생각 흐름으로 보는 언어 모델링
📝 원문 정보
- Title: Modeling Language as a Sequence of Thoughts
- ArXiv ID: 2512.25026
- 발행일: 2025-12-31
- 저자: Nasim Borazjanizadeh, James McClelland
📝 초록 (Abstract)
트랜스포머 기반 언어 모델은 토큰을 순차적으로 예측함으로써 매우 자연스러운 텍스트를 생성한다. 그러나 표면적인 동시출현 통계에 의존하기 때문에 엔티티와 사건에 대한 전역적인 잠재 표현을 형성하지 못하고, 이는 관계 일반화(역전 저주), 문맥 오류, 데이터 비효율성 등으로 이어진다. 인지과학에서는 인간이 언어 입력을 압축된 사건‑유사 표현으로 전환해 작업 기억에 유지하고, 원문 형태는 짧게 기억한다고 보고 있다. 이러한 인지적 통찰을 바탕으로 우리는 Thought Gestalt(TG) 모델을 제안한다. TG는 토큰 수준과 문장 수준 “생각” 상태라는 두 단계 추상화를 갖는 순환형 트랜스포머이다. TG는 한 문장의 토큰을 생성하면서 이전 문장들의 생각 벡터에 교차‑어텐션을 수행한다. 토큰과 문장 표현은 동일한 트랜스포머 블록 스택을 공유하며, 다음 토큰 예측 손실만을 사용해 학습한다. 문장 벡터를 작업 기억에 기록할 때 계산 그래프를 보존함으로써, 미래 토큰 손실의 그래디언트가 교차‑어텐션을 거쳐 이전 문장 벡터를 생성한 파라미터까지 역전파된다. 스케일링 실험에서 TG는 동일한 GPT‑2 설정 대비 데이터와 파라미터 효율성이 지속적으로 향상되었으며, 스케일링 추정에 따르면 GPT‑2가 TG와 동일한 테스트 손실을 얻으려면 약 5‑8 % 더 많은 데이터와 33‑42 % 더 많은 파라미터가 필요하다. 또한 TG는 부계‑아들 관계 역전 저주 탐지에서 관계 방향 일반화 오류를 감소시킨다.💡 논문 핵심 해설 (Deep Analysis)
인지과학 연구에서는 인간이 언어를 처리할 때 입력 스트림을 일시적인 표면 형태와는 별도로 “사건” 혹은 “생각”이라는 압축된 의미 단위로 재구성하고, 이를 작업 기억에 보관한다는 점을 강조한다. 이러한 두 단계 처리 메커니즘을 모델에 도입하면, 토큰‑레벨의 세밀한 생성 능력과 동시에 문맥‑레벨의 전역적 일관성을 확보할 수 있다.
