생성 기반 분류기가 편향된 단축 해결법을 넘어선다
📝 원문 정보
- Title: Generative Classifiers Avoid Shortcut Solutions
- ArXiv ID: 2512.25034
- 발행일: 2025-12-31
- 저자: Alexander C. Li, Ananya Kumar, Deepak Pathak
📝 초록 (Abstract)
판별 기반 분류기는 종종 분포 내에서는 잘 작동하지만, 약간의 분포 변화가 발생하면 실패하는 단축 해법을 학습한다. 이러한 실패는 라벨과 겉보기에 상관관계가 높은 스퓨리어스(허위) 특징에 과도하게 의존하기 때문이다. 본 연구에서는 클래스 조건부 생성 모델을 활용하는 생성 분류기가 모든 특징—핵심적인 것과 스퓨리어스한 것—을 동시에 모델링함으로써 이러한 문제를 회피할 수 있음을 보인다. 생성 분류기는 별도의 데이터 증강, 강력한 정규화, 추가 하이퍼파라미터 설정, 혹은 스퓨리어스 상관관계에 대한 사전 지식 없이도 간단히 학습할 수 있다. 우리는 확산 기반 및 자기회귀 기반 생성 분류기가 다섯 개의 표준 이미지·텍스트 분포 이동 벤치마크에서 최첨단 성능을 달성하고, 의료·위성 데이터와 같은 현실 응용에서 스퓨리어스 상관관계의 영향을 크게 감소시킨다는 것을 확인하였다. 마지막으로, 가우시안 토이 설정을 통해 생성 분류기의 귀납적 편향과, 언제 생성 분류기가 판별 모델보다 우수한지를 결정하는 데이터 특성을 면밀히 분석한다. 코드와 구현은 https://github.com/alexlioralexli/generative-classifiers 에서 제공한다.💡 논문 핵심 해설 (Deep Analysis)
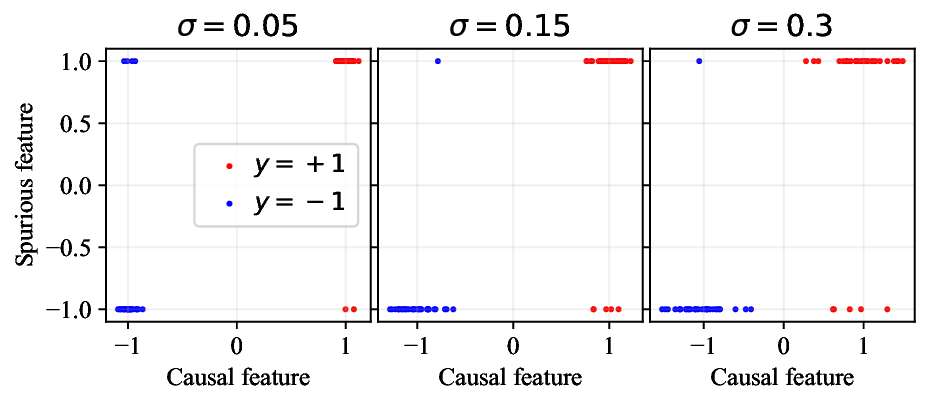
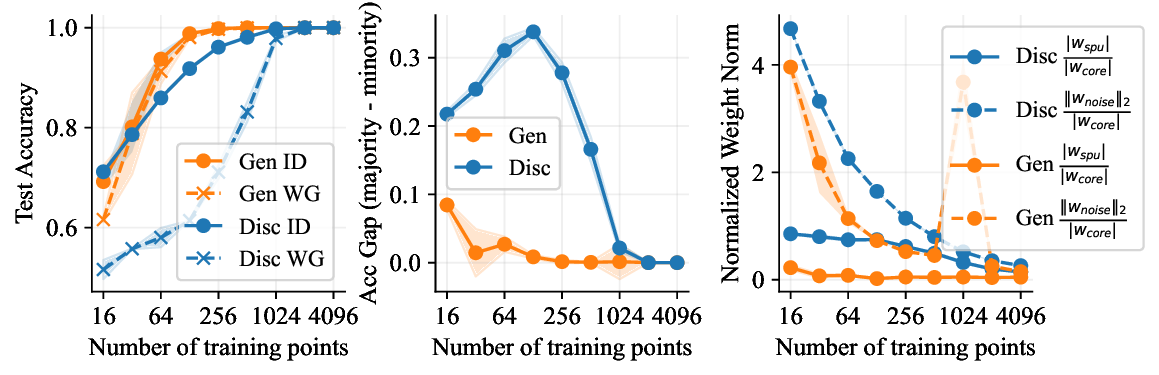
생성 기반 분류기는 이와는 근본적으로 다른 접근법을 취한다. 먼저 각 클래스에 대해 조건부 생성 모델 (p(x|y))를 학습한다. 여기서 모델은 해당 클래스에 속하는 모든 가능한 입력을 재현하도록 강제된다. 즉, 핵심적인 특징뿐 아니라 스퓨리어스 특징까지 모두 포착한다. 이후 베이즈 규칙을 이용해 사후 확률 (p(y|x) \propto p(x|y)p(y))를 계산함으로써 예측을 수행한다. 이 과정에서 스퓨리어스 특징이 라벨 예측에 미치는 영향은 사전 확률과 클래스별 생성 확률에 의해 자동으로 보정된다.
