양자 포아송의 언어
📝 원문 정보
- Title: Path Integral Solution for Dissipative Generative Dynamics- ArXiv ID: 2601.00860
- 발행일: 2025-12-30
- 저자: Xidi Wang
📝 초록
본 논문은 언어 모델을 양자역학적 시스템으로 해석하는 방법을 제시합니다. 이를 통해 블랙박스로 간주되는 변형 모델의 동작 원리를 명확히 이해할 수 있습니다.💡 논문 해설
1. **기여 1**: 언어 생성이 양자역학적 시스템으로 해석될 수 있다는 것을 보였습니다. 이는 복잡한 언어 모델을 간단한 물리학 법칙으로 설명할 수 있는 길을 열었습니다. 2. **기여 2**: Koopman 연산자를 사용하여 비선형 동작을 선형화하는 방법을 제시했습니다. 이를 통해 언어 모델의 내부 작동 원리를 더 잘 이해하고 예측할 수 있습니다. 3. **기여 3**: 양자 시스템에서 중요한 개념인 경로 적분을 언어 생성에 적용하여, 토큰 간 정보 유동을 효과적으로 설명했습니다.간단한 설명:
- 초보자용: 이 논문은 복잡한 언어 모델을 이해하기 쉽게 하기 위해 물리학의 개념을 사용합니다. 이를 통해 언어 생성 과정을 더 잘 예측하고 이해할 수 있습니다.
- 중급자용: Koopman 연산자를 사용하여 비선형 동작을 선형화하는 방법은, 복잡한 모델의 내부 작동 원리를 명확히 파악하는 데 도움이 됩니다. 이는 토큰 간 정보 유동을 효과적으로 설명하기 위한 중요한 개념입니다.
- 고급자용: 본 논문에서는 언어 생성 과정을 양자역학적 시스템으로 해석하여, 복잡한 변형 모델의 동작 원리를 명확히 이해하고 예측할 수 있는 방법을 제시합니다. Koopman 연산자를 사용하여 비선형 동작을 선형화하고 경로 적분을 통해 토큰 간 정보 유동을 효과적으로 설명합니다.
📄 논문 발췌 (ArXiv Source)
현대 언어 모델(변형 모델과 그 변종)은 주의 메커니즘, 활성화 함수 및 정규화 계층을 포함하는 수십억 개의 매개변수로 구성된 고도로 비선형적인 신경망 구조를 통해 놀라운 성능을 발휘합니다. 이러한 시스템은 블랙박스로 작동하며, 내부 동작이 불투명하고 예측이 학습된 변환의 미묘한 조합에서 발생하여 물리적 통찰력을 추출하는 것은 매우 어렵습니다. 특정 출력이 생성되는 이유나 정보가 계층을 통해 어떻게 흐르는지 이해하려면 시스템 외부를 탐사하는 후속 분석 도구가 필요합니다.
양자역학적 시스템은 이와 대조됩니다. 스펙트럼 분해를 통해 해밀토니안이 고유값과 고유함수로 분리되며, 시스템의 기본 주파수와 정상 모드를 나타냅니다. 시간 진전이 투명하게 보입니다. 각 고유모드는 그 특성 주파수에서 진동하고, 내재적인 비율로 감쇠하거나 증가합니다. 전체 동적 현상은 이 독립된 모드들의 중첩으로 나타납니다. 스펙트럼을 검사함으로써 안정성, 공명, 감쇠 시간 척도 및 장기 행동이 직접적으로 추론됩니다. 고유 함수는 상태 공간에 대한 완전한 기저를 제공하여 엄격한 수학적 분석과 직접적인 물리적 해석이 가능합니다. 시스템의 진전을 실제로 보는 것은 어떤 모드가 활성화되고 어떻게 간섭하는지를 검사하는 것으로 충분합니다.
본 연구에서는 비선형 변환기에서 유래된 언어 생성이 정확한 스펙트럼 분석이 가능한 완벽하게 해결 가능한 양자 시스템으로 체계적으로 전달될 수 있음을 보여줍니다. 우리는 블랙박스 신경망을 고차원 양자 상태에 작용하는 선형 Koopman 연산자로 변환하는 진행적 학습 프레임워크를 개발합니다. 이 경우 스펙트럼 분해는 언어 진화의 기본 모드를 밝혀냅니다.
