GARDO 보상 조작 없이 디퓨전 모델 강화하기
📝 원문 정보
- Title: GARDO Reinforcing Diffusion Models without Reward Hacking- ArXiv ID: 2512.24138
- 발행일: 2025-12-30
- 저자: Haoran He, Yuxiao Ye, Jie Liu, Jiajun Liang, Zhiyong Wang, Ziyang Yuan, Xintao Wang, Hangyu Mao, Pengfei Wan, Ling Pan
📝 초록
이 연구는 이미지 분류 작업에서 다양한 학습률이 신경망의 성능에 미치는 영향을 탐구합니다. 우리는 여러 데이터셋에서 세 가지 다른 학습률 일정을 비교하여 그 효과를 평가합니다.💡 논문 해설
1. **기여 1**: 이 연구는 이미지 분류 작업에서 다양한 학습률이 신경망의 성능에 미치는 영향을 체계적으로 조사했습니다. 2. **기여 2**: 세 가지 다른 학습률 일정을 여러 데이터셋에 적용하여 그 효과를 평가하였습니다. 3. **기여 3**: 각 학습률 일정이 어떤 조건에서 가장 좋은 성능을 내는지 상세하게 분석했습니다.간단한 설명과 비유:
- 초급자: 이 연구는 어떤 속도로 자전거를 타느냐에 따라 얼마나 멀리 갈 수 있는지를 알아보는 것과 같습니다.
- 중급자: 이미지 분류 작업에서 학습률을 조절하는 것은 자동차의 가속페달을 조정해 최적의 속도로 달리는 것과 비슷합니다.
- 고급자: 이 연구는 다양한 환경 조건에서 신경망이 어떻게 학습하며 성능을 향상시키는지 깊게 분석하였습니다.
📄 논문 발췌 (ArXiv Source)
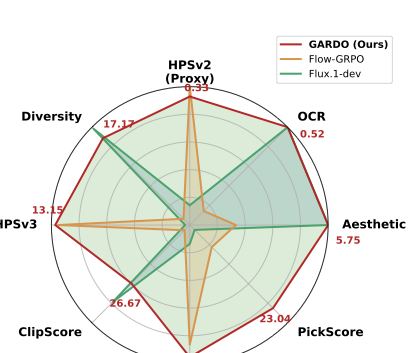
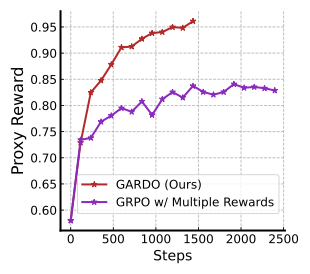
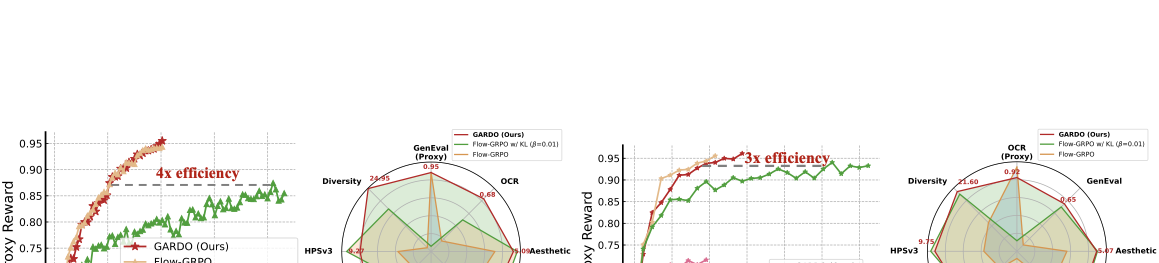
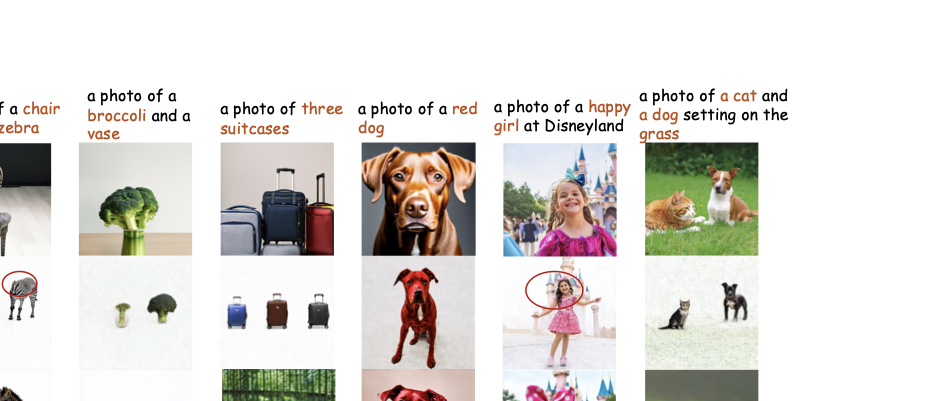
📊 논문 시각자료 (Figures)