다중 단계 액터‑크리틱 학습과 리아푸노프 인증을 이용한 지수 안정 제어
📝 원문 정보
- Title: MSACL: Multi-Step Actor-Critic Learning with Lyapunov Certificates for Exponentially Stabilizing Control
- ArXiv ID: 2512.24955
- 발행일: 2025-12-31
- 저자: Yongwei Zhang, Yuanzhe Xing, Quan Quan, Zhikun She
📝 초록 (Abstract)
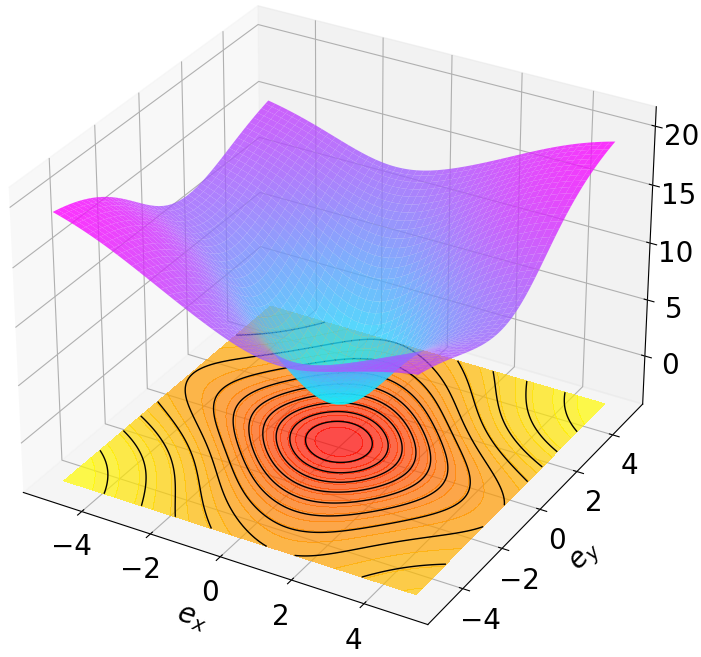
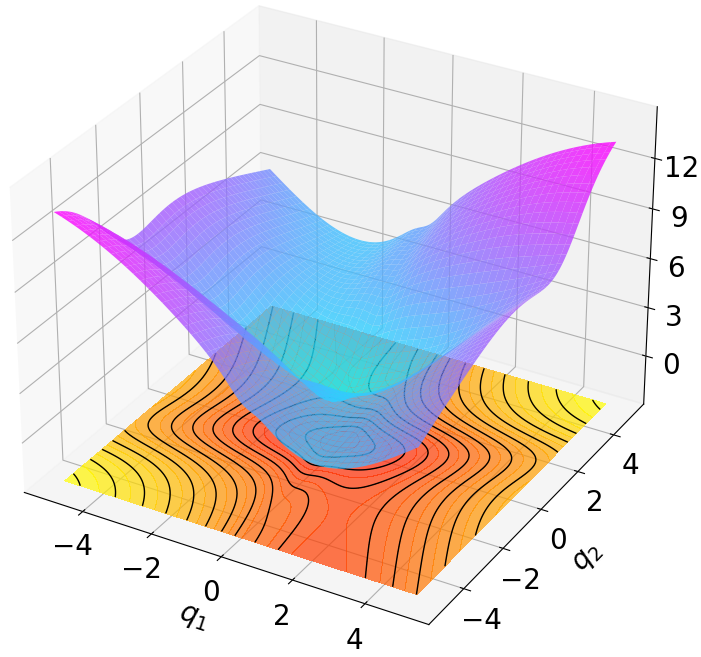
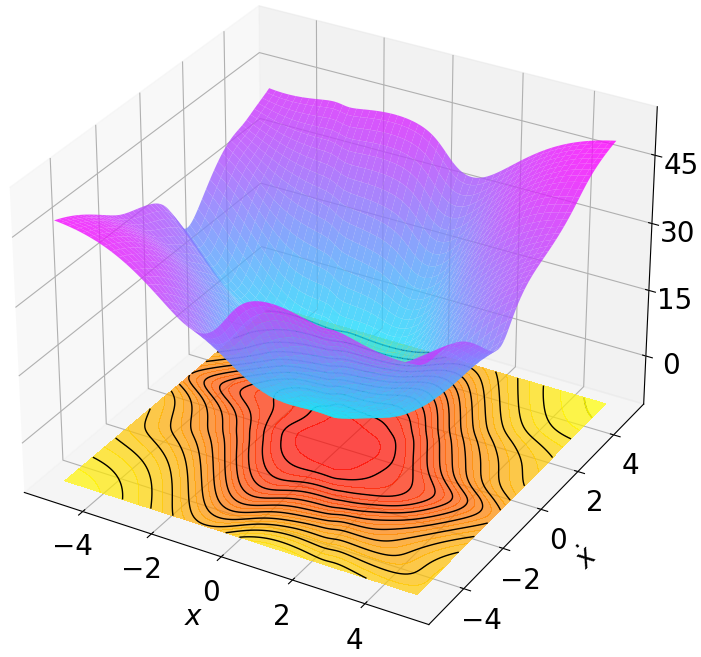
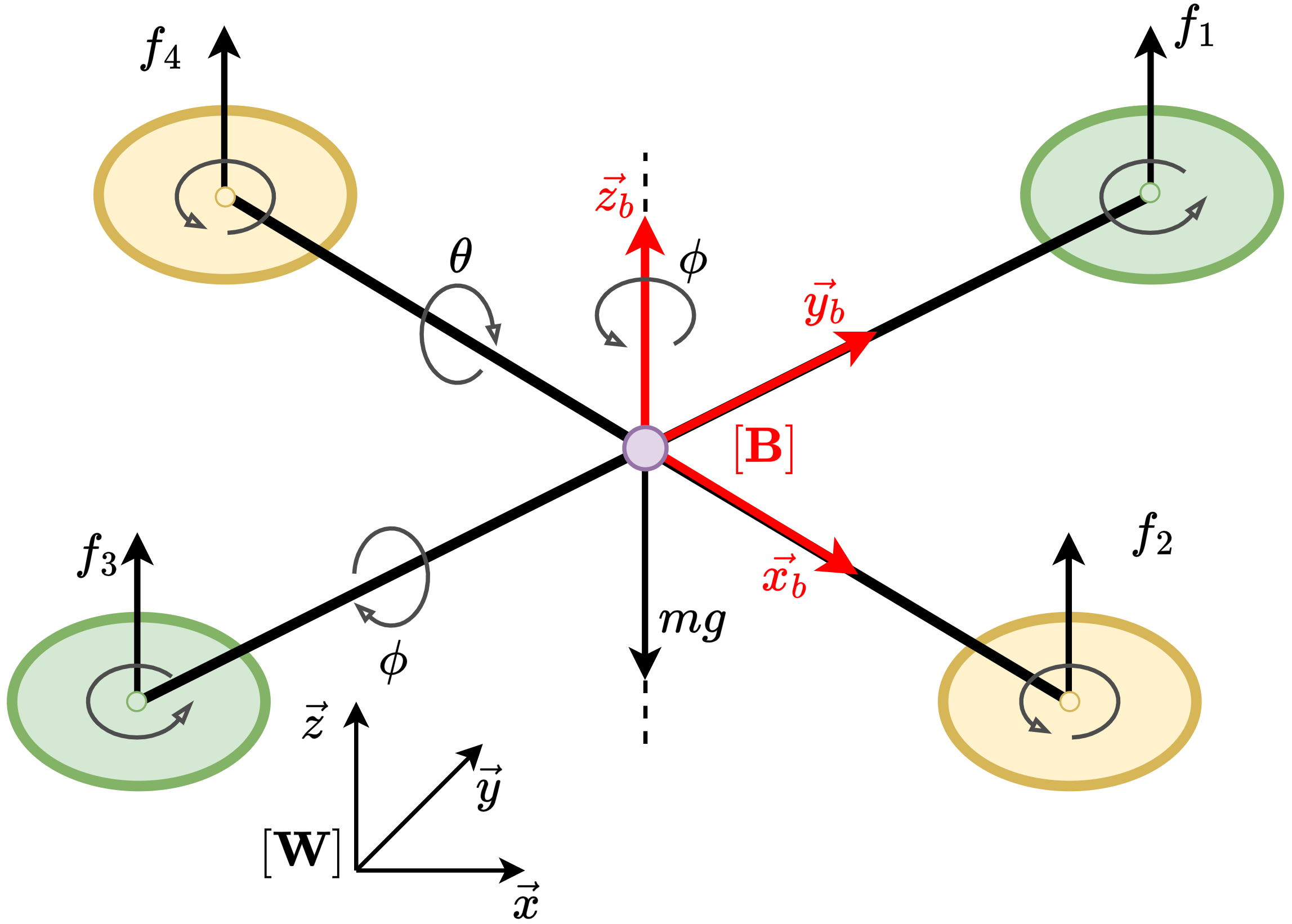
안전이 중요한 분야에서 모델‑프리 강화학습은 검증 가능한 안정성 보장을 제공하기 어렵고 탐색 효율성도 저하되는 문제에 직면한다. 이를 해결하고자 본 연구는 지수 안정성(Exponential Stability)과 최대 엔트로피 강화학습(Maximum Entropy RL)을 자연스럽게 결합한 새로운 방법인 다중 단계 액터‑크리틱 학습 with Lyapunov Certificates(MSACL)를 제안한다. 기존 연구가 복잡한 보상 설계와 단일 단계 제약에 의존하는 반면, MSACL은 직관적인 보상과 다중 단계 데이터를 활용한다. 구체적으로, 먼저 샘플을 지수 안정성 라벨(Exponential Stability Labels, ESL)로 구분하고, λ‑가중 집계 메커니즘을 통해 리아푸노프 인증을 학습한다. 이 인증을 이용해 안정성을 고려한 어드밴티지 함수를 정의함으로써 정책 최적화 시 빠른 리아푸노프 감소와 강인한 상태 수렴을 유도한다. 네 개의 안정화 과제와 두 개의 고차원 추적 과제로 구성된 여섯 개 벤치마크에서 실험한 결과, MSACL은 기존 표준 RL 및 최신 Lyapunov 기반 RL 알고리즘보다 일관되게 우수한 성능을 보였다. 빠른 수렴 외에도 환경 불확실성에 대한 강인성 및 보이지 않는 목표 신호에 대한 일반화 능력이 크게 향상되었다. 소스 코드와 벤치마크 환경은 https://github.com/YuanZhe‑Xing/MSACL 에서 제공한다.💡 논문 핵심 해설 (Deep Analysis)
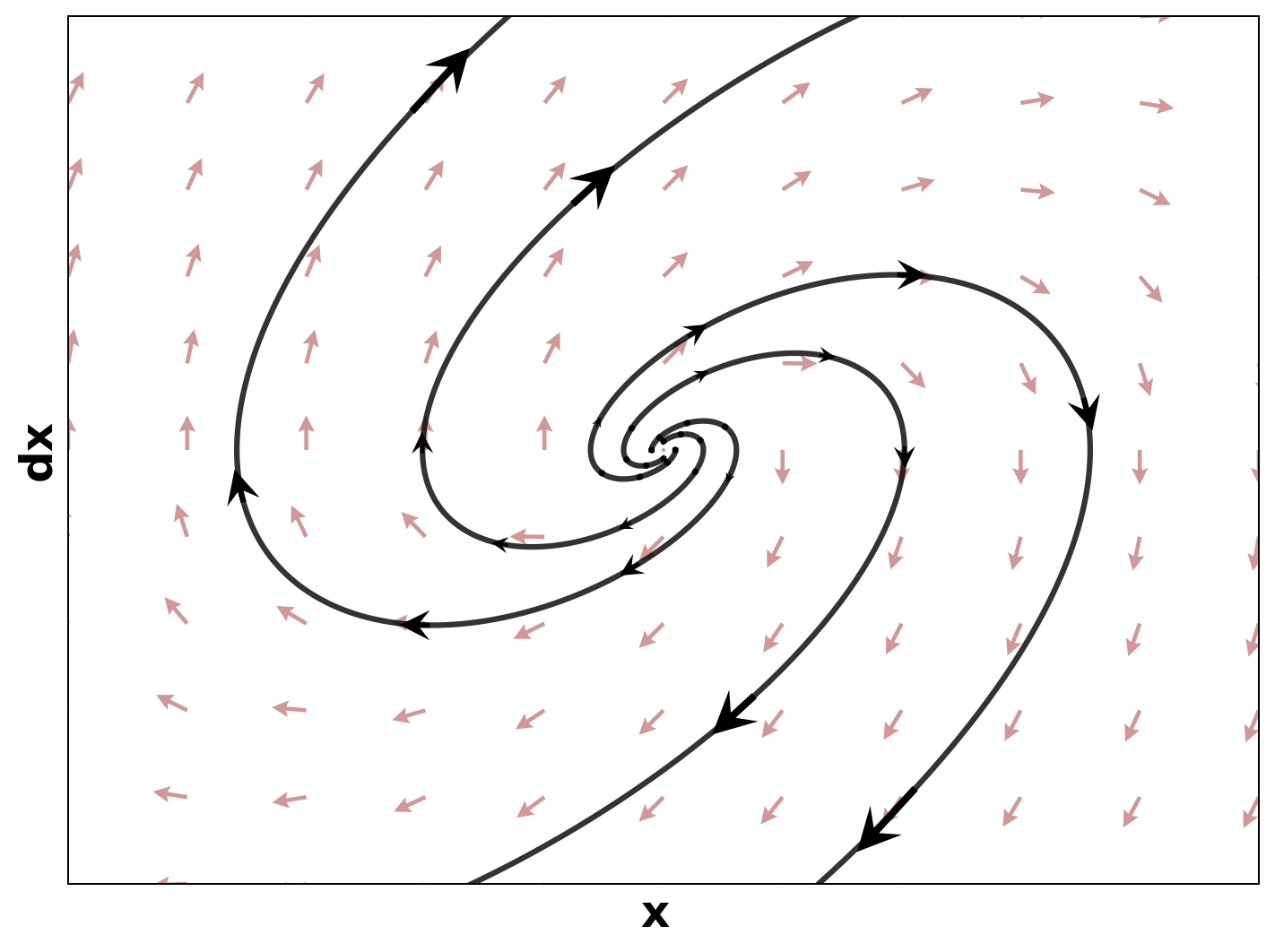
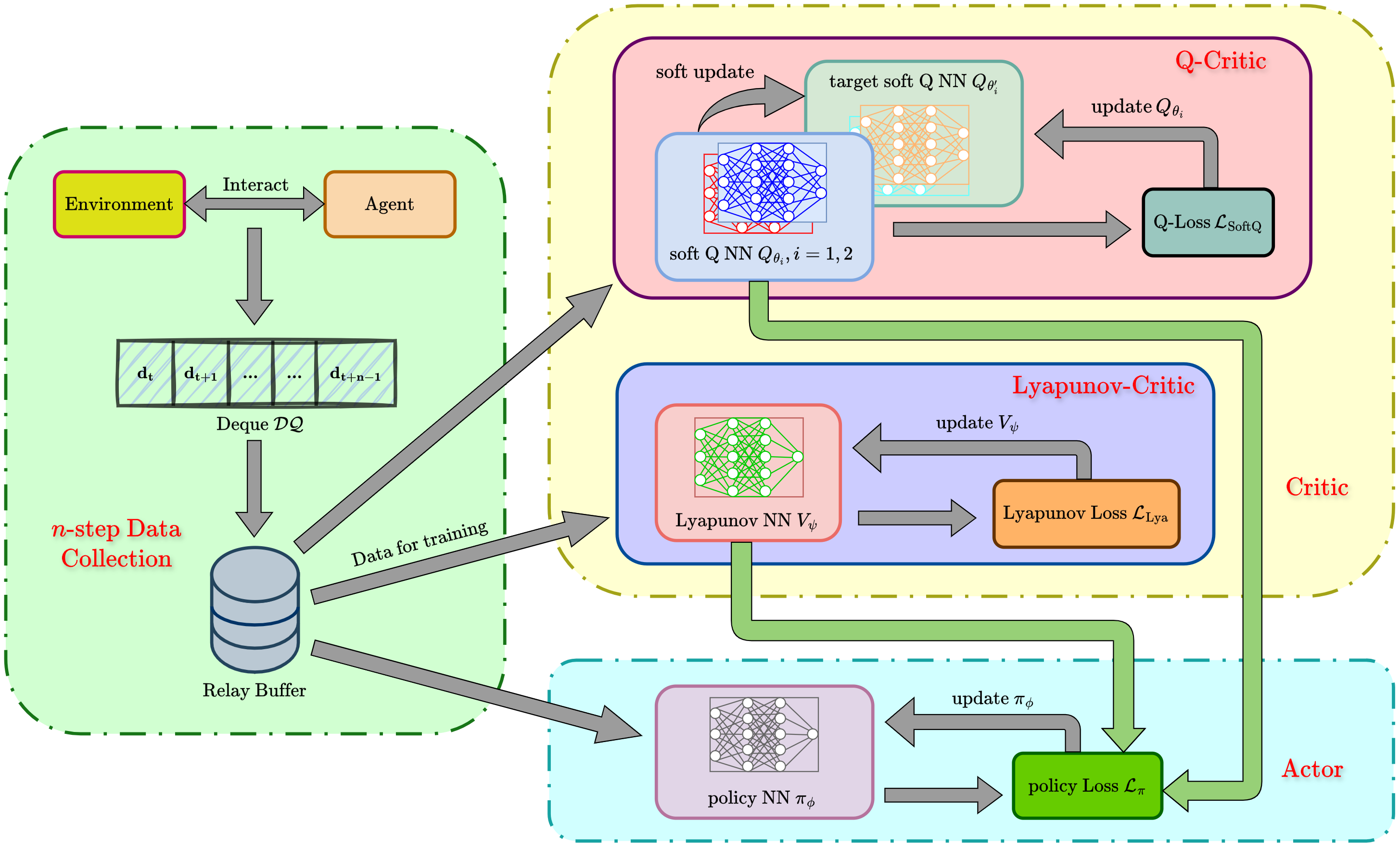
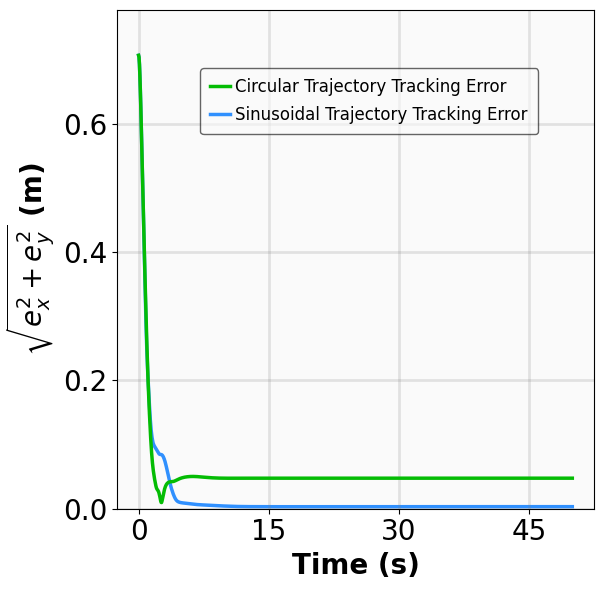
두 번째 혁신은 ‘안정성‑인식 어드밴티지 함수’를 정의한 점이다. 전통적인 어드밴티지 함수는 기대 보상의 차이만을 반영해 정책을 업데이트한다. 그러나 MSACL은 리아푸노프 인증값을 보상에 가중치로 결합해, 정책이 선택하는 행동이 리아푸노프 감소에 기여하는 정도를 직접적으로 측정한다. 결과적으로 정책 업데이트는 ‘빠른 Lyapunov descent’를 목표로 하며, 이는 수렴 속도를 크게 가속화한다. 또한, 최대 엔트로피 RL 프레임워크와 결합함으로써 탐색 단계에서의 무작위성을 유지해 지역 최적에 빠지는 위험을 감소시킨다.
