GenZ 전통 통계 모델 내 잠재 변수 생성기로서의 기초 모델
📝 원문 정보
- Title: GenZ: Foundational models as latent variable generators within traditional statistical models
- ArXiv ID: 2512.24834
- 발행일: 2025-12-31
- 저자: Marko Jojic, Nebojsa Jojic
📝 초록 (Abstract)
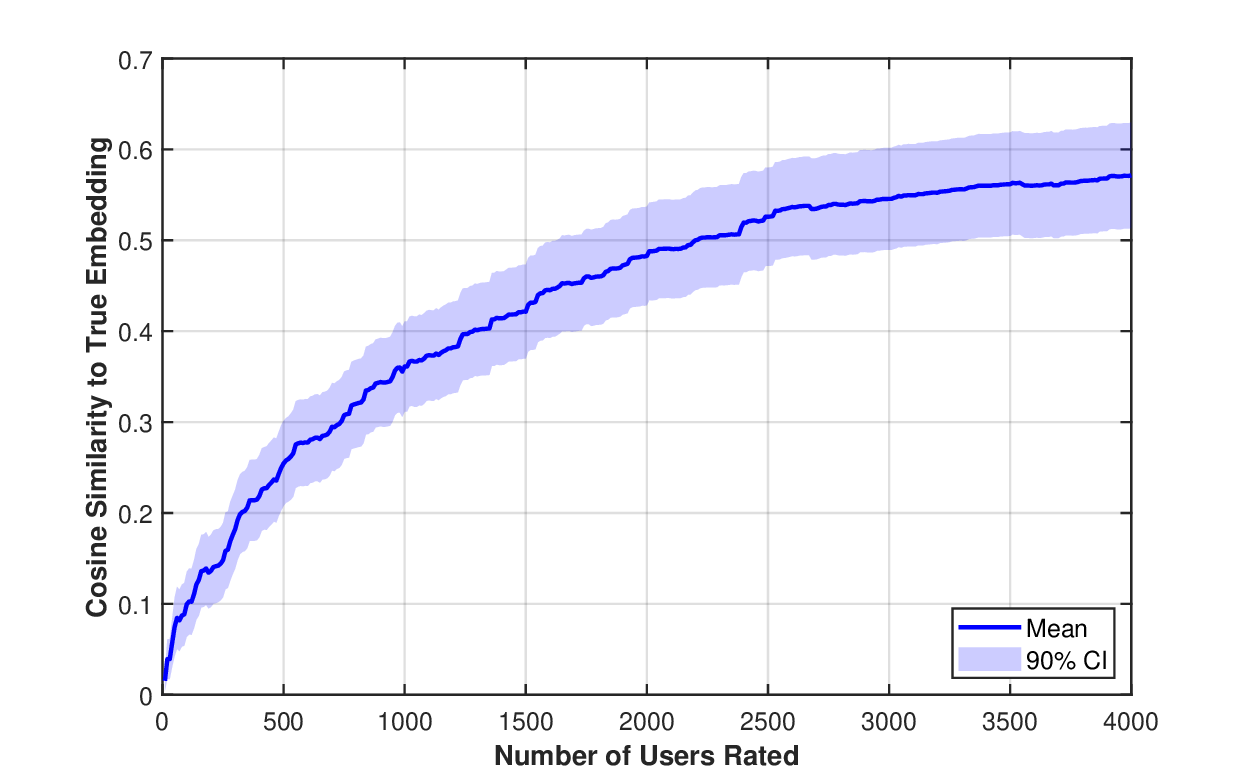
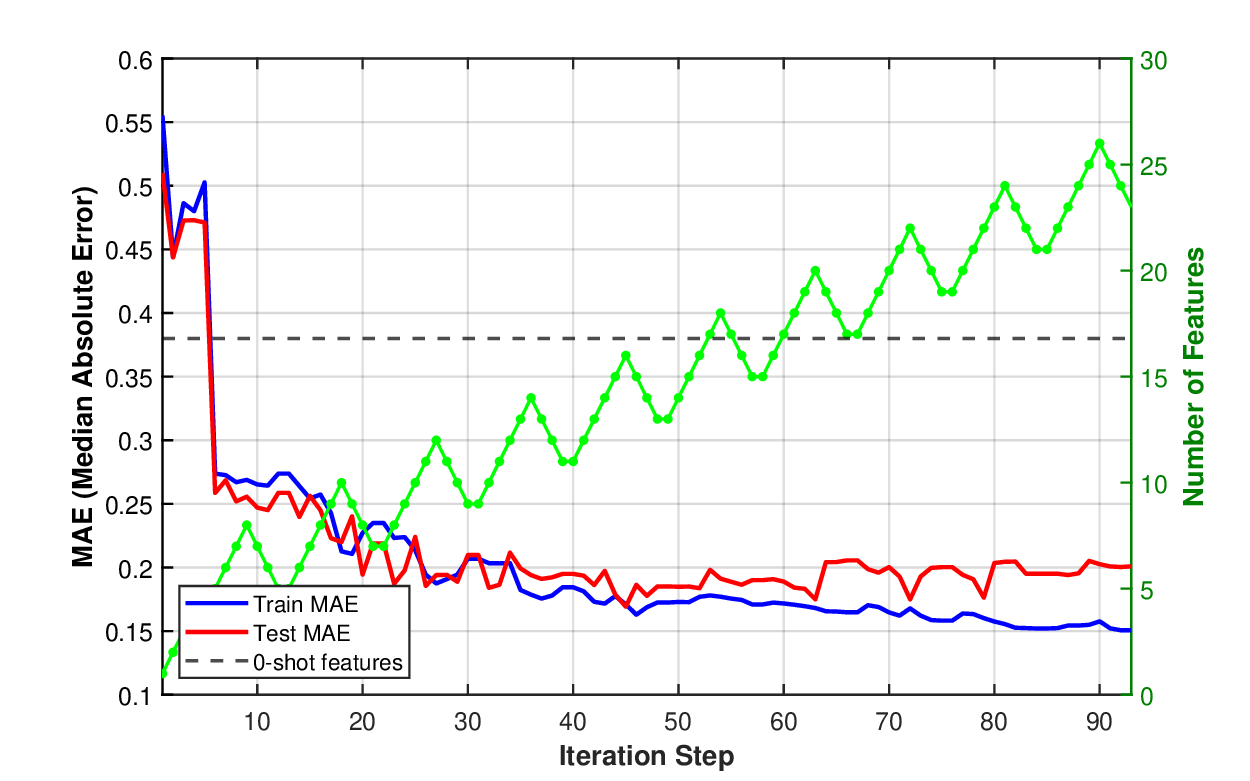
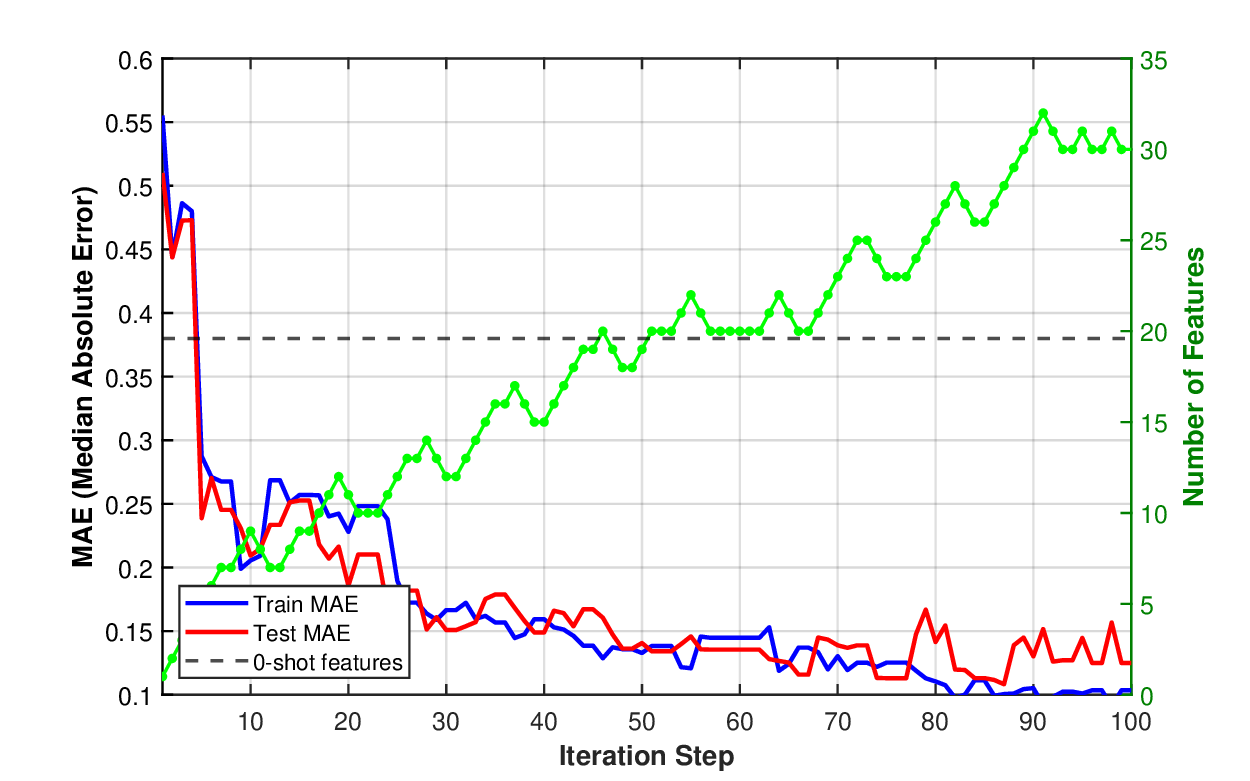
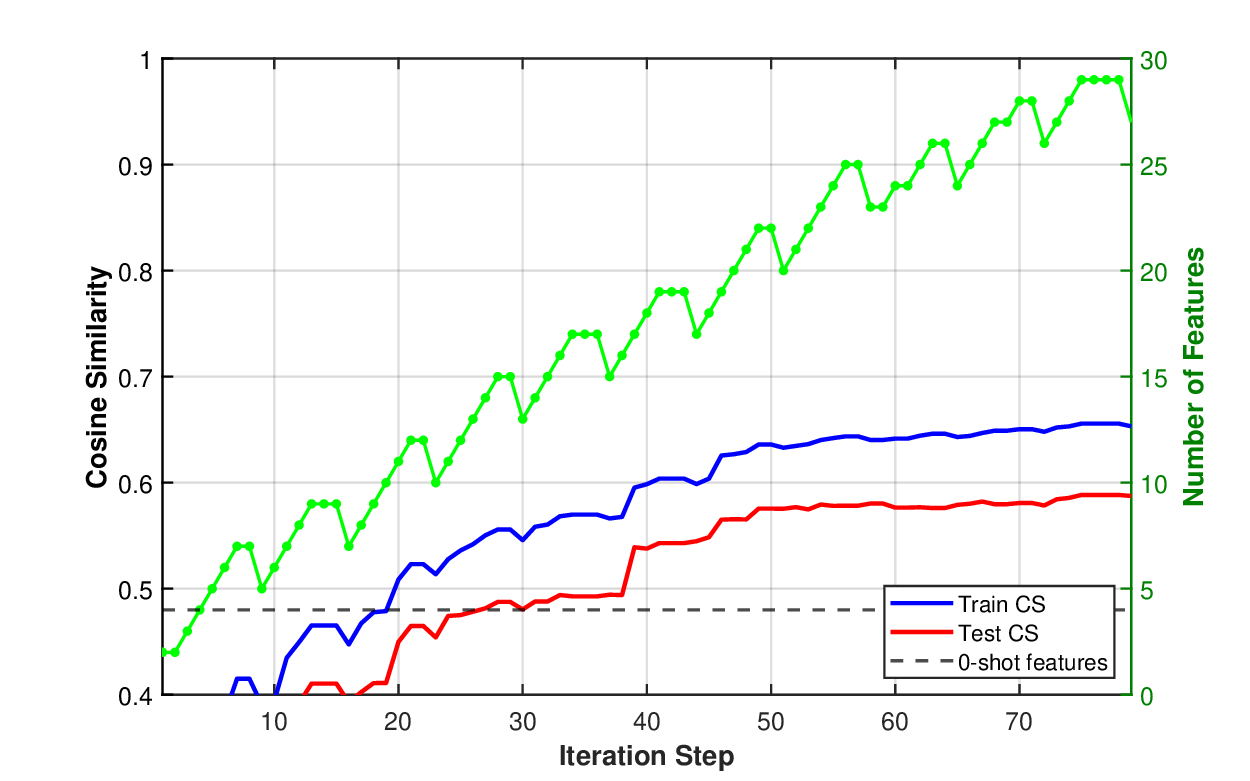
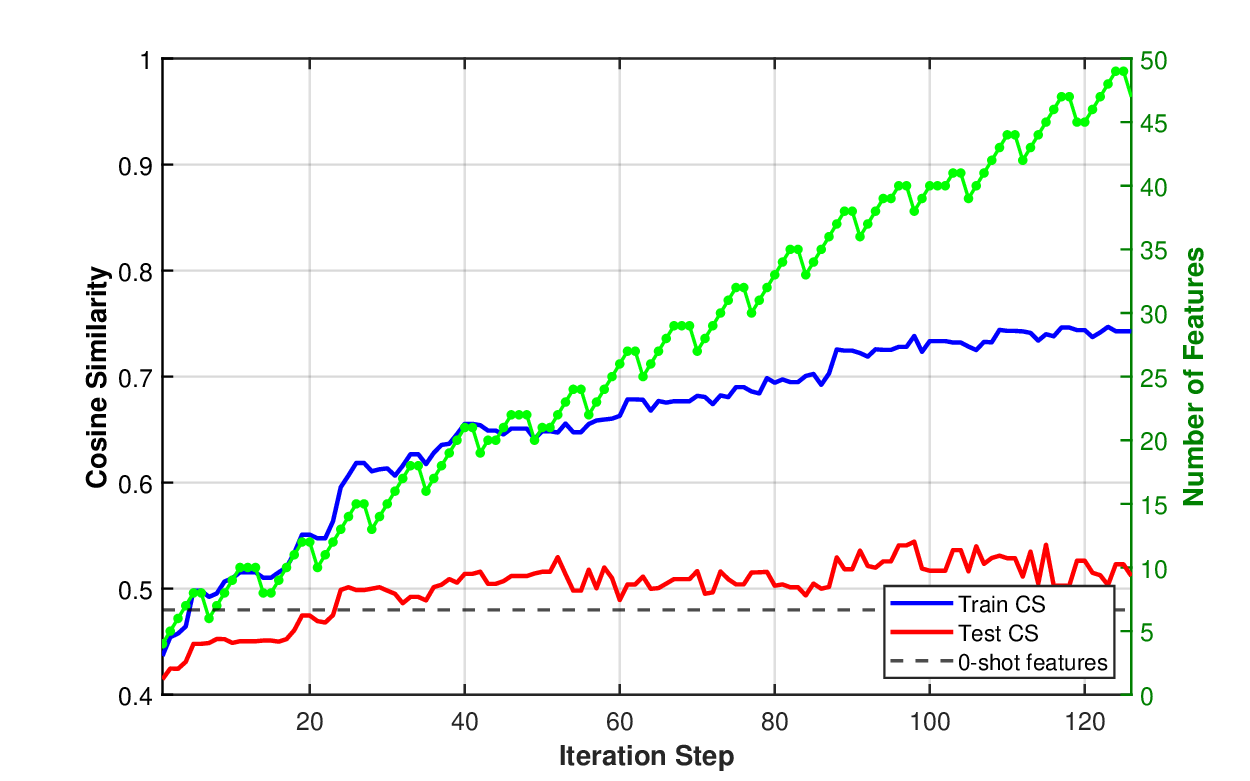