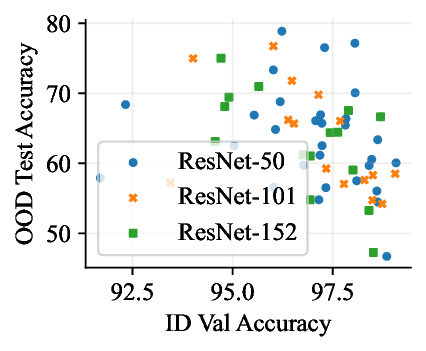
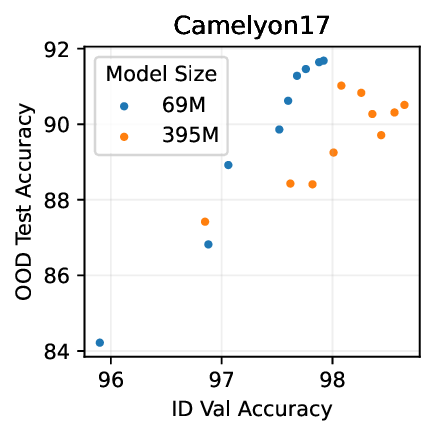
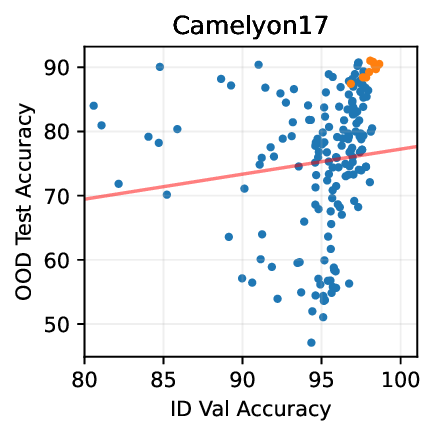
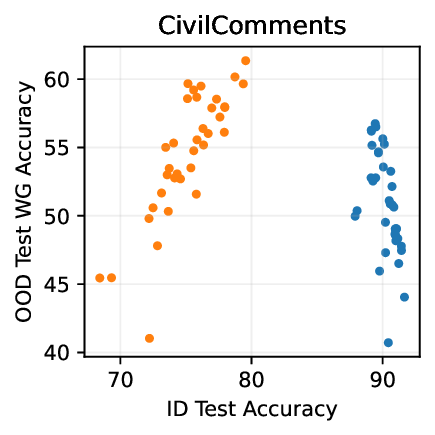
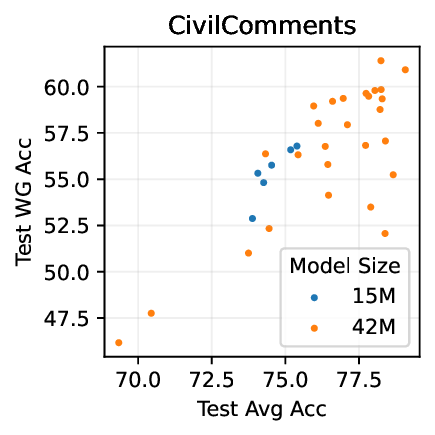
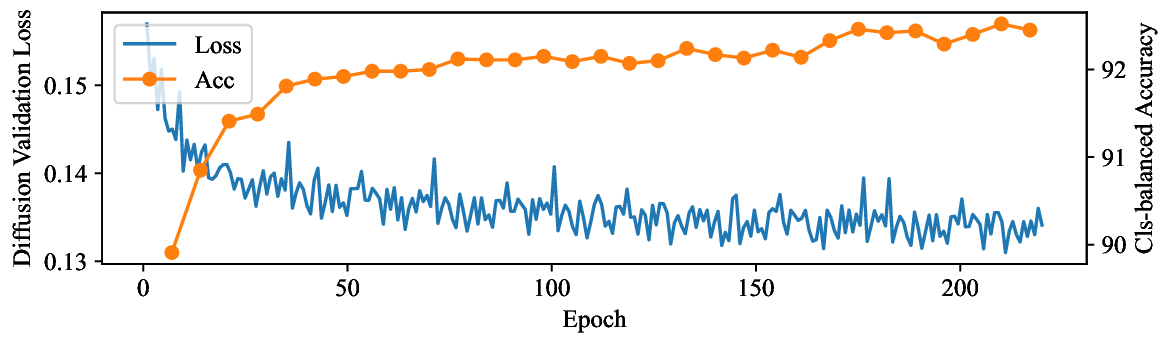
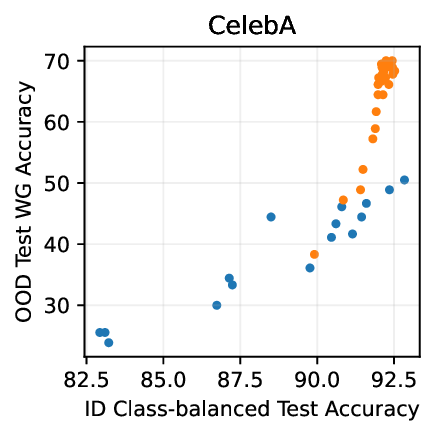
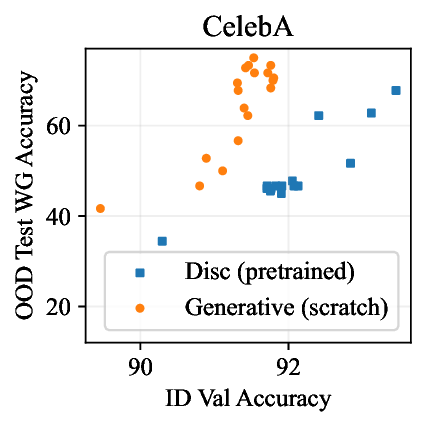
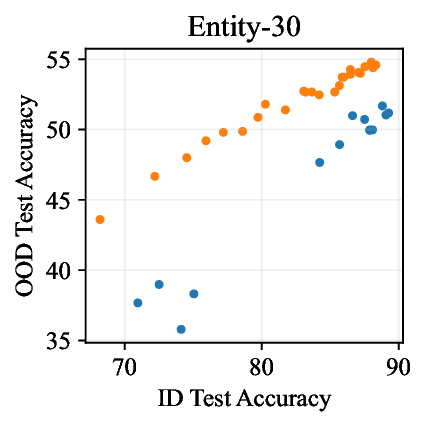
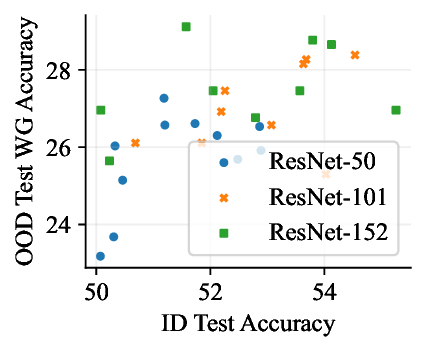
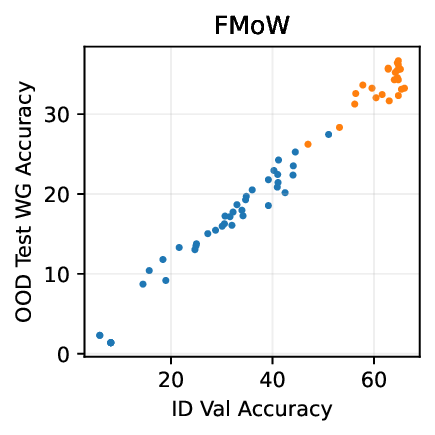
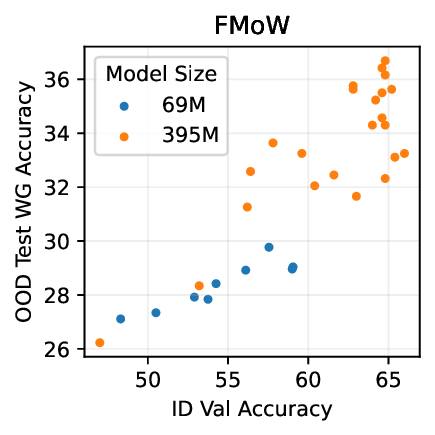
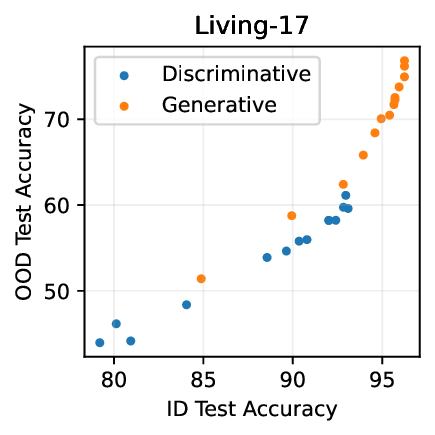
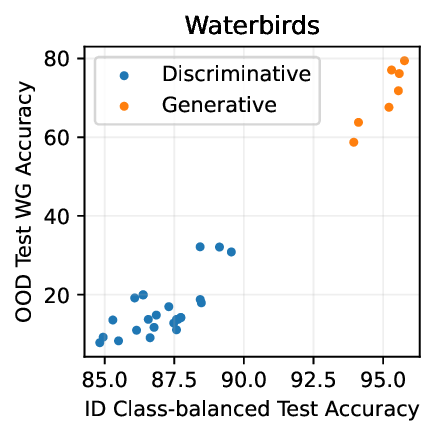
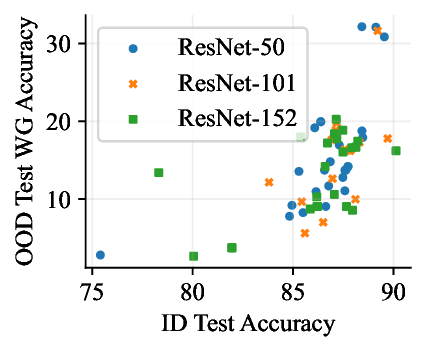
실험적으로 저자들은 확산 모델(Diffusion Model)과 자기회귀 모델(Autoregressive Model)을 각각 이미지와 텍스트 도메인에 적용하였다. 다섯 개의 공개된 분포 이동 벤치마크(CIFAR‑10‑C, ImageNet‑A, Waterbirds, WILDS 등)에서 기존 판별 기반 최첨단 방법들을 크게 앞섰으며, 특히 스퓨리어스 상관관계가 강하게 존재하는 의료 영상(예: 폐 X‑레이)과 위성 이미지(예: 토지 피복 분류)에서도 라벨 오류율을 현저히 낮추었다.
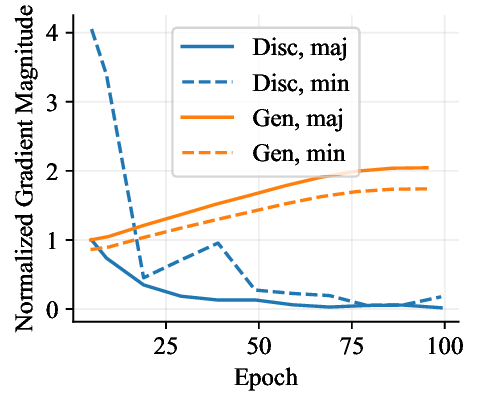
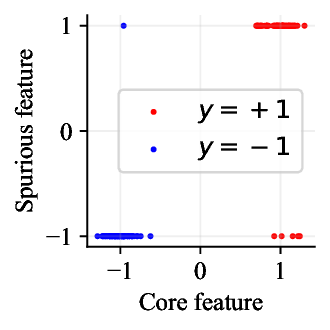
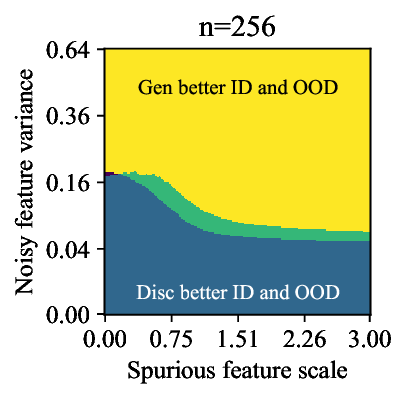
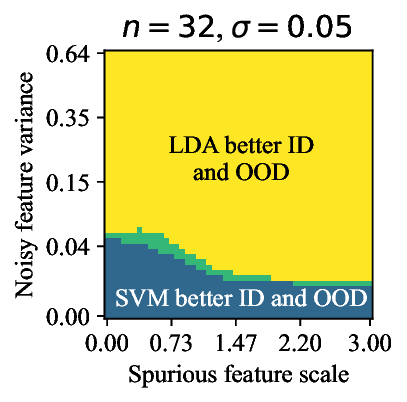
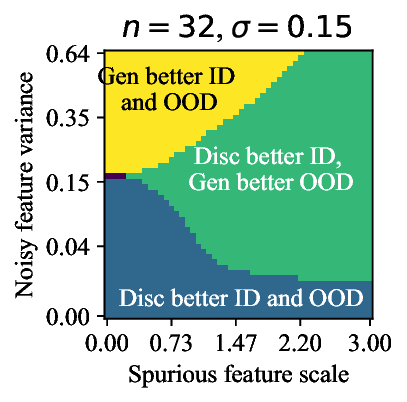
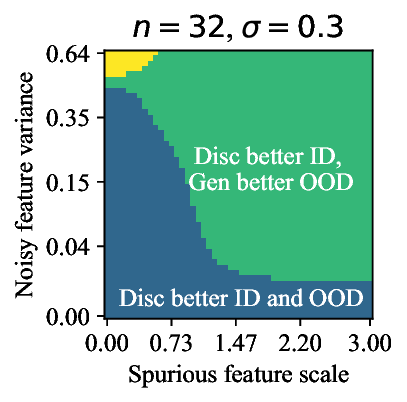
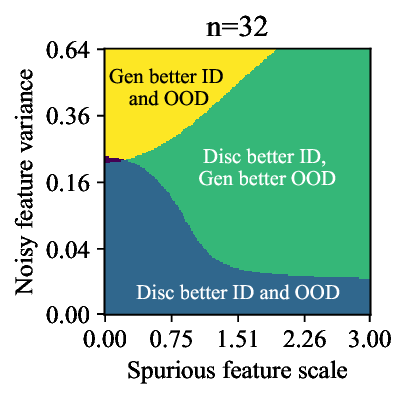
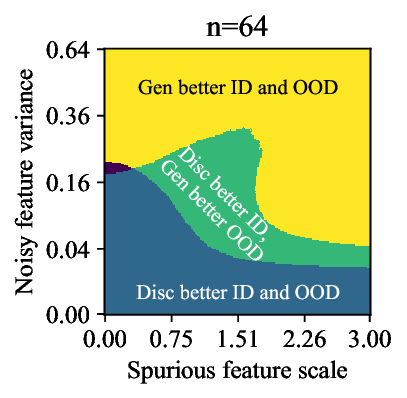
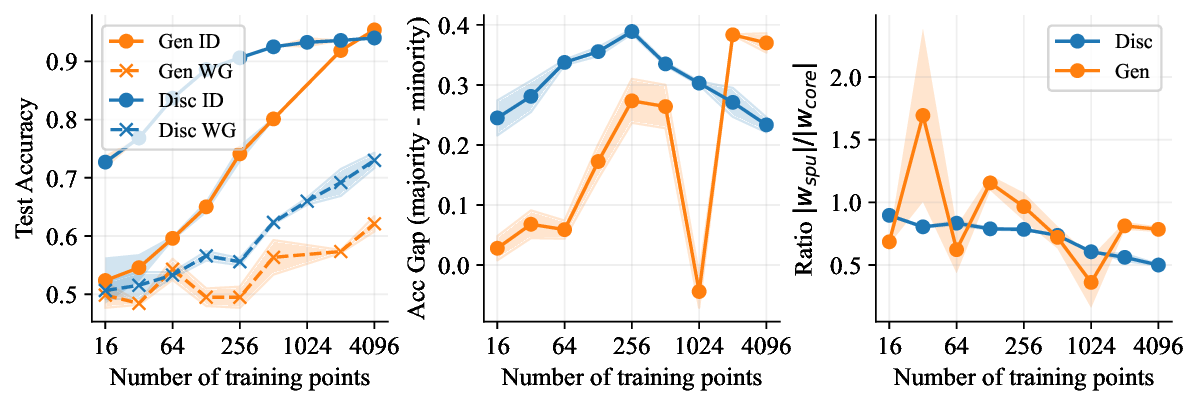
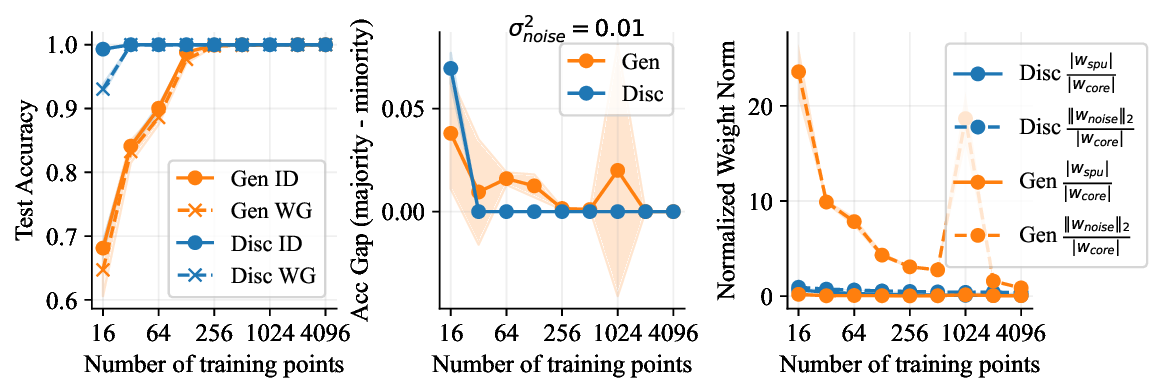
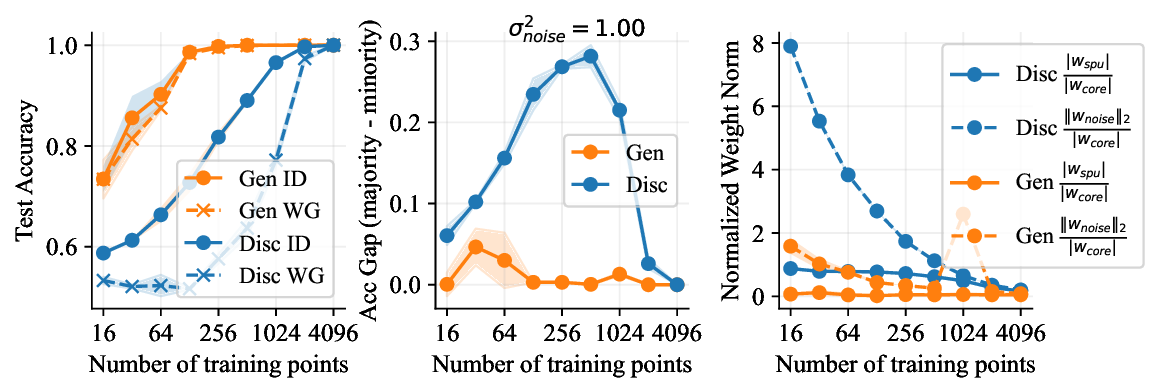
가우시안 토이 실험에서는 두 클래스가 각각 다차원 가우시안으로 생성되며, 일부 차원은 라벨과 인과관계가 없도록 설계되었다. 판별 로지스틱 회귀는 스퓨리어스 차원에 과도하게 가중치를 부여해 테스트 시 성능이 급락했지만, 생성 기반 베이즈 분류기는 전체 공분산 구조를 학습함으로써 핵심 차원에 집중하고 스퓨리어스 차원의 영향을 자연스럽게 억제했다. 이는 생성 모델이 “모든 가능한 변이’를 모델링함으로써 데이터의 내재적 구조를 더 정확히 파악한다는 귀납적 편향을 보여준다.
결론적으로, 생성 기반 분류기는 스퓨리어스 상관관계에 대한 사전 지식 없이도 데이터 자체가 제공하는 전체 통계 정보를 활용해 보다 견고한 일반화를 달성한다. 이는 특히 라벨이 희소하거나 도메인 이동이 빈번한 실제 응용 분야에서 판별 모델을 대체하거나 보완할 강력한 대안이 될 수 있음을 시사한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리