시간 그래프 어텐션과 계층적 융합을 활용한 UGV 혼잡 환경 내 내비게이션
📝 원문 정보
- Title: DRL-TH: Jointly Utilizing Temporal Graph Attention and Hierarchical Fusion for UGV Navigation in Crowded Environments
- ArXiv ID: 2512.24284
- 발행일: 2025-12-30
- 저자: Ruitong Li, Lin Zhang, Yuenan Zhao, Chengxin Liu, Ran Song, Wei Zhang
📝 초록 (Abstract)
딥 강화학습(DRL) 기반 방법은 혼잡한 환경에서 무인 지상 차량(UGV)의 자율 주행 및 장애물 회피에 큰 가능성을 보여왔다. 기존 대부분의 접근법은 단일 프레임 관측에 의존하고, 다중 모달리티 융합을 단순 연결 방식으로 수행해 시간적 맥락을 포착하지 못하고 동적 적응력이 제한된다. 이러한 문제를 해결하기 위해, 우리는 TG‑GAT(Temporal‑Guided Graph Attention Network)와 GHAM(Graph Hierarchical Abstraction Module)을 결합한 DRL‑TH 프레임워크를 제안한다. TG‑GAT는 시간 가중치를 어텐션 점수에 통합해 연속 프레임 간 상관관계를 학습함으로써 장면 변화의 암시적 추정을 가능하게 한다. GHAM은 계층적 풀링과 학습 가능한 가중치 융합을 적용해 RGB와 LiDAR 특징을 동적으로 통합하고, 다양한 스케일에서 균형 잡힌 표현을 제공한다. 광범위한 실험 결과, DRL‑TH는 다양한 혼잡 환경에서 기존 방법들을 능가하는 성능을 보였으며, 실제 UGV에 적용한 제어 정책 역시 현실 세계 시나리오에서 우수한 주행 능력을 입증하였다.💡 논문 핵심 해설 (Deep Analysis)
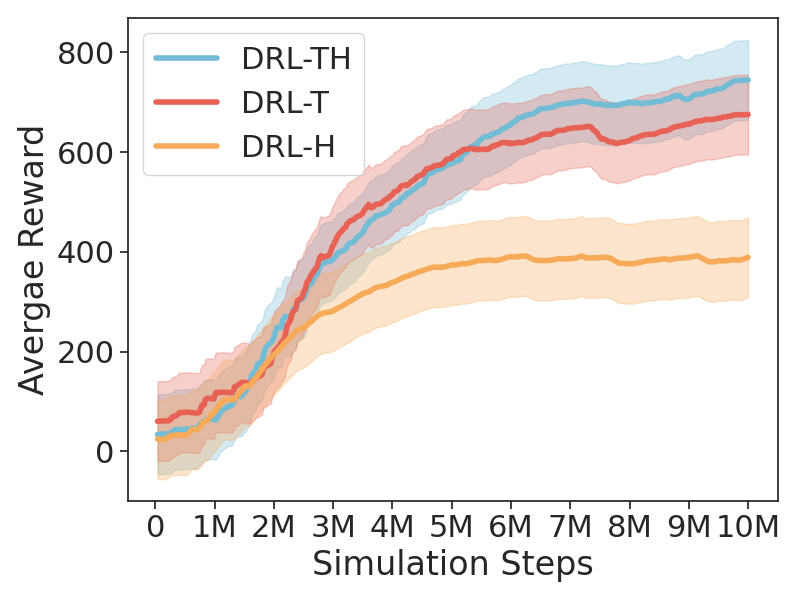
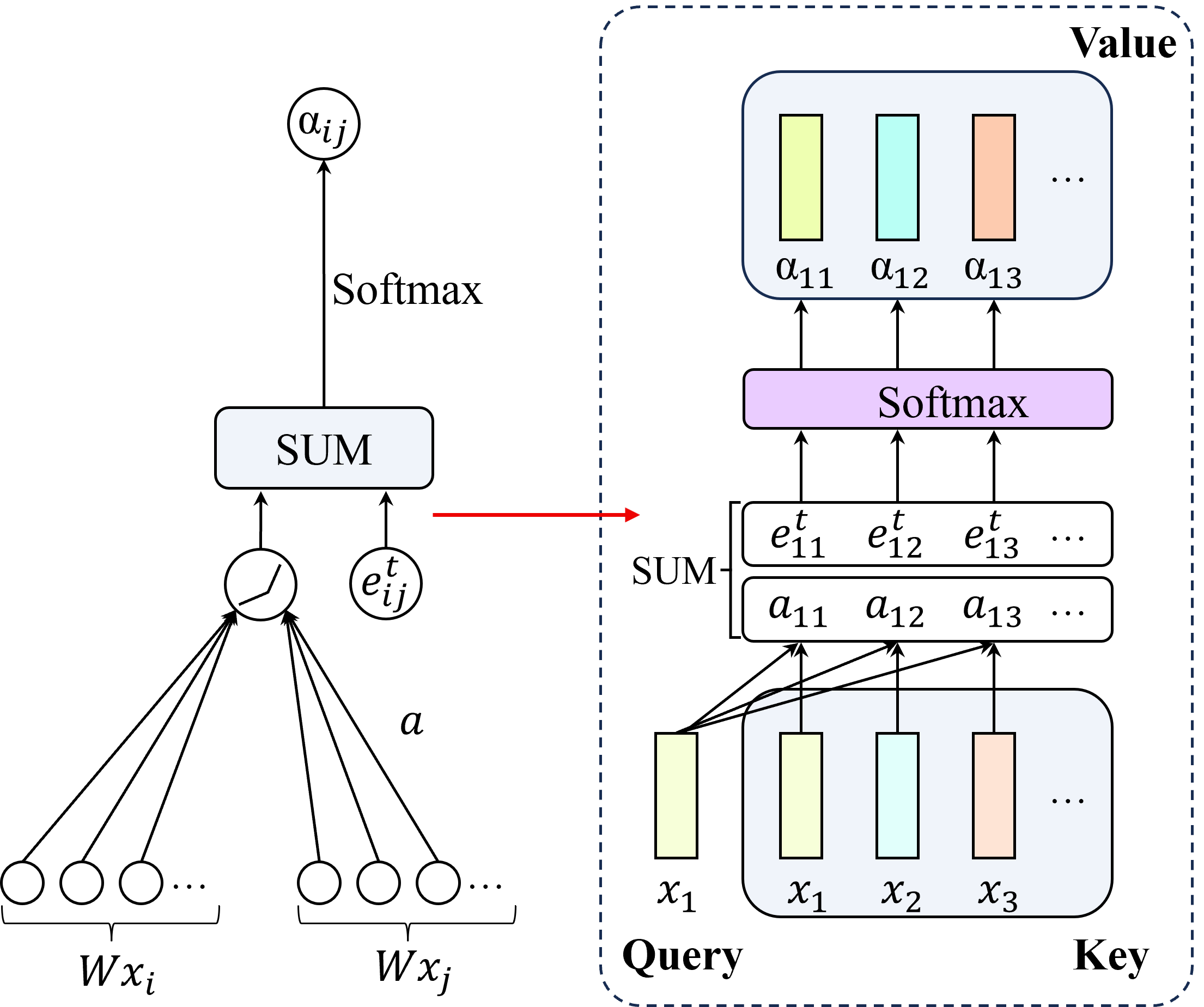
DRL‑TH는 이러한 한계를 극복하기 위해 두 개의 그래프 기반 모듈을 도입한다. 첫 번째인 TG‑GAT는 각 프레임을 그래프 노드로 변환하고, 노드 간 어텐션을 계산할 때 시간 가중치 τ를 곱함으로써 “시간‑공간 어텐션”을 구현한다. 구체적으로, 시간 차이가 클수록 가중치가 감소하도록 설계된 함수 f(Δt)=exp(−λΔt) 를 사용해, 최근 프레임의 정보가 더 크게 반영되면서도 과거 정보가 완전히 사라지지 않도록 한다. 이 메커니즘은 장면의 동적 변화를 암시적으로 추정하게 하여, 움직이는 보행자나 이동 장애물의 미래 위치를 예측하는 효과를 제공한다.
