- Title: Skim-Aware Contrastive Learning for Efficient Document Representation
- ArXiv ID: 2512.24373
- 발행일: 2025-12-30
- 저자: Waheed Ahmed Abro, Zied Bouraoui
📝 초록
(이 논문은 긴 문서를 처리하는 새로운 방법을 제안합니다. 이 방법인 CPE는 자비학습 대조 학습을 사용하여 문서의 중요한 부분들을 찾아내고 이를 통해 효과적인 문서 임베딩을 생성합니다.)
💡 논문 해설
1. **새로운 문서 인코더 개발**
- **간단 설명**: 이 논문은 긴 법률 및 의료 문서를 처리하는 새로운 방법을 제안합니다. 이 방법인 CPE는 각 문서의 중요한 부분들을 찾아내고 이를 통해 효과적인 임베딩을 생성합니다.
- **비교**: 이 인코더는 마치 우리가 책에서 중요한 내용만 추려낼 때와 비슷한 역할을 합니다.
자비학습 대조 학습 사용
간단 설명: CPE는 자비학습 대조 학습을 통해 문서의 중요 부분들을 찾아냅니다. 이를 통해 모델은 각 문서가 무엇인지 이해하는 데 도움이 됩니다.
비교: 이 방법은 마치 우리가 새로운 책을 읽을 때 중요한 장면만 기억하려고 노력하는 것과 같습니다.
다양한 실험으로 성능 검증
간단 설명: 논문에서는 다양한 실험을 통해 CPE의 효과를 입증합니다. 이를 통해 기존 방법보다 더 나은 결과가 나왔습니다.
비교: 이는 마치 새로운 약이 기존 약보다 효과적인지 확인하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 서론
언어 모델(LMs) 도입 이후, NLP의 주요 관심사는 큰 사전 훈련된 언어 모델을 세밀하게 조정하는 것이었다. 특히 문장 및 단락 수준 작업에 중점을 뒀다. 그러나 문서 임베딩을 정확히 학습하는 것은 여전히 중요한 과제로 남아 있다. 예를 들어, 문서 분류, 순위 매기기, RAG 시스템 등에서 효율적인 문서 표현 인코더가 필요하며, 법률 및 의료 애플리케이션에서는 판결 예측, 법률 정보 검색, 생물의학적 문서 분류 등에 활용된다.
고품질 문서 표현을 학습하는 것은 복잡성과 효율성을 균형 있게 처리하는 인코더 개발의 어려움 때문에 과제가 된다. 대부분의 문서 인코더는 BERT와 같은 자기 주의 아키텍처 기반 문장 인코더를 사용한다. 그러나 입력 길이에 따라 자기 주의 메커니즘이 2차적으로 확장하기 때문에 너무 긴 입력을 처리하는 것은 실현 불가능하다. 이러한 문제를 해결하기 위해 Linformer, Big Bird, Longformer 및 계층적 트랜스포머와 같은 아키텍처가 개발되었다. 이들 아키텍처는 전통적인 주의 메커니즘에서 2차적으로 확장하는 대신 희소 주의 메커니즘이나 계층적 주의 메커니즘을 사용하여 선형으로 확장한다. 따라서 이러한 모델은 $`4096`$ 입력 토큰을 처리할 수 있으며, 이는 대부분의 문서를 포함하는 데 충분하다.
희소 주의 네트워크 기반 방법이 복잡성을 해결하긴 하지만, 문서 길이는 여전히 하류 애플리케이션에서 정확한 표현을 구축하는 데 문제가 된다. 특히 법률 및 의료 도메인과 같은 하류 작업에 대한 모델의 세밀한 조정은 계산적으로 집약적이다. 두 번째로, 문서 전체의 의미를 포착하는 것은 여전히 복잡하다. 텍스트 조각 간의 내부 종속성이 어떻게 고려되는지 명확하지 않기 때문이다. 긴 문서는 짧은 문서보다 더 많은 정보를 포함하기 때문에 일정 크기의 표현 내에서 모든 관련 정보를 포착하는 것이 어렵다. 또한 문서는 일반적으로 다른 부분을 다루므로 인코딩 과정이 복잡해지고, 이로 인해 표현이 붕괴될 수 있다. 특히 법률 및 의료 문서에서는 전문 용어와 연관된 여러 사실을 설명하는 텍스트 조각이 포함되어 있어 더욱 그렇다.
