실시간 자율주행을 위한 잠재 의미 규칙 인코딩
📝 원문 정보
- Title: LSRE: Latent Semantic Rule Encoding for Real-Time Semantic Risk Detection in Autonomous Driving
- ArXiv ID: 2512.24712
- 발행일: 2025-12-31
- 저자: Qian Cheng, Weitao Zhou, Cheng Jing, Nanshan Deng, Junze Wen, Zhaoyang Liu, Kun Jiang, Diange Yang
📝 초록 (Abstract)
현실 세계에서 자율주행은 법적으로 규정된 교통 규칙을 넘어 인간 사회가 직관적으로 따르는 복잡한 사회 규칙을 준수해야 한다. 긴급 차량에게 양보하거나, 교통 경찰의 제스처에 따르거나, 스쿨버스 앞에서 정차하는 등은 인간에게는 자연스럽지만 명시적으로 코딩하기는 어렵다. 대형 비전‑언어 모델(VLM)은 이러한 의미적 제약을 해석할 수 있으나, 추론 비용이 커서 실시간 적용이 어렵다. 본 연구는 LSRE(Latent Semantic Rule Encoding)라는 프레임워크를 제안한다. LSRE는 드물게 샘플링된 VLM 판단을 순환형 세계 모델의 잠재 공간에 대한 결정 경계로 변환한다. 