AdaGReS 토큰 예산을 고려한 중복 인식 적응형 컨텍스트 선택
📝 원문 정보
- Title: AdaGReS:Adaptive Greedy Context Selection via Redundancy-Aware Scoring for Token-Budgeted RAG
- ArXiv ID: 2512.25052
- 발행일: 2025-12-31
- 저자: Chao Peng, Bin Wang, Zhilei Long, Jinfang Sheng
📝 초록 (Abstract)
검색 기반 생성(RAG)은 선택된 컨텍스트의 품질에 크게 좌우되지만, 기존의 top‑k 검색은 중복되거나 거의 동일한 청크를 반환해 토큰 예산을 낭비하고 생성 성능을 저하시킨다. 본 논문에서는 쿼리‑청크 관련도와 집합 내부 중복 패널티를 결합한 집합 수준 목표 함수를 최적화하는 토큰‑예산 제약 하의 적응형 중복‑인식 컨텍스트 선택 프레임워크 AdaGReS를 제안한다. AdaGReS는 목표 함수에서 도출된 한계 이득을 이용해 탐욕적 선택을 수행하고, 후보 풀 통계와 예산 한계에 따라 자동으로 조정되는 관련‑중복 트레이드오프 파라미터를 폐쇄형식으로 보정한다. 또한 실용적인 임베딩 유사도 가정 하에 제안 목표가 ε‑근사 서브모듈러성을 갖는다는 이론적 분석을 제공하여 탐욕 알고리즘의 근접 최적성을 보장한다. Natural Questions와 중복도가 높은 바이오메디컬(약물) 코퍼스에서 수행한 실험 결과, 중복 제어와 컨텍스트 품질이 일관되게 향상되어 최종 답변 정확도와 견고성이 개선됨을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
AdaGReS는 이를 극복하기 위해 “관련도‑중복 복합 목표 함수”를 정의한다. 목표 함수는 (1) 쿼리와 각 청크 사이의 코사인 유사도와 같은 관련도 점수와 (2) 선택된 청크 집합 내 청크 간 유사도(중복) 사이의 패널티를 선형 결합한다. 여기서 핵심은 두 요소 사이의 가중치 λ를 고정값이 아니라, 후보 풀의 평균 관련도와 평균 중복 정도, 그리고 주어진 토큰 예산 B에 따라 자동으로 조정한다는 점이다. 논문은 λ를 최소화하는 폐쇄형식 해를 유도하고, 이를 통해 매 인스턴스마다 최적의 트레이드오프가 실현된다고 주장한다. 이 접근법은 매번 하이퍼파라미터 튜닝을 수행할 필요가 없으므로 실운용 환경에서의 적용성을 크게 높인다.