법률이나 의료 분야의 전문가들이 문서를 읽는 방식에서 영감을 받은 본 논문은 긴 문서에 대한 고품질 임베딩 생성을 목표로 하는 문서 인코더 개발에 초점을 맞추고 있다. 이러한 인코더는 전문가처럼 관련 텍스트 조각을 추출하여 세밀한 조정 없이 하류 작업에서 우수한 성능을 발휘할 수 있게 한다. 우리는 긴 법률 및 의료 문서를 대상으로 하는 새로운 자기 학습 대조 학습 프레임워크를 제안한다. 우리의 접근 방식은 내부 및 외부 문서 조각 관계를 활용하여 문서 표현 학습을 위한 CPE를 중심으로 한다. 이 모델은 문서에서 텍스트 조각을 무작위로 선택하고 해당 조각이 동일한 문서의 다른 부분과 얼마나 관련이 있는지 예측하는 인코더를 사용한다. 이를 통해 독서 과정을 시뮬레이션하며, 우리는 이 작업을 자연어 추론(NLI) 문제로 설정한다. 우리의 방법에서 “entailment” 및 “contradiction"은 리터럴한 NLI 레이블이 아니며, 대신 NLI 스타일의 이진 목표를 활용하여 모델에게 해당 조각이 문서 컨텍스트와 의미적으로 호환되는지(긍정) 또는 그렇지 않은지(부정) 가르친다. 이를 통해 인코더는 지역적 조각이 문서 수준 컨텍스트와 호환되는지를 판단할 수 있다. 이 방법은 단지 다양한 문서 간의 연결을 드러내는 데 그치지 않고 여러 섹션의 관련성을 강조하여 전체적인 학습 과정을 풍부하게 한다. 주요 기여 사항은 다음과 같다:
우리는 자기 학습 Chunk Prediction Encoder (CPE)를 도입하며, 이 인코더는 계층적 트랜스포머와 Longformer에 무작위 스팬 샘플링을 적용한다. 텍스트 스팬을 샘플링하고 해당 스팬이 동일한 문서에 속하는지 예측하도록 모델을 학습함으로써 CPE는 내부 및 외부 문서 조각 관계를 포착하며, 조각 집합을 통해 전역 컨텍스트를 유지한다.
우리는 관련된 조각의 표현을 서로 가깝게 하며, 그렇지 않은 조각은 멀리 떨어지도록 하는 대조 손실을 적용하여 동일 문서의 다른 부분 간 의미 있는 연결을 강화한다.
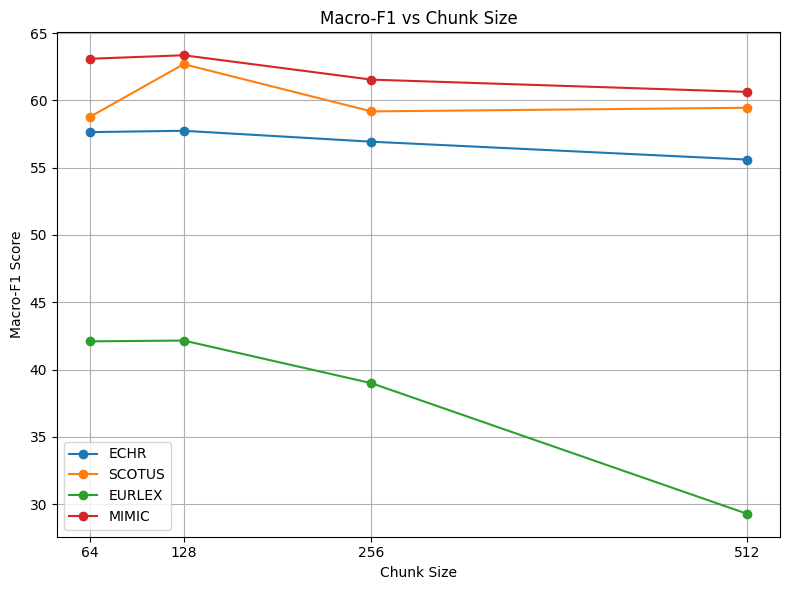
우리는 우리의 프레임워크의 효과를 입증하기 위해 광범위한 실험을 수행한다. 구체적으로, i) 기존 베이스라인과 우리 문서 임베딩의 품질을 비교하고, ii) CPE 기반 모델을 전체 세밀한 조정 설정에서 평가하며, iii) 다른 조각 크기의 영향을 평가하는 실험을 수행한다.
