- Title: What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
- ArXiv ID: 2512.24497
- 발행일: 2025-12-30
- 저자: Basile Terver, Tsung-Yen Yang, Jean Ponce, Adrien Bardes, Yann LeCun
📝 초록
본 논문은 제어 및 탐색 계획 작업을 위한 임베딩 공간에서 동적 모델을 효율적으로 학습하는 방법에 대해 연구합니다. 주요 기여는 액션 조건부 결합 예측 월드 모델(JEPA-WM)의 핵심 구성 요소들에 대한 분석이며, 이를 통해 DINO-WM과 V-JEPA-2-AC을 능가하는 최적의 JEPA-WM을 제안합니다.
💡 논문 해설
1. **기본 개념**: 월드 모델은 과거 관찰 및 행동을 기반으로 미래 상태를 예측하는 모델입니다. 이는 로봇이나 그 외 물리적인 에이전트가 환경과 상호작용할 때 필요한 중요한 구성 요소로, 보상이 희박한 환경에서 효과적으로 학습할 수 있게 해줍니다.
JEPA-WM의 장점: JEPA 월드 모델은 데이터 시각화와 인공 지능의 통합을 통해 복잡한 환경에서 성능을 향상시킵니다. 이는 로봇이 다양한 작업을 수행할 수 있도록 돕습니다.
최적화 방법: 본 논문에서는 제어 및 탐색 계획 작업에 최적의 JEPA-WM 모델을 찾기 위해 여러 구성 요소를 분석하고, 이를 통해 기존 모델보다 우수한 성능을 보이는 새로운 모델을 제안합니다.
📄 논문 발췌 (ArXiv Source)
# 서론
능력 있는 물리적 에이전트를 구축하기 위해, 과거 관찰과 행동을 기반으로 미래 상태를 예측하는 월드 모델이라는 아이디어를 제안합니다. 이러한 월드 모델은 추상화 수준에서 예측을 수행하여 위에 정책을 훈련하거나 샘플 효율적으로 계획을 수행할 수 있어야 합니다.
월드 모델링에 대한 광범위한 문헌이 이미 존재하며, 대부분 강화 학습(RL) 커뮤니티에서 나왔습니다. 비모델 기반 RL은 많은 샘플을 요구하며, 이는 보상이 희박한 환경에서는 문제가 됩니다. 이를 해결하기 위해 모델 기반 RL(MBRL)은 환경의 주어진 또는 학습된 모델을 사용하여 정책이나 Q-함수를 훈련합니다. 자동화 사전 훈련 목표와 결합하여 MBRL은 시뮬레이션에서 월드 모델링에 대한 새로운 알고리즘을 이끌었습니다.
최근에는 대규모 월드 모델이 번창하고 있습니다. 데이터가 충분한 특정 도메인, 예를 들어 운전이나 자아중심 비디오 게임에서는 상대적으로 긴 기간 동안 인상적인 시뮬레이션 정확도를 달성했습니다.
본 발표에서 우리는 (로봇) 에이전트가 장비된 (시각) 센서가 동적 시스템으로 작동하는 월드를 모델링합니다. 여기서 상태, 관찰 및 행동은 모두 파라미터화된 인코더에 의해 특징 공간에 임베딩되며, 동적인 본질 자체도 특징에 의존하는 파라미터화된 예측기 형태로 학습됩니다. 이 인코더/예측기 쌍을 우리는 월드 모델이라고 부릅니다. 여기서는 비디오로부터 학습된 액션 조건부 결합 예측 월드 모델(JEPA-WMs)에 집중합니다. JEPA-WM은 제안된 결합 예측 아키텍처(JEPAs)에서 계획 문제를 해결하는데, 여기서 데이터의 표현은 인코더/예측기 쌍을 학습하여 어떤 데이터 샘플의 한 시각의 임베딩이 두 번째 시각의 임베딩을 잘 예측하도록 합니다. JEPA-WM이라는 용어는 [eq:frame-teacher-forcing-loss,eq:plan_objective,eq:Ftheta_unroll_1,eq:Ftheta_unroll_2]에서 통합 구현 레시피로 정식화된 방법론 집단을 지칭합니다. 실제로 우리는 이론적 보장 없이 액션 시퀀스를 최적화하여 더 나아가 트레일러지 옵티마이제이션에 가깝지만, 일반적으로 사용되는 용어인 계획에 머물렀습니다.