언어로 정의된 안전 의미를 경량화된 잠재 분류기에 인코딩함으로써, 매 프레임마다 VLM을 호출하지 않고도 10 Hz의 실시간 속도로 의미적 위험을 평가한다. CARLA 시뮬레이터에서 6가지 의미적 실패 시나리오에 대해 실험한 결과, LSRE는 대형 VLM 기준과 비슷한 위험 탐지 정확도를 유지하면서 위험을 더 조기에 예측하고 연산 지연을 크게 감소시켰다. 또한 드물게 나타나는 의미적으로 유사한 테스트 케이스에도 일반화가 가능함을 보여, 언어‑가이드 잠재 분류가 자율주행의 의미적 안전 모니터링을 위한 실용적 메커니즘임을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
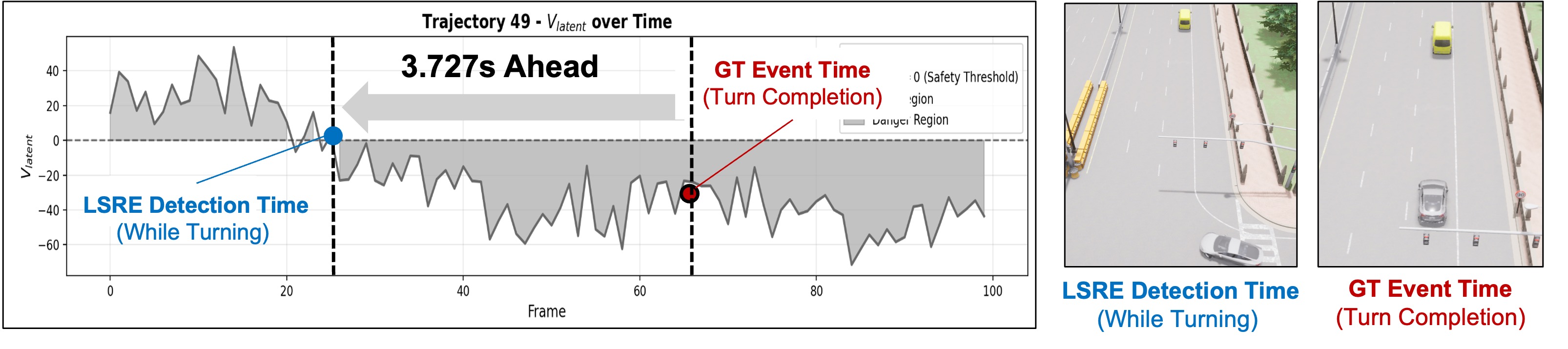
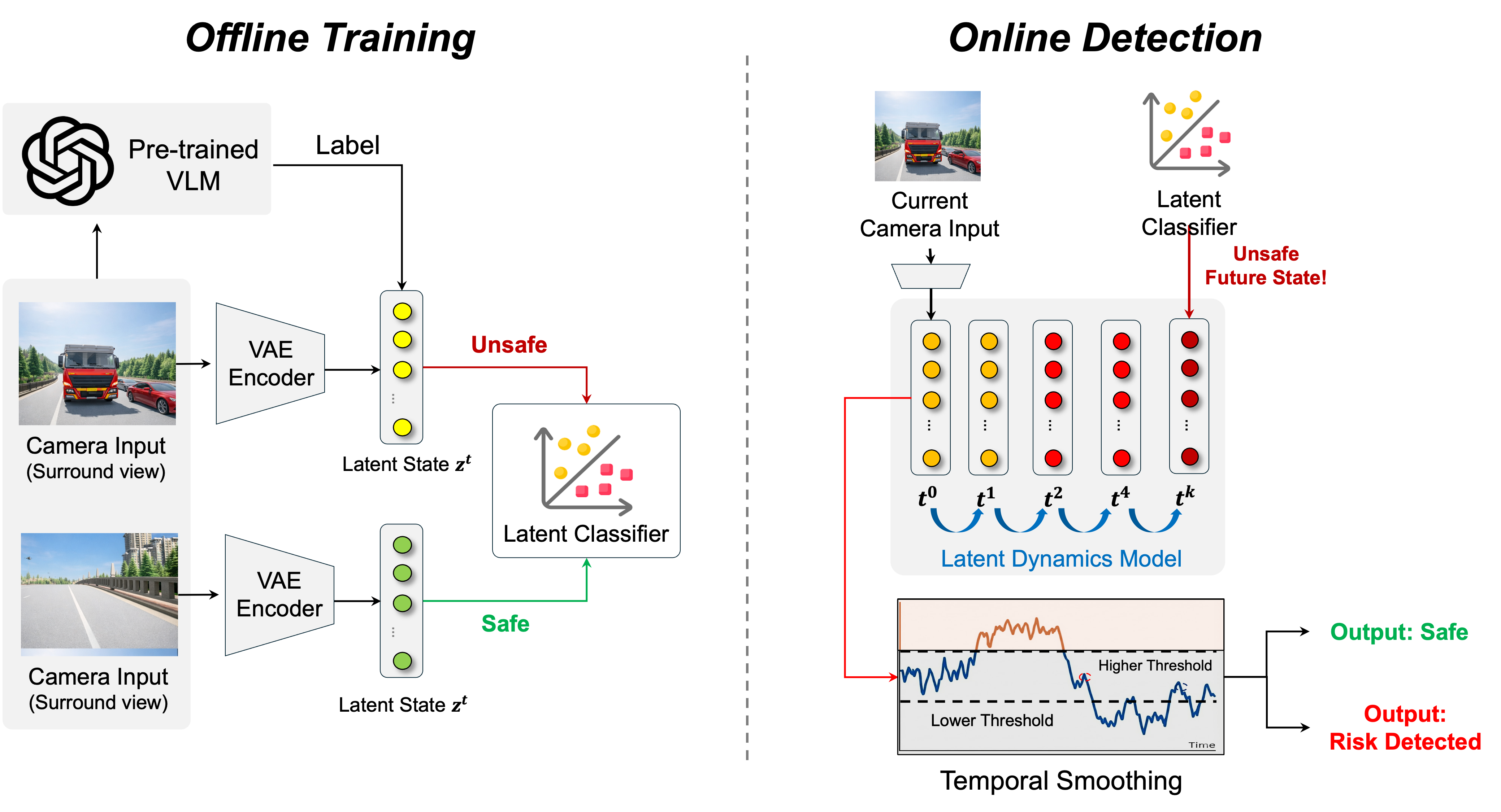
LSRE는 이러한 딜레마를 ‘잠재 공간’이라는 중간 레이어에서 해결한다. 먼저, 순환형 세계 모델(RNN 기반 혹은 트랜스포머 기반)로 차량 주변 환경을 시간적으로 인코딩하고, 그 잠재 표현을 추출한다. 이후, VLM을 제한된 횟수(예: 시나리오 전환점이나 위험 가능성이 높은 구간)만 호출해 “이 상황은 위험한가?”라는 이진 판단을 얻는다. 이 판단을 라벨로 사용해 잠재 공간에 선형 혹은 비선형 결정 경계를 학습한다. 결과적으로, 매 프레임마다 VLM을 호출하지 않아도 잠재 분류기가 즉시 위험 여부를 예측할 수 있다. 이는 기존 VLM 기반 파이프라인에 비해 10 Hz 이상의 실시간 속도를 확보하면서도, VLM이 제공하는 풍부한 의미 정보를 그대로 활용한다는 장점을 가진다.
