- Title: Privacy-Preserving Semantic Communications via Multi-Task Learning and Adversarial Perturbations
- ArXiv ID: 2512.24452
- 발행일: 2025-12-30
- 저자: Yalin E. Sagduyu, Tugba Erpek, Aylin Yener, Sennur Ulukus
📝 초록
의미 통신은 메시지 복원에만 집중하는 대신 작업 관련 의미를 전달함으로써 차세대 무선 시스템에서 대역폭 효율성과 견고성을 향상시키지만, 학습된 의미 표현이 여전히 예기치 않은 수신자(espionage)에게 민감한 정보를 유출할 가능성이 있습니다. 이 논문은 다수의 수신자 작업을 지원하면서 동시에 esponeage에 대한 의미 유출을 명시적으로 제한하는 딥러닝 기반 의미 통신 프레임워크를 제시합니다. 정당한 링크는 전송기에서 학습된 인코더를 사용하며, 수신기는 의미 추론과 데이터 복원을 위한 디코더를 훈련합니다. 보안 문제는 반복적 최소-최대 최적화를 통해 구성되며, 여기서 esponeage는 의미 추론을 개선하기 위해 훈련되고 정당한 송신자-수신자 쌍은 임무 성능 유지하에 esponeage의 성공률을 줄이기 위해 훈련됩니다. 또한 전송된 파형 위에 협력적이고 적대적으로 구상된 변동을 겹치는 보조 레이어를 도입하여 esponeage에게 의미 유출을 저하시키도록 합니다. 성능은 MNIST와 CIFAR-10 데이터셋을 사용한 가우시안 잡음과 Rayleigh 침식 채널에서 평가됩니다. 잠재 차원이 증가함에 따라 의미 정확도와 복원 품질이 향상되며, 최소-최대 메커니즘은 정당한 수신자의 성능을 저하시키지 않고 esponeage의 추론 성능을 크게 감소시킵니다. 이 보조 레이어는 정당한 링크가 자신의 임무만을 위해 훈련된 경우에도 의미 유출을 줄이는 데 성공합니다. 이 포괄적인 프레임워크는 적응적 대상자에 대한 조절 가능한 종단간 사생활 보호를 갖춘 의미 통신 설계를 촉구하며 실제 무선 환경에서의 사용을 모티베이트하고 있습니다.
💡 논문 해설
1. **통합 멀티태스크 학습 프레임워크**: 이 논문은 통신과 보안을 동시에 해결하는 새로운 접근법을 제시합니다. 이를 이해하기 쉽게 말하자면, 이는 마치 음식점에서 다양한 요리를 동시에 준비하면서도 각각의 요리가 최적화되어 나오는 것처럼, 다양한 신호를 처리하면서도 각각의 의미를 보존하는 방법입니다.
민감 정보 유출 방지: 통신 중 민감한 정보가 유출되는 것을 막기 위해 적응형 적대자와 게임을 하는 방식으로 학습합니다. 이것은 마치 스포츠 경기에서 상대팀의 전략에 맞서 자신의 전략을 개선하는 것과 같습니다.
적대적 변위를 통한 정보 보호: 이 논문은 적대적 변위 기법을 사용하여 합법적인 연결에는 영향을 주지 않으면서도 불법 수신자에게는 정보 유출을 줄이는 방법을 제시합니다. 이것은 마치 건물의 문을 잠그면서도 내부에서는 쉽게 열릴 수 있도록 하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
의미 통신, 개인정보 보호 학습, 멀티태스크 학습, 딥러닝, 최소-최대 최적화, 적대적 변위.
서론
무선 시스템은 대역폭과 지연 제약 내에서 분류, 탐지 및 의사결정을 포함하는 지능형 엣지 서비스를 점점 더 지원하고 있습니다. 의미 통신은 복원 가능한 원본 재구성에 초점을 둔 대신 특정 작업 성공을 위해 최적화된 컴팩트 표현을 전송함으로써 이러한 서비스를 가능하게 합니다. 무선 채널을 통해 엔드-투-엔드로 학습된 의미 통신 시스템은 제한된 채널 사용 하에서 채널 효과에 강건한 잠재적 표현을 학습할 수 있으며, 이를 통해 수신자는 의미 추론 및 재구성을 가능하게 합니다.