관련 연구
이 섹션에서는 긴 문서 처리 및 자기 학습 문서 임베딩에 대한 모델링 방법론을 개요합니다.
긴 문서의 모델링
긴 문서는 일반적으로 Longformer와 BigBird와 같은 희소 주의 네트워크를 사용하여 처리된다. 이러한 모델은 표준 전체 주의 메커니즘의 $`O(n^2)`$ 복잡성을 극복하기 위해 지역적 및 전역적인 주의 메커니즘을 사용한다. 또한 계층적 주의 메커니즘을 활용할 수 있다. 예를 들어, 계층적 BERT 모델은 긴 법률 문서를 처리하는 데 적용되며, 이 모델은 각 문장에서 단어를 처리하여 문장 임베딩을 생성한 다음, 문장 수준의 임베딩에 자기 주의 메커니즘을 적용하여 문서 임베딩을 생성한다. 저자들은 계층적 BERT 모델이 Vanilla BERT 아키텍처 및 Bi-GRU 모델보다 우수함을 입증했다. 또한 여러 방법으로 긴 문서를 분할하는 것과 희소 주의 메커니즘을 비교한 결과, 128 토큰 단위로 문서를 분할하면 더 나은 성능이 나타났다. Hi-Transformer 모델은 문장 수준 및 문서 수준 트랜스포머와 계층적 풀링을 적용한다. 또한 콘텍스트 인코더 및 교차 콘텍스트 인코더를 사용한 계층적 주의 변환기 변형이 Longformer 모델과 유사한 결과를 보여주었다. 본 연구에서는 계층적 주의 메커니즘과 희소 주의 Longformer 인코더를 사용하여 긴 문서를 처리한다. 또한 자기 학습 대조 학습을 통해 문서 임베딩을 개선한다.
무신호 문서 표현
무신호 문서 표현 학습은 활발한 연구 분야다. 초기에는 Word2Vec 및 GloVE와 같은 문맥화 단어 표현 생성을 위한 딥러닝 모델이 도입되었다. Doc2Vec 모델은 컨텍스트화된 단어 표현을 사용하여 문서 임베딩을 생성했다. Skip-Thoughts 모델은 word2vec 접근법을 문장 수준으로 확장했다. 트랜스포머 기반 모델도 문장의 벡터 표현을 생성하기 위해 제안되었다. 최근에는 자기 학습 대조 학습 방법론이 발전하고 있다. CONPONO는 마스킹된 언어 모델을 사용하여 문장 간 의사소통을 포착하는 문장 수준의 목표를 제안한다. SimCSE는 짧은 문장에 대해 동일 문장의 드롭아웃 버전을 긍정 쌍으로 사용한다. SDDE 모델은 RNN 인코더를 사용하여 문서 간 관계를 기반으로 문서 표현을 생성한다. 우리는 유사한 전략을 활용하며, 트랜스포머 기반 사전 훈련된 언어 모델과 여러 개의 부정 쌍 랭킹 대조 손실을 사용한다.
법률 및 의료 문서 표현
법률 및 의료 문서 처리는 활발한 연구 주제다. 계층적 BERT 모델은 법률 문서를 처리하기 위해 제안되었다. 또한 계층적 트랜스포머 모델 아키텍처가 법원 판결 예측 작업에 적용되었다. 입력 문서는 512 토큰 크기의 여러 조각으로 분할된다. 각 조각 임베딩은 사전 훈련된 XLNET 모델을 통해 생성되며, Bi-GRU 인코더를 적용하여 최종 문서 임베딩을 생성한다. CaseHOLD 데이터셋에서 BERT 모델을 학습했다. GPT-2 모델을 사용해 대법원 판결에 대한 각 판사의 투표를 예측했다. Multi-Perspective Bi-Feedback Network를 사용하여 법률 기사를 분류하는 데 법률 문서를 처리한다. 그래프 신경망을 사용하여 문서를 표현하려고 하였다. 혼동할 수 있는 문서를 구분하기 위해 증거 기반 주의 네트워크를 적용해 차별적 특징을 추출했다.
