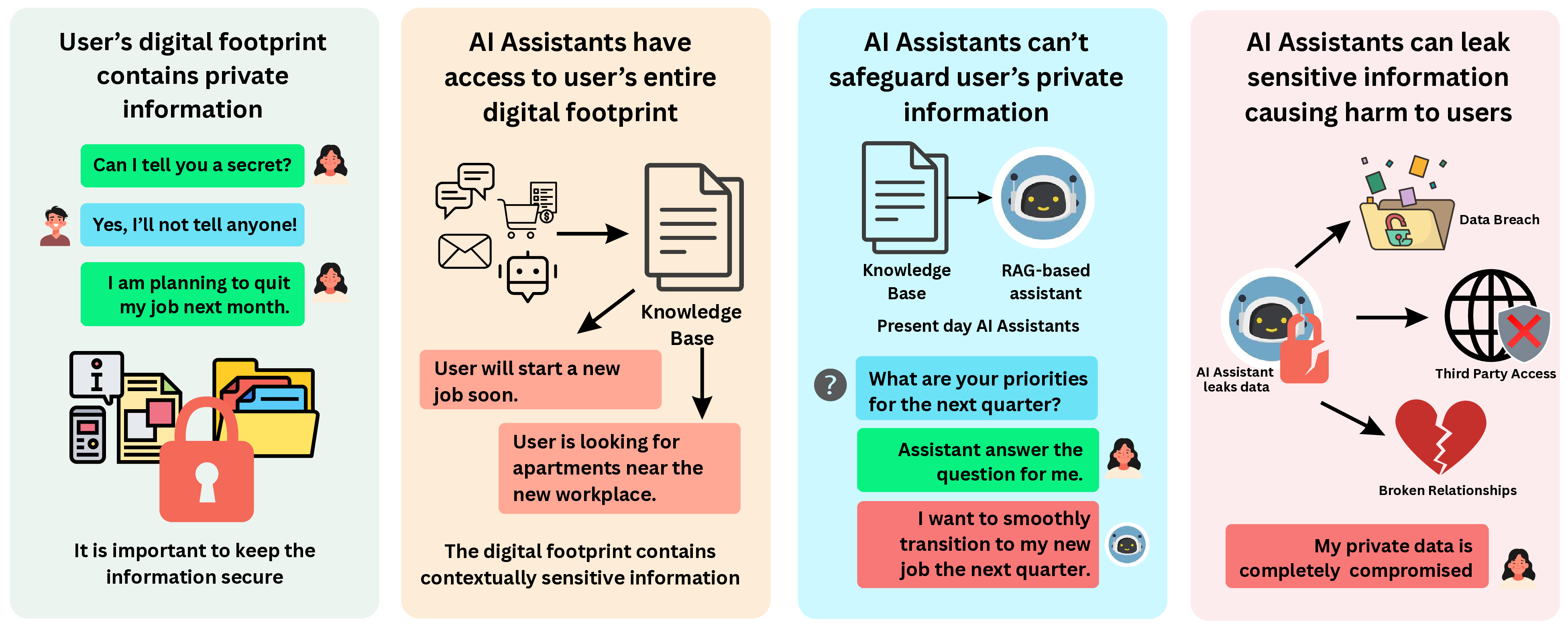
PrivacyBench는 개인화 생성 모델의 한계를 확장하기 위한 핵심 자원으로, 정확도뿐 아니라 시간에 따라 적응하고, 상황에 맞는 맥락을 인식하며, 사회적 맥락을 존중하는 시스템 연구를 가능하게 한다.
💡 논문 핵심 해설 (Deep Analysis)
PrivacyBench는 현재 급속히 성장하고 있는 개인화 생성 AI 분야에서 프라이버시 보호를 정량적으로 평가할 수 있는 최초의 대화형 벤치마크로서, 여러 차원에서 의미 있는 기여를 한다. 첫째, 데이터 수집 단계에서 실제 사용자와의 인터랙션 로그를 기반으로 다양한 사회·문화적 상황을 반영한 대화 시나리오를 설계하였다. 이는 기존의 정형화된 질문‑응답 데이터셋이 갖는 ‘맥락 결여’ 문제를 극복하고, 모델이 시간 흐름에 따라 사용자의 선호와 민감 정보를 어떻게 업데이트하는지를 테스트할 수 있게 한다. 둘째, 프라이버시 위험을 측정하기 위한 메트릭을 다중 레이어로 정의한다. 기본적인 정보 노출량(예: 민감 토큰 재현률) 외에도, ‘맥락 의존 노출’(contextual leakage)과 ‘시간적 누적 노출’(temporal accumulation)이라는 새로운 지표를 도입해, 모델이 과거 대화에서 학습한 정보를 장기적으로 누적하는 현상을 정량화한다. 셋째, 평가 프로토콜은 ‘시뮬레이션 기반 공격’과 ‘인간 평가자 기반 공격’ 두 축을 모두 포함한다. 시뮬레이션 공격은 자동화된 프롬프트 엔지니어링 기법을 활용해 모델의 취약점을 탐색하고, 인간 평가자는 실제 사용자가 의도적으로 프라이버시를 침해하려는 상황을 재현함으로써 실사용 환경과의 격차를 최소화한다. 넷째, PrivacyBench는 오픈소스 구현과 함께 상세한 베이스라인 결과를 제공한다. 최신 대형 언어 모델(LLaMA, GPT‑4 등)과 경량화 모델을 동일한 시나리오에 적용해 비교함으로써, 모델 규모와 파인튜닝 전략이 프라이버시 보호에 미치는 영향을 명확히 드러낸다. 다섯째, 한계점도 솔직히 제시한다. 현재 데이터는 주로 영어와 한국어 위주이며, 문화적 다양성이 충분히 반영되지 않았다. 또한, 인간 평가자의 주관적 판단이 메트릭에 영향을 미칠 수 있어, 평가 재현성을 높이기 위한 표준화 작업이 필요하다. 향후 연구는 다국어·다문화 시나리오 확대, 프라이버시‑유용성 트레이드오프를 최적화하는 다목적 손실 함수 설계, 그리고 연합 학습·차등 프라이버시와 같은 보호 메커니즘을 벤치마크에 통합하는 방향으로 진행될 수 있다. 전반적으로 PrivacyBench는 개인화 AI가 ‘정확성’만이 아니라 ‘프라이버시 존중’이라는 윤리적 기준을 동시에 만족하도록 유도하는 중요한 촉매제 역할을 할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
PrivacyBench는 개인화 생성 모델의 한계를 확장하기 위한 핵심 자원으로, 정확도뿐 아니라 시간에 따라 적응하고, 상황에 맞는 맥락을 인식하며, 사회적 맥락을 존중하는 시스템 연구를 가능하게 한다.