물리학적으로 영감을 받은 신경망 아키텍처는 닫힌 물리 시스템이 기계 학습에 유익하게 적용되는 보존 법칙, 대칭성 및 해밀토니안 구조를 학습 시스템에 부과하려고 합니다. 그러나 우리는 언어 생성에 대한 이 가정을 도전합니다.
우리의 주요 결과는 언어 모델링을 *양자 순차 필드(QSF)*로 정립한다는 것입니다: 공간 좌표가 $`d`$-차원 임베딩 공간이고, 시간 좌표가 이산 토큰 시퀀스이며, 진전이 순차적으로 업데이트되는 선형 연산자에 의해 통제되는 감쇠 양자 시스템입니다. QSF 프레임워크는 구조적인 상수로 구성됩니다. 각 토큰 간격 내에서 생성기 $`G_t`$가 일정함(정확한 경로 적분 평가 가능)이고, 토큰 경계에서는 매개변수가 컨텍스트 확장 및 정보 주입을 반영하여 이산적으로 점프합니다. 이러한 순차적 업데이트 구조는 정확한 해 가능성과 컨텍스트 종속적인 생성을 유지하면서 아키텍처의 불투명성을 수학적 투명성으로 대체하는 데 필수적입니다: 고유 함수 분석, 연산자 분해 및 경로 적분 방법.
언어는 근본적으로 역가능성이 있습니다. 토큰 $`w_t`$를 생성함으로써 미래의 가능성은 조건부 확률 $`P(w_{t+1}|w_{\leq t})`$을 통해 제약받으며, 이 정보 유동은 되돌릴 수 없습니다. 효과적인 언어 모델링에는 통제된 정보 소멸이 필요합니다: 무관한 세부 사항을 잊으면서 중요한 특징을 증폭하는 것입니다. 이러한 속성은 에너지를 보존하는 해밀토니안 역학과 직접적으로 충돌하며, 시간 반전 가능성을 유지합니다 $`U^{-1} = U^\dagger`$. 양자역학이 언어 생성을 모델링할 수 있는가? 우리는 이 질문에 대한 답변이 ‘예’라는 것을 증명하지만, 단지 비단위 진전을 통제하는 감쇠 양자 시스템에서 가능하다는 것입니다.
이론적 프레임워크
언어의 양자 역학
오토리거시브 언어 생성을 고려하면 이산 시간 진전 $`\psi_t \in \mathbb{C}^d`$에서 $`\psi_t`$는 토큰 위치 $`t`$에서 숨겨진 상태를 나타내고, $`d`$는 임베딩 차원입니다. 이를 양자-언어적 매핑으로 정의하여 (1+1)차원 양자 필드 구조를 설정합니다:
-
공간 좌표(1차원): 이산 토큰 사전 공간, $`V`$ 가능한 구성(토큰). 각 토큰은 이 1차원 구성 공간의 독특한 위치를 나타냅니다.
-
시간 좌표(1차원): 토큰 시퀀스 위치 $`t = 0, 1, 2, \ldots, N`$이 이산 시간 진전을 제공합니다.
-
내부 힐베르트 공간($`d`$ 차원): 각 토큰 위치에서 양자 상태는 $`\psi_t \in \mathbb{C}^d`$, 여기서 $`d`$는 추가적인 공간 좌표가 아닌 내부 자유도를 나타내는 임베딩 차원입니다.
-
진전 연산자: 위치에 따라 선형 변환 $`\psi_{t+1} = U_t\psi_t + b_t`$이 내부 힐베르트 공간을 자기 자신으로 맵핑합니다: $`U_t: \mathbb{C}^d \to \mathbb{C}^d`$.
이는 언어를 (1+1)D 양자 필드 이론으로 설정합니다. 모델의 $`L`$ 계층 아키텍처는 연속 시간을 통과하여 $`d`$차원 양자 상태를 전파하는 선형 연산자의 사슬을 구현합니다.
