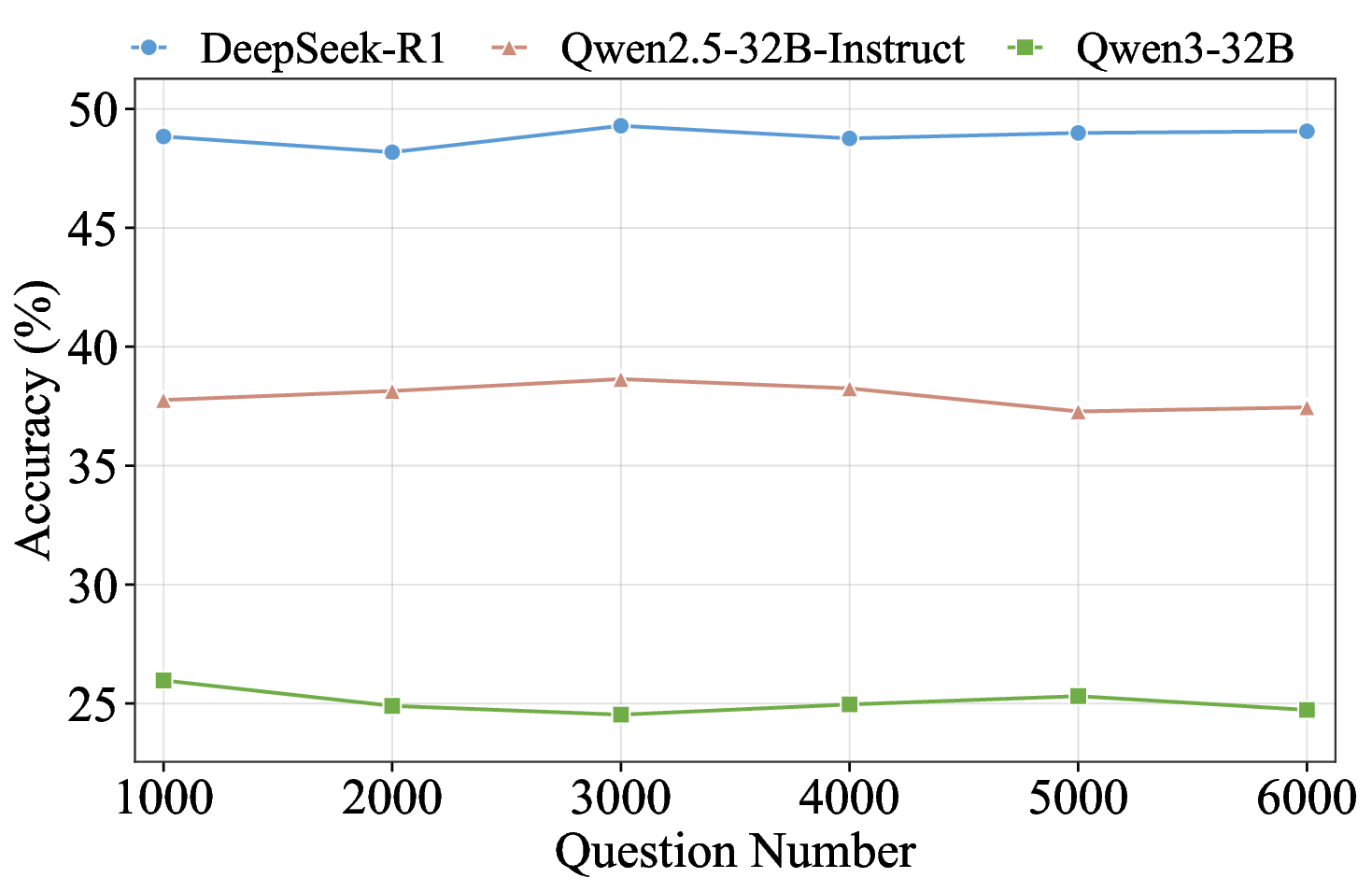
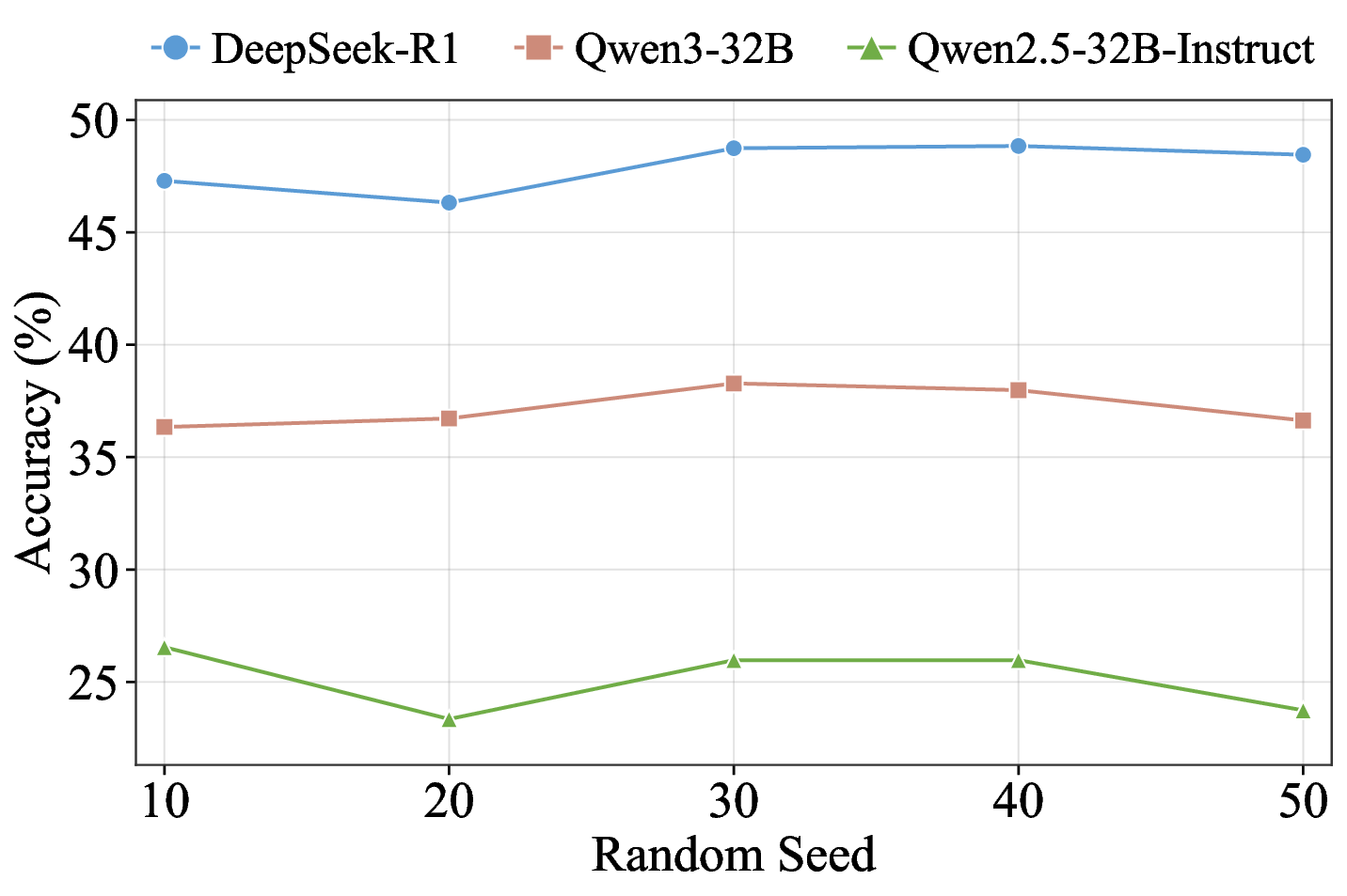
실험 결과에서도 흥미로운 패턴이 관찰된다. 50여 개 모델 중 최고 성능을 보인 GPT‑5.1조차 62% 수준에 머물렀으며, 추론 전용 모델과 챗봇 모델 사이에 뚜렷한 격차가 존재한다. 이는 현재 LLM이 “지식 저장”보다는 “대화 흐름 유지”에 최적화된 경우가 많다는 점을 시사한다. 또한 모델 성능이 연속적인 분포를 이루는 점은, 단순히 “상위/하위” 구분이 아니라 성능 차이를 정량적으로 측정할 수 있는 새로운 평가 지표 설계의 필요성을 강조한다.
종합하면, Encyclo‑K는 데이터 오염 방지, 다중 개념 종합 평가, 저비용 주석이라는 세 축을 동시에 만족시키는 혁신적인 벤치마크이다. 앞으로 LLM 개발자와 연구자는 이와 같은 동적 생성 기반 평가 방식을 채택함으로써, 실제 응용 환경에서 요구되는 복합 추론 능력을 보다 정확히 측정하고, 모델 개선 방향을 명확히 설정할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리