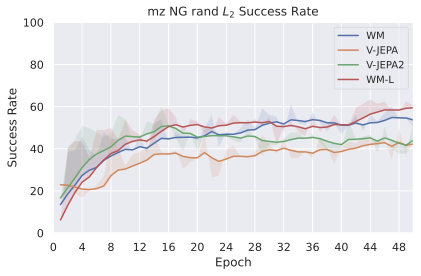
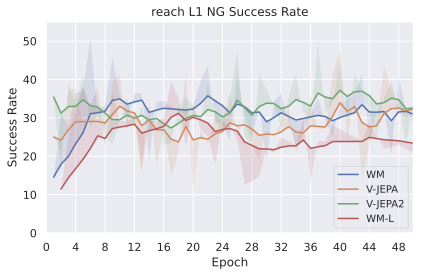
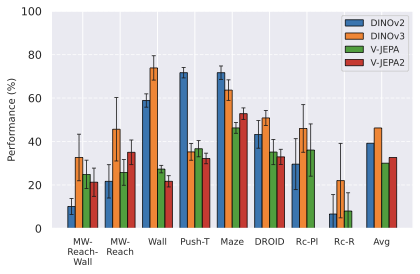
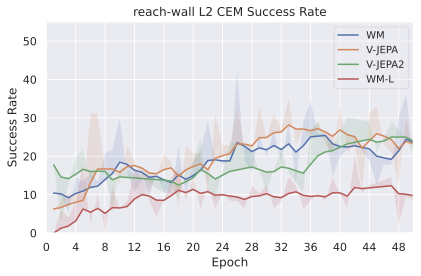
JEPA-WMs 중 PLDM은 잠재 공간에서 학습된 월드 모델이 다른 목표 조건 강화 학습(GCRL) 방법보다 더 좋은 일반성을 제공하며 특히 서브최적 훈련 트래젝토리에서 더욱 그렇습니다. DINO-WM은 보상 없이 잠재 월드 모델을 비교했을 때, 동결된 DINOv2 인코더로 학습된 JEPA 모델이 DreamerV3와 TD-MPC2보다 우수합니다. DINO-World은 DINOv2 위에서 학습된 JEPA-WM의 밀도 예측과 직관적 물리학 능력이 COSMOS를 능가함을 보여줍니다. V-JEPA-2-AC 모델은 Octo와 같은 비전 언어 액션(VLA) 베이스라인보다 이미지 하위 목표를 사용한 객체 조작에서 굶주린 계획에 이기고 있습니다.
본 논문에서는 DINO-WM과 V-JEPA-2-AC처럼 표현(인코더)보다 동적 모델(예측기) 학습에 초점을 맞추었습니다. 이러한 모델의 중요성이 증가함에 따라, 우리는 문헌에서 보완되지 않은 부분을 채우려고 시도합니다: 임베딩 공간에서 사전 훈련된 시각 인코더를 사용하여 조작 및 탐색 계획 작업을 효율적으로 학습하는 방법?
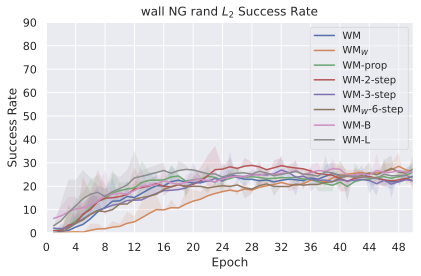
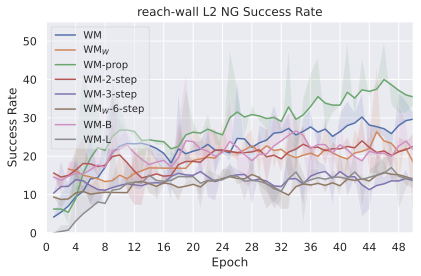
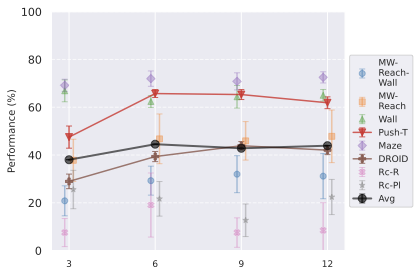
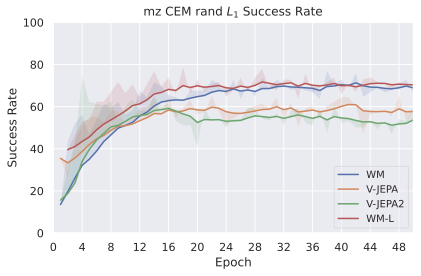
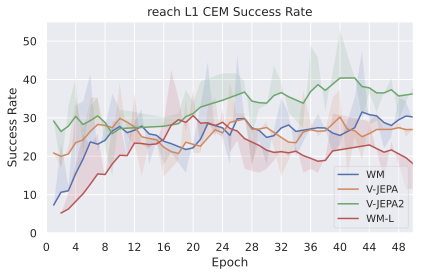
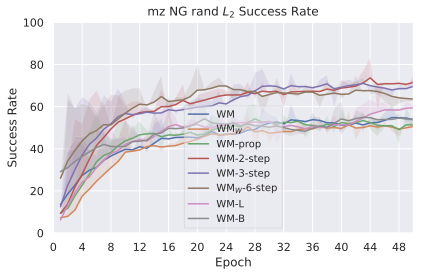
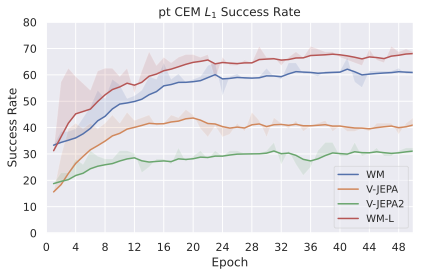
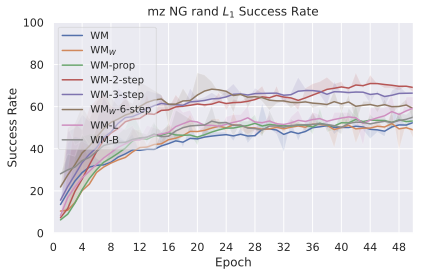
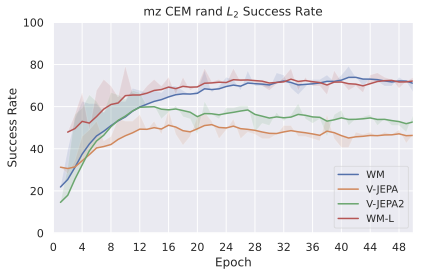
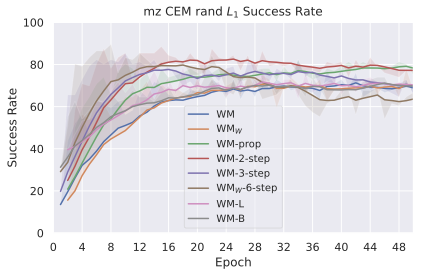
저희 기여는 다음과 같습니다: (i) JEPA-WM의 학습과 계획에 대한 여러 중요한 구성 요소인 다단계 롤아웃, 예측기 아키텍처, 훈련 컨텍스트 길이, 본능 인식 사용 여부, 인코더 유형, 모델 크기, 데이터 증강 및 계획 최적화자를 연구합니다. (ii) 이러한 통찰을 통해 JEPA-WM 클래스에서 DINO-WM과 V-JEPA-2-AC보다 우수한 최적의 모델을 제안합니다.