Koopman 프레임워크를 통한 감쇠 역학
Koopman 연산자 형식은 비선형 역학을 선형화합니다:
\begin{equation}
\psi_{t+1} = F(\psi_t)
\end{equation}관측 가능한 $`\mathcal{K}`$에 대한 연산자를 lifing하여 다음과 같이 표현됩니다:
\begin{equation}
(\mathcal{K}g)(\psi) = g(F(\psi)).
\end{equation}실용적인 구현을 위해 유한 행렬 $`\mathcal{K} \in \mathbb{C}^{d \times d}`$로 근사합니다.
해밀토니안-감쇠 분해: 각 생성기 $`G \in \mathbb{C}^{d \times d}`$는 유일하게 다음과 같이 인수분해됩니다:
\begin{equation}
G = -iH + \Gamma,
\end{equation}여기서 $`H = H^\dagger`$는 고유 진동을 통제하는 헤르미트이고, $`\Gamma = \Gamma^\top \in \mathbb{R}^{d \times d}`$는 실수 대칭으로 소실을 통제합니다.
연산자 $`\mathcal{K} = e^G`$의 고유값 구조는 $`\lambda_i = e^{-i\omega_i + \gamma_i}`, $|\lambda_i| = e^{\gamma_i}$, 여기서 $\omega_i$는 $H$의 고유값(진동 주파수)이고, $\gamma_i$는 $\Gamma$의 고유값(성장/감쇠율)입니다. 해밀토니안 $H$는 $|\lambda_i| = 1$, 즉 모든 $i$에 대해 $\gamma_i = 0$일 때 단위 진전을 통제합니다. 반면, 언어 생성은 $\gamma_i \neq 0$인 감쇠 역학이 필요합니다: 감쇠 모드 $\gamma_i < 0$는 정보를 잊게 하고, 성장 모드 $\gamma_i > 0$는 증폭을 가능하게 하며, 중립 모드 $\gamma_i = 0$는 정보를 보존합니다. 이 구조는 열린 양자 시스템을 통제하는 Lindblad 마스터 방정식과 유사하며, 소실자는 $\Gamma$가 탈상태화, 감쇠 및 환경 결합을 설명합니다.
선형 주의를 통한 컨텍스트 종속적 진전
언어 생성은 비지역 상호 작용을 필요로 합니다: 위치 $`t`$에서 다음 토큰 예측이 모든 이전 위치 $`0, 1, \ldots, t - 1`$의 정보를 반영해야 합니다. 물리학적으로 이를 캐스터드 상호 작용으로 설명할 수 있으며, 인과 광원 구조를 존중합니다. 위치 $`t`$는 오직 그 인과 과거만 “볼” 수 있습니다.
주의 메커니즘: 주의는 이 비지역 집계를 쿼리-키-값 패러다임을 통해 구현합니다. 위치 $`t`$에서 숨겨진 상태 $`\psi_t`$는 다음과 같이 생성됩니다:
\begin{align}
\text{쿼리:} \quad q_t &= W_Q\psi_t, \\
\text{키:} \quad k_s &= W_K\psi_s \quad (s \leq t), \\
\text{값:} \quad v_s &= W_V\psi_s \quad (s \leq t),
\end{align}여기서 $`W_Q, W_K, W_V \in \mathbb{R}^{d \times d}`$는 학습된 투영 행렬입니다. 이들은 학습 중에 결정되고 생성 동안 일정합니다.
선형 주의: 정확한 해 가능성과 컨텍스트 집계를 유지하면서 선형 주의를 사용합니다:
\begin{equation}
\text{LinearAttention}(Q, K, V) = \phi(Q)\left(\phi(K)^\top V\right),
\end{equation}여기서 $`\phi : \mathbb{R}^d \to \mathbb{R}^d`$는 원소별로 적용되는 기능 맵입니다. 위치 $`t`$에서 이 집계는 다음과 같이 수행됩니다:
\begin{equation}
\psi_{\text{target},t} = \sum_{s=0}^{t} w_{ts} \cdot v_s, \quad w_{ts} = \phi(q_t)^\top\phi(k_s),
\end{equation}여기서 $q_t = W_Q\psi_t, k_s = W_K\psi_s, v_s = W_V\psi_s.