의료 문서 처리에서는 컨텍스트화된 문서 표현을 제안하여 긴 의료 문서에서 질문에 답하도록 한다. 이 모델은 계층적 LSTM 기반 계층적 듀얼 인코더를 사용하여 의학적 엔티티를 인코딩한다. CNN 기반 레이블별 주의 네트워크를 제안하여 각 의료 코드에 가장 관련된 문서 정보에 집중하도록 하여 레이블 별 문서 표현을 생성한다. 사전 학습된 BERT 모델이 CNN 기반 레이블별 주의 네트워크보다 우수하다는 것을 보였다. 동일한 방향에서 인코더-디코더 아키텍처를 제안하여 법률 및 의료 도메인에 대한 다중 레이블 텍스트 분류에서 인코더만 모델을 능가한다. 이 작업은 사전 학습된 언어 모델을 바이오의학적 도메인 내에서 통합하는 포괄적인 조사를 제공하며, LMs를 다양한 NLP 작업에 활용하는 상당한 혜택을 강조한다. 기존 연구와 달리 우리는 자기 학습 대조 학습 사전 학습된 언어 모델을 사용하여 문서 표현을 학습하도록 제안한다.
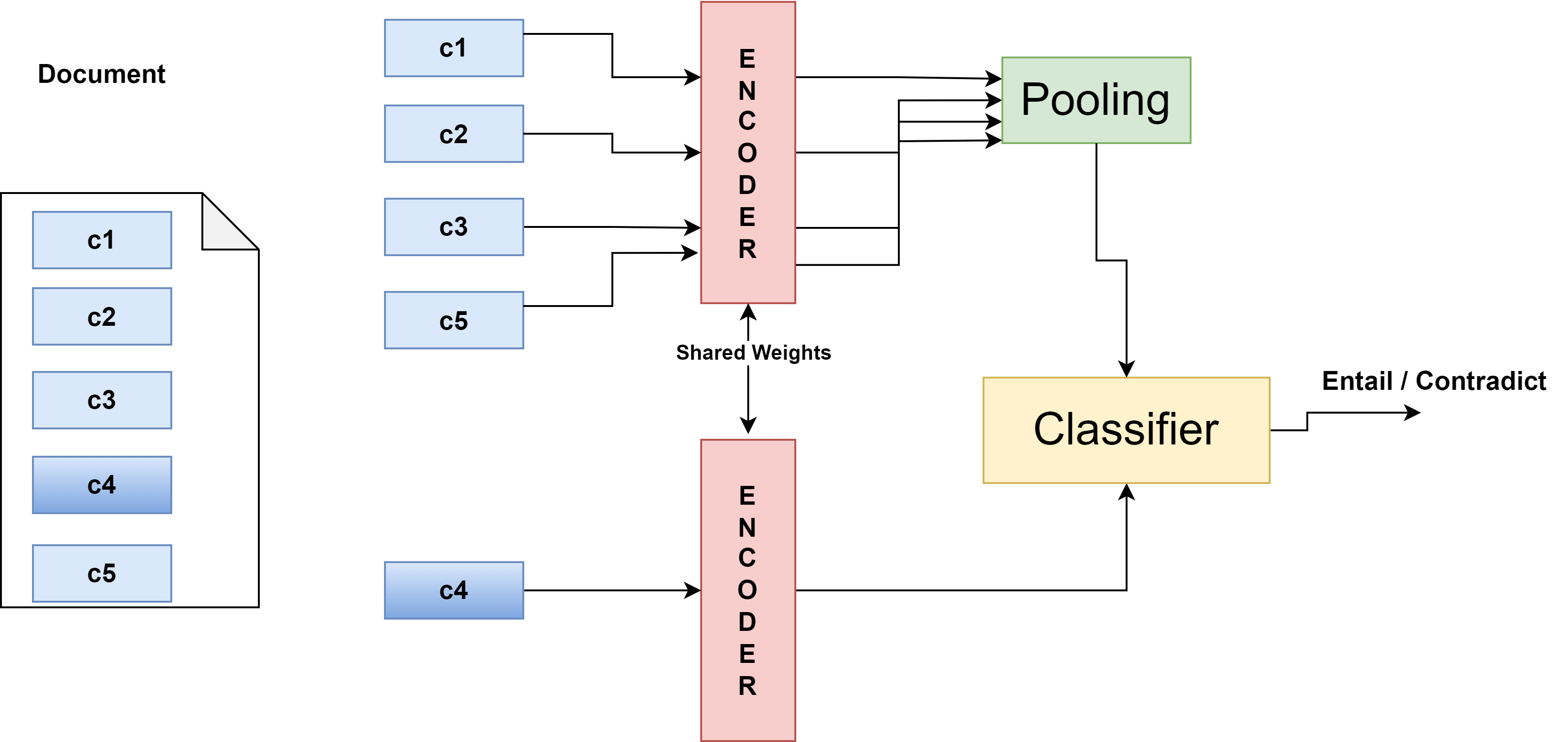
CPE 계층적 트랜스포머 모델을 통한 대조 학습의 일러스트.