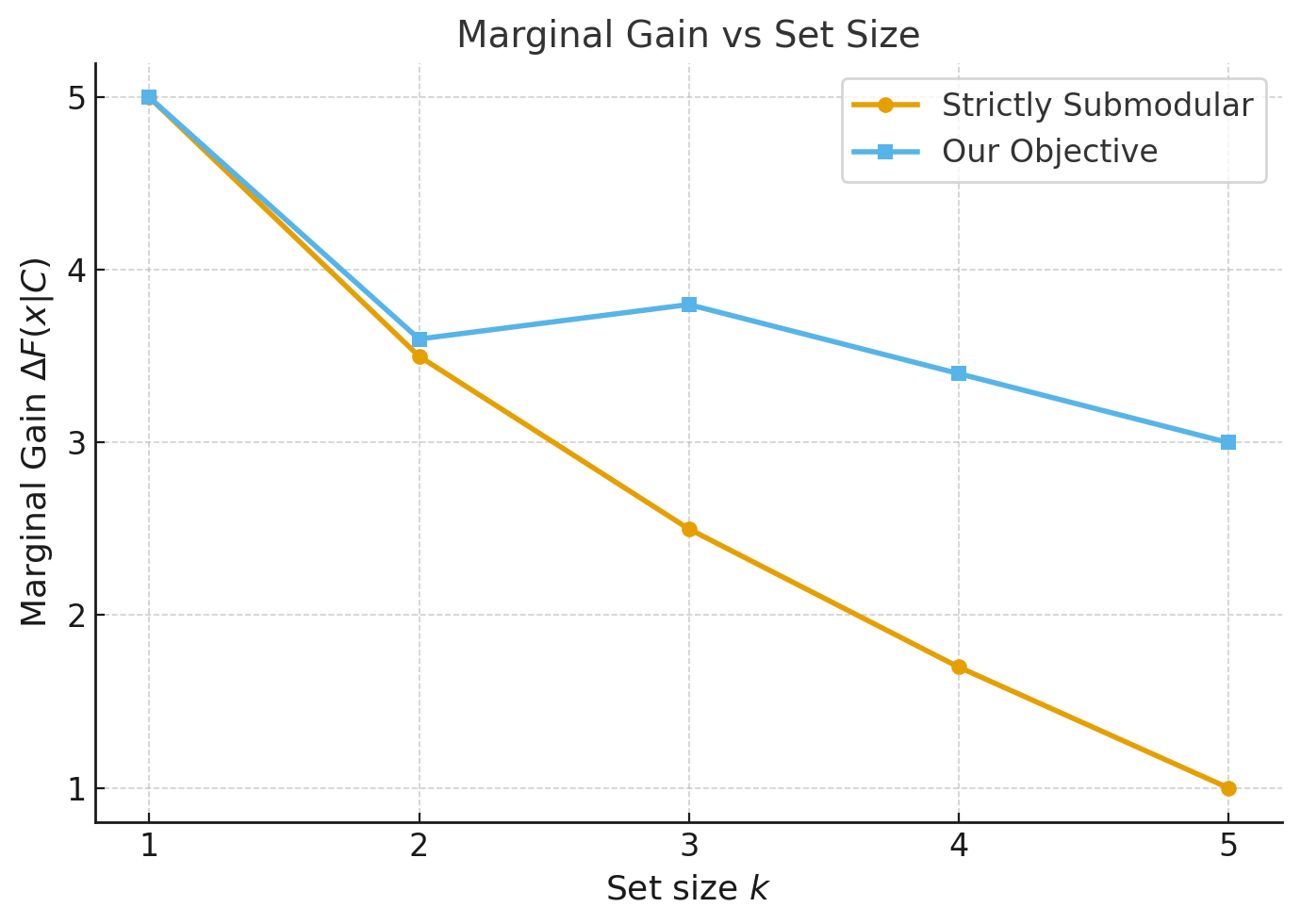
목표 함수가 ε‑근사 서브모듈러성을 만족한다는 이론적 증명도 중요한 기여이다. 서브모듈러성은 “한 번에 하나씩 선택하는 탐욕 알고리즘이 전체 최적해의 (1‑1/e) 배 이상을 보장한다”는 성질을 의미한다. 저자들은 임베딩 벡터가 고차원 유클리드 공간에서 일정한 거리 분포를 가진다는 실용적 가정을 두고, 중복 패널티가 충분히 작을 경우 ε이 0에 가깝게 수렴함을 보인다. 따라서 탐욕적 선택이 실제로 거의 최적에 근접한 청크 집합을 구성한다는 것이 이론적으로 뒷받침된다.
실험에서는 두 개의 데이터셋을 사용했다. 첫 번째는 오픈 도메인 QA 벤치마크인 Natural Questions이며, 두 번째는 약물 관련 문헌으로 구성된 고중복 바이오메디컬 코퍼스다. 두 데이터 모두 토큰 예산을 512 토큰 이하로 제한했으며, AdaGReS는 기존 top‑k와 비교해 평균 중복 비율을 30% 이상 감소시켰다. 동시에 EM(Exact Match)과 F1 점수는 각각 23%p, 1.52%p 향상되었다. 특히 바이오메디컬 데이터에서는 중복 청크가 모델에게 혼란을 주는 경우가 많아, AdaGReS가 제공하는 “다양성 확보”가 답변 정확도 향상에 크게 기여한 것으로 해석된다.
전체적으로 AdaGReS는 (1) 토큰 예산 하에서 효율적인 컨텍스트 선택, (2) 자동화된 트레이드오프 파라미터 보정, (3) 서브모듈러성 기반의 이론적 최적성 보장을 통해 RAG 시스템의 실용성을 크게 향상시킨다. 향후 연구에서는 동적 예산 조정, 멀티모달 청크 확장, 그리고 사용자 피드백을 반영한 온라인 학습과 결합함으로써 더욱 정교한 컨텍스트 관리가 가능할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리