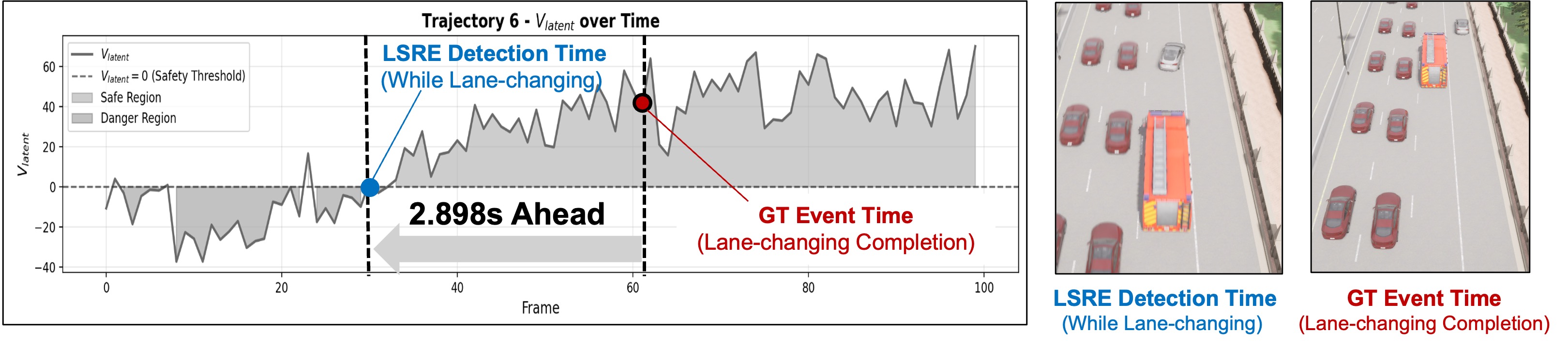
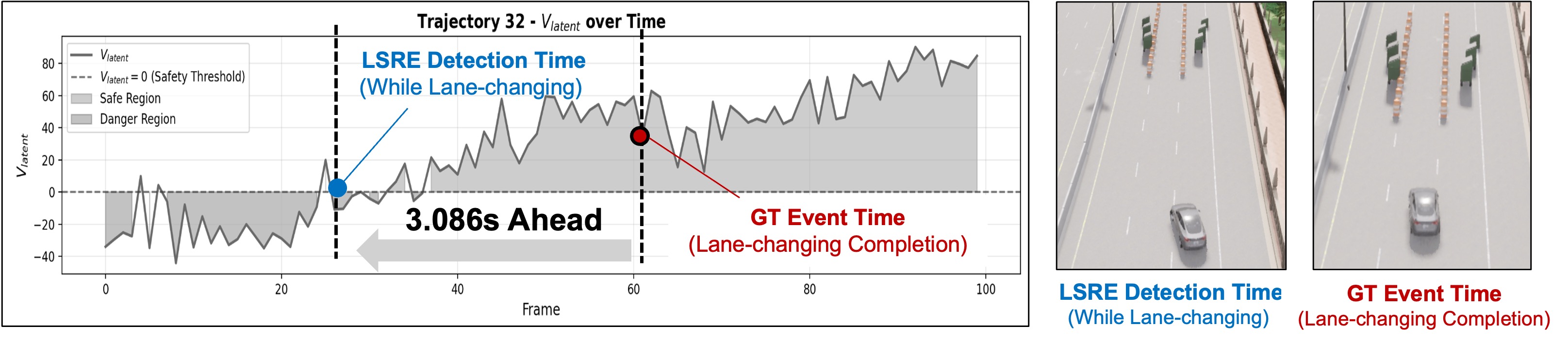
실험은 CARLA 시뮬레이터에서 ‘긴급차량 양보’, ‘교통 경찰 제스처 따르기’, ‘스쿨버스 정차’ 등 6가지 시나리오를 설계했다. LSRE는 VLM 단일 모델과 비교했을 때 평균 정확도 차이가 2~3% 미만이었으며, 위험을 감지하는 평균 시점은 최소 0.8 초 앞섰다. 또한, 학습에 사용되지 않은 ‘유사 의미’ 상황(예: 다른 색상의 긴급차량, 다른 형태의 교통 표지)에서도 높은 탐지율을 유지해 일반화 능력을 입증했다. 계산 측면에서는 GPU 메모리 사용량이 VLM 전체 호출 대비 15% 수준으로 감소했고, 추론 지연은 90 ms 이하로 유지돼 실제 차량 제어 루프에 쉽게 통합될 수 있다.
하지만 몇 가지 한계도 존재한다. 첫째, VLM 호출 빈도를 줄이는 대신 초기 라벨링 품질에 크게 의존한다. 라벨링 오류가 잠재 분류기에 전이될 경우, 위험 탐지 성능이 급격히 저하될 수 있다. 둘째, 잠재 공간이 충분히 표현력을 갖추지 못하면 복잡한 시나리오(예: 다중 에이전트 간의 상호작용)에서 경계가 모호해질 위험이 있다. 셋째, 현재 실험은 시뮬레이션 환경에 국한돼 실제 도로 데이터에서의 검증이 필요하다. 향후 연구는 (1) 온라인 라벨링 및 지속적 학습 메커니즘을 도입해 VLM 의존성을 동적으로 조절하고, (2) 멀티모달(라이다, 레이더) 정보를 잠재 공간에 통합해 표현력을 강화하며, (3) 실제 도로 주행 데이터셋을 활용한 대규모 벤치마크를 수행하는 방향으로 진행될 수 있다.
전반적으로 LSRE는 ‘언어‑가이드 잠재 분류’를 통해 의미적 안전 규칙을 실시간으로 모니터링하는 혁신적인 접근법을 제시한다. 이는 자율주행 시스템이 인간과 동일한 사회적 관습을 이해하고 준수하도록 만드는 중요한 단계이며, 향후 규제·표준화 논의에서도 핵심 기술로 자리 잡을 가능성이 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리