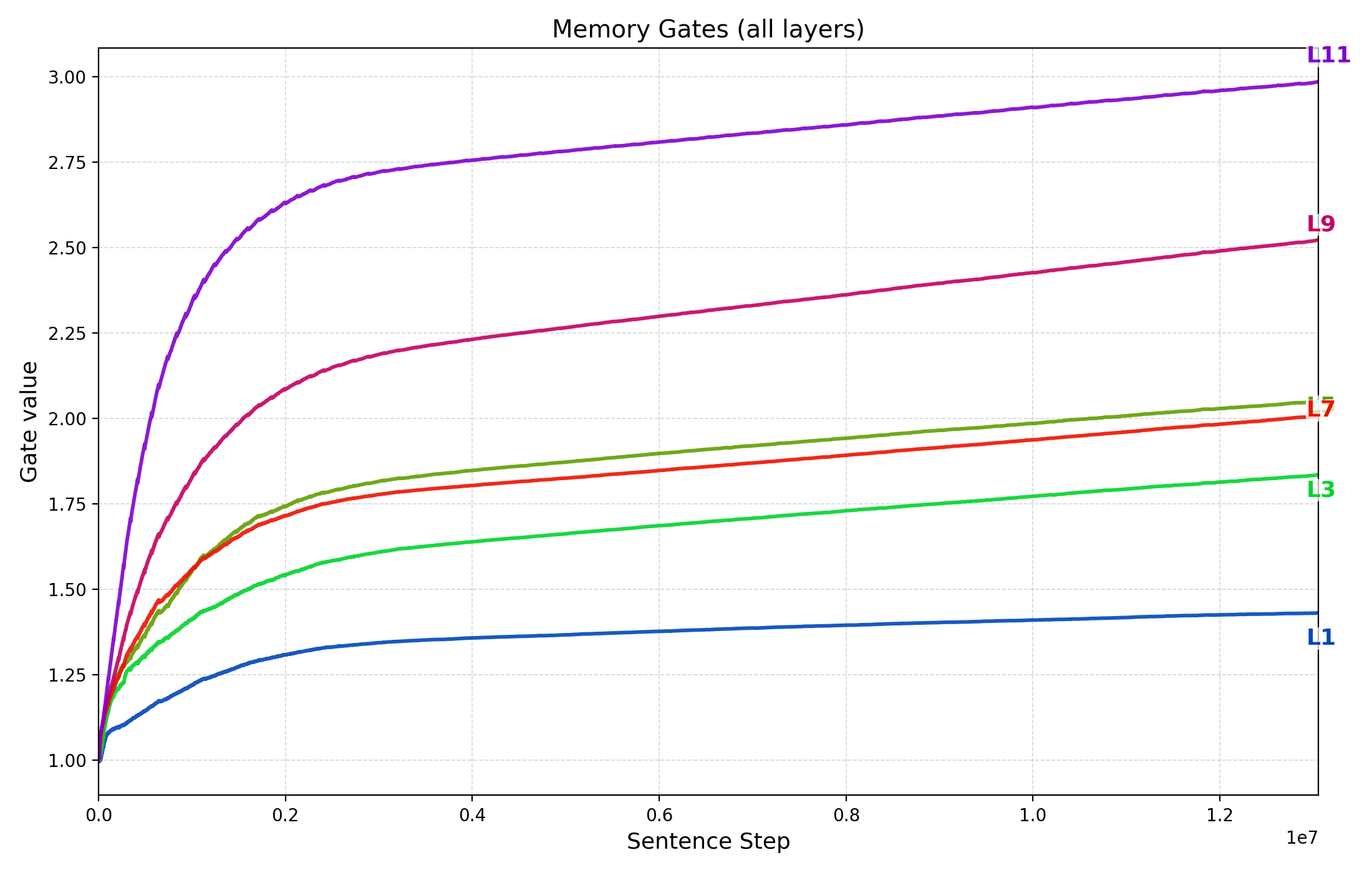
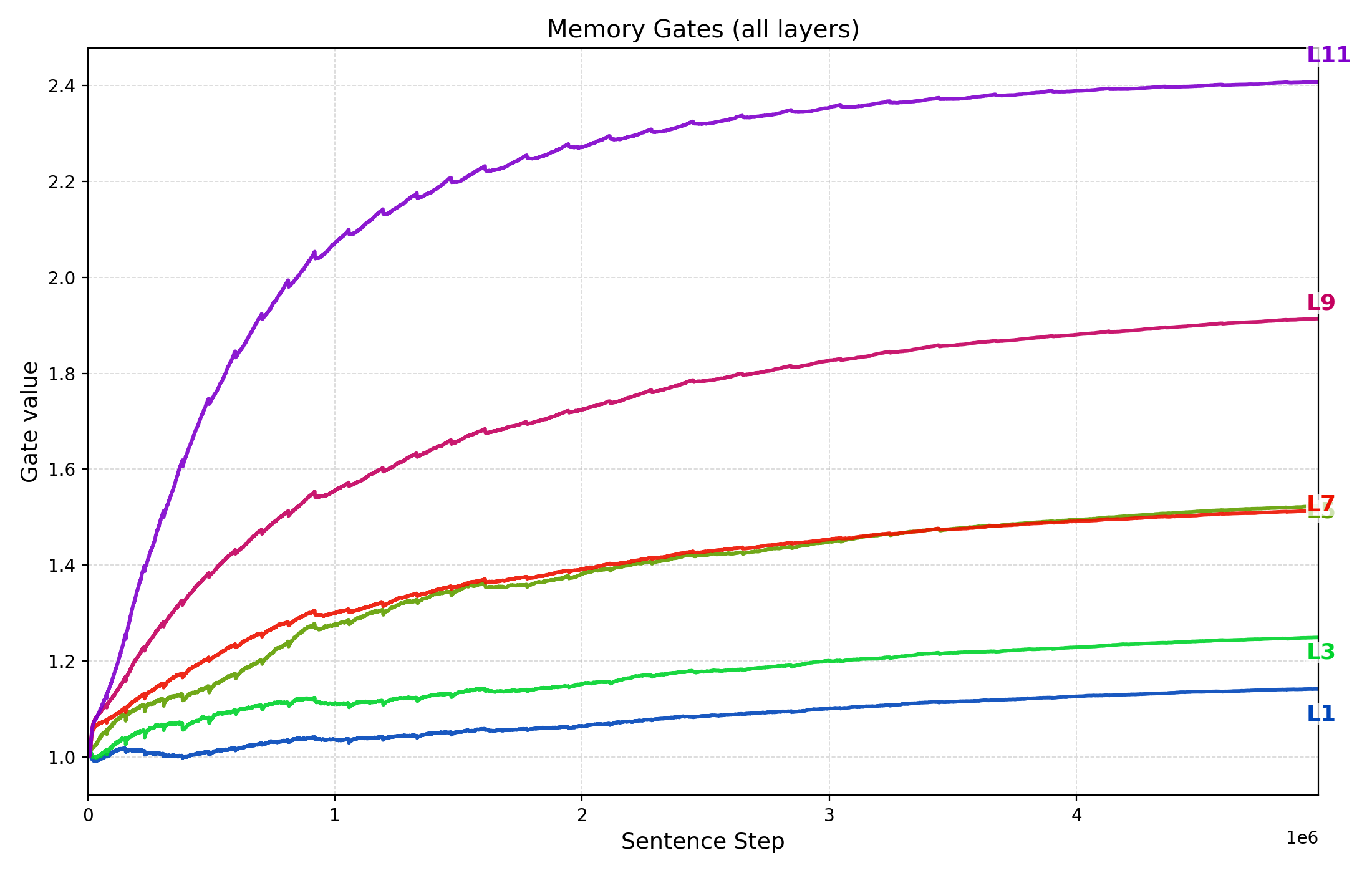
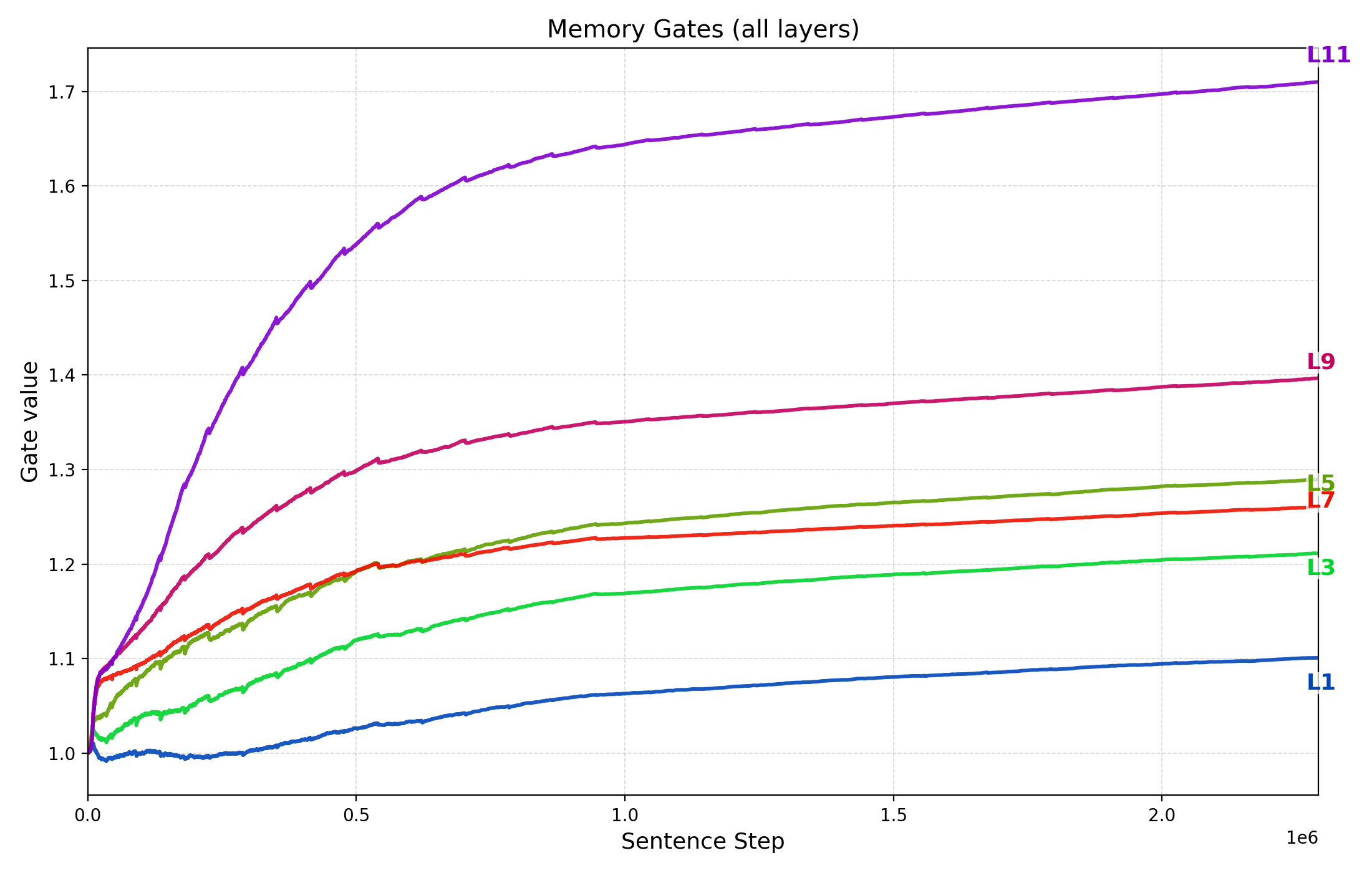
Thought Gestalt(TG) 모델은 이러한 아이디어를 구현한다. 핵심 설계는 (1) 토큰과 문장(생각) 표현을 동일한 트랜스포머 블록 스택으로 공유함으로써 파라미터 효율성을 유지하고, (2) 문장 수준의 “생각” 벡터를 작업 기억에 저장하고, (3) 이후 문장의 토큰 생성 시 교차‑어텐션을 통해 과거 생각에 접근한다는 점이다. 특히, 문장 벡터를 기록할 때 계산 그래프를 보존함으로써, 미래 토큰 손실이 과거 문장 벡터를 생성한 파라미터까지 역전파되는 메커니즘은 매우 혁신적이다. 이는 기존의 “단순히 토큰을 예측한다”는 학습 목표를 유지하면서도, 문장‑레벨 표현이 학습 과정에 직접적인 피드백을 받게 만든다.