개인 정보. 개인정보는 오랜 기간 동안 기본적인 정보 유출 제한을 통해 정보 이론에서 연구되어 왔으며, 일반적으로 비밀 유지 기준과 통계적 측정을 통해 형식화됩니다. 이러한 기초에 보완적으로, 본 논문은 딥러닝으로 지원되는 의미 통신 내의 의미 유출에 초점을 맞추고 있으며 이는 위험성이 원시 데이터 복원을 넘어서 학습된 표현에서 작업 관련 추론에 집중합니다.
개인 정보 문제점. 의미를 위해 최적화된 표현은 여전히 민감한 정보를 유출할 수 있습니다. 작업 관련 특징이 부도덕한 탐지자가 의미 추론을 가능하게 할 수 있기 때문입니다. 전통적인 물리 계층 보안은 주로 메시지 비트를 탐지자로부터 보호하며, 이를 통해 직접적으로 의미 유출을 제한하는 개인 정보 기제가 필요합니다.
개인정보 보호를 위한 여러 기제들이 연구되었습니다. 정보 병목 표현을 사용하여 적대적 학습과 채널 변동에 따른 적응 가중치로 탐지자의 회복을 줄일 수 있습니다. 지식 인식 방법은 공유 또는 불일치한 배경 지식에서 유출을 완화하기 위해 지식 관리, 매핑 및 해석을 통해 수행할 수 있습니다. 