아핀 기능 맵: 우리는 아핀 기능 맵 $`\phi(x) = x + c`$를 사용하여 표현력을 향상시키고 선형성을 유지합니다. 여기서 $`c \in \mathbb{R}^d`$는 학습된 상수 벡터입니다.
인과 구조: 선형 주의는 합계 제한을 통해 인과구조를 존중합니다: $`s \leq t`. 위치 $t$는 오직 그 인과 과거 $\{0, 1, \ldots, t\}$에서 정보를 집계하여 (1+1)D 필드 이론의 광원 제약을 구현합니다.
층 아키텍처: 모델은 $`L`$ 층으로 구성되며 각 층에는 전파기 $`U^{(\ell)} = \mathcal{K}^{(\ell)}`$가 있으며, 다음과 같이 조합됩니다:
\begin{equation}
\psi^{(L)} = \prod_{\ell=1}^{L} U^{(\ell)} \psi^{(0)}.
\end{equation}Koopman 연산자 $`\mathcal{K}^{(\ell)}`$는 위치에 따라 주의를 코딩하는 시간 변형 구조를 갖습니다.
가이드된 Feynman 경로 적분
표준 해밀토니안 경로 적분은 고유값을 단위 원 $`|\lambda| = 1`$으로 제한하는 가우스 측정을 사용합니다. 우리는 Fresnel 적분으로 일반화합니다: 복잡한 가우시안 측정이 소실 스펙트럼 $`|\lambda| \neq 1`$를 허용합니다. 우리는 편향 $`\beta \in \mathbb{C}^d`$가 있는 아핀 역학 $`d\psi/dt = G\psi + \beta`$로 확장합니다. 폐형 솔루션은 다음과 같습니다:
\begin{equation}
\psi(T) = e^{GT}\psi_0 + G^{-1}(e^{GT} - I)\beta.
\label{eq:affine_solution}
\end{equation}주의는 표준 Feynman 경로 적분을 수정하여 과거 숨겨진 상태를 집계하는 컨텍스트 종속적 타겟 상태 $`\psi_{\text{target},t}`$를 도입합니다. 가우시안 가중치로 경로 적분은 다음과 같이 가이드됩니다:
\begin{equation}
W[\psi] = \exp\left(-\frac{1}{2\sigma^2}\|\psi(T) - \psi_{\text{target},t}\|^2\right),
\end{equation}여기서 $`\sigma^2`$는 가이드 강도를 제어합니다. 이는 전파기를 $`K(\psi_1, \psi_0) = \mathcal{N}(\psi_1; \nu, \Lambda)`$로 생성하며, 공분산은 다음과 같습니다:
\begin{equation}
\Lambda^{-1} = \Sigma_T^{-1} + \frac{1}{\sigma^2}W_k^\top W_k,
\end{equation}평균은 다음과 같습니다:
\begin{equation}
\nu = \Lambda\left[\Sigma_T^{-1}\left(e^{GT}\psi_0 + G^{-1}(e^{GT} - I)\beta\right) + \frac{1}{\sigma^2}W_k^\top W_q\psi_0\right].
\end{equation}상세한 유도는 부록 자료 섹션 I에 제공됩니다.
구조적 상수 구조: 각 토큰 간격 내에서 매개변수 $`G_t`, ` `\beta_t`, ``\Sigma_{T,t}`$가 일정하여 정확한 경로 적분 평가 가능합니다. 토큰 경계에서 $`t \to t+1`$, 매개변수가 이산적으로 점프: 업데이트된 생성기 $`G_{t+1}`$은 추가된 새 토큰에 대한 주의를 포함하고, 모든 이전 위치 $`\{0, 1, \ldots, t\}`$의 기여를 전파자 구조로 통합합니다. 이러한 순차적 집계(토큰 내부에서 매끄러운 진전과 토큰 간 컨텍스트 확장)는 정확한 해 가능성과 인과 정보 유동을 유지하는 데 필수적입니다.