/>
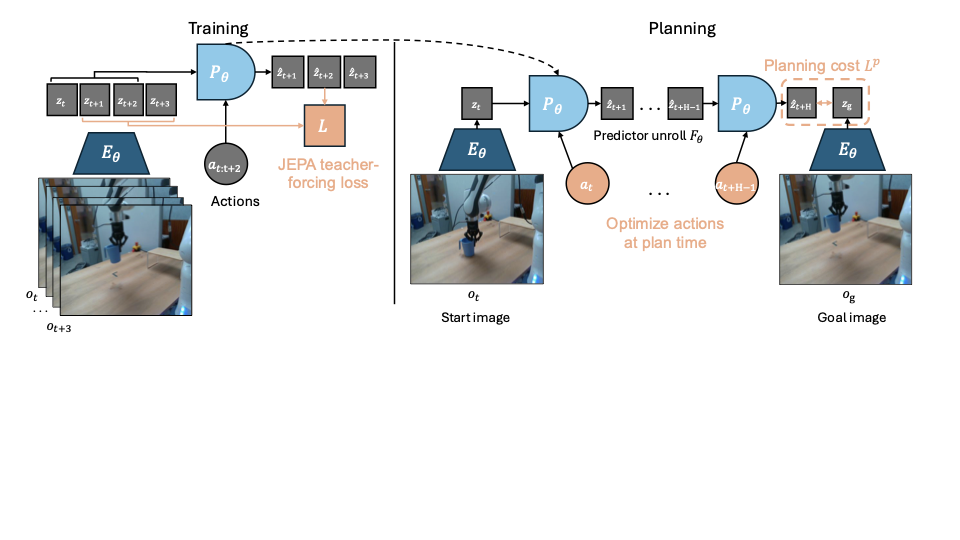
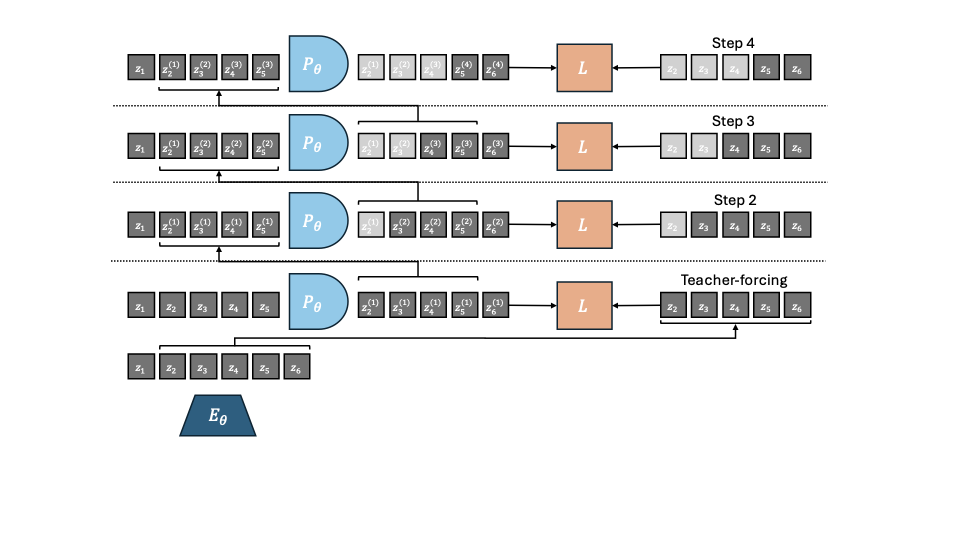
왼쪽: JEPA-WM 학습: 인코더 $`E_{\phi,\theta}`$는 비디오와 선택적으로 본능적 관찰을 임베딩하고 이를 예측기 $`P_\theta`$에 피드합니다. 액션과 함께 시간 단계 간 병렬로 다음 상태 임베딩을 예측합니다. 오른쪽: JEPA-WM 계획: 액션 시퀀스를 샘플링하고, 이를 롤아웃하여 각 트래일러지에 대한 계획 비용 $`L^p`$를 계산한 후 이 비용을 사용하여 액션 샘플링을 반복적으로 정제합니다. 액션 인코더와 본능적 인코더는 가독성을 위해 이 그림에서 명시적으로 표시되지 않습니다.