비밀 유지 기제에는 적대적 암호화 훈련과 함께 키 기반 암호화 의미 통신이 포함되며, 변위, 암호화, 적대적으로 학습된 트랜스시버 및 개인 정보 보호-업무 성능 교환을 위한 학습 기반 양자화의 비교 연구가 있습니다. 도메인 특수 목적 (예: 시각)은 가로채진 재구성의 유용성을 줄이면서 작업 성능을 유지할 수 있습니다. 배포 지향 설계는 의미 암호화, 개인 정보 보호 변위 및 수신자 측면에서의 의미 교정을 조합하여 수행할 수 있습니다.
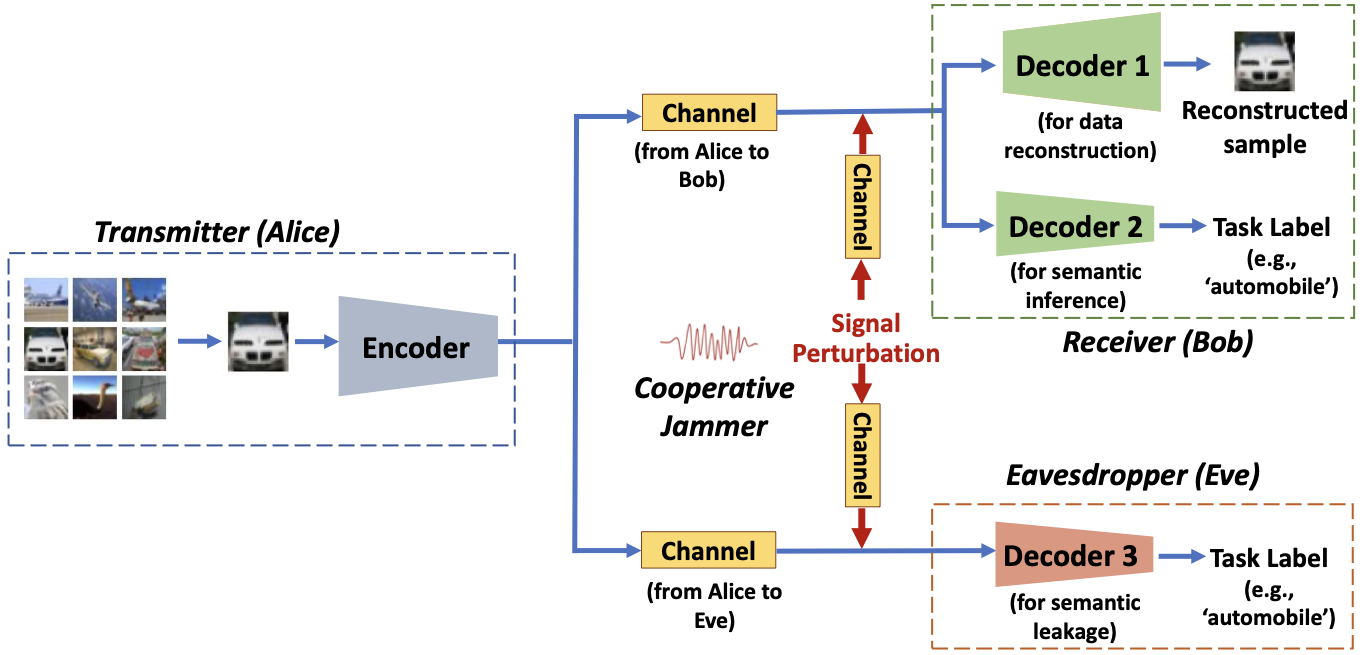
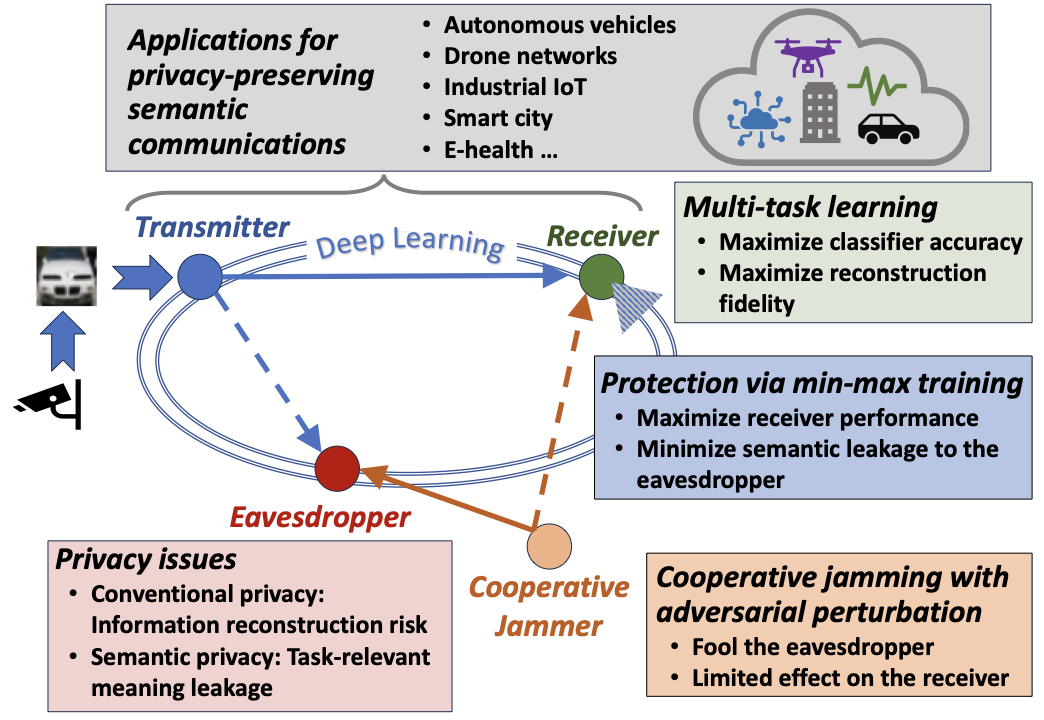
이 방향들을 기반으로 이 논문은 경쟁적 최소-최대 훈련을 통해 개인정보를 강제하는 통합 엔드-투-엔드 멀티태스크 의미 통신 프레임워크를 제시하며, 핵심 인코더-디코더 목표를 수정하지 않고도 의미 유출을 줄이는 보조 변위 계층을 도입합니다. 개인정보 보호를 위한 의미 통신의 탐지 위협과 보호 기제는 그림 1에 설명되어 있습니다.
/>
개인 정보 보호 의미 통신: 탐지와 보호 기제.
