다크EQA 저조도 실내 환경에서 구현형 질문 응답을 위한 비전 언어 모델 벤치마크
📝 원문 정보
- Title: DarkEQA: Benchmarking Vision-Language Models for Embodied Question Answering in Low-Light Indoor Environments
- ArXiv ID: 2512.24985
- 발행일: 2025-12-31
- 저자: Yohan Park, Hyunwoo Ha, Wonjun Jo, Tae-Hyun Oh
📝 초록 (Abstract)
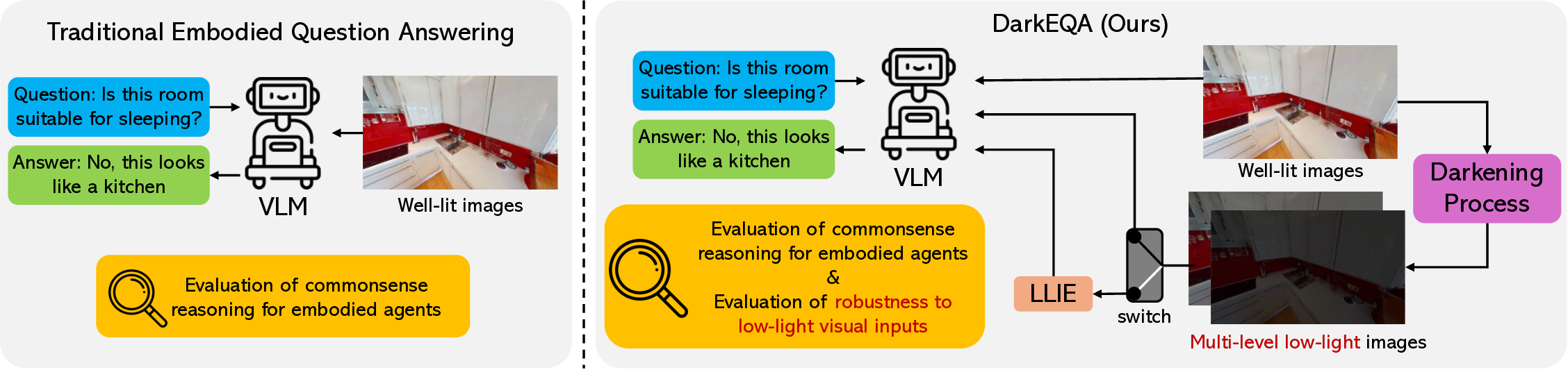
전통적인 구현형 질문 응답(EQA) 연구는 주로 밝은 조명 하의 이미지에 초점을 맞추어, 실제 환경에서 흔히 마주치는 저조도 상황에 대한 모델의 견고성을 간과해 왔다. 이를 보완하고자 우리는 DarkEQA라는 새로운 벤치마크를 제안한다. DarkEQA는 입력 영상을 두 가지 조건, 즉 조명이 충분히 확보된 클린 이미지(L0)와 물리 기반 시뮬레이션을 통해 생성된 다중 단계 저조도 이미지(L1‑L5)로 구분하여 VLM(비전‑언어 모델)의 성능을 평가한다. 이러한 이질적인 설계는 모델의 상식적 추론 능력과 시각적 열화에 대한 내성을 명확히 구분하여 분석할 수 있게 한다. 또한, 저조도 이미지 향상(LLIE) 모델을 사전 처리 단계에 적용했을 때 성능 변화도 함께 측정한다.💡 논문 핵심 해설 (Deep Analysis)
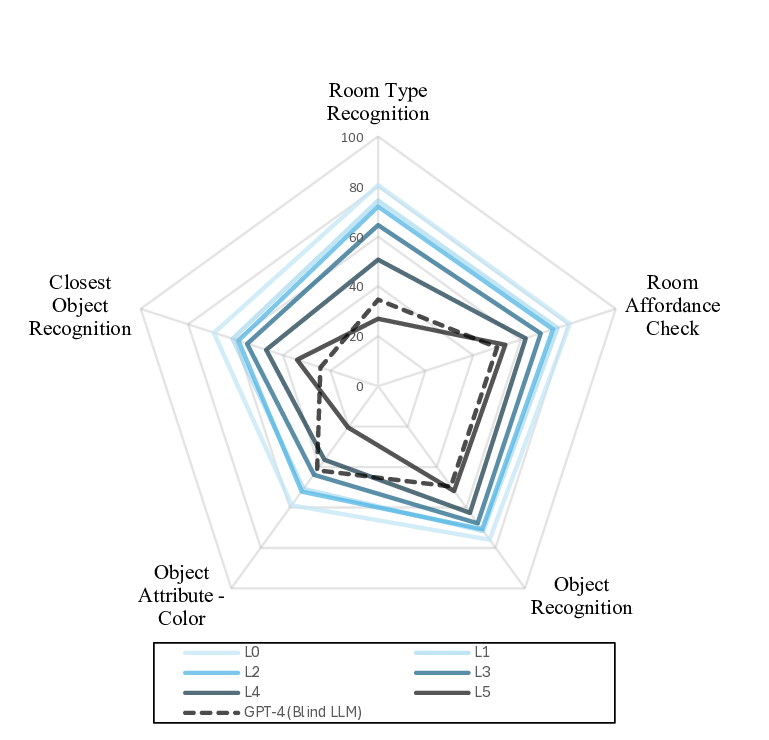
둘째, DarkEQA는 두 축으로 평가를 진행한다. 하나는 ‘상식적 추론 능력’이다. 질문 자체가 방의 용도, 물건의 위치, 행동 가능성 등 일반적인 상식에 기반한 경우, 시각 정보가 충분히 제공되지 않더라도 언어적 컨텍스트와 사전 학습된 세계 지식으로 답을 유추할 수 있다. 반면, 시각적 디테일이 핵심인 질문(예: “이 방에 침대가 있나요?”)에서는 저조도 이미지가 직접적인 성능 저하를 초래한다. 두 번째 축은 ‘시각적 견고성’이다. 여기서는 모델이 저조도 이미지에 대해 얼마나 일관된 특징을 추출하고, 이를 언어 모듈에 전달하는가를 측정한다.