우리는 해석 가능한 의미적 특성을 통해 기초 모델과 전통 통계 모델을 연결하는 하이브리드 모델인 GenZ를 제안한다. 대형 언어 모델은 방대한 도메인 지식을 보유하지만, 예측 과제에 필수적인 데이터셋 고유 패턴을 포착하지 못하는 경우가 많다. 본 접근법은 통계 모델의 오류를 기반으로 그룹을 구분하고, 그 차이를 이용해 의미적 특성 설명을 반복적으로 발견함으로써 이러한 한계를 극복한다. 이를 일반화된 EM 알고리즘으로 공식화하여 의미적 특성 서술자와 통계 모델 파라미터를 공동 최적화한다. 고정된 기초 모델에 발견된 특성을 프롬프트하여 아이템을 분류하도록 하고, 이 판단을 잠재 이진 특성에 대한 잡음이 섞인 관측치로 취급한다. 이러한 이진 특성은 학습된 통계 관계를 통해 실수값 타깃을 예측한다. 주택 가격 예측(헤도닉 회귀)과 영화 추천의 콜드 스타트 협업 필터링 두 분야에 적용한 결과, 주택 가격에서는 의미적 특성을 활용해 중위 상대 오차 12%를 달성했으며, 일반 도메인 지식에만 의존한 GPT‑5 기반 베이스라인(38% 오차)을 크게 능가했다. 