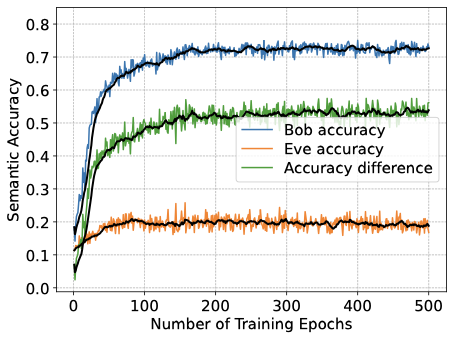
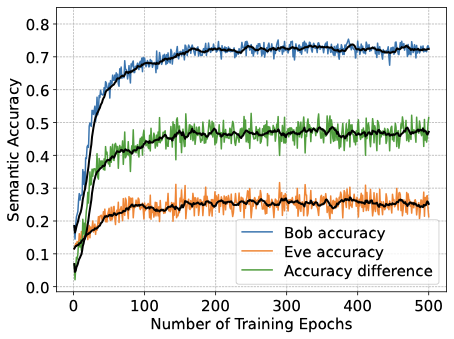
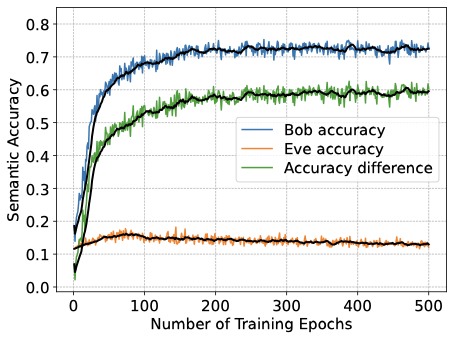
멀티태스크 학습을 통한 의미 유출 방지. 가로채진 학습된 표현은 개인 정보-유틸리티 교환에 맞게 조정할 수 있는 본질적인 의미 학습 파이프라인에 원래 속한 보호 기제를 동기화합니다. 여기서 의미 유출은 고려되는 의미 작업에 제한되며, 탐지자의 작업 정확도는 특정 작업에 대한 유출의 경험적 대리자로 사용됩니다. 멀티태스크 학습 환경에서 최소-최대 훈련 연산을 적용하여 단일 잠재 표현이 합법적인 수신자의 의미 추론 및 재구성을 동시에 지원하도록 형성하고, 적응형 탐지자의 성공을 명시적으로 줄입니다. 합법적 송수신 쌍은 작업 정확도, 재구성 품질 및 보호를 위해 훈련되며, 탐지자는 의미 추론을 위한 디코더를 학습합니다. 이 상호작용은 합법적인 쌍과 탐지자 사이의 적대적 최소-최대 게임으로 간주되고 반복적인 가장 좋은 응답 업데이트를 통해 구현됩니다. 각 라운드에서, 탐지자는 현재 전송된 표현에 대한 추론을 강화하고 그 후 합법적인 쌍은 의도한 성능을 유지하면서 탐지자의 성공을 줄입니다.
적대적 변위를 통한 의미 유출 방지. 본 논문은 또한 전송 파형에 협력적이며 적대적으로 설계된 변위 계층을 추가하는 보조 보호 계층을 고려합니다. 적대적 공격이 의미 통신 시스템에서 연구되어 왔지만, 여기서의 변위는 합법적인 작업 성능을 유지하면서 탐지자의 추론을 선택적으로 저하시키도록 설계되었습니다. 송수신 쌍은 단순히 합법적인 유틸리티를 위해 훈련될 수 있으며 (탐지자 훈련 과정에 대한 액세스 없이), 변위는 탐지자의 추론을 최소한의 영향으로 저하시키도록 설계됩니다.
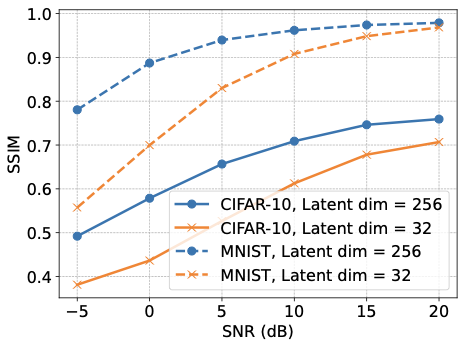
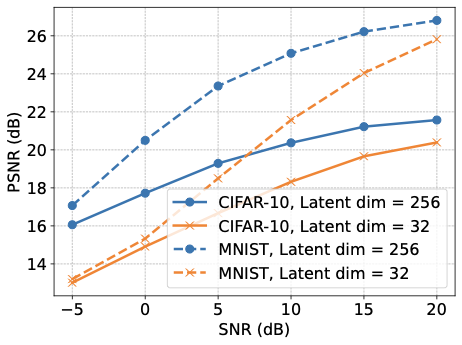
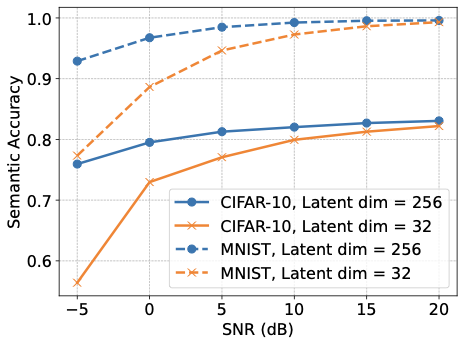
성능-개인 정보 교환 및 설계 지침. 성능은 Rayleigh 빠짐과 가우시안 잡음 채널 (AWGN)을 통과하는 MNIST와 CIFAR-10 데이터셋에서 평가되었습니다. 제안된 멀티태스크 의미 통신 접근법은 제한된 수의 채널 사용으로 높은 의미 정확도 및 뛰어난 재구성 품질을 달성하며, 이를 PSNR과 SSIM를 통해 측정합니다. 모든 성능 지표는 잠재 차원 또는 SNR이 증가함에 따라 체계적으로 개선됩니다.