다중 토큰 전파
다중 토큰 생성은 위치별 전파자를 연결하고 누적된 편향을 사용합니다:
\begin{equation}
\psi_N = U_N U_{N-1} \cdots U_1 \psi_0 + \sum_{k=1}^{N} \left(\prod_{j=k+1}^{N} U_j\right) b_k,
\label{eq:multitoken}
\end{equation}여기서 $`U_t = e^{G_t T}`$는 위치 $`t`$에서의 전파자이고, $`b_k`$는 위치 $`k`$에서의 편향 벡터입니다. 이는 재귀적 계산 형태 $`\psi_{k+1} = U_{k+1}\psi_k + b_{k+1}`$를 가집니다. 편향 누적은 각 위치에서 정보 주입을 나타내며, 순수 선형 역학 $`\psi_N = U_{\text{total}}\psi_0`$는 $`\psi_0`$에 포함되지 않은 새로운 정보를 포착할 수 없습니다.
진행 학습
우리는 높은 비선형 변환 아키텍처를 정확하게 해결 가능한 선형 역학으로 체계적으로 전달하는 진행 학습 프레임워크를 개발합니다. 전략: 간단한 스펙트럼 방법에서 시작하여 복잡성을 점진적으로 추가하면서 수학적 구조를 유지하고, 최종적으로 폐형 전파자를 생성합니다.
단계 I: 인과 구조를 갖춘 스펙트럼 기반
우리는 인과 Fourier 아키텍처(FNetAR)로 초기화하여 오토리거시브 구조를 존중합니다:
\begin{equation}
\text{FNetAR}(X)_i = \text{Re}(\mathcal{F}_1(X_{1:i}))_i,
\end{equation}여기서 $`X_{1:i}`$는 위치 1부터 $`i`$까지의 인과 슬라이스를 나타내며, $`\mathcal{F}_1`$은 1차원 이산 푸리에 변환을 나타냅니다. 각 위치 $`i`$에서 사용 가능한 역사에 대해 푸리에 변환을 계산하고 구성 요소 $`i`$를 추출한 후 실수 부분을 취합니다. 이를 통해 정보는 앞으로만 전파됩니다.
각 층은 다음과 같이 구현합니다:
\begin{equation}
x^{(\ell)} = x^{(\ell-1)} + \text{FNetAR}(x^{(\ell-1)}) + \text{MLP}(x^{(\ell-1)}),
\end{equation}여기서 FNetAR은 계층 정규화(LayerNorm)를 포함하며(평균 0, 분산 1로 표준화하여 학습된 아핀 재스케일링), 이에 앞서 인과 푸리에 변환을 적용합니다. MLP는 비선형 피드포워드 맵 $`\text{MLP}(h) = W_2 \, \phi(W_1 h + b_1) + b_2`$이며, 여기서 $`W_1 \in \mathbb{R}^{4d \times d}`$, $`W_2 \in \mathbb{R}^{d \times 4d}`$, 활성화는 $`\phi(x) = \frac{x}{2}[1 + \text{erf}(x/\sqrt{2})]`$ (가우시안 오류 선형 단위, GELU), 모드 간 결합을 제공합니다. TinyStories에 대한 학습이 수렴할 때까지 진행하여 이후 단계의 구조적 초기화를 제공합니다.
단계 II: Koopman 연산자 학습
우리는 단계 I에서 임베딩 층과 출력 프로젝션을 초기화하며, Koopman 행렬 $`K^{(\ell)} \in \mathbb{C}^{d \times d}`$는 무작위로 초기화됩니다. 학습은 두 단계로 진행합니다. (1) 동결된 전이: 임베딩 $`(W_{\text{tok}}, W_{\text{pos}})`$, 최종 계층 정규화, 출력 프로젝션을 단계 I에서 전달하고 이 매개변수를 동결한 상태에서 Koopman 행렬 $`\{K^{(\ell)}\}`$만 초기 기간동안 학습합니다. (2) 공동 세밀 조정: 모든 매개변수를 해동하고 수렴할 때까지 공동으로 학습합니다.