관련 연구
월드 모델링과 계획.
‘인공 지능으로의 길’에서는 모델 예측 제어(MPC)를 자율 기계 인텔리전스(AMI)의 핵심 구성 요소로 제시합니다. 자기 주도 학습(SSL)을 통해 학습된 월드 모델은 정보 획득 추정이나 호기심을 사용하여 탐색을 관리하거나 희귀 데이터를 가진 로봇 작업으로 전환하는 데, 샘플 효율성을 개선하는 강화 학습 연구에서 많이 사용되었습니다. 또한 월드 모델은 플래닝에 사용되어 목표 도달을 위한 하위 목표를 찾거나 보지 못한 환경에서 목표를 상상합니다. 월드 모델은 생성적일 수 있으며, 잠재 공간에서 JEPA 손실을 사용하여 학습할 수도 있습니다. 이들은 잠재 공간에서 계획에 사용될 수 있으며, 할인된 보상의 합을 최대화하거나 정책을 학습하는 데 사용됩니다. 잠재 공간 계획의 다른 접근법에는 로컬-선형 동적 모델, 기울기 기반 트레일러지 옵티마이제이션 및 확산 기반 계획자가 있습니다. 이러한 방법들은 JEPA-WMs와 동적 모델 클래스, 최적화 전략 또는 훈련 가정에서 차이가 있으며, 자세한 비교는 7절을 참조하세요.
목표 조건 강화 학습(GCRL).
목표 조건 강화 학습은 비보상 데이터에 대한 대규모 사전 훈련을 활용하는 자기 주도 접근법입니다. LEAP와 HOCGRL과 같은 기초 방법들은 RL로 학습된 목표 조건 정책이 계획에 통합될 수 있음을 보여줍니다. PTP는 하위 목표 생성기를 사용하여 목표 도달 문제를 계층적으로 분해합니다. FLAP은 오프라인 강화 학습을 통해 목표 조건 정책을 획득하며, 서브-목표에 따라 온라인 미세 조정이 가능합니다. RE-CON은 거리와 액션의 잠재 변수 모델과 이미지의 비파라미트릭 토폴로지 메모리를 학습합니다. IQL-TD-MPC는 TD-MPC에 은닉 Q-학습(IQL)을 확장하며, HIQL은 오프라인 데이터에서 목표 조건 강화 학습을 위한 계층적 모델 없는 접근법을 제안합니다.
로봇 공학.
로봇 문제의 전통적인 접근 방식은 분석적 물리 모델과 센서를 활용한 MPC 루프에 의존하며, MIT 인간형 로봇이나 BiconMP와 같이 자주 재계획됩니다. 외부 인식을 위해서는 환경 상태를 감지하기 위해 카메라를 사용합니다. 현재 조작의 최첨단은 비전-언어-액션(VLA) 모델인 RT-X, RT-1 및 RT-2에 의해 달성되었습니다. LAPA는 로봇 동작 없이 로봇 트래젝토리에 의존하여 VQ-VAE 목표를 사용해 이산 잠재 액션을 학습합니다. 물리 지능의 첫 번째 모델 $`\pi_0`$은 Open-X 표현 데이터셋 및 플로우 매칭을 활용하여 동작 트래젝토리를 생성합니다.
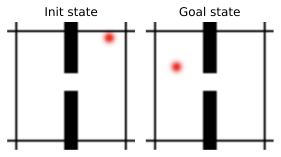
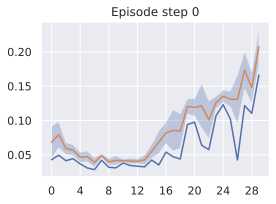
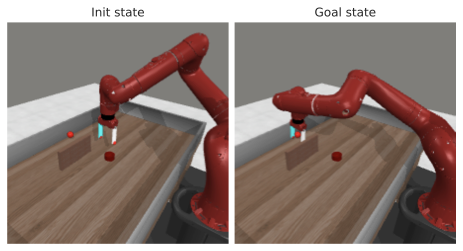
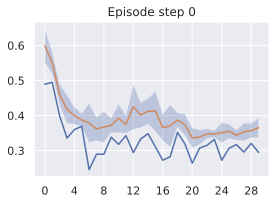
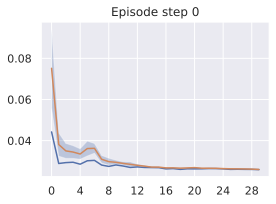
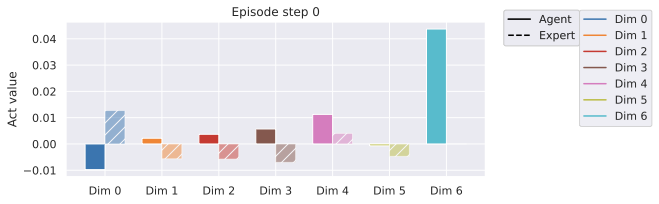
다른 방법들을 대안적인 Franka 아ーム 잔치대 잡기 작업에 대해 비교한 결과입니다. 여기서 두 개의 액션 "열고 위로 이동"과 "닫고 위로 이동"을 하드코딩했습니다. 각각은 오픈 루프 롤아웃에서 5개의 모델 액션을 보여줍니다. 왼쪽: "열고 위로 이동" 액션. 오른쪽: "닫고 위로 이동". 첫 번째 줄: V-JEPA-2-AC, 두 번째 줄: DINO-WM, 세 번째 줄: 5.3절에서 설명한 최적 모델.
