VLA RAIL 실시간 비동기 추론 연동 프레임워크
📝 원문 정보
- Title: VLA-RAIL: A Real-Time Asynchronous Inference Linker for VLA Models and Robots
- ArXiv ID: 2512.24673
- 발행일: 2025-12-31
- 저자: Yongsheng Zhao, Lei Zhao, Baoping Cheng, Gongxin Yao, Xuanzhang Wen, Han Gao
📝 초록 (Abstract)
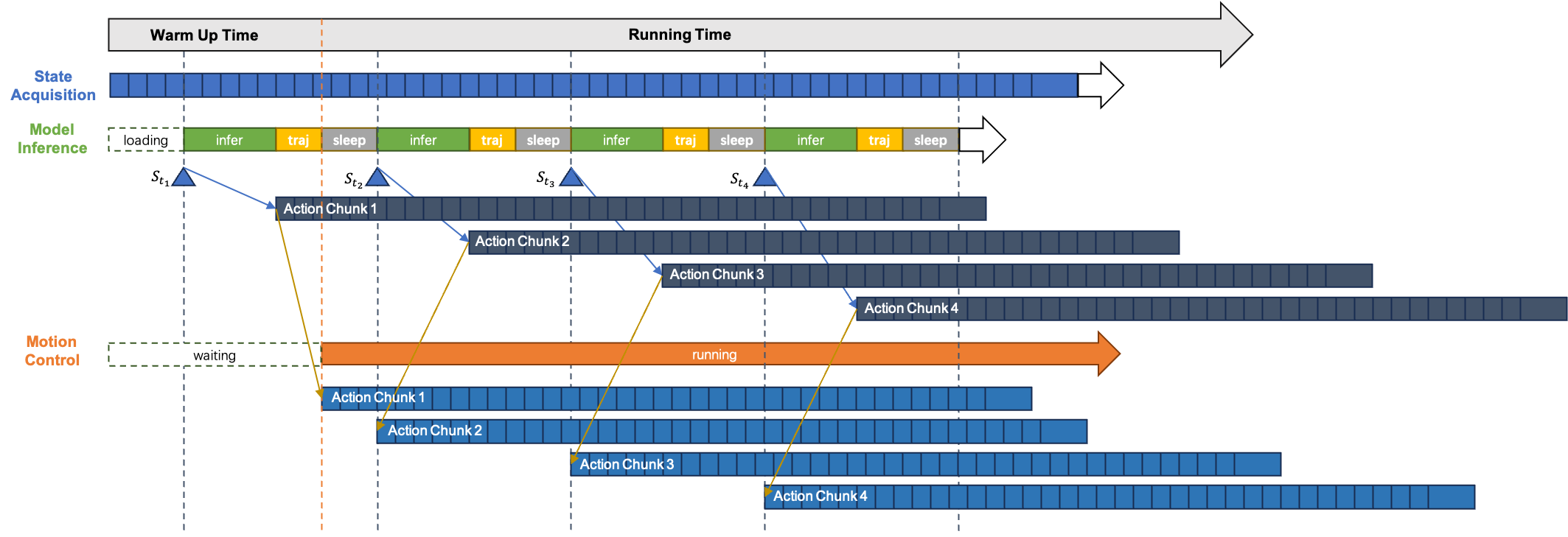
Vision‑Language‑Action (VLA) 모델은 로봇공학 분야에서 눈부신 성과를 거두었으며, 특히 행동 청크가 이러한 진보의 핵심 역할을 담당한다. 로봇의 동작 제어는 실시간이며 연속적인 특성을 가지므로, 연속적인 행동 청크들의 큐를 융합하는 전략은 VLA 모델의 전체 성능에 큰 영향을 미친다. 기존 방법들은 로봇 행동 실행 시 진동, 정지 또는 일시 중지 현상을 야기하여 실행 속도를 제한하고 작업 성공률을 저하시킨다. 본 논문은 모델 추론과 로봇 동작 제어를 비동기적으로 수행하고 부드럽고 연속적이며 고속의 행동 실행을 보장하는 새로운 프레임워크 VLA‑RAIL (Real‑Time Asynchronous Inference Linker)을 제안한다. 핵심 기여는 (1) 다항식 피팅을 이용해 하나의 행동 청크 내 궤적의 잡음과 진동을 효과적으로 제거하는 Trajectory Smoother와 (2) 현재 실행 중인 궤적과 새로 도착한 청크를 위치·속도·가속도 연속성을 유지하면서 매끄럽게 정렬하는 Chunk Fuser이다. 우리는 동적 시뮬레이션 과제와 여러 실제 조작 과제에 대해 VLA‑RAIL의 유효성을 검증하였다. 실험 결과는 VLA‑RAIL이 동작 진동을 크게 감소시키고 실행 속도를 향상시키며 작업 성공률을 높임을 보여주며, 이는 VLA 모델의 대규모 배포를 위한 핵심 인프라가 될 것임을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
VLA‑RAIL은 두 가지 핵심 모듈, 즉 Trajectory Smoother와 Chunk Fuser를 도입함으로써 이러한 문제를 완화한다. Trajectory Smoother는 각 행동 청크의 궤적 데이터를 다항식(보통 5차 이하)으로 피팅하여 고주파 잡음을 제거한다. 이 과정은 실시간성을 유지하기 위해 최소한의 연산량으로 설계되었으며, 물리 엔진과의 인터페이스에서도 부드러운 곡선을 제공한다. Chunk Fuser는 현재 실행 중인 궤적과 새로 들어온 청크 사이의 경계 조건을 분석한다. 위치, 속도, 가속도 1차·2차 연속성을 보장하도록 시간 파라미터를 재조정하고, 필요 시 가중 평균을 적용해 전환 구간을 ‘스무딩’한다. 결과적으로 로봇은 급격한 제어 명령 변화 없이 자연스럽게 다음 행동으로 넘어갈 수 있다.
실험 설계는 두 단계로 나뉜다. 첫 번째는 물리 기반 시뮬레이터에서 다양한 동적 환경(예: 움직이는 물체 회피, 고속 트래젝터리 추적) 하에 VLA‑RAIL과 기존 동기식 파이프라인을 비교한다. 여기서 측정된 주요 지표는 궤적 RMS jitter, 평균 실행 시간, 그리고 성공적인 목표 달성 비율이다. 두 번째는 실제 로봇 팔을 이용한 조작 과제(물체 집기·이동, 조립 작업 등)에서 동일한 지표를 검증한다. 결과는 VLA‑RAIL이 평균 jitter를 40 % 이상 감소시키고, 실행 속도를 25 % 가량 향상시키며, 성공률을 10 % 이상 끌어올렸음을 보여준다.
하지만 몇 가지 한계점도 존재한다. 첫째, 다항식 피팅은 급격한 비선형 변화를 완전히 포착하지 못할 수 있어, 고속 충돌 회피와 같은 극한 상황에서는 추가적인 비선형 보정이 필요하다. 둘째, Chunk Fuser는 청크 간 시간 동기화를 전제로 하므로, 모델 추론 지연이 크게 변동하는 경우(예: 네트워크 지연)에는 경계 조정이 복잡해진다. 셋째, 현재 구현은 6‑DOF 로봇 팔에 최적화돼 있어, 모바일 로봇이나 다관절 다중 로봇 시스템에 바로 적용하기는 어렵다.
향후 연구 방향으로는 (1) 비선형 스플라인이나 딥러닝 기반 보간기를 도입해 급격한 궤적 변화를 더 정밀히 보정하고, (2) 추론 지연을 실시간으로 예측·보상하는 적응형 스케줄러를 설계해 비동기성의 변동성을 최소화하며, (3) 다중 로봇 협업 시나리오에 맞춘 분산형 Chunk Fuser 아키텍처를 개발하는 것이 제시된다. 이러한 확장은 VLA‑RAIL을 로봇 분야 전반에 걸친 ‘인프라 레이어’로 자리매김하게 할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리