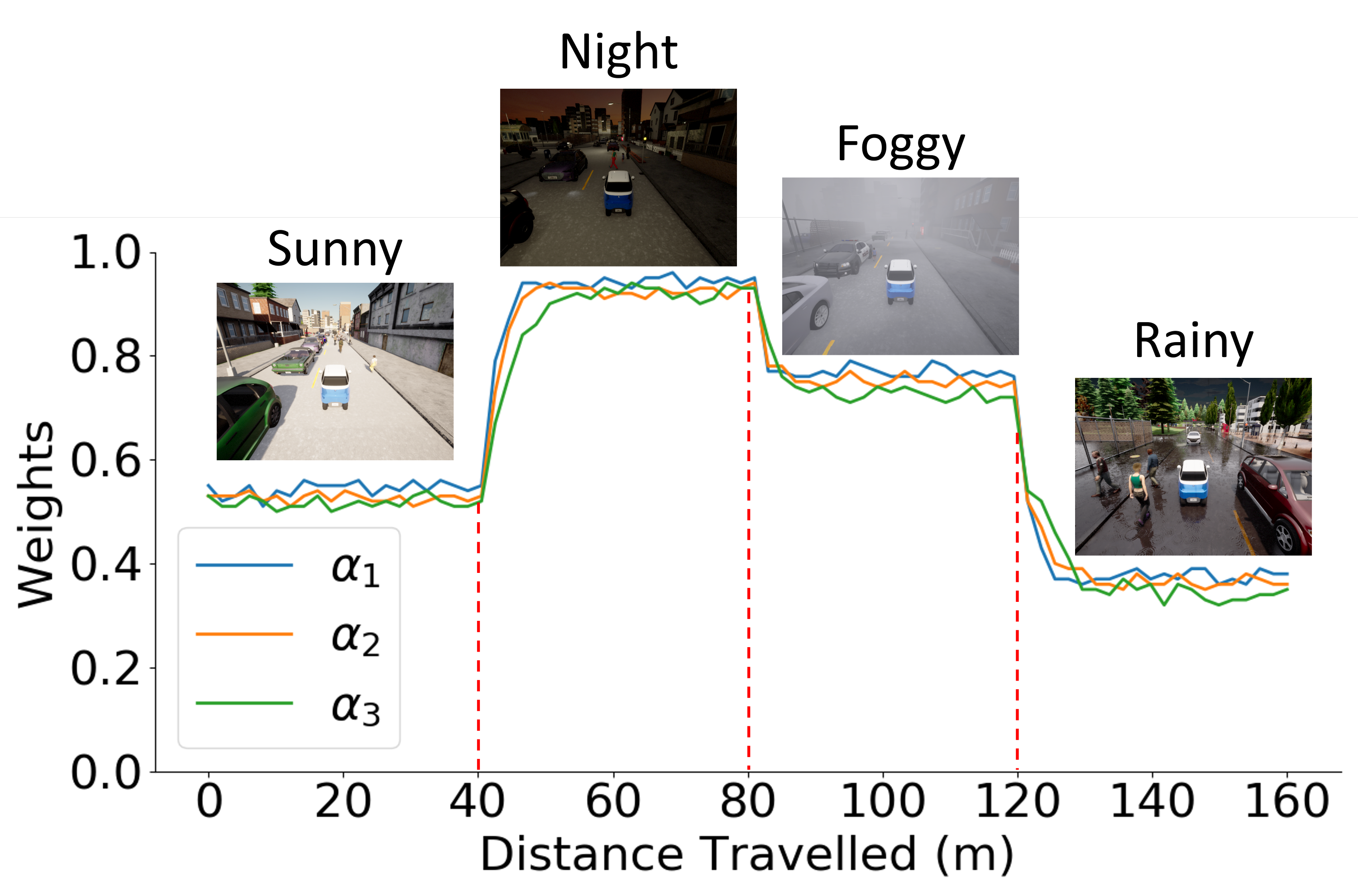
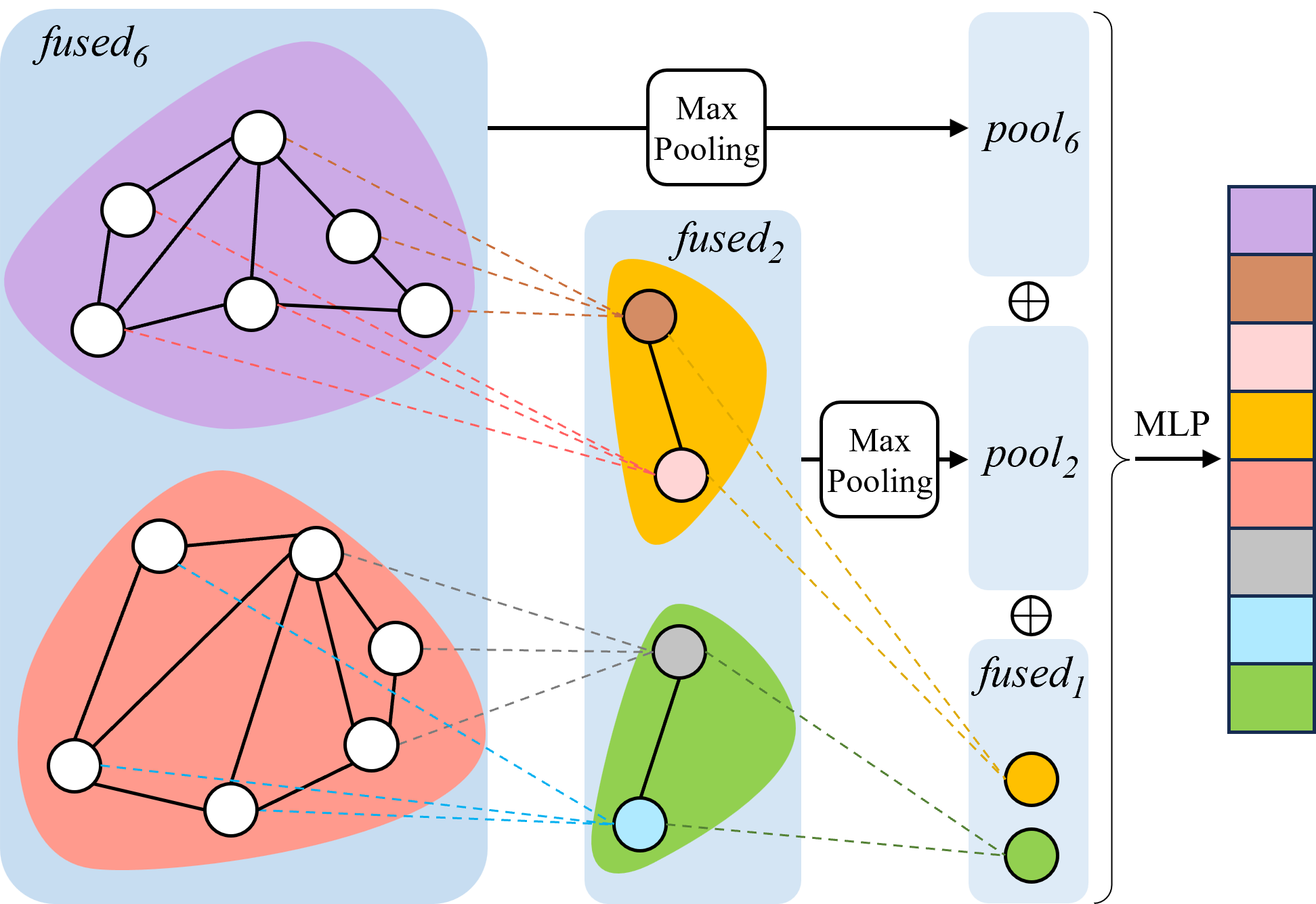
두 번째인 GHAM은 RGB와 LiDAR 두 모달리티의 특징을 각각 그래프 형태로 추출한 뒤, 계층적 풀링(Hierarchical Pooling) 과정을 통해 서로 다른 스케일의 추상화를 수행한다. 풀링 단계마다 학습 가능한 스칼라 α와 β를 도입해 두 모달리티의 기여도를 동적으로 조정함으로써, 조명 변화가 심한 RGB 이미지와 고밀도 포인트 클라우드 사이의 불균형을 자동 보정한다. 또한, 풀링된 그래프는 상위 레벨에서 다시 어텐션을 적용받아 전역적인 상황 인식을 강화한다.
