실제 업무 기반 LLM 에이전트 도구 활용 평가 벤치마크
📝 원문 정보
- Title: MCPAgentBench: A Real-world Task Benchmark for Evaluating LLM Agent MCP Tool Use
- ArXiv ID: 2512.24565
- 발행일: 2025-12-31
- 저자: Wenrui Liu, Zixiang Liu, Elsie Dai, Wenhan Yu, Lei Yu, Tong Yang, Jinjun Han, Hong Gao
📝 초록 (Abstract)
대형 언어 모델(LLM)이 자율 에이전트로 활용되는 사례가 늘어나면서, Model Context Protocol(MCP)을 통한 외부 도구 사용이 향후 핵심 기술로 떠오르고 있다. 기존 MCP 평가 세트는 외부 MCP 서비스에 의존하고 난이도 인식이 부족하다는 문제점을 가지고 있다. 이를 해결하고자 본 연구는 실제 MCP 정의를 기반으로 한 벤치마크인 MCPAgentBench를 제안한다. 본 벤치마크는 실제 업무와 유사한 과제와 시뮬레이션된 MCP 도구를 포함한 데이터셋을 구축하고, 동적 샌드박스 환경에서 에이전트에게 방해 요소가 포함된 후보 도구 목록을 제공함으로써 도구 선택 및 구별 능력을 평가한다. 또한 과제 완수율과 실행 효율성을 동시에 측정하는 종합 지표를 도입하였다. 최신 주류 LLM들을 대상으로 한 실험 결과, 복합적이고 다단계 도구 호출이 요구되는 과제에서 모델 간 성능 차이가 크게 나타났다. 모든 코드는 오픈소스로 공개한다.💡 논문 핵심 해설 (Deep Analysis)
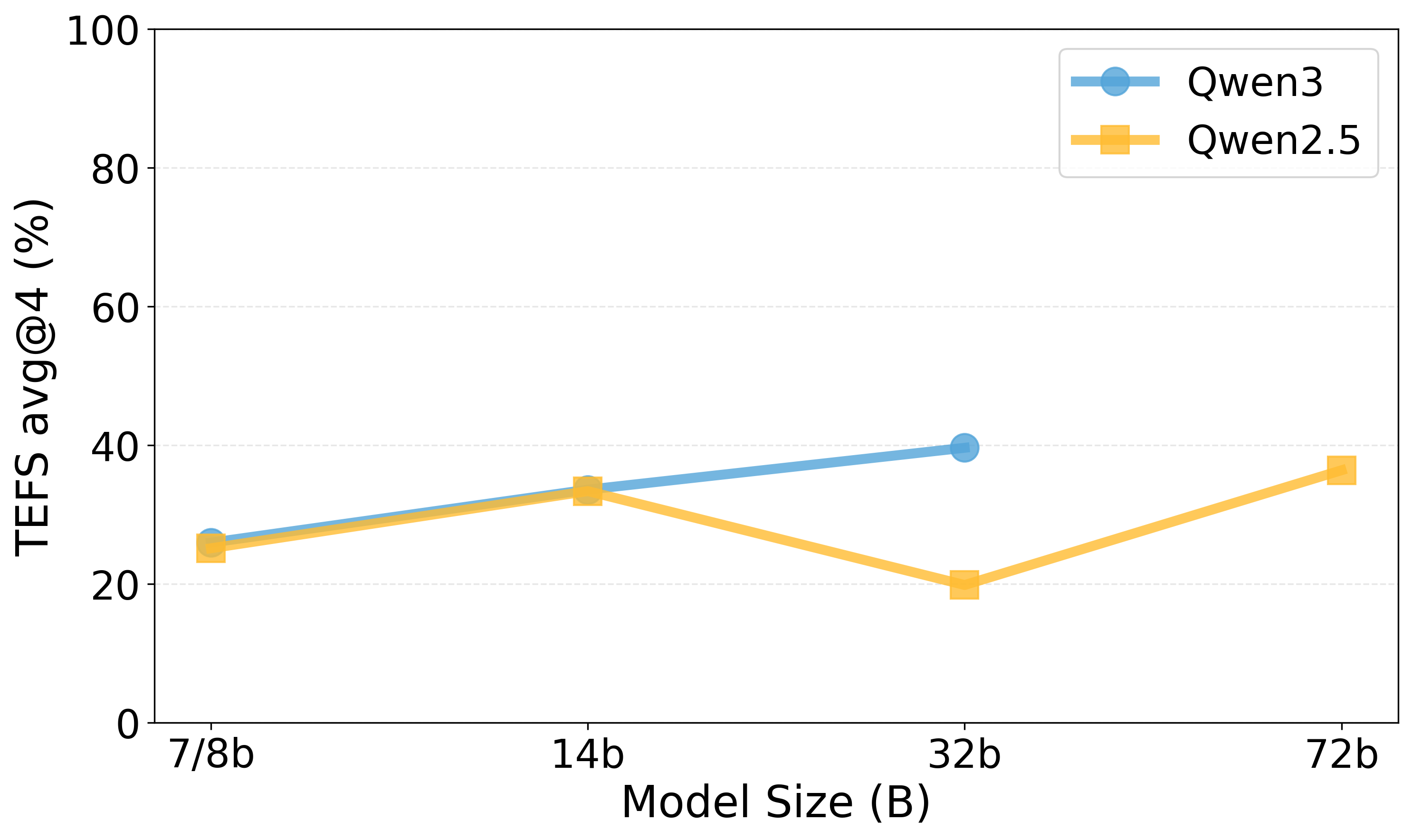
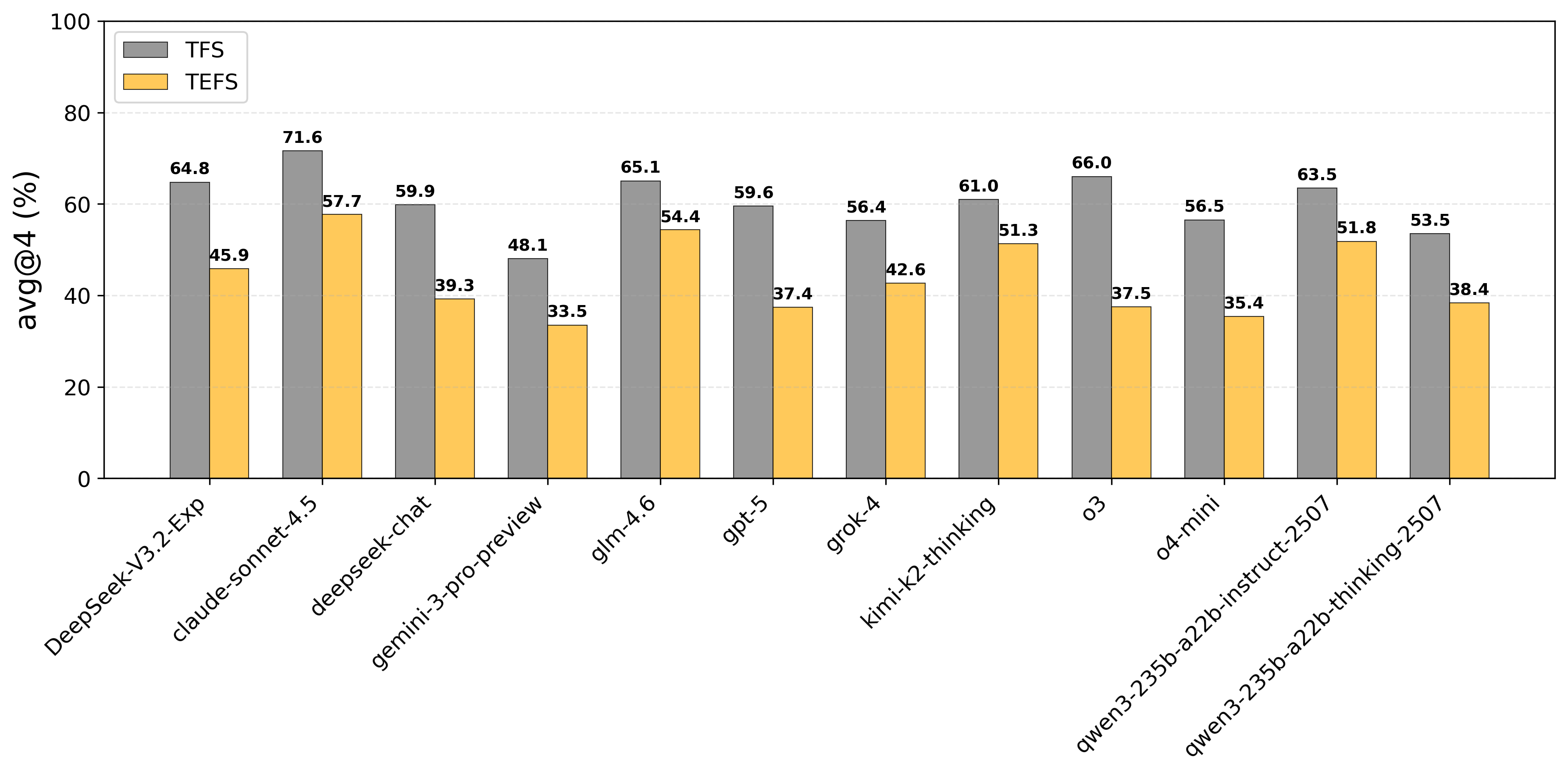
