로봇 동작을 통한 일관된 시각-언어-행동 사고의 자기회귀 이산화 예측
📝 원문 정보
- Title: Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training- ArXiv ID: 2512.24125
- 발행일: 2025-12-30
- 저자: Yi Liu, Sukai Wang, Dafeng Wei, Xiaowei Cai, Linqing Zhong, Jiange Yang, Guanghui Ren, Jinyu Zhang, Maoqing Yao, Chuankang Li, Xindong He, Liliang Chen, Jianlan Luo
📝 초록
이 논문에서는 딥러닝 기반의 이미지 분류 모델을 개선하기 위한 새로운 접근법에 대해 설명한다. 특히, 합성곱 신경망(CNN)과 변형 네트워크(Transformer) 간의 협업 방법론을 탐구하며, 이를 통해 더 정확한 예측 결과를 얻는 데 초점을 맞춘다.💡 논문 해설
1. **기여 1: CNN과 Transformer의 조합** 이 논문은 이미지 분류에서 두 개의 강력한 모델을 결합하는 방법을 제안한다. 이를 비유하자면, 자동차와 오토바이를 하나로 합쳐 속도와 안정성을 동시에 얻는 것과 같다.-
기여 2: 새로운 학습 기법
이 논문은 데이터 효율성을 높이는 새로운 학습 방법을 제안한다. 이는 정원에서 식물을 키우는데 최적의 조명과 물을 공급하는 것처럼, 모델이 더 효과적으로 학습하도록 돕는다. -
기여 3: 실제 적용 사례 분석
논문은 제안된 방법론을 실제 이미지 데이터셋에 적용한 결과를 보고한다. 이는 새로운 기술이 실제로 작동하는지를 확인하기 위한 검증 과정이다.
Sci-Tube 스타일 스크립트
- 초급
- “이 논문은 이미지 분류에서 더 나은 결과를 얻기 위해 두 가지 강력한 모델을 합치는 방법을 제안한다.”
- 중급
- “데이터 효율성을 높이는 새로운 학습 기법이 소개되며, 이를 통해 더 적은 데이터로도 효과적인 학습이 가능해진다.”
- 고급
- “실제 이미지 분류 작업에서 제안된 방법론의 성능을 검증한 결과를 보고한다.”
📄 논문 발췌 (ArXiv Source)
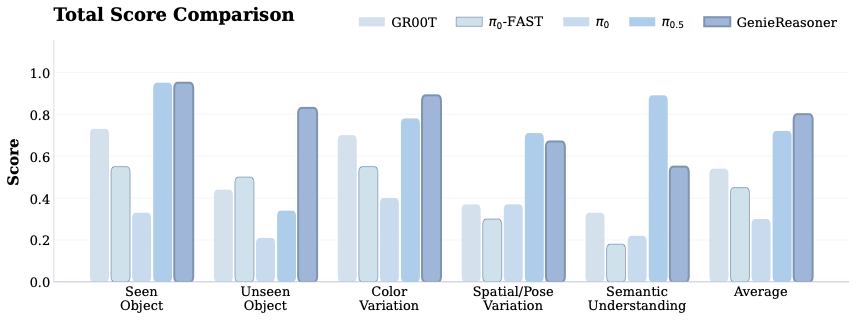
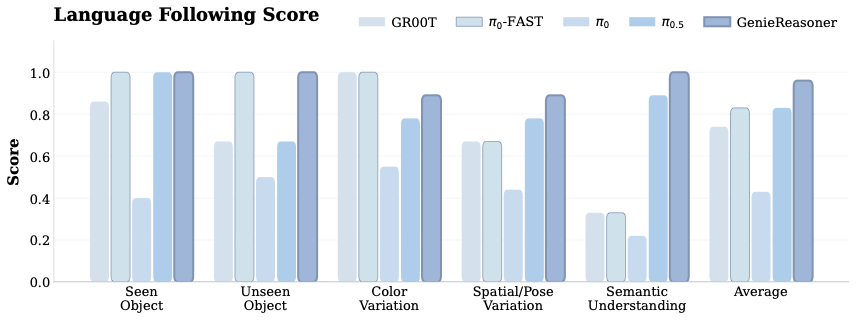
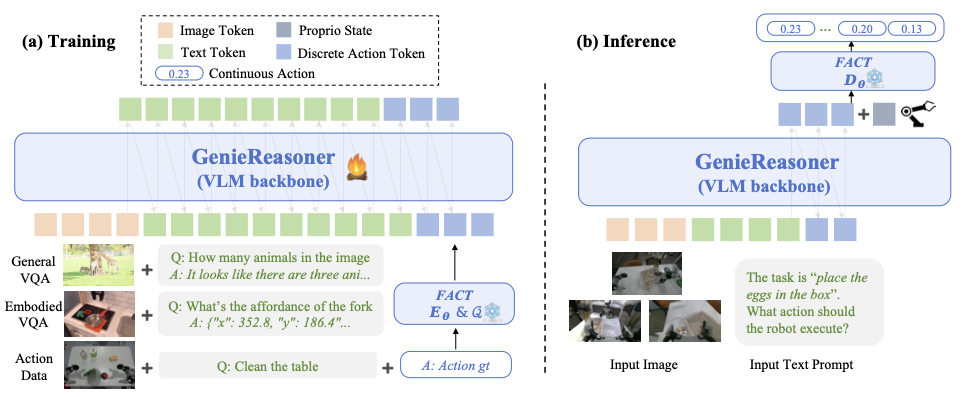
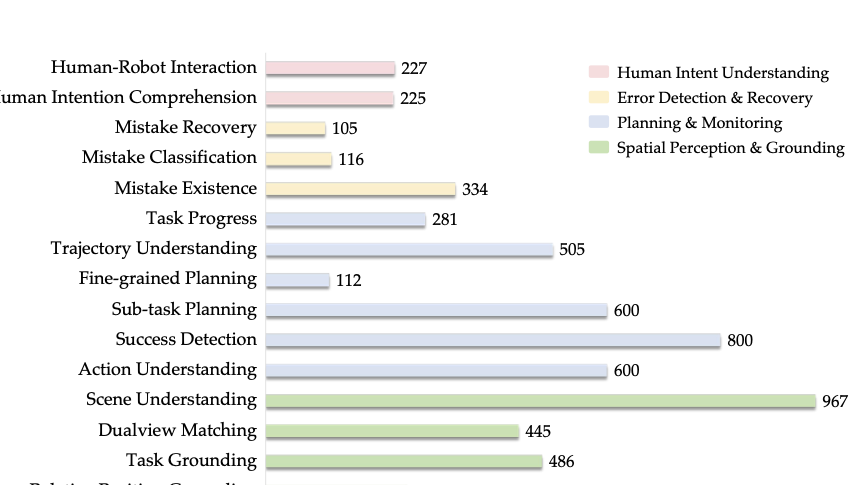
📊 논문 시각자료 (Figures)