넷플릭스 영화 임베딩에서는 의미적 설명만으로 협업 필터링 표현을 예측해 코사인 유사도 0.59를 기록했으며, 이는 전통 협업 필터링으로 약 4,000개의 사용자 평점이 필요했던 수준과 동등하다. 발견된 특성들은 데이터셋 고유 패턴(예: 지역 주택 시장을 예측하는 건축 세부 요소, 사용자 선호를 좌우하는 프랜차이즈 소속) 을 드러내며, 이는 기초 모델의 일반 도메인 지식과는 다른 정보를 제공한다.💡 논문 핵심 해설 (Deep Analysis)

GenZ는 이러한 한계를 극복하기 위해 의미적 특성을 데이터‑주도적으로 생성한다. 구체적으로, 초기 통계 모델(예: 선형 회귀 또는 행렬 분해 모델)로부터 예측 오류가 큰 샘플들을 두 그룹(오류가 큰 그룹 vs. 오류가 작은 그룹)으로 나눈다. 그런 다음 LLM에게 두 그룹을 구분할 수 있는 차별적 설명을 생성하도록 프롬프트한다. 이 과정은 EM 알고리즘의 E‑스텝에 해당하는데, LLM이 제공한 설명을 이진 특성(예/아니오) 형태의 관측치로 변환한다. 이후 M‑스텝에서는 이러한 이진 특성을 잠재 변수로 간주하고, 통계 모델의 파라미터와 특성 설명자를 동시에 업데이트한다. 이 반복 과정을 통해 모델은 (1) LLM이 제공하는 자연어 기반 의미를 유지하면서, (2) 실제 데이터에 최적화된 특성 집합을 학습한다는 두 마리 토끼를 잡는다.
실험 결과는 두 도메인에서 인상적이다. 주택 가격 예측에서는 전통적인 헤도닉 회귀에 비해 12%의 중위 상대 오차를 달성했으며, 이는 GPT‑5만을 사용한 베이스라인(38% 오차)보다 3배 가량 개선된 것이다. 여기서 핵심은 “지붕 재료가 슬레이트인지 시멘트인지”, “주택이 최근 5년 내에 리노베이션 되었는가”와 같은 세부적인 건축 특성이 LLM에 의해 자동으로 추출되고, 통계 모델에 직접 연결된 점이다. 영화 추천에서는 콜드 스타트 상황에서 사용자 평점이 전혀 없는 영화에 대해, 의미적 설명(예: “액션·SF 프랜차이즈의 3번째 작품”, “주연 배우가 이전에 높은 평점을 받은 영화에 출연”)만으로도 기존 협업 필터링이 4,000개의 평점을 필요로 하는 수준의 코사인 유사도 0.59를 달성했다. 이는 의미적 특성이 사용자 선호를 효과적으로 대변한다는 강력한 증거다.
또한, 발견된 특성들은 도메인 전문가가 사전에 정의하지 않은 데이터‑특화 패턴을 드러낸다. 이는 기초 모델이 사전 학습 단계에서 접하지 못한 최신 트렌드나 지역적 변동성을 포착할 수 있게 해준다. 따라서 GenZ는 LLM의 일반 지식과 전통 통계 모델의 데이터 적합성을 결합한 새로운 패러다임을 제시한다는 점에서 학계와 산업 모두에 큰 파급 효과를 기대할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리