조각 예측 인코더
긴 문서를 효율적으로 처리하기 위해 최신 계층적 트랜스포머 방법과 희소 주의 Longformer 모델을 사용한다. 이러한 표현의 품질을 개선하기 위해 내부 및 외부 문서 간 관계를 고려하고 관련 조각을 결정하는 자기 학습 CPE를 제안한다. 마지막으로, 우리는 단일 레이블 및 다중 레이블 분류에 대한 법률 및 의료 분류 작업에서 문서 임베딩을 사용하여 결과를 예측한다.
계층적 표현을 위한 CPE
먼저 사전 학습된 모델 $`\mathcal{M}`$을 사용한 계층적 표현 모델을 간략히 소개한다. $`D`$를 입력 문서로, $`c_1, c_2, ..., c_n`$은 $`n`$이 최대 조각 수일 때 $`D`$에 해당하는 텍스트 조각 집합이고, 조각이 $`n`$보다 적을 경우 0으로 패딩한다. 각 조각에는 $`T`$ 개의 토큰 시퀀스 $`C = (w_{1}, w_{2},.., w_{t})`$, 여기서 $`t`$는 $`512`$ 미만이다. 또한 각 조각의 시작 부분에 특수 분류 [CLS] 토큰이 추가된다. 우리의 목표는 공유된 작은 언어 모델 인코더를 사용하여 각 조각의 벡터 표현을 학습하는 것이다:
여기서 $`f`$는 모델의 출력을 나타내며 (BERT, RoBERTa, LegalBERT, ClinicalBioBERT 등이 포함된다). 일반적인 전략에 따라 우리는 [CLS] 토큰을 전체 조각의 표현으로 간주한다. 다양한 조각 특성에서 최종 문서 표현을 얻기 위해 다음 풀링 전략을 고려한다: 각 조각 표현의 평균인 Mean-Pooling $`d_t = 1/ n \sum_{i=1}^n {f_i}`$와 각 조각 표현에 대한 Max-Pooling. 각 조각은 문서의 지역적 특성을 인코딩하고, 전체 문서는 이러한 지역적 특성들의 평균으로 표현된다.