셋째, LLIE(저조도 이미지 향상) 모델을 사전 처리 단계에 도입함으로써, 저조도 이미지가 원래의 고품질 이미지와 얼마나 가까워지는지를 실험적으로 검증한다. LLIE가 단순히 밝기를 높이는 수준을 넘어, 노이즈 억제와 색상 복원까지 수행한다면, VLM은 기존의 “깨끗한 이미지”에 학습된 파라미터를 그대로 활용할 수 있다. 그러나 LLIE가 과도한 인공적 보정(예: 과도한 색상 채도)으로 인해 새로운 시각적 아티팩트를 만든다면, 오히려 성능이 악화될 위험도 존재한다. DarkEQA는 이러한 양면성을 정량화하기 위해, LLIE 전·후의 동일 질문에 대한 정확도 차이와, 이미지 품질 지표(PSNR, SSIM, LPIPS) 간의 상관관계를 함께 보고한다.
넷째, 평가 메트릭은 단순 정확도 외에도 ‘질문 유형별 정확도’, ‘시각적 손실 단계별 정확도 감소율’, ‘LLIE 적용 시 회복율’ 등을 포함한다. 이러한 다차원 평가 체계는 연구자가 모델의 약점을 구체적인 단계(L2에서 급격히 떨어지는 경우 등)와 질문 유형(공간 관계 추론 vs. 물체 존재 판단)으로 세분화하여 분석할 수 있게 한다.
다섯째, 현재 제시된 결과는 대부분의 최신 VLM(예: CLIP‑V, BLIP‑2, Flamingo)이 L0에서는 높은 정확도를 보이지만, L3‑L5 단계에서는 급격히 성능이 저하된다는 점을 보여준다. 특히, “이 방은 잠자기에 적합한가?”와 같은 상식 기반 질문은 저조도에서도 비교적 안정적인 반면, “이 방에 냉장고가 있나요?”와 같은 구체적 물체 탐지는 거의 무작위 수준으로 떨어진다. 이는 현재 VLM이 시각적 디테일을 충분히 활용하지 못하고, 언어적 상식에 과도하게 의존하고 있음을 시사한다.
마지막으로, DarkEQA는 향후 연구 방향을 제시한다. 첫째, 저조도 환경에 특화된 비전 백본(예: 저조도 전용 CNN, 노이즈‑강인 트랜스포머) 개발이 필요하다. 둘째, 멀티모달 사전 학습 단계에서 저조도 이미지와 그에 대응하는 라벨을 함께 학습함으로써, 모델이 저조도에서도 의미 있는 특징을 추출하도록 유도할 수 있다. 셋째, LLIE와 VLM을 엔드‑투‑엔드로 공동 최적화하는 파이프라인을 구축하면, 보정 과정에서 발생하는 아티팩트를 최소화하면서 최종 QA 성능을 극대화할 수 있다. 이러한 연구는 가정용 로봇, 야간 감시 드론, 의료 현장 등 실제 저조도 환경에서 작동해야 하는 인공지능 시스템의 실용성을 크게 향상시킬 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리