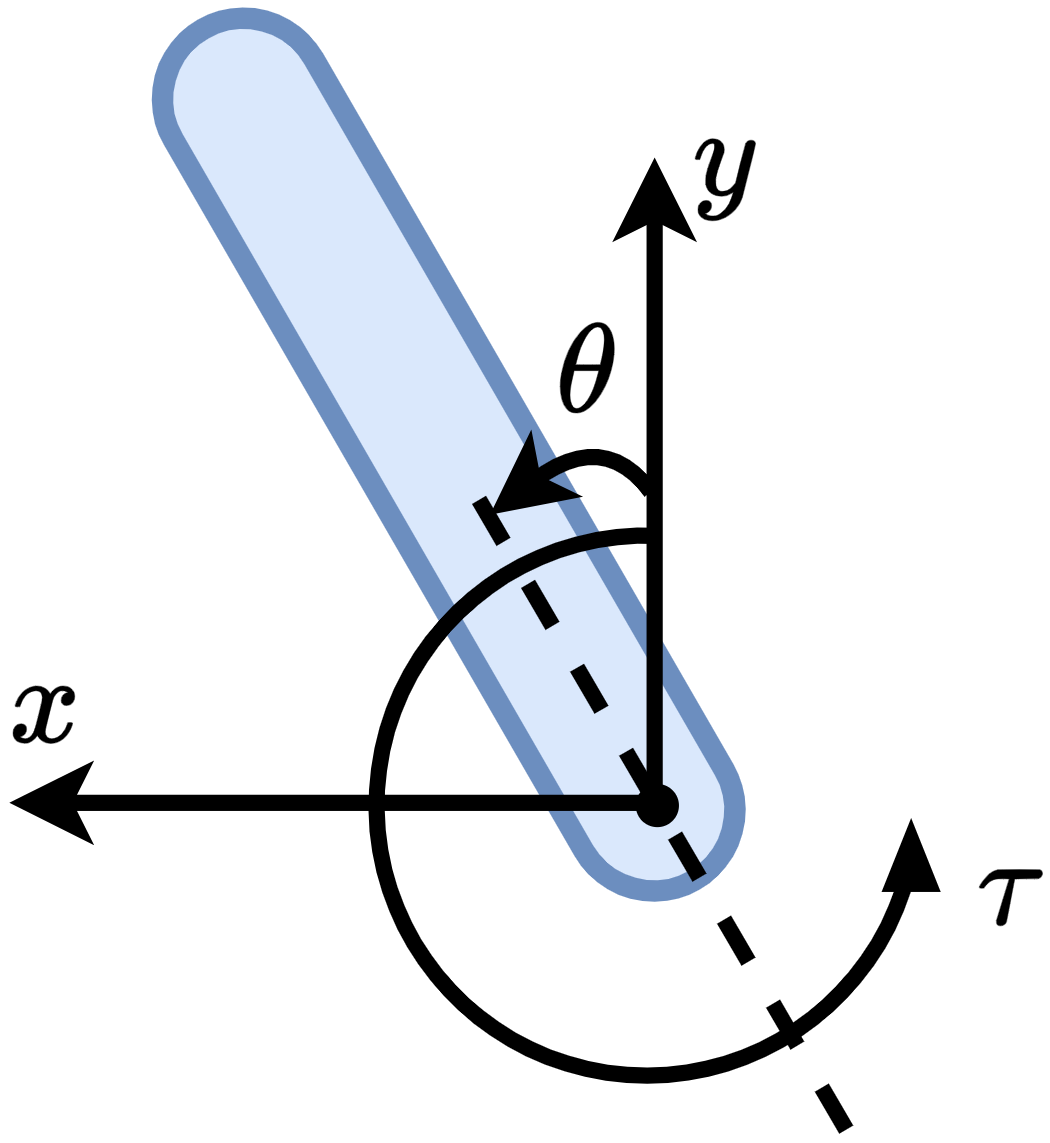
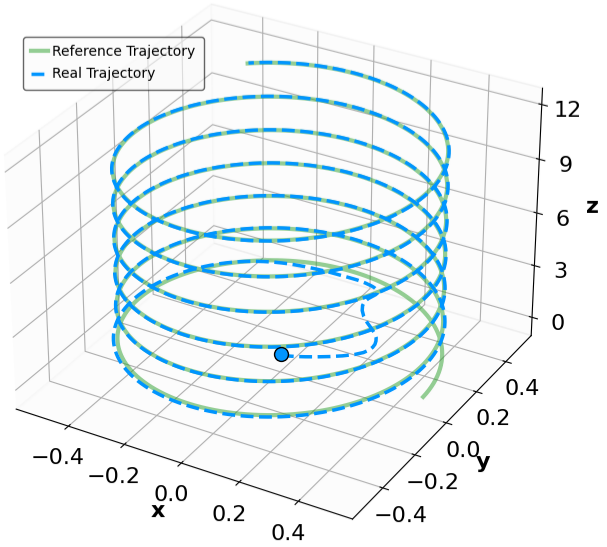
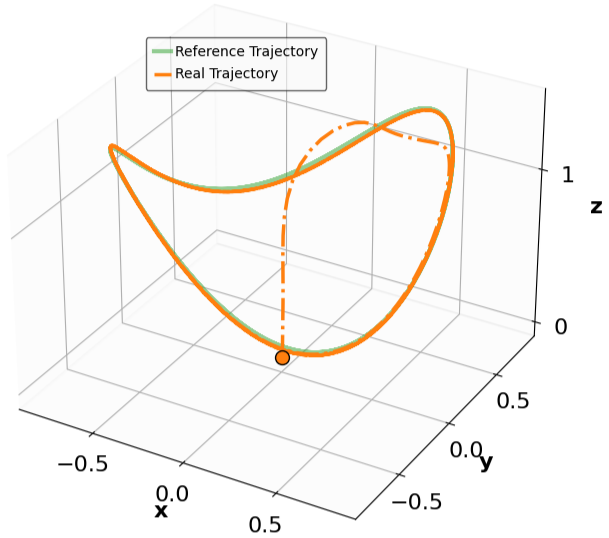
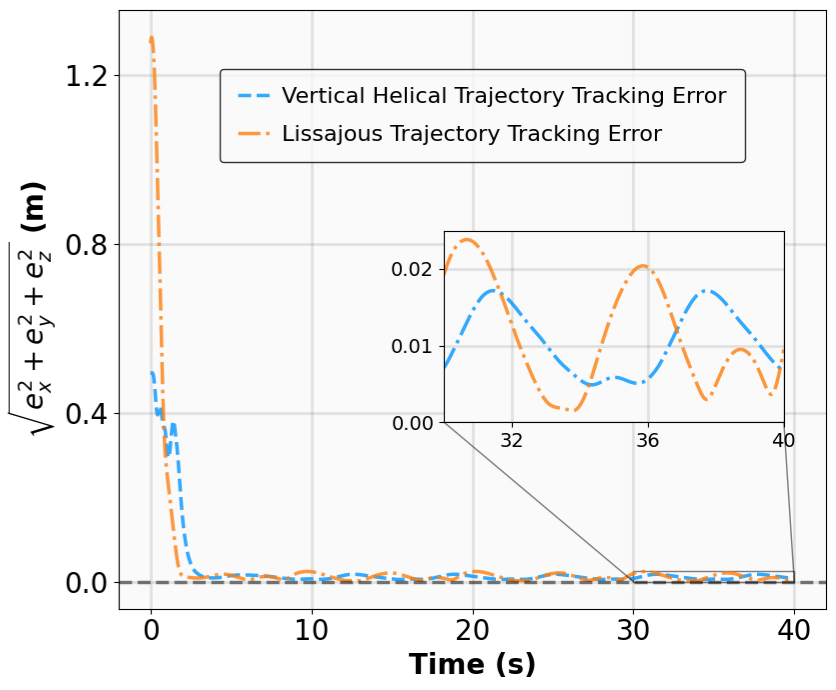
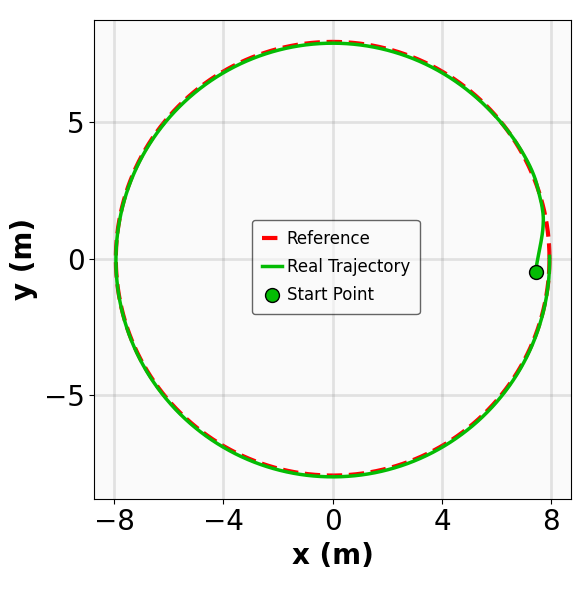
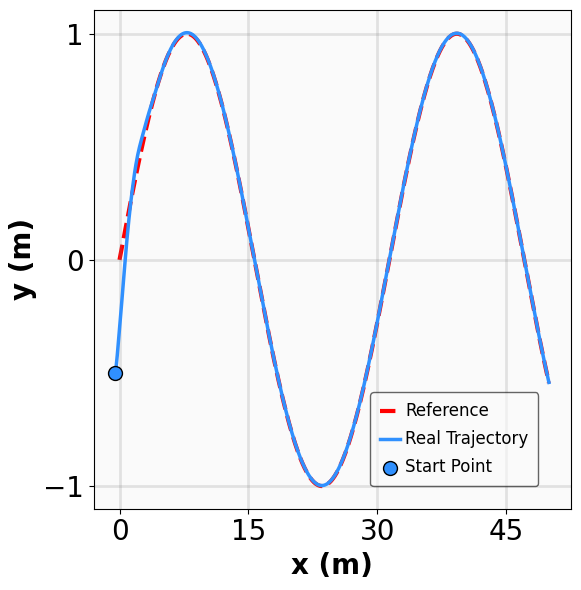
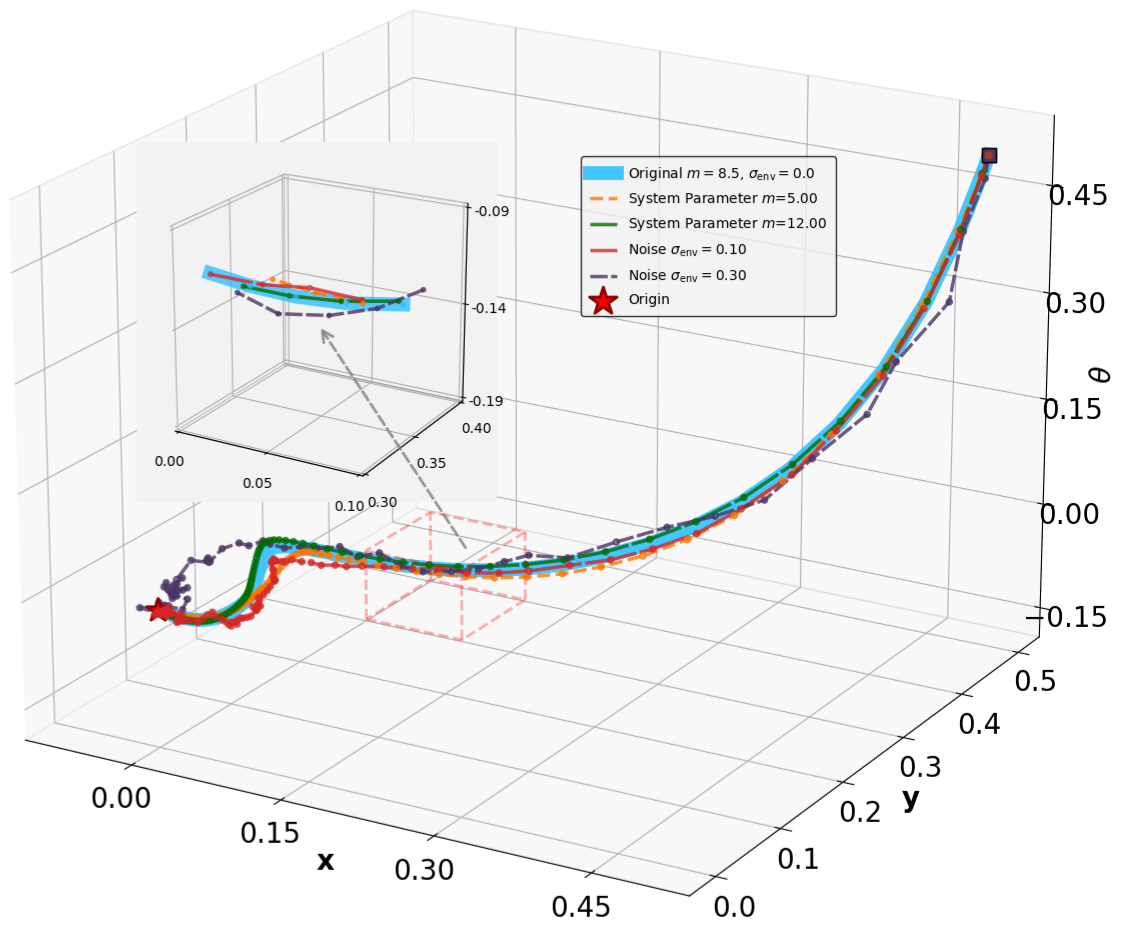