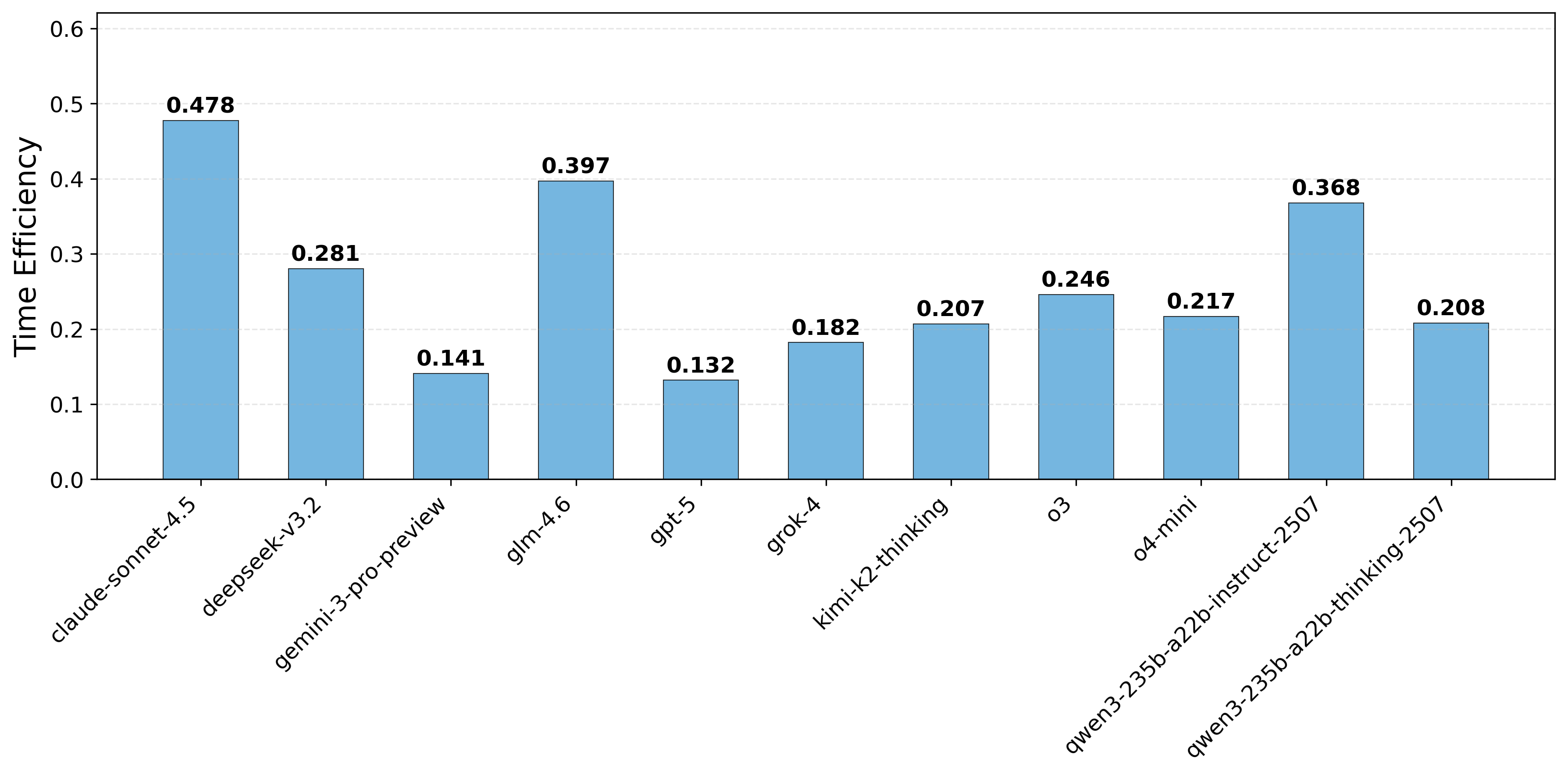
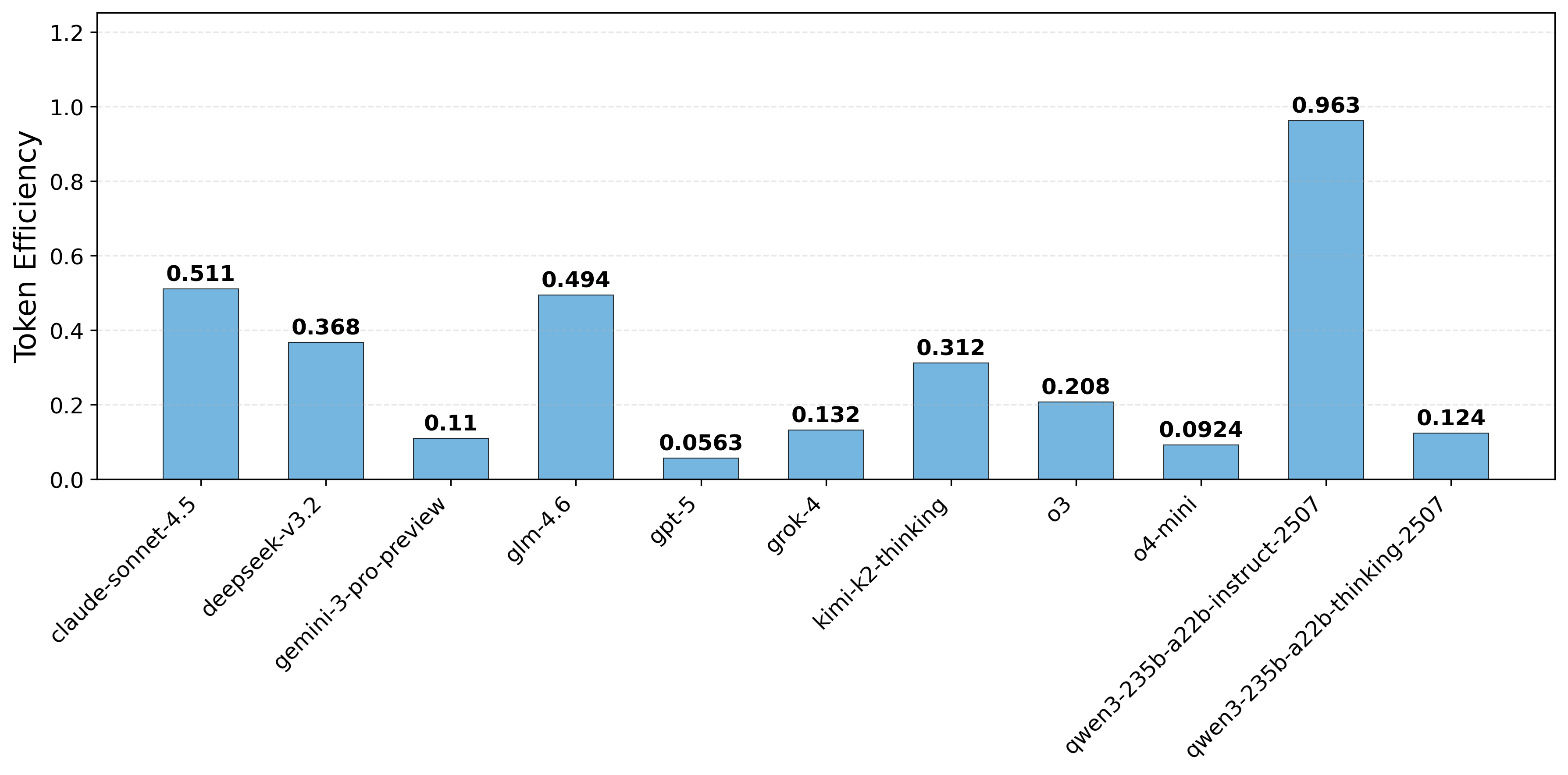
평가 지표 역시 두 축으로 확장되었다. 전통적인 “Task Completion Rate”(과제 성공률) 외에 “Execution Efficiency”(실행 효율성)라는 새로운 메트릭을 도입해, 모델이 최소한의 호출 횟수와 연산 비용으로 목표를 달성했는지를 정량화한다. 이는 실제 서비스 운영에서 비용 절감과 응답 시간 단축이라는 실질적 가치를 반영한다.
