코드 언어 모델의 국소화된 보정 불확실성
📝 원문 정보
- Title: Localized Calibrated Uncertainty in Code Language Models
- ArXiv ID: 2512.24560
- 발행일: 2025-12-31
- 저자: David Gros, Prem Devanbu
📝 초록 (Abstract)
대형 언어 모델(LLM)은 자연어 프롬프트로부터 복잡한 소스 코드를 생성할 수 있다. 그러나 생성된 코드는 사용자의 의도와 어긋나는 경우가 빈번해 추가적인 감독과 수정이 필요하다. 이를 지원하기 위해 본 연구는 “최소 의도 정렬 패치”(Minimal Intent Aligning Patches)라는 데이터셋을 구축하였다. 각 프로그램은 테스트 케이스를 통해 정답 여부를 검증한다. 이후 다양한 기법이 코드의 어느 부분이 최소 패치에서 수정될 확률을 잘 보정(calibrated)된 형태로 제공할 수 있는지를 평가한다. 우리는 화이트박스 탐색(임의 구간 질의를 효율적으로 수행하는 새로운 프로빙 기법)과 블랙박스 반사(reflective) 및 자기 일관성(self‑consistency) 기반 접근법을 비교한다. 실험 결과, 작은 감독 모델을 이용한 프로브는 낮은 보정 오차와 Brier Skill Score 약 0.2를 달성하며, 수십 배 규모가 큰 생성 모델의 수정 라인 예측에 성공한다. 또한 코드 전용으로 학습된 프로브가 새로운 확률 스케일링을 적용하면 자연어 오류에도 일정 수준 일반화되는 현상을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
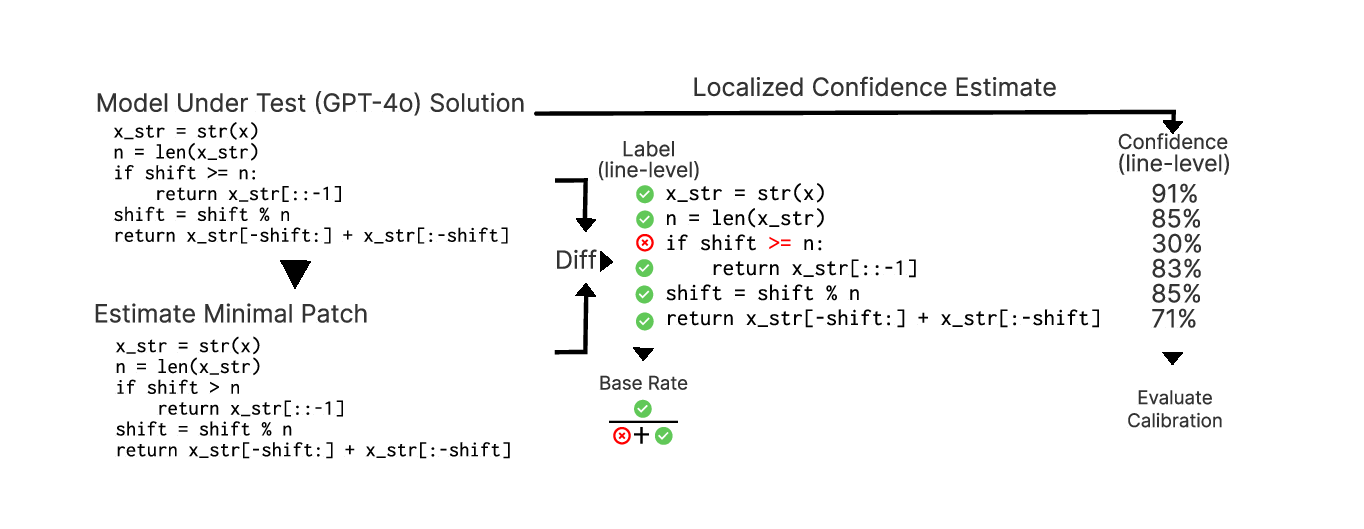
예측 기법은 크게 두 축으로 나뉜다. 첫 번째는 화이트박스 프로빙(white‑box probing)이다. 여기서는 사전 학습된 작은 “감독 모델”(supervisor model)을 이용해 임의의 코드 스팬에 대해 “수정될 확률”을 질의한다. 논문은 효율적인 임의 구간 질의를 위해 트리 구조와 마스크 연산을 결합한 새로운 프로빙 메커니즘을 제안한다. 두 번째는 블랙박스 접근법으로, LLM 자체에 “반사 프롬프트”(reflective prompt)를 삽입하거나, 동일한 입력에 대해 여러 샘플을 생성한 뒤 일관성을 측정하는 self‑consistency 방식을 적용한다.
