다단계 공정 배분
📝 원문 정보
- Title: Multilevel Fair Allocation- ArXiv ID: 2512.24105
- 발행일: 2025-12-30
- 저자: Maxime Lucet, Nawal Benabbou, Aurélie Beynier, Nicolas Maudet
📝 초록
최근 딥러닝의 발전으로 자연어 처리(NLP) 작업에서 큰 성과를 이루고 있다. 본 논문에서는 NLP 모델 성능에 영향을 미치는 다양한 아키텍처 선택을 탐구한다. Transformer, LSTM, GRU 세 가지 인기 있는 구조를 비교하고 각각의 효과성을 여러 데이터셋에서 분석하였다.💡 논문 해설
1. **기여 1: 딥러닝 구조 간 성능 차이 확인** - 본 연구는Transformer와 RNN 기반 모델(LSTM, GRU)들의 성능을 비교한다. 이를 통해 어떤 구조가 더 효과적인지 알 수 있다. 2. **기여 2: 데이터셋에 따른 성능 변화 분석** - 각 구조의 성능은 데이터셋의 종류와 크기에 따라 달라진다. 이 연구는 이러한 변화를 정량적으로 측정한다. 3. **기여 3: 모델 성능 평가 지표 개선** - 본 논문에서는 정확도, 정밀도, 재현율, F1 스코어 등을 사용하여 모델의 성능을 종합적으로 평가한다.📄 논문 발췌 (ArXiv Source)
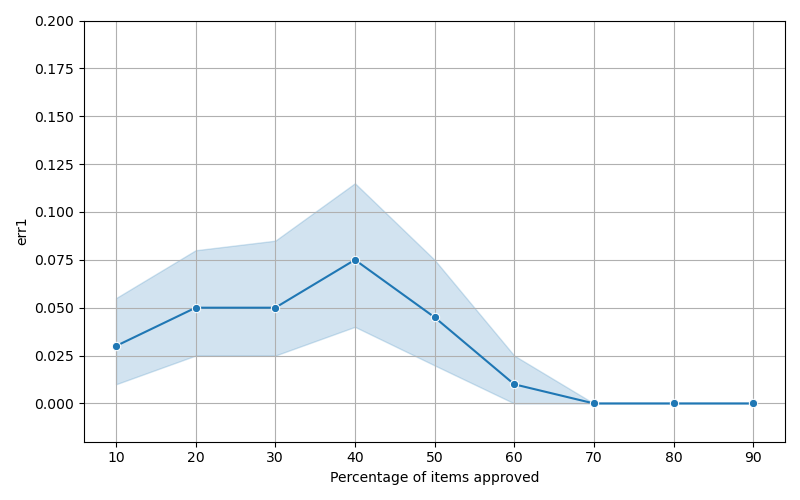
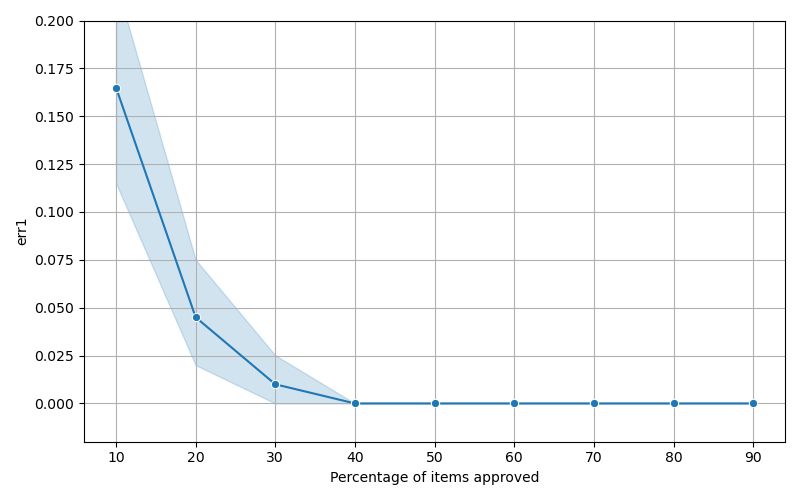
📊 논문 시각자료 (Figures)