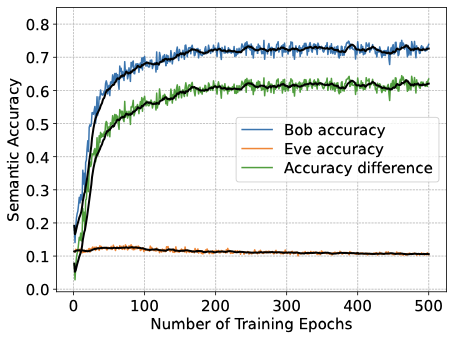
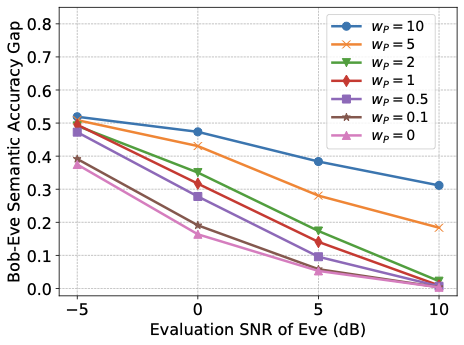
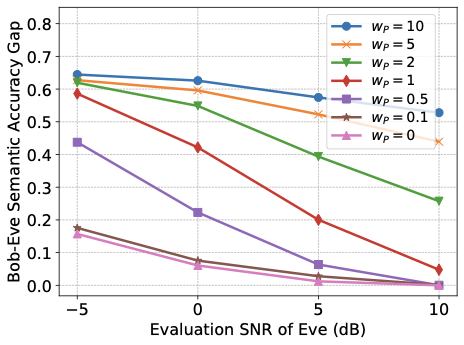
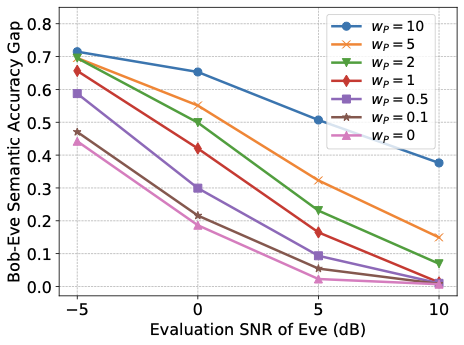
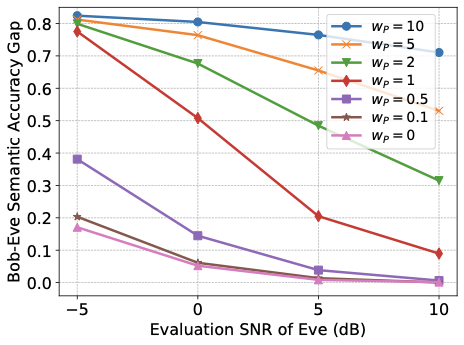
성능 결과는 합법적인 훈련에 최소-최대 개인 정보 목표를 추가하면 탐지자의 의미 추론 정확도가 저하되며, 이는 합법적 수신자의 의미 작업 성능을 저하시키지 않음을 보여줍니다. 더 강력한 개인 정보 가중치는 채널 사용이 증가함에 따라 개인 정보-유틸리티 교환을 개선하며, 탐지자 성능은 SNR 증가에 따라 향상되어 지속적으로 강화되는 탐지자와의 조정 가능한 교환이 가능합니다. 높은 의미 정확도를 유지하면서 합법적 수신자의 재구성을 약간만 영향을 주는 개인 정보 압박이 가해지고, 잠재 차원 (대역폭 프록시)이 이 보호 기제에 어떻게 영향을 미치는지 특성화합니다.
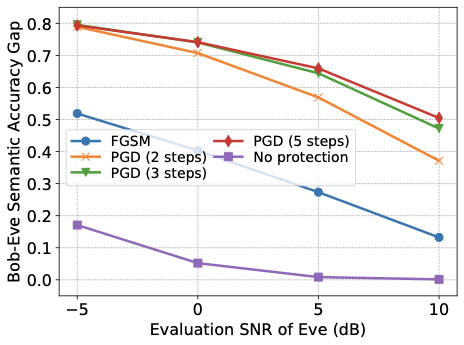
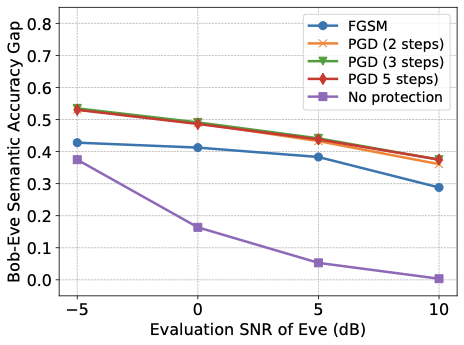
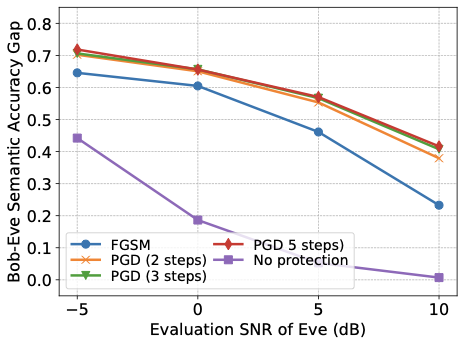
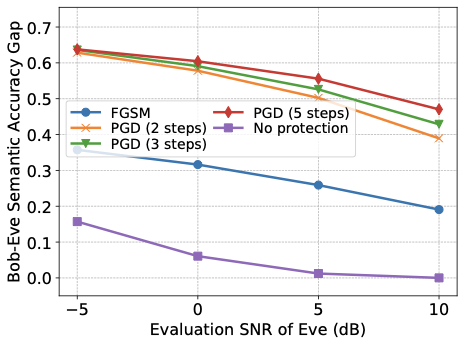
또한 합법적인 의미 링크가 탐지자를 통합하지 않고 훈련되어도 탐지자의 의미 추론 능력을 줄일 수 있음을 보여줍니다. 변위 계층을 사용하여 단계별 Fast Gradient Sign Method (FGSM) 및 반복 Projected Gradient Descent (PGD) 방법을 적용하여 의미 유출을 크게 감소시키는 적대적 변위를 생성할 수 있으며, PGD가 FGSM보다 더 강력한 보호를 제공하고 추가 PGD 단계로 더 많은 개선이 가능합니다.
이러한 설계 지침과 관찰을 동기화하여 개인 정보는 의미 통신 시스템의 조정 가능한 목표로서 취급될 수 있으며, 업무 유틸리티를 손상시키지 않고 직접적인 엔드-투-엔드 학습에 통합될 수 있습니다. 이러한 관점은 성능을 유지하면서 다양한 운영 조건에서 점점 더 능력있는 탐지자에게 대응하기 위해 강력하고 적응형 보호를 제공하는 배포 지향 아키텍처와 훈련 패러다임을 촉진합니다.
이 논문의 나머지는 다음과 같이 구성됩니다. 섹션 [sec:sem]에서는 멀티태스크 학습과 함께 의미 통신에 대해 설명하고, 섹션 [sec:privacy]에서는 탐지 위협 모델을 소개하고 최소-최대 훈련을 통해 의미 유출을 줄이는 방법을 제시합니다. 섹션 [sec:perturbation]에서는 의미 유출에 대한 변위 기반 보호 메커니즘을 제시하며, 섹션 [sec:future]에서는 미래의 연구 방향을 다룹니다. 섹션 [sec:conclusion]에서 논문을 마무리합니다.
멀티태스크 학습과 함께 의미 통신
송신자 (앨리스)의 이미지 소스와 AWGN 채널을 포함한 Rayleigh 빠짐 무선 채널 위에서 작동하는 합법적 수신자 (밥)를 고려합니다. 시스템 모델은 그림 2에 설명되어 있습니다. 앨리스와 밥이 각각 단일 안테나를 가진다고 가정합니다. 송신자는 입력 이미지를 제한된 복잡 채널 사용을 나타내는 잠재 공간의 차원으로 표현되는 고정 길이의 잠재적 표현에 매핑합니다. 무선 채널은 빠짐과 잡음으로 이 표현을 손상시키며, 수신자는 명시적인 채널 상태 정보 (CSI) 없이 학습된 디코딩을 수행합니다.
/>
개인 정보 보호 의미 통신 시스템 모델. />
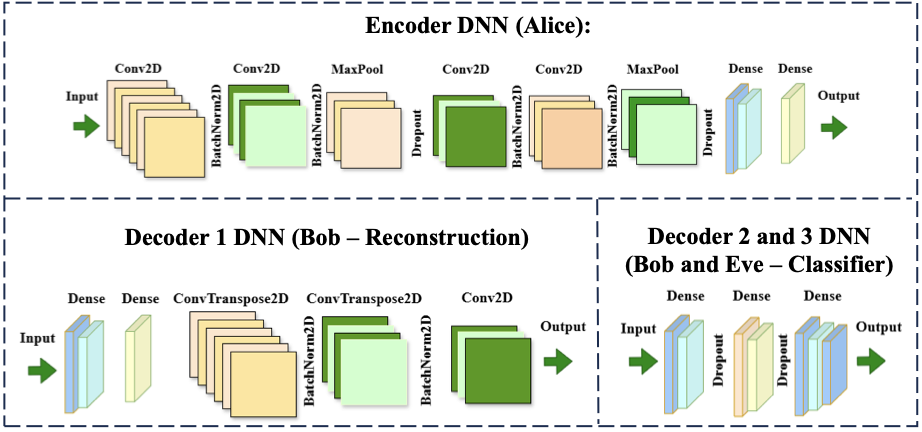
인코더 및 디코더를 위한 신경망 아키텍처.개인 정보 보호 의미 통신 시스템 모델과 기본 인코더와 디코더 아키텍처.
송수신 쌍의 인코더 및 디코더
앨리스와 밥의 인코더 및 디코더 아키텍처는 그림 3에 설명되어 있습니다. 앨리스는 각 입력 이미지를 무선 전송을 위한 컴팩트 잠재 표현으로 압축하는 컨볼루션 신경망 (CNN) 기반 인코더를 사용합니다. 인코더는 두 단계의 컨볼루션 특징 추출기로 구성되며, 각 단계는 배치 정규화와 ReLU 활성화 함수가 있는 작은 커널 컨볼루션 계층을 사용한 후 max-pooling 기반 다운샘플링과 중간 드롭아웃으로 조정합니다. 첫 번째 단계는 특징 깊이를 64 채널로 확장하고 두 번째 단계는 이를 128 채널로 확장하여 전체적으로 공간 해상도를 4배 감소시킵니다 (예: MNIST의 경우 7 x 7, CIFAR-10의 경우 8 x 8). 결과 특징 맵은 평탄화되어 두 계층의 완전 연결 투영 헤드를 통해 1024 단위 숨겨진 계층을 거쳐 I/Q 벡터를 생성합니다. 이 출력은 선택한 잠재 길이 (예: 32 또는 256)에 대한 두 스트림으로 재구성되어 in-phase 및 quadrature 구성 요소를 나타냅니다. 인코더 출력에서 표본별 전력 정규화가 적용되어 각 전송 표현이 일관된 송신 전력 예산을 만족하고 배치와 에포크 간의 채널 SNR 해석이 안정적으로 유지됩니다.
밥은 동일한 수신 잠재적 표현에 의해 구동되는 두 가지 분기로 구성된 멀티태스크 디코더를 사용합니다. 재구성 분기는 I/Q 스트림을 평탄화하고 중간 계층 1024 단위의 두 계층 완전 연결 확장을 적용하여 수신 벡터를 256 채널로 공간 해상도가 4분의 1인 저해상도 특징 맵으로 매핑합니다. 이 특징 맵은 각각 배치 정규화와 ReLU가 있는 두 개의 전치 컨볼루션 블록을 통해 확장되고 마지막 컨볼루션과 시그모이드를 통과하여 유효한 픽셀 강도를 생성합니다. 병렬로, 의미 분기는 ReLU 및 드롭아웃이 있는 두 개의 숨겨진 계층을 갖춘 완전 연결 분류기이며, 마지막 선형 계층은 다운스트림 작업에 대한 클래스 로짓을 출력합니다.
두 가지 분기를 동시에 훈련하면 잠재적 표현이 작업 관련 의미를 유지하고 재구성 기반 메트릭을 통해 인식 품질을 모니터링하는 것을 장려합니다. 밥은 명시적인 CSI 없이 훈련되며, 채널 손상에 대한 노출을 통해 종단 간 학습으로 강건성을 학습합니다. 각 전송 블록 동안 앨리스-밥 채널의 SNR은 넓은 범위에서 무작위로 변동되어 인코더와 밥의 디코더가 보바가 관찰하는 SNR 조건에 일반화되는 표현을 학습합니다.
멀티태스크 학습 목표
훈련 중, 밥은 의미적 정확도 및 재구성 품질에 대한 결합된 목표를 최적화하며 이는 작업 손실의 가중합으로 구현됩니다. 의미 손실은 범주형 교차 엔트로피 (CCE)이며, 재구성 손실은 왜곡 충실도와 시각적인 품질을 위한 SSIM 기반 항목을 결합한 평균 제곱 오차 (MSE)입니다. 검증 시, 성능은 분류 정확도, PSNR 및 SSIM를 통해 재구성 품질을 측정합니다. 이미지의 경우, PSNR과 SSIM는 픽셀 단위 손실보다 시각적 충실도와 구조적 일관성을 더 잘 포착하며, SSIM은 의미 압축 하에서 작업 관련 구조를 유지하고 PSNR은 스케일 정규화되고 해석 가능한 MSE 변형을 제공합니다.
멀티태스크 학습은 두 가지 보완적인 역할을 합니다. 첫째, 인코더 표현이 픽셀 복원뿐만 아니라 추론에도 유용하도록 강제합니다. 둘째, 채널 손상 하에서 학습을 안정화시킵니다: 의미적 및 재구성 신호가 동시에 존재할 때, 인코더는 투명도 또는 잡음에 취약한 단일 목표에 과적합되는 가능성이 줄어듭니다. 실제로, 의미 분기는 의미를 인코딩하고, 재구성 분기는 구조 정보를 유지하여 해석성을 개선합니다. 이 멀티태스크 베이스라인은 후속 섹션 [sec:privacy]에서 도입될 보호 메커니즘에 대한 명확한 참조점도 제공하며, 여기서 추가적인 목표가 부가되어 탐지자 추론을 억제합니다.
의미 통신 성능
두 가지 이미지 데이터셋을 복잡성 효과를 설명하기 위해 사용했습니다. MNIST 이미지는 단일 그레이스케일 채널의 28 x 28 픽셀로, 그 형태는 28$`\times`$28$`\times`$1입니다. CIFAR-10 이미지는 세 가지 색상 채널을 가진 32 x 32 픽셀이며, 그 형태는 32$`\times`$32$`\times`$3입니다. 재구성 MSE 손실은 5로 가중되었으며, 다른 모든 손실은 각각 1의 가중치를 사용하여 결합된 손실에서 재구성 및 의미 항목의 상대 기여를 균형있게 맞춥니다. 섹션 [sec:privacy]에서는 개인 정보 보호 손실에 대한 조정 가능한 가중치가 도입됩니다. 훈련은 NVIDIA RTX PRO 6000 Blackwell GPU에서 PyTorch로 500 에포크 동안 수행되었습니다.
의미 통신 성능은 그림 8에서 Alice-Bob 채널의 SNR에 따라 보여집니다. 전반적으로 성능이 SNR 증가함에 따라 향상됩니다. MNIST는 시각적 복잡성이 낮고 강력한 클래스 분리로 인해 더 높은 의미 정확도를 달성합니다.