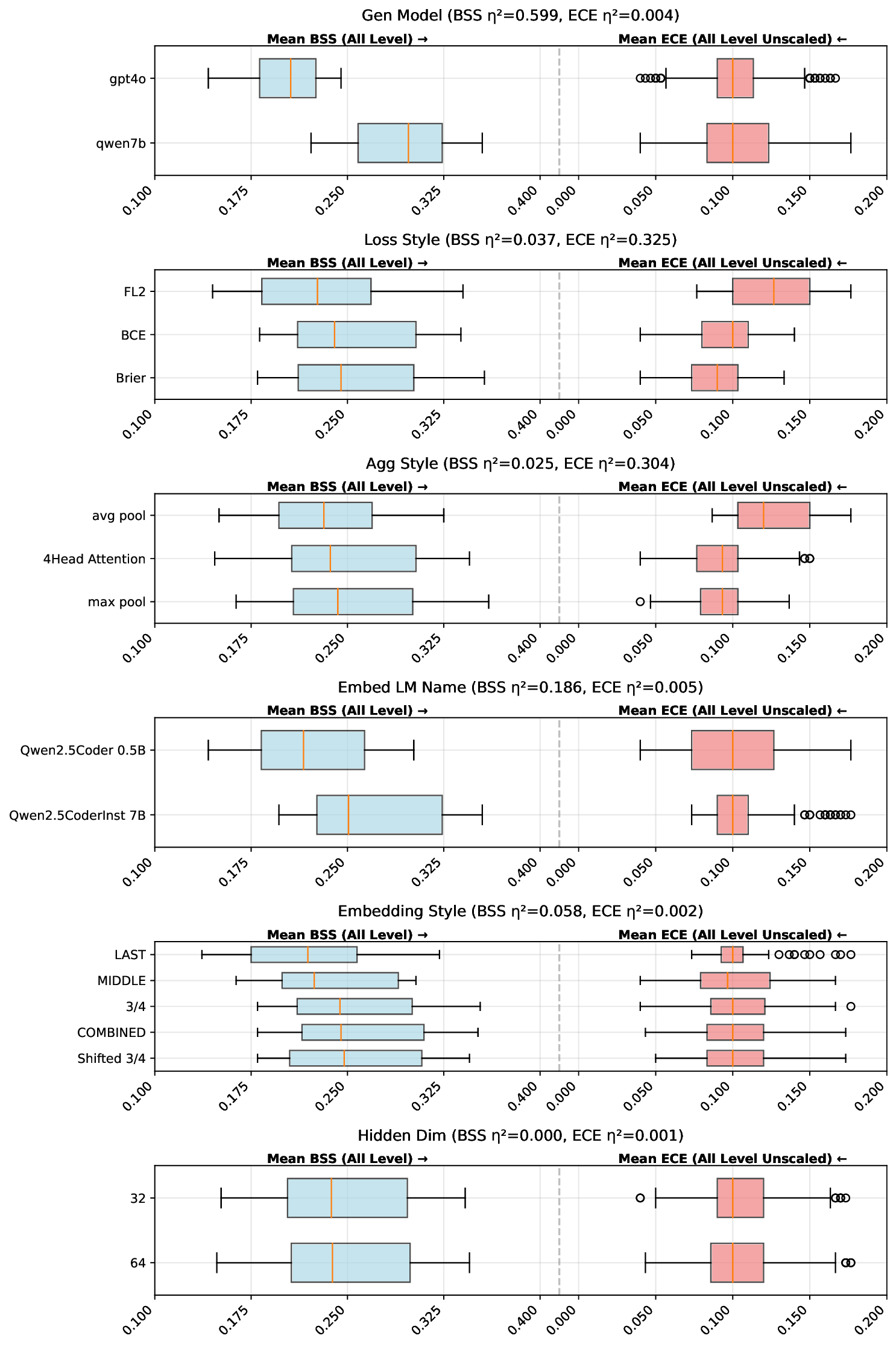
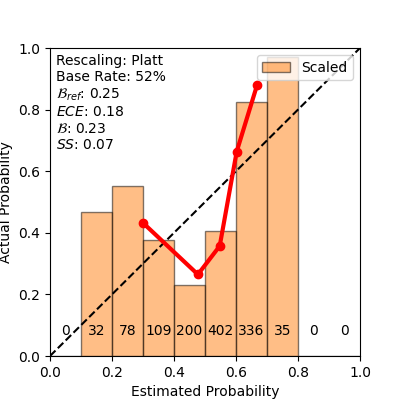
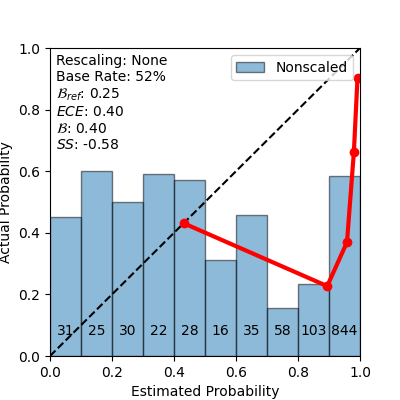
성능 평가는 보정 오류(calibration error)와 Brier Skill Score(BSS)를 사용한다. 보정 오류는 모델이 출력한 확률과 실제 수정 빈도 사이의 차이를 측정하며, BSS는 무작위 베이스라인 대비 예측 정확도의 향상을 정량화한다. 실험 결과, 화이트박스 프로브는 보정 오류를 0.07 이하로 낮추고 BSS≈0.20을 기록했다. 흥미롭게도, 이 프로브는 1‑Billion 파라미터 규모의 LLM이 생성한 코드에 대해서도 높은 예측력을 유지했으며, 파라미터 수가 수십 배 차이 나는 모델 간에도 일반화가 가능했다. 반면 블랙박스 방식은 확률이 과도하게 보수적이거나 과신적인 경향을 보여 보정이 어려웠다.
추가 실험에서는 코드 전용으로 훈련된 프로브를 자연어 오류 탐지에 적용하였다. 기존 확률 스케일링을 재조정하면, 프로브는 문법 오류나 의미적 부조화 등을 일정 수준 탐지했으며, 이는 AI 감시와 안전성 확보에 새로운 가능성을 시사한다. 그러나 현재 프로브는 코드 구조와 토큰 수준의 패턴에 크게 의존하므로, 복잡한 논리적 버그나 비정형 입력에 대해서는 한계가 있다. 향후 연구에서는 멀티모달 감독 모델, 더 정교한 스팬 선택 전략, 그리고 인간 피드백을 활용한 온라인 보정 메커니즘을 도입해 정확도와 일반화를 동시에 향상시키는 방안을 모색할 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리