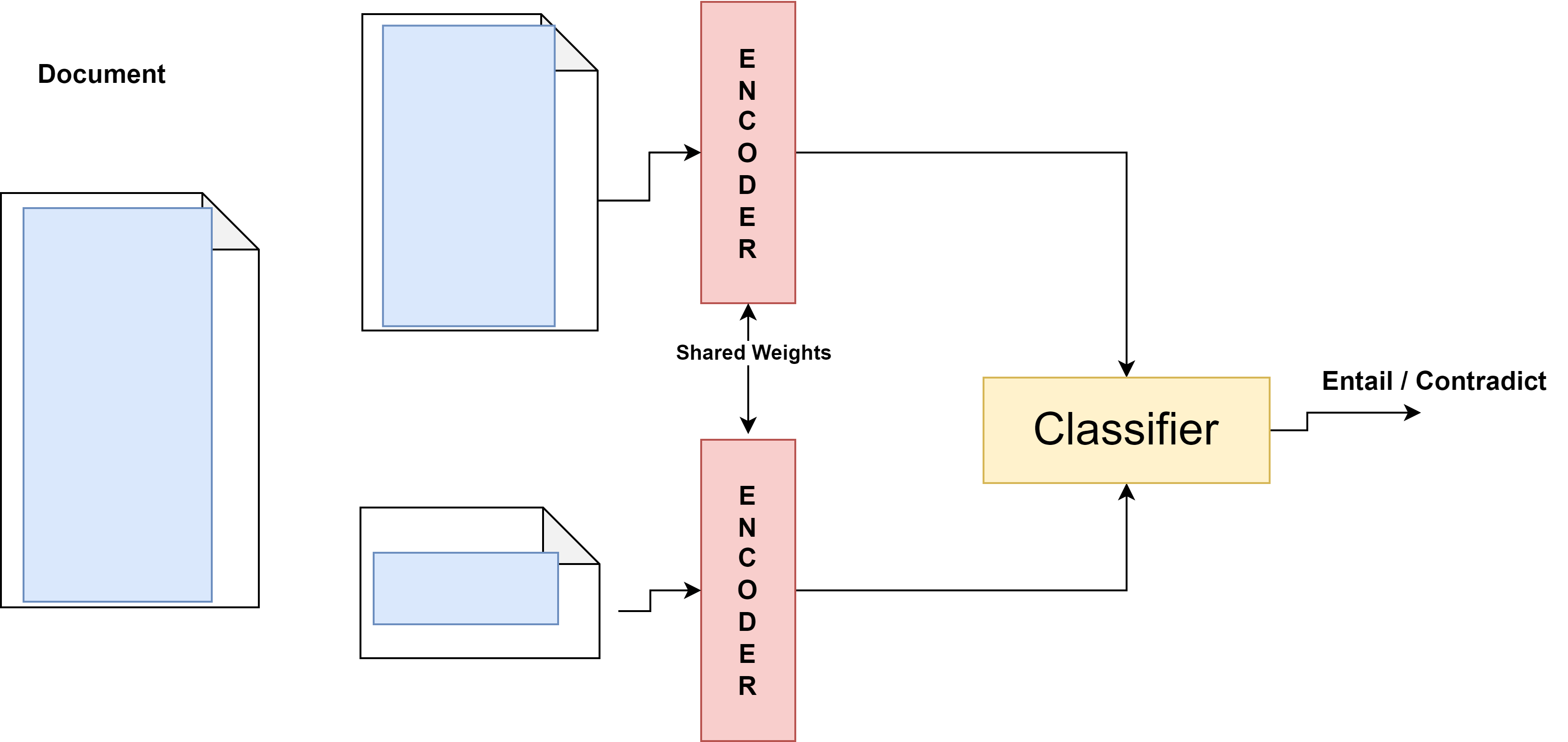
Longformer 모델을 사용한 CPE 대조 학습 프로세스.
학습 과정
우리는 계층적 트랜스포머 모델을 자기 학습 대조 학습을 통해 훈련하는 조각 예측 인코더를 제안한다. 이 방법은 내부 및 외부 문서 관계를 활용한다. 각 문서에서 한 개의 조각을 무작위로 삭제한 다음 NLI 분류기를 사용하여 해당 조각이 문서의 다른 부분에서 파생되었는지 예측하도록 한다. 이를 통해 모델은 조각 간 종속성을 학습하고 문서 표현에 대한 중요성을 배운다. 미니배치 $`N`$개의 문서를 나타내며, 각 문서 $`{d_i}`$, 무작위로 선택된 텍스트 조각 $`c^+`$와 해당 조각을 제거한 문서 $`\tilde{d_i}`$로 구성된다. 이를 통해 양성 쌍 $`\left ( \tilde{d_i}, c^+ \right )`$를 형성한다. 그런 다음 배치의 나머지 $`N-1`$개 문서에서 음성 조각 $`c^-`$를 선택하여 음성 쌍 $`(\tilde{d_i}, c^-)`$를 생성한다. 여기서 $`c^-`$는 문서 $`\tilde{d_i}`$에 속하지 않는다. 이 과정에서 텍스트 조각이 양성 및 음성 문서 모두에게 적합할 수 있다는 문제가 있을 수 있다. 그러나 이것은 문제가 되지 않으므로 학습 목표에는 여러 개의 음성이 있으며, 모델은 가장 유사한 것보다 가장 다른 문서를 최적화하도록 강제된다. 조각 예측 대조 학습 과정은 무신호 자연어 추론 작업으로 볼 수 있으며, 양성 조각 샘플은 문서의 entailment을 나타내고, 음성 샘플은 다른 문서의 contradiction을 나타낸다. 우리는 여러 개의 부정 랭킹 손실을 사용하여 모델을 학습한다: