- Title: Align While Search Belief-Guided Exploratory Inference for World-Grounded Embodied Agents
- ArXiv ID: 2512.24461
- 발행일: 2025-12-30
- 저자: Seohui Bae, Jeonghye Kim, Youngchul Sung, Woohyung Lim
📝 초록
이 논문에서는 부분적으로 관찰할 수 있는 환경에서 작동하는 에이전트의 탐색적 의사결정을 연구합니다. 특히, 이 논문은 "Align While Search" (AWS)라는 가벼운 월드-얼라인먼트 에이전트를 소개하며, 이는 테스트 시간에 제어를 신념 지도 검색으로 변환합니다.
💡 논문 해설
1. **가벼운 세계 맞춤형 에이전트**: AWS라는 가벼운 에이전트를 도입하여, 테스트 시간에만 제어를 수행하고 추가 학습이나 경사 하강을 필요로하지 않습니다.
2. **베이지안 관점에서의 설명**: AWS는 근사 베이즈 적응제어로 간주되며, LLM을 사용하여 포스터리오리 신념을 정교화하고 정보 획득에 기반한 행동 선택을 합니다.
3. **다양한 환경에서의 성능 향상**: AWS는 ALFWorld, VirtualHome, BabyAI에서 다양한 물체 유형과 상호 작용 역사에 대해 검색 성공-비용 교환을 개선합니다.
비교적 쉬운 설명:
AWS는 에이전트가 세계를 더 잘 이해하고 효율적으로 탐색할 수 있도록 도와줍니다. 이를 통해 에이전트는 새로운 환경에서도 적응력이 높아집니다.
일상적인 비유: 이는 마치 우리가 새로운 곳을 방문했을 때, 이미 알고 있는 지식과 새롭게 얻은 정보를 결합하여 더 잘 탐색하는 것과 같습니다.
중간 수준의 설명:
AWS는 에이전트가 주어진 환경에서 목표 물체를 찾는데 필요한 정보를 효율적으로 수집하고 활용할 수 있도록 돕습니다. 이로 인해 에이전트는 부분적으로 관찰 가능한 환경에서도 더 효과적인 탐색을 수행할 수 있습니다.
비즈니스 비유: 이는 마치 회사가 새로운 시장에 진출했을 때, 이미 알고 있는 정보와 새로운 시장에서 수집한 데이터를 결합하여 최적의 전략을 세우는 것과 같습니다.
고급 설명:
AWS는 에이전트에게 부분적으로 관찰 가능한 환경에서 목표 물체를 찾는 데 필요한 정보를 효율적으로 수집하고 활용할 수 있는 능력을 부여합니다. 이를 통해 에이전트는 테스트 시간에만 제어를 수행하며, 추가 학습이나 경사 하강을 필요로하지 않습니다.
과학 비유: 이는 마치 우주선이 새로운 행성을 탐사할 때, 이미 알고 있는 정보와 새로운 행성에서 수집한 데이터를 결합하여 최적의 탐사 경로를 계획하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
0.8ex plus 0.4ex minus .1ex 0.8ex 소개
부분적으로 관찰 가능한 환경에서 작동하는 에이전트는 목표를 달성하는 과정에서 항상 불완전한 정보에 직면합니다. 이러한 설정에서는 탐색적 의사결정 능력이 필수입니다: 에이전트는 목표를 달성하기 위해 행동해야 하지만, 동시에 세계에 대한 자신의 믿음을 정교화하는 정보도 수집해야 합니다. 행동, 관찰 및 신념 정교화의 상호작용은 불확실한 조건에서 효과적인 행동을 하는 기초가 됩니다.
ALFWorld 하위 작업에 대한 성공률과 토큰 사용량. AWS는 강력한 추론 시간 베이스라인보다 2-5× 적은 토큰을 사용하면서 더 높은 성공률을 보여줍니다. 부분적으로 관찰 가능한 환경에서 효율적인 신념 지도 탐색을 강조합니다. 자세한 결과는 부록 20 참조.
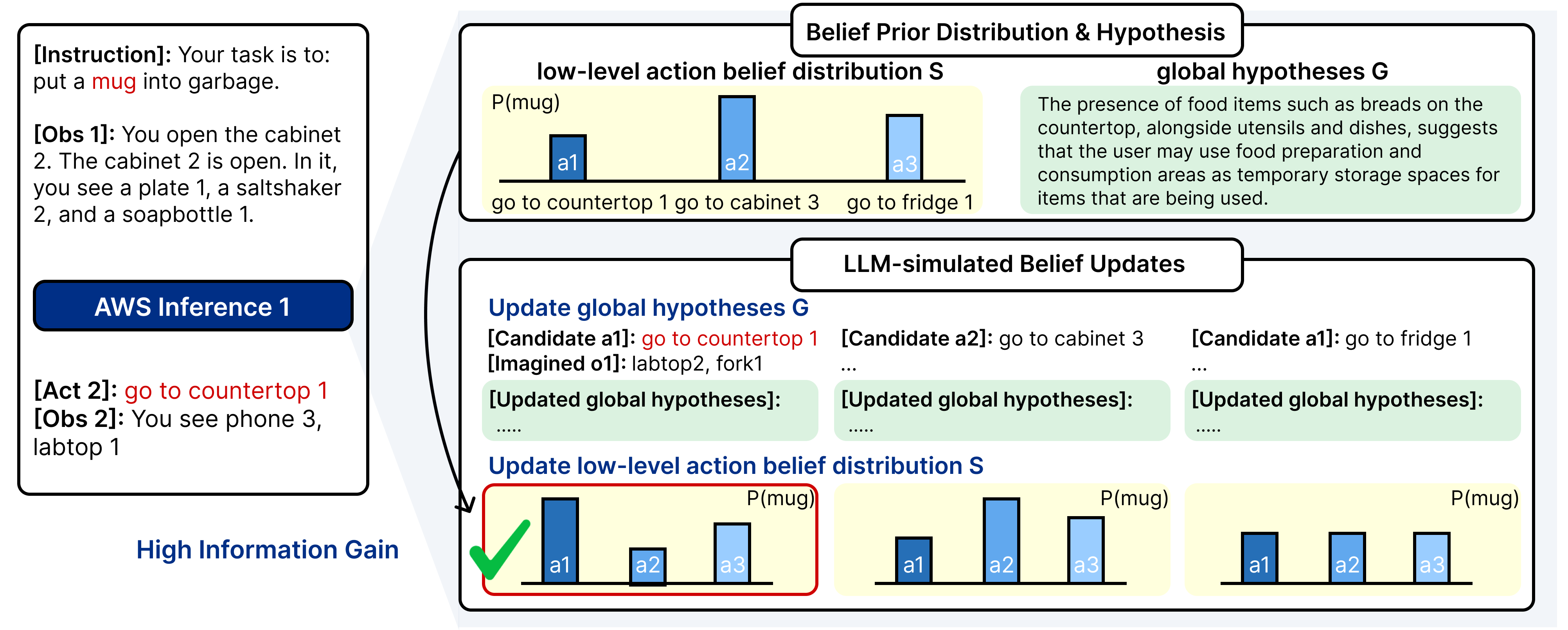
이 논문에서는 불확실성 하에서의 탐색적 의사결정에 초점을 맞추며, 기본적인 작업인 검색 작업을 고려하고 부분적으로 관찰 가능한 환경에서 추론 시간의 세계 이해를 조사합니다. 대형 언어 모델(LLMs)은 제로샷 작업 수행에 대한 희망을 보여주지만, 그들의 정적 사고는 부분적으로 관찰 가능성이 있는 환경의 전개되는 동역학에 적응하는 데 실패할 수 있습니다. 이와 같은 부분적으로 관찰 가능한 문제에 대한 이전 접근법에는 감독 학습 또는 강화 학습 훈련을 통한 훈련 시간 정책 최적화와 추론 시간 확대 방법이 포함됩니다. 하지만 전자는 큰 훈련 비용과 배포 유연성 제한을 필요로 하며, 후자는 환경과의 적응적인 상호 작용을 제공하지 않습니다. 최근에 개발된 추론 시간 에이전트들 중 Reflexion, RAP, RAFA, LAC, ReflAct 등은 LLMs와 고전적 MDP 계획 또는 질문 기반 신념 요약을 결합하지만 일반적으로 추가 시뮬레이터나 학습된 비평가를 필요로 하며 잠재 환경 구성 및 물체 위치에 대한 명시적인 확률 분포를 유지하지 않습니다. 대신, 우리는 부분적으로 관찰 가능한 상황에서의 검색 작업을 근사 베이즈 적응제어 문제로 간주합니다: 에이전트는 잠재 환경 구성에 대한 사후 확률을 유지하고, 신념 공간에서 작업 보상과 정보 획득을 교환하는 행동을 선택합니다.
이 관점을 통해 우리는 가벼운데도 효과적인 새로운 에이전트 아키텍처를 제안합니다. 이는 추론 시간 탐색적 사고를 신념 정교화를 통한 사후 확률로 수행합니다. 우리의 핵심 아이디어는 다음과 같습니다: 에이전트는 검색 행동 공간에 대한 구조화된 사후 확률을 유지하고, 환경 피드백에 따라 이를 업데이트하며, 이 진화하는 신념을 반영하는 행동을 선택합니다. 따라서 우리의 행동 정책은 기억 패턴이 아니라 동적으로 정교해진 세계 이해를 기반으로 합니다. 중요한 점은 모든 적응이 경사 업데이트나 세부 조정 없이 테스트 시간에 이루어진다는 것입니다. 실험 결과는 추론 시간 정책 최적화 베이스라인보다 훨씬 낮은 계산 부담으로 우리의 추론 시간 통합 전략이 우수함을 보여줍니다 (그림 1). 우리의 방법은 다양한 물체 유형, 환경 및 상호 작용 역사에 대해 일반화되며 특정 작업 훈련이나 보상 기반 튜닝이 필요하지 않습니다.
우리의 기여는 다음과 같습니다:
$`\bullet`$ 우리는 Align While Search (AWS), 가벼운 월드-얼라인먼트 에이전트를 도입하여 테스트 시간 제어를 신념 지도 검색으로 변환합니다. 추가 학습이나 경사 업데이트가 필요하지 않습니다.
$`\bullet`$ 우리는 AWS에 대한 베이지안 설명을 제공합니다: 근사 베이즈 적응제어로 간주되며, LLM을 사용하여 포스터리오리 신념 정교화를 구현하고, 정보 획득 기반 행동 선택을 합니다.
$`\bullet`$ ALFWorld, VirtualHome 및 BabyAI에서, 텍스트만 또는 이미지 보강 환경에서 AWS는 추론 시간 프롬프트/대규모 액세스 그래프 확장과 훈련 시간 월드 모델이나 정책 경사 베이스라인보다 검색 성공-비용 교환을 일관되게 개선합니다 (그림 1 참조).
0.8ex plus 0.4ex minus .1ex 0.8ex
예비지식
LLM 에이전트의 MDP/POMDP.
많은 언어-에이전트 설정은 마르코프 의사결정 과정(MDP)로 표현될 수 있습니다.
$`\langle\mathcal{S}, \mathcal{A}, T, \mathcal{R}, \gamma \rangle`$. ALFWorld 및 VirtualHome과 같은 몸체 환경에서 잠재적인 세계 상태 $`s`$는 에이전트 자세, 물체 위치, 컨테이너 열기/닫기 상태 및 인벤토리를 포함합니다. 에이전트가 고수준 행동을 내려($`a`$, 예를 들어, 탐색, 열기, 조작) 환경의 부분적으로 관찰되는 장면에 대한 텍스트 관찰 $`o`$를 받습니다. 그런 다음 세계 상태 $`s`$는 현재 상태와 에이전트 행동을 기반으로 전환 $`T`$에 따라 변경됩니다. LLM기반 에이전트의 입력은 일반적으로 상호 작용 이력 $`h_t=\{(o_i,a_i)\}_{i=1}^t`$ 또는 텍스트/기호 요약이며, LLM이 정책을 구현합니다.
$`\pi(a_t\mid h_t)`$. ALFWorld/VirtualHome의 구체적인 예는 부록 9.2 참조.
인식 불확실성과 베이즈 적응제어 MDPs.
환경은 부분적으로 관찰되므로, ALFWorld 및 VirtualHome에서 LLM 에이전트는 자연스럽게 POMDP로 모델링됩니다: 각 단계에서 에이전트는 환경 상태 $`s`$에 대한 부분적인 관찰 $`o \sim \mathcal{O}(o\mid s,a)`$를 받습니다. 인식 불확실성 외에도, 물체 배치나 확률적 동역학과 같은 잠재 환경 매개변수에 대한 인식론적 불확실성이 있으며, 이를 상호작용에서 추론해야 합니다. 베이즈 적응제어 MDPs (BAMDPs)는 이를 명시적으로 나타내며, 잠재 변수 $`\phi \in \Phi`$와 사전 분포 $`b_0(\phi)`$을 도입하고 $`\phi`$에 대한 신념을 상태의 일부로 취급합니다. 따라서 BAMDP
$`\langle \mathcal{S}, \mathcal{A}, \Phi, T, \mathcal{R}, \gamma, b_0 \rangle`$
에서 에이전트는 역사를 통해 $`\phi`$에 대한 사후 업데이트를 유도하여 예상 수익을 극대화하는 정책을 찾습니다. 이를 통해 정보 획득 행동을 동기 부여합니다.
0.8ex plus 0.4ex minus .1ex 0.8ex LLM 에이전트의 위험과 기회
현대 언어 에이전트, 기본 모델과 감독 트레일을 사용하여 후속 학습된 모델 모두가 학습된 행동에 과적합되는 경향이 있습니다. 이 섹션에서는 부분적으로 관찰 가능한 환경에서 이러한 현상을 조사합니다.
0.6ex plus 0.3ex minus .1ex 0.5ex 검색 작업의 실패 모드 우리는 에이전트가 생성한 행동 시퀀스의 다양성과 테스트 시간 적응을 조사하기 위한 실험을 수행했습니다. 이 실험에서, 각 실행에서는 에이전트는 가정에서 물체를 검색해야 하며 하나의 행동 시퀀스를 얻게 됩니다. 각 실행에는 다른 방 레이아웃과 타겟 위치가 있습니다. 결과는
Figure 2 (left)에 표시되어 있으며, 엔트로피는 모든 실험 실행에서 계산된 행동 집합의 경험적 분포의 엔트로피를 나타내며, 유일한 비율은 총 행동 시퀀스 중 고유한 행동 시퀀스의 수입니다. 기본 모델 (GPT-4o-mini)이 1.94와 0.21의 낮은 행동 엔트로피와 고유 트레일 비율을 보이는 반면, 우리의 방법은 각각 3.11과 0.5를 보여줍니다. 이는 환경이 실행마다 다르지만 기본 LLM 에이전트가 다양성이 낮은 행동으로 인해 반복적인 검색 동작을 생성한다는 것을 나타냅니다. 더욱 중요한 것은 감독 학습 세부 조정(SFT) 후에도 이러한 동작이 지속된다는 것입니다.
기본 모델과 SFT 모델의 탐색 실패. (왼쪽) 엔트로피와 고유 트레일 비율에 기반한 트레일 다양성 측정. (오른쪽) SFT 에이전트 실패 분석은 대부분의 오류가 훈련 시간 검색 패턴의 경직된 재생 때문임을 보여줍니다.
그림 2 (오른쪽) 및 부록 10은 테스트 시간 환경에서 검색 작업을 주어진 경우에 중점을 둡니다. 이 환경에서는 방 레이아웃은 학습된 레이아웃과 유사하지만 물체 위치는 다릅니다. 이러한 상황에서 에이전트는 테스트 시간 환경에서 84.5% (=52.7+31.8)의 총 검색 시퀀스를 학습된 방 방문 순서로 재생합니다. 특히, 50% 이상의 실패가 학습과 유사한 검색 패턴에서 발생하여 에이전트는 무엇을 관찰하는 대신 학습된대로 무작정 행동한다는 것을 나타냅니다.
0.6ex plus 0.3ex minus .1ex 0.5ex 신념 강화 탐색의 기회
잠재 변수 $`\phi`$를 도입하고 추론하면 환경 유형이나 구성에 대한 적응력과 효율적인 의사결정을 향상시킬 수 있습니다. 이는 에이전트가 상황에 맞는 행동을 선택하고, 목표된 탐색을 통해 불확실성을 줄이고, 유사한 환경에서 일반화할 수 있게 합니다. 잠재 변수 $`\phi`$를 사용하여 트레일 $`\tau_t = (o_0, a_0, o_1, \dots, a_t)`$, 에이전트는 명시적인 신념 $`b:=p(\phi|\tau)`$을 유지하고 정보 획득을 최대화하기 위해 행동을 선택합니다. 본 논문의 핵심 관찰은 많은 작업 환경이 잘 정의된 잠재적 의미 구조를 갖추고 있다는 것입니다. 예를 들어, 방은 종류(예: 주방과 침실)에 따라 달라지고 관련 물체 패턴이 있으므로 이러한 LLM 에이전트 환경에 잠재 변수 $`\phi`$를 사용할 수 있습니다.
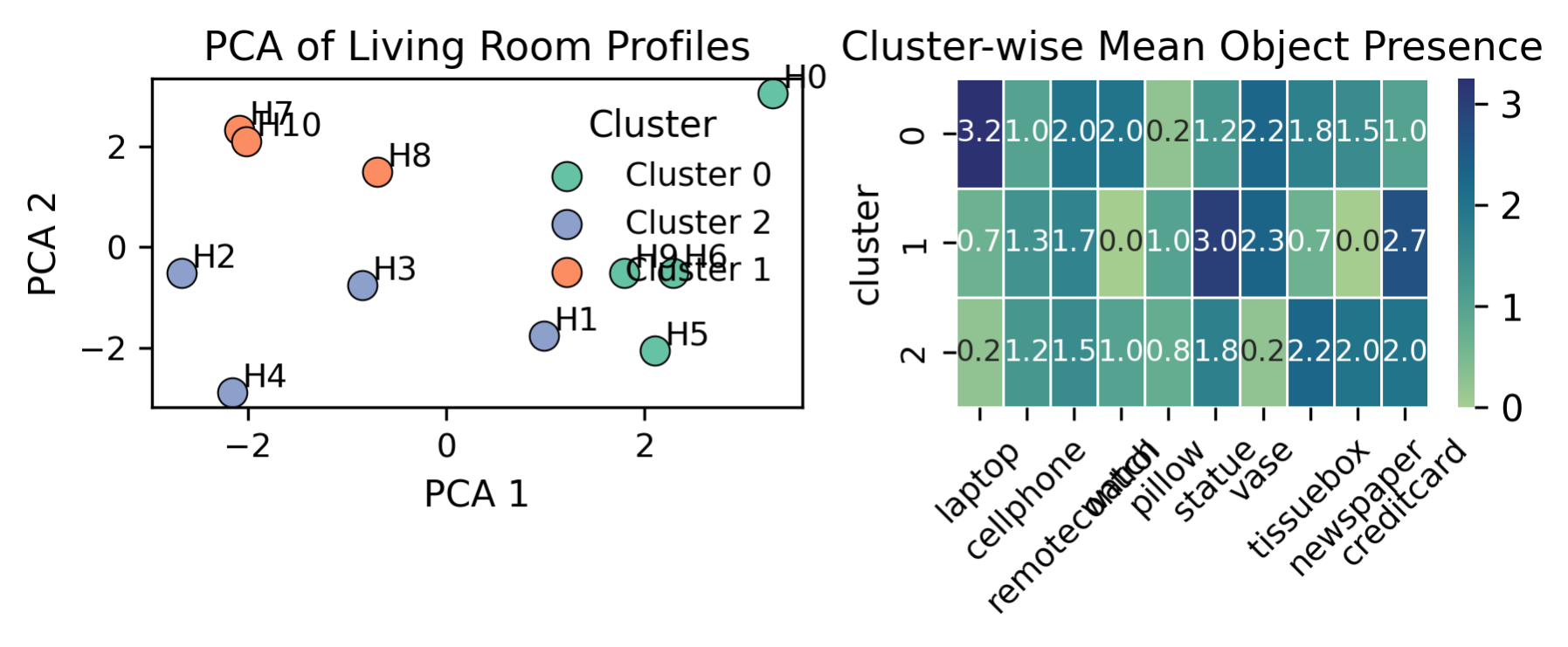
가구 카운트는 잠재적 다양성을 드러냅니다. (왼쪽) PCA는 가정 간의 물체 사용 패턴을 군집화합니다. (오른쪽) 각 군집은 고유한 물체 선호도를 나타내어 잠재적인 사용자 행동 차이를 보여줍니다.
예를 들어, 그림 3 (left)에서 가정은 생활실 물체 사용에 따라 자연스럽게 군집화되며, 각 군집의 객체 프로필(그림 3 (right))은 구조적인 차이를 보여줍니다 (예: 테크 중량 또는 미니멀리즘 사용). 그림 3의 관찰 결과는, 검색 시 복잡한 세계 구성이나 동역학이 아니라 에이전트가 잘 정의된 잠재 구조를 효율적으로 활용하지 못하는 것이 어려움의 원인임을 나타냅니다. 잠재적 의미 변수 $`\phi`$를 채택하고 이를 기반으로 명시적인 신념 구조를 구성함으로써 우리는 검색 작업을 돕습니다. 다음 섹션에서는 이 아이디어를 정식화합니다.
0.8ex plus 0.4ex minus .1ex 0.8ex 문제 정의: 신념 강화 탐색
우리는 이제 검색 작업에 대한 형식적 추상화를 소개하며, 이는 세계 동역학을 제외하고 에이전트의 물체 위치에 대한 인식론적 불확실성을 중심으로 합니다.
몸체 환경 내에서의 검색 MDP
검색 작업은 ALFWorld 및 VirtualHome 에피소드에서 반복됩니다: LLM 에이전트는 세계를 변경하는 행동(예: 물체 이동, 컨테이너 재배치)을 수행하기 전에 타겟 물체를 찾아야 합니다. 검색 단계에서는 실제 세계 상태 (모든 물체 위치 포함)가 고정되어 있으며 시간이 지남에 따라 변하는 것은 에이전트의 신념입니다. 이 단계에서 전체 몸체 동역학을 모델링 대신, 최근 물체 탐색 표현은 세계 동역학을 추상화하고 후보 위치에 대한 신념만을 기반으로 합니다. 따라서 우리는 검색 작업을 신념 강화 단일 상태 의사결정 문제로 모델링합니다. 공식적으로, 에피소드 내에서 고정된 검색 하위 목표(예: 사과 찾기)를 고려하고, $`\mathcal{L}=\ell_1, \dots, \ell_L`$는 타겟이 있을 수 있는 후보 위치 또는 수용체의 유한 집합을 나타냅니다 (방, 컨테이너 또는 환경에 의해 결정된 표면). 우리는 명시적인 신념 상태 $`b_t \in \Delta^{L}`$를 도입하며 여기서 $`b_t(\ell)`$는 타겟 물체가 검색 단계 $`t`$에서 위치 $`\ell`$에 있을 확률이며, $`\Delta^L`$은 $`\mathcal{L}`$ 위의 모든 확률 분포 세트입니다.
검색 작업 동안 우리는 기본 세계 상태 $`s`$를 고정된 것으로 추상화하고 단일 상태 MDP
에서 $`s^\star`$는 가짜 세계 상태이며 모든 비중요 동역학은 신념 안으로 밀려납니다. 행동 $`a_t \in \mathcal{A}_{\text{search}}`$는 위치를 확인하는 것을 의미하며, 실제로는 탐색 및 낮은 수준 조작을 원자적 작업으로 결합합니다.
MATH
a_t = \textsc{Check}(\ell_t),
클릭하여 더 보기
이는 $`\ell_t`$로 가서 필요시 열고 검사하는 것을 의미합니다. 환경은 텍스트 관찰 $`o_t`$를 반환합니다 (예: “당신이 사과를 봅니다” 또는 “DRAWER는 비어 있습니다”).
베이지안 관점에서의 신념 상태 제어 목표
검색 단계에 대한 정적 세계 가정 하에서는 타겟의 실제 위치가 변경되지 않으며, 대신 에이전트의 신념만 업데이트됩니다. 우리는 이를 신념 업데이트 연산자 $`\mathrm{BU}(\cdot)`$로 모델링하며 이는 신념 공간에서 효과적인 전환을 정의합니다,
$`b_{t+1} = \mathrm{BU}(b_t, a_t, o_t)`$. 보상은 희박합니다.
검색 작업은 타겟을 찾거나 단계 예산이 소진될 때까지 계속됩니다. 따라서 각 검색 작업은 신념만 진화하는 단일 상태 MDP와 유사한 밴딧입니다.
전체 에피소드 내에서는 여러 개의 이러한 하위 검색 작업이 나타날 수 있습니다 (예: “사과를 찾아” 다음에는 “컵을 찾아”). 각각은 후보 집합 $`\mathcal{L}`$ 및 초기 신념 $`b_0`$(다른 검색 하위 작업에 대해 동일할 수도 있음)를 가집니다. 주요 ALFWorld/VirtualHome 작업(타겟을 찾은 후 방 간 탐색과 물체 조작 포함)은 POMDP이지만, 우리의 Align While Search 모듈은 임베디드 검색 하위 작업에 대해 외부 신념 모듈로 작동합니다. 이 추상화 하에서 우리의 목표는 검색 효율을 향상시키는 것입니다: 고정된