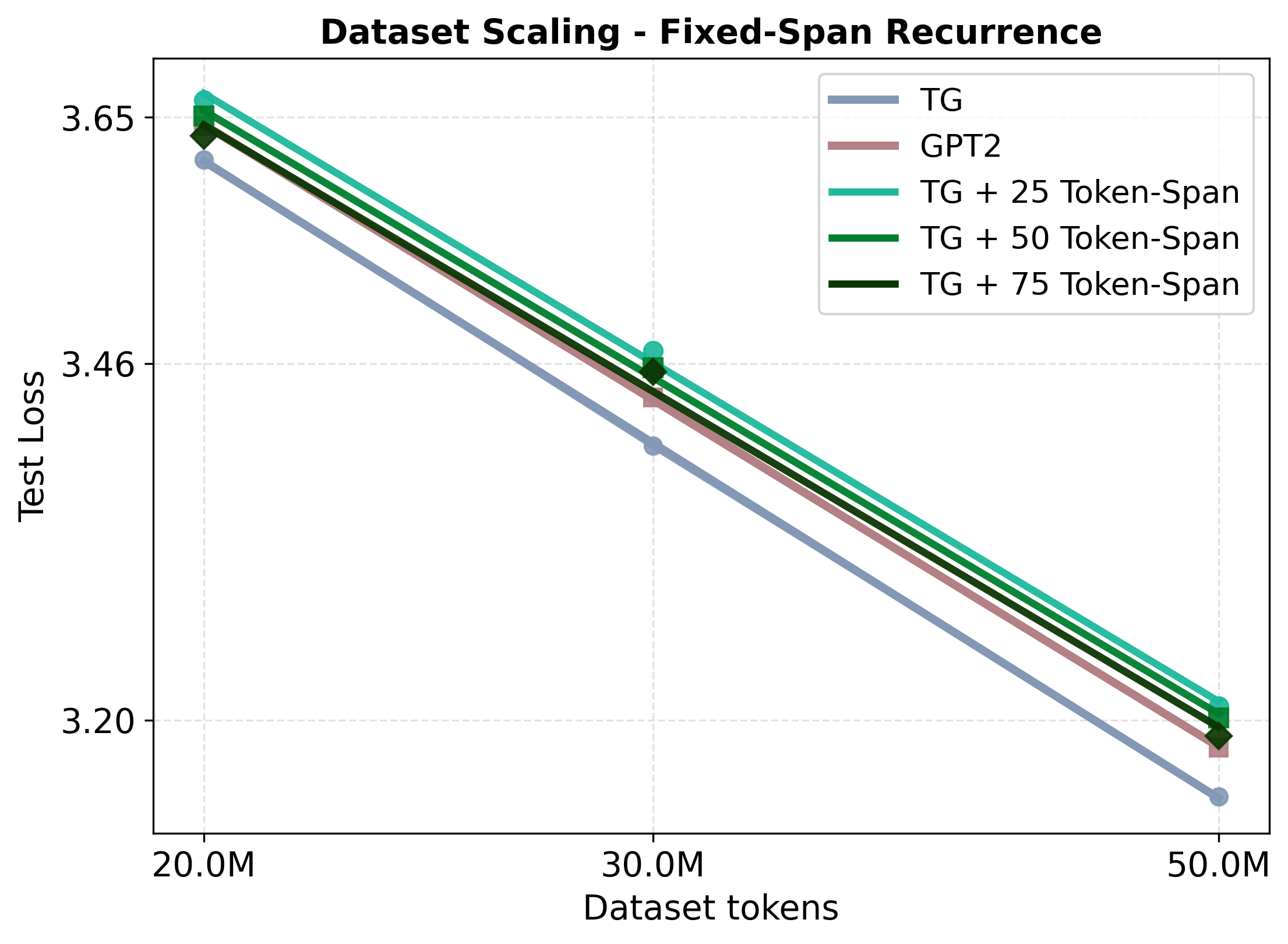
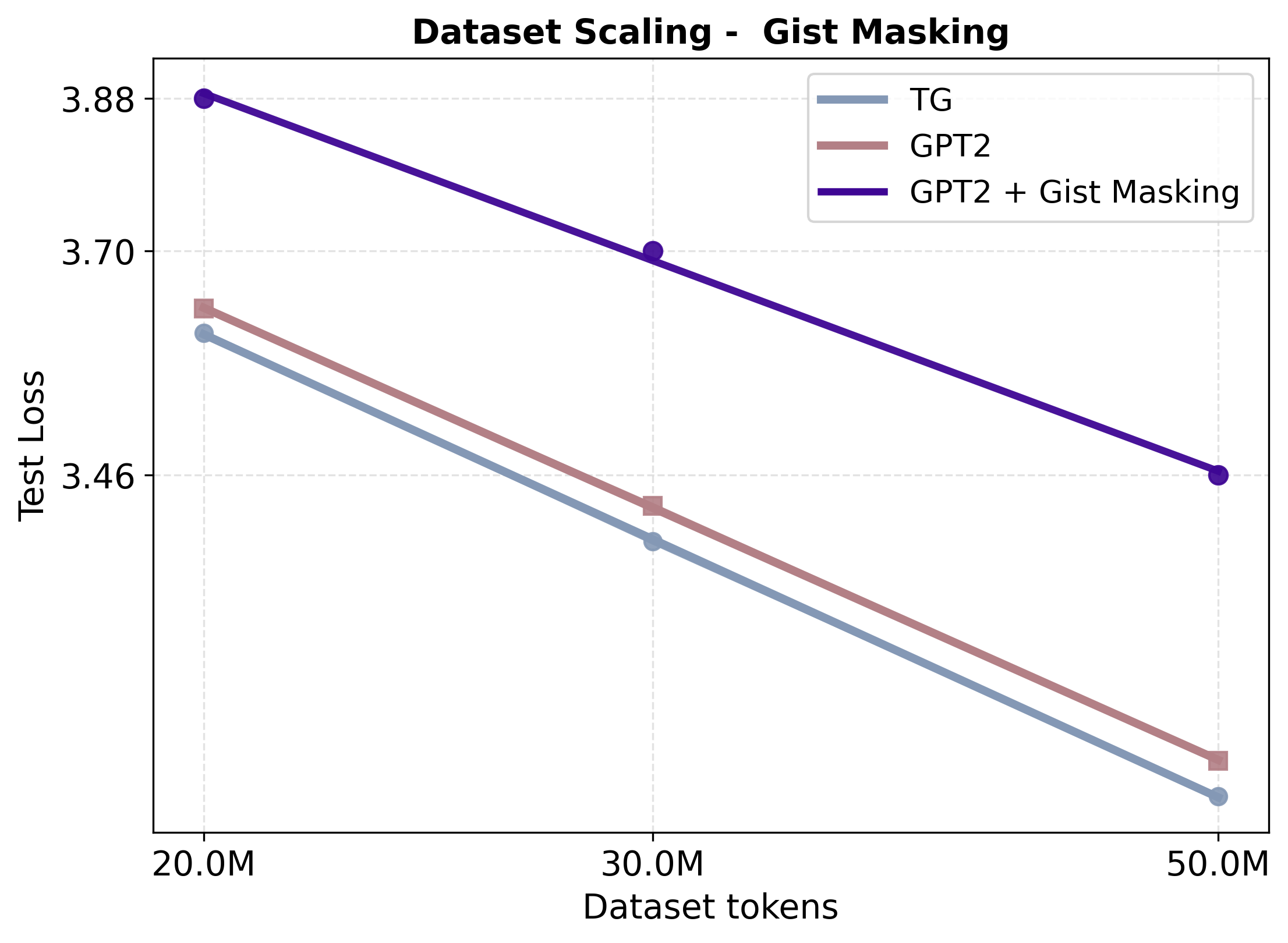
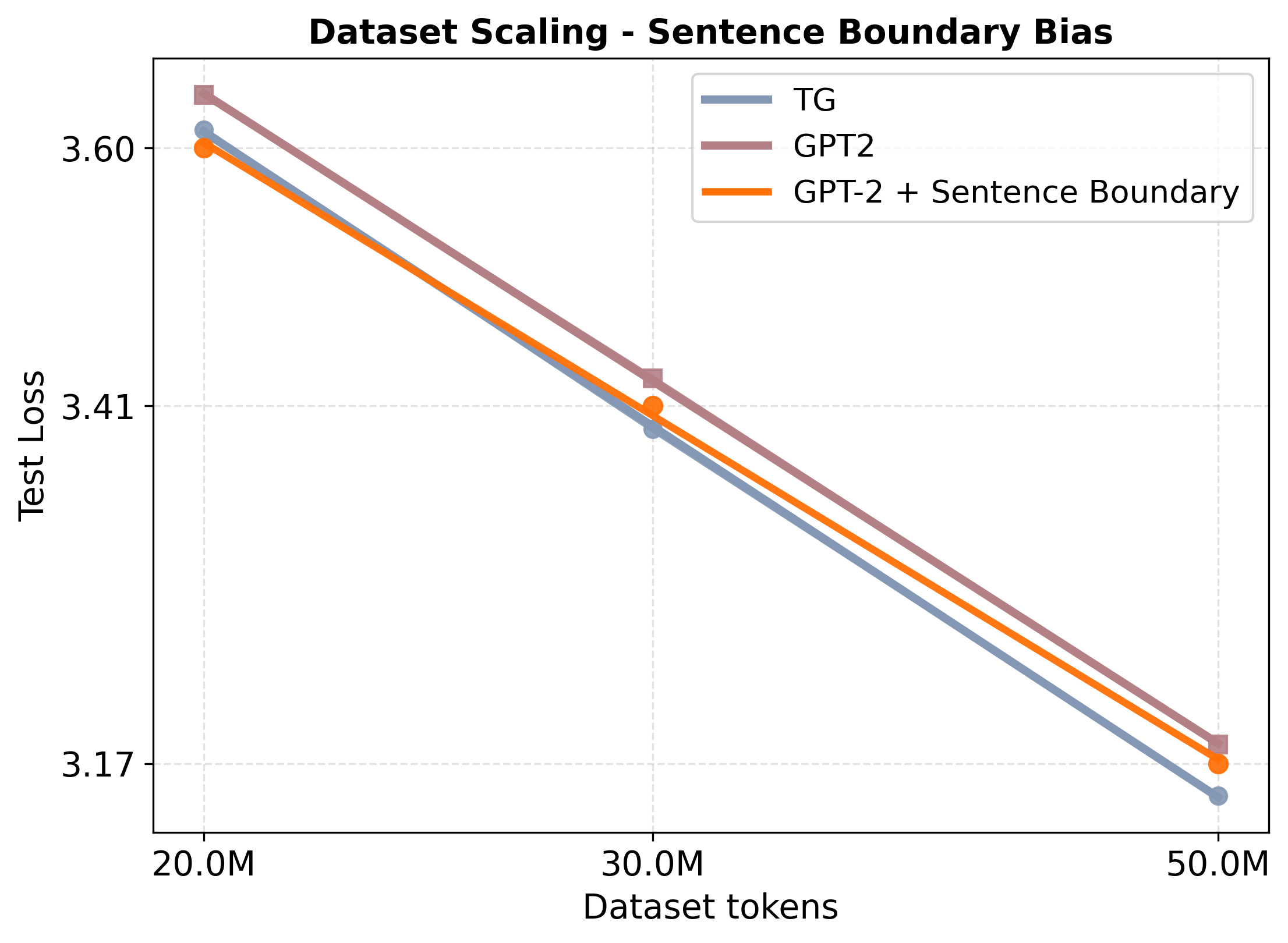
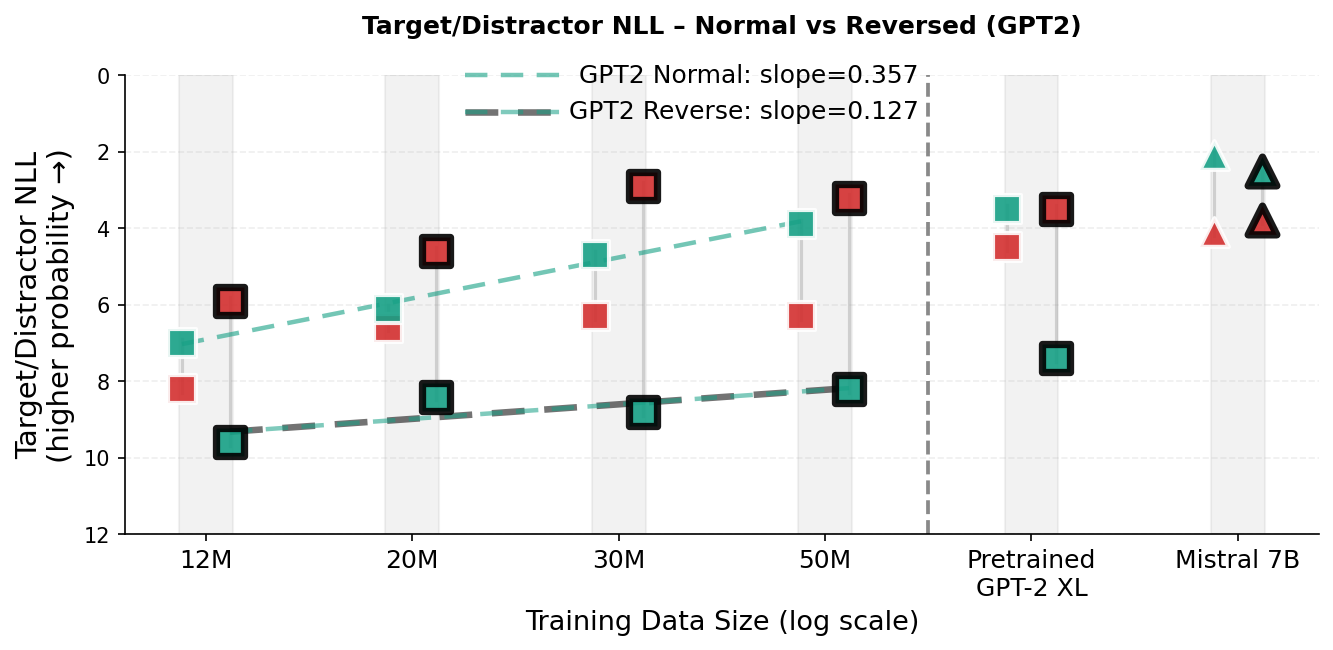
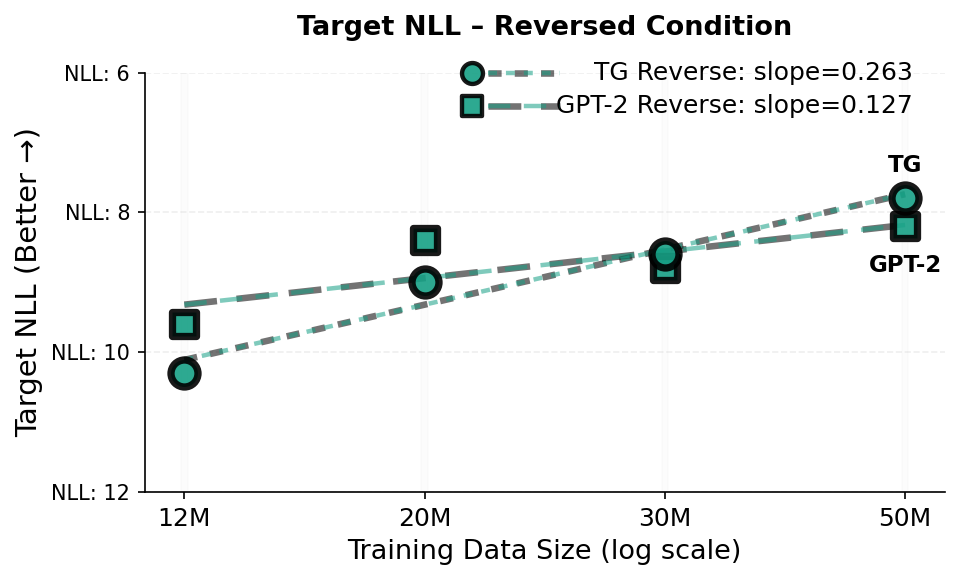
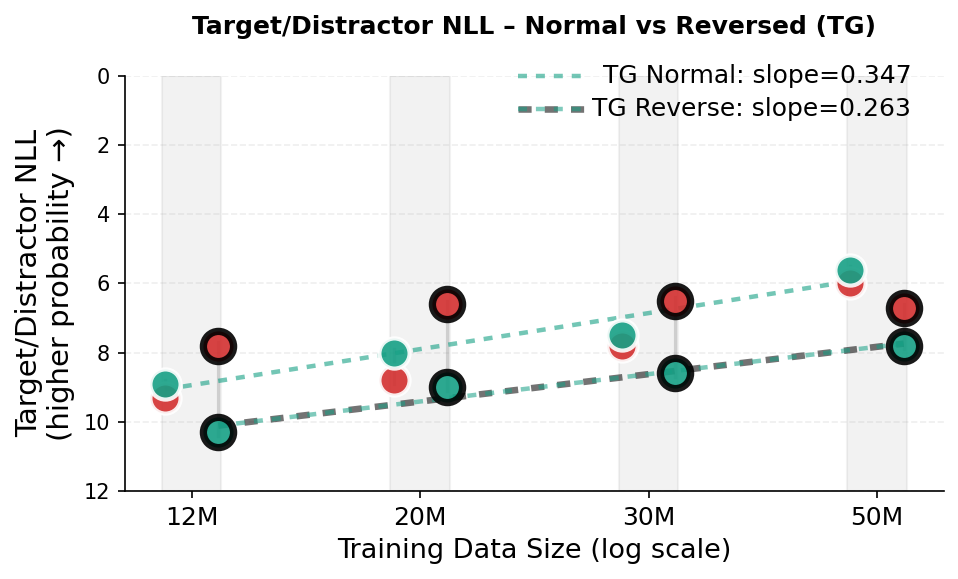