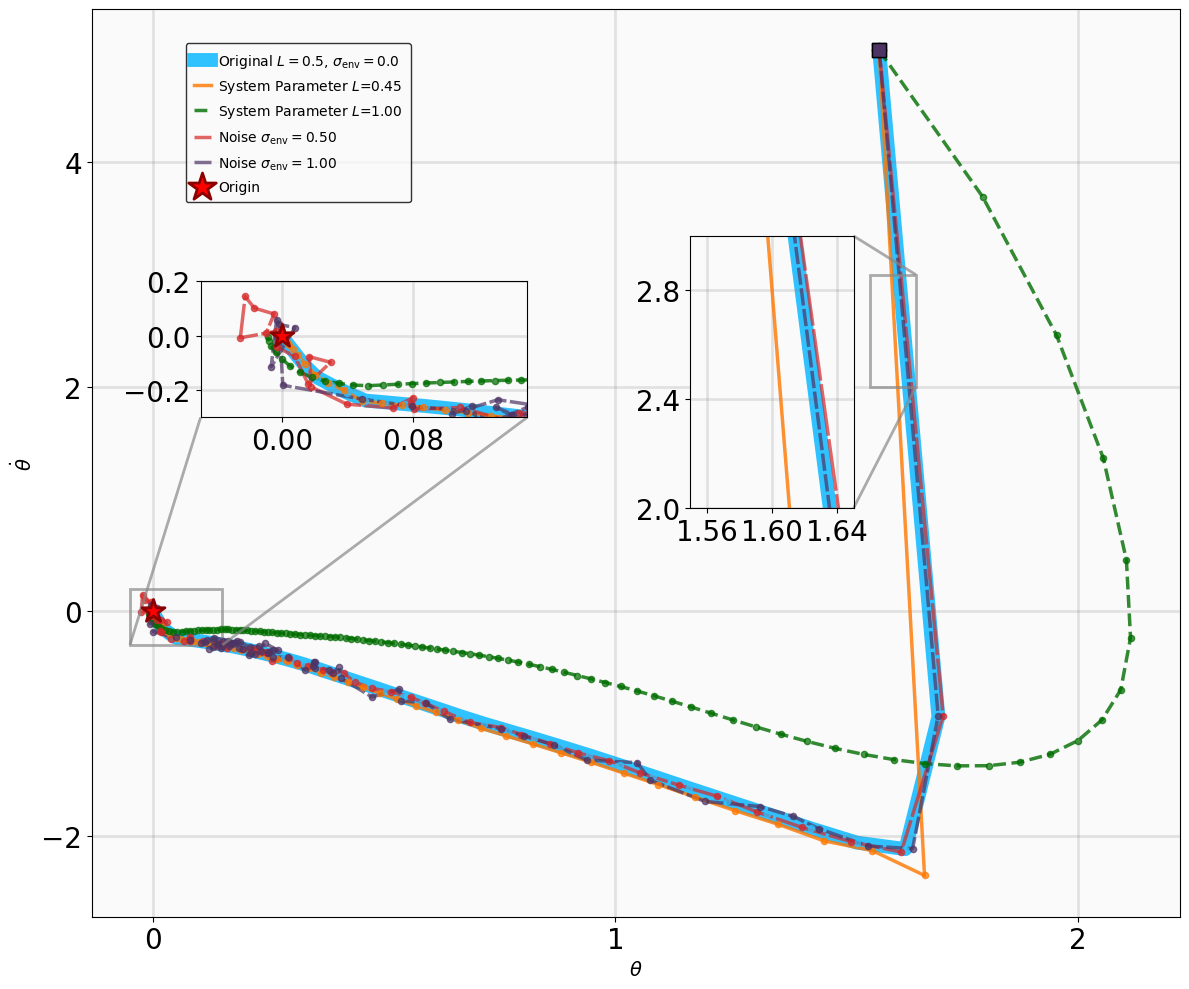
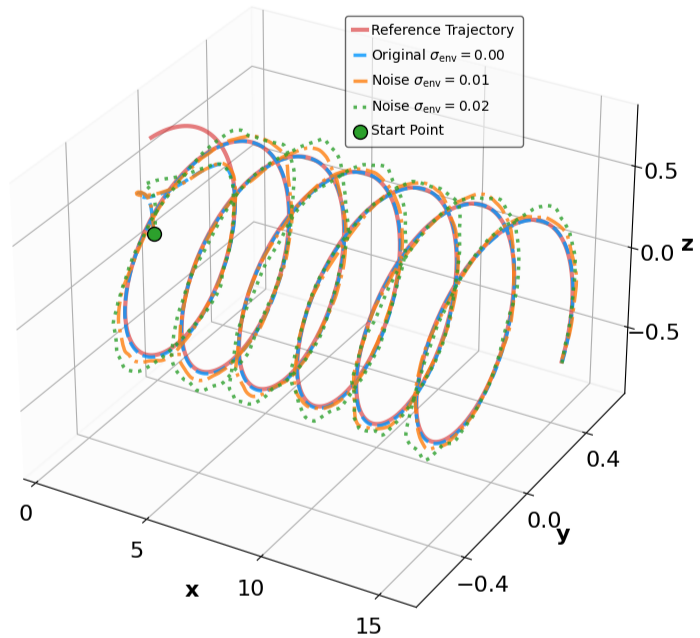
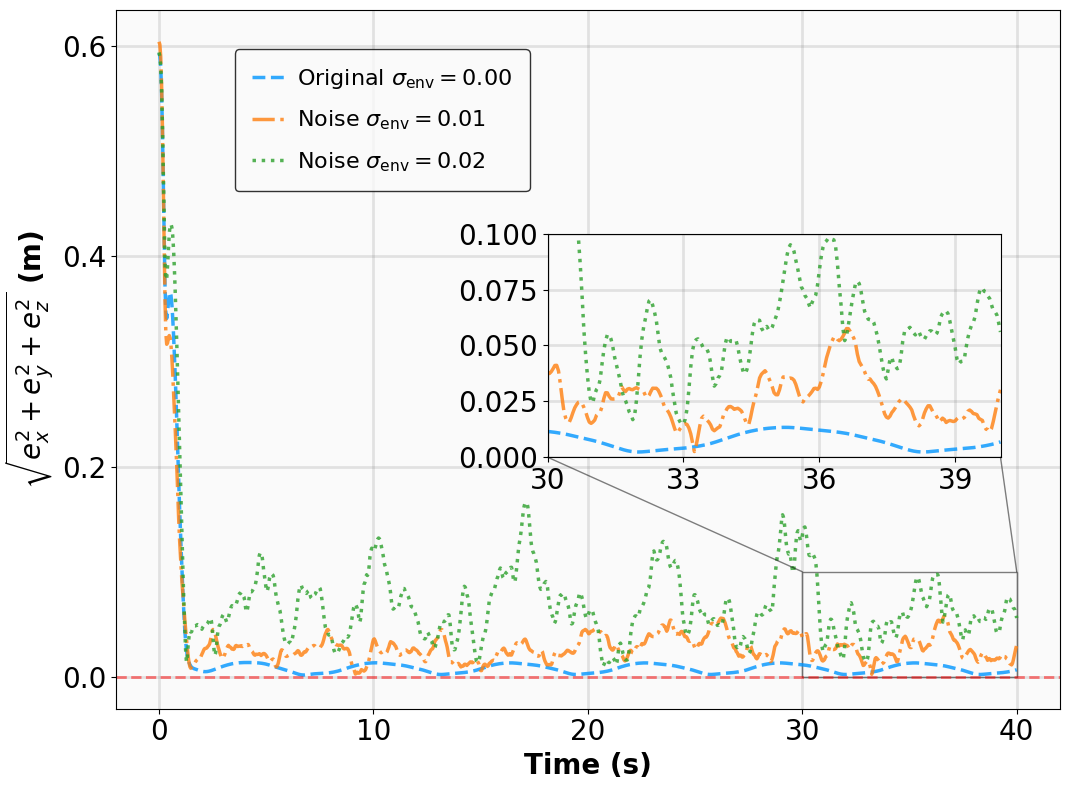
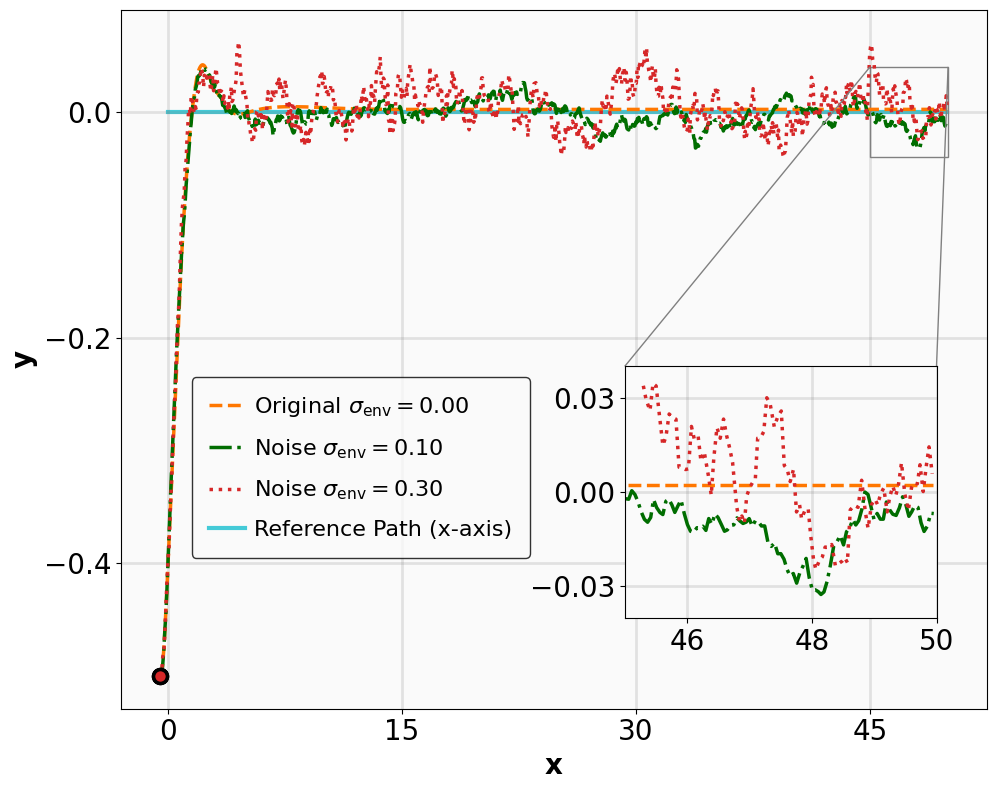
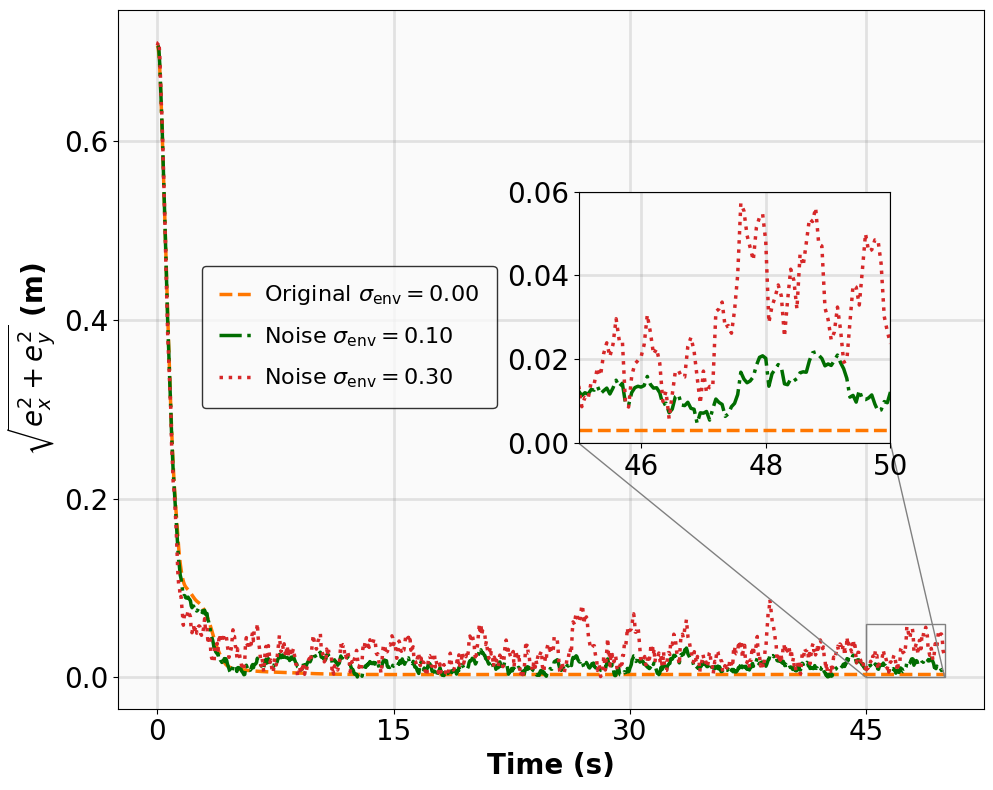
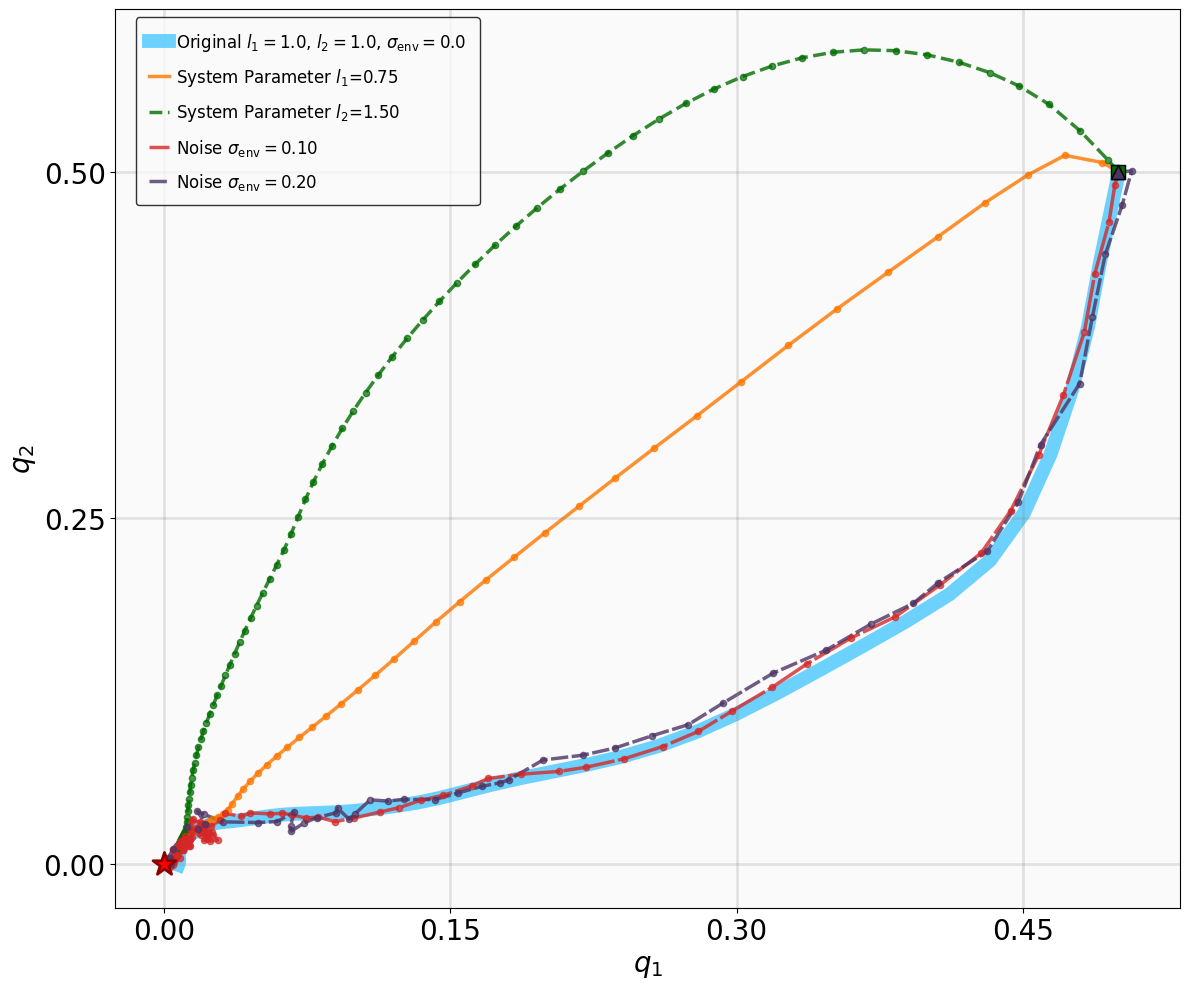
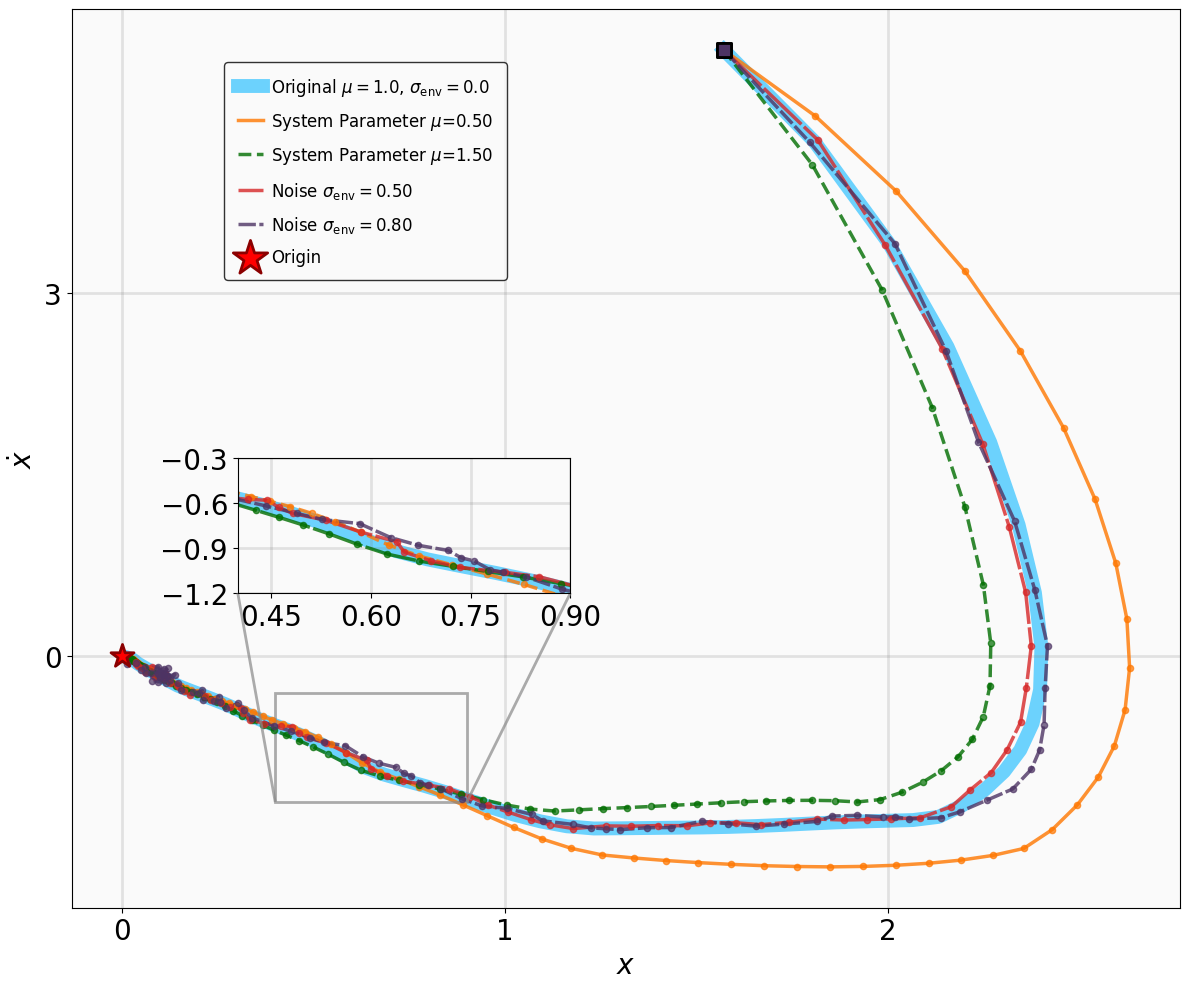
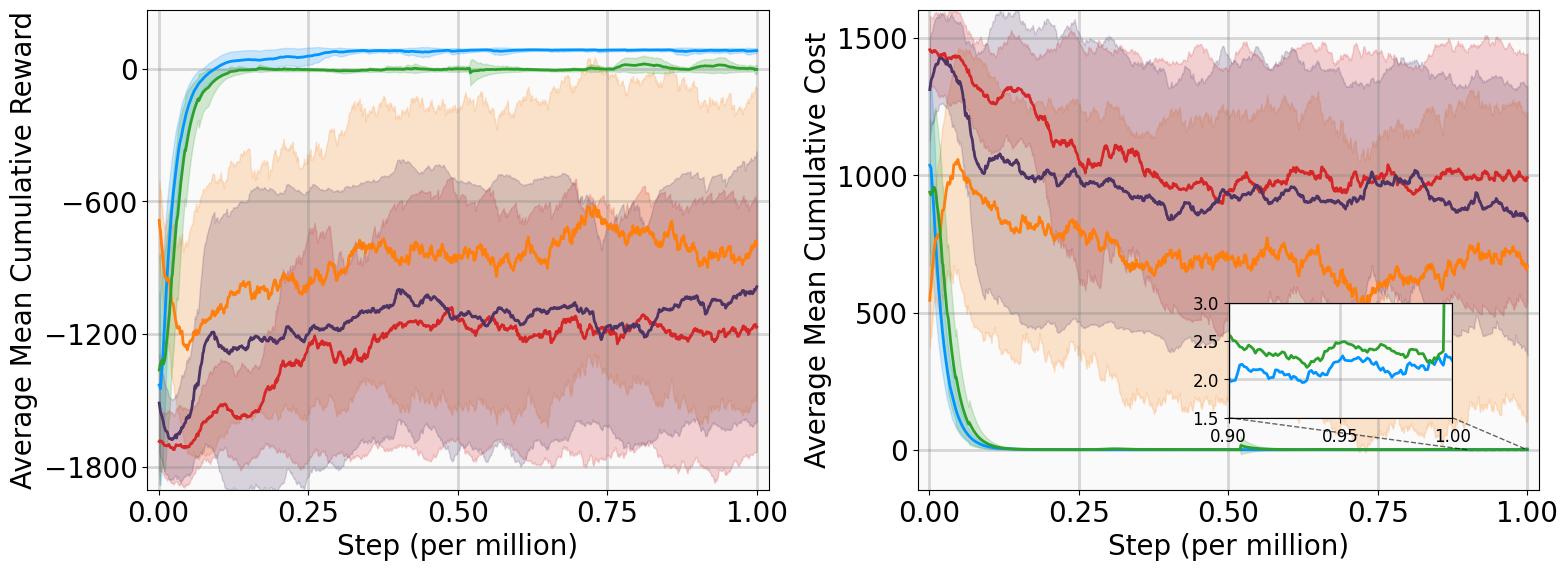
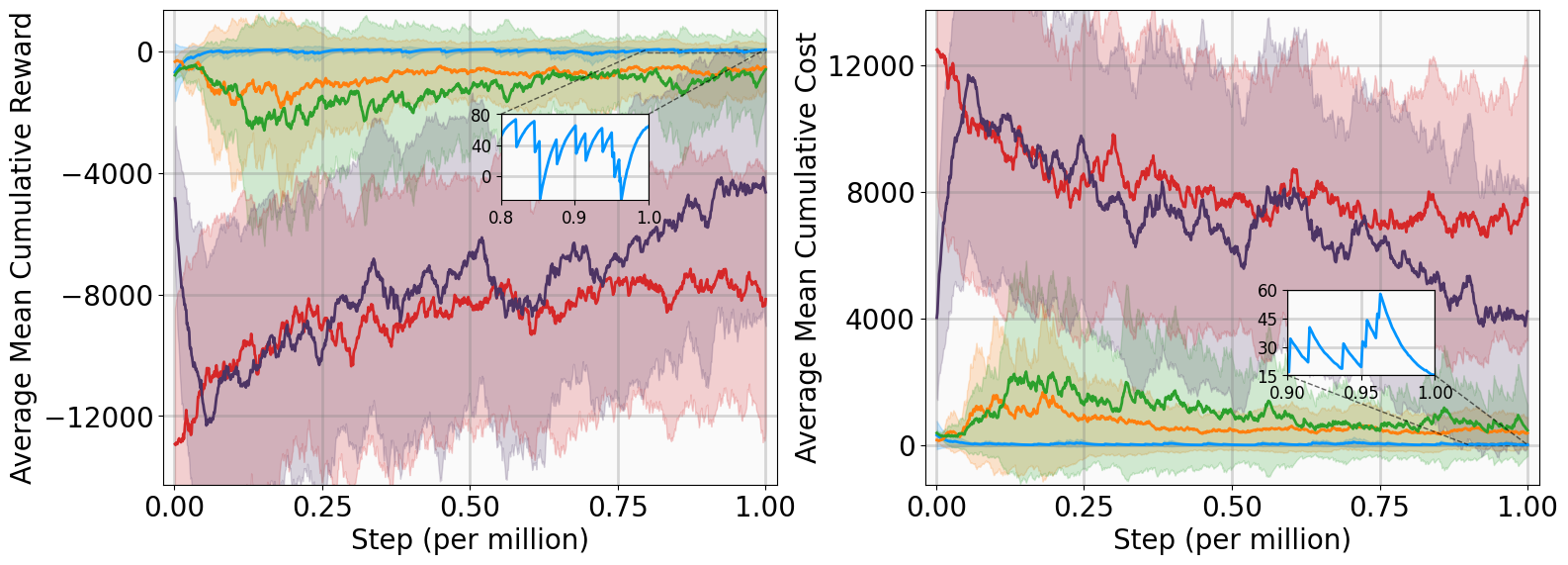
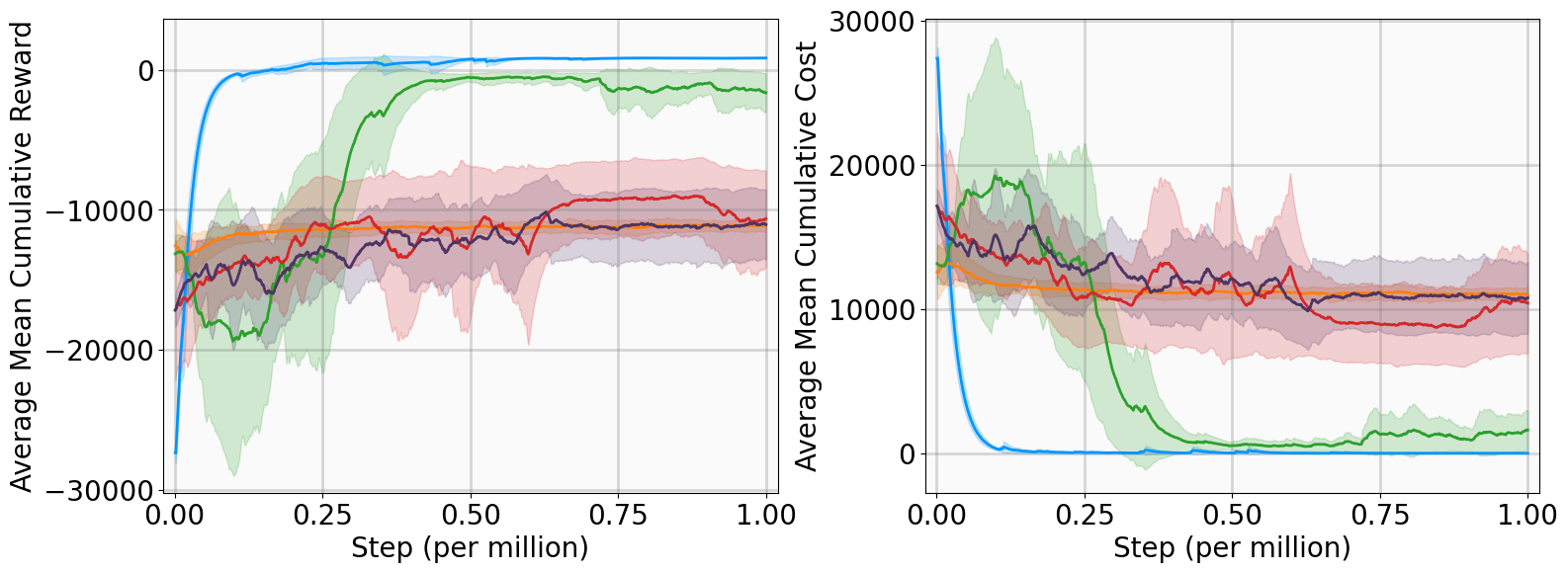
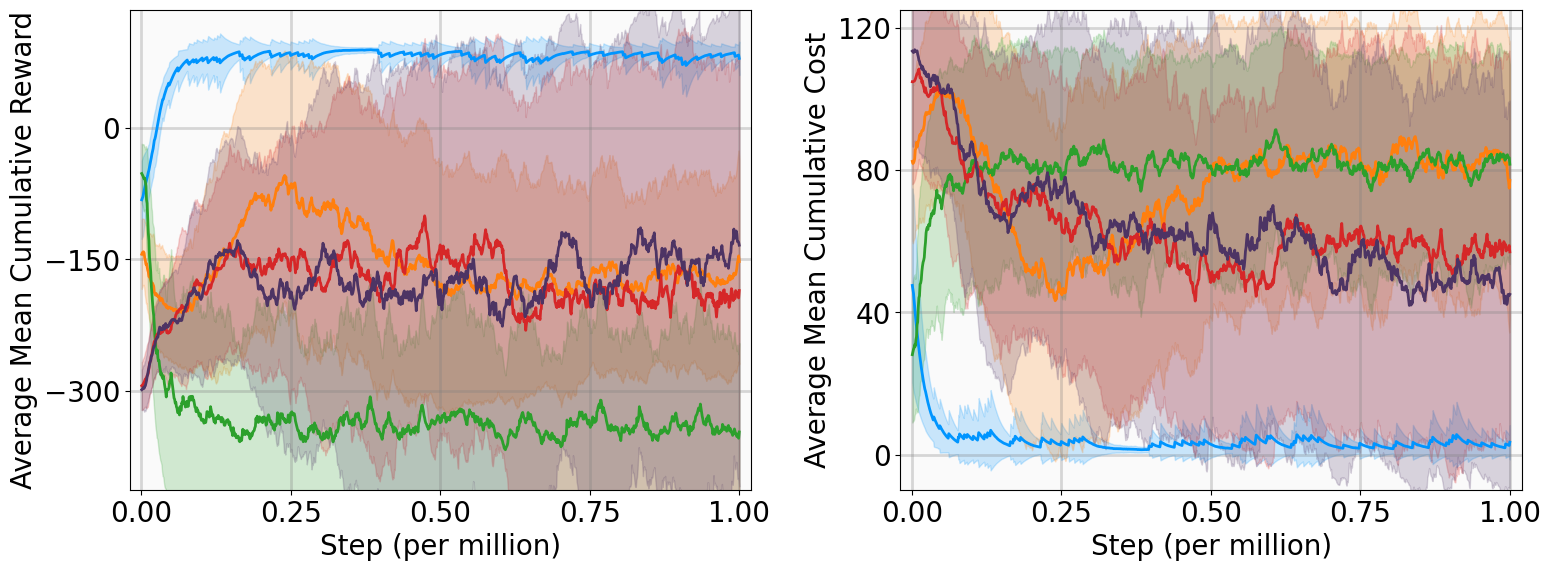
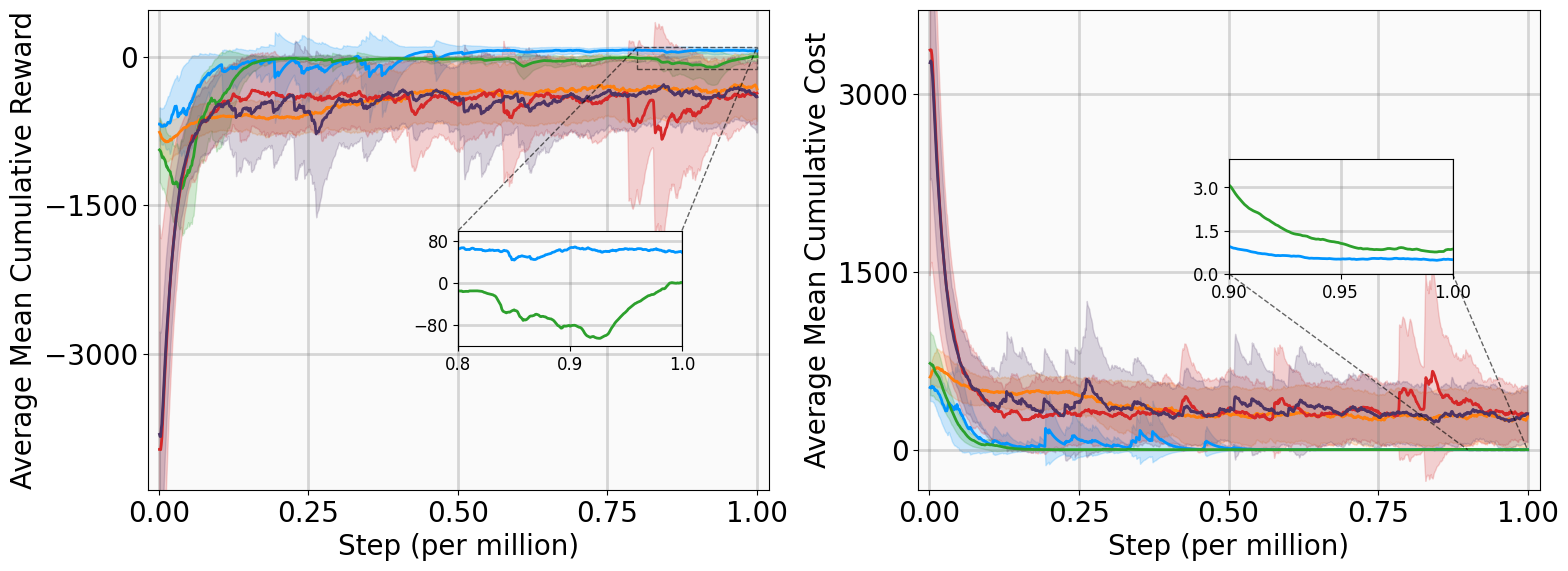
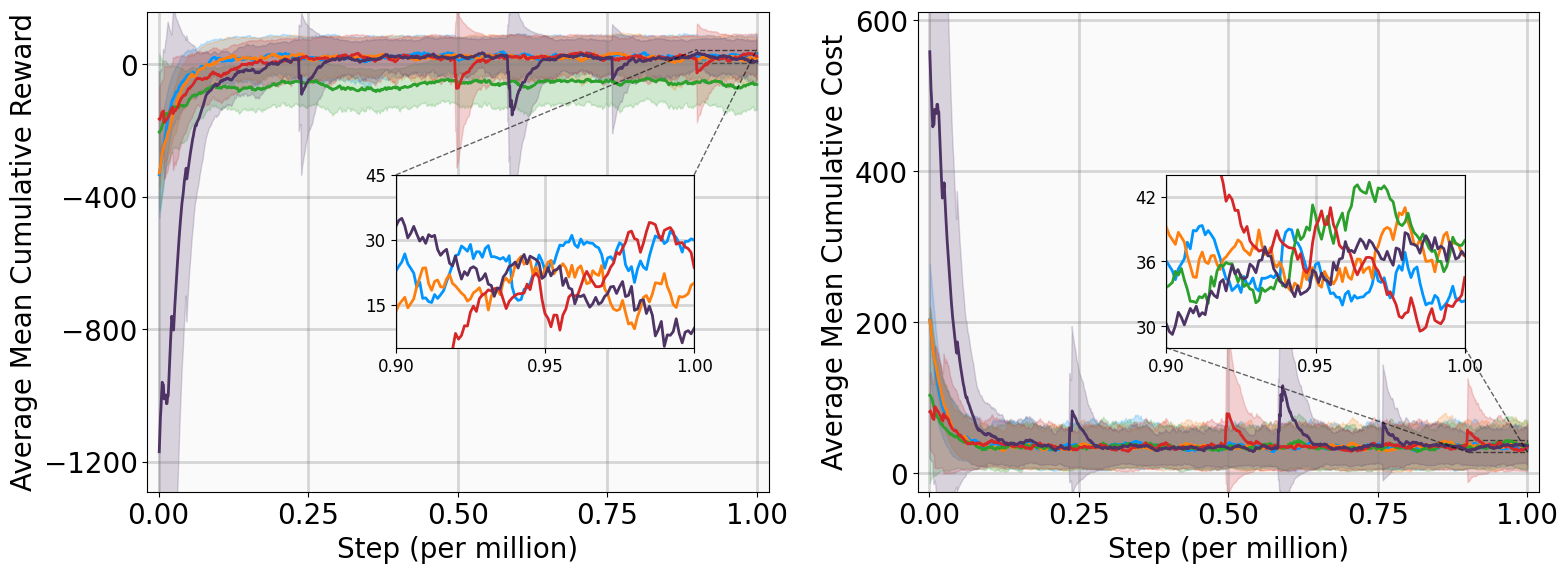
실험 설계도 주목할 만하다. 네 개의 고전적인 안정화 과제(예: inverted pendulum, cart‑pole 등)와 두 개의 고차원 추적 과제(예: 로봇 팔의 궤적 추적)에서 MSACL은 표준 SAC, TD3, PPO와 같은 베이스라인뿐 아니라 최신 Lyapunov‑기반 알고리즘(Lyapunov‑SAC, LQR‑RL 등)보다 일관된 성능 우위를 보였다. 특히 ‘환경 불확실성(노이즈, 파라미터 변동)’에 대한 실험에서, 리아푸노프 인증이 정책에 내재된 안정성 마진을 제공함으로써 급격한 성능 저하를 방지한다는 점이 확인되었다. 또한, 훈련 시 보지 못한 새로운 목표 신호에 대해서도 빠르게 적응하는 모습을 보여, 일반화 능력이 뛰어남을 입증한다.
이 논문의 한계도 존재한다. λ‑가중 집계 파라미터와 ESL 임계값을 어떻게 설정하느냐에 따라 학습 안정성이 크게 달라질 수 있으며, 현재는 경험적 튜닝에 의존한다는 점이다. 또한, 리아푸노프 인증을 신경망으로 근사하는 과정에서 과적합 위험이 존재하고, 대규모 연속 제어 문제에서는 인증 네트워크의 규모와 학습 비용이 증가할 가능성이 있다. 향후 연구에서는 자동화된 하이퍼파라미터 최적화와 인증 네트워크의 구조적 제약(예: 입력‑출력 라디컬 베이스 함수) 등을 탐색하면 실용성을 더욱 높일 수 있을 것이다.
요약하면, MSACL은 ‘다중 단계 데이터 활용’, ‘라벨 기반 Lyapunov 인증 학습’, ‘안정성‑인식 어드밴티지’를 결합해 모델‑프리 RL에서 안정성을 보장하면서도 탐색 효율성을 유지하는 새로운 패러다임을 제시한다. 이는 안전‑중요 시스템(자율 주행, 로봇 팔, 전력망 등)에서 실시간 제어 정책을 학습하는 데 있어 중요한 전환점이 될 것으로 기대한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리