배경
이 섹션은 사전 훈련된 시각 인코더로부터 학습된 JEPA-WMs의 공통 설정을 정식화합니다만, 새로운 방법론을 소개하지는 않습니다. JEPA-WM의 학습과 계획에 대한 요약은 1도표를 참조하세요.
학습 메소드.
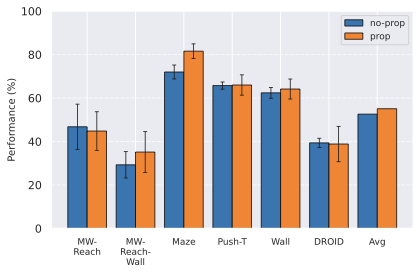
JEPA-WM에서 우리는 동결된 시각 인코더 $`E_{\phi}^{vis}`$와 선택적 얕은 본능적 인코더 $`E_{\theta}^{prop}`$을 사용하여 관찰을 임베딩합니다. 각 인코더를 해당 모달성에 적용하면 전체 상태 인코더가 되며, 이를 $`E_{\phi,\theta}=(E_{\phi}^{vis}, E_{\theta}^{prop})`$로 표기합니다. 액션 인코더 $`A_{\theta}`$는 로봇의 동작을 임베딩합니다. 이 위에 예측기 $`P_{\theta}`$가 상태와 액션 임베딩을 입력으로 받습니다. $`E_{\theta}^{prop}`, A_{\theta}, P_{\theta}`$은 함께 훈련되며, $`E_{\phi}^{vis}`$는 동결됩니다. 과거 관찰 창 $`w`$에서의 관찰 $`o_{t-w:t}:= (o_{t-w}, \dots, o_{t})`$, 시각 및 선택적 본능적 입력과 과거 액션 $`a_{t-w:t}`$에 대해 배치의 $`B`$ 요소를 대상으로 하는 일반적인 학습 예측 목표는 다음과 같습니다:
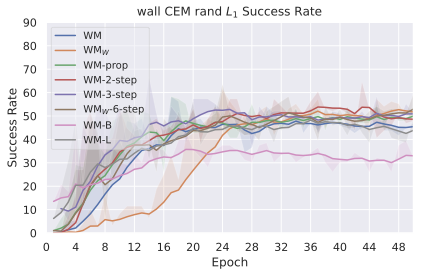
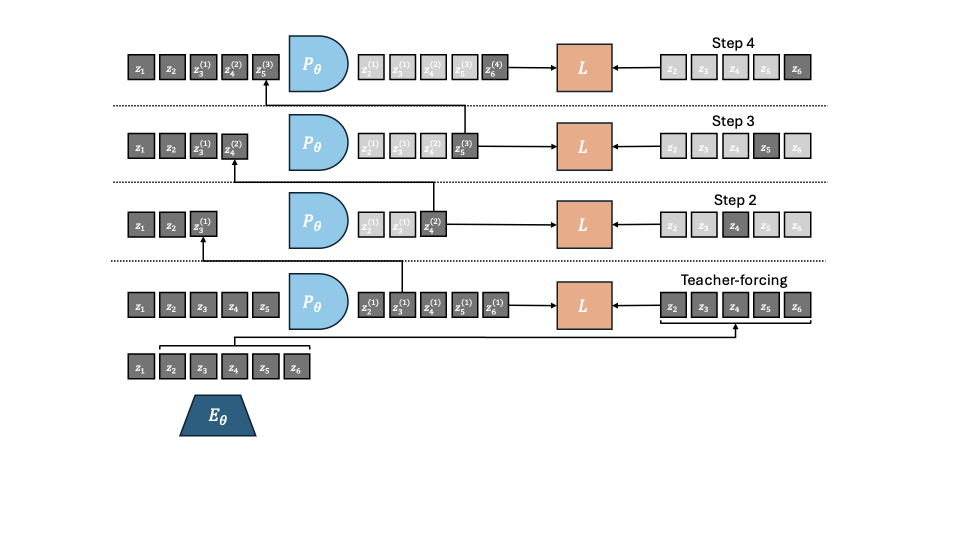
여기서 $`L`$은 시각 예측과 목표 사이, 본능적 예측과 목표 사이의 쌍별로 계산된 손실입니다. 실험에서는 MSE를 선택했습니다. 이 연구에서 사용한 인코더와 예측기 아키텍처는 ViT이며 기본 모델에서도 동일합니다. DINO-WM에서 액션 및 본능적 인코더는 단순히 선형 계층으로, 그 출력은 시각 인코더의 출력에 임베딩 차원을 따라 연결됩니다. 이는 특징 조건부라고 알려져 있으며, 반면에 시퀀스 조건부는 액션과 본능적 정보를 토큰으로 인코딩하여 시각 토큰 시퀀스와 연결하는 방식입니다. V-JEPA-2에서 사용됩니다. 우리는 $`P_{\theta}`$가 프레임 인과적 주의 마스크로 학습되므로, $`w=0`$부터 $`w=W-1`$까지 모든 컨텍스트 길이에 대해 동시에 예측하도록 학습한다고 강조합니다. 여기서 $`W`$는 훈련 하이퍼파라미터로 설정되어 $`W=3`$입니다. 인과적 예측기는 하나의 동작 대신 여러 개의 동작 결과를 예측하도록 학습됩니다. 이를 위해, DINO-WM에서와 같이 프레임스킵을 사용하여 $`f`$ 관찰을 건너뛰고 해당 액션을 결합하여 차원이 $`f \times A`$인 더 높은 차원의 액션을 형성할 수 있습니다. 훈련 절차에 대한 자세한 내용은 8절을 참조하세요.
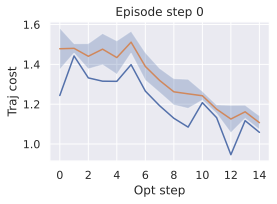
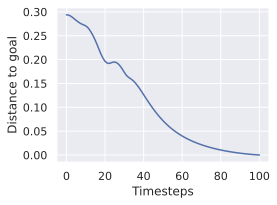
계획.
시평면 $`H`$에서 계획은 행동 공간의 곱집합 $`\mathbb{R}^{H \times A}`$ 위의 최적화 문제입니다. 각 액션은 차원 $`A`$, 훈련 시 프레임스킵을 사용할 때는 $`f \times A`$로 취합니다. 초기 및 목표 관찰 쌍 $`o_t, o_g`$가 주어졌을 때, 각 행동 트래일러지 $`a_{t:t+H-1} := (a_{t}, \dots, a_{t+H-1})`$는 계획 목표 $`L^p`$로 평가됩니다. 학습 시와 마찬가지로, 두 시각 임베딩 사이의 거리 $`L_{vis}`$, 본능적 임베딩 사이의 거리 $`L_{prop}`$을 측정하는 거리 메트릭 $`L`$(예: $`L_1`, L_2`$ 거리 또는 코사인 유사성의 음수)을 사용합니다. 시각 및 본능적 입력이 모두 있는 모델로 계획할 때, $`\alpha \geq 0`$, 최소화하려는 계획 목표 $`L^p_\alpha`$는 다음과 같습니다:
여기서 $`G_{\phi,\theta}`$는 우리의 월드 모델에 종속된 함수입니다. 우리는 예측기를 행동에서 시작하여 최대 컨텍스트 길이가 $`w`$(고정값 $`W^p`$, 6절 참조)인 $`z_t=E_{\phi,\theta}(o_t)`$에서 재귀적으로 $`F_{\phi,\theta}`$를 정의합니다.
우리의 경우 $`G_{\phi,\theta}`$를 예측기 롤아웃 함수 $`F_{\phi,\theta}`$로 취하며, 중간 롤아웃 단계들에 대한 함수가 아닌 마지막 단계만 사용할 수 있습니다. 계획 최적화자에 대한 자세한 내용은 10절을 참조하세요.
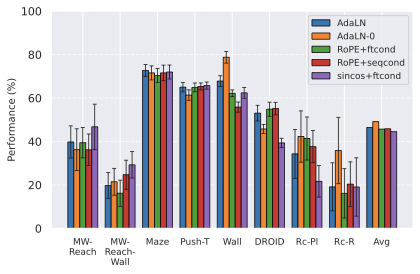
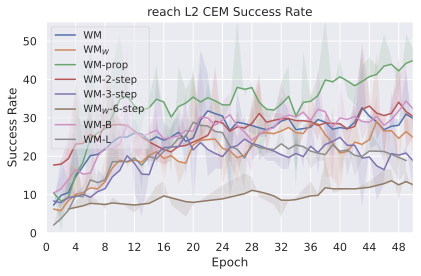
연구된 설계 선택
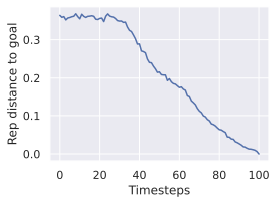
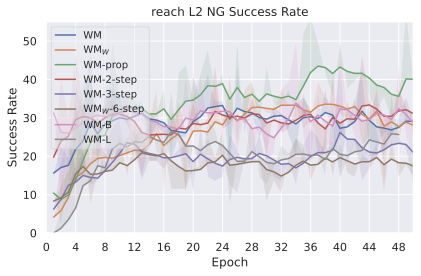
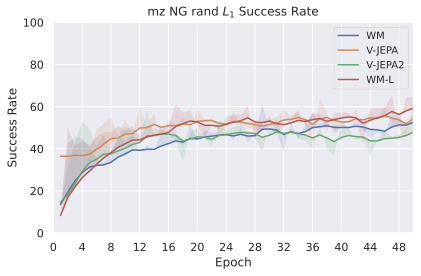
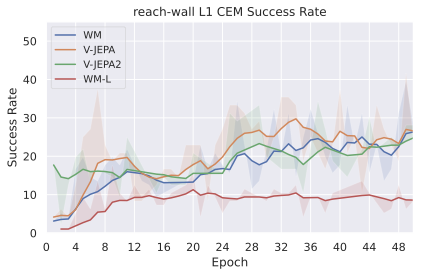
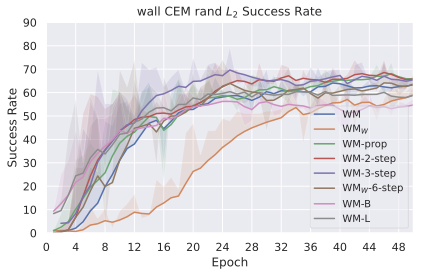
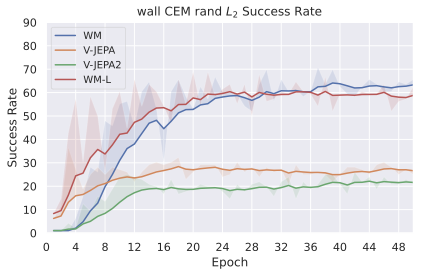
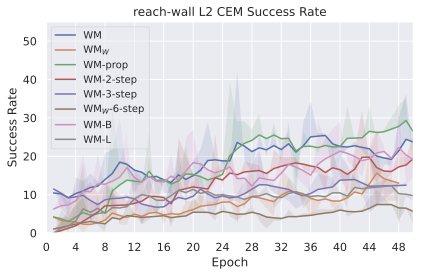
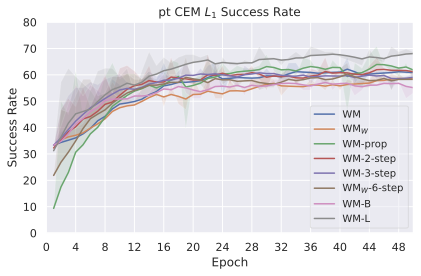
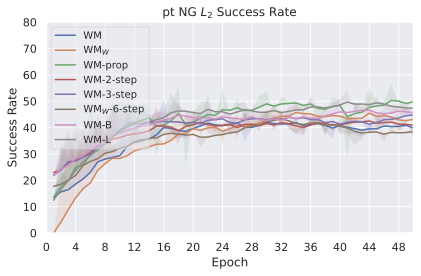
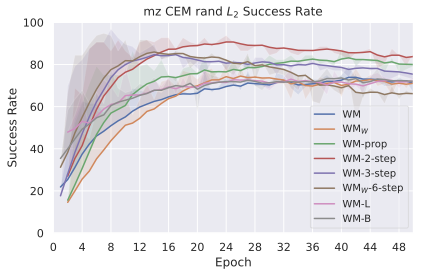
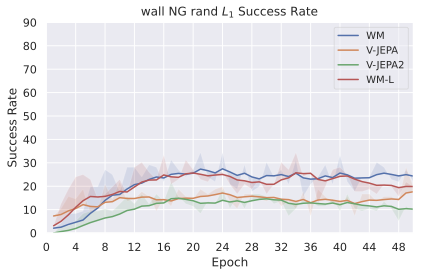
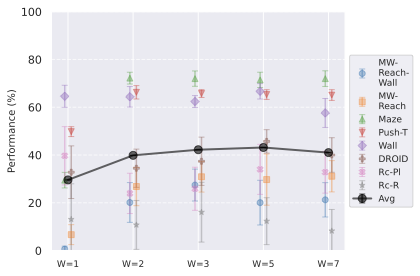
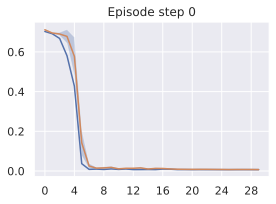
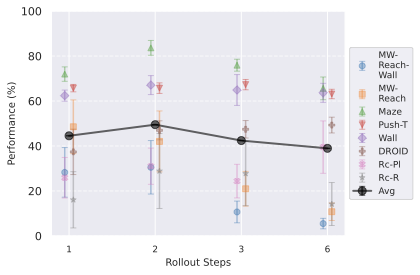
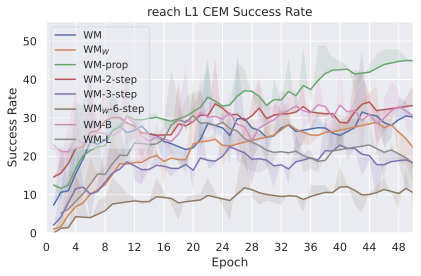
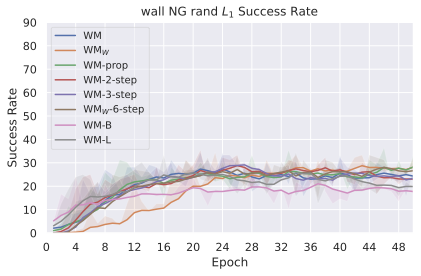
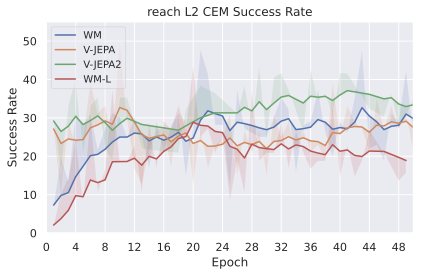
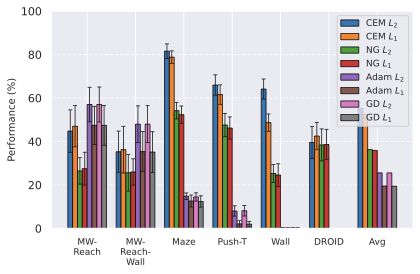
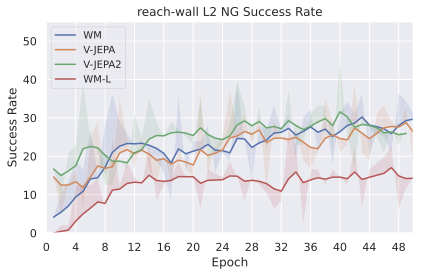
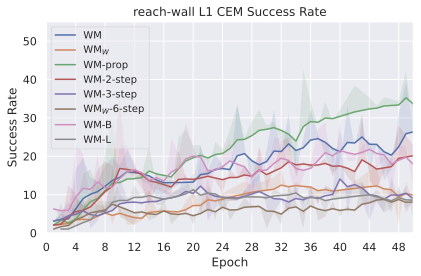
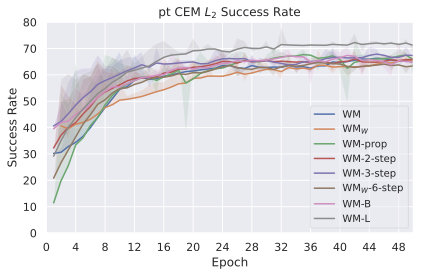
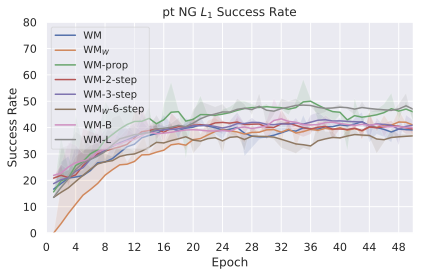
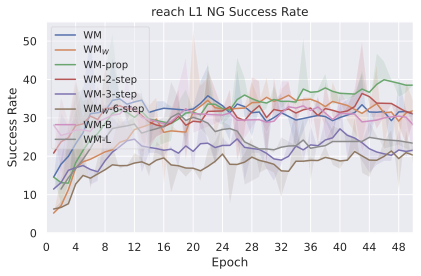
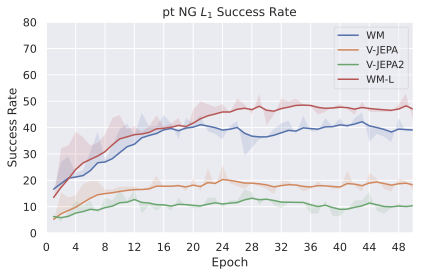
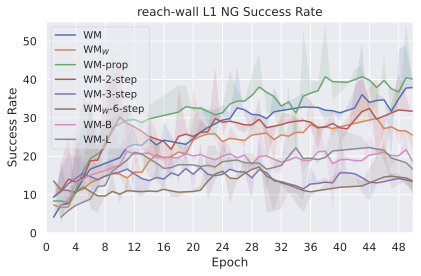
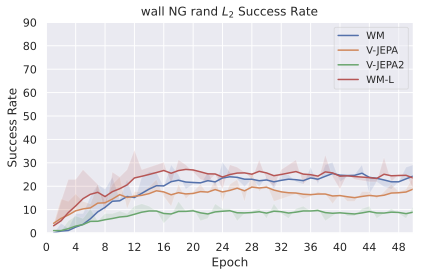
우리의 기본 구성은 본능 인식이 없는 DINO-WM으로 ViT-S 인코더와 동일 임베딩 차원을 가진 깊이가 6인 예측기입니다. 우리는 영향 범위에 따라 설계 선택을 우선순위로 정합니다: 계획 시점의 선택은 모든 평가에 영향을 미치므로 먼저 이를 최적화하고 각 환경에 대해 가장 좋은 계획자를 고정한 다음 실험을 진행합니다. 훈련 및 아키텍처 선택이 그 뒤를 따르며, 확대 실험이 우리의 발견을 검증합니다. 각 구성 요소는 기본 구성에서 독립적으로 변화하여 그 효과를 격리합니다.
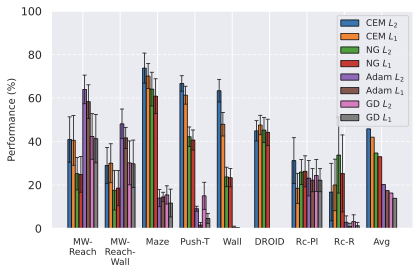
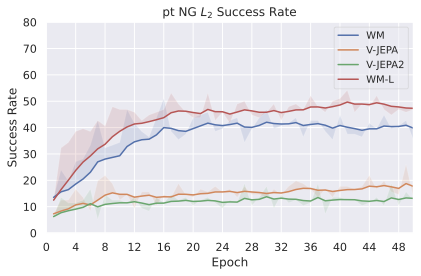
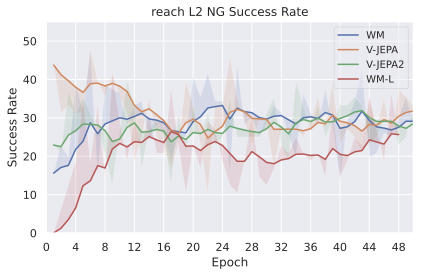
계획자.
다양한 최적화 알고리즘이 미분 가능한 문제인 방정식 [eq:plan_objective]을 최소화하는 데 관련될 수 있습니다. CEM(또는 MPPI라는 변형)이 10절에서 설명되어 있습니다. 이 방법은 비용 함수의 기울기에 의존하지 않는 인구 기반 최적화 방법이므로, NeverGrad에서 제공하는 모든 최적화 메소드를 활용할 수 있는 계획자를 도입합니다. 우리의 실험에서는 기본 NGOpt 최적화기인 [appendix: plan_opt]을 선택했습니다.