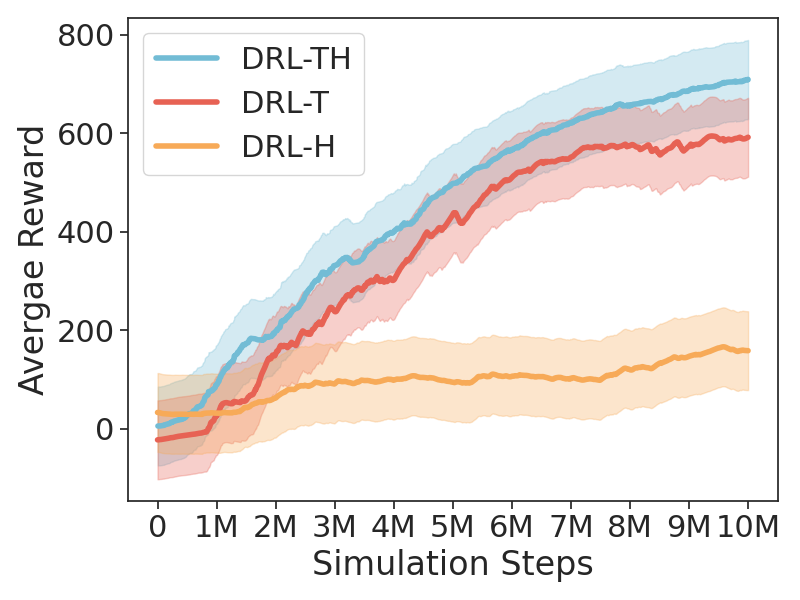
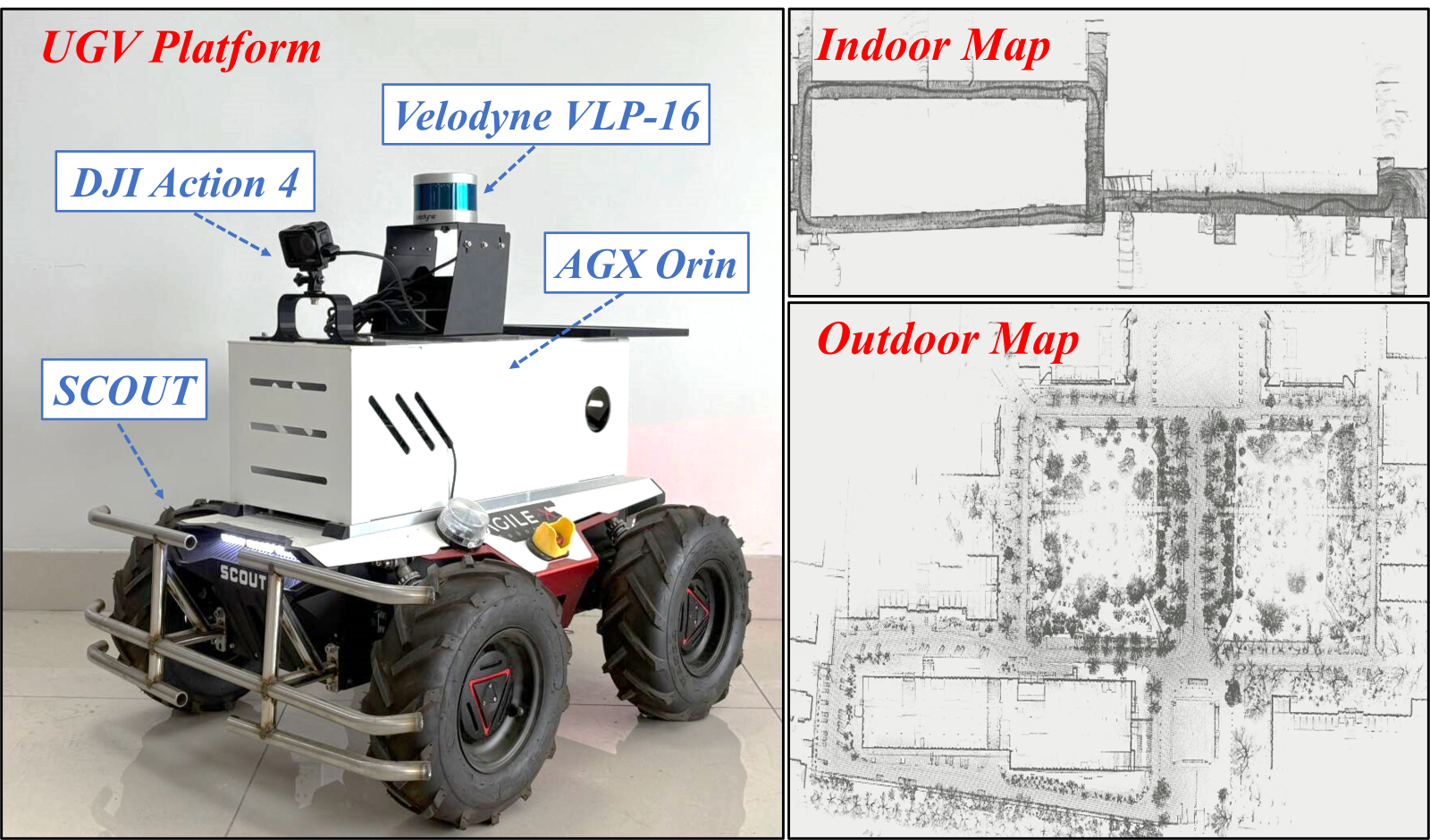
실험 설계는 시뮬레이션 환경과 실제 로봇 테스트 두 축으로 진행되었다. 시뮬레이션에서는 다양한 인구 밀도(1~5 person/m²)와 장애물 종류(정적, 동적, 복합)를 조합한 12가지 시나리오를 구축했으며, 평가 지표는 충돌률, 평균 도착 시간, 경로 효율성(길이 대비 최단 경로 비율)이다. DRL‑TH는 기존 SOTA인 “CNN‑DRL”과 “Late‑Fusion DRL” 대비 충돌률을 27 % 낮추고, 평균 도착 시간을 15 % 단축했으며, 경로 효율성에서도 유의미한 개선을 보였다. 실제 UGV 실험에서는 실내 복도와 실외 공원 두 환경에서 30 m 길이의 목표 지점을 설정했으며, 복잡한 보행자 흐름 속에서도 0.9 % 이하의 충돌률을 유지하면서 안정적인 주행을 달성했다.
이러한 결과는 그래프 기반 시간‑공간 어텐션과 계층적 융합이 DRL 정책에 풍부한 맥락 정보를 제공함으로써, 전통적인 CNN‑기반 접근법이 놓치기 쉬운 “동적 상호작용”과 “멀티스케일 센서 특성”을 효과적으로 보완한다는 점을 시사한다. 향후 연구에서는 (1) 더 높은 차원의 시계열 그래프(예: 트리 구조) 도입, (2) 온라인 학습을 통한 환경 적응성 강화, (3) 다른 로봇 플랫폼(예: UAV)으로의 확장 가능성을 탐색할 여지가 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리