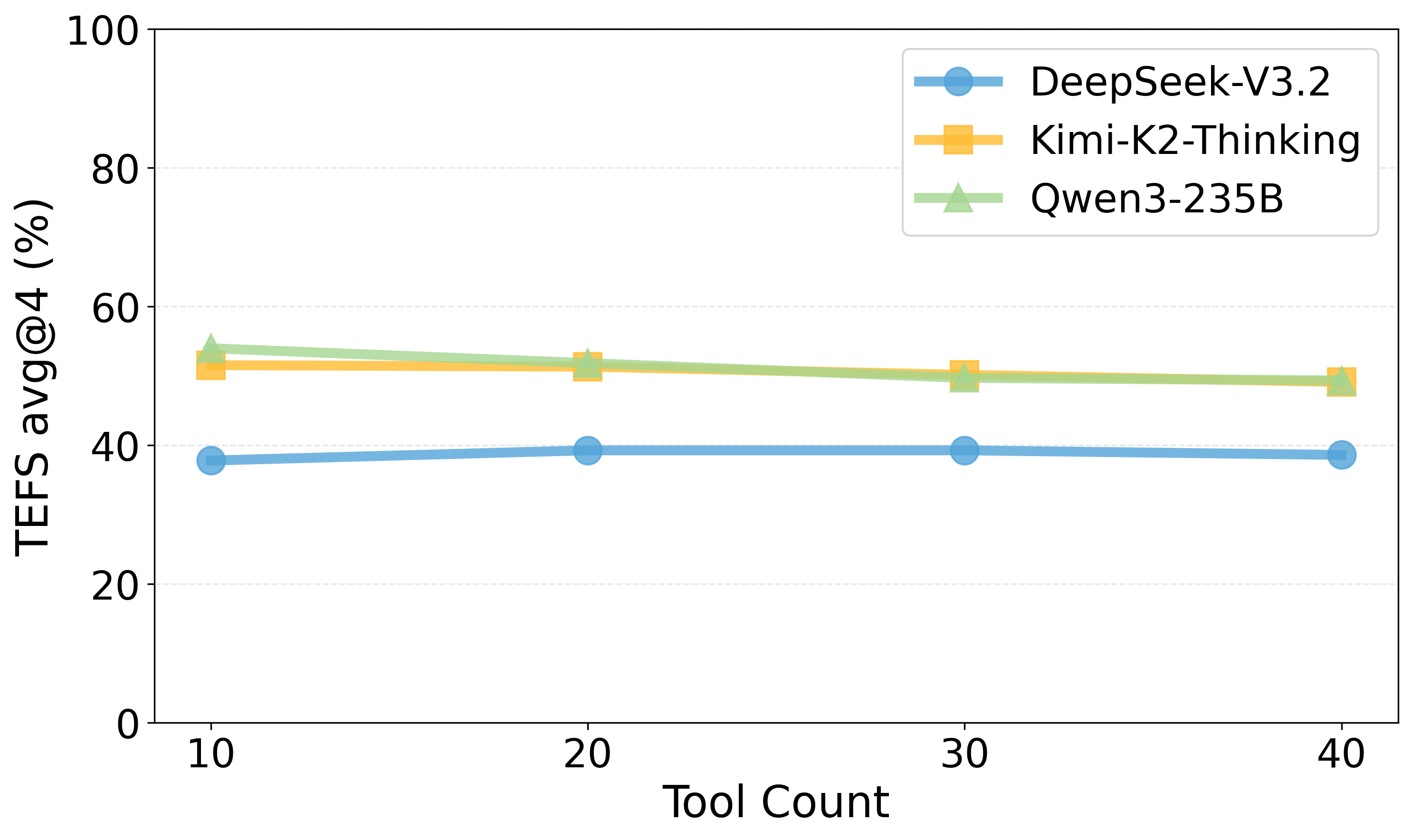
실험 결과는 흥미롭다. 최신 GPT‑4, Claude‑3, LLaMA‑2 등 여러 최신 모델을 동일한 환경에 투입했을 때, 복합 다단계 도구 연계가 필요한 시나리오에서 성능 격차가 크게 나타났다. 특히, 모델이 “도구 선택 → 파라미터 조합 → 결과 검증”의 순환 과정을 몇 차례 반복해야 하는 경우, 일부 모델은 과도한 호출을 발생시켜 효율성 점수가 급락했다. 반면, 사전 학습된 도구 사용 프롬프트 템플릿을 내장한 모델은 적은 호출 횟수로 높은 성공률을 기록했다. 이는 향후 LLM 에이전트를 설계할 때, 도구 사용에 특화된 프롬프트 엔지니어링과 메타러닝이 중요함을 시사한다.
마지막으로, 코드와 데이터가 모두 오픈소스로 제공된다는 점은 연구 재현성을 크게 높인다. 커뮤니티가 새로운 MCP 도구를 추가하거나 난이도 조절 파라미터를 변형함으로써 벤치마크를 확장할 수 있다. 따라서 MCPAgentBench는 현재뿐 아니라 미래의 LLM‑Agent 연구와 산업 적용을 위한 표준 평가 플랫폼으로 자리매김할 가능성이 높다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리