각 층은 다음과 같이 적용됩니다:
\begin{align}
h^{(\ell)} &= \text{LayerNorm}(x^{(\ell-1)}), \\
k^{(\ell)} &= K^{(\ell)} h^{(\ell)}, \\
x^{(\ell)} &= x^{(\ell-1)} + k^{(\ell)} + \text{MLP}(h^{(\ell)}),
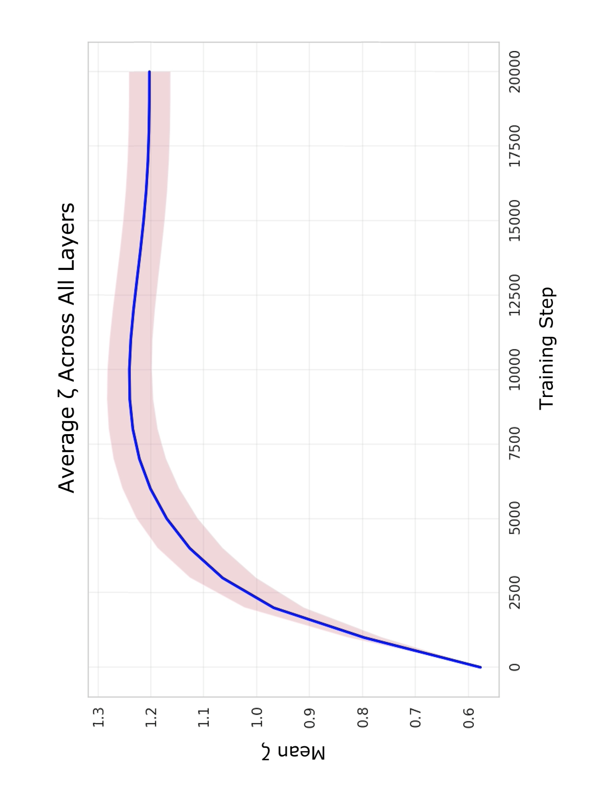
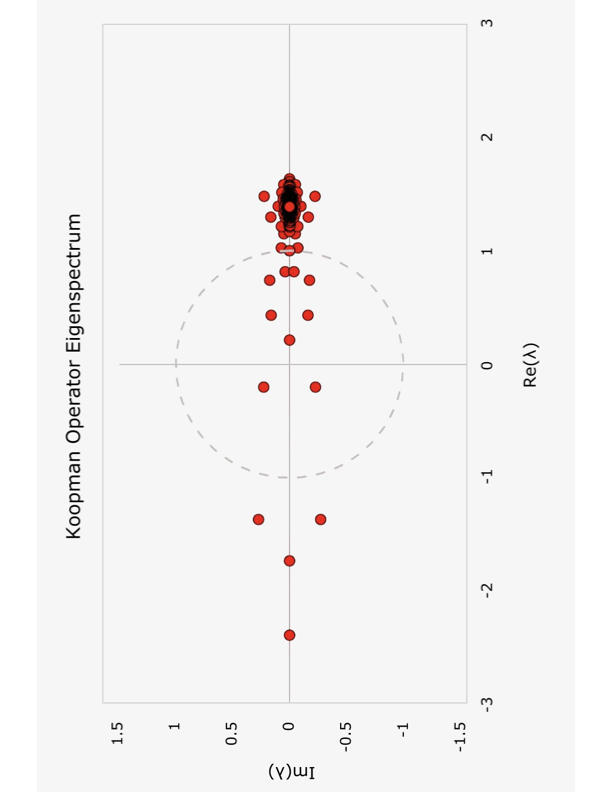
\end{align}여기서 정규화는 수치적 안정성을 제공하고, MLP는 학습 중 모드 간 결합을 가능하게 합니다. 학습 후 스펙트럼 분석은 고유분해 $`\mathcal{K}^{(\ell)} = V^{(\ell)}\Lambda^{(\ell)}(V^{(\ell)})^{-1}`$을 나타냅니다, 여기서 고유값의 절대 값은 일반적으로 0.1에서 2.0 사이를 범위로 합니다. 이는 비보존적 성질을 확인합니다. 그러나 단계 II Koopman 연산자만으로 검증 손실이 약 $`3.5`$이며, 단계 I의 손실 $`\approx 3.7`$보다 약간 좋지만 기준 변환기 손실 $`\approx 2.7`$에 비해 현저히 높습니다.
단계 III: Koopman + 선형 주의
📊 논문 시각자료 (Figures)