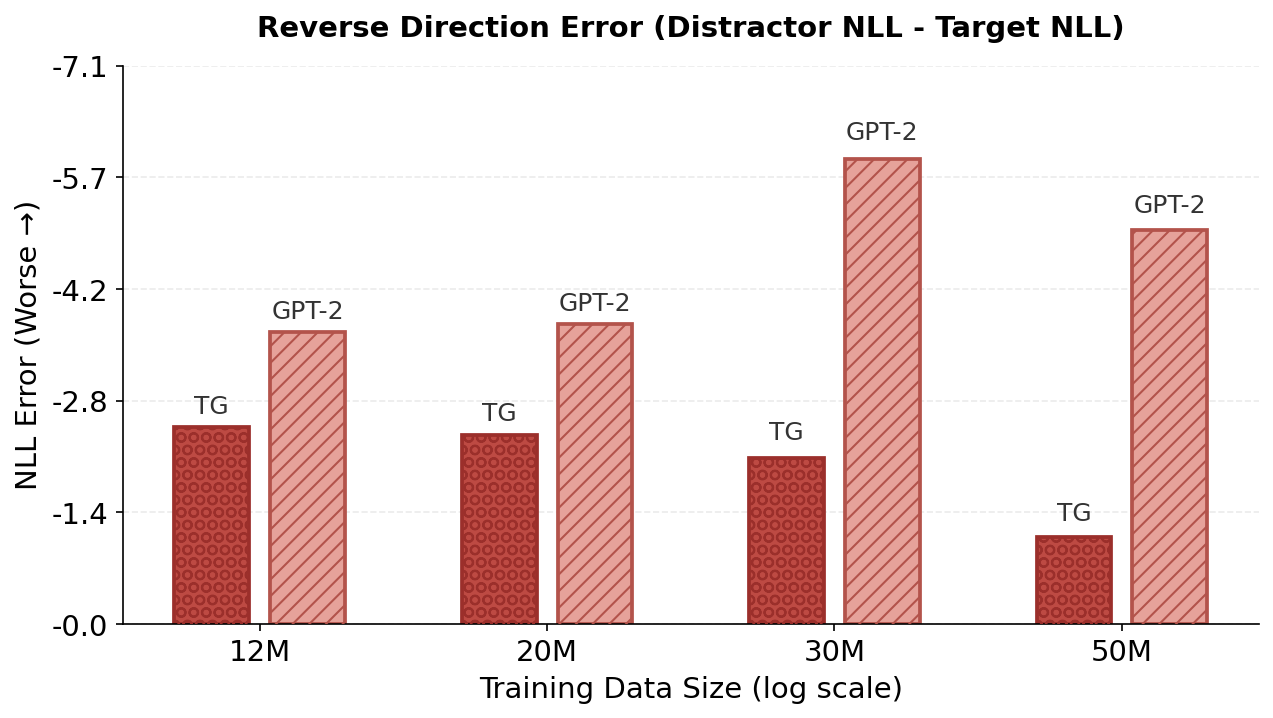
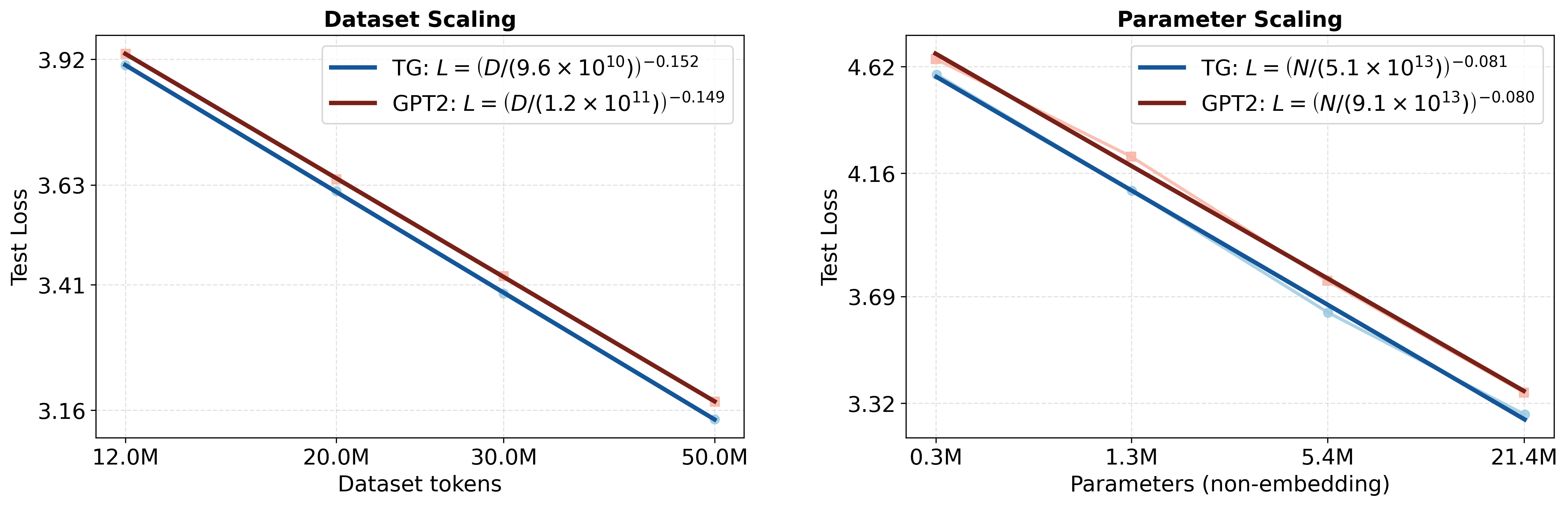
실험 결과는 두드러진 성능 향상을 보여준다. 동일한 데이터·파라미터 조건에서 GPT‑2 대비 테스트 손실이 지속적으로 낮으며, 스케일링 법칙을 적용했을 때 GPT‑2가 TG와 동등한 성능을 내기 위해서는 약 5‑8 % 더 많은 학습 데이터와 33‑42 % 더 많은 파라미터가 필요하다는 추정이 나온다. 이는 TG가 데이터와 모델 규모에 대한 효율성을 크게 개선했음을 의미한다. 또한, “부계‑아들 역전 저주”와 같은 관계 방향 일반화 테스트에서 TG는 오류율을 현저히 낮춰, 전역적인 엔티티·관계 표현이 실제로 강화되었음을 확인할 수 있다.
하지만 몇 가지 한계도 존재한다. 첫째, TG는 문장을 “생각” 단위로 묶어 처리하므로, 문장 경계가 명확하지 않은 텍스트(예: 대화형 데이터, 스트리밍 문서)에서는 적용이 어려울 수 있다. 둘째, 작업 기억에 저장되는 생각 벡터의 수가 증가하면 메모리·연산 비용이 급격히 늘어나며, 현재 구현에서는 고정된 윈도우 크기로 제한하고 있어 장기 의존성을 완전히 포착하지 못한다. 셋째, 단일 다음‑토큰 손실만을 사용한다는 점은 여전히 토큰‑레벨의 확률 분포에 크게 의존한다는 의미이며, 보다 강력한 구조적 손실(예: 관계 추론 손실)과 결합하면 추가적인 이득을 얻을 가능성이 있다.
향후 연구 방향으로는 (1) 생각 벡터의 동적 관리·삭제 메커니즘을 도입해 무한히 긴 문맥을 효율적으로 다루는 방법, (2) 멀티‑모달 입력(음성·영상)과 결합해 생각 수준의 통합 표현을 학습하는 확장, (3) 토큰‑레벨과 생각‑레벨의 손실을 다중 목표로 최적화해 관계 추론 능력을 더욱 강화하는 방안 등을 제시할 수 있다. 전반적으로 TG 모델은 인간의 인지 메커니즘을 언어 모델에 도입함으로써, 기존 트랜스포머의 한계를 보완하고 효율성과 일반화 능력을 동시